
{kind=link}
{kind=link}
结合复杂网络的特征权重改进算法研究
[杜坤 , 刘怀亮, 郭路杰]
, 刘怀亮, 郭路杰]
, 刘怀亮, 郭路杰]
|
|


目的 为了更准确计算特征权重, 以提高文本相似度计算的准确性。方法 考虑特征项间的语义关联构造文本复杂网络并进行特征选择, 定义类别相关系数并结合特征选择结果, 提出一种改进的特征权重计算方法, 并进行中文文本分类实验。结果 对比实验结果表明, 本文提出的特征权重改进算法较之TFIDF算法能够取得较好的分类效果。【局限】特征选择评估函数中的参数需要人工给定。结论 相较于传统的TFIDF算法, 该算法能够更加准确地计算特征权重。
[Objective] This paper aims to calculate feature weights more accurately for the improvement of the accuracy of text similarity calculation. [Methods] The semantic association among features is considered to structure text complex networks and select features. An improved calculation method of feature weighting is proposed to carry out the Chinese text classification experiment with the definition of category correlation coefficient and the combination of the feature selection results. [Results] Experiment results show that the proposed Chinese text classification method works better in classification than the TFIDF algorithm. [Limitations] The parameters in the feature selection evaluation function need to be given. [Conclusions] Compared with the traditional TFIDF algorithm, the new algorithm is more accurate in the representation of feature weights.
大数据时代需要进行有效的文本挖掘, 文本分类是文本挖掘的关键技术之一, 其目的是对文本进行有效的组织与管理, 便于用户准确定位所需信息。文本表示是文本分类领域的基础性问题, 利用向量空间模型进行文本分类时, 需要经过特征选择、特征权重计算及文本相似度的度量等多个步骤。特征权重表示特征项在文本中的重要程度, 权值越大, 特征项越能代表文本的主题, 权重计算的合理性和有效性直接影响到文本相似度的准确性和分类的效果。
基于VSM的TFIDF权重计算方法被广泛地应用于文本间的相似度计算, 但该方法通过词频TF反映文本内部特征过于简单, 没有考虑特征项间的语义关联, 此外IDF的计算并没有考虑到特征项在类内和类间的分布情况。国内外学者多从IDF方面改进特征权重算法, 如台德艺等[1]利用集中度系数及分散度参数改进算法, 提出TF-IIDF-DIC权重函数; 苏丹等[2]定义最少出现文档频率LDF, 用LDF替换IDF, 但这两种方法都使用TF作为文本内部特征表示, 忽略了特征项在文本上下文中的语义作用。还有学者从特征选择角度修正特征词权重, 如赵小华等[3]将χ 2统计量引入到特征权重计算中, 提出TF-IDF-CHI算法修正各个特征词的权重; 李原[4]通过引入信息熵IG改进TFIDF算法; Debole等[5]和陆玉昌等[6]使用特征选择函数代替IDF因子以提高特征权重计算的准确度。但他们使用的特征选择方法是基于词频信息或词语与类别间关系的统计信息, 没有考虑特征项间的语义相关关系, 并且文献[3, 4, 5, 6]也是利用特征选择弥补IDF的不足, 没有考虑TF的不足之处。
