{kind=link}
{kind=link}
社会化标签质量自动评估研究
[章成志1, 2  , 李蕾
, 李蕾1 ]
, 李蕾|
|


作者贡献声明:
章成志: 提出研究思路, 讨论研究方案, 数据采集, 论文起草及最终版本修订;
李蕾: 设计研究方案, 实验设计与实施, 数据分析。
【目的】对用户标注的大量标签实现自动评估, 自动选择或推荐高质量的标签, 提高社会化标签应用效果。【方法】现有的标签质量评估研究割裂了标签的内容属性与社会化属性, 没有结合标签多方面属性进行综合评估。因此本文以博文标签作为研究对象, 融合社会化标签内容属性与社会化属性, 利用统计机器模型对社会化标签质量进行自动评估研究。【结果】结果显示, 结合标签的内容属性特征和社会化属性特征, 支持向量机标签质量评估模型评估结果明显优于多元回归和朴素贝叶斯评估结果。【局限】仅使用科学网博文的标签数据, 其社会化功能还不够完善, 一些社会化属性并不能有效地提高社会化标签质量自动分类效果。【结论】该工作为进一步提升社会化标签的组织与应用质量打下基础。
[Objective] It’s important to improve application performance of social tags by selecting or recommending tags with high quality automatically.[Methods] The existing research on quality evaluation of social tags are separated into content and social attributes of tags, which don’t combine these two attributes to evaluate the social tags. In this paper, the authors use tag’s content and social attributes to evaluate the quality of tags by statistical machine learning model.[Results] Exprimental results show that with combining content and social attributes of tags, the quality evaluaton model based on SVM outperforms other models.[Limitations] Only use the blog tag data to evaluate the quality of social tags. The performance based on the social attributes are not perfect. Some social attributes can not effectively improve the automatic classification of social tags’ quality.[Conclusions] This work is useful for improving the performance of the tags organization and related application.
