





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
标注内容与用户属性结合的标签聚类研究
[顾晓雪1 , 章成志1, 2  ]
]
]
|
|


作者贡献声明:
顾晓雪: 研究方案设计, 实验设计与实施, 数据清洗与分析, 论文起草;
章成志: 提出研究思路, 讨论研究方案, 采集并分析数据, 论文最终版本修订。
【目的】研究标签聚类中标注内容与用户属性及其结合对聚类效果的影响。【方法】采用科学网博客数据, 对其进行特征抽取、模型构建和相似度计算, 利用线性函数和Sigmod函数进行相似度加权, 并使用AP聚类算法进行标签聚类。【结果】在学科分类体系下, 用户属性与标注内容的结合均对标签聚类的结果有所提升, Sigmod加权表现最优; 在系统分类体系下, 两者结合均不如标注内容结果表现优秀。【局限】选择的数据量较小, 评估标签聚类的分类体系不够完善, AP聚类算法不适用于大数据的处理。【结论】两种特征的结合在部分情况下能够提高聚类效果, 标签聚类中应更加关注标签的内容特征。
[Objective] Explore the impact of tags’ annotated content and tags’ user attributes and their combinations in tag clustering.[Methods] Using ScienceNet.cn blogs, extract tag feature, build a vector space model and calculate the similarities between tags where linear method and Sigmod method are used to weight them, finally use the AP algorithm to cluster the tags.[Results] Experimental evaluation results show that in subject classification, in combination of annotated content and user attributes, two types of weighting methods can improve the clustering results, and the performace of Sigmod method is optimal; while in systematic classification, the combination of these two features can’t perform as well as the former one and even worse than the content feature.[Limitations] The data selected for experiment is small and the classification for estimating the clustering results is not perfect. What’s more, AP clustering algorithm lacks the ability to deal with big data.[Conclusions] The combination of these two features can improve the tag clustering results in some cases, and we should focus more on tag’s content in tag clustering.