Huang等[7]、Liu等[8]分别以词语的句法关系及知网语义相似度为基础构建文本复杂网络实现特征抽取; 赵辉等[9]利用构建的文本复杂网络进行特征选择。这些方法为本文的特征权重改进提供了新思路。
本文利用维基百科计算词语语义相关度, 构造加权的中文文本复杂网络, 同时使用文献[9]中的节点综合特性评估函数CF计算特征项在文本中的重要度。不同于文献[3, 4, 5, 6], 本文利用特征选择评估函数CF替代TF, 以弥补使用词频表示文本内部特征的不足, 并定义类别相关系数以修正IDF, 使特征项的权重计算方法更合理, 以达到提高文本分类的效果。
共现频率法[10]是目前基于语料库的词语相关度计算的主要方法。其基本原理是: 在统计语料中对在同一窗口单位的两个词进行统计, 它们之间的相关度随着它们共现频率的增高而增大。公式如下:
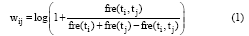
其中, fre(ti, tj)表示特征词ti和tj在一个窗口单元中共现的频率, fre(ti)、fre(tj)则表示特征词ti和tj在文本dk中出现的总频率。
本文以维基百科知识库为数据源, 将文本中的特征词转化为维基百科中的主题概念, 即将特征词t映射为维基百科中存在的主题概念C。当该特征词存在重定向[11, 12]时, 分别以重定向的概念作为它们的主题概念, 考虑到词语-概念匹配有不成功的情况, 此时使用共现频率法确定词语ti与tj间的相关度。如果词语-概念匹配成功, 利用概念间的链接结构[11]和所在的类别体系[12]分别计算概念距离和类别距离, 将这两个值进行线性组合, 计算概念间的相关度, 从而完成词语相关度的计算。具体计算方法如下:
(1) 链接距离
对于一个概念的主题页面而言, 不仅会在其他页面中被链接, 表现为链入链接, 也有该主题页面中包含的其他概念的链接, 表现为链出链接。Witten等[13]对这两种链接分别计算相关性后再综合, 提出了基于维基百科链接的概念间语义相关度计算方法(WLM算法)。考虑到实际运算的效率, 本文在计算两个概念间的链接距离时, 仅考虑链入链接距离。对于链入链接距离, WLM算法采用修改了的Google Distance方法, 其公式如下:
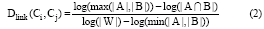
其中, A、B是指在维基百科中分别与概念Ci、Cj有相互链接关系的概念集合, W则指维基百科中所有概念解释页面的集合。符号“ | |” 表示集合中的实体数量。
(2) 类别距离
类别距离是通过概念节点在层次结构中的距离反映概念间的相关度。距离越小, 两个概念越相关。在维基百科的分类体系中, 一个分类节点可能包含多个上层和下层分类节点, 因此两节点间的路径可能不唯一。Rada等[14]认为在两节点的多条路径中, 必然存在一条最短路径, 故两节点间的最短路径越小, 则其距离就越近, 概念间的相关度也就越高。但是在维基百科中, 即使路径长度相同的两个节点, 如果所在层次越高, 表示的概念也越抽象, 节点间的相关度会越小。因此本文采用Wu等[15]在层次结构中寻找最近公共父节点(Least Common Subsumer, LCS)的方法计算两个概念间的类别距离, 其公式如下:
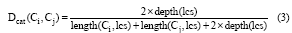
其中, lcs为概念节点Ci和Cj在层次结构中的最近公共父节点, depth(lcs)为节点lcs在层次结构中的深度, length(Ci, lcs)和length(Cj, lcs)分别为节点Ci、Cj到lcs的最短路径长度。
(3) 相关度计算方法
为了更准确地衡量概念间的相关度, 本文综合考虑链接距离和类别体系中蕴含的概念之间的关系, 对于主题概念Ci和Cj, 它们之间的概念语义距离形式上表现为链接距离Dlink和类别距离Dcat的线性组合, 计算方法如下:
D(Ci, Cj)= α Dlink(Ci, Cj)+(1-α )Dcat(Ci, Cj) (4)
其中, D(Ci, Cj)表示两个概念间的语义距离, α (0< α < 1)为调节参数。由于概念与其本身的距离为0, 而且概念距离越大, 它们之间的相关关系越不明显。因此, 将概念之间的相关度计算公式定义为:
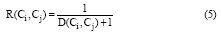
求得概念间的语义相关度作为对应词语ti与tj的相关度, 并把该计算结果作为加权复杂网络中的特征词之间的权重。
基于维基百科的词语语义相关度计算流程如图1所示:
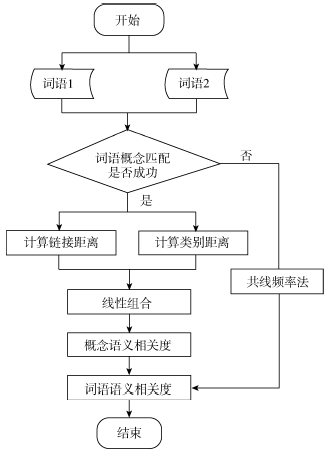 | 图1 词语语义相关度计算流程图 |
在对文本进行分词、去停用词等预处理之后, 文本d被表示为特征项的集合T=(t1, t2, …, tm)。为更大限度地保留原文的语义信息和结构信息, 本文将特征项集合表示成复杂网络加权无向图的结构。定义一个三元组的图结构形式, 即G=(N, E, W), 其中N表示网络中节点的集合, E表示网络中连接边的集合, W为对应E中边的权重集合。构建方法主要包括以下步骤:
(1) 定义一个句子为一个窗口共现单元, 将文本的特征项集T=(t1, t2, …, tm)中的特征项映射为图结构中的节点, 得到图的初始节点集N0=(n1, n2, …, nm)。
(2) 从N0中任意选取两个节点ni和nj, 如果这两个节点对应的特征项Ti和Tj在同一个窗口单元中出现, 则在两个节点间添置一条无向边eij, E={eij}, 并将ni和nj加入到节点集N中。
(3) 计算无向边eij的权重wij, W={wij}。边的权重计算过程即词语的语义相关度计算过程, 边的权重大小表示两个特征项间的语义关联程度。权重越大, 两个特征项间的语义关联越紧密。
经上述步骤, 文本d的原始特征集T=(t1, t2, …, tm)就转化为由节点集合N={n1, n2, …, nk}、连接边集合E={eij=(ni, nj)|ni, nj∈ N}以及权重集合W={w12, w13, …, wij}组成的复杂网络图结构G。
本文构造的文本复杂网络中, 节点间的连边权值对应的是特征词间的相关程度, 权值越大, 表示两节点间的连接越紧密, 距离越小, 故这种加权方式是一种相似加权。相应地, 本文使用复杂网络节点的统计特性定义如下:
(1) 节点加权度[16]
节点的度表示该节点与其他节点的连接数目。在加权网中, 与节点度相对应的是节点加权度WDi, 其表示如下:
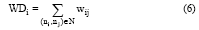
其中, wij表示节点ni与其连接节点nj的边的权值。节点加权度既考虑了节点的近邻数, 又考虑了该节点和近邻之间的权重, 是该节点局域信息的综合体现。
(2) 节点加权聚集系数[17]
节点的聚集系数是指与该节点相连的近邻节点之间互连的比例。用WCi表示节点的加权聚集系数:
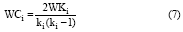
其中, WKi为节点ni邻接节点间边的权重和, 称为节点ni的加权聚集度, ki表示节点ni的度数。加权聚集系数可以反映节点的连接强度和密度。
(3) 节点介数[18]
节点介数反映节点在网络中的作用与影响力, 即网络中用来衡量任意节点间最短路径通过该节点的比例。节点介数Pi可以定量地表示为:
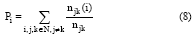
其中, njk表示连接任意节点的最短路径数量, njk(i)表示最短路径经过节点ni的数量。
为了综合考量节点在文本中的重要程度, 本文使用文献[9]提出的节点重要度综合计算公式作为文本特征选择的评估函数:
CFi=β 1WDi+β 2WCi+β 3Pi (9)
