面向协同过滤推荐的多粒度用户偏好挖掘研究
[宋梅青 ]
]
]
|
|


[Objective] Researching the relationship between users’ preference mining granularity and mining efficiency in collaborative filtering, this paper aims at finding out the most efficient mining granularity. [Methods] According to the practical application, the users’ preference mining granularity is divided into three kinds from coarse-grained to fine-grained, and then design the corresponding preference mining algorithm under the three kinds of granularities, finally contrast users’ preference mining efficiency under different granularities through experiments. [Results] Experimental results show that the preference mining efficiency reduces as the users’ preference mining granularity changes from coarse to fine. [Limitations] Data only includes users’ consumption data and rating data, other types of data are not covered temporarily. [Conclusions] Coarse-grained preference mining is better for discovering users’ preferences.
协同过滤目前广泛应用于电子商务、新闻推送、在线视频以及社交网站等领域, 是当前最热门的个性化推荐技术之一。协同过滤推荐主要包含用户偏好挖掘和个性化推荐实施两个阶段。在第一阶段的用户偏好挖掘中, 系统通过对用户的历史行为数据进行分析, 找到用户的兴趣所在, 并用适当的语言或者模型对用户偏好进行定义和描述。在第二阶段的个性化推荐实施中, 系统根据第一阶段描述的用户偏好, 寻找与目标用户有相同兴趣的相似用户集合, 或者根据项目消费的相似性寻找相似项目集合, 最后根据相似用户或相似项目实现偏好的传递。这两个阶段的效率都会影响最终的推荐质量。本文主要针对协同过滤的第一阶段展开研究, 先从多粒度的角度对用户偏好进行描述, 再通过对比不同粒度下用户偏好挖掘的效率, 找出效率最高的偏好挖掘粒度。本研究不仅为进一步的算法创新奠定基础, 也有助于丰富整个协同过滤研究的理论体系。
目前有关协同过滤推荐的研究中, 比较有代表性的改进思路有:
(1) 通过改进相似性度量方法提升推荐精度。Liu等[1]提出一种新的用户相似性计算模型, 该模型在计算用户相似性时将用户评分的局部相似性和用户的全局性偏好相结合, 在面对只有很少评分时也能发挥作用, 改善了冷启动问题, 提升了推荐质量。Bobadilla等[2]将基于用户之间常见评价与不常见评价的比例作为一个独立变量, 并与用户投票的数量信息相结合, 设计一种新的用户相似性度量方法, 实验证明该方法改善了推荐效率。
(2) 引入信任度变量提高推荐的准确性。王海艳等[3]提出一种新的协同过滤模型, 该模型加入了推荐可信度, 可信度值的权重通过层次分析法确定, 实验表明新模型提升了系统的效率。刘胜宗等[4]通过对评分准确性、认可程度和数量权重的分析, 得到用户评分的可信度, 再与相似性度量结合, 提升了协同过滤推荐的准确性。
(3) 在推荐中引入时间因子, 考虑兴趣的变化。孙光福等[5]提出一种基于时序行为的新协同过滤算法, 该算法先基于用户的时序行为找出最近邻, 再与基于概率的矩阵分解技术相结合, 改进了协同过滤算法的推荐精度。郑志高等[6]考虑数据的时间有效性, 对相似度进行时间加权, 还引入近邻因子寻找推荐概率高的用户子群和项目子群, 实验结果表明该算法提高了系统的推荐效率。
(4) 结合聚类技术实现算法改进。Nilashi等[7]提出一种基于聚类和回归的多标准协同过滤推荐算法, 由于每一个用户子群会对部分项目有相似的偏好, 该算法可以通过聚类和偏好模型自动寻找用户子群, 并且当有新的评价信息出现时, 该模型还支持评价增量的更新。实验结果表明该模型的推荐精度更高。张莉等[8]通过引入用户兴趣的活跃度因子改进基于用户聚类的协同过滤算法, 实验结果表明该算法提升了推荐的准确性。
