







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于EM-LDA综合模型的电商微博热点话题发现
[伍万坤1  , 吴清烈
, 吴清烈1 , 顾锦江1, 2 ]
, 吴清烈|
|


目的 在社交营销环境下, 准确且有效地挖掘电商微博中的热点话题。方法 提出一种综合模型EM-LDA对电商微博文本数据进行主题挖掘。EM-LDA综合模型包含两个子模型: ET-LDA模型和IT-LDA模型, 前者对含有哈希标签的微博进行主题挖掘, 后者对不含有哈希标签的微博进行主题挖掘。结果 在确定合适的主题个数之后, 标准LDA模型和EM-LDA综合模型均被用来挖掘电商微博文本数据的热点话题, 与标准LDA模型相比, EM-LDA综合模型的热词挖掘准确率和有效性均较高, 且能提高主题可解释性。【局限】在ET-LDA模型中, 未考虑微博联系人之间的关联关系, 即模型中未引入用户特征; 在IT-LDA模型中没有考虑如何处理那些既是转发式又是对话式的电商微博。结论 EM-LDA综合模型根据数据的特点, 改进了标准LDA模型, 能够提升电商微博热点话题识别的准确性。
[Objective] Extract hot topics from e-commerce microblog in social marketing. [Methods] This paper proposes an integrated model, EM-LDA (E-commerce Microblog-LDA) to extract hot topics from e-commerce microblog. The integrated model contains two submodels, that is, ET-LDA model and IT-LDA model. The former is to extract hot topics from those e-commerce microblog with Hashtag, and the latter is to extract hot topics from those e-commerce microblog without Hashtag. [Results] The standard LDA model and EM-LDA integrated model are both used to extract hot topics from e-commerce microblog text after the number of topics is determined. Compared with the standard LDA model, EM-LDA model extract hot topics more accurately and effectively, also can improve interpretability. [Limitations] ET-LDA model is not considered about the relationship between microblog contacts, that is, user feature is neglected. IT-LDA model does not concern how to deal with those e-commerce microblog both belong to conversation and retweet. [Conclusions] According to the special features of e-commerce microblog text, EM-LDA integrated model ameliorates the standard LDA model to improve the accuracy of hot topic extraction from e-commerce microblog.
