




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
微博用户兴趣发现研究
[石伟杰1  , 徐雅斌
, 徐雅斌1, 2 ]
, 徐雅斌|
|


作者贡献声明:
徐雅斌: 提出研究命题;
石伟杰: 提出研究思路, 设计研究方案, 数据的获取与标注, 进行实验, 论文起草;
徐雅斌: 论文最终版本修订。
【目的】微博用户兴趣发现对微博社交网络的个性化推荐和提升用户满意度具有重要的意义和价值。【方法】不仅通过挖掘用户自身微博数据识别出用户兴趣, 而且进一步挖掘其关注用户的微博数据以及他们之间的社交联系, 并通过计算用户微博与其关注用户兴趣的相似度以及用户与其关注用户间的亲密度, 进一步发现用户兴趣。最后将从两方面发现的兴趣进行合并, 得出用户的兴趣。【结果】基于爬取的新浪微博数据集进行实验, 准确率和召回率较传统的方法提升15%以上。【局限】数据预处理中, 停用词表不充分, 没有实现停用词表的自动学习; 需人工标注用户兴趣集计算准确率和召回率。【结论】实验结果表明, 该方法明显优于传统方法, 能够更加有效和准确地发现用户兴趣。
[Objective] Discovering the micro-blog user interests plays an important role in the personalized recommendation of micro-blog social network to improve users’ satisfaction.[Methods] In this paper, apart from the data mining from the user’s own micro-blog, analyze the data of the micro-blogs that followed by this user, as well as the social correlation among them. By computing the similarity between their micro-blogs and intimacy, uncover the user interests further. Also combine the results coming from the two aforementioned aspects to get the interest set of users.[Results] This paper experiments on the dataset gained from Sina Micro-blog, and the precision rate and recall rate rise both more than 15% compared with the traditional method.[Limitations] The stop words are not full in the process of data preprocessing, because of not realize the automatic learning the list of stop words. And needs manually tagging user interest set to calculate the precision rate and recall rate.[Conclusions] The experimental results show that the method is better than the traditional method, and it’s more effective and accurate to discover user interests.
微博是一个基于用户关系进行信息发布、获取、分享、传播的平台, 它提供了单向关注机制, 用户可以选择关注其他用户, 自动接收这些用户的微博信息, 但不要求这些用户关注他。这些被关注的人可能是用户感兴趣的人, 如同事、朋友、亲人, 或某些名人。这种信息发布方式的便捷性、聚焦关注的自主性和广泛连接的社会性, 使微博这一社会媒体受到互联网用户的喜爱, 成为用户获取信息、获知社会动态的重要途径。
