

{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于模板用户信息搜索行为和统计分析的共谋销量欺诈识别
[王忠群 , 乐元, 修宇, 皇苏斌, 汪千松]
, 乐元, 修宇, 皇苏斌, 汪千松]
, 乐元, 修宇, 皇苏斌, 汪千松]
|
|


目的 针对电子商务推广中出现的共谋虚增销量的欺诈问题, 提出一种基于模板用户信息搜索行为和统计分析的共谋销量识别方法。方法 为了刻画用户在C2C网站购物时的信息搜索行为, 提出一种带关键字的用户信息搜索行为模型以及信息搜索行为的相似度计算方法; 依据共谋用户信息搜索行为的相似性, 提出一种基于层次聚类的欺诈嫌疑挖掘算法; 给出基于统计分析的欺诈识别方法从欺诈嫌疑中识别共谋买家, 以实现对卖家销售记录中虚增销量的识别。结果 在改进的数据集上验证该方法的召回率和准确率分别为88.6%和90.1%。【局限】不能动态调整用于识别欺诈嫌疑行为是否为“刷单”的阈值。结论 该方法可有效识别基于模板用户信息搜索行为的共谋虚增销量。
[Objective] Aiming at collusive sales inflation fraud in e-commerce promotion, this paper presents a collusive product sales fraud detection method based on users’ information search behavior. [Methods] Firstly, in order to describe users’ information search behavior in online shopping, a model for user information search behavior with keywords and a similarity calculating method for users’ information search behavior are proposed. Secondly, a suspicious fraud mining algorithm based on hierarchical clustering algorithm for inflation sales is proposed, which depends on the similarity between users’ information search behavior. Finally, this paper proposes a method for detecting suspicious fraud based on statistical analysis, to identify inflating sales in sale record of illegal vendors. [Results] The experimental results show that the recall and precision of the method are 88.6% and 90.1% respectively based on the improved data set. [Limitations] The threshold value predetermined for judging whether the fraudulent behavior is “scalping” behavior is fixed. [Conclusions] The method is effective for the detection of collusive sales inflation fraud based on users’ information search behavior template.