随着互联网技术和应用服务的不断发展, Web2.0的概念逐渐深入人心。Web2.0网站为互联网用户的信息生成、信息共享及信息获取提供了便利的平台。传统的以系统为中心的互联网正逐渐转变为以用户为中心的互联网。互联网用户在加工、传播、浏览网络信息的同时, 产生了大量的用户生成内容(User Generated Content, UGC), 即广大用户既是内容的消费者, 同时也是内容的生产者。社会化标签作为UGC的典型代表之一, 融合大众智慧, 对Web 页面浏览、组织与索引非常有效[1]。不少学者依据社会化标签特性进行Web 资源的自动分类、信息检索、信息推荐等不同应用场合, 取得一定效果[2, 3, 4]。与基于受控词汇的传统资源组织方式不同, 基于社会化标签的资源标注和组织方式成本较小、且比较容易扩展。由于互联网用户使用的标签多采取自由标引方式, 部分用户标注标签时比较随意, 从而使得有些标签并不能有效地揭示资源的内容或主题, 于是产生了一些低质量的标签。常见的低质量标签包括: 标注过于主观、拼写错误、垃圾标注等。社会化标签的质量问题已成为影响其应用效果的重要因素之一。低质量的标签干扰了资源组织的秩序, 降低了标签在信息组织与检索中的应用效果。因此如何对用户标注的大量标签实现自动评估, 自动选择或推荐高质量的标签, 是提高社会化标签应用效果亟待解决的问题。针对低质量标签问题, 现有的标签质量评估研究割裂了标签的内容属性与社会化属性, 没有结合标签多方面属性进行综合评估。
针对该问题, 本文以科学网博客标签数据为研究对象, 结合标签的内容属性与社会化属性, 建立标签质量评估数据集, 通过机器学习方法训练标签质量评估模型, 进而实现社会化标签质量自动评估。该工作为进一步提升社会化标签的组织与应用质量打下基础。
现有标签质量评估方法主要包括人工方法[5, 6]、基于标签自身统计属性[7, 8, 9, 10]、依据规范词语[11]、依据标签和主题词的比较[12, 13]、依据用户标签与专家标注结果的比较[14, 15]、依据标签与文本内容关键词的比较[16, 17]、基于信息检索[18, 19]以及基于用户、资源、标签三者关系来评估标签质量[20, 21]等。
当前标签质量评估通常利用标签的统计属性, 其代表性工作包括: Van Damme等[7]利用标签频率、标签同意度、TF-IDF三个维度来评估标签质量, 并让用户评估筛选出高质量标签, 结果得出利用标签频率和TF-IDF评估出的标签质量好于利用标签同意度评估出的标签; Zhang等[8]提出标签的三个统计属性可以用来衡量标签质量, 即中心性、频率与熵值, 结果得出标签的频率和熵值可以有效衡量标签质量; Belé m等[9]利用标签共现(两个标签同时出现的频率)、标签稳定性(确保标签既不太普遍也不太专指, 保持稳定的状态)、标签描述力(衡量标签是否同时出现在标题和描述中)等三个指标评估标签质量; 孙柯[10]将明晰度、TF-IDF度量以及信息增益等三种指标用于评估标签质量。
需要指出的是, 目前标签质量研究基本上只利用标签的单一属性, 这样割裂了标签内容属性与社会化属性之间的相互影响关系, 未将各属性结合进行综合分析, 以实现标签自动评估。因此, 如何结合社会化标签多方面属性进行全面的质量评估, 是值得深入探索的问题。
针对标签质量问题, 文献[22, 23, 24]对标签质量评估、标签类型和用户标注行为相关的研究进行调研, 开发标签评估系统, 收集相关标注数据, 对用户在不同标注系统的标注行为进行分析。这些工作是在宏观领域对各种类型的标注对象的标签进行研究, 而本文主要针对博客类型的标签, 利用统计机器学习的方法, 探索如何进行标签质量自动评估研究。
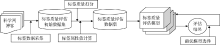
本文选取科学网博客①(①http://blog.sciencenet.cn, 数据获取日期: 2013年8月25日。)的博文标签数据作为研究对象, 随机抽取一定规模的博文, 将其对应的标签作为标签质量评估初始数据集。邀请志愿者对随机抽取的博文标签进行质量打分, 志愿者打分时参考事先设定的评分参照表; 对每个标签的属性值进行计算; 以上两个过程完全独立, 是分别进行的。基于上述过程建立科学网博文标签质量评估数据集, 由此可构建标签质量评估模型。选取朴素贝叶斯、支持向量机以及多元回归模型作为候选的标签质量评估模型, 依据测试数据对各个模型进行性能评价, 选择性能最优的标签质量评估模型, 以实现标签质量自动评估。标签质量自动评估的基本框架如图1所示:
 | 图1 社会化标签质量评估模型构建的流程图 |
(1) 社会化标签质量评估数据集的建立
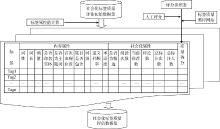
社会化标签质量评估数据集是本文选择标签质量评估模型的基础。社会化标签质量评估数据集的建立步骤为: 采集科学网博文的标签数据作为研究对象、抽样一定规模的数据作为标签质量评估初始数据集; 设立标签质量得分的打分参照表, 通过已开发的标签质量测评网站邀请志愿者依据该打分表, 按照标签与标注资源的相符程度, 给出标签质量分值; 利用计算机自动生成标签的属性值, 标签的属性包括内容属性值和社会化属性值; 综合考虑标签属性值和质量得分, 得到关于标签质量评估数据集。图2为社会化标签质量评估数据集的建立过程示意图, 其中列出社会化标签的各种属性。
 | 图2 社会化标签质量评估数据集的建立过程示意图 |
①标签质量打分
标签质量分值的打分依据为标签与所标注资源的相符程度, 利用“ 5分” 规则对标签进行打分, 从“ 1分” 到“ 5分” 利用描述的相符程度进行排序, 打分规则如表1所示:
| 表1 标签质量打分规则说明与举例 |
确定好标签质量评分依据后, 笔者开发了在线标签质量测评网站, 对随机选取的博文标签进行打分, 邀请有过标签标注经验的志愿者对博文内容进行详细阅读, 然后按照上述标签质量打分规则, 对随机选取博文的标签打分, 共完成2 000个标签打分。
②标签属性值计算
标签属性计算主要包括内容属性和社会化属性两个方面, 现将各个属性分别说明如下。
1) 标签的内容属性主要包括标签的词性、词长、熵值、是否为主题词、是否为命名实体、标签首次出现位置、博文的题目中是否包含该标签、标签的词频、逆文档频次、术语度。
词性(POS): 利用词性标注工具包①(①https://pypi.python.org/pypi/jieba/.)得到各个标签的词性; 根据标签在博文中的上下文进一步做人工校对, 得到每个标签最终的词性, 并按照不同词性提供信息量的不同, 对各个标签的不同词性赋予不同权重值。本文对名词(n)赋予最高权重1, 动词(v)、形容词(a)、成语(i)、习用语(l)、区别词(b)、状态词(z)赋予权重依次递减, 依次为0.9、0.8、0.7、0.6、0.5、0.4。
词长(Len): 计算各个标签的词长, 本文将中文标签的字符数作为其词长。例如: 标签“ 科研” 词长为2, 标签“ 新人文主义” 词长为5, 并将每个词语的长度除以数据集中长度最长的标签的长度(本次实验数据集中的最大词长为10), 进行归一化处理。
熵值(Entropy): 标签熵值的计算公式为:
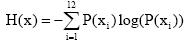 |
其中, i表示科学网上博文分类类目的序号; P(xi)的计算公式如下:
 |
是否为主题词(Is_Thesaurus): 判断各个标签是否在中国分类主题词表中, 存在为1, 不存在为0。
是否为命名实体(Is_Entity): 利用词性标注工具包进行词性标注时, 可以识别出人名、地名、机构名和时间词, 同时为了确保结果准确性, 通过人工校对确定标签是否为命名实体。即是否是人名、机构名、地名、时间、日期、货币等。如果为命名实体赋值为1, 否则为0。
标签首次出现位置(Pos_First): 计算标签在文章中首次出现的位置, 并将其除以该博文的长度进行归一化处理。
博文的题目中是否包含该标签(At_Title): 判断博文标题中是否存在此标签, 存在赋值为1, 不存在赋值为0。
标签的词频(TF): 计算该标签在博文中出现的次数, 将其除以该标签所在博文中最高词频词语的词频数, 得到归一化结果。
逆文档频率(IDF): 逆文档频率是一个词语普遍重要性的度量, 如果包含某一词语的文档越少, IDF越大, 则说明这一词语具有很好的类别区分能力[25], 为了将计算结果归一化处理, 其计算公式如下:
 |
术语度(Termhood): 术语度由Kageura和Umino[26]于1996年定义为“ 候选术语与一特定领域概念的相关程度” 。同时为了将计算结果归一化处理, 计算公式如下:

(4)
本文所使用的前景语料为课题组抓取的带有标签的科学网博文数据(时间跨度为: 2007年3月6日-2013年8月25日), 背景语料为《人民日报》1998年1月-6月的标注数据[27]。
2) 标签的社会属性主要包括当前标签对应博文是否为精选博文、阅读次数、推荐数、评论数、使用该标签进行标注的总标注次数、使用该标签进行标注的总标注人数。
当前标签对应博文是否为精选博文(Is_Refining): 判断该标签所属博文是否为精选的数据, 如果是精选赋值为1, 不是精选赋值为0。
当前标签对应博文的阅读次数(Freq_Read): 以该标签所属博文的阅读次数为基础, 将其除以数据集中阅读次数的最大值, 得到归一化结果。
当前标签对应博文的推荐数(Freq_Recommended): 以该标签所属博文的推荐次数为基础, 将其除以数据集中推荐数的最大值, 得到归一化结果。
当前标签对应博文的评论数(Freq_Commented): 利用该标签所属博文的评论数数据。同时将每个标签对应博文的评论数除以数据集中评论数最高的数据进行归一化处理。
使用该标签进行标注的总标注次数(Freq_Tagged): 在实验中, 通过博文的URL链接获取发表该博文的用户ID, 计算出某一标签在科学网博客博文数据中总标注次数, 将其除以数据集中总标注次数最大值, 得到归一化结果。
使用该标签进行标注的总标注人数(Freq_Tagged User): 在实验中, 通过博文URL获取发表该博文的用户ID, 计算出标签的总标注人数。由于某一标签可能被同一个人标注多次, 因此Freq_Tagged计算的是标签总的标注次数, Freq_ TaggedUser计算的是标签被不同人使用的次数, 将该值除以数据集中总标注人数的最大值, 得到归一化结果。
(2) 社会化质量评估模型的建立与选择
①社会化标签质量评估模型的建立
社会化标签的质量自动评估研究是针对每一个标签, 依据该标签的各种属性值, 利用质量评估模型对该标签的质量得分做出评估(或预测)。社会化标签质量评估模型的建立过程为: 给定社会化标签质量评估的初始数据集, 在预处理的基础上进行各标签的属性值计算, 得到数据集的量化表示形式; 将朴素贝叶斯、支持向量机以及多元回归分析等统计模型作为候选的标签质量自动评估模型, 通过N折交叉验证方法对数据集进行测试, 综合考虑各质量类别标签预测的准确率P和召回率R, 即调和平均值F1, 并计算所有类的各评估指标的宏平均值, 将F1最高的模型作为最终用于预测标签质量的标签质量评估模型。其中宏平均准确率、宏平均召回率以及宏平均F1值计算公式如下:
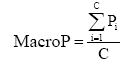 |
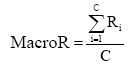 |
 |
其中, C为所有类别的数目。
②社会化标签质量评估模型的选择
将社会化标签质量自动评估视为分类问题, 标签质量打分结果, 即1分、2分、3分、4分、5分对应标签质量的1分类别、2分类别、3分类别、4分类别、5分类别。
本文分别利用多元回归、朴素贝叶斯和支持向量机这三种评估模型预测出各个标签的质量类别。多元回归模型是通过对两个或两个以上的自变量与一个因变量的相关分析, 建立预测模型进行预测的方法。在现实问题研究中, 因变量的变化往往受几个重要因素的影响, 此时就需要用两个或两个以上的影响因素作为自变量解释因变量的变化[28]。本文利用标签各个属性维度作为自变量对标签质量因变量进行预测。朴素贝叶斯分类器的分类原理是通过某对象的先验概率, 利用贝叶斯公式计算出其后验概率, 即该对象属于某一类的概率, 选择具有最大后验概率的类作为该对象所属的类[28]。支持向量机分类器利用核函数将输入的空间变换到一个高维特征空间, 在这个空间构造一个或多个超平面, 并且找到分类效果最佳的超平面, 即使得属于两个不同类的数据点间隔最大的那个面[29]。支持向量机分类器中比较常用的核函数包括线性核函数、多项式核函数、径向基核函数、Sigmoid核函数等。
