{kind=link}
{kind=link}
{kind=link}
区分标签质量的机器生成标签聚类研究
[章成志1, 2  , 顾晓雪
, 顾晓雪1 ]
, 顾晓雪|
|


作者贡献声明:
章成志: 提出研究思路, 讨论研究方案, 采集并分析数据, 论文起草及最终版本修订;
顾晓雪: 设计研究方案, 设计与实施实验, 清洗与分析数据。
移动电话
【目的】常规的标签或词语聚类没有考虑聚类对象的质量差异对聚类效果的影响, 本文旨在分析不同质量的机器生成标签的聚类效果差异, 并提出融合标签质量的标签聚类算法优化建议。【方法】首先, 抓取Engadet中英文博客数据, 对其进行数据预处理得到候选标签, 抽取标签社会化特征与内容特征并进行权重计算, 采用两种标签质量区分策略, 得到不同质量的标签集合; 然后, 对不同质量的标签集合进行相似度计算, 使用AP算法进行聚类, 分析比较它们的聚类结果。【结果】实验结果表明, 对于中英文标签, Top5标签聚类结果要优于Top5-10标签聚类结果, 加权社会化属性标签聚类结果优于不加权社会标签聚类结果。【局限】区分标签质量的方法比较单一, 缺乏评价标签质量的有效方法。【结论】高质量的机器生成标签聚类结果比低质量的标签聚类结果更好, 对标签的社会化属性的加权能够提高机器生成标签的聚类效果, 且社会化属性可以作为区分标签质量的特征之一。
[Objective] Conventional tags or words clustering haven’t considered the impact of clustering members’ quality to clustering results. This paper aims to analyze the differences in clustering results of different quality of the clustering machine-generated tags and make suggestions to improve the clustering result with fusion of tag quality.[Methods] Firstly, fetch the data of Engadet’s blogs in Chinese and English, preprocess the data and get the candidate tags, extract tags’ social and content features to calculate their weight. The authors use two strategies to distinguish different quality tags and obtain different tag sets. Then calculate the similarities of these tag sets and use AP algorithm to get clustering results, which could be compared and analyzed.[Results] The experiment results show that, for both Chinese and English tags, clustering results of Top5 tags are better than Top5-10, and clustering results of weighted social attributes of tags are better than non-weighted tags.