近年来, 我国电子商务C2C(Consumer to Consumer)市场发展迅速, 网络购物群体持续增大, 但市场存在诸如虚增商品销量、虚增信誉等不法行为[1]。商品销量如同卖家信用、商品评论和商品价格等信息一样, 是顾客网购决策的重要信息源, 对消费者购买决策有着很大的影响力。与传统购物方式相比, 电商交易平台因易于发布电商企业的销量, 使得消费者和电商企业能够更加便捷地了解商品的销量和销量的排名“ 榜单” 。为此, 电商企业或者网店设法通过多种渠道和方法(如利用诸如威客-猪八戒网等网店推广服务平台[2])提高或虚增其商品销量。为保障电子商务市场的健康发展, 如何识别诸如虚假信用、评论和销量等欺诈行为已引起业界和学术界的广泛重视[3, 4, 5, 6, 7, 8], 对其研究也提出了挑战。
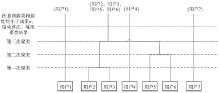
在C2C平台中, 用户一般通过首页商品分类导航、关键字搜索引擎、店铺URL三种方式进入商品列表挑选商品。一家新上线或者信誉值较低的C2C网店在商品列表中的排名不具有优势, 使得利用商品分类导航方式的用户难以找到该卖家的店铺。对此, 把网店推广作为其服务内容之一的服务平台, 如威客-猪八戒网等, 应运而生, 如图1和图2所示[2], 其分别为猪八戒网上某商家所发布的刷单需求和其中某一任务的具体要求。
网店发布的推广业务, 本质上是一种共谋虚增网店商品销量的行为, 目的是实现所推广网店的商品或者网店在商品销量列表中具有排名优势。重要的是, 它给潜在顾客提供了虚假的购买决策信息, 危害电商市场的健康发展。如果不法卖家让“ 刷单” 者直接通过店铺URL进入店铺并进行多笔虚假交易, 则存在易于被C2C交易平台监管查封的风险。因此, 更多情况下不法卖家采取让“ 刷单” 共谋者运用关键字搜索的方式进入店铺, 再进行交易的策略, 即规定明确的搜索— 浏览— 购买流程, 包括搜索的关键字、浏览的页面序列、停留时间等, 如图2所示, 以便让共谋“ 刷单” 者能够快捷、准确地找到所需“ 刷单” 的商品。
 | 图1 推广平台中推广需求 |
 | 图2 推广需求的任务描述 |
对于共谋欺诈识别的研究, 目前已有了一些工作。文献[9]认为共谋是指一组成员为了谋取非合作就无法获得的正当利益而协同采取的行动, 并研究了国内一个大型P2P文档共享社区Maze系统中的共谋骗取积分的行为。文献[10]提出用一种新的迭代评价算法来识别机动车保险中的共谋骗保行为。在C2C市场中, 针对共谋和欺诈问题的研究主要集中于信誉欺诈或信用虚增、拍卖Shill投标欺诈等主要欺诈的识别模型和方法。文献[11]提出基于交易历史的社会网络分析并用于构建信誉欺诈识别指标体系, 通过使用LVQ神经网络对采集数据进行分类, 从而达到有效识别信誉欺诈账户的目的。文献[12]提出基于交易记录形成的社交网络关系来进行共谋欺诈的识别。文献[13]借鉴SNA, 提出用K-Core和Core/Periphery比例作为交易网络结构度量指标区别正常和虚增信誉账户。文献[14]提出一个移动APP排名欺诈的整体视图(Holistic View), 以及一种融合排名、评价和评论证据的移动APP领域的下载量排名欺诈检测系统。上述文献主要从买卖双方账户特征和交易特征等方面研究信誉欺诈和信用虚增的问题。就笔者所知, 目前对商品销量虚增或者“ 刷单” 的欺诈识别研究比较少。
事实上, 信息搜索行为是用户获得网购决策信息的重要途径, 其表现为用户与网站的交互行为。基于时间成本及理性“ 经济人” 理论, 不同于“ 刷单” 者, 真实的购买用户更愿意付出较大的搜索成本进行信息搜索。因此, 信息搜索行为是区分“ 刷单” 用户和真实用户的重要特征之一。针对电商推广中出现的共谋虚增商品销量的欺诈问题, 本文从用户在C2C平台上的网购信息搜索行为出发, 建立一种基于指令模板的信息搜索行为模型; 并依据共谋群体具有相似的信息搜索行为, 提出一种基于用户信息搜索行为模板相似度聚类的欺诈嫌疑挖掘算法; 再给出基于统计分析的欺诈判别规则从欺诈嫌疑中识别共谋买家, 以实现对卖家销售记录中虚假销量的识别, 并在改进的数据集上对识别虚增销量的方法进行验证。
对于Web用户浏览行为及其相似度的计算方法, 已经有相关文献对其进行了研究。考虑用户对站点访问路径的兴趣, 文献[15]提出了一种K-paths路径聚类方法, 用于聚类用户访问的Web站点的路径。文献[16]用一种结合新的路径相似度系数与雅可比相似度系数的方法计算用户访问行为的相似度。文献[17]在计算相似度时把浏览模式作为一种序列模式来考虑, 同时加入用户浏览的时间因素。