选择科学网博客作为实验数据, 数据采集日期为2013年8月25日。科学网博客给出了博文的系统分类目录, 包括“ 博客新闻” 、“ 观点评述” 、“ 海外观察” 、“ 教学心得” 、“ 科普集锦” 、“ 科研笔记” 、“ 论文交流” 、“ 人文社科” 、“ 人物纪事” 、“ 生活其它” 、“ 诗词雅集” 以及“ 图片百科” 等12个类别。从采集到的博文中随机抽取2 000个标签以及其对应的705篇博文(涉及403个博客用户)作为标签质量评估数据源。在实验中, 将这2 000个标签进行特征计算与质量打分, 最终得到标签评估数据集。利用该数据集、依据十折交叉验证结果比较不同评估模型的性能, 即: 首先将2 000个标签平均分成10组(每组200个标签), 每次取其中1组作为测试集, 其他9组作为训练集, 接着利用评估模型得到10次实验结果, 取10次结果的平均值作为该模型的最终测试结果。
(1) 三种标签质量评估模型自动评估结果
①多元回归预测结果
使用上述提出的与标签质量相关的属性作为自变量, 将标签质量作为因变量, 利用多元线性回归模型测量词性、词长、熵值、是否为主题词、是否为命名实体、首次出现位置、题目中是否包含、词频、逆文档频率、术语度、是否为精选、阅读次数、当前推荐数、评论数、总标注次数、总标注人数对标签质量的影响, 并对各标签的质量进行预测。
表2为该标签质量评估模型方差分析结果, 可以看到该回归模型的显著性检验F值[30]为47.874, 显著性概率为0.000, 表明多元线性回归模型显著。
| 表2 方差分析 |
表3为标签质量与各维度属性的回归系数与显著性分析结果, 可以看出除词频、是否为主题词、是否为命名实体、总标注人数、是否为精选博文和评论数维度没有通过显著性检验, 其余维度均通过显著性检验(p< 0.05)。根据“ 标准系数绝对值越大对因变量影响程度越大” 原则, 可以看出熵值对标签质量影响程度最大, 词频和是否为命名实体对标签质量影响程度最小。
| 表3 回归系数与显著性系数检验 |
表4为利用上述单一特征作为自变量的多元逻辑回归分类结果, 可以看出特征“ 总标注次数” 分类效果最好, MacroF1值最高为0.23, 但是其不能分类出质量得分为3、4和5的类别。
| 表4 单一特征多元逻辑回归分类实验结果 |
表5为部分不同特征组合多元逻辑回归分类实验结果, 按照单一属性的表现, 逐步增加特征数量, 可以看出在逐步增加特征数量的过程中分类效果逐步提升, 当利用总标注次数、题目中是否包含该标签、词长、词频、阅读次数、总标注人数、术语度、首次出现位置、当前推荐数、评论数、是否为精选、是否为主题词、是否为命名实体这13个特征使分类的MacroF1值达到最高, 为0.37。
| 表5 部分不同特征组合多元逻辑回归分类实验结果 |
②朴素贝叶斯分类算法预测结果
利用朴素贝叶斯分类算法计算各特征以及特征组合对标签质量预测的准确性。对朴素贝叶斯分类模型进行十折交叉验证, 结果如表6所示。可以看出:“ 总标注次数” 和“ 词性” 此单一特征分类效果最好, MacroF1值为0.22, 稍低于多元逻辑回归“ 总标注次数” 分类的MacroF1值。
| 表6 单一特征朴素贝叶斯分类实验结果 |
表7为部分不同特征组合朴素贝叶斯分类实验结果。可以看出: 在利用总标注次数、词性、熵值、逆文档频次、题目中是否出现该标签、词频和词长达到了分类的最大MacroF1值0.25, 小于多元回归预测结果, 在逐渐增加特征的过程中, 分类的宏平均准确率、宏平均召回率和MacroF1均减小, 总体看出利用朴素贝叶斯进行标签质量评估的结果并不优于多元回归分析结果。