2011年京东商城与新浪微博合作推出了“ 微购物” , 合作创造的W-Commerce模式, 与Facebook推出的F-Commerce具有异曲同工之妙。目前主流电商企业都想方设法利用微博进行营销宣传, 微博是广大网民沟通的即时平台, 它本身所具有的特点就决定了如果利用微博做营销宣传, 一旦成功则会产生惊人的效果。如果将微博所带来的口碑营销、人际传播等效应引入到商业应用中, 则能够为企业的社交营销带来意想不到的效果。在社交营销领域, 电商企业发布的营销微博往往被众多的“ 噪音” 微博淹没, 错综复杂的关注关系和杂乱无章的微博环境使得电商企业无法向特定用户传递商务信息, 如新品宣传、活动推广、产品促销等, 同时用户在有限的时间内也无法在浩如烟海的微博中发现自己感兴趣的信息, 因此对电商微博的主题挖掘就显得十分重要。
LDA模型是主题建模中的一个公认的标准, 且应用于多个领域, 如社会网络、社交媒体[1]。LDA主题模型具有优秀的降维能力和扎实的概率理论基础, 所以LDA模型在微博主题挖掘中具有很大的潜力[2, 3]。近年来, 为了提高LDA模型主题挖掘的效率和准确性, 出现很多对LDA模型的改进方法, 可归纳为纵向的过程扩展和横向的模型扩展[4]。
一方面, 针对微博文本篇幅较短的局限, 基于操作过程扩展的方法考虑将微博文本进行适当的聚集, 这样短文本被聚集成相对适合挖掘的长文本。Weng等[5]采用同一微博用户的所有微博文本聚集成一篇长文档的策略, 利用LDA模型进行主题挖掘。Hong等[6]出基于训练的用户模式(User Scheme)建模和基于术语模式(Term Scheme)建模。另一方面, 为了适应微博短文本的主题挖掘, 规避短文本数据噪声大的影响, 基于模型扩展的方法优化LDA模型, 典型的改进模型包括ATM[7]、Twitter-LDA[8]、Labeled-LDA[9]、MB- LDA[2]、HLDA[10]以及MA-LDA[11]。Zhao等[8]提出一种Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题。Ramage等[9]提出Labeled-LDA, 这是一个基于标签的主题模型。张晨逸等[2]提出一种微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘。对于LDA模型的纵向和横向改进方法的比较如表1所示:
| 表1 改进LDA主题建模方法比较[4] |
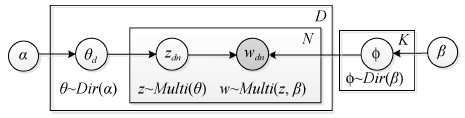
LDA模型是一种典型的用于话题提取的概率潜语义模型, 由Blei等[12]提出, 是一种具有文本主题表达能力的无指导学习模型, 如图1所示。LDA模型可以随机生成一篇由若干个主题组成的文档。假设文档集有D篇文档, 每篇文档看作是由K个主题混合产生, 每个主题k由词上的多项式分布形成。wdn表示第d个文档的第n个词, wdn∈ V, V是词的词语集; zdn表示产生wdn的主题; α 是文档集的主题先验分布超参数; θ d是文档d在主题上的分布比例, 对于每篇文档d, θ d服从参数为α 的Dirichlet分布, 即θ d ~Dir(α ); 一个主题Φ k是词语集V中词的分布; 图中模型包含K个主题在词上的分布Φ 1:K, N是文档d的总词数。
 | 图1 LDA模型[16] |
电商微博文本中的哈希标签(Hashtag)是一种用于简化搜索、索引和趋势发现的用户自定义标签, 格式为“ #话题名称#” , 这种标签具有用户特征和日期属性等。将含有哈希标签的微博归为一类, 称为显式话题微博; 剩余不含哈希标签的微博归为隐式话题微博, 此类微博还可以按照不同的消息发布方式细分为广播式、对话式和转发式微博, 其定义如下:
(1) 显式话题(Explicit Topic, ET)微博是指在电商微博中存在以“ #话题名称#” (称为哈希标签)的形式显式地表达所要发布的主题信息或热点话题, 这类微博具有重要的用户特征和日期属性。