上述文献将用户浏览行为定义为用户对网站的页面节点访问, 而较少考虑用户网购信息搜寻的特征(如使用关键字进行商品检索)。在C2C平台中, 用户一般通过网站首页的商品分类导航、关键字搜索引擎、店铺URL三种方式进入商品列表挑选商品。再者, 不法卖家在发布刷单需求任务时对商品浏览时间、收藏商品以及对应店铺有特定的要求。对此, 为了刻画用户网购商品时的决策信息搜索行为, 本文依据用户网页搜索浏览的特征, 选择用户在网页的停留时间、对商品的收藏和对店铺的收藏这三个用户浏览行为的特征值作为用户网购信息搜索行为模型的要素, 同时增加对用户在进行网购信息搜索时所使用关键字的考虑。下面给出用户浏览行为节点、信息搜索行为的定义和用户信息搜索行为模型。
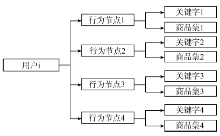
定义1 用户i的行为节点Vin={Cwin, Cpin}。其中Cwin为用户i进行第n次搜索商品时的关键字, Cpin为用户i通过关键字Cwin搜索后所点击浏览的商品集合, Cpin={(item1, P1), … (item2, P2), (itemk, Pk)}, 其中itemj为第j个商品的标识符, Pj为浏览第j个商品行为的特征值集合。
定义2 用户i的信息搜索行为Ui={Vi1, Vi2, …, Vin}。其中Vin为用户i搜索商品行为序列中的第n个节点。
针对用户带关键字的商品信息搜索过程, 本文提出一种用户商品信息搜索行为模型, 如图3所示。其中, 用户i信息搜索行为由若干信息搜索行为节点构成, 每个行为节点包括搜索关键字和对应浏览的商品集。
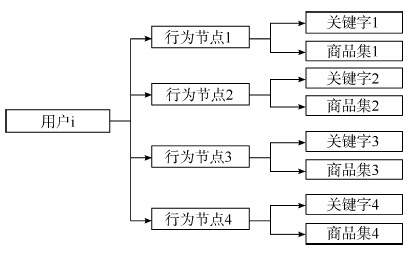 | 图3 用户信息搜索行为模型 |
图3构建了用户网购商品时的决策信息搜索行为模型。时间成本及理性“ 经济人” 理论说明, 非法“ 刷单” 者与真实购买用户在信息搜索的成本方面存在较大差异。因此, 用户信息搜索行为为识别“ 刷单” 用户和真实用户提供了潜能。
在用户信息搜索行为模型中, 其行为是否相似取决于搜索关键字和用户浏览商品集的相似程度。下面讨论用户商品信息搜索行为相似度的计算。
(1) 关键字相似度计算
关键字相似度的计算是通过计算两个关键字字符串的编辑距离(Edit Distance)后进行归一化处理得到的。编辑距离又称Levenshtein距离, 是指两个字串之间, 由一个变换成另一个所需的最少编辑操作次数。其中, 编辑操作包括将一个字符替换成另一个字符、插入一个字符、删除一个字符等三种操作。
依据通过编辑距离计算两字符串相似度公式提出用户i的搜索行为节点Vin的关键字Cwin和用户j的搜索行为节点Vjm的关键字Cwjm的相似度计算公式如下:
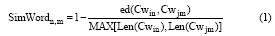
其中, Len(Cwin), Len(Cwjm)分别为字符串Cwin, Cwjm的长度, ed(Cwin, Cwjm)为Cwin, Cwjm的编辑距离。
编辑距离通过动态规划算法求得, 算法如下:
已知字符串Cwin, Cwjm的长度Len(Cwin)=p, Len(Cwjm)=q, 定义矩阵D:
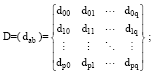
其中, dab为矩阵D中元素, 通过如下步骤对每个元素dab进行赋值。对D中所有元素赋值完成后取dpq的值为两字符串的编辑距离。赋值过程如下:
赋值第1列和第1行
da0← a, d0b← b
对剩下的每个dij按如下进行赋值:
if Cwin[a]=Cwjm[b] then dab=da-1, b-1
if Cwin[a] ≠ Cpjm[b] then
dab=min(da-1, b+1, da, b-1+1, da-1, b-1+1)
取最后一行最后一列元素dpb的值为两字符串的编辑距离, 即:
Ed(Cwin, Cwjm)=dpq
根据公式(1)求得关键字Cwin和关键字Cwjm的相似度SimWordn, m。
(2) 基于浏览行为的商品集相似度计算
