

{kind=link}
{kind=link}
{kind=link}
{kind=link}
社交网络中的好友推荐方法研究
[吴昊 , 刘东苏]
, 刘东苏]
, 刘东苏]
|
|


作者贡献声明:
吴昊: 提出研究思路, 实施实验, 起草论文;
刘东苏: 论文最终版本修订。
【目的】利用社交网络中用户的好友和历史行为, 为用户推荐潜在的好友。【方法】通过共同好友比例和互动比例两个指标衡量社交网络图中好友关系亲密程度, 综合社交兴趣度和兴趣相似度进行评分, 选取分数最高的Top-k用户推荐给目标用户。【结果】实验结果表明, 相比传统方法, 本文方法在准确率和召回率上均有显著提升。【局限】互动行为中的非正常情况未识别和处理, 可能影响推荐结果准确率。【结论】考虑互动比例等多因素的好友推荐方法较传统单一角度方法有更好的效果。
[Objective] Make use of the friends and historical behavior of users in social network, to recommend potential friends for the target users.[Methods] The proportion of common friends and the proportion of interaction are used as indicators to measure the closeness of the relationship in a social network graph. The relationship between friends is scored according to sociality interest and interest similarity, and the Top-k users with the highest scores are recommended to the target users.[Results] Experimental results show that the precision rate and recall rate of this method are improved significantly in comparison with traditional methods.[Limitations] Abnormal interaction without identification and treatment, may affect the accuracy of the recommendation results.[Conclusions] Considering more factors, including the proportion of interaction, the improved friend recommendation method has a better effect than traditional single factor method.
一些具有代表性的社交网站已成为影响力巨大的信息平台。社交网络上的用户和信息出现爆炸式增长, 用户找到感兴趣的内容却变得越来越困难。用户的粉丝数分布表现出明显的重尾特性[1], 少量明星用户具有较高的影响力和吸引度, 拥有大量的粉丝群, 而大部分的普通用户好友较少且不够活跃。好友推荐功能作为社交网络中非常流行且实用的个性化服务[2], 其目的是根据用户现有好友及历史行为记录给用户推荐新的好友, 使用户(特别是新用户)能更快地建立良好的好友关系圈, 融入社交网络的信息服务当中, 从而增加用户活跃度及用户对社交网络的粘着性。
目前大多数的推荐算法倾向于根据用户兴趣偏好或需求推荐网页、电影、商品、标签等相关资源[3]。然而, 向用户推荐潜在好友的算法方面的研究则相对较少。社交网络中的好友推荐, 其所推荐的不是普通物品而是其他用户, 也即是说好友推荐中推荐项目集合就是用户集合。传统推荐技术不能简单地应用于好友推荐。
