{kind=link}
{kind=link}
{kind=link}
普渡大学研究仓储及其支持的科学数据管理服务
[王辉1  , Michael Witt
, Michael Witt2 , 窦天芳3 ]
, Michael Witt|
|


作者贡献声明:
王辉: 提出研究思路, 设计研究方案, 起草论文;
Michael Witt: 仓储建设者, 设计研究方案;
窦天芳: 设计研究方案, 论文最终版本修订。
【目的】对普渡大学研究知识库案例进行全面剖析。【方法】分别从PURR平台的建设背景、保存政策、保存策略、工作流、参考标准、开发平台、元数据、数据引用、数据备份、工作机制以及PURR支持的大学科学数据管理服务等方面进行分析。【结果】PURR参考多个标准进行建设, 支持数据服务, 但在用户体验及元数据支持等方面仍需完善。【结论】PURR作为先驱性的数据管理工具, 其在开发及推广过程中积累的经验可以为我国开展数据管理实践提供参考。
[Objective] Conduct a comprehensive analysis of the case of Purdue University Research Repository (PURR).[Methods] This article analyzes the case from many aspects, including the construction background of PURR platform, preservation policy, preservation strategies, workflow, reference standards, development platform, metadata, DataCite, backup, working mechanism and the campus scientific data management services supported by PURR.[Results] Development of PURR is using many standards to support the data management services, but it still need to improve in user experience, metadata support and other aspects.[Conclusions] As a pioneer of data management tools, experience about PURR gained in the development and promotion provides a valuable reference for data practice in China.
《第四范式: 数据密集型科学发现》阐述了科学范式从经验到理论再到数据驱动科学计算的转变, 数据不仅是科学研究的结果, 而且是科学研究的基础, 越来越多的联邦资助机构对研究人员的数据管理提出明确要求。早在2003年, 美国国立卫生研究院(NIH)就对资助金额超过5万美元的项目提出数据共享要求[1]。2011年1月, 美国国家科学基金会(NSF)开始要求受资助的所有科研提案必须包括两页的数据管理计划[2]。美国国家人文基金会(NEH)也要求基金申请必须包含数据管理计划[3]。美国国家司法研究所(NIJ)要求拨款项目结束前90天内提交数据归档政策[4]。