已知用户i的第n个节点由k个页面构成的商品集Cpin={(item1, p1), …, (itemk, pk)}, 其中itemr(r∈ [1, 2, …, k])为用户浏览的第r个商品的ID, Pr(r∈ [1, 2, …, k])为用户浏览第r个商品行为的特征值集合, 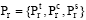
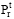
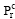
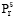
另设用户j第m个节点由l个不同商品构成的商品集为 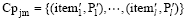
1建用户i和用户j浏览的总商品集X
设集合 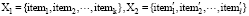
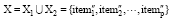
2据用户i的浏览序列给X赋值, 即 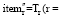
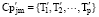

商品集Cpin和Cpjm的相似度通过计算其对应的浏览向量的余弦相似度得到, 考虑到|Cp’ in|和|Cp’ jm|的值可能为0的情况, 提出商品集Cpin和Cpjm在某一特征下的相似度计算公式如下:
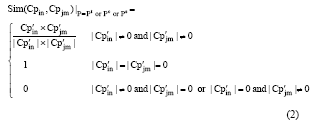
则商品集Cpin和Cpjm多个特征的相似度加权相加后的总相似度计算公式如下:
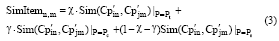
其中, SimItemn, m为用户i第n次搜索和用户j第m次搜索时点击浏览的商品集总的相似度, x、γ 、(1-x-γ )分别对应浏览时间特征相似度、收藏商品特征相似度、收藏店铺特征相似度的权重值。基于信息经济学原理, 用户的时间投入成本是不法者实施“ 刷单” 时首要考虑因素, 其权重一般要高于其他两个特征的权重。
(3) 用户信息搜寻行为相似度计算
①节点相似度
用户i的搜索行为的节点Vin和用户j的搜索行为节点Vjm的相似度加权相加后的相似度计算公式如下:
Simn, m=α • SimWordn, m+β • SimItemn, m α +β =1 (4)
其中, Simn, m为用户i第n次搜索和用户j第m次搜索的行为节点的总相似度, α 、β 分别为对应节点的关键字相似度SimWordn, m和商品集相似度SimItemn, m的权重值。搜索关键字是“ 刷单” 商品能否被搜索行为检索的决定因素, 因此其权重要大于对页面相似度的权重, 即α 要大于β 。
②搜索行为相似度
用户i包含n个节点的搜索行为Vi和用户j包含m个节点的搜索行为Vj的相似度Sim(Vi, Vj), 其大小为所有节点相似度的最大值, 因为用户i和用户j如同时参与某个发布的信息搜索模板的需求任务而进行网页搜索, 则两者按照该模板任务进行搜索行为所对应的节点的相似度应该最高。据此, 提出两个用户间信息搜寻行为相似度的计算公式如下:
Sim(Vi, Vj)=max(Simr, s) r∈ [1, 2, …, n] s∈ [1, 2, …, m] (5)
基于模板的用户信息搜索行为具有较高的相似性。对此, 提出通过聚类算法挖掘出具有较高相似度的信息搜索行为, 发现嫌疑共谋买家。根据数据在聚类中的积聚规则以及应用这些规则的方法, 存在多种聚类算法。聚类算法大致分为层次化聚类算法、划分式聚类算法、基于密度和网格的聚类算法和其他聚类算法[18]。
针对信息搜索行为模型(簇点对应着信息搜索行为样本), 通过聚类算法将买家搜索行为样本根据模型的相似度划分为不同的簇类。若簇点数量较多的簇类, 则该簇类中的样本间存在基于模板的共谋, 具有共谋欺诈嫌疑。如果簇类只有一个簇点(称为单点簇), 则该簇点的样本行为不具有共谋欺诈的嫌疑。
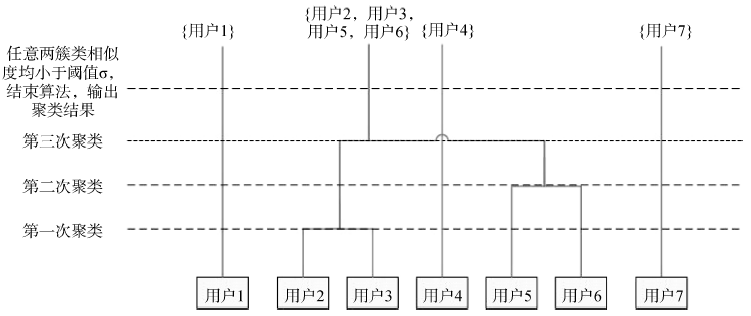