协同标注系统允许互联网用户通过用户自定义的注释来管理和分享网上资源, 国外两个典型案例是Delicious (http://del.icio.us)和Flickr (http://www.flickr.com)。在Delicious中, 用户标记URLs; 在Flickr中, 用户可以上传、分享、管理图片。在国内, 大量的网络资源也可以被用户自定义标记, 如博客、微博、视频、商品等。如科学网博客(http://bbs.sciencenet.cn/blog.php)中, 用户可以自定义文章的关键词, 也可以使用机器生成的关键词; 新浪微博(http://weibo.com)中, 用户可以为自己打标签也可以为发表的微博内容打标签; 在优酷(http://www.youku.com)中, 用户可以为自己上传的视频打标签; 在淘宝(http://www.taobao.com)中, 用户可以为自己收藏的商品打上标签。
协同标注系统的基础是一个用户可以自定义一个用户标签来描述网络资源[1]。在复杂网络中由相互关联用户、 资源和标签组成的注释结果的一个集合, 通常被称为大众分类法(Folksonomies)[2]。大众分类法, 使互联网用户能够标注或搜索资源时使用自定义的用户标签, 而不受预定义的导航或术语约束。Hammond等[3]认为标签可以很容易检索和查看以前搜索过的资源。其次, 大众分类法允许用户对资源分类时可以使用几个术语, 而不是一个目录名称或是单个分支的本体[4]。再次, 与符合严格的分类层次结构的系统相比, 大众分类法的用户进入成本很低。用户可以得到更好的搜索体验, 更易于个性化的导航设置, 更准确的用户推荐[5]。大众分类法提供了一种社区的思想, 而不是提供一种本体或者搜索引擎。大众分类法吸收了许多用户的观点而不是几个专家的观点, 使得分类体系更加动态且能不断收入一系列变化的热词并很快地表现出流行趋势[6]。大众分类法的问题在于巨大的用户标签集合中包含客观描述的标签和主观描述的标签, 语义明确的标签和无语义的标签[1]。数据分析工具如聚类分析可以识别出用户最重要的个性和爱好[7]。聚类分析等数据挖掘技术可以用来改善这一问题, 减少数据中的噪声并发现资源趋势。提取高质量的用户标签并对其进行聚类处理可以帮助用户解决这些问题。
本研究以科学网博客为例, 从资源和用户两个角度分别构建标签向量空间模型, 计算标签之间的相似度, 并用不同的加权方法将两者结合起来, 比较其聚类结果的差异。
从内容的角度来看, 结合外部语义词典的标签内容相似度计算可以帮助找到标签之间的关系。然而, 当新标签或新单词未收录于词典中时, 这种方法并不适用[8]。从用户标注的角度来看, 标签的共现次数可以用于度量标签之间的相关度[9]。
计算标签相似度的工作包括如下三个方面:
(1) 标签与外部资源的相似度, 通过它们的内容和信息从词汇或术语资源相似度评价的角度评估两个标签之间的相似度[10]。比如Leo词典①(①http://dict.leo.org/.)和WordNet②(②http://wordnet.princeton.edu/.)可以用来测量两个标签之间的语义关系, Agirre等[11]提出对WordNet 词义的不同聚类方法的比较结果。一些网上的语义资源如Google③(③https://www.google.com/?gws_rd=ssl.)和Wikipedia④(④http://en.wikipedia.org/wiki/Main_Page.)能够提供不包含在传统词典中的新生词汇的信息, 如Fokker等[12]介绍了P2P维基百科, 一个应用于维基百科多媒体内容的个性化基于标签的导航系统原型。
(2) 从标注资源的相似度测量标签的相似度, Simpson[8]提出基于资源的向量空间相似度计算标签相似度, 每个标签都构建一个向量, 每个向量中的元素代表这个标签在这篇文档中被使用的次数, 通过余弦值相似度衡量标签的相似度。Begelman等[9]提出标签共现的概念, 表示两个标签同时标注同一个资源。他们使用标签之间共现的次数衡量标签之间的相似度。Christopher等[13]通过比较他们所注释的文档的相似度衡量标签之间的相似度, 文档的相似度可以基于TF× IDF[14]的向量空间模型(VSM)[15]计算。周津等[16]提出基于特征向量表示法的标签聚类算法, 将标签用一个N 维的特征向量建模表示, 并给出三种不同的特征向量表示方法, 通过计算两个特征向量在欧式空间的余弦夹角得到标签两两之间的相似度。