[Limitations] The method of distinguishing tags’ quality is relatively simple and lacking of effective method to evaluate the quality of tags.[Conclusions] Clustering results of machine-generated tags with high quality are better than clustering results of tags with low quality. The clustering performance of machine-generated tags can be improved by weighting the social attribute. At the same time, the social attribute of tags can be used to evaluate the quality of them.
随着Web2.0网站的不断兴起, 社会化媒体网站中的标签日益增多, 用户使用各自语言对Web资源进行标注, 这促使了互联网上多语言社会化标签资源不断丰富。社会化标签融入了互联网用户的集体智慧, 部分标签能够很好地描述资源的主题内容, 所以, 社会化标签无疑是描述资源的重要途径。
目前, 研究者从社会化标签的分布与特点[1]、社会化标签的自动生成[2, 3, 4]、基于社会化标签的个性化推荐[5, 6, 7, 8]等方面进行了比较深入的研究, 但还存在一系列尚需解决的问题。首先互联网中的标签质量参差不齐, 用户标注标签中由于用户标注标签的动机、目的及环境不同, 所以标签的质量得不到保障, 而机器抽取或推荐标签由于其算法的不完善、文本长度的限制、及多语言文本含有大量的HTML标记等问题, 使部分抽取或推荐的标签质量得不到控制。对于海量标签的知识组织和信息发现, 大多研究者采用无监督的聚类分析方法。在无监督的标签聚类中, 对标签质量的管理缺乏有效的控制。不同质量的标签对最终的标签聚类结果会产生哪些影响, 低质量标签的混入是否仅仅只是降低标签聚类效果, 这些都是值得研究和探讨的问题。
常规的标签或词语聚类没有考虑聚类对象的质量差异对聚类效果的影响, 本文旨在分析不同质量的机器生成标签的聚类效果差异。为此, 本文抓取中英文两种网络语料资源, 融合标注资源的内容特征与社会化特征, 实现高质量社会化标签的生成, 同时对抽取出的标签进行不同条件的筛选, 分别对高质量的中英文语言社会化标签进行自动聚类, 并对聚类结果进行评估, 比较与分析不同条件下的标签聚类结果, 探索聚类对象的质量差异对聚类效果的影响。
社会化标签的质量问题主要体现在含糊性、同义词问题、过度主观性以及拼写错误等方面。已有研究提出一些标签质量评价方法, 过滤信任度低的噪音标签, 从而提高社会化标签应用质量。
社会化标签分为用户标注标签和机器抽取标签。社会化标签质量评估的方法, 可以分为内部评估与外部评估两种。内部评估是针对社会化标签本身的特征属性进行评估。对于社会化标签质量评估的研究, 李蕾等[9]总结了以下8个方面的工作:
(1) 利用人工评价评估标签的质量;
(2) 基于标签自身统计属性评估标签的质量;
