
{kind=link}
{kind=link}
{kind=link}
{kind=link}
多媒体微博评论信息的主题发现算法研究
[叶川, 马静 ]
]
]
|
|


目的 发现微博中图片或视频等多媒体内容的主题特征。【应用背景】多媒体微博的文本内容普遍简短且主题通常蕴含在图片或视频等多媒体内容中, 传统的文本挖掘方法不适用于这种多媒体类微博。方法 通过热点评论扩充该多媒体微博的文本空间, 并使用LDA主题模型进行分类推断与主题特征挖掘, 使用“主题标签-特征词”的形式表达微博多媒体内容的主题特征。结果 使用爬虫工具采集的99 823条新浪微博构建训练集, 151条热门多媒体微博及其所有评论构建测试集进行实验, 构建的分类目录中标签完善, 主题标签推断准确率达到88.6%, 相关特征词挖掘准确率为76.0%。结论 实验结果表明本文的算法可以有效且显著地发现多媒体微博的主题特征。
[Objective] This paper is aiming at discovering the topic of multimedia content such as images or videos in microblogs. [Context] The text content of multimedia microblogs is usually brief and the topic of such microblogs generally contains in its multimedia content such as images or videos, so the traditional text mining methods may not be applied to these cases. [Methods] Extend text space of the multimedia microblog through the use of hot comments. Then use LDA topic model to inference the classification and mine the topic features. Finally, express topic features of the multimedia mircoblog in the form of ‘topic tag - feature words’. [Results] Experiments by constructing the training set use 99 823 Sina microblogs collected by crawler tool set, and constructing the test set use 151 hot multimedia microblogs with all those comments. Results show that the classification directory built in this paper is complete, the topic tag infers with 88.6% accuracy, and the relevant feature word mining accuracy is 76.0%. [Conclusions] The experiment results show that the new algorithm can effectively and significantly discover topic features of multimedia microblogs.
微博在互联网生活中有着深刻的影响力。截至2014年12月, 我国微博用户规模达到2.49亿[1], 微博的文本内容简短, 但有丰富的表现形式。一条微博除文本外还可以有图片、音乐、视频与链接等多种媒体信息, 本文将此类微博称为“ 多媒体微博” 。本文采集的10万条热门新浪微博中, 多媒体微博的比例高达89.7%。可见大部分热门微博都是多媒体微博, 这类微博拥有很强的渲染力, 因此多媒体微博的主题发现有着很高的研究价值。