设有用户搜索行为集{U1, U2, U3, U4, U5, U6, U7}, 对应用户1至用户7的搜索行为, 则有如图4所示的聚类过程。
基于上述聚类过程, 提出一种改进的层次化聚类算法, 算法中的相似度计算采用第3节介绍的方法, 并引入阈值σ , 其值大小决定所比较的用户行为的相似程度。不同于其他聚类算法, 如K-means聚类算法, 在聚类前要设定聚类的簇类个数, 层次聚类算法将阈值σ 作为聚类的终止条件使聚类得到簇类的个数是不确定的。考虑到不法卖家为了避免被C2C平台监管发现欺诈而查封的风险, 要求共谋“ 刷单” 者的信息搜索行为略微差异与所发布的搜索行为模板, 故阈值σ 不妨设定为适当的值(如0.80)。设用户搜索行为集U={U1, U2, …, Uk}, 算法步骤如下:
2将每个用户搜索行为Ui置为一个簇类;
②计算任意两个簇类间相似度, 已知Up, Uq∈ U且Up≠ Uq, 则 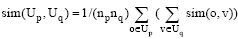
3找出相似度最大的两个簇类Ur、Us
若sim(Ur, Us)> σ , 则将Ur和Us合并为一个新的簇类Urs并返回步骤②, 否则结束本算法, 输出聚类结果。
正常买家不具有共谋关系, 信息搜索行为相似性大的可能性较小。在依据任务模板“ 刷销量” 的情况下, 若商品销量中存在大量共谋虚增, 则买家信息搜索行为聚类后共谋欺诈的用户信息搜索行为样本将构成聚类结果中簇点最多的最大簇。但是, 若商品销量为正常销量或仅存在少量共谋虚增, 则买家信息搜索行为聚类结果中的最大簇仅属于正常销量中偶然具有相似信息搜索行为的非共谋买家。具体为哪种情况, 需进一步甄别。事实上, 通过对网购共谋“ 刷单” 行为的分析, 商品的“ 刷单” 行为一般存在以下特征:
(1) 从时间上讲, “ 刷单” 行为发生一般比较集中, 呈现突发性[13]。发布“ 刷单” 信息的服务网站一般以一段时间作为发布任务的有效期, 如猪八戒网发布的网店推广的任务需求有效期为10天。因此“ 刷单” 行为一般集中在任务有效时间内。
(2) 对于存在大量共谋虚增的商品销量, 相似的共谋买家的欺诈行为样本数量要远远大于正常用户因为偶然性而具有相似信息搜索行为的样本数量。
依据上述共谋“ 刷单” 交易的特征, 并结合卖家销售记录中交易次数, 本文给出以下基于统计分析的共谋“ 刷单” 欺诈的识别方法(表达抽象为簇点的信息搜索行为样本对应着顾客交易账户):
(1) 交易集中度。设最大簇的簇点数为n, , 其发生的日期为te(e∈ [1, n]), “ 刷单” 任务的有效期为η (如猪八戒网η =10), 将该日期向后推η 天的时间窗口[te, te+η ]内包含的簇点数为Ne。Ne的最大值为Nmax, 即最多的信息搜索行为发生在时间窗口[tmax, tmax+η ]中, 通过计算该时间窗口内的交易次数和簇类中包含的总交易次数的比值描述行为样本集中在该时间窗口内的程度, 比值越大, 最大簇表达的购买交易的集中程度越高, 该簇类中的嫌疑行为是“ 刷单” 的可能性越大。依据上述原理, 提出如下“ 刷单” 的可能性的计算公式:

(2) 交易平均次数偏离度。设聚类结果中的簇类数为m, 每个簇类中信息搜索行为样本的个数为Nv(v∈ [1, m]), 最大簇包含的样本个数为Nmax, 计算最大簇包含的行为样本个数与其他簇类包含的样本数的相对平均偏差, 偏差越大, 最大簇表达的购买交易次数偏离平均交易次数较大, 说明最大簇类中的嫌疑行为是“ 刷单” 的可能性越大。依据上述原理, 提出如下“ 刷单” 的可能性的计算公式:
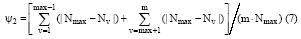
进一步, 提出通过如下公式将Ψ 1和Ψ 2整合:
Ψ =λ • Ψ 1+μ • Ψ 2 (8)
其中, λ +μ =1, λ 和μ 是对应公式(6)和公式(7)计算出的嫌疑值Ψ 1和Ψ 2的权重, Ψ 为对交易集中度和交易平均次数偏离度加权后相加得到的欺诈嫌疑值。考虑到交易集中度和交易平均次数偏离度均是反映共谋“ 刷单” 者聚类特征的重要方面, 所以不妨设它们对应的权重相等, 即λ =μ =0.5。另外, 存在欺诈行为样本的最大簇中亦可能存在部分正常用户的行为样本, Ψ 反映最大簇类中的嫌疑行为是“ 刷单” 行为的可能性, 故不妨设定适当的嫌疑判别阈值, 如Ψ =0.8。