(3) 依据规范词语进行隐含的质量评估;
(4) 依据标签和主题词的比较进行评估;
(5) 依据用户标签与专家标注结果的比较结果进行评估;
(6) 依据标签与文本内容关键词的比较进行评估;
(7) 基于信息检索的方式评估标签质量;
(8) 基于用户、资源、标签三者关系评估标签质量。
同时还对不同的标签质量评估方法进行比较与分析, 指出现有的社会化标签质量评估研究工作的不足之处在于标签质量评估没有结合标签的应用场合、标注资源的类型特点、标签自身的分类及用户的标注动机[9]。
对于机器抽取标签质量评估, 较客观的评价方法是将机器生成的标签集合与领域专家标注的关键词集合通过对比来进行评价[10]。机器抽取标签的质量评估, 大多数研究将信息检索中的准确率、召回率及F值引入标签质量评估中。准确率为机器抽取标签集合中包含人工标注的关键词的比率。召回率为人工标注的关键词中有多少被机器抽取出来。F值为综合指标, 其值越大, 说明机器抽取的标签质量越好。这种质量评价方法只能基于有预先标注关键词的文本, 对于海量的互联网文本, 不可能所有领域都具备专家所标注的关键词集合。
由于标签由用户选择, 从而不可避免地使社会化标签系统中产生了大量冗余的、主观的、模糊的、语义不明确的垃圾标签, 使得用户在检索主题和组织内容时产生了不必要的噪音, 阻碍了有效的信息传播。为此, 如何从海量的文本中抽取出有意义的标签并且推荐给用户成为学者开始探索和研究的问题。
研究者通过标签的文本特征(如标签出现的频率、比例等)实现标签抽取, 如Sen等[10]通过对标签的打分及标签的文本特征发现高质量的标签并利用表现最好的标签抽取算法得到了高质量的标签, 并将其发布在网络上。Chen等[11]针对向Flickr用户推荐标签的问题, 结合标签文本特征(如标签频率)及社会特征(标签在用户中的共现频率), 使用贝叶斯分类法为用户推荐与其兴趣相关的标签, 文本特征可以提高标签的质量, 社会特征可以发现用户与社会活动的相关信息。另外一部分研究者对产品评论进行标签抽取, 如李丕绩等[12]提出了一种能够为每个实体抽取特征标签的方法, 并且通过语义去重, 保证标签在语义空间内相互独立。还有利用被标记的网页之间的联系实现标签抽取, 如Suchanek等[13]分析标签之间的语义属性及标签与被标记网页之间的关系来发现标签, 基于网页语料的关键词、内容及标签建立了一个标签推荐影响力的评估模型。
标签聚类模型方面, 研究者主要将现有的聚类模型或方法用于标签聚类。一般来说, 标签聚类算法可以描述为:
(1) 定义一个标签相似性度量, 并构建一个标签相似矩阵。Begelman等[14]将标签共现用作相似性度量, 并构建一个无向加权图, 对图形分区然后获得集群。Cui等[15]基于链接图对标签进行分类, 提出一种TagClus的聚类方法。
(2) 执行传统的如K-means聚类算法、层次凝聚聚类这种相似矩阵生成聚类结果。如Ramage等[16]利用K-means聚类算法社会化标签进行聚类、曹高辉等[17]利用凝聚式层次聚类算法进行标签聚类。Shepitsen等[6]提出了一个个性化推荐算法依赖分层标记集群大众分类。
(3) 抽象出每个群集的有意义的信息, 并对标签进行推荐。Sbodio等[18]利用自组织映射(SOM)模型对Delicious网站上的标签进行聚类。Zong等[19]使用近似骨架标签聚类结果, 找出更好的标记集群, 并提出一个近似骨架为基础的聚类算法标签(APPECT)。