其中, CFi为节点i的综合特征指数, 在计算CFi之前, 需要先对WDi、WCi、Pi进行归一化处理, β i(1≤ i≤ 3)为可调节参数, 代表各个部分的权重, 且β 1+β 2+β 3=1。利用上述公式计算每个节点的综合特征值, 按照特征值CFi进行排序, 选取CFi值较大的前m个节点对应的特征词, 可以达到特征降维的效果。
传统的特征权重计算方法主要考虑文本特征项的频率(Term Frequency, TF)及倒排文档频率(Inverse Document Frequency, IDF)。TFik是指某个特征词ti在文本dk中出现的频率, TFik越大, 表明特征词ti对文本dk越重要。为避免文档中大量出现的禁用词对特征权重计算的干扰, 引入倒排文档频率解决这一问题, 它表示该特征词在文档集合中分布情况的量化, 常用的计算方法是log(N/nk+0.01)。经过归一化处理, 特征词ti在文本dk的权重计算公式如下:
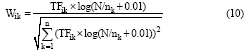
其中, TFik为词频, N为文档集合中的文档数目, nk表示出现过该词语的文档数目。
TFIDF方法原理简单, 计算量也不大, 易于被人们接受。但是该方法也不可避免地存在一些缺点:
(1) 文本内部特征通过TF来反映过于简单。事实上, 除词频外, 出现的位置、出现的范围及与其他词的关系都是词的重要特征。而且, 最能表达文本主旨内容的往往不是频率最高的词。
(2) 如果一个特征词在某个类中频繁出现, 而在其他类中却极少出现, 这样的词具有明显的类别区分度, 应被赋予较高权重, 但根据IDF定义, 这样的词很有可能被赋予较低的权重。
特征权重算法对文本分类的精确度有很大影响, 针对上述TFIDF算法的不足之处, 本文从以下两个方面做改进:
(1) 复杂网络特征选择评估函数CFik表示特征项Ti在文本dk中的重要度, 综合考量了特征项的结构信息和语义信息, 比仅考虑特征项在文本中频率的TFik更具有代表意义。因此, 令 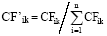
(2) 利用训练集中特征项在类内的分布信息, 若特征项在某一类别中出现次数较多, 在其他类别中很少出现, 则该特征项具有明显的类别区分度, 应提高该特征项的权值。因此, 本文提出类别相关系数γ i, 以提高频繁出现在某一类中的特征项的权值, 降低出现次数少的特征项的权值, 则 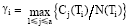
经过上述两种改进, 本文的特征权重计算公式如下:
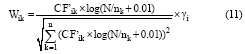
其中, Wik表示文本dk中第i个特征项Ti的权重, CF’ ik为特征项Ti在文本dk中的综合特征指数, 可由公式(9)计算得到。N为文本集中总的文本数, nk为包含特征项Tk的文本数。
通过分词软件进行分词、去除停用词处理后, 将文本表示成复杂网络图, 计算节点重要度并进行特征选择, 利用上述的特征权重计算公式计算特征项权重, 以提高中文文本的分类精度。算法描述如下:
输入: 训练文本集D1和测试文本集D2
输出: 带有类标签的测试文本集D2
过程:
①文本预处理, 对训练文本集D1和测试文本集D2进行分词和词性标注, 保留动词、名词、形容词等实词, 去除感叹词、连词、介词等虚词, 得到初始的文本特征集合。
②根据第3节介绍的方法对训练集D1构建文本复杂网络图, 根据公式(9)计算特征节点的综合指数CFi, 选取前m个节点对应的特征词作为特征选择的结果, 形成数据词典。
③根据数据词典, 对测试集文本D2进行特征选择, 并使用公式(11)计算训练集和测试集中每篇文档中特征项的权重, 形成特征向量。
④使用夹角余弦法计算D2中的一个文本d与训练文本集D1中的每一个文本的相似度, 将计算得到的相似度降序排列, 选取相似度值排在前面的K篇训练集D1中的文本。
⑤在选取的与待分类文本d最近邻的K篇文本中, 利用以下公式计算文本类别Cj对待分类文本d的权重:
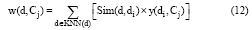
