{kind=link}
{kind=link}
{kind=link}
数字文献资源内容服务推荐方法研究*
[毕强, 刘健 ]
]
]
|
|


作者贡献声明:毕强: 提出研究方向, 设计研究方法; 刘健: 设计算法, 实验及分析, 论文撰写。
[Objective] Service recommendation of the content of traditional digital literature resources is unable to fully exploit the user potential information demand and the ratings matrixes are always sparse. This paper provides an algorithm using collaborative filtering algorithm and association semantic link. [Methods] A recommendation algorithm for the content of digital literature resources is proposed by using the association semantic link and collaborative filtering algorithm. [Results] The experimental result shows that the algorithm can overcome the problems of the potential information needs of the users and the sparsity of the matrix. [Limitations] Lack of large-scale collection of digital resources, and the experimental cases are few. [Conclusions] The algorithm can fully exploit the users’ information demand and generate the literature recommendation information. Finally, the validity and practicability of the proposed algorithm are verified by experiments.
以用户为中心, 根据用户的个性化需求开展具有针对性和主动性的信息服务, 是提高信息服务质量和信息资源使用效率的重要手段[1]。数字文献资源内容服务推荐是有效满足用户个性化价值追求的有效方法之一[2]。目前, 资源服务推荐策略主要包括: 基于内容的推荐、基于协同过滤推荐和基于情境的推荐等。超星和中国知网都采用基于内容的服务推荐策略[3]。基于协同过滤推荐是根据用户特征、偏好以及对资源访问行为进行分析和挖掘, 识别用户兴趣、资源的关联以及具有相似行为的用户群, 可对多种类型的资源进行过滤, 并能为用户发现新的感兴趣的信息[4, 5, 6]。基于情境的推荐是对传统服务推荐进行扩展, 即在推荐过程中融合情境信息, 如用户性别、年龄、专业、信息需求水平、背景知识等都可以作为情境信息并与推荐算法结合, 为用户提供更符合其个性需求的相关信息[7, 8, 9, 10]。
上述服务推荐策略采用传统的余弦相似度、Pearson相关系数和改进的余弦相似度作为项目相似性计算的基础[11], 但是近邻查找时间过长, 而且没有考虑相似度计算存在着用户冷启动、评分矩阵稀疏等问题[12, 13, 14], 推荐精确性不高; 另一方面推荐项目与用户模型耦合过于紧密, 无法发现用户潜在的信息资源需求[15, 16]。鉴于此, 本文提出一种基于关联语义链和协同过滤组合的算法, 以此解决评分数据集稀疏和耦合紧密问题, 从而增强推荐的准确性[17]。
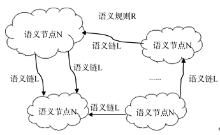
关联语义链网络(ALN)是一种用于对Web资源进行管理的具有语义关系的数据模型。关联语义链网络通常都是由三个部分组成(N, L, R), 即N语义节点, L关联语义链和R关联语义规则[18], 如图1所示:
 | 图1 关联语义链网络图 |