Lo等[4]提出根据互动次数衡量好友之间的亲密度, 互动次数越多说明关系越好, 如果两个用户都和第三个用户有很好的关系, 则这两个用户就可能建立起新的好友关系。Chin[5]根据任意两个用户之间的手机交互次数来进行推荐。使用交互次数衡量亲密度的缺陷是依赖用户的活跃程度。Shen等[6]和Zheng等[7]分别根据关注的Blog或去过的地方分析出用户的兴趣模型, 由模型计算兴趣相似度进而发现潜在好友。Bacon等[8]提出按照用户关系先建立完全子图, 子图满足任何两个用户都具有好友关系, 然后子图之间按照共同用户数进行合并, 并为合并后的图中未建立好友关系的用户进行推荐。Wu等[9]提出了一种适合特定社交网络的根据用户的长相进行推荐的算法。牛庆鹏[10]研究了博客中的潜在好友推荐算法。于海群等[11]通过分析社交网络中用户的话题偏好提出了基于用户话题偏好的推荐算法。史岭峰[12]研究了基于社交网络好友关系的图查询算法。刘乾[13]研究了结合社交网络和地理位置信息的好友推荐方法。杨婷[14]研究了基于云计算技术的好友推荐系统。
用户关注的人分为现实好友、潜在网络好友(志趣相投的人), 以及能提供感兴趣的信息的人[15]。好友关系可以归结为交际关系和兴趣关系[15]。根据社交网络拓扑进行的好友推荐, 偏重于线下已经认识的好友即现实交际关系而忽视网络潜在感兴趣好友的推荐, 这样无法挖掘出潜在的网络好友关系, 也很难让社交网络变得更加密集。而根据用户内容或兴趣爱好进行的好友推荐虽然在网络潜在好友的推荐中发挥着更重要的作用, 但是忽视了用户行为及其中所包含的规律, 也容易由于陌生和不信任而受到用户拒绝。
Chen等[16]通过用户调查对比了4种不同算法的用户满意度。InterestBased: 内容匹配算法, 为用户推荐和他兴趣相似的其他用户作为好友。SocialBased: 好友的好友, 基于社交网络给用户推荐好友的好友作为好友。Interest+Social: 内容加拓扑连接, 将InterestBased算法推荐的好友和SocialBased算法推荐的好友按照一定权重融合。SONA: IBM内部的推荐算法, 基于SONAR系统, 该系统用于收集社会关系信息, 如公司组织结构、发布数据库、专利数据库、朋友系统、用户标记系统等。调查结果显示, 对推荐结果的新颖性有如下排名: InterestBased> Interest+Social> SocialBased> SONA。综合了更多信息的SONA推荐的好友大多数都是用户认识的, 因此新颖度不高。而从用户认为推荐结果是否好的比例看有如下排名: SONA> SocialBased> Interest+Social> InterestBased。这表明如果用户认识推荐结果中的人, 那么绝大部分用户都会觉得这是一个好的推荐结果, 反之亦然。实验结果说明, 综合考虑社交和兴趣可以有效平衡推荐结果的新颖程度和用户的信任程度。因此, 在进行社交网络好友推荐时, 可以综合考虑社交和兴趣两个因素, 找到最合适的融合参数, 从而获得最令用户满意的推荐结果。
传统的根据社交网络图计算用户相似度的方法中, 或者直接计算目标用户与待推荐用户之间的相似度而较少考虑用户好友对其交友的影响, 或者目标用户的所有好友在推荐过程中都有相同权重, 即考虑了关系数量却没有区分重要性。针对这些情况, 研究者提出了多种新的方法。胡文江等[17]将好友类比于电子商务中的交易项, 提出基于关联规则与标签的好友推荐算法。张中峰等[18]考虑用户好友对其交友的影响, 分别提出了进行相似度传播的两阶段推荐模型以及结合PageRank与信任传播思想的信任传播推荐模型, 来推荐潜在好友。杨晶等[19]突出了权威用户在好友推荐中的作用。黄亮等[20]设计了一个混合信任网络, 结合用户声望信任和局部信任来实现好友推荐。