(5) 考虑情境因素。邓晓懿等[9]依据情境对用户进行聚类, 基于社会网络理论衡量用户之间的关系, 以此判断用户推荐能力的高低, 最后实现评分预测, 研究发现该模型提高了推荐的精度和覆盖率。
(6) 融合社交网络改进推荐算法。于洪等[10]提出一种集合社交信息与标签信息的协同过滤算法, 该算法先计算用户的个体重要度, 再基于标签产生一个用户的相似度, 以此为基础实施个性化推荐, 实验结果表明该算法提升了推荐准确性。俞琰等[11]提出可根据社会网络计算用户间信任程度的高低, 以此改进传统算法。实验结果证明该算法提高了推荐的准确性。
(7) 针对冷启动、可扩展性问题的协同过滤改进算法。李聪等[12]提出可通过分析用户的历史访问记录, 产生一个网络访问的序列, 以此为依据计算用户的相似性, 实验结果证明该算法可有效改善冷启动问题。杨兴耀等[13]先对评分奇异性进行分析, 再结合扩散相似性模型对协同过滤模型进行改进, 实验结果证明该模型提升了可扩展性, 并有效提高了推荐质量。
无论是设计新的相似性计算模型, 还是引入时间、信任度、情境等变量, 或是结合社会网络等方法, 其算法改进思路都是为了提高相似性计算的精度, 而对算法的冷启动与可扩展性问题进行改进, 也是为了提升相似性计算的精度和实时性。因此, 总体来看目前针对协同过滤的研究, 大多数集中在协同过滤推荐的第二阶段, 都希望通过提升相似性计算的精度和效率提升系统的推荐质量。现有研究中缺少对第一阶段中用户偏好的定义和描述的深入研究, 而第一阶段的用户偏好挖掘是推荐实施的基础, 对推荐效率也有重要的影响。由于协同过滤是通过发现相似偏好产生推荐集合的, 当系统对用户偏好的定义和描述不同时, 找到的相似用户或相似项目也会不同, 系统的推荐精度也相应会发生变化。鉴于此, 本文将用户偏好按照粒度的粗细划分为三种, 并分别设计相应的算法进行偏好挖掘, 通过对比推荐效果, 分析用户偏好挖掘粒度与挖掘效率之间的关系。
结合现有研究和实际应用环境, 本文将用户偏好挖掘粒度从粗到细分为三种, 分别用G1、G2、G3表示, 具体如下:
(1) 粒度G1: 将用户偏好归为正面、负面两类。
在判断目标用户对某一项目是否存在一定的偏好时, 最直接的方法就是将偏好分为正负两面。如果目标用户在浏览相关项目的产品信息后, 直接产生了购买行为, 并在消费完该项目后给出了积极的产品评价, 可视作目标用户对该项目有正面反馈, 这时判定用户对该项目的偏好为正面。反之, 如果目标用户在查看完某项目的产品信息后, 没有消费该项目, 或者消费完该项目后给出了消极的评价, 则可视作目标用户对该项目有负面反馈, 这时应判定用户对该项目的偏好为负面。将用户偏好归为正负两面, 是本文中粒度最粗的一种分类。用“ 是” 或“ 否” 这种定性的判断, 将复杂的用户偏好简约化, 便于系统处理。推荐系统根据得到的用户偏好的正负判定结果, 对目标用户进行个性化推荐。
(2) 粒度G2: 将用户偏好归为正面、中性、负面三类。
在用户偏好分为正负两类的基础上, 对偏好粒度进一步细化, 是多粒度偏好挖掘的方向。结合协同过滤推荐的实际应用情况, 笔者发现在用户偏好的判断过程中, 会出现这样一种情况, 即: 目标用户对某项目既没有表现出明显的积极评价, 也没有表现出消极的反应, 介于正负两者之间, 属于中性。例如目标用户在消费完某一项目后给出了一个中等评分, 没有表现出很强烈的兴趣, 但也不能认定其偏好为负面, 对于诸如此类情况都视作中性偏好。将中性偏好和正负两面结合起来, 形成第二种偏好粒度划分, 即: 用户偏好归为正面、中性、负面三类。
(3) 粒度G3: 将用户偏好按评价的值划分为连续多个类。
正负两面的二分法和正面、中性、负面的三分法, 都是通过对用户兴趣数据源进行定量分析后, 得到的定性判断, 便于系统快速进行匹配, 及时进行个性化推荐。而在实际应用中, 系统还可以根据自身的推荐需求, 设定不同的搜索对比范围, 再基于协同过滤技术, 找出相似用户或者相似项目即可。这种情况下, 用户偏好按照实际评分被划分为连续多个类别, 理论上每个评价值都可以视作单独的一个类别, 偏好划分得以进一步细化, 使得偏好挖掘粒度更小, 从而方便系统在实施推荐时, 可以根据自身需要, 进行不同程度的精准匹配。
设U={ui, i=0, 1, 2, ……, m }为全体用户集合(非空集合)。ui为U中的任意一个用户。B={bj, j=0, 1, 2, ……, n}为全体项目集合(非空集合)。bj为B中的任意一个项目。 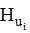
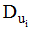
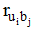
(1) 基于粒度G1的用户偏好挖掘
①从 
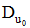
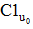
②测算正面偏好和负面偏好的评分临界值, 本文称之为偏好临界值(S)。
定义1: 偏好临界值。当用户ui对项目bj的评分 