(3) 从标签和资源构成的关系图, 一些研究者构建标签之间的二分图, 图中的节点之间的关联性表示标签之间的关联性。Jeh等[17]提出SimRank, 定义一个链接图中节点之间的相似度为两个随机冲浪者从两个节点出发到第一次遇见的所有不同步骤的可能性之和。Cui等[18]引入一种基于随机游走的方法通过构建标签和资源之间的链接图测量标签之间的相似度。王萍等[19]构建基于相似度的标签共现网络, 并赋予标签节点相应的信息值来衡量节点的核心程度。
目前在数据挖掘中存在大量的聚类方法, 聚类方法的选择取决于数据的类型、聚类的目的和应用。现有的数据挖掘中常用的聚类方法可以大致分为以下几种: 基于原型的聚类方法(如K-means [20]和K中心点[21])、基于图的聚类方法(如凝聚层次聚类法[21]和分裂层次聚类法[21])、基于密度的方法(如DBSCAN[22])。
标签聚类模型方面, 研究者主要将现有的聚类模型或方法用于标签聚类。一般来说, 标签聚类算法可以描述为: 构建相似矩阵计算标签相似度, 如Begelman等[9]将标签共现用作相似性度量, 并构建一个无向加权图, 对图形分区然后获得集群。Cui等[18]基于链接图对标签进行分类, 提出一种TagClus聚类方法。对标签执行如K-means聚类算法, 或层次凝聚聚类这种传统的相似矩阵生成聚类结果; 如Ramage等[23]利用K-means聚类算法对社会化标签进行聚类, 曹高辉等[24]利用凝聚式层次聚类算法进行标签聚类。Shepitsen等[25]提出一个基于分层标记集群大众分类的个性化推荐算法, 从而抽象出每个群集有意义的信息。如Sbodio等[26]利用自组织映射(SOM)模型对Delicious网站上的标签进行聚类。Zong等[27]使用近似骨架标签聚类结果, 找出更好的标记集群, 并提出了一个近似骨架为基础的聚类算法标签(APPECT)。
对于通过词典和WordNet等测量两个标签之间的语义关系[10], 从而对标签进行聚类的方法, 脱离了社会化标签系统的背景, 落入传统的词语分析方法。通过标签对之间的共现[8, 9]对标签进行聚类的方法, 标签聚类结果中一些标签类簇过于庞大, 不易于用户浏览、导航及推荐, 且无法用一个精确的数学模型表征单个标签, 只能两两计算相似度, 导致计算得到的相似度精确度并不高, 从而影响最终的聚类效果[16]。对此有些研究者[13, 16]用基于对象的特征向量表示标签, 这样能够很精确地表征一个标签, 提高标签之间相似度计算的准确性, 有效解决了传统的标签共现算法存在的不足, 基于对象特征向量表示算法确实可以有效地提高聚类的准确性。但是这种方法只适用对标注对象为文本的标签。还有研究将用户、资源、标签作为图的顶点, 通过共现构成图的边, 将社会化因素引入标签聚类, 提高了标签聚类效果[18]。
本文研究思路如图1所示。从互联网上抓取科学网用户的博客数据, 筛选出博文的用户标签, 对这些用户标签进行数据清洗后得到高质量的用户标签, 对其分别进行基于内容和社会化特征抽取, 构建向量空间模型后计算出基于内容和基于社会化特征的相似度。将这两者进行相似度加权, 得到结合内容及社会化特征的标签相似度, 用AP聚类算法对这三种相似度进行聚类, 基于内容特征的聚类结果、基于社会化特征的聚类结果及结合标注内容与用户属性的聚类结果, 对聚类结果进行结果评测, 探讨结合内容与社会化特征能否对原来单一的聚类结果有所提升。
 | 图1 总体研究思路 |