| 表7 部分不同特征组合朴素贝叶斯分类实验结果 |
③支持向量机分类算法预测结果
本文调用LibSVM①(①http://www.csie.ntu.edu.tw/~cjlin/libsvm/.)工具, 利用SVM分类算法计算各属性对标签质量预测的准确性, 将SVM 分类算法4 种核函数(线性核函数、多项式核函数、径向基核函数、Sigmoid核函数)模型的实验结果进行对比, 并得到分类效果最好的核函数分类结果。对SVM分类模型进行十折交叉验证结果如表8所示。可以看出: 同样是“ 博文的题目中是否包含该标签” 和“ 词性” 此单一特征分类效果最好, MacroF1值为0.18, 低于多元逻辑回归和朴素贝叶斯单一最高属性的分类效果。
| 表8 单一特征支持向量机分类实验结果 |
表9为部分不同特征组合支持向量机分类实验结果, 当利用特征题目中是否包含该标签、词性、词长、是否为主题词、总标注次数、总标注人数这6个属性时分类效果达到最好, MacroF1值为0.36, 此值是利用径向基核函数得到的分类结果。
| 表9 部分不同特征组合支持向量机分类实验结果 |
因此对在上述6个属性上分类效果较好的径向基核函数进行参数优化, 主要是利用交互检验功能进行寻优, 以获得对标签质量更高的分类效果, 实验结果如表10所示。可以看出, 调整参数后的 SVM 模型的宏平均准确率、宏平均召回率和MacroF1均有所提升, MacroF1值由0.36上升到0.49, 参数优化后的标签质量的预测能力有所提高。
| 表10 优化后结果对比 |
(2) 三种标签质量评估模型自动评估结果对比分析
对上述多元回归分析、朴素贝叶斯、支持向量机这三种标签质量评估模型自动评估进行比较, 结果如表11所示。可以看到, 对多元回归分析需要使用较多的特征, 包括标签内容属性特征与社会化属性特征, 预测出的标签质量结果的MacroF1值为0.37, 处于三个模型效果的中间位置; 利用朴素贝叶斯分类方法进行标签质量自动评估, 是三个模型中效果最差的, MacroF1值仅为0.25。对RBF核函数进行参数优化后的支持向量机分类算法进行标签质量自动评估, 其MacroF1值达到0.49, 是三个模型中分类效果最好的, 其也综合利用了标签的内容属性特征与社会化属性特征, 从各类别的F1值也可以看出, 其对各类的分类效果均高于另外两个模型。综合以上分析可以得出: 结合标签的内容属性特征和社会化属性特征, 利用参数优化后的SVM进行标签质量评估的结果明显优于多元回归和朴素贝叶斯的结果。
| 表11 三种标签质量评估模型自动评估结果对比分析 |
本文以科学网标签数据作为研究对象, 结合标签内容属性与社会化属性, 建立标签质量评估数据集, 利用有效的标签质量评估维度, 将多元回归、朴素贝叶斯和支持向量机这三种质量评估模型进行对比, 结果显示结合标签的内容属性特征和社会化属性特征, 经过参数优化的支持向量机标签质量评估模型评估结果明显优于多元回归和朴素贝叶斯评估结果。
由于本文使用的标签数据是科学网博文的标签数据, 社会化功能还不够完善, 一些社会化属性并不能有效提高社会化标签自动分类效果, 导致即使是效果最佳的支持向量机模型也仅仅获得0.49的F1值。因此下一步拟采用更富有社会化属性的标签数据作为研究对象, 如LibraryThing图书标注网站, CiteULike文献标注网站数据进行更为广义领域的标签质量评估, 同时扩充测评数据集的规模和种类, 采用更为丰富的数据对不同类型的标注对象, 例如图书、图片、视频、音乐等, 分别进行社会化标签质量自动评估研究。此外, 下一步工作还包括: 针对不同类型的标注对象, 在计算标签的属性时, 引入更多的标签属性, 并优化标签属性的计算过程, 如在进行标签的词性判断时, 对在博文正文中出现的标签, 直接依据其在正文中的上下文进行词性标注等。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|