微博信息通常是用户行为的记录, 其中必然反映出用户的兴趣和爱好。通过对微博数据进行挖掘和分析, 可以发现用户的兴趣。针对每个用户的具体兴趣, 可以为用户推荐相应的信息、产品、广告等, 也可以为用户推荐其可能感兴趣的用户, 从而达到个性化的推荐效果。此外, 对于提升用户对网站的满意度以及促进网站自身的发展具有十分重要的作用。因此, 研究微博用户兴趣发现具有十分重要的意义。
微博的内容涉及多个方面, 从日常生活到时事新闻, 但并非所有内容都能反映出用户的兴趣。另外, 大量的微博信息也使用户无暇顾及。因此, 采用有效的方法从大量杂乱的微博信息中准确提取用户的兴趣便成为当下社交网络研究领域十分重要的课题。
Tang等[1]提出了一个新的概率图模型在网站内容中提取隐藏的话题, 并在每个网站集群上探测用户兴趣。Genc等[2]通过提取单条微博实体, 将其映射到相应的维基百科类别节点, 从而对每条微博分类。Welch等[3]分析了用户间关注和转发两种关系, 分别对由这两种关系得到的用户关系图进行分析, 发现转发用户微博比关注该用户更能体现对该用户讨论话题的感兴趣程度。Abel等[4]提取Twitter中的 HashTag、Entity等与大新闻媒体如 CNN、New York Times 等关联, 丰富微博的语义。Xu等[5]通过使用一个标识用户兴趣的变量来改进LDA(Latent Dirichlet Allocation)模型, 从而提取用户主题。Michelson等[6]将用户发布的微博中提及的实体经过消歧等处理后, 映射到维基百科的某个类别节点上, 经过投票策略可得到用户最感兴趣的维基百科类别节点。宋巍等[7]提取词语层次和主题层次的特征并进行组合, 构成特征空间, 并利用支持向量机(SVM)进行微博主题分类。方维[8]通过对微博用户行为分析, 提出了文本分类和主题库词匹配相结合的策略, 对用户兴趣进行识别。孙威[9]通过调查发现使用关注用户的微博信息具有较好的兴趣发现效果。崔争艳[10]提出一种基于语义的微博分类方法, 该方法通过对微博文本进行处理, 得到关键词语义扩展后的特征向量文本表示和训练集文本的语义特征向量, 并从训练集中选取与测试文本集中最相似的N个文本, 最后利用SWF决策规则将文本分到权重最大的类别。
根据用户兴趣的具体程度将其划分为粗粒度兴趣和细粒度兴趣。粗粒度兴趣范围广, 比较模糊, 往往可再具体划分, 如兴趣主题; 细粒度兴趣指向明确具体, 能更加细致地描述用户的兴趣, 有利于更加深入了解微博用户, 从而准确合理地进行个性化推荐。总的来说, 当前研究微博用户兴趣发现多从粗粒度层面直接对用户微博进行主题分类, 虽然取得了一定的研究效果, 但不能细致具体地描述用户的兴趣, 无法满足个性化推荐的要求, 同时这些方法未充分考虑与用户有关联的其他用户的信息, 忽略了微博社交网络的结构特征。针对这种情况, 本文基于新浪微博, 从研究细粒度层面的用户兴趣出发, 综合考虑用户与其关注用户的微博以及他们之间的社交联系, 提出一种新的发现微博用户兴趣的方法。
本文通过研究微博用户u的微博与其关注用户v的微博, 以及用户u与用户v之间的社交相关度来识别微博用户u的兴趣, 具体步骤如下:
(1) 对用户u的微博数据进行分词、词性标注、命名实体识别、句法分析、语义角色标注预处理, 之后对经过预处理的数据采用改进的tf-idf算法提取出兴趣关键词, 得到用户u的兴趣集Iu1;
(2) 采用同样方法提取关注用户v的兴趣集Iv, 经同义词合并后, 通过中文维基百科获取每个兴趣关键词 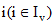
(3) 通过《知网》[11]合并用户u的兴趣集Iu1与兴趣集Iu2, 得出用户u的兴趣集Iu。
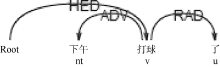
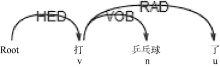
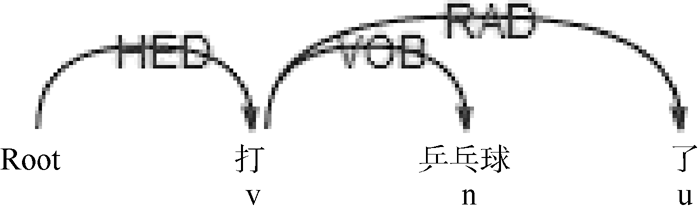
本文选取新浪微博用户发布、评论、转发的微博。通过观察微博语料发现, 兴趣关键词一般为名词或动词; 无动宾结构时语句的核心谓语和动宾结构下的宾语中心词往往能较好地代表微博用户兴趣, 分别如图1和图2所示; 趋向动词的存在可能会对正确提取核心谓语造成干扰, 如图3和图4所示:
 | 图1 无动宾结构核心谓语 |
 | 图2 动宾结构VOB |
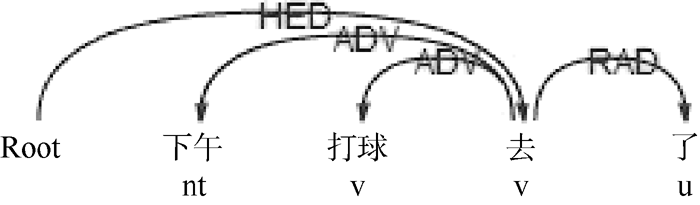 | 图3 趋向动词干扰核心谓语1 |
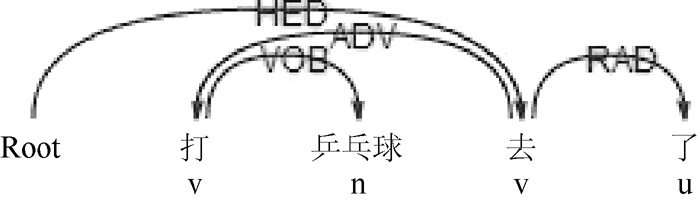 | 图4 趋向动词干扰核心谓语2 |