基金资助机构对数据管理和数据共享的要求给大学图书馆发展带来新的机遇, 一些大学图书馆已经开展了数据管理服务, 结合图书馆学专业知识帮助研究人员解决数据管理问题, 探索嵌入科学研究生命周期的数据管理服务。如协助研究人员制定符合基金要求的数据管理计划, 组织、描述研究数据集, 建设数据馆藏与数据仓储, 制定数据保存策略, 开展数据素质教育。美国大学与研究图书馆协会(ACRL)2012年白皮书调研了美国和加拿大的221家协会成员馆, 对这些学术图书馆的科学数据服务与服务计划进行了评估, 已有32家图书馆提供了数据存储、监护的基础设施, 46家图书馆嵌入了研究项目提供数据管理咨询服务[5]。
我国对科学数据管理的研究无论是理论上还是实践上都处于起步阶段。理论方面大多局限于总结和归纳, 如国外典型的研究数据管理框架实例对比分析[6], 基于数据生命周期的研究数据管理工具分类[7], 国外高校图书馆的研究数据管理服务[8], 图书馆在科学数据管理中的角色[9]等内容。实践方面目前也仅停留在初期探索阶段, 如武汉大学图书馆利用DSpace构建社会科学数据管理平台, 并对如何开展科学数据管理服务进行了相关思考[10], 武汉大学图书馆科学数据管理与服务的案例分析[11], 复旦大学进行高校科学数据管理平台系统选型研究[12]等。
本文从政策与管理设计、技术路线、建设与维护以及支持的服务方面进行普渡大学研究仓储PURR的案例分析, 为我国开展数据管理实践提供了参考。
普渡大学是一所在科学、技术、工程领域领先的大学, NSF是普渡大学最主要的研究项目资助来源, 每年资助超过1亿美元。为帮助研究人员实施基金要求的数据管理计划, 普渡大学图书馆调整了服务布局, 2010年普渡大学图书馆馆长、信息技术副主任、研究副校长办公室共同组成指导委员会, 计划建设普渡大学数据管理平台[13]。2011年来自图书馆、信息技术部、系统服务部和研究副校长办公室的专门工作人员组建了普渡大学研究仓储(Purdue University Research Repository, PURR)工作组, 基于HUBzero平台开发了PURR。2012年PURR正式开展服务, 为普渡大学研究人员提供一个在线合作的工作空间与数据共享平台[14]。
PURR的保存政策由数据监护、数字保存方面的专家合作完成, 为PURR的保护方向和操作提供了基本框架, 其核心是PURR作为普渡大学图书馆的一部分, 有责任识别、保护数字资产, 提供保存和持续访问的方式[15]。PURR服务模型的基础部分是承诺成为可靠的、长期保存的出版物。为了保证指定用户社区(普渡大学的教师、科研人员、研究生和直接合作者)和较大的学术社区, PURR是一个可利用的、安全的数据仓储。基于发布数据集关系、正在进行的教学价值、长期研究价值开发保护优先结构。
数据归档专家结合PURR的保存政策与ISO 16363制定了数据集的保存战略计划和保存策略。保存战略计划列出了PURR的总体目标是提供长期数字保存, 并保证数据的长期可访问性。保存策略制定了具体的政策和保存措施, 描述保存支持的类, 首选文件格式, 每类数据可能的保护措施。PURR提供三个保存级别, 即比特级保存、全部保存和不保存。PURR在摄入时使用英国国家档案数字记录对象识别(Digital Record Object IDentification, DROID)[16]的PRONOM文件格式注册表进行检查, 根据数据集情况确定目标文件的保存级别, 如图1所示, 保存水平可以在数据集生命周期各阶段灵活转换。
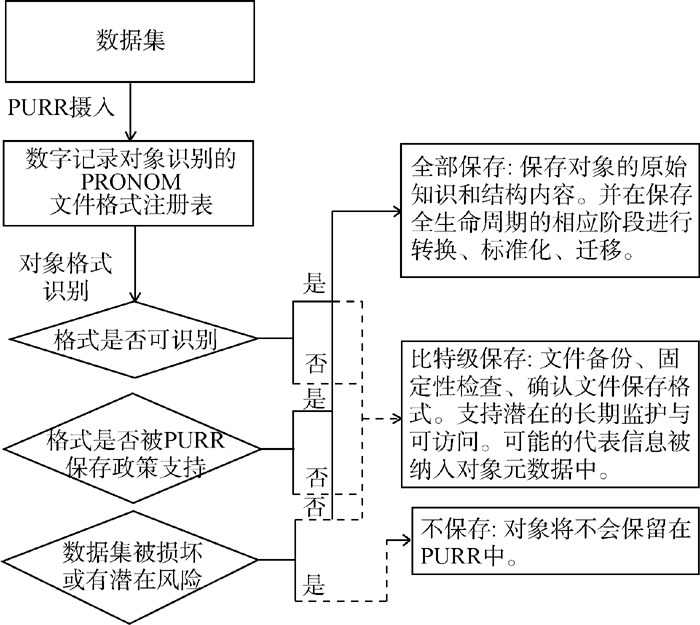 | 图1 数据集保存级别 |
PURR的保存策略列出了数据集生命周期中的保存措施, 包括: 文件格式识别、标准化、固定性检查、迁移和文件备份, 如表1所示:
| 表1 数据集保存措施 |