针对传统的从社交或兴趣单一角度进行好友推荐的方法存在的局限性, 本文采用综合交际关系和兴趣关系的好友推荐方法, 而为了反映不同好友关系的内容和强度, 引入交互比例以改进社交相似度。其基本思想是, 用户的好友关系存在亲疏的不同, 用户通常更信任与其关系密切的好友, 因此关系紧密的好友在推荐过程中应当具有更大的贡献, 计算时应当对不同的好友根据关系亲密程度分配不同的信任度。本文用共同好友比例和互动比例两个维度反映交际关系。
本文的主要工作包括: 根据关系亲密程度, 改进基于社交网络图中共同好友的用户相似度的计算; 借鉴信息检索领域的TF-IDF 方法建立兴趣模型, 计算用户与待推荐好友的兴趣相似度; 综合考虑社交关系因素和兴趣因素, 给出Top-k的推荐好友。
好友关系可以归结为交际关系和兴趣关系[15]。综合考虑社交和兴趣可以有效平衡推荐结果的新颖程度和用户的信任程度。本文用共同好友比例和互动比例两个指标衡量社交网络图中好友关系亲密程度, 综合共同好友比例、互动比例和兴趣相似度进行评分, 选取分数最高的Top-k用户推荐给目标用户。
在社交网络中, 可以根据现有的社交网络图给用户推荐新的好友, 比如给用户推荐好友的好友(Friend- of-Friend)。基于好友的好友推荐算法[21]可以用来为用户推荐在现实社会中相互熟悉而在当前社交网络中没有联系的其他用户。例如使用人人网时, 经常看到一些久未联系的老同学出现在推荐好友列表中。
这种方法的优点是简洁、易实现, 效果明显。但是其缺点也是显而易见的, 如果用户好友人数不够多, 那么无论是为其推荐其他好友或者将其推荐给其他人都会变得很难。其次是该算法只是关注“ 人” 的因素而忽略了其他因素, 可能影响所推荐好友的准确性。
最简单的好友推荐算法是为用户推荐共同好友数最多的用户。其基本思想是, 用户之间的共同好友越多, 则他们越可能是好友。由于这种方法受用户好友总数影响较大, 因此通常根据共同好友比例计算相似度来推荐好友。
在Twitter和新浪微博等有向社交网络中, 用户u关注的人out(u)和关注用户u的人in(u)是两个不同的集合, 因此使用共同好友比例计算相似度有三种不同形式, 本文采用出度的方法, 用户u和用户v的共同好友比例fuv表示为[2]:
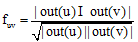 |
其中, out(u)表示用户u关注的用户集合, out(v)表示用户v关注的用户集合。out(u)∩ out(v)表示两个集合的交集。|out(u)|和|out(v)|分别表示集合out(u)和out(v)的元素个数。
不管人们有多少共同好友, 都无法确定是否会一直与其保持联系。社交网站倾向于促使用户尽可能多地与别人产生互动, 这样他们就能看到并从中提取信息。如果两个人之间没有互动, 很难称得上朋友, 互联网上也是这样[4]。
社交网络中用户之间的互动包括消息、评论、转发和收藏等形式, 转发和评论等行为在一定程度上代表着信息对于用户的吸引力[1], 评论与转发等通常有不同的权重, 为了简化计算, 本文对消息、评论和转发取相同权重。
用户u与用户v之间的互动情况iuv可以用两者之间互动次数占用户u和用户v全部互动行为的比例来表示, 本文提出的互动比例计算方法如下:
 |
其中, interact(u, v)表示用户u对用户v的互动次数, interact(u)表示用户u对所有用户的总互动次数。两用户之间互动次数用单向互动次数的平均值表示。
本文对根据社交图谱计算用户相似度的传统方法进行改进, 从共同好友和互动情况两方面来表现用户之间的关系亲密程度, 从而计算出目标用户对待推荐用户的社交兴趣度, 以此描述目标用户和待推荐用户成为好友的可能性。
建立n个用户之间的关系矩阵A, A是一个n× n矩阵, 其中, 如果用户u和v是好友关系(或用户u关注了用户v), 则auv=1, 否则auv=0。矩阵A中第u行ua= (au1, au2, 

矩阵C中元素 
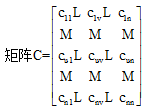