其中, 语义节点可以是网络中任意类型的资源, 例如文本、图片、资源、甚至是一个语义链网络。关联语义链将Web资源语义化以此来链接松散的资源。只要关联语义链的节点存在语义关系, 那么关联语义链可以链接网络中的任意节点。关联语义规则是关联语义链中的节点之间的关联规则, 表明语义节点之间的关联程度。关联语义链的构造即构造各种语义节点之间的关系。将语义节点由关键词进行语义的表示, 由此建立两个语义节点之间的关系等价于寻找关键词之间的关系。由于语义节点之间可能有一个或者几个关键词, 因此关联语义链由这几个节点的语义规则的和得到[19]。
常用的关联规则筛选方法为支持度(Support)与置信度(Confidence), 公式如下[19]:
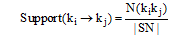 |
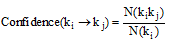 |
其中,
关联语义链的构造算法如下:
①由语义节点计算语义向量和语义规则。如果关键词出现就标记为1, 否则标记为0, 由此得到语义向量。
②计算两个语义节点的关系语义链权值。由语义规则求和计算得出规则向量。其中求和的方法是将指向同一关键词的权值相加。
③将语义规则与语义向量做“ 与” 操作。得出两个语义节点之间的权值。即得出关联语义链。
④重复以上操作, 直到构造完成。
以上求得的语义链值往往大于1, 因此可以将语义节点的关联语义链值改为其占所有语义节点语义链值的百分比, 使语义链值保持在0到1之间。
公式(3)[19]说明了如何计算节点之间的关联语义链值, 可以将此链接值作为资源权重。
 |
其中, 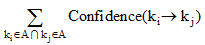
协同过滤推荐是目前最为成功的推荐技术, 已经有许多学者将协同过滤方法成功应用到数字资源服务推荐中[20, 21, 22]。协同过滤推荐可以分为以下三个步骤:
(1) 构建用户-项目评分矩阵。收集用户关于资源的评价信息, 并对数据进行清理、转换和录入, 最终得到用户对于资源项目的评分矩阵。
(2) 最近邻居搜索。通过余弦相似性、修正的余弦相似性和相关相似性等公式计算用户间相似度, 得到相似度矩阵。算法在使用基于用户的协同过滤算法时采用相关相似性公式, 而使用基于项目的协同过滤算法时采用修正的余弦相似性度量公式。根据相似度矩阵使用K最近邻方法或者设定阈值方法得到目标用户的最近邻居。
(3) 产生推荐结果。获得目标用户的最近邻居集合后, 预测目标用户对任意项目的评分, 形成 Top-N 推荐列表并返回给用户。
基于内容的推荐算法可对数字文献资源内容进行准确的表征, 且算法简单、查准率高, 但无法发现用户新的或隐含的阅读兴趣, 容易生成无效规则。关联语义链网络以语义互联的方式组织松散的网络资源, 协同过滤算法能发现用户潜在或新的信息需求。本文将关联语义链和协同过滤算法结合起来, 构造数字文献资源内容服务推荐算法, 便于向用户提供真正有价值的数字文献资源内容推荐服务。
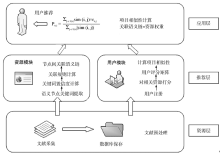
本文结合关联语义链和协同过滤算法来构建数字文献资源内容服务推荐算法, 算法模型如图2所示。数字文献资源内容服务推荐算法模型共有三层结构。其中, 资源层用来收集数字文献资源信息, 并将信息保存到数据库中; 推荐层由两个模块构成: 资源模块用来计算数字文献资源之间的关联语义链链接权值, 用户模块用来收集用户浏览数字文献资源信息及评分信息, 在此基础上计算项目相似性; 应用层即为推荐系统实现, 使用公式(4)[23]计算得分, 并对用户进行推荐。
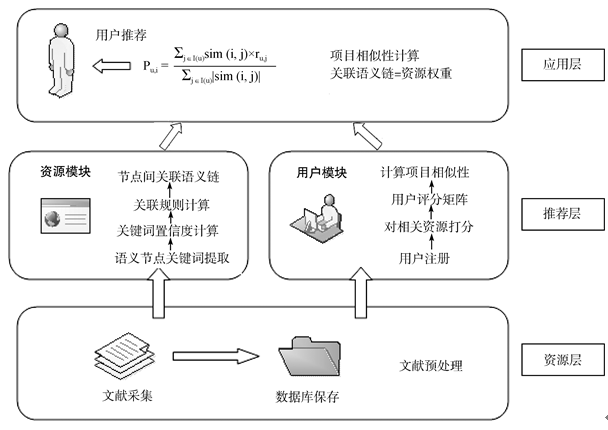 | 图2 数字文献资源内容服务推荐算法模型 |
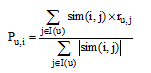 |
(1) 关联语义链链接权值计算
本文使用中国科学院计算技术研究所的分词软件ICTCLAS①将数字文献资源进行分词并保留名词, 对出现频率较高的词汇进行统计和筛选, 得到描述数字文献资源的关键词。再通过公式(3)计算各个数字文献资源之间的关联语义链权值, 执行操作如下:
For each 文献 s
For each 关键词 k
Do {初始关键词词频阈值μ ;
关键词词频排序;
关键词词频α ; }
If (α > μ )
保留该关键词;
End if
End for
Do {计算数字文献资源之间的链接权值wu;
}
End for
①http://ictclas.nlpir.org/.