标签聚类可以找出学科的主要研究内容和研究热点及学科研究趋势, 同时通过标签聚类可以找出交叉学科, 把握学科发展的趋势。对情感词进行聚类, 对用户舆情观点的掌握和动态观测有一定的作用, 能够用于辅助舆情监测和对网民进行舆情引导。同时标签可视化可以使标签的聚类结果更加清晰, 有助于互联网的信息组织与信息管理。
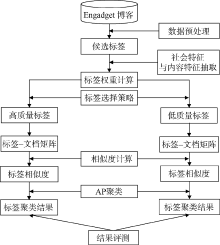
本文研究内容如图1所示, 从网络上抓取中英文博客资源, 分别对中英文博客语料进行数据预处理, 得到候选标签, 对候选标签进行内容特征与社会化特征抽取, 得到候选标签的权重。对于候选标签, 采用对比实验, 一种不使用标签的位置加权, 一种使用标签的位置加权; 在候选标签中进行标签选择, 有两种选择方法, 一种是依据标签权重的大小, 一种是依据标签所出现的文档数。对两批内容相同、权重不同的标签构建标签-文档矩阵, 并计算其相似度。得到标签之间的相似度后, 用开源的聚类算法对标签进行聚类, 并对不同的标签聚类结果进行对比, 分析实验结果和可能原因。
 | 图1 总体研究思路 |
数据预处理包括数据清洗、分词和数据筛选三部分。对于中文博文, 导入用户词典, 主要包括IT领域的常用词, 利用中国科学院计算技术研究所分词软件NLPIR①(①http://ictclas.nlpir.org/)(又名ICTCLAS)实现中文博客的分词以及停用词过滤。对于英文博文, 先对博文的标题和正文用空格进行分词和停用词过滤, 并统一为小写, 过滤符号和标点, 使用PorterStemmer②(②http://tartarus.org/martin/PorterStemmer/.)对英文进行词干提取。
(1) 标签权重计算
对于候选标签的内容特征抽取, 选择内容特征抽取— — 位置加权的TF× IDF[20]作为其权重, 词条i在文档Dj标题中出现的频次、在全文中出现的频次, 且出现在不同位置被赋予不同的权重, LT、LF为文档Dj标题和全文长度, WT、WF分别取2和1。
对候选标签的内容特征抽取, 将候选标签在用户标签中出现的抽取标签的频次权重 WT设为3。
候选标签的特征加权函数为:
(2) 标签质量区分策略
对于标签质量区分策略, 本实验按照每篇文章的候选标签的权重从大到小排序, 分别选取前10个标签、前5个标签和第6-10个标签作为三种标签集, 并在这三种标签集中按DF(标签出现的文档数)大于1、大于2、大于3、大于4分为4种标签集。对于每种语言按标签质量区分, 共12个标签集。同时还将标签社会化属性作为衡量标签质量的因素之一, 在聚类算法中将同时作为用户标签出现的机器标签给予更高的权重, 说明其贡献更突出。如果机器生成标签在用户标签中出现, 将对其赋予社会化属性权重
本实验采用基于向量余弦值[20]的方法进行相似度计算, 用一个特征向量表示标签, 对于任一特征表示标签集中的两个标签向量为 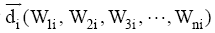
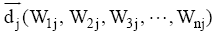
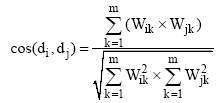 |
其中, m为第i个标签和第j个标签共同的不重复的特征数量,
本文使用加拿大多伦多大学的概率与统计推理Frey实验室开发的Windows (32-bit)AP聚类算法开源软件①(①http://www.psi.toronto.edu/index.php?q=affinity%20propagation.)对标签进行聚类。这是Frey和Dueck在Science杂志上提出一种新的聚类算法Affinity Propagation (AP)[22]。AP算法不需要指定聚类数目, 它将所有的数据点都作为潜在的聚类中心, 称之为exemplar。AP需要输入数据点之间的相似度集合, 用