针对以上情况, 使用哈尔滨工业大学语言技术开发平台LTP[12]对原始微博数据进行句法分析, 该平台可实现中文分词、词性标注、命名实体识别、句法分析、语义角色标注等操作。
(1) 通过LTP平台提取微博语句中的无动宾结构时语句的核心谓语以及动宾结构下的核心谓语和宾语中心词;
(2) 构建趋向动词表对核心谓语和宾语中心词进行修正, 该表包含“ 上” 、“ 下” 、 “ 来” 、“ 去” 等22个趋向动词;
(3) 提取修正后动宾结构下的宾语中心词和无动宾结构时的核心谓语;
(4) 将全部提取的核心谓语和宾语中心词构建成动名词关键词词表。
tf-idf是一种统计方法, 多用以评估一个字词在文档中的重要程度, 其计算公式[13]为:
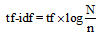 |
其中, tf表示词语t在文档d中出现的次数, idf= 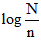
应用于微博时, 公式(1)存在以下问题: 由公式(1)可以看出, 词语t的重要度与它在当前文档出现的频率成正比, 与文档集合中包含它的文档数成反比。这就容易导致有些词在当前文档出现频率很低, 但包含它的文档数很少, 导致它的tf-idf值很高。很明显, 这与微博的实际不符。
针对这个问题, 本文对传统的tf-idf方法进行改进: 当一个词的词频低于m时, 将其滤除, 能有效地改善效果(本文取m= 2), 如公式(2)所示。利用改进后的tf-idf方法对微博文本进行处理; 按照4.1节构建的动名词关键词表进行过滤, 滤除所有不在表中的词; 提取tf-idf值最高的前K个词作为微博用户的兴趣关键词。
本文定义词频tf的值如下:
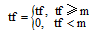 |
根据以上内容, 提出基于用户微博信息的兴趣发现算法:
输入: 经预处理后的用户微博
输出: 兴趣关键词集Iu1
(1) 计算词语ti的总词频tfi和包含这个词的微博数ni以及总微博数N;
(2) 设定阈值m, if tfi< m, then tfi= 0; else tfi值不变;
(3) 计算词语ti的idf值, 结合tfi、ni以及N得出词语ti的tf-idf值;
(4) 重复步骤(1)至步骤(3), 直到计算出所有词语的tf-idf值;
(5) 按照构建的动名词关键词表进行过滤, 滤除所有不在表中的词;
(6) 取前K个tf-idf值最高的词, 作为兴趣集Iu1。
与用户有关联的用户包括用户的粉丝、评论转发用户微博的用户以及用户关注的用户。研究表明, 通过关注用户的微博发现用户的兴趣是可靠的[9]。然而用户的关注用户中一般都含有名人, 所以将关注用户分为名人和非名人用户。
名人用户是经过官方认证的微博用户, 具有十分强大的影响力。名人的影响力是由于其知名度而并非其微博内容造成的, 故分析名人用户的微博内容意义不大。本文只分析关注用户中的非名人用户, 非名人用户的特征是粉丝数小于5万[9]。
本文识别用户u的兴趣, 需先识别出u所关注用户的兴趣。设用户u的关注用户集为V, 

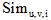
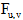
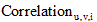

用户u与用户v对兴趣i的社交相关度 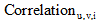

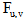
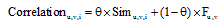 |
其中, i为用户v的某个兴趣, 
用户u对兴趣i的兴趣分 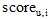

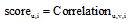 |
相似度 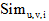
将用户u的微博和兴趣i的描述文本分别记为文档du和dvi。其中, 文档du由用户u的所有微博组成, 文档dvi由用户v某个兴趣i的解释页面文本组成, 如表1所示。使用LDA模型[15]分别计算文档du和dvi的主题分布向量 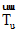
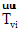