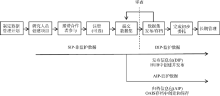
PURR结合科研人员对数据管理的需求制定了符合其服务模式的工作流框架, 如图2所示:
 | 图2 PURR工作流[13] |
研究人员在PURR上注册一个账号, 同时可以通过PURR创建ORCID账号, 在PURR里创建一个项目空间, 并邀请合作者共享。项目创建人及合作者都可以填写在线表单提交数据集, 在线表单内容包括数据描述信息与数据使用的条款。数据描述信息供元数据捕捉, 数据使用条款包含隐私、保密、知识产权、版权、数据访问与共享等信息。最后检查并保存数据集及评论后提交。
数据集提交后进入开放档案信息系统(Open Archival Information System, OAIS)流程, PURR将实际数据集、元数据信息打包成提交信息包(Submission Information Package, SIP), PURR的仓储专家、相关学科馆员通过审查SIP确认数据集是否符合发布要求, 审查内容包括数据集是否符合PURR的保存政策, 数据集的元数据与数据内容信息是否完整。如不符合发布要求, 审查员将给研究人员发送提交审查意见, 建议提交到其他仓储及其具体信息。如符合发布要求, 学科馆员在标签字段增加该学科领域的控词, 自然语言与控词的结合为数据集检索与发现提供丰富的描述信息。之后系统启动档案信息包 (Archival Information Package, AIP) 创建工具, 完成一系列的元数据生成过程, 元数据及所有的保存数据、保存文件放在一起准备保存。
PURR参考值得信任的仓储审核检查表(Trusted Repository Audit Checklist, TRAC)作为设计指导文件, 从可信任数据仓储的高度设计PURR, TRAC提供了数据保存基础设施严格的、规范化的路线图, 给出84条标准条款, 对组织架构、数字对象可靠性、软硬件的迁移、数据安全性等方面提出明确要求, 为建设良好的数字保存环境提供了保障。TRAC通过了标准过程, 成为数字仓储国际标准ISO 16363[17]。PURR借助该标准建设值得信任的数据仓储。
PURR基于HUBzero平台开发, HUBzero作为支持科学发现、学习与合作的开源工具起源于美国NSF资助的计算纳米技术网络(NCN)系统nanoHUB。nanoHUB利用开放资源LAMP(Linux+Apache+MySQL+PHP)平台和Joomla内容管理系统开发, 可维护教程、演示、动画、视频和文件等各种数字内容的提交和共享, 并支持一套协作功能, 包括标记、注释、排序、维基、日历、引用跟踪和工作板。支持通过远程访问虚拟机共享桌面, 访问后端的计算, 在TeraGrid和开放科学网格存储资源[18]。截至2014年5月, nanoHUB.org用户总数已超过327 000[19], 经常被NSF及其他网络基础设施作为成功案例引用。HUBzero科学协作平台是nanoHUB网络基础设施的通用版本, 可以根据需求定制。HUBzero平台的协作、发布服务满足PURR的需求, 且方便解决代码集成和本地技术支持的问题。PURR为项目内合作提供一个专门的工作空间, 可用于存储数据、项目跟踪、Wiki及待办事项清单。用户创建一个项目后, 可邀请其他合作者进入项目。PURR平台支持用户发布数据集供公开获取和发现。
HUBzero在开发时没有考虑元数据及保存问题, PURR的元数据专家为兼顾数据描述、发现、可跟踪及保存需求, 采用多种元数据标准, 将几个元数据标准整合到一起, 形成一整套PURR的元数据解决方案[20], 如表2所示:
| 表2 PURR采用的元数据标准 |
为了支持有效的数据集发现, 描述性元数据必须完整可索引, PURR中利用DCMI元数据标准记录描述性元数据, 研究人员在创建项目和发布数据集的过程中, 需要填写在线表单, 这部分信息将被纳入描述元数据部分, 如表3所示:
| 表3 描述性元数据映射关系 |
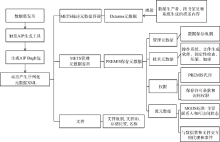
PURR利用美国国会图书馆的BagIt打包数据集及元数据, 数据集被批准发布后, PURR开发的档案信息包生成工具开始对元数据进行打包、序列化并生成可扩展语言 (eXtensible Markup Language, XML)文件。AIP首先生成AIP BagIt包, 写入METS元数据包, 依次插入描述性元数据、技术元数据、权限部分、源元数据、文件部分, 如图3所示。经过验证完整的AIP数据集一起保存。
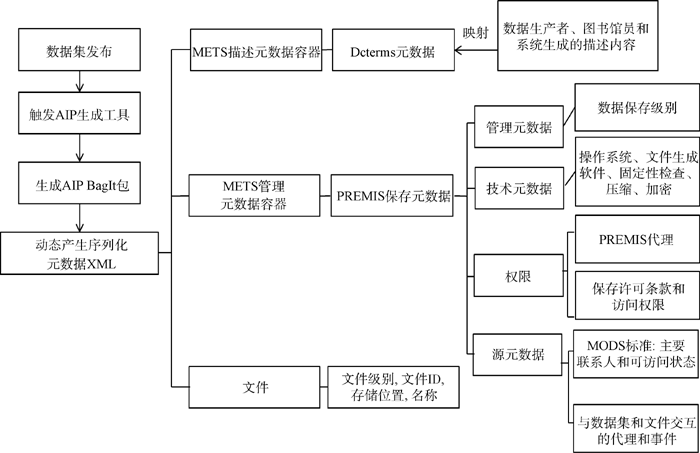 | 图3 元数据生成过程 |
在PURR中保存的数据将获得唯一的、持久的数字对象标识(Digital Object Identifier, DOI), 数据创建者的ORCID账号将包含在DOI元数据中, 并显示在DataCite引用信息中[26], 如表4所示。PURR使用多个开放标准最大限度地提升数据的可发现与可利用性。
| 表4 PURR 中的ORCID信息 |
PURR利用分布式数字保存模型作为AIP的战略备份。普渡大学是MetaArchive合作成员[27], MetaArchive利用LOCKSS软件通过复制和地理分配创建数字保存网络, 为PURR提供强大的存档备份, 建设普渡大学本地和卫星存储基础设施。
PURR工作组由图书馆、信息技术部、研究副校长办公室组成。研究办公室熟悉研究人员的工作, 将项目资助者的要求与研究者的需求纳入到PURR的设计中。信息技术专家和研究计算机专家负责软件开发与迭代更新, 利用专业知识和能力应对如服务器和存储基础设施等相关的技术挑战。图书馆员进行数字化保存、永久标识符、元数据、数据发现等问题的实施。
项目组在平台建设过程中开展了一系列广泛讨论, 就工作流的每一步实施、仓储系统提供的功能、成员需要完成的任务、每一步的政策进行讨论, 充分利用PURR项目空间的协作功能, 将议程、讨论记录及相关文件记录在Wiki上, 共同创建和编辑文件, 发布资源。工作组成员通过使用PURR获取系统用户体验并提出即时反馈帮助系统改善。研究组成员分组完成研究任务, 在随后的会议中汇报提案、讨论实施方案, 这是一个反复完善的过程。
(1) 数据发现与数字化保存
图书馆通过PURR完成了数据对象的描述及技术、管理元数据的采集, 支持基本的数据集检索与浏览。PURR将本地元数据记录映射到DCMI中, 通过开放档案元数据收割协议(Open Archives Initiative Protocol for Metadata Harvesting, OAI-PMH)收割元数据, 在图书馆在线检索中建立索引, 使研究数据集与图书、期刊及其他馆藏一样被检索与发现。此外, PURR通过与DataCite集成, 使得PURR里所有发布和存档的数据集都可获取一个DOI, 有利于数据引用与访问。
PURR提供数据集内的关系与语义文件的保存与存档, 承诺数据集将被发布、归档10年。数据集创建者将在数据集过期前6-12个月内接到电子邮件通知, 如果不再购买额外的存储, 数据集将被保存在图书馆内, 相关学科馆员评价数据集, 并将其纳入正规馆藏。
(2) 数据管理计划