Engadget是一个专注于数码产品报道、评测的博客。Engadget提供了中文版内容, 而且更新同样迅速、及时, 新闻几乎与主站同步。本文选取Engadget中文版②(②http://cn.engadget.com/.)与对应的英文版③(③http://www.engadget.com/.)博文共4 906对博文(中英文对应且有35个分类)作为实验数据, 采集博文全文和用户标签等信息。具体的博文分类如表1所示:
| 表1 Engadget博文类别表 |
对于每个标签, 将其标注的博文的类别(见表1)作为它的分类项。
其中,
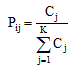 |
本实验采用熵值和纯度评价博文聚类结果。这是面向分类的度量, 这些度量评估了类簇包含单个类的对象的程度。
(1) 熵: 每个簇由单个类的对象组成的程度。对于每个簇, 首先计算数据的类分布, 即对于簇i, 计算簇i的成员属于类j的概率[23]:
其中,
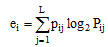 |
其中, L是类的个数。簇集合的总熵用每个簇的熵的加权和计算:
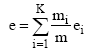 |
其中, K是簇的个数, 而m是数据点的总数[23]。熵值越小, 聚类效果越好。
(2) 纯度: 簇包含单个类的对象的另一种度量方法。纯度越大, 聚类效果越好。簇i的纯度和聚类的总纯度[23]分别是:
 |
对中英文标签聚类概况进行分析。中文标签聚类结果如表2所示, 所有的标签集在聚类中都成功收敛。
| 表2 中文博客Tag聚类结果 |
在Top10的标签集中由于成员个数大于Top5和Top6-10的成员个数, 所以其类簇个数较多, 但是Top10聚类结果中各组的Net Simi均大于Top5和Top6-10各组的Net Simi。Net Simi值是AP算法中的净相似度, 它是度量exemplars (聚类代表点)是否适用于解释数据的分数, 也是AP算法试图最大化的目标函数。所以Top10中各组的聚类代表点更适用于解释聚类结果。同时在Top10、Top5和Top6-10这三组中, 随着DF条件的变化, 成员个数的减少, 净相似度也随之下降。说明DF越大的成员点, 并不意味着其作为聚类代表点的可能性越大。DF小的成员点也可以更好地作为聚类代表点。在标签聚类中, 不能将DF作为衡量标签质量的标准, 因为DF的改变不能更好地改善标签聚类结果。
英文标签聚类结果如表3所示, Top10中有两组标签集没有收敛。与中文标签聚类结果相比, 聚类结果趋势大致相同。但是英文标签聚类结果中的净相似度均大于中文标签聚类结果中的净相似度, 说明英文标签聚类结果中的代表点比中文标签聚类结果中的代表点更能解释数据。但是在英文标签聚类结果中的Top5中DF> 1的这组数据却例外。原因在于英文标签集中只有这一组数据的聚类结果中的类簇个数比相应的中文标签聚类结果中的类簇个数要少。
| 表3 英文博客Tag聚类结果 |
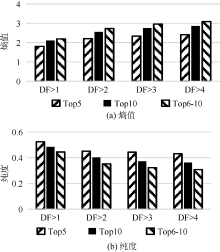