目前, 公开、可用的C2C平台的用户浏览行为数据较少, 且尚未发现同时具有用户在C2C网站购物时的关键字搜索和点击行为的数据集。淘宝的天池数据平台[19]公布了部分用户4个月内的行为日志, 用于预测用户未来一个月的购买行为。该数据集包含562件商品信息(主要为服装, 包括商品ID、商品标题、商品类别、品牌ID、买家ID等)、4 844条用户行为(包括用户ID、商品ID、行为类别和时间)和2 712条用户评价(包括用户ID、评价商品ID、评价时间等)。其中的用户行为数据包含用户购物时的点击、收藏和购买行为, 但是, 缺少用户点击、浏览商品之前进行关键字搜索的数据。为此, 基于此数据集依据用户浏览的商品标题近似生成用户搜索关键字, 以构建满足本文验证需要的合成数据集。
C2C网站一般根据用户的搜索关键字, 返回与商品标题最匹配的商品作为搜索结果供用户浏览、挑选。一次搜索后用户浏览点击的商品为同类且标题较为相似的商品。依据以上两点, 对数据集中所有商品标题做如下处理: 首先, 利用中国科学院计算技术研究所的分词系统[20]对数据集中所有商品标题逐一分词, 构成商品标题词库; 删除词库中词频小于15次的词及商品标题中出现较多但用户搜索时较少用到的词, 如“ 2014” 、“ 潮” ; 将由于分词系统缺陷而使完整词汇分开的词重新整合, 如“ 打” 、“ 底” 、“ 衫” 、“ 显” 、“ 瘦” ; 人工将处理后的词库中的词分为商品类别词(如“ 休闲裤” 、“ 衬衣” )和商品描述词(如“ 纯棉” 、“ 高领” )两类, 分类后的部分词汇如表1所示:
| 表1 商品标题词分类结果 |
进一步, 依据分类后的商品标题词库按照如下步骤自动将每个用户的点击行为划分为若干次搜索。
(1) 根据商品类别词将用户一次购买的点击记录划分为若干次搜索, 若该用户连续点击的几个商品的标题存在一个或多个相同的商品类别词, 则将这几次点击记录归为一次搜索;
(2) 提取用户连续点击的存在相同类别词的商品标题中出现的所有商品描述词;
(3) 随机取1个共同包含的商品类别词和1-3个随机提取的商品描述词作为此次搜索关键字。
表2为用户2724于2014年9月5日购买商品的点击行为, 按上述方法进行划分, 并生成搜索关键字。
| 表2 用户2724的部分点击行为 |
如表2所示, 用户2724的行为1- 行为3所点击的商品221、446、121均包含商品类别词“ 小脚裤” , 故自动归为一次搜索。这三个商品标题中出现的商品描述词有“ 大码” 、“ 小脚” 、“ 休闲” 、 “ 新款” 、“ 女裤” 、“ 秋冬” 、“ 弹力” 、“ 黑色” 、“ 女士” 、“ 牛仔” 、“ 白色” 。随机取1-3个商品描述词(取1个商品描述词“ 黑色” )和1个商品类别词(三个商品共同包含的商品类别词只有一个“ 小脚裤” )构成此次搜索关键字“ 黑色小脚裤” 。同理, 将点击行为4和行为5划分为1次搜索, 点击行为6和行为7各为一次搜索。最终划分后的结果如表3所示:
| 表3 用户2724的搜索关键字的生成结果 |
本文采用的数据集为交易平台发布的用于产品推荐的数据集。为了能准确地从用户的点击行为中反映出用户的兴趣从而精确地实现推荐, 数据集中存在虚假的欺诈行为数据的可能性较小, 故将数据集中的用户行为均视为正常数据。依据“ 托” 攻击和网络攻击验证的常规方式, 在正常数据集中灌注“ 刷单” (“ 刷单” 可以看做是一种攻击)数据形成验证数据集, 以此验证对“ 刷单” 欺诈的检测性能[6]。选择猪八戒网上发布的三个任务需求(见表4)作为模板分别构建100条行为数据作为欺诈行为灌注到新合成的数据集中, 构成三个不同数据集: 数据集A、数据集B、数据集C。灌注“ 刷单” 数据的步骤如下:
(1) 按照任务模板规定的关键字在购物平台进行搜索;
(2) 在搜索返回结果中找到指定商品, 停留浏览5分钟左右, 并随机浏览其他商品3分钟左右, 记录下每次点击的时间和点击的商品地址;
(3) 将点击行为数据添加到行为表中, 将点击的商品信息添加到商品信息表中。