对网络博文的标签进行预处理, 从博文的关键词中提取用户标签, 去除HTML等无意义的网页标签, 如“ amp” 、“ hightlight” 、“ quot” 、“ for” 、“ & a” 、“ http” 、“ lt” 、“ gt” 、“ of” 、“ a” 、“ ?” 等。对用户标签进行频次统计, 选取标签频次大于等于5的共6 615个用户标签作为标签聚类的数据集。
标签的共现可以分为两种, 一种指两个标签用来描述相同的资源, 另一种指两个标签被同一个用户所使用。图2显示了标签和用户、资源之间的关系。对于标签1和标签2, 虽然没有用来描述相同资源, 却都被用户2所使用。对于标签2和标签3, 都被用来描述资源2、资源3且被用户3所使用。对于标签1和标签3, 没有用来描述相同资源也没有被同一用户所使用。
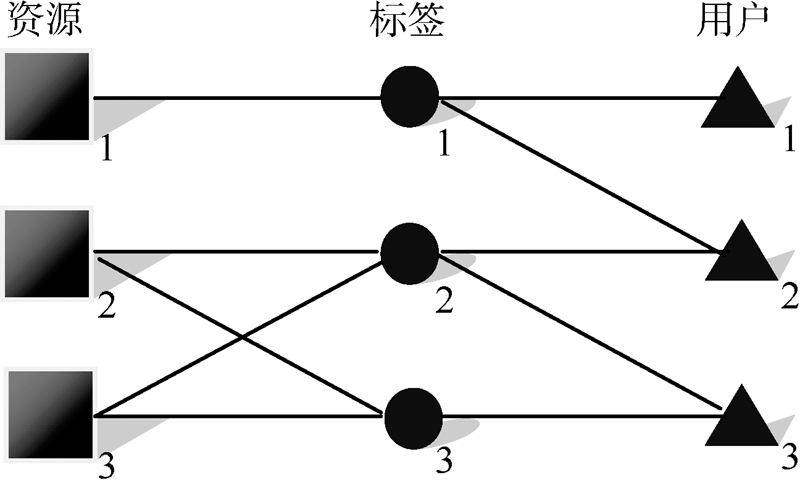 | 图2 资源、标签、用户关系图 |
(1) 内容特征抽取— 位置加权的TF× IDF
位置加权的TF× IDF区别于传统的TF× IDF, 传统的TF[28]指Term Frequency, 表示词条i在文档Dj中出现的次数, 称为词频; 而位置加权的TF[29]则由三部分组成, 即词条i在文档Dj标题中出现的频次、关键词中出现的频次和在全文中出现的频次, 且出现的不同位置被赋予不同的权重, 本文中取WT、WK、WF值分别为2、3、1, LT、LK、LF分别为文档Dj标题、关键词和全文长度。
 |
IDF指Inverse Document Frequency, 即逆文档频率。Salton等[28]将IDF定义为:
 |
其中, N表示文档集合中所有的文档数目, ni表示整个文档集合中出现过的词条i的文档的总数, 称为特征的文档频率[30]。
加权的TF× IDF函数为:
 |
(2) 社会化特征抽取— UF× IUF
由内容特征的定义, 可以推出社会化特征的抽取, 一个标签可以被多个用户使用, 一个用户可以使用多个标签。那么标签和标签之间的联系可以通过用户来连接。定义UF为User Frequency, 表示标签i被用户Uj使用的次数, 定义UT为User Tags, 表示用户Uj使用所有标签的总次数, 则归一化后可得:
 |
而IUF指 Inverse User Frequency, 定义为:
 |
其中, U表示用户集合中所有的用户数目, ui表示整个用户集合中出现过的标签i的用户总数。则UF× IUF 公式为:
 |
本文采用基于向量余弦值[15]的方法进行相似度计算, 用两种特征向量(基于内容和基于社会化)表示标签, 对于任一特征表示标签集中的两个标签向量为 
 |
其中, m为第i个标签和第j个标签共同的不重复的特征数量, Wik表示第i个标签中第k个特征项的权重, Wjk表示第j个标签中第k个特征项的权重。当两向量余弦值越大时, 两标签的相似度越高, 被归为同一类别的可能性越大[31]。
对于相似度的加权, 选择两种加权方案, 线性加权和Sigmod函数加权。线性加权, 即对两个相似度线性加权, 本文选取10组相似度权重系数, 分别为(0.1, 0.9)、(0.2, 0.8)、(0.3, 0.7)、(0.4, 0.6)、(0.5, 0.5)、(0.6, 0.4)、(0.7, 0.3)、(0.8, 0.2)、(0.9, 0.1)。
 |
其中, simc表示基于标注内容的标签相似度, simu表示基于用户属性的标签相似度。
根据文献[32], 多个相似度的结合可以用以下公式表示[33]:
 |
其中, wk是各策略的权重, adj(x)是Sigmoid 函数, 该函数是一个平滑函数, 使得合并结果偏向于预测值高的策略[32]。函数adj(x)的定义为:
 |
其中, x是某一相似度的值, 0.5是Sigmoid 函数中心[34]。