根据基金资助方对数据管理的要求, 数据管理计划应包括研究将产生的数据类型、描述和格式化数据所采用的标准、共享数据所涉及的知识产权政策、隐私、权利、数据重用、归档与保存计划。普渡大学图书馆为研究者提供了一个简明问题列表, 帮助研究者撰写数据管理计划[28]。针对不同的基金要求设计了个性化的数据管理计划教程, PURR工作组的成员建设并维护知识基地, 提供科学数据管理常见问题解答。
(3) 数据参考咨询
普渡大学利用嵌入图书馆网页的即时聊天工具与电子邮件提供数据参考咨询服务, 支持问题记录与问题查找。普渡大学图书馆将PURR纳入到现有的咨询服务框架中, 在PURR中嵌入咨询软件, 基于DCC的数据监护生命周期预测可能出现的咨询问题, 将问题映射到现有的服务中。这些映射包括: 在NSF项目申请时如何撰写数据管理计划; 如何选择正确的数据仓储保存研究产生的数据; 撰写文章时如何引用科学数据; 如何发现课堂作业或研究需要的数据。对于普渡大学及图书馆没有提供解决方案的问题, 学科馆员利用自身的知识与技能帮助用户有效地发现、评价并使用其他可用的数据资源与服务。
当研究人员在PURR中创建一个项目时, 相关学科馆员同时收到项目创建的提示邮件, 当一个项目成员发布数据集或归档, 学科馆员会再次得到通知。学科馆员可以联系项目组, 了解研究并与项目组进行合作。研究人员也可以通过PURR网站联系相关学科馆员帮助他们完成、修改数据管理计划, 学科馆员以首席合作研究者、高级人才的角色与研究人员合作开展数据密集型研究。
普渡大学图书馆从2011年8月开始将数据相关的主题培训纳入到每年的员工培训内容中, 学习哪些数据对学术领域是重要的, 数据如何描述, 在何处储存, 及数据相关的知识产权、长期保存、元数据、真实性等问题, 学科馆员研究与本学科相关的数据问题, 并将数据纳入馆藏、教学和咨询工作。
在基金的要求以及研究人员的数据管理需求的驱动下, 普渡大学图书馆分布式数据监护中心已经开展了一系列数据管理服务, 包括面向用户的数据问题指导、数据素质教育、数据参考咨询。PURR作为大学的数据仓储, 为普渡大学开展一系列的科学数据服务提供了一个平台, 为学科馆员广泛嵌入研究人员数据管理提供了机会。
PURR参考ISO 16363建设值得信任的数据仓储, 利用现有的METS、DCMI等标准支持数据发现、利用与长期保存, 并将第三方服务ORCID与DataCite有机地嵌入平台中, 为普渡大学研究人员提供了一个制定和实施数据管理计划平台, 满足大多数基金对数据管理的要求, 支持研究人员开展在线合作研究, 发布数据集与工具, 构建了强大、安全、长期的数字保存环境。
PURR目前的核心元数据采用DCMI标准, 对于地图、影音、基因数据等特定类型的数据集合的描述支持尚显不足, 在DCMI标准上扩展描述性元数据还是引入特定学科的元数据标准仍是PURR正在解决的问题。
PURR工作组是个活跃的组织, PURR与HUBzero团队每年举办两次PURR CAMP活动, 结合最新技术和应用反馈讨论PURR下一阶段的新功能, 制定明确的开发与改进计划, 例如增加面向特定学科特定类型数据的功能模块, 支持与Google Drive的互操作, 增加RSS定制、标签云图、通讯功能与研究组日历等功能, 改进Wiki功能, 安全升级, 改善本地备份等。
PURR作为普渡大学机构数据仓储, 在协助普渡大学研究人员申请基金、提交数据管理计划方面发挥了重要作用, 已经在普渡大学研究人员中形成一定影响, 但在用户体验及元数据支持方面仍需完善, 作为先驱性的数据管理工具, 其在开发及推广过程中积累的经验为我国开展数据管理实践提供了参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|