
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于用户兴趣模糊聚类的协同过滤算法
[刘占兵1  , 肖诗斌
, 肖诗斌1, 2 ]
, 肖诗斌|
|


目的 解决传统协同过滤推荐算法存在的数据稀疏性、用户不同时间的兴趣被等同考虑的问题。方法 提出一种基于用户兴趣模糊聚类的协同过滤算法。将用户兴趣模型分为稳定兴趣和当前兴趣, 利用用户稳定兴趣对用户进行模糊聚类, 确定用户最近邻, 形成初始推荐集; 计算推荐列表中各个项目和用户当前兴趣的相似度, 然后按照相似度大小排序, 生成最终推荐列表。结果 在数据集MovieLens上验证本方法的推荐准确率, 其平均绝对误差(MAE)较传统方法降低近10%。【局限】该算法中, 在对用户稳定兴趣建模时考虑所有的项目类别, 没有对项目类别进行处理(如合并和删除等)。结论 与传统的推荐算法相比, 该方法的推荐准确度有明显提高。
[Objective] Solve the problems in the traditional collaborative filtering recommendation algorithm, such as sparse data and user’s interests in different time being considered equally. [Methods] This paper proposes a collaborative filtering algorithm based on user’s interest fuzzy clustering. In the algorithm, the model of user’s interest consists of the stable interest and the current interest. Users are clustered by the fuzzy clustering according to the stable interest, then the nearest neighbours and the initial recommendation list can be obtained. The final recommendation list is generated by sorting the similarity between the each item of initial recommendation list and user current interest, on the basis of the initial recommendations. [Results] The Mean Absolute Error (MAE) of the proposed method is nearly 10% reduction verified on the MovieLens dataset, compared with the traditional method. [Limitations] All categories of projects are considered in the model of the user stable interest without special treatments, such as merge and delete. [Conclusions] The experiment result indicates that the recommendation accuracy of the advanced approach is more efficiency, compared with the traditional recommendation algorithm.
随着用户数据和商品数据的激增, 对数据进行有效的分析和挖掘, 为用户提供个性化的推荐服务成为许多商家关注的焦点。而在个性化推荐的过程中, 作为主流技术的协同过滤推荐算法起着最为关键的作用。例如淘宝、京东、亚马逊、爱奇艺、豆瓣等网站利用协同过滤技术为用户进行商品个性化推荐, 提升服务质量。虽然协同过滤在众多领域得到成功的应用, 但是其存在的一些不足仍需要不断深入研究, 以达到更好的应用效果。