Frey和Dueck[35]在Science杂志上提出一种新的聚类算法Affinity Propagation(AP)。本实验采用加拿大多伦多大学Frey实验室开发的AP聚类算法开源软件①(①http://www.psi.toronto.edu/index.php?q=affinity%20propagation.)对用户标注标签进行聚类。AP算法将全部样本看作网络的节点, 通过网络中各条边的消息传递, 不断更新迭代过程计算出各样本的聚类中心, 直到产生m个高质量的exemplar, 同时将其余的数据点分配到相应的聚类中。
(1) 实验数据
科学网②(②http://www.sciencenet.cn/.)由中国科学院、中国工程院、国家自然基金委、中国科学技术协会主管, 由中国科学报社主办, 为全球最大的中文科学社区。本文选取科学网博客③(③http://bbs.sciencenet.cn/blog.php.)作为实验数据, 采集2007年3月6日到2012年1月22日共1 951个博主的43 545篇博文(含用户标签)作为数据样本。对于每个标签, 将其标注的博文的系统分类(见表1)作为它的系统分类项, 其用户的学科分类(见表2)作为它的学科分类项。
| 表1 博文系统分类表 |
| 表2 用户学科分类表 |
 |
其中, Cj表示第i个标签属于第j个系统分类的博文数量, K是系统分类总数。那么Tagi所属第j个系统分类的概率为:
 |
 |
其中, Uj表示第i个标签所属于第j个学科分类的用户个数, M是学科分类总个数。同上可以得到Tagi所属第j个学科分类的概率为:
 |
(2) 评测方法
采用熵值和纯度评价博文聚类结果。这是面向分类的度量, 这些度量评估簇包含单个类的对象的程度。熵值表示每个簇由单个类的对象组成的程度。对于每个簇, 首先计算数据的类分布, 即对于簇i, 计算簇i的成员属于类j的概率。计算每个簇i的熵, 其中L是类的个数。簇集合的总熵为计算每个簇的熵的加权[36]。熵值越小, 聚类效果越好。纯度是簇包含单个类的对象的另一种度量方法。纯度越大, 聚类效果越好[36]。
实验结果如表3所示, 对于单个特征的聚类结果, 用户特征聚类结果净相似度最高, 聚类个数较少(表3中加黑), 内容特征聚类结果净相似度最低, 聚类个数最多(表3中加黑)。净相似度是度量exemplars是否适用于解释数据的分数, 这是AP算法试图最大化的目标函数。所以用户特征聚类中的exemplars更适用于解释数据。
| 表3 标签聚类结果 |
在学科分类中, 用户特征聚类结果的熵值比内容特征聚类结果要小, 而纯度要高; 在系统分类中, 用户特征聚类结果的熵值比内容特征聚类结果要高, 纯度要小。所以在学科分类中, 用户特征聚类的结果更好; 而在系统分类中, 内容特征聚类的结果更好。其原因在于学科分类是基于用户的分类, 而系统分类是基于内容的分类。两种特征选择在各自的分类体系下都表现出较优的聚类结果。
对于两个特征的几组线性加权及Sigmod加权聚类结果评测, 画出两种分类体系下聚类结果的柱状图并作分析。学科分类下的两特征加权熵值图和加权纯度图如图3和图4所示。可以看出, 在线性加权中, 随着加权系数w1的增加, w2的减小, 即用户特征权重的减小和内容特征权重的增加, 聚类结果中熵值减小, 纯度增大, 但是到(0.6, 0.4)后, 熵值又开始增大, 纯度无明显变化。(0.6, 0.4)权重系数作为图中的转折点, 是内容和用户特征线性加权几组系数中, 最优的加权系数。说明内容特征与用户特征的线性加权可以提高标签聚类效果, 且内容特征的比重比用户特征的比重要稍大, 即内容特征的重要性更高。Sigmod加权函数作为神经元的非线性作用函数, 具有连续、光滑、单调且关于(0, 0.5)中心对称的特征。内容特征和用户特征的Sigmod加权的聚类结果中, 其熵值要远小于线性加权中最优的值(0.4, 0.6), 而纯度与其持平, 说明更注重平滑的Sigmod加权函数使基于内容特征和基于用户特征在学科分类体系下达到了最优的加权效果。综上所述, 两种加权方法都使得内容和用户特征的结合在学科分类体系下改善了标签聚类结果。
 | 图3 学科分类下的两特征加权熵值图 |