通常情况下, 仅从简短的文本内容中难以了解博主想要表达的主题, 且博主的意图往往体现在图片、视频等多媒体信息中。因此需要仔细观看其多媒体内容才能发现微博的主题。根据现有的研究成果, 当用户试图发现、跟踪图片或视频的主题时, 可以使用谷歌或百度的视觉搜索服务。视觉搜索基于一种被称为卷积神经网络的深度识别技术, 借助卷积神经网络, 搜索引擎就像经过训练的神经一样可以从多角度识别搜索目标[2]。这类技术通过输入多媒体信息, 最终返回与搜索目标主题相关的文本, 用文本描述多媒体内容的主题。这种方法需要一个庞大的训练集的支持, 往往只有搜索引擎界巨头才能获取如此庞大的数据, 因此这种方法的普适性不强。针对上述情形, 本文采用逆向思维提出一种算法, 不分析多媒体信息, 而通过多媒体内容的评论, 试图发现并挖掘多媒体内容的主题特征, 拟通过评论内容描述多媒体内容想表达的主题。使用这种简洁有效的算法, 可以通过评论预先发现微博的主题, 并在此基础上挖掘主题的特征, 从语义层面发现博主发帖传递的思想; 可以帮助读者阅读多媒体内容之前掌握多媒体微博的主题特征, 或帮助微博服务商扩展阅读服务, 提高服务质量。因此, 本文的算法有着重要的研究价值与现实意义。
主题发现的研究可以追溯到话题检测与跟踪(Topic Detection and Tracking, TDT)的话题检测阶段。话题检测阶段的主要任务是检测和组织的话题[3], 通常使用向量空间模型[4](Vector Space Model, VSM)表示词语、文档空间。然而多媒体微博不同于传统媒体, 多媒体微博的正文文本更为简短, 有着严重的数据稀疏问题, 传统的VSM模型表示微博文档空间时, 可能会得到维度极大的稀疏矩阵。因此, 传统的话题检测方法不能直接应用于多媒体微博主题发现。
随着主题模型(Topic Model)的兴起, 越来越多的研究者开始进行主题模型的扩展研究, 试图使用主题模型解决微博文本挖掘的问题。主题模型是描述主题的数学模型, 其中主题(Topic)可以看成是词项的概率分布。使用主题模型对文档的生成过程进行模拟, 再通过参数估计得到各个主题[5]。主题模型通过降维将文档集映射到相对低维的空间中, 理论上能一定程度解决文本稀疏的问题。其中使用最广泛的是Blei等[6]在2003年提出的LDA (Latent Dirichlet Allocation) 模型。LDA模型[7]以贝叶斯理论为基础, 是一种三层贝叶斯层次模型, 它易被扩展成其他形式的概率模型。国内外多位学者对模型进行了扩展, 并应用在短文本的微博研究中。部分学者试图从Twitter用户的发帖兴趣的角度出发, 聚集微博文本[8, 9]; 也有许多学者[10, 11, 12, 13]针对微博特殊的文本结构, 综合考虑微博的信息交互特点, 提出适合于微博主题的改进LDA模型。也有学者将LDA模型应用于网络评论的研究中, 此类研究主要有三种: 垃圾评论发现[14]、评论情感分析[15]与特征挖掘[16]。这些研究都是从评论中获取相关信息, 并没有考虑使用评论来改善简短的正文语义不充足的缺点。
本文借鉴文献[8, 9]中集合一类微博短文本构建长文档的思想, 提出一种基于评论的多媒体微博主题发现算法。使用大量微博文本构建一个多主题的LDA模型作为分类目录; 基于分类目录使用多媒体微博的热点评论对该微博进行分类; 根据微博分类挖掘评论空间中有效主题的特征词。并通过实验证明在富含评论的微博环境下, 该算法简洁且有效。
训练集 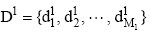
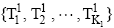
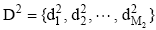
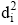
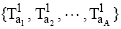

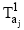
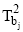