针对中英文标签聚类评测, 将表2、表3中的熵值和纯度根据分组画出柱状图, 如图2和图3所示。对于中英文标签, 在DF> 1至DF> 4的4个不同数据集中, Top5的标签聚类结果的熵值比Top6-10的标签聚类结果的熵值要低, 而前者的纯度比后者要高。说明标签质量的选择策略中, 按照标签的权重大小进行选择是正确的。权重越大的标签, 其标签质量越高, 所以其聚类结果更好。同时可以看到Top10的标签聚类结果都处于Top5和Top6-10的中间。正是由于Top10的标签将高质量的标签和低质量的标签融合起来, 所以其标签聚类结果也处于高质量标签和低质量标签的中间。
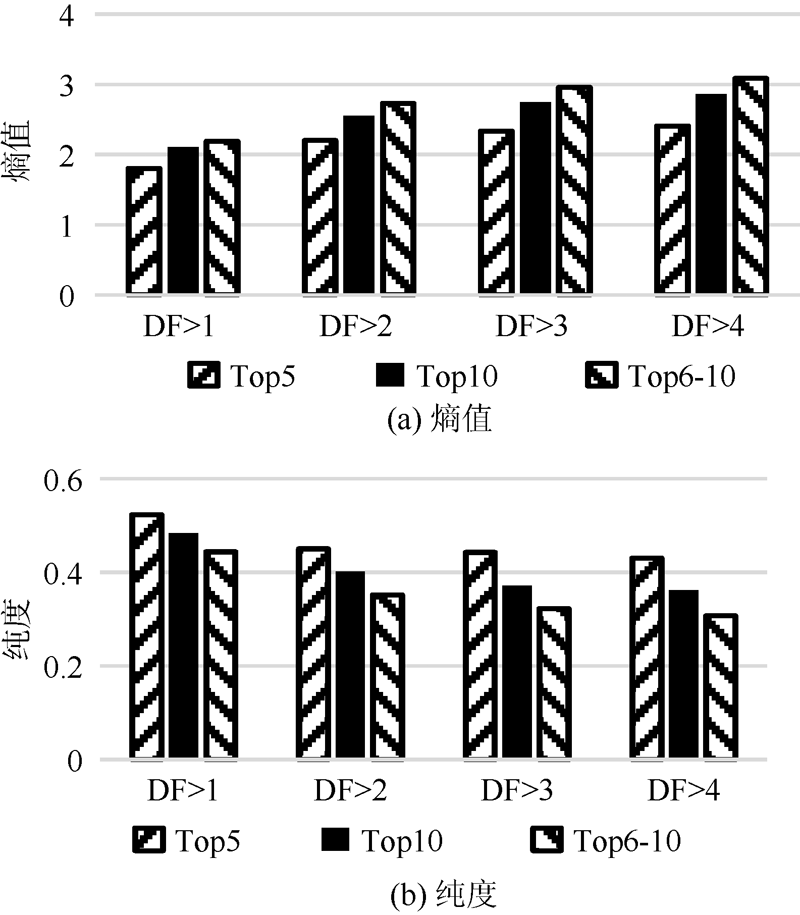 | 图2 中文标签聚类结果 |
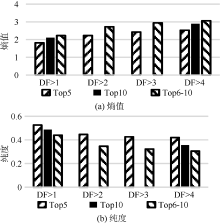
从图3可以发现, 高质量和低质量标签的融合还可能引发标签聚类失败, 即产生聚类未收敛的结果。在英文标签聚类中, Top5和Top6-10中的DF> 2、DF> 3的两组标签都能聚类成功。而Top10中的DF> 2、DF> 3的两组标签却聚类失败。说明高质量标签和低质量标签的融合不仅使整个标签集中的标签的平均质量变差, 还可能对整个标签集产生更糟糕的影响, 使得聚类失败。所以如何评估社会化标签的质量或是从网络文本中抽取高质量的标签成为标签聚类应用首先应该考虑和继续解决的问题。
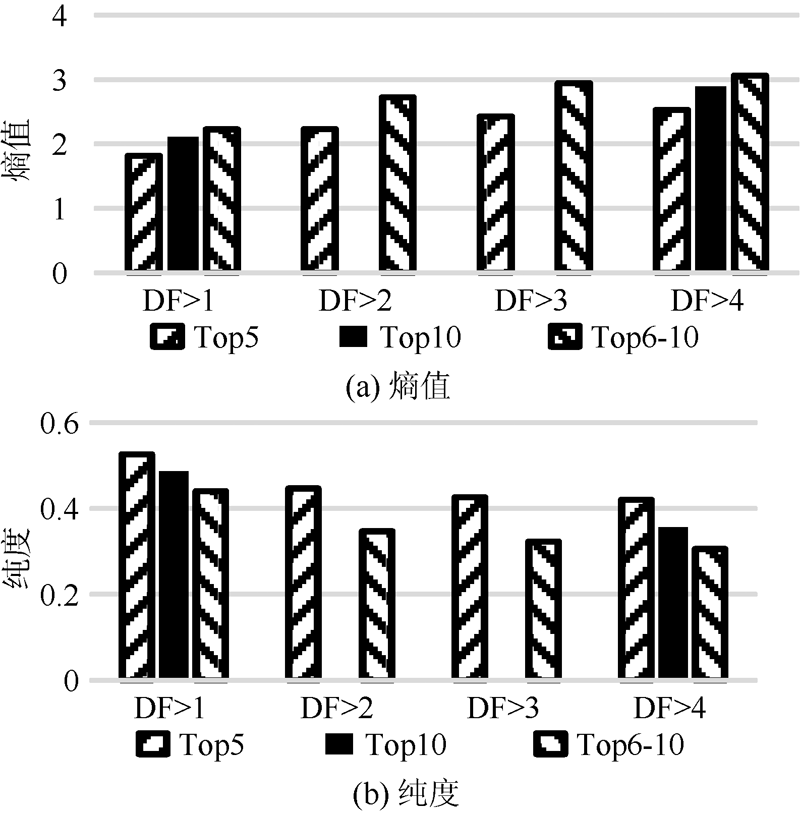 | 图3 英文标签聚类结果 |
对于标签社会化属性加权, 选用中英文博客中Top10且DF> 1的标签, 从表4可以看出, 随着社会化属性权重系数
| 表4 中英文博客Tag社会化属性加权聚类结果 |
(1) 增加标签聚类算法的比较
本实验只采用AP聚类算法, 没有选择多种聚类算法对标签聚类结果进行对比实验。研究者在对标签聚类时可以选择多种聚类方法, 如基于原型的K-means[24]聚类方法、基于图的层次聚类[25]方法、基于密度的DBSCAN[26]聚类方法等, 对标签进行对比实验, 选取最优的聚类算法策略。
(2) 标签质量的多种度量方法及其对聚类的影响
本实验通过标签的内容特征、标签的社会化特征、包含标签的博文频次(DF)及标签出现的总次数这几个方面度量标签的质量。实验结果表明标签的内容特征、社会化特征、标签出现的总次数可以度量标签的质量, 但是出现包含标签的博文频次不能度量标签的质量。同时还可以考虑标签的语义关联、标签在博文的深度、标签被用户标注的数量等其他因素。
(3) 标签聚类算法中引入高质量标签贡献机制
对标签的社会化属性采用不同的加权系数进行实验, 结果表明标签社会化属性加权权重系数越高, 高质量标签贡献越大, 标签的聚类结果越高。因此在对标签进行聚类时, 可以通过引入高质量标签贡献机制来提高标签的聚类结果。
本文抓取中英文对应的网络博文作为实验数据, 对博文的候选标签进行内容特征和社会特征的抽取及权重计算, 采用不同的标签质量区分策略, 且引入高质量标签贡献机制, 对不同质量的标签集进行聚类及结果评测。实验结果表明, 标签质量的高低对标签聚类结果有重要的影响, 标签的内容与社会化特征、标签出现的总次数能够反映标签的质量, 而出现包含标签的博文频次不能衡量标签的质量, 且社会化属性权重的增加能够提高标签聚类结果。在对海量的标签进行标签聚类的时候, 应对标签质量采用多种度量方法, 引入高质量标签贡献机制, 比较不同的标签聚类算法, 从而提高标签的聚类结果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|