将三个数据集随机分为80%的训练集和20%的测试集, 通过实验挖掘出训练集中灌注的基于任务模板的欺诈行为数据。对训练集数据按本文方法进行建模、聚类, 得到聚类结果, 找出“ 刷单” 欺诈嫌疑聚类; 依据第5节中基于统计分析的“ 刷单” 欺诈识别方法来识别“ 刷单” 账户; 逐一计算测试集中数据与所找出模板的相似度, 若其与模板的相似度小于80%, 则该用户的行为不为基于模板的共谋欺诈行为; 若相似度大于80%, 则其行为属于基于该模板的共谋欺诈行为。
| 表4 猪八戒网发布的任务需求 |
(1) 参数设定
依据信息经济学原理, 对信息搜索行为中的关键字、客户在页面浏览中所停留时间的分析, 为公式(3)、公式(4), 以及行为聚类相似度阈值设置如下:
公式(3)中的参数x=0.4, γ =0.3; 公式(4)中参数α =0.6, β =0.4; 聚类算法中的阈值σ =0.8, 嫌疑欺诈识别中的嫌疑判别阈值为0.8。
(2) 实验结果获取
实验结果获取有以下4步骤:
①通过对数据集A的训练数据集中的数据样本按照公式(5)相似度计算方法和第4节聚类算法进行聚类后得到的最大簇类有103个簇点, 远大于聚类得到的其他簇类。
②依据“ 刷单” 欺诈嫌疑识别方法的公式(6)和公式(7)分别计算出最大簇的交易集中度Ψ 1=90.2%, 交易平均次数偏离度Ψ 2=89.2%。
4过公式(8)将Ψ 1和Ψ 2整合后的嫌疑值为89.7%, 大于设定阈值, 为灌注基于模板的信息搜索行为数据构成的簇类。
④使用公式(5)逐一计算测试集中数据与该簇的相似度作为该行为样本的欺诈嫌疑。
实验所获取的部分测试数据如表5所示:
| 表5 部分测试集数据的实验结果 |
(3) 实验结果分析
为了规避被交易平台监管查封的风险, 不法商家往往会要求刷单者不完全按照模板制定的关键字进行搜索。因此在按照模板构建买家u643的行为数据灌注到数据集中时, 没有完全按照模板进行关键字搜索, 但最终算法求得与对应模板簇类的相似度达到87.1%, 识别出其为基于模板的共谋欺诈行为。买家u3336进行第一次搜索时的关键字和模板定义的关键字相似度达到0.71, 但浏览每个商品的时间均为1分钟左右且没有收藏操作, 而任务模板要求用户双收藏。计算其与对应模板的簇类的相似度为52.3%, 将其作为该用户搜索行为的欺诈嫌疑值, 仍小于设定的阈值, 故不为共谋欺诈行为。
通过召回率(Recall)和准确率(Precision)评价识别效果。召回率和准确率的计算方法如下:

实验在聚类算法的阈值取σ =0.8。调整公式(3)、公式(4)中参数为不同值时算法的召回率、准确率如表6所示:
| 表6 不同参数下算法的召回率和准确率 |
从表6可以看出参数分别取x=0.4, γ =0.3和α =0.6, β =0.4时方法的召回率和准确率最高, 分别达到88.6%和90.1%, 证明了本文方法的有效性。
进一步, 在数据集B和数据集C上对本文方法进行验证得到的准确率和召回率如表7所示:
| 表7 不同数据集下本文算法的召回率和准确率比较 |
从表7可以看出, 在灌注基于不同任务模板的欺诈数据的数据集上, 本文方法均具有较高的识别率。
不法商家为在短时间内提高店铺销量以获得更多消费者关注, 或给消费者提供错误的网购决策认知信息, 利用第三方服务平台发布任务需求寻求“ 刷单” 进行网店推广。本文将这种按照特定模板化的任务需求进行电商网络推广视为一种共谋欺诈行为, 提出一种带关键字的用户信息搜索行为模型来刻画描述用户在C2C平台上购物时的搜索行为, 以及一种基于行为相似度的欺诈嫌疑聚类挖掘算法; 给出基于统计分析的欺诈识别方法从欺诈嫌疑中识别共谋买家, 实现对卖家销售记录中虚假销量的识别。并在中国某C2C交易平台公布的用户行为数据集的基础上, 依据用户点击的商品标题近似生成搜索关键字的方法以构造合成的数据集进行验证测试。测试结果表明本文方法可有效识别基于模板的共谋虚增商品销量。本文的不足之处在于, 实验所采用的数据集数据量尚不够大, 以及不能够自动调节用以识别欺诈嫌疑行为是“ 刷单” 欺诈的判别阈值。未来将结合社交网络来进一步研究识别电商中虚增商品销量问题。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|