最近邻协同过滤技术中, 由于最近邻居与目标用户对项目的评分非常相似, 因此目标用户对未评分项目的评分可以通过最近邻居对该项目评分的加权平均值近似表示。类似地, 在好友推荐中, 可以把待推荐用户看作待评分项目, 把好友作为邻居, 把用户u与用户v的关系亲密程度看作用户u对用户v的评分或者邻居用户v的权重。
矩阵C中, 行向量 

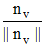


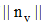
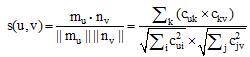 |
社交网络中用户留下的文字和行为可以反映用户兴趣和需求。通常用户可使用自然语言或者标签主动展示其喜好。这种方法可以获得一些关于用户兴趣爱好的信息, 但是其缺点也比较明显, 自然语言理解技术不能很好地理解用户的描述, 而且用户兴趣是动态变化的, 兴趣描述很容易过时, 况且很多时候用户并不知道或者很难用语言描述喜欢什么。因此, 需要通过算法自动发掘用户历史行为数据, 以推测用户兴趣, 从而推荐满足兴趣的项目。
计算用户之间的兴趣相似度, 主要思想是: 如果用户喜欢相同物品, 则说明具有相似的兴趣。微博内容可以看作物品, 如果两个用户曾经评论、转发或者收藏过同样的微博, 则说明他们具有相似的兴趣。此外, 也可以根据用户在社交网络中的发言提取用户的兴趣标签(关键词), 计算用户的兴趣相似度。基于标签的推荐中, 很多时候用户主动标记使用的标签很少, 这可能是由于用户没有使用标签的习惯或者用户新近加入或者用户活跃度较低。因此, 通常从用户的内容数据中抽取关键词作为标签或者是根据标签之间的相似度做一些关键词扩展。
本文运用现有知识计算兴趣相似度。用关键词向量描述兴趣, 用TF-IDF公式计算关键词权重, 用关键词向量之间的余弦相似度表示兴趣相似度。
一般来说, 用户兴趣可以通过向量空间模型表示为一个关键词向量。从微博内容中提取关键词的过程需要引入一些自然语言处理技术。关键词向量生成过程包括中文文本分词、命名实体(如人名、地名、组织名等)检测、关键词排名和关键词权重计算等。用户u兴趣特征向量可以表示为[2]:
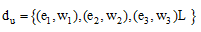 |
其中, ei是关键词, wi是关键词对应的权重。由于用户发布的微博以文本内容为主, 因此可以用信息检索领域著名的TF-IDF公式[22]计算特征词的权重:
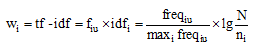 |
其中, 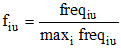
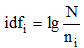
向量空间模型的优点是简单, 缺点是丢失了一些信息, 比如关键词之间的关系信息。但是, 在绝大多数应用中, 向量空间模型对于文本的分类、聚类、相似度计算已经可以给出令人满意的结果。
用户之间的兴趣相似度可以通过兴趣特征向量之间的余弦相似度计算如下:
 |
余弦值与相似度成正比, 余弦值越小表示相似度越低, 余弦值越大表示相似度越高, 其取值范围为[0, 1], 0表示完全不同, 1表示完全相同。
不同的社交网络中人们的目的和侧重点往往是存在差异的, 因此, 人们通常在不同的社交网站建立不同的关系网络。例如人人网中的好友通常以同学校友或者熟人为主, 而豆瓣网中的好友却大多因相似兴趣而聚集。因此本文先计算交际兴趣度和兴趣相似度, 然后将二者综合评分, 最终推荐得分最高的Top-k位用户。由于只需要计算存在好友关系的用户之间的共同好友比例和互动比例, 因此可以有效提高效率。
社交图谱是静态的, 没有时间变化概念, 认识10年的朋友和昨天才发生交集的朋友在社交关系图上没有明显差别; 而兴趣图谱是动态的, 其变化通常会反映在历史行为中。社交图谱反映了用户的交友倾向, 而兴趣图谱反映了用户的兴趣偏好, 将两者综合考虑很可能获得比单纯考虑社交关系或者兴趣爱好更好的推荐结果。为了便于控制以上两个因素对最终结果的影响, 可将社交兴趣度和兴趣相似度分别按最大值归一化。综合社交关系和兴趣偏好的最终评分可表示如下:
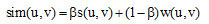 |
其中, β 是改进的好友推荐算法的可调参数, 表示最终评分中社交因素的权重, β 取值范围为[0, 1], 本文实验中β 取0.5。s(u, v)为社交兴趣度。w(u, v)为兴趣相似度。
本文好友推荐算法执行过程如图1所示:
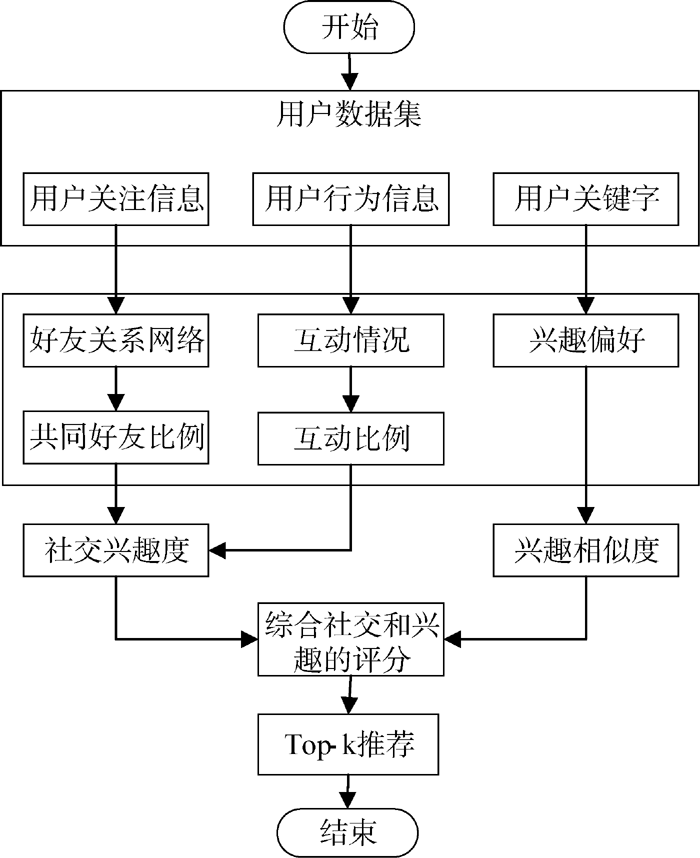 | 图1 基于社交和兴趣的好友推荐方法 |
从 2012 KDD 竞赛所提供的腾讯微博数据[23]中提取部分作为实验数据, 对本文提出的算法进行实验分析。所采集数据包括用户社交网络(关注关系)、用户社交行为(通知、转发和评论行为)以及用户关键词(关键词及其权重)。
从用户社交网络中随机选取5个较活跃用户作为种子, 采用宽度优先策略收集用户好友关系, 过滤掉好友数目少于5个和大于150的用户, 最终得到3 237个用户, 以此模拟一个小型的社交网络。随后的实验中只考虑这些用户之间的好友关系。平均每个用户关注13.4个人, 为非常稀疏的好友网络, 网络稀疏度99.6%, 表现出明显的数据长尾性。根据以上获得用户列表, 分别从用户社交行为和用户关键词中提取出相关用户的社交行为和关键词。实验数据处理步骤如图1所示。根据关系网络计算共同好友比例, 根据行为信息计算交互比例, 综合共同好友比例和交互比例获得社交兴趣度。然后根据用户关键词建立兴趣向量, 从而计算兴趣相似度。最后综合社交和兴趣两方面因素获得最终评分, 将评分最高的k位用户推荐给目标用户。
Top-k推荐中常用的评价指标有准确率(Precision)、召回率(Recall)以及综合准确率和召回率的F1-measure。其定义如下:


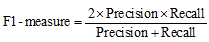
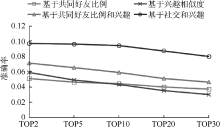
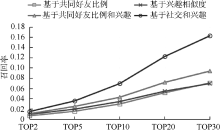
实验比较了基于共同好友比例、基于兴趣相似度、基于共同好友比例和兴趣相似度以及基于社交和兴趣相似度4种好友推荐算法的性能。图2-图4分别显示了4种不同推荐算法准确率、召回率和F1-measure的比较结果。
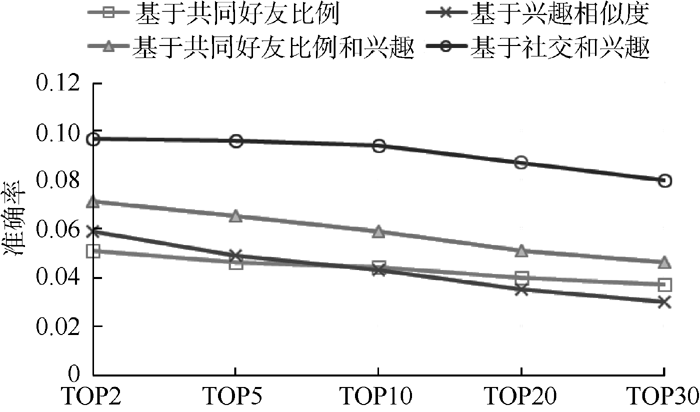 | 图2 准确率对比 |
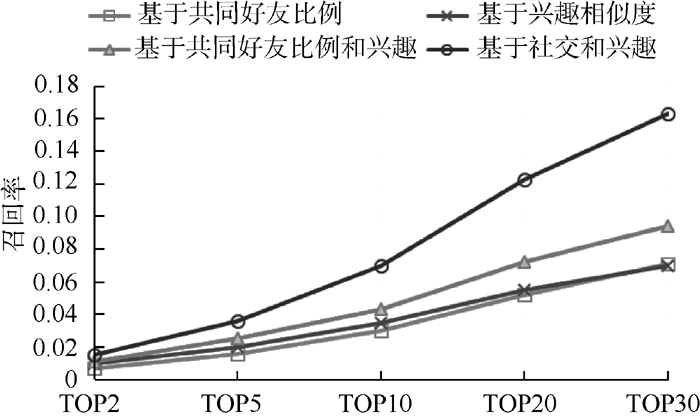 | 图3 召回率对比 |
 | 图4 F1-measure对比 |
表1显示了不同情况下, 各算法详细数据记录。数据显示当推荐用户不断增加时, 在准确率和召回率之间寻求平衡的F1-measure也随之增加, 并且增速放缓趋于平稳。可以看出, 本文方法准确率和召回率都比较高, 推荐效果要明显优于其他三种方法, 这主要是由于利用了更多的用户信息。后两种推荐方法效果要好于前两种, 这说明综合考虑社交图谱和兴趣图谱能够取得更好的推荐效果。
| 表1 好友推荐方法性能比较 |
在进行社交网络好友推荐时, 综合考虑社交和兴趣两个因素, 找到最合适的融合参数, 从而可以获得最令用户满意的推荐结果。为了区分关系亲密程度不同的好友对用户的影响, 对好友关系赋予不同的权重。本文用共同好友比例和互动比例来描述关系, 有效提高了推荐质量。
实验中仍然存在一些不足有待进一步研究。如用户之间的互动可能存在多种情况, 对于广告信息、骚扰信息等, 以及用户之间单向无回复的交流等情况, 应当采取特殊的处理措施。再如不同社交网络特征和侧重点不同, 算法中不同影响因素所占比例可能相差较大, 推荐效果也可能有所波动。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|