(2) 隐式话题(Implicit Topic, IT)微博是指不含哈希标签的微博, 按照消息发布方式其主要分为三类: 广播式微博、对话式微博和转发式微博, 这三类微博分别表征了联系人与文本之间的关联关系, 联系人之间的关联关系以及微博之间的文本关联关系。
(3) 广播式(Broadcast)微博比较简单, 即发布者首创并以简短的文字、图片、音频、视频、超链接等形式实现即时分享的一种微博。
(4) 对话式(Conversation)微博是指微博的联系人之间以“ @微博名……” 形式表达关联关系的微博, 这种关联关系指的是带有“ @” 的微博与@的联系人之间存在潜在的语义关联。一般来说, 与同一个联系人存在关联的微博, 他们的主题往往也是相关的。
(5) 转发式(Retweet)微博是指微博的文本以“ ……//@微博名……” 形式表达关联关系的微博, 这种关联关系指的是带有“ //@” 的微博与原微博之间存在潜在的语义关联, 其中“ //@” 之前的是原创内容, 有时可以省略, “ //@” 之后的是转发内容。
由于电商微博文本数据包含大量可供参考的标签信息, 因此分别建立两种主题挖掘模型: 将含有哈希标签的微博归为显式话题微博, 并用ET-LDA模型进行主题挖掘, 在模型中引入日期属性, 并利用标签信息增加标签词在主题中出现的概率, 这样使得主题挖掘结果更容易被解释; 将不含哈希标签的微博归为隐式话题微博, 对于一条微博, 其必然是广播式微博, 抑或是转发式微博, 抑或是对话式微博, 由于转发式微博具有联系人关联关系, 对话式微博具有文本关联关系, 所以可以利用这两种关系进行整合建模, 从而建立IT-LDA模型, 该模型挖掘主题词的结果比标准LDA模型更加准确。本文的研究对象是电商微博(E-commerce Microblog), 基于EM-LDA(E-commerce Microblog-LDA)综合模型的电商微博热点话题识别流程如图2所示:
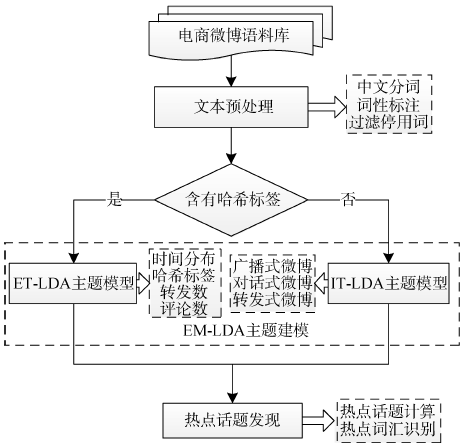 | 图2 基于EM-LDA综合模型的电商微博热点话题发现技术流程 |
对于显式话题微博有一个重要的关于日期的特征, 那就是此类微博往往在某个特殊的日期前后高频率的出现, 比如各大电商发起的“ 年中大促” 、“ 双十一” 、“ 双十二” 、“ * * 周年店庆” , 因此挖掘这类微博的 热点话题, 日期属性是非常重要且有价值的。本文将日期属性作为一个变量引入模型中, 同时标签也被结合到LDA模型中, 标签主要是调节话题出现的概率, 让那些出现在标签中的热点词的概率增大。在显式话题微博中, 虽然存在一些标签标注了话题, 但是这些话题并不都是热点话题, 对于那些短时间内不被很多人关注的微博, 将其视为非热点话题处理。
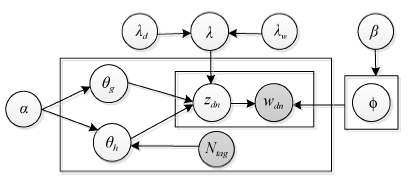
ET-LDA(Explicit Topic-LDA)模型是对MA-LDA模型[11]的改进, 对日期变量给出更加严格的定义, 标签变量是可观测到的数据, 所以纳入模型中以灰色表示, 据此给出ET-LDA模型的贝叶斯网络图, 如图3所示:
当对每个文档生成主题分布时, 引入一个二值变量λ , 此变量用于决定当前的词语是来自于非热点主题θ g(λ =0)还是热点主题θ h(λ =1)。λ 值由另外两个变量决定, 它们是关于词语的日期分布的二值变量λ w和关于文本的日期分布的二值变量λ d。对于词表中的一个词wi, 其λ w值的计算过程可以描述为: 从微博数据集中随机地选取一部分文本, 将这部分文本发表的日期分为T个时间段, 一个时间段可以被定义为一天(T≥ 15), 也可以被定义为其他值, 计算词wi在每个时间段t中出现的频数ft(wi)。假设第t个时间段中包含m个微博文本, 每个微博文本包含词wi的频数是f(wi, dj), 则ft(wi)可以被定义为: 