其中, Cj为某一文本类别, KNN(d)表示待分类文本d的K个最近邻的文本, Sim(d, di)为余弦相似度计算公式, y(di, Cj)表示类别属性函数, 取值如下:
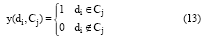
将待分类文本d的类标签标记为权重最大的类别, 返回分类结果C。
⑥对测试文本集D2中的每一个文本重复步骤④和步骤⑤, 得到每篇文本的类别标签。
实验数据选取复旦大学中文语料库中的2 400篇文本, 分为农业、经济、政治、体育4个类别, 每个类别600篇文本, 从每个类别随机抽取400篇作为训练集, 其余文本作为测试集。分词软件使用中国科学院计算技术研究所的ICTCLAS软件[15], 选取哈尔滨工业大学的中文停用词表, 包含767个中文停用词。本文下载2014-12-04版本的维基百科中文数据①(http://download.wikipedia.com/zhwiki/20141204), 利用JWPL已定义好的Java API接口计算词语相关度。具体的实验过程如下:
第一组实验采用本文的结合复杂网络改进特征权重的中文文本分类算法。第二组实验采用本文提出的基于复杂网络的方法进行特征选择, 使用传统的TFIDF算法计算特征权重。第三组实验采用卡方检验的方法进行特征选择, 使用传统的TFIDF算法计算特征权重。实验公式(4)中的α 取0.7, 公式(9)中β i(1≤ i≤ 3)采用文献[9]中的取值, 即β 1取0.4, β 2取0.3, β 3取0.3。三组实验均采用KNN分类算法, 其中K取15, 确定特征选择维数为1 000维。为保证实验结果的准确性, 对每组实验重复三次, 每次实验时三组实验的训练集和测试集是相同的, 选取三次分类结果F1的平均值作为最终结果。
采用使用广泛的准确率P(Precision)、召回率R(Recall)和F1测度值作为文本分类评价指标。准确率P、召回率R公式如下:
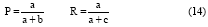
a, b, c表示满足一定条件的文档数量, 如表1所示:
| 表1 分类评价二元表 |
F1的公式如下:

三组文本分类实验的每次F1值如表2所示。每组实验的三次结果的F1值的平均值如表3所示:
| 表2 三组实验的每次F1值(%)比较 |
| 表3 F1值(%)结果对比 |
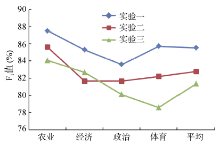
将对比结果绘制成折线图, 如图2所示:
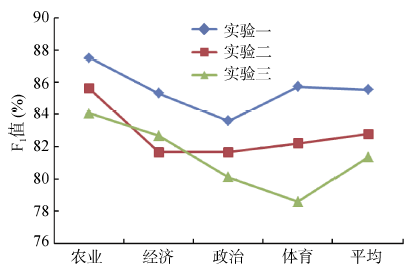 | 图2 实验结果F1值对比 |
从表3及图2中可以看出, 不管从各个类别还是从平均值来看, 实验一F1值比实验二和实验三都要高, 这说明使用本文的中文文本分类算法可有效提高文本分类的精度。实验一和实验二相比, 同是使用基于复杂网络的特征选择方法, 使用本文提出的改进特征权重计算公式提高了分类的准确度, 验证了结合复杂网络的特征权重改进算法的有效性和可行性。实验二和实验三相比, 使用复杂网络特征选择的实验二总体上比实验三的分类效果要好, 本文的实验方法虽然和文献[9]构建文本网络的方法不一样, 但也从一定程度上验证了利用复杂网络进行特征选择的有效性。
文本相似度计算的准确与否直接影响到文本分类的精度, 而特征权重的精确度直接影响到文本相似度的准确性。本文通过构建文本复杂网络来保留文本结构及词语间的语义相关信息, 利用节点综合特性计算特征项在文本中的综合指数, 使特征选择结果能够体现文本的结构信息及语义信息, 并尝试在传统的TFIDF算法基础上, 引入特征项在文本中的综合特征指数及类别区分度, 改进特征项权重计算方法。中文文本分类实验表明, 该算法能够有效提高分类精度。本文是从文本分类的角度进行特征权重的改进, 类别相关系数必须经过训练文本集的训练产生, 但没有训练集的文本聚类也会用到TFIDF算法, 下一步将研究单独使用CF替代TF对文本聚类的影响。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|