
{kind=link}
{kind=link}
科学数据元数据标准述评及其通用化设计研究*
[刘峰1, 2, 3  , 张晓林
, 张晓林1 ]
, 张晓林|
|


作者贡献声明:
张晓林: 提出研究思路和框架, 参与内容分析和组织, 审定论文; 刘峰: 设计研究方案, 收集、整理、统计与分析研究数据, 论文起草及修订。
[Objective] Conduct a comprehensive analysis of scientific metadata standards and build a common metadata standards design model. [Methods] Make an overview and analysis of six typical metadata standards in different research fields and design common metadata standards of scientific data based on statistics. [Results] There are many obvious differences in format, organization, expression of metadata standards of different research fields, but there are also some similarities in its elements. [Conclusions] Discipline-oriented metadata standards of scientific data promote the development of scientific research, but also pose a challenge to the unified management and service of scientific data. Based on the statistics of metadata standards elements in different research fields and build a common metadata specification is an idea to solve this problem.
近年来, 随着数字化技术与网络技术的发展, 科学研究日益成为数据密集型的工作, 进而形成大量的科学数据。它具有学科领域众多, 结构差异大等特点, 这为高效、统一的数据组织、管理、共享与服务提出了新的挑战。
理解和掌握科学数据元数据标准是进行有效科学数据管理的基础, 本文在对现有科学数据元数据标准概述的基础上, 重点对地理、生物、化学、物理等主要学科领域典型元数据标准进行综述分析, 并在已有通用元数据设计研究基础上, 补充融合最新的学科领域及数据知识库元数据标准, 进而提出基于统计的科学数据通用元数据设计规范化模型。为科学数据的集中、规范化组织管理与服务提供一种思路。
元数据(Metadata)是描述信息资源或数据对象的数据, 其最本质、最抽象的定义就是: 关于数据的数据(Data about Data)[1, 2, 3], 现实应用中常常存在因具体情景而定制性的解释, 如描述、解释、定位、检索、使用或管理信息资源的结构化信息[4], 信息对象必要属性的结构化描述等[5], 表达多样性说明了“ 关于数据的数据” 这个概念表达的模糊性[6], 也正因为如此不同从业背景的人员在关于元数据的交流时常常会造成误解或沟通困难, 所以在具体应用中应根据实际语境明确元数据内涵的表述。元数据通过对描述对象的揭示, 促进对被描述对象的共识性理解及高效利用。1994年, 电器和电子工程师协会(IEEE)在白皮书[7]中明确了元数据应用的4种场景: 查询、浏览、检索数据; 数据获取、质量保证、再加工; 系统间转换数据; 存储、建立数据档案。
总体来说, 元数据的使用目的在于识别资源、评价资源和追踪资源在使用过程中的变化, 以实现信息资源的有效发现、查找、一体化组织和对使用资源的有效管理。它可用于资源的组织、发现、互操作、归档和保藏等, 虽然目前对概念和场景有所扩展, 但基本上其核心还是围绕这些定位展开的。
如前所述, 人们基于应用场景的不同, 对元数据理解存在多样性。与此相类似, 元数据的分类也多种多样。其中广泛使用的是数字图书馆方向的METS[8]标准中将元数据分为以下三类:
(1) 描述元数据: 用于发现和标识数据项的元数据。例如: 标识、题名、摘要、作者、关键词等。
(2) 结构元数据: 用于记录包含数据的文件位置、结构及其相互关系的元数据。例如: 章、节、段等。
(3) 管理元数据: 记录数据项管理信息的元数据。包括存储、格式、溯源及访问权限信息的元数据。例如: 权限、来源、日期、范围。
元数据的基本表现形式是名值对, 其中名称部分来自受控命名空间, 值可能是自由文本、数值或来自受控词表。
元数据最常用的基本组织形式包括: XML和Fielded Text[9]。
(1) 可扩展标记语言(Extensible Markup Language, XML) , 可以用来标记数据、定义数据类型, 是一种允许用户对自己的标记语言进行定义的源语言。XML是标准通用标记语言 (SGML) 的子集, 非常适合 Web 传输。XML 提供统一的方法描述和交换独立于应用程序或供应商的结构化数据。XML支持访问XML文档的标准API, 如DOM、SAX、XSLT、XPath等。
(2) 域文本(Fielded Text)是标注含有表格数据文本文件的推荐标准。它可以处理通常的CSV文件及以逗号分隔值的相似文件。在这些文件中表格数据被简单地存入文本文件中, 其中一行代表表格的一行(或记录), 同一行中的每一列用逗号进行分隔。
元数据的研究和发展, 与蓬勃发展的信息科学和空间数据团体密不可分[5], 所以科学研究领域可谓既是元数据的发源地, 也是其发展和应用的根据地。作为描述科学资源对象、科学活动或科研成果等内容的数据, 科学数据一直是元数据研究和应用的重要前沿。科学数据元数据是对科学数据外部形式和内部特征的详细描述, 为科学数据共享提供信息, 其主要目标是提供科学数据资源的全面指南, 以便用户对数据资源进行准确、高效与充分的开发和利用。
Diederich等[10]1991年撰文提出面向领域创建科学数据元数据的建议, 而此后科学数据元数据的发展也正是在各个学科领域呈现出了百花齐放的势态, 特别是地球科学、生命科学等领域, 如地理空间数据元数据内容标准(Federal Geographic Data Committee Content Standard for Digital Geospatial Metadata, FGDC/ CSDGM)、地理信息元数据Geographic Information-- Metadata (ISO 19115)、美国国际地球科学信息网络中心(CIESIN)元数据规范、美国国家航空和宇宙航行局(NASA)目录交换格式 (Directory Interchange Format, DIF) 标准、地理信息元数据(GB/T 19710-2005)、海洋信息元数据(HY/T 136-2010)、数字林业标准与规范第10部分: 元数据标准(LY/T 1662.10-2008)、气象数据集核心元数据(QX/T 39-2005)、城市