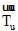
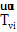
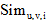
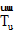
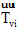
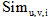
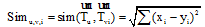 |
| 表1 兴趣i描述文本示例 |
用户间时常会进行社交联系。用户u与用户v之间的社交联系是通过用户u评论、转发用户v的微博实现的。用户间的社交联系越频繁, 他们之间的亲密度就越高, 用户v对用户u的影响就越大, 用户u与用户v之间存在共同兴趣的可能性就越高。用户亲密度Fu, v由用户u评论、转发用户v微博的次数a、b决定。
本文定义用户亲密度Fu, v计算公式如下:
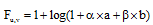 |
其中, α 、β 分别为用户u评论、转发次数的权重。社交联系中评论、转发重要性有些区别, 它们与用户使用微博的行为习惯有关。本文做简化处理, 设α =β =1。最后, 将Fu, v通过max(Fu, v)进行归一化处理。
综上所述, 提出基于关注用户信息的兴趣发现算法:
输入: 预处理后的用户u及其关注用户集V的微博数据
输出: 用户u兴趣集Iu2
(1) vk∈ V, if vk粉丝数num< 10 000, vk为非名人用户;
else对vk+1进行判断;
(2) 通过兴趣关键词提取算法获得vk的兴趣集Ik;
(3) 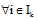
(4) 用LDA[15]分别提取文档du和dvi的主题分布向量 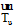
和 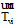
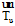
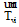
(5) 对u评论和转发vk微博的次数a和b分别设定权重α 和β , 计算亲密度Fuvk;
(6) 设定θ 值, 根据Simu, v, i和Fuvk计算 u对i的兴趣分scoreu, i;
(7) 重复步骤(1)到步骤(6), 直到所有关注用户计算结束;
(8) 取前K个scoreu, i值最高的词, 作为兴趣集Iu2。
用户兴趣可由用户兴趣集Iu1与用户兴趣集Iu2合并后的兴趣集Iu来表示。 Iu1与Iu2之间很可能存在相似兴趣, 所以需要对两个兴趣集中的相似兴趣进行合并, 得出最终的用户兴趣集Iu。
合并同义词需计算词语间的相似度, 当两个词语t1、t2间的相似度Sim(t1, t2)超过阈值δ 时, 则将两个词合并为一个词。本文使用刘群等[11]的方法计算词语之间的相似度。一个实词概念的语义表达式分为4部分:
(1) 基本义原描述式相似度, 记为sim1;
(2) 其他基本义原描述式的相似度, 记为sim2;
(3) 关系义原描述式的相似度, 记为sim3;
(4) 符号义原描述式的相似度, 记为sim4。
计算公式如公式(7)所示:
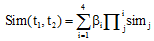 |
义原之间的相似度如公式(8)所示:
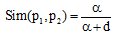 |
其中, p1, p2表示义原, d是两个义原在义原树上的距离, α 和β i为预设参数。本文采用刘群等[11]经过实验得出的参数α =1.6; β 1=0.5, β 2=0.2, β 3=0.17, β 4=0.13。
计算结束后便可得到最终的用户兴趣集Iu。其算法如下:
输入:Iu1, Iu2
输出: 用户兴趣集Iu
(1) 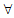
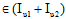
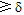
(2) 重复步骤(1), 直到Iu稳定不变。算法结束。