协同过滤算法通过对用户-项目评分矩阵中评分数据的统计来判断用户或项目的相似性, 而相似性计算是产生推荐集合的基础。随着用户数和项目数的不断增加, 用户-项目评分矩阵逐渐成为高维矩阵, 使得相似性计算的复杂度急剧增加, 进而导致系统性能下降。在用户-项目评分矩阵中, 用户真正给予评分的商品项很少, 通常在1%以下, 使得评分矩阵的数据逐渐稀疏, 从而导致推荐质量下降。此外, 协同过滤推荐算法不能快速发现用户的兴趣变化。聚类算法能够减小用户相似邻居的搜索范围, 而用户兴趣建模则可以描述用户的兴趣以及变化, 因此结合聚类和用户兴趣建模的方法对提高推荐质量有较大帮助。
针对传统协同过滤算法存在的评分矩阵稀疏、可扩展性弱、推荐精确度较低等缺点, 许多研究人员结合聚类方法和兴趣建模改进协同过滤的方法。
引入聚类算法可改善协同过滤算法的可扩展性, 提高最近邻的搜索效率[1, 2, 3]。李涛等[1]提出一种基于用户聚类的协同过滤推荐算法: 在线时对基本用户数据进行预处理, 并对基本用户聚类, 离线时利用已有的用户聚类寻找目标用户最近邻居, 并产生推荐。王荣等[2]基于项目属性特征对项目进行聚类, 再利用用户对项目簇的偏好对用户进行聚类以提高推荐效率。在这些算法中, 用户只会分到一个聚类中, 不符合现实中用户往往属于多个用户群体的情况, 严重影响推荐精度。为此研究人员引入模糊聚类方法。Verma等[4]提出一种结合模糊C-means聚类和协同过滤算法的混合推荐系统, 以解决稀疏性和可扩展性问题。李华等[5]提出一种基于用户情景模糊聚类的协同过滤推荐算法, 根据用户情景信息利用模糊聚类算法得到情景相似的用户群分类, 以改善数据稀疏性和实时性问题。王晓耘等[6]引入粗糙集概念, 提出一种基于粗糙用户聚类的协同过滤推荐模型, 根据用户与聚类中心的相似度将其分配到K个类的上、下近似中, 形成用户的初始近邻集。王明佳等[7]利用模糊聚类的方法对项目进行聚类, 结果证明能有效提高初始预测相似度计算精度。
为解决传统协同过滤算法不能及时反映用户兴趣变化而偏离用户真实需求的弊端, 一些研究人员针对用户的行为, 引入了用户兴趣漂移的概念[8, 9]。为了反映用户兴趣的动态变化, 邢春晓等[8]提出基于时间的数据权重和基于项目相似的数据权重, 其中基于时间的权重函数为线性函数, 而使用指数函数作为时间函数同样也可以改善推荐质量[9]。于洪等[10]提出基于艾宾浩斯遗忘曲线的时间函数用以学习和跟踪用户兴趣的变化。为感知用户特定背景下的语义信息和用户兴趣随着时间的变化, 刁祖龙等[11]基于用户兴趣本体提出一种新用户兴趣模型, 并通过激活扩展理论描述该用户兴趣模型的更新算法。
上述方法主要侧重用户兴趣遗忘的策略, 即如何消除用户过时的兴趣, 却没有考虑主动发现用户新的兴趣。然而用户的兴趣类是不断变化的, 因此对用户新的兴趣的发现也是非常重要的。有些方法对兴趣的处理只与兴趣出现在时间序列中的位置有关。但是有些兴趣属于用户长期关注的主题, 尽管在某段时间用户的访问(表现)次数很少, 但不能就此认为用户对该主题已经不感兴趣。单纯将聚类算法或者用户兴趣模型应用在协同过滤算法的研究比较多, 而将模糊聚类和兴趣模型结合进行推荐的研究比较少。
在前人研究的基础上, 本文提出一种基于用户兴趣模糊聚类的协同过滤算法。算法中构建了用户兴趣模型: 稳定兴趣模型和当前兴趣模型。首先基于用户稳定兴趣对用户进行模糊聚类, 根据目标用户选取不同比例的邻居形成最近邻; 根据最近邻产生初始推荐结果集; 最后计算推荐项和用户当前兴趣的相似度并对推荐项进行排序, 筛选之后形成最终推荐结果集。
现实生活中, 大多数项目往往具有的种类特征不止一个, 例如电影《智取威虎山》的类别特征有: 军事、冒险和战争等。相应地, 对于用户而言, 用户喜欢的影片类型也不止一种。模糊聚类分析能够建立样本对于类别的不确定性描述, 表达样本类属的中介性。模糊C-means聚类[12, 13, 14]是用隶属度确定每个数据点属于某个聚类程度的一种聚类方法。此方法把n个向量xi(i=1, 2, …, n)分为c个模糊组, 并求解每组的聚类中心和样本的模糊分类集合。
本文提出基于用户兴趣模糊聚类的协同过滤算法: 建立用户兴趣模型(包括用户稳定兴趣和用户当前兴趣)来表示和预测用户的兴趣行为, 并使用模糊C-means聚类方法对用户进行聚类, 从而对传统协同过滤算法进行改进。
用户兴趣模型[15]的表示方法有主题表示法、关键词列表向量法、向量空间模型[16]表示法、书签表示法、基于本体的表示法等。其中, 向量空间模型表示法的应用较广泛。本文使用向量空间表示法构建用户兴趣模型。
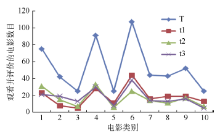
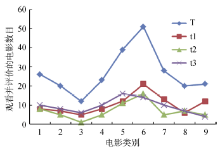
传统的协同过滤推荐算法中, 通常用户兴趣的变化没有被考虑, 但是在现实生活中, 用户的兴趣是随着时间的变化和环境的影响而不断变化。以用户观看电影为例来简单说明用户兴趣的变化。MovieLens 中ml-100k数据集中userId为1和298的统计信息如图1和图2所示:
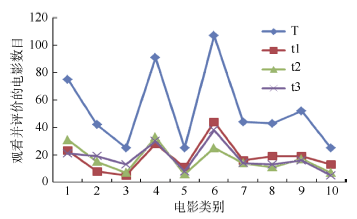 | 图1 用户(userId=1)不同时期观看评价的电影类别情况(注: 横坐标值依次对应的电影类别为: Action, Adventure, Children’ s, Comedy, Crime, Drama, Romance, Sci-Fi, Thriller, War。) |
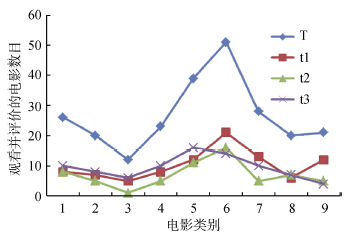 | 图2 用户(userId=298)不同时期观看评价的电影类别情况(注: 横坐标值依次对应的电影类别为: Action, Adventure, Animation, Children’ s, Comedy, Drama, Romance, Thriller, War。) |
图1和图2分别显示了用户(userId=1, userId=298)在不同时间周期(T表示其观看的整个时间周期, t1, t2, t3则表示将其观看的时间周期分为3个阶段)所观看的不同类别的电影数目。可以看出, 总体上用户在t1, t2, t3时期和T周期对不同影片类型观看数量比重的变化趋势基本上是一致的, 而局部对比单个时期的变化趋势, 其又有差异。例如userId=1的用户, 在三个时间阶段, 其观看的主要电影类别的数量比重依然很大; 而在各个时间段中, 各类别的影片数量有细微的变化, 如在t1时间周期, Action、Adventure、Crime、Sci-Fi、War数量(比重)分别为23(12.2%)、8(4.3%)、11(5.9%)、19(10.2%)、12(6.5%); 而在t2时间周期内, 数量有了一定的变化, 分别为31(18.7%)、15(9.0%)、6(3.6%)、11(6.6%)、7(4.2%)。
用户的长期稳定兴趣是用户在长期行为过程中逐渐形成的, 是对用户过去行为习惯的一个整体描述; 而用户的当前兴趣是用户在现阶段一个行为缩影的描述, 故本文将使用长期的稳定兴趣和短期的当前兴趣来描述用户兴趣。建立的兴趣模型描述如下:
(1) 稳定兴趣模型
考虑到在用户的兴趣变化过程中, 用户在长期访问或购买的习惯往往会形成以项目类别为特征的稳定兴趣, 所以利用从用户开始有访问记录的时间开始到现在为止访问过的所有项目的类别信息来定义用户u的稳定兴趣favs(u)为:
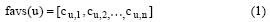
其中, cu, i表示用户u对项目类别为i的项目的兴趣度系数, 它由以下公式得到:
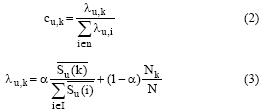
其中, λ u, k表示用户u对项目类别为k的项目的兴趣度, 既注重了用户对项目的数量, 也考虑了用户的评分, α 表示权重系数。 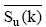
(2) 当前兴趣模型
用户的当前兴趣和用户最近访问的项目有很大关系, 用户也会经常性地根据项目的属性特征(比如电影, 其类别、导演、演员、产地等信息)来选择要访问或者购买的项目, 所以可以使用项目在不同维度上的属性[17]来表示用户的当前兴趣。设用户当前兴趣的时间周期为t, 那么用户u在t时间周期的当前兴趣可以表示为:
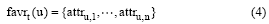
其中, attru, i是用户u的第i个属性特征。
一般来说, 用户近期访问过的资源对推荐该用户未来可能感兴趣的资源有比较重要的作用, 而早期访问记录对生成推荐影响相对较小, 这是因为用户兴趣会随时间的推移逐渐减弱, 而在较短的一段时间内用户的兴趣是相对稳定的, 因此一个用户感兴趣的资源最可能和他近期访问过的资源相似[8]。文献[9, 10, 18]依据这一特点引入时间函数描述用户兴趣的变化。在此基础上, 笔者提出当前兴趣的更新机制:
当前兴趣的更新和用户的活跃程度有很大关系。当这个用户比较活跃的时候, 其当前兴趣才能更好地体现出来。用户的活跃度(本文使用用户在最近t时间内的电影浏览数量)用参数atv表示, 设用户t时间周期的当前兴趣为favrt(u), 那么预测用户u下一个时间周期t+1的当前兴趣为favrt+1(u):
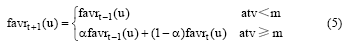
其中, m表示当前用户在t周期内访问资源数目。
(3) 相似度计算
①用户稳定兴趣相似度公式如下:
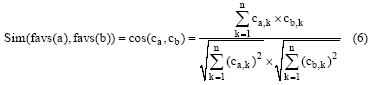