(2) 确定最近邻居
最近邻居指与当前评分行为的用户比较相似的用户群体。最近邻居检索是整个算法的核心部分, 决定推荐算法的效果和效率。最近邻居检索的过程就是协同过滤算法中模型建立的过程, 根据用户评分矩阵和资源相似性, 通过Pearson相似性公式, 将
For each 数字文献资源 si
For each数字文献资源sj
Do{计算资源之间相似度sim(i, j)
}
End for
End for
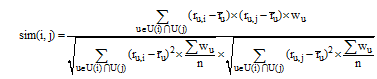
(5)
其中, 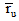
(3) 数字文献资源推荐
对用户u已打分的数字文献资源的分数进行加权求和, 权值为各个数字文献资源与数字文献资源i的相似度, 对所有数字文献资源相似度的和求平均, 使用公式(4)预测用户u对数字文献资源i的打分, 并对用户进行推荐。
本文选取两篇文献《我国房地产经济泡沫的形成机理与区域性特征》和《房地产经济波动的影响因素及对策》作为语料, 演示两个文献之间如何生成关联语义链。将两篇文献进行分词并保留名词, 剔除与文献无关以及出现频率小于3的名词。经过预处理后, 第一篇文献提取出的关键词包括: 市场、投资、销售量、资金、原则、影响力、土地、收益率、成果、房地产、经济; 第二篇文献提取出的关键词包括: 决定、动机、市场、形势、房价、房地产、政策、理论、对策、经济。由此得到的关联语义向量, 记为C1{0100000011}、C2{0010010001}。其中, 语义规则R1(2, 10, 0.4)表示关键词2指向关键词10, 权值为0.4。语义规则R2(3, 10, 0.5)表示关键词3指向关键词10, 权值为0.5。语义规则R3(6, 9, 0.7)表示关键词6指向关键词9, 权值为0.7。语义权值向量{0, 0.5, 0, 0, 0, 0, 0, 0.7, 0, 0, 0.4}, 可以得到关联语义链权值和0.4+0.5+0.7=1.6。这样建立了第一篇文献与第二篇文献的链接, 其链接的权值为1.6。同样, 可建立有共同关键词的文献间的链接。设其链接的权值和为N, 那么第一篇文献和第二篇文献链接权值为1.6/N, 即关联度为1.6/N。在建立的过程中, 也可以设定阈值, 删除那些关联度较低的文献, 保留关联度较高的文献。
(1) 数据集
为了检验该推荐算法的有效性, 本文使用MovieLens数据集①进行实验, 实验数据集中包括U1base和U1test两个文件。为了验证准确性, 从知网经济、历史、计算机、数字图书馆等分类中选取200篇文献作为数据来源, 并请本校本科生120人, 研究生80人对资源进行评分。由于知网中每篇文献描述中包含文献的关键词与摘要, 因此可以利用关键词建立起文献内容之间的关联网络, 并在用户对文献评分的基础上对其他用户进行推荐。
(2) 评价标准
本文使用平均绝对误差(Mean Absolute Error, MAE)对推荐算法进行评价。MAE[24]计算如公式(6)所示, MAE 越小, 表明推荐的质量越高。
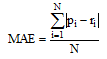 |
F评价指标如公式(7)所示[25], F值越高, 推荐效果越好。
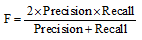 |
其中, 查准率(Precision)与查全率(Recall)计算方法如下:
 |
 |
(3) 实验结果及分析
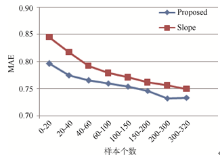
实验过程中利用MovieLens数据集测试该算法的有效性, 考虑到训练集规模对于推荐精度的影响, 选取U1base文件作为训练集, 建立用户-项目评分矩阵, U1test文件作为测试集。设定样本间隔数为20, 选取近邻数为10, 不同样本数(20-320个)运行结果见本篇论文网络版支撑数据, 并与Slope协同过滤算法[25]对比, 对测试数据集中每条评分记录进行预测, 求出其MAE 值。实验结果如图3所示:
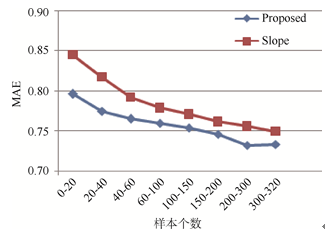 | 图3 本文算法与Slope协同过滤算法MAE比较 |
本文提出算法的MAE评价指标要低于Slope协同过滤推荐算法。样本个数越少, 对应数据源越稀疏。实验以不同稀疏程度的数据测试算法在数据稀疏性方面的表现。当样本个数过少时, 本文提出的算法MAE 值较小, 这是因为加入资源权重因子后, 不需要用户评分即可向用户进行服务推荐。随着已知评分项的增多, MAE 值不断下降, 预测质量较高。当样本数在200到300 之间时, 算法的MAE值最小。之后, 随着样本数的增多, MAE值略有提升。
本文利用从知网抽取的文献资源检验算法准确性, 从数据集中随机抽取10%-90%数据作为训练集[27], 选取近邻数为10, 利用F评价指标比较数据稀疏程度不同时的推荐效果。实验结果如表1所示:
| 表1 本文算法F评价指标 |
随着测试集数据的增多, 算法的查准率与查全率都随之增加, F值随着数据的增多而增大, 表明本文提出的算法通过使用关联语义链的方法提高了推荐准确性, 也说明可以通过增加数字文献资源数量和用户人数, 使得推荐结果更加符合用户对于数字文献资源的偏好。
本文引入关联语义链, 提出一种数字文献资源内容服务推荐算法。以关联语义链为基础建立数字文献资源的关联语义链网络, 得到数字文献资源之间关联的权重; 将数字文献资源链接权重加入到Pearson相关性公式中计算用户相似度; 预测评分并对用户进行推荐。实验结果表明, 该算法与传统协同过滤算法相比, 具有更好的推荐精确性, 并且在一定程度上缓解了数据稀疏问题。本文为增强资源服务推荐的准确性和针对性提供了一种新途径, 有利于推进数字文献资源产品的开发与利用, 为用户提供更符合其需求的数字文献资源推荐服务。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|