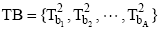
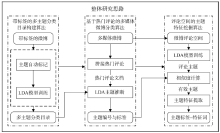
本文提出的算法由三个子算法构成, 分别为带标签的多主题分类目录构建算法、基于热点评论的多媒体微博分类算法与评论空间的主题特征挖掘算法, 这三个子算法按顺序执行。
本文的整体研究思路如图1所示:
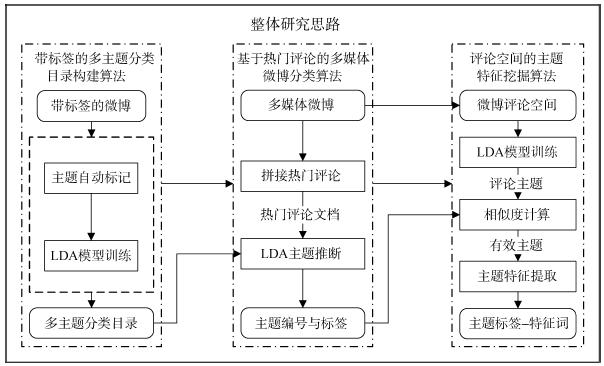 | 图1 整体研究思路 |
(1) 使用带标签的多主题分类目录构建算法训练一个带标签的K1-Topic LDA模型, 称作“ 多主题分类目录” , 用作指导微博的分类;
(2) 使用基于热点评论的多媒体微博分类算法, 引入“ 多主题分类目录” , 推断测试集里每条多媒体微博所属的主题编号与分类标签, 初步得到微博的宏观语义;
(3) 使用评论空间的主题特征挖掘算法, 对测试集中的每条微博计算出其评论空间中与步骤(2)中推断主题相近的评论主题, 并从中提取特征词, 进一步从细节上描述微博的主题特征。
本文的算法需要构建一个多主题的分类目录。一个多主题的分类目录可以对微博的主题进行规范的划分, 从宏观角度标记多媒体微博所属的语义类别。微博服务商大都预先提供了完整的热门微博分类目录, 新浪微博基于用户的兴趣喜好, 提供多种分类维度的阅读形式, 将热门微博划分在多个标签下, 如“ 健康” 、“ 美食” 、“ 数码” 等标签。
基础LDA建模结果中主题并无标题或分类信息。近年来, 学者们通过改进LDA模型实现了给主题添加分类标签, 如Ramage等[17]提出的Labeled-LDA模型。本文借鉴应用预定义标签的思想, 基于新浪微博预先定义的分类属性, 提出一种自动标记主题标签算法可以近似计算出主题的分类, 实现LDA建模结果中自动标记主题标签, 算法如下:
MT(T1)= K1-TopicLDA=LDA.LEAM(d1, K1, I);
For each t1i in T1;
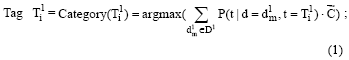
End For;
公式(1) 中 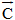
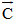
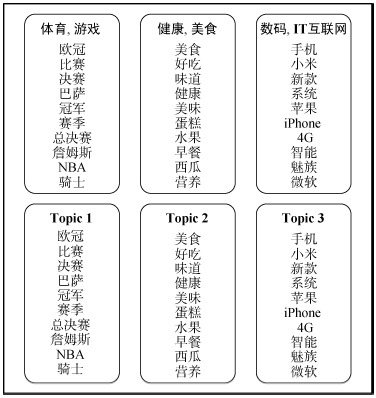 | 图2 应用标签标记算法的LDA模型与基础LDA模型建模结果对比 |
在多主题分类目录的指导下, 一条多媒体微博可以被推断出一个或多个标签, 初步确定多媒体微博的宏观语义倾向。
在基于本体的话题跟踪与基于种子文档的LDA模型研究[18, 19]中, 往往需要事先选取初始语料并构建初始模型。初始语料通常是具有代表性的语料, 因此构建出的初始模型可以牢牢把握中心思想, 在初始模型的基础上使用相关算法, 可以实现模型的完善。“ 热点评论” 是指一条微博的评论中, 点赞数多的评论, 新浪微博服务中包括显示热点评论的排序功能。本文借鉴上述思想, 因为热点评论是受到大量微博用户认可的评论, 热点评论比普通评论往往有着更丰富的语义信息, 且能更生动地表现微博的主题, 所以热点评论可以作为类似上述方法中的初始语料, 起到标杆的作用。
本文对测试集D2中的一条多媒体微博d2i, 抽取其热点评论拼接成为一条文档dHi, 用以代表微博的中心语义思想, 并使用多主题分类目录推断热点评论的主题分类。LDA的Inference算法如下:
2load MT; Initialize new documents;
②For each word wi.j in documentd2i;
allocate a random topic to every word; End For
3For each d2i in D2;
For each wi, j in W2i; Gibbs sample a topic; End For;
End For
4Iterate step ②, ③ for I times, compute matrix θ for new model;