其中, ca, k表示用户a对项目类别为k的项目的兴趣度。
②用户当前兴趣和推荐电影项的相似度公式如下:
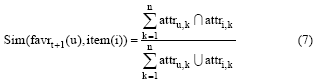
其中, favrt+1(u)表示预测目标用户u在下一个时间周期t+1的当前兴趣, item(i)表示初次推荐集中的第i个项目。Attru, k表示用户u 在favrt+1(u)下的第k个属性, attri, k表示初次推荐集中第i个项目的第k个特征。
基于用户兴趣模糊聚类的协同过滤算法如下:
输入: 用户-项目评分矩阵
输出: 项目的预测评分和TOP-N推荐
①根据公式(2)和公式(3)计算用户的各个类别兴趣度, 构建用户的稳定兴趣度矩阵。
②用户稳定兴趣模糊聚类; 通过模糊C-means聚类, 不仅可得到用户稳定兴趣的聚类中心H和隶属度矩阵U, 还可以得到用户在稳定兴趣上的相似性分类。对于这一步来说, 推荐系统可采用离线的方式完成, 这样不会影响到推荐系统的实时性。
③根据目标用户u对各个聚类j∈ C (C表示个聚类中心)的隶属度sim(u, j), 分别从各个聚类(隶属度大于e的聚类, e为给定的阈值)中选取对应比例 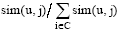
④根据目标用户的最近邻, 计算其对未评分项目的预测评分, 依据预测评分生成初始推荐项目集合。
⑤利用公式(5)预测目标用户下一周期的当前兴趣。
⑥利用公式(7)计算目标用户的当前兴趣和推荐项目的相似度, 利用当前用户兴趣和推荐项目的相似度对初始推荐列表进行排序, 并产生TOP-N推荐。
本实验数据采用GroupLens项目组提供的MovieLens数据集, GroupLens站点提供了不同大小的数据集, 本文采用ml-100k数据集, 该数据集包含943位用户对1 628部电影的100 000个评分, 且评分范围为1-5, 每个用户至少对20部以上的电影进行了评分, 数据稀疏度为93.7%。
具体实验取数据集中u.data的评分记录的子集: 选取700名用户, 他们的评分大于等于4且评论电影数在20部以上。总计52 184条记录, 随机选取80%作为训练集, 20%作为测试集。
本文采用平均绝对偏差MAE[19]作为推荐准确度评价标准。MAE通过计算目标用户的预测评分与实际评分之间的偏差度量预测的准确性, 因而MAE指标的值越小, 推荐质量越高。
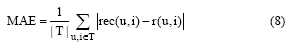
其中, T表示测试集, | T |表示测试集中评分数目, rec(u, i)表示用户u对项目i的预测评分, r(u, i)表示在T中用户u对项目i的实际评分。
(1) 参数α 对MAE值的影响
由于公式(3)中参数α 在用户兴趣聚类时决定了项目数量和项目评分用户稳定兴趣中的比重, 所以该取值会对推荐精度产生很大的影响。实验1设计α 取值从0到1.0, 每次增加0.1, 观察MAE值的变化。其中控制的变量: 最近邻数目为25, 聚类数目为7。实验结果如图3所示。可以看到结合用户观看的各个类型影片的数量和评分信息, 推荐效果有明显提升; 而在α 取值在0.6-0.7之间时, 效果最好。
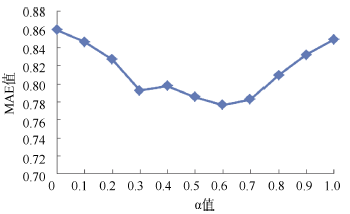 | 图3 参数α 对MAE值的影响 |
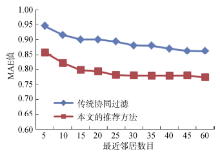
(2) 与传统算法实验结果的比较
为验证本文方法的有效性, 设计实验2与传统协同过滤方法进行对比。在实验1的基础上, 公式(3)中参数α 值选取0.6-0.7达到最优, 为此本文选取α 值为0.6进行实验。同时在用户与电影项的相似度计算上, 只考虑电影类别属性。实验结果如图4所示, 可以看出, 随着目标用户的邻居数量的增加, 算法的推荐准确度开始有所提高。在相同的实验条件下, 本文提出的算法在准确性方面优于传统的协同过滤方法。
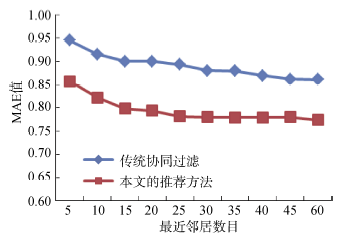 | 图4 本文算法和传统推荐算法的MAE比较 |
针对传统协同过滤中的数据稀疏性问题, 本文引入了用户稳定兴趣和当前兴趣的模型, 并利用模糊聚类算法改进传统协同过滤推荐算法。实验表明本文方法可以显著提高推荐的准确性。本文方法虽然在一定程度上缓解了数据稀疏问题对推荐准确性的影响, 然而实验中发现, 数据规模较大时运行效率不高, 因而未来将会重点研究结合分布式的推荐算法以提高运行效率。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|