公式(1)是在朱颖[11]提出公式的基础上进行的修改, 其中 

考虑到电商微博文本的稀疏性, 假设在一个文本中, 存在两个或两个以上的词, 其λ w值等于1, 那么令λ d; 否则, λ d=0。根据λ w、λ d的值, 可以确定λ 取值, 即λ =λ w • λ d, 只有当λ w和λ d的值都为1时, λ 值才为1, 这样处理的原因是为了更加有效地挖掘热点话题。
在模型建立完成以后, 需要对ET-LDA模型中的潜在变量进行求解, 本文采用Gibbs抽样方法。在词语t的λ 值等于1时, 词语t将从热点主题中生成, 其主题分布概率如下:

其中, 




在得到热点话题的参数矩阵之后, 选择每个主题下概率值排最前面的词组成话题。判断词是否来自于标签, 如果来自于标签, 则在其出现的次数上加Ntag (Ntag为所有热点词在微博文本集中出现的平均数), 从而提出改进后的变量取值公式如下:

这样所有标签词在主题中的概率增加, 排序也将增加, 而且标签词更容易让人理解, 对热点词也相对比较重要。
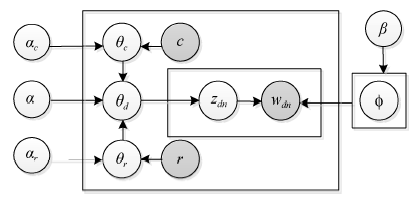
对于隐式话题的电商微博, 本文从微博类型出发, 对三种类型的微博进行整合建模, 形成一种适合于主题挖掘的模型— — IT-LDA(Implicit Topic-LDA)模型, 其贝叶斯网络图如图4所示:
 | 图4 面向隐式话题的IT-LDA模型的贝叶斯网络图 |
在IT-LDA模型关联的微博文本, 如果首先出现的是“ @……” 则认定为对话式微博, 从以t1为参数的伯努利分布中抽取二值变量c, 决定从参数为α c的Dirichlet分布中抽取对话式微博中的主题分布θ c, 赋值给θ d, 微博与主题间关系应该由θ c决定, 从而给出θ 的概率分布如下:
P(θ |α , α c, c)=P(θ c|α c)cP(θ d|α )1-c (8)
同理, 如果首次出现的是“ //@……” 则认定为转发式微博, 从以t2为参数的伯努利分布中抽取二值变量r决定从参数为α r的Dirichlet分布中抽取对话式微博中的主题分布θ r, 并赋值给θ d, 微博与主题间关系应该由θ r决定。若c=0且r=0, 表示这是广播式微博, 直接从参数为α 的Dirichlet分布中抽取出该微博d与各个主题之间的关系θ d。类似于对话式微博, 给出转发式微博对应θ 的概率分布如下:
P(θ |α , α r, r)=P(θ r|α r)rP(θ d|α )1-r (9)
对于隐式话题微博, 所有单词与其所属主题的联合概率分布可以表示为:
P(w, z|α , β , θ )=P(θ |α )P(z|θ )P(w|z, β )=P(θ |α , α c, c)cP(θ |α , α r, r)rP(z|θ )P(w|z, β ) (10)
对面向隐式话题的IT-LDA模型, 同样采用Gibbs抽样的方法对模型进行求解。通过条件概率, 抽样出词i最新的主题, 可以推导得到:

其中, 

根据多项式分布, 可以估计θ d和Φ z的结果为:


同样, 通过抽样分别得到对话式和转发式微博文本的主题分布θ c和θ r:

根据参数值就能求出每条微博关于各个主题的概率分布以及主题关于每个词语的概率分布, 对整个微博集进行分析, 根据概率值可以识别出每条微博最可能属于哪个主题、每个主题最具代表性的词语。
本文利用数据堂[17, 18]和新浪API提供的数据, 通过人工收集与整理, 得到新浪微博上粉丝数和影响力均较大的几家电商企业在2013年11月30日至2015年1月10日之间发布的微博作为实验数据集, 收集到的微博数据集共涵盖40多家电商企业, 共89 847条微博。微博数据存储于事务数据库中, 每条微博对应一条事务或者一个元组, 并对每个元组进行编码, 将其作为主属性。另外, 收集到的微博信息包括微博账号、微博文本、哈希标签、日期时间、转发数、评论数、点赞数、收藏数等, 这些信息作为元组的属性集合。
选用中国科学院计算技术研究所中文分词工具ICTCLAS①( ①http://ictclas.nlpir.org/.), 对每个元组的微博文本属性进行预处理, 即对微博文本语料进行分词、词性标注和去除停用词处理。同时还要抽取标签, 即微博中“ #……#” 之间的内容, 并且根据是否存在标签对微博进行分类, 将含有哈希标签的微博归入“ Explicit Topic Database” 数据库中, 给每个元组增加一个“ 标签信息” 属性, 即将经过文本预处理后的标签内容放入此属性中。对于不含哈希标签的微博归入“ Implicit Topic Database” 数据库中, 给每个元组增加一个“ 微博类型” 属性, 在文本预处理阶段, 扫描每个元组的微博文本属性, 若首次遇到“ @” 符号, 则此元组的“ 微博类型” 属性值为1, 表示对话式微博; 若首次遇到“ //@” 符号, 则此元组的“ 微博类型” 属性值为2, 表示转发式微博; 否则为0, 表示广播式微博。
实验前需要确定模型参数和主题个数, 根据文献[19]的研究, 对于ET-LDA模型, 取经验值α =50/K, β =0.01, 对于IT-LDA模型, 取经验值α =50/K, α c=α r=1, β =0.01, 其中K为主题个数。由于主题个数影响EM-LDA综合模型对微博文本集的拟合性能, 因此需要确定主题个数的最佳值。本文采用目前常用的评价标准“ 困惑度(Perplexity)” 确定最佳主题个数, 困惑度是从模型泛化能力衡量LDA模型对于文本的预测能力, 通常情况下, 困惑度越小, 说明模型的泛化能力越强, 模型的推广性也就越好[20]。计算公式如下:

其中, M为文档个数, Ni为文档di的长度, P(di)表示模型产生文档di的概率。
为了确定最佳主题个数, 令K取不同的值, 在各种不同的值下运行Gibbs抽样, 分析困惑度的变化, 实验结果如图5和图6所示:
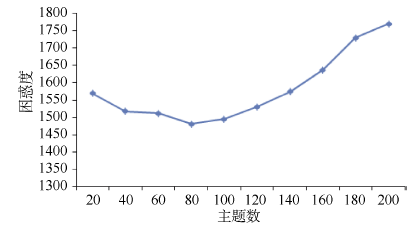 | 图5 ET-LDA模型不同主题数下的困惑度 |
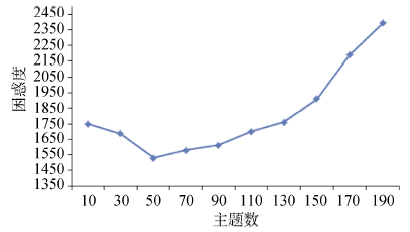 | 图6 IT-LDA模型不同主题数下的困惑度 |
从图5可以看出, 对于ET-LDA模型, 当主题数 K选择80时, ET-LDA模型的困惑度最低, 这时模型的性能最好; 从图6可以看出, 对于IT-LDA模型, 当主题数K设置为50时, IT-LDA模型的困惑度最低, 所以将ET-LDA模型的主题数设置为80, 将IT-LDA模型的主题数设置为50。
实验选择R语言实现EM-LDA综合模型的任务, R语言提供了很多用于文本挖掘的程序包, 如tm包、XML包、Rwordseg包, 对于LDA模型还有专门的LDA程序包。利用LDA模型直接对存储于事务数据库中的电商微博进行主题挖掘, 得到LDA模型运行结果, 经过处理后的结果如图7所示; 其次利用R语言编程实现事先建立好的ET-LDA模型和IT-LDA模型, 并分别将“ Explicit Topic Database” 数据库和“ Implicit Topic Database” 数据库关联到R语言程序中, 根据上面的工作, 规定两个模型的各参数值, 运行程序得到EM-LDA综合模型的部分主题分布如图8所示:
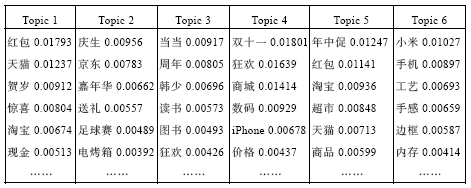 | 图7 标准LDA模型的主题分布 |
 | 图8 EM-LDA综合模型的主题分布 |
图7和图8均显示了两个模型各自主题上的热词, 并按照热词间的概率降序排列。可以看出, EM-LDA综合模型的热词挖掘准确率高于标准LDA模型, 且EM-LDA综合模型挖掘出的热点词均是数据集中的热点词, 而LDA模型挖掘出的结果并非都是热点词, 所以EM-LDA综合模型可以更加准确且有效地挖掘各个主题下的热点词。
本文提出的EM-LDA综合模型是对标准LDA模型的扩展, 主要结论包括:
(1) 对于电商微博文本数据, 根据其是否含有哈希标签进行分类处理, 区别于标准LDA模型直接应用到原始数据的弊端, 根据数据特征分别建立适合主题挖掘的模型。
(2) 将日期特征引入LDA模型, 从而建立面向显式话题微博的ET-LDA模型, 其可以有效且准确地挖掘出显式话题微博中的热点话题, 提高挖掘出的热点话题的可解释性。
(3) IT-LDA模型充分考虑了电商微博中的结构化和非结构化信息, 结合转发式微博和对话式微博特点整合建模, 主题挖掘结果比LDA模型更准确。
由于需要对电商微博文本数据进行分类处理, 所以需要预先进行人工干预, 在整个主题挖掘时效性上要低于标准LDA模型; ET-LDA模型没有考虑到用户特征, 只将日期特征引入模型中; IT-LDA模型没有考虑如何处理那些既是转发式又是对话式的微博。在后期的研究中, 可以将用户特征、标签信息等作为变量引入ET-LDA模型中, 同时更加深入地细分微博类型, 综合考虑多种类型的微博, 并建立一个综合的适合主题挖掘的模型, 以提高结果的可解释性和挖掘结果的准确率。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|