对dH推断结束后, 得到文档集合的“ 文档-主题” 矩阵θ , 从矩阵θ 表示的概率分布中, 提取指定文档d2i的A个可能的主题构成的集合TA。基于热点评论的多媒体微博分类算法如下:
①∀ d2i∈ D2, i=1, 2, …, M2, For eachd2i;
extract top H comments order by heat;
combine into a document named dHi;
DH. add(dHi); End For;
②TA=LDA.inference(DH, MT, A, I);
③For each dHi in DH; For j← 1 to A;
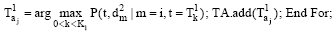
多媒体微博的分类初步定义了该微博语义中潜在的几个主题, 接下来的工作是从多媒体微博全部评论构成的文本空间中挖掘代表其主题特征的特征词项。
微博作为一种风格自由的交互平台, 用户可以自由发表对微博内容的感想, 评论空间中必定隐含了多种类型的主题。例如: 一条带有残疾人励志视频的短文本微博, 微博正文为“ 看到35秒时, 我震惊了” , 其评论中有描述视频内容的, 有发表观后情感的, 也有与视频主旨不相关的“ 垃圾评论” 。
将一条多媒体微博d2i的所有评论D3i训练成K2个主题的LDA模型, 这个模型中可能包含上述分析中存在的多种主题, 也可能包含与主题无关的“ 垃圾主题” 。这时可以用热点评论推断出的主题集合TA作为标杆, 计算K2-Topic模型的主题集合T2中每个主题与TA中每个主题的相似度。可以认为K2-Topic模型中与TA相似度高的主题是反映微博潜在语义的主题, 而相似度低的主题则是与分类无关的“ 垃圾主题” 。
LDA模型中两个主题间的相似度通常使用KL (Kullback Liebler)距离[6]的对称公式(2)进行计算。KL距离的计算要在相同的事件空间中进行, 因此不适用于两个不同LDA模型间主题相似度计算。
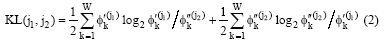
本文提出一种使用修正余弦公式计算两个不同LDA模型间主题之间的相似度的方法, 如下所示:
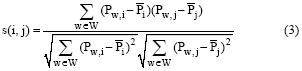
由于LDA模型的训练是一种近似计算的过程, 主题中所有单词的概率之和约等于1, 且不同主题的概率分布之和不一定相等。因此, 本文借鉴协同过滤中处理不同级数分值的方法[21], 对一个主题的概率分布计算平均数。词项集合W是两个概率分布中共有的词项集合, 相似度的计算只考虑共有词项的相似度, 应该忽略非共有词项, 因此, 计算时只取概率分布中共有词项的概率进行计算。
使用公式(3)分别计算出K2-Topic模型的主题集合T2中, 与集合TA中的一个主题T1ai相似度最高的主题T2bi, 最终从T2中提取A个主题并构成主题集合TB。并从TB的每个主题T2bi中抽取概率最高的X个词作为特征词表达该主题的特征。算法使用“ 主题标签-特征词” 的方法标记并描述一条微博中多媒体内容表达的主题特征, 如下:
For each d2i in D2
get D3i with all comments of d2i;
Kti(T2)=K2-TopicLDAleam(D3, K2, I); End For;
For each T1ai in T1;
Initialize a list;
For each T2j;
S=S(i, j)=similarity(T1ai, Tj);
List.add(s); End For;
Sort list; T2b=list.fistElement; TB.add(T2b);
End For;
For each T2b in TB, extract Top X words From T2b;
And show final result like“ tag-words” ;
依据以上算法进行实验, 实验环境使用南京航空航天大学信息管理与电子商务研究所的中文文本挖掘研究平台。研究平台集成了信息采集、文本处理等基本功能与话题检测与跟踪、本体构建与进化等研究成果, 并提供了主要功能接口, 实验者可以便捷地使用平台已有功能或扩展新的功能以进行实验。根据提出的整体研究思路, 本文逐步对总体算法的三个子算法进行实验验证, 并使用一个实例详述, 最后对实验结果进行分析。