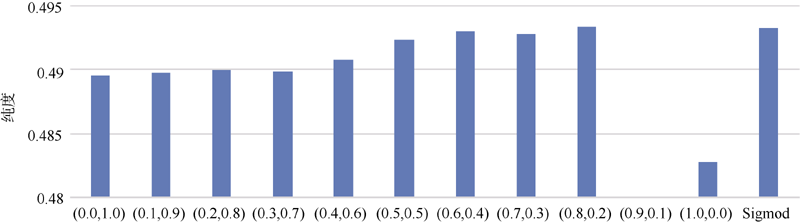 | 图4 学科分类下的两特征加权纯度图 |
系统分类下的两特征加权熵值图和加权纯度图如图5和图6所示。可以看出, 在线性加权中, 随着加权系数w1的增加, w2的减小, 即用户特征权重的减小和内容特征权重的增加, 标签聚类结果中熵值不断减小, 纯度不断增大, 最终在单独的内容特征聚类结果中熵值达到最小, 纯度达到最大。Sigmod加权中聚类结果表现一般, 和线性加权中的结果相当。笔者推测, 这种现象产生的原因在于系统分类是基于博文内容的分类, 以内容为标准的分类体系使得以内容为特征的标签聚类效果达到最优。用户特征的介入不但不能改善聚类结果, 反而成为聚类过程中的一种噪音和干扰。
 | 图5 系统分类下的两特征加权熵值图 |
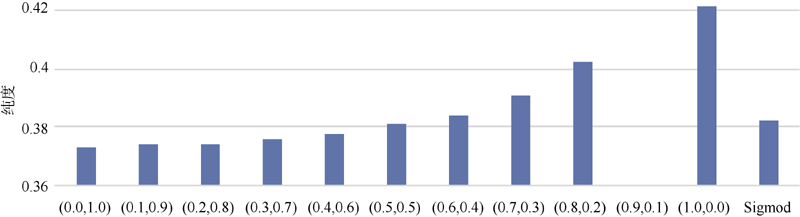 | 图6 系统分类下的两特征加权纯度图 |
综上所述, 单独基于内容或基于用户特征的标签聚类可以满足一般用户的需要, 单独的特征聚类在不同的分类依据下的分类结果存在差异, 基于用户特征的标签聚类结果在学科分类评估中表现更好, 基于内容的标签聚类结果在系统分类中表现更好。内容与用户特征的结合在某些情况下能够提高标签聚类结果。实验表明内容与用户特征线性加权和Sigmod加权在学科分类体系下都能提高用户标签聚类效果, Sigmod加权的表现结果更好。但在系统分类体系下, 内容与用户特征的两种加权均不能改善用户标签聚类结果。在某些情况下, 对内容特征与用户特征的结合能够提高标签聚类效果, 更加满足对用户的个性化标签聚类结果的需要。
(1) 优化权重分配策略
从实验结果中发现, 在线性加权中, 当标注内容权重稍大于用户属性权重时, 标签聚类质量最好, 而非线性Sigmod函数加权中, 标签聚类质量更好。说明非线性加权的方法要优于线性加权的方法, 在两种属性加权时, 应优先选择具有连续、光滑、严格、单调关于(0, 0.5)对称特征的非线性加权方法, 从而能够达到最优的标签聚类结果。
(2) 优化标签内容的相似度计算
本文采用两种特征向量(基于标注内容和用户属性)表示标签, 构建各自的向量空间模型, 计算它们之间的向量余弦值作为标签之间的相似度。在标签内容相似度的计算中还可以考虑标签的共现信息, 如标签在文章中的共现, 标签在用户中的共现; 标签的语义相似度等。
(3) 优化用户属性的相似度计算
在本文中, 用户属性的度量基于TF× IDF定义了UF× IUF的计算方法, 计算基于标签用户属性还可以考虑其他社会化因素, 如用户与用户之前的关系紧密程度(如好友关系), 用户对资源的评价行为(如点赞、评论等)。
(4) 增加不同类型的数据集
在本文实验中, 选择的标签为博文的标签, 为更偏向内容属性的样本。在社会化标注系统中, 还存在大量偏用户属性的标签, 如用户为自己打的标签。对不同偏好属性样本, 具体的聚类的策略选择还应根据样本的自身属性来确定, 即在标注内容和用户属性的权重分配或加权策略上也要进行调整。
本文从介绍大众分类法及其优缺点切入, 以中文网络博客标签为数据源, 从内容及社会化特征两个角度对标签特征进行抽取, 用两种加权方法对基于内容和社会化特征的相似度进行加权, 用AP聚类算法对样本进行聚类, 在两种博文分类体系下, 对两种不同的特征抽取方法及其加权结合的聚类结果进行评测, 并分析其产生的可能原因。通过实验证明, 在学科分类体系下, 内容特征及社会化特征的结合对标签聚类有明显的改善, 但在系统分类体系下, 内容特征和社会化特征的结合对标签聚类起到相反作用, 最后给出了标签聚类算法优化建议。本文不足之处在于只考虑用户标签, 忽略了从博文内容抽取的关键词, 未来工作可以探讨对于从文本内容中抽取的关键词, 社会化特征与内容特征的结合对关键词的聚类结果的影响。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|