数据集应包含用户及其关注用户的微博信息。微博信息包含用户及其关注用户的微博和用户与其每个关注用户的社交联系(评论、转发)次数。数据集中关注用户的粉丝数应小于5万, 且对于每个用户, 粉丝数小于5万的关注用户数应不少于三个。本文使用Python语言编写爬虫程序, 从新浪微博爬取1 054个用户的微博及其关注用户的微博。经筛选, 其中符合数据集要求的用户数为927个(目标用户), 关注用户数为8 916个。
实验前需按照4.1节的要求对微博数据进行分词和过滤预处理。
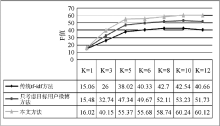
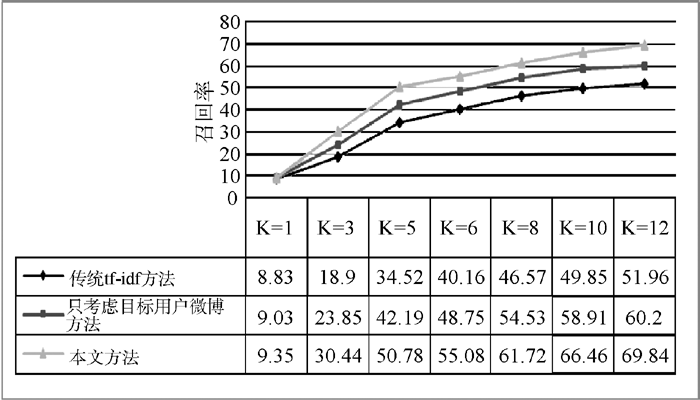
根据经验, 兴趣集Iu1和Iu2中排名靠前的兴趣具有较高的可信度, 故研究高排名的用户兴趣具有重要意义。本文重点测试兴趣集集Iu1和Iu2的K值分别取1、3、5、6这4种情况下, Iu1和Iu2合并后所得兴趣集Iu的效果, 并与传统的tf-idf [13]方法和只考虑目标用户微博方法进行对比。
将提取的兴趣关键词和人工标注的兴趣关键词进行对比, 使用准确率P、召回率R和F测度值对微博文本进行测评, 如果方法A的准确率P、召回率R和F测度值总体高于方法B, 那么认为方法A比方法B具有更高的推荐性能。分别如公式(9)-公式(11)[16]所示:
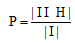 |
 |
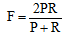 |
其中, I表示提取的关键词词集, H表示人工标注的关键词词集, |I|和|H|分别表示各词集包含的词语数目。P是准确率, 表征算法正确提取关键词的水平; R是召回率, 表征召回|H|中关键词的水平。
(1) 基于筛选后的数据集(927个目标用户和8 916个关注用户的微博)进行实验, 分别取K值为1、3、5、6、8、10、12这7种情况下, Iu1和Iu2合并后所得兴趣集Iu的实验结果。
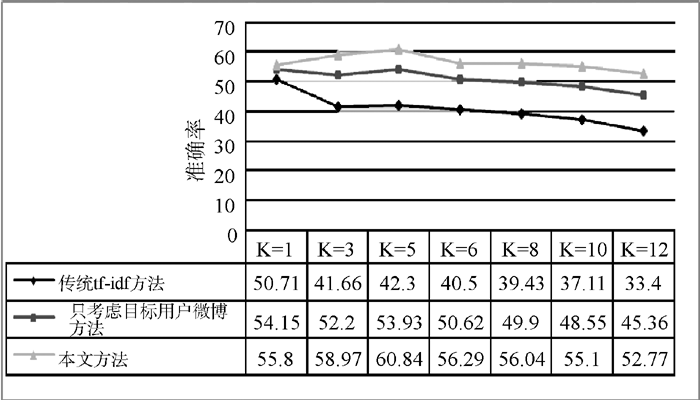
(2) 基于927个目标用户的微博使用传统的tf-idf [13]方法和只考虑目标用户微博方法进行实验, 并以此为基准, 进行用户兴趣发现效果的对比。
通过图5至图7可以看出, 在K值取1时, 三种方法性能相差不大; 随着K值的增大, 本文方法的准确率和召回率都明显优于传统tf-idf方法和只考虑目标用户微博方法; 但K值不宜过大, 否则性能会有所下降。
总的来说, 传统的tf-idf方法的实验效果不佳。这是由于微博语句短小且不规范, 前后语句联系过少, 且包含较多口语、噪音等自然语言处理常见问题。同时部分用户微博数量较少, 使得数据存在一定的稀疏性, 能挖掘的信息相对较少, 这些因素造成传统的tf-idf方法对微博文本进行兴趣关键词提取时准确性不高。只考虑目标用户微博方法由于是针对微博实际改进了传统的tf-idf方法, 故性能有了较大提高。但由于只考虑目标用户微博, 信息不够全面, 故性能仍有待提高。本文方法的性能较前两种方法有较大的提高, 这是由于针对微博文本的实际情况, 对传统的tf-idf方法进行了改进, 使之更加适应微博文本。不但考虑了目标用户的微博, 而且也考虑了其关注用户的微博, 极大地缓解了目标用户微博文本不充足的问题。同时考虑到微博社交网络的结构特征, 提取了目标用户与其每个关注用户之间社交联系(评论、转发)次数, 以此来判断关注用户对目标用户的影响, 这些因素都使得本文方法进行用户兴趣发现的效果有所提升。
本文基于新浪微博进行用户兴趣发现的研究, 使用句法分析方法对微博文本进行过滤, 综合考虑了用户及其关注用户的微博数据, 缓解了微博数据不足的情况; 同时考虑了用户与其关注用户间的社交联系对挖掘用户兴趣的贡献。通过对爬取的新浪微博数据集进行实验, 发现本文方法发现用户兴趣的效果比传统tf-idf方法和只考虑目标用户微博方法的效果都有较大提高, 从而证明了该方法的有效性。
在商业应用方面, 研究微博用户兴趣可以针对用户具体的兴趣爱好, 为用户进行个性化推荐, 同时对于提升用户对网站的满意度以及促进网站自身的发展具有十分重要的作用。下一步工作中, 笔者将在数据预处理方面加强研究工作, 重点研究停用词表的自动学习和生成。此外, 如何更准确识别不同关注用户对目标用户的影响力也是下一步的研究方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|