使用爬虫工具集中的“ 微博发现爬虫” 连续10天定时爬取新浪微博中的热门微博, 最终采集99 823条热门微博。并从中提取2015年6月1日至6月8日间的82 140条热门微博作为训练集, 在剩下的6月9日与6月10日的热门微博中挑选了符合条件的多媒体微博。挑选的条件是热点评论数大于20条, 且总评论数大于200条, 最终得到151条热门微博。同样使用“ 微博评论爬虫” 采集这151条微博的评论, 构建实验的测试集。
中文文本处理研究大多需对文本内容进行预处理, 从新浪微博采集的微博文本大都是中文文本, 因此需对训练集与测试集的微博文本进行预处理。预处理阶段分为以下几步:
(1) 考虑使用正则表达式去除微博文本中的特有文本, 包括@某位微博用户, “ 秒拍视频” 标志或“ 网页链接” 标志等大量出现且无法反映语义信息的文本。
(2) 使用中国科学院计算技术研究所汉语分词系统NLPIR2015①(http://ictclas.nlpir.org/downloads.)对微博正文文本进行分词。系统导入了30万用户词典, 并开启新词发现功能。
(3) 分词结束后, 对分词结果进行去除停用词处理, 停用词表选用哈工大停用词表、百度停用词表与川大停用词库等②(http://www.datatang.com/data/19300.)。
经过预处理后, 语料库中共有96 238个不同的词汇。
(1) 带标签的多主题分类目录构建
实验选用参数α =50/K1, β =0.01, 其中K1为预设的主题数量, Gibbs采样的迭代次数I为1 000次。可以通过计算主题建模的评估指标, 以分析预设主题K1的数量对LDA建模的影响。传统的LDA主题建模评估方法是使用Perplexity(困惑度), 在测试集中能体现出单调下降的特性。通常, Perplexity值越低, 主题建模的效果越显著, 公式如下:
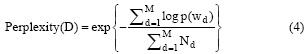
其中D是测试集, wd是测试集中可观测的词语在文档中出现数量, Nd是每篇文档的词汇数。
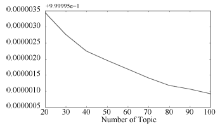
图3是主题数从20开始, 以10为步长递增至100个主题时的Perplexity曲线图。可以发现Perplexity的值随主题数增加而递减。
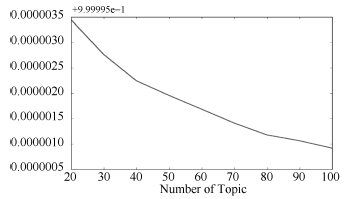 | 图3 Perplexity分布图 |
新浪微博的分类目录共有38个, 且其中有部分分类较为相似, 因此选取K1时还应考虑主题建模对原有38个目录的覆盖率。本文将一种自动分类标签生成算法应用于LDA模型的训练过程中, 由于部分主题间的界限模糊, 因此实验为每个主题指派了两个概率最高的分类标签。实验从20个主题开始, 以10个主题为步长递增至100个主题, 统计主题覆盖分类标签的情况。结果如表1所示:
| 表1 主题覆盖分类标签情况表 |
当LDA模型的主题数从50个主题开始, 每个主题模型没有覆盖的分类标签中都有“ 神最右” 这个界限模糊的分类标签, 因此在主题数K为80时, 模型已经基本完全覆盖了新浪微博分类标签。综合考虑Perplexity值与主题覆盖率, 选取主题数K为80。
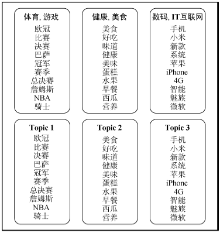
实验将应用本文的自动分类标签生成算法后的主题建模结果。由于篇幅限制, 仅展示其中部分主题, 每个主题取概率前10的词汇进行对比, 如表2所示:
| 表2 部分主题标签与主题词表 |
(2) 基于热点评论的多媒体微博分类
从数据库中筛选了热点评论数大于20条、总评论数大于200条、带有多媒体内容的热门微博共计151条。取出前20条热点评论拼接成文档, 使用分词系统NLPIR2015预处理文档。
对于LDA的推断算法, 设置Gibbs采样的迭代次数I为1 000次, 进行多次推断实验。当推断概率最高的主题等于原微博的分类时, 称为“ 完全正确分类” , 当推断概率最高的两个主题中包含原微博的分类标签时, 称为“ 模糊正确分类” , 实验结果如表3所示:
| 表3 分类推断实验结果表 |
(3) 评论空间的主题特征挖掘
从上一个测试集中随机选取50条推断正确的微博, 对每条微博分别训练一个10-Topic的LDA模型, 并使用2.5节算法进行实验。设定推断主题数A=2, 即上一步实验中“ 模糊正确分类” 。特征词数X=5, 即挖掘主题下概率最高的5个词。
人工观察10-Topic模型中选出的两个主题中概率最高的10个词是否能表现微博多媒体内容的主题, 对每个特征词表达正确的主题打0.5分。正确表达主题特征的主题数为0, 1, 2的微博数量分别为5条, 14条, 31条, 总分为38分, 可以认为特征词挖掘准确率为76.0%。
| 表4 主题特征挖掘测评表 |
本文选取Mid为“ Clf8RAx7l” 的美食类微博, 观测实验结果, 微博URL为http://weibo.com/1757142323/ Clf8RAx7l。忽略微博正文文本, 仅观察微博多媒体块中的9张图片, 如图4所示:
 | 图4 微博多媒体内容截图 |
在上一步“ 基于热点评论的多媒体微博分类” 实验中, 使用训练好的分类目录LDA模型推断该条微博的主题, 推断结果中概率最高的两个主题为“ 美食” 与“ 情感” 。根据人工观测, 可以认为推断的分类结果准确。根据该微博的10-Topic模型与分类目录相似度计算的结果, 与分类目录中“ 美食” 主题相似度最高的主题是Topic8, 而与分类目录中“ 情感” 主题相似度最高的主题是Topic1。分别提取两个主题中概率最高的5个词, 并用“ 美食— — 蛋糕, 西瓜, 水果, 草莓, 奶油” 与“ 情感— — 好想, 试试, 好吃, 喜欢, 好感” , 这种形式表示这条短文本多媒体微博的特征。通过查看放大后的图片, 可以发现“ 美食” 标签下的5个词很好地描述了这条微博展示的西瓜蛋糕的细节, 而“ 情感” 标签下的5个词则反映了阅读者观看这条诱人的图片微博后迫切想吃或想尝试制作图中蛋糕的情感。
带标签的多主题分类目录构建实验中, 当设定主题数为80时, LDA主题建模结果中包含了新浪微博除“ 神最右” 这个模糊标签外的其他全部37个分类目录, 可以基本上完全覆盖新浪微博原有的分类目录。人为观测主题建模的结果, 可以发现主题下概率最高的20个词语与主题在语义上关联性较好。基于热点评论的多媒体微博分类实验中, 使用热点评论, 扩充多媒体微博的文本空间, 并使用LDA推断算法进行分类, 考虑当推断概率最高的两个主题中包含原微博的分类标签时, 结果正确, 则分类的准确率达到88.6%。分类精度较为理想, 可以从宏观上给多媒体微博划分语义范围。评论空间中的主题特征挖掘实验中通过挖掘主题中概率最高的5个词, 可以从语义上较好地反映微博的主题内涵, 通过“ 主题标签-特征词” 的形式表现微博多媒体内容的主题特征拥有较强的表现力。
结合上述三个子算法, 本文提出的算法有效性较高, 有较好的实用价值。
本文提出一种面向短文本、多媒体类微博的主题发现算法。用LDA构建多主题的分类目录模型, 通过微博的热点评论扩充文本空间, 使用LDA的推断算法对热点评论拼接成的文档在主题分类目录模型中进行分类推断, 再对该多媒体微博的总评论空间训练LDA模型, 并通过推断结果与此主题模型的相似度计算, 发现总评论空间LDA模型中有意义的主题, 挖掘特征词以表达微博中多媒体内容的主题。
通过自制爬虫抓取的99 823条微博数据进行实验。实验结果表明, 本文的分类目录模型可以很好地覆盖新浪微博原有的38个分类目录, 对多媒体微博的分类有很高的精确度, 主题特征词的挖掘可以较好地描述微博多媒体内容的特征。实验结果验证了通过挖掘微博评论, 可以显著表达正文短文本所不能体现的图片、视频等多媒体内容的主题。多媒体微博主题推断出概率最高的几个主题中, 往往有情感相关的主题, 接下来的研究可以考虑分别抽取多媒体微博的内容主题与情感主题, 从两个维度上分别描述多媒体微博的内容特征与情感特征。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|