设系统评分规则中的上限值为p0, 随机设定一个偏好临界值的参考初值S0, S0= ∂ × p0, 其中∂ (0.6≤ ∂ ≤ 1)为初值的随机参数, 即设定的参考初值S0不低于评分规则中上限值的60%。在初次推荐时, S=S0, 参考初值S0即为S值。从全部用户中随机抽取部分用户, 按照基于G1的挖掘算法流程对S值进行推荐效率测试, 从而给出一个调整值∆ S, 最终的偏好临界值的计算公式如下:
S = S0 + Δ S (1)
经过∆ S修正过的S值即为系统的偏好临界值, 用于全部用户的实际推荐。
③对照偏好临界值S, 对项目评分集合 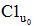
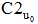
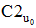
④将用户评分值转换为新的偏好值, 计算最终的项目推荐分数。系统依据协同过滤的流程得到待推荐项目集合, 在计算每个待推荐项目的推荐分数时, 应以偏好临界值S为依据, 将原来的用户评分值转换为新的偏好值, 再计算最终的推荐分数, 产生推荐列表。偏好值转换公式如下:
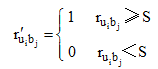 |
其中, 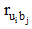

(2) 基于粒度G2的用户偏好挖掘
①从 

②测算用户偏好的正面、中性、负面的评分值区间, 本文称之为偏好域。
定义2: 偏好域。将评分值从高到低划分为三个互不重叠的区间: A1、A2、A3, 且A1UA2UA3=A, A为评分值的全部取值范围。当用户对项目的评分分别处于区间A1、A2、A3时, 依次判定用户对该项目的偏好为正面、中性、负面。本文分别称A1、A2、A3为正面偏好域、中性偏好域、负面偏好域。
设系统评分的上限值为P1、下限值为P2, 由此产生了一个初始偏好域, A1为只包含P1的区间, A3为只包含P2的区间, A2区间包含大于P2且小于P1的全部值。首次推荐时, 先使用初始偏好域作为系统的偏好域, 再经过测试, 不断调整偏好域的范围。具体的调整方法是: 从U中随机选取部分用户, 按照基于G2的挖掘算法流程对偏好域进行测试, 测试过程中应逐步扩大A1和A3的区间范围, 逐渐缩小A2区间的范围, 经过几轮修正后, 最终得到系统的偏好域, 分别由A10、A20、A30表示。它们可应用于全部用户的实际推荐。
③对照最终的偏好域, 对目标用户已消费项目的评分集合 
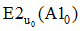

W=W(A10)+W(A20) (3)
④得到相似度后, 系统依据协同过滤的流程查找待推荐项目集合, 在计算待推荐项目的推荐分数时, 也应将原来的用户评分值转换为新的偏好值, 偏好值转换公式如下:
 |
其中, 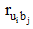

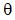


(3) 基于粒度G3的用户偏好挖掘
①从 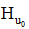
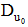
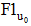
②根据评分规则, 结合系统自身的推荐需求, 直接设定感兴趣的评分阈值。设基于粒度G3的偏好挖掘中的感兴趣的阈值由K表示。将集合 

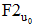
③根据协同过滤的流程得到待推荐集合, 在计算待推荐项目的推荐分数时, 不进行偏好值的转换, 直接使用用户的实际评分值参与计算, 得到最终的推荐列表。这种将用户评分值直接认定为偏好值并参与计算的方式, 在目前研究中使用较多, 代表了传统的偏好挖掘方式。
本文将对以上三种粒度的偏好挖掘效率进行对比, 分析粒度粗细与挖掘效率之间的关系。
实验数据来自美国明尼苏达大学的GroupLens研究组提供的数据集ml-100k①, 该数据集包含了943位用户对1 682部电影的10万条评分数据, 评分标准为5分制, 评分越高代表对电影的满意度越高。文件u.data记录了全部的评分数据, 共有用户编号、电影编号、评分值、时间戳4个属性。由u.data随机生成5组训练集和测试集, 训练集与测试集的数据比例分别为80%、20%。
本文旨在研究不同粒度下用户偏好挖掘效率的区别, 而偏好挖掘效率很难直接衡量, 只能通过最终的推荐效率的高低反映出来。本次实验选择基于用户的协同过滤基本算法(UBCF)为载体, 分别与不同粒度下的偏好挖掘算法相结合, 实现个性化推荐, 以最终的推荐效果对比不同粒度下用户偏好挖掘的效率。
设基于用户的协同过滤算法在用户偏好挖掘粒度依次为G1、G2、G3的情况下, 分别表示为G1-UBCF、G2-UBCF、G3-UBCF。实验在计算用户的相似度时采用余弦相似度公式[14]。
本文选取的评价标准为通用的准确率[15](Precision)、召回率[15](Recall)以及F1值[16]。
 |
算法在5组训练集和测试集上依次进行测试, 将得到的结果取平均值。
依据算法得到基于粒度G1的偏好临界值为4; 基于粒度G2的正面、中性、负面偏好域依次为[4, 5]、[3, 4)、[1, 3); 基于粒度G3的阈值K为4。
系统训练产生的临界值和偏好域在实际检验中, 对大多数用户是适用的。在协同过滤算法的推荐分数计算中, 某项目被越多相似用户认可, 那么它被推荐的可能性就越高, 这在客观上可以抵消个别用户评分过严或过宽带来的误差。
5组训练集和测试集的组合分别用BT1、BT2、BT3、BT4、BT5表示, 使用Matlab7.0, 得到最终的测试结果如表1、表2所示:
| 表1 准确率、召回率的测试结果 |
| 表2 F1值的结果 |
无论是准确率、召回率还是F1值, 都反映出同一结果, 即G1-UBCF的推荐效率最高, G2-UBCF次之, G3-UBCF最低。由于三种不同粒度下的用户偏好挖掘都是以同一协同过滤基本算法为载体, 由此可以反映出基于粒度G1的用户偏好挖掘效率最高, 基于粒度G2的用户偏好挖掘效率居中, 而基于粒度G3的用户偏好挖掘效率最低。
对照实验结果, 可以发现当偏好挖掘粒度从粗到细变化时, 用户偏好的挖掘效率会逐渐降低。这种变化趋势说明, 在对用户偏好进行挖掘时, 本来期望通过对偏好本身进行粒度的细化, 可以更精确地描述用户的兴趣, 但实际上反而降低了系统发现真实兴趣的能力。
对于推荐系统来说, 发现用户的兴趣偏好是实现推荐的基础。在基于G1的偏好挖掘中, 对用户偏好的是一种非此即彼的划分, 只要达到偏好临界值都视作同等程度的兴趣。在后续计算推荐分数时, 原有的评分值也都相应进行了偏好值的转换, 降低了历史评分的权重, 实验结果证明这种设计反而能更好地发现用户的偏好。在基于G2的偏好挖掘中, 中性偏好的权重值低于正面反馈偏好, 算法设计的初衷是为了更好地描述那些介于正负之间的兴趣, 认为用户对它们的消费和评分行为本身也反映了一定的兴趣, 但实验结果显示这么做反而会降低推荐效率。在基于G3的偏好挖掘中, 用户兴趣被划为连续多个层次, 原始的用户评分在衡量用户偏好时有更大的权重, 实验结果显示在三种粒度的偏好挖掘对比中, 基于G3的偏好挖掘效率最差。
综上所述, 可以总结为粗粒度的偏好挖掘具有更高的效率, 可能的解释是粗粒度的偏好能够更加简单直接地反映用户对项目的兴趣, 而在挖掘粒度细化的过程中, 可能受粒度划分的主观性等因素的影响, 降低了发现真实偏好的能力。所以在实际应用中, 可尽量选择粗粒度的偏好挖掘, 但不能绝对化, 还应结合具体情况调整实际的用户偏好挖掘粒度。
本文面向协同过滤推荐, 对用户偏好挖掘粒度与挖掘效率之间的关系进行深入研究。定义了粗细不同的三种用户偏好挖掘粒度, 再结合协同过滤基本算法进行实验分析, 实验结果显示用户偏好挖掘的效率随着偏好挖掘粒度的变小而降低。因此在进行协同过滤推荐时, 采用粗粒度的挖掘更符合系统的需要。总之, 本研究不仅为其他学者研究协同过滤提供了参考, 对协同过滤的实际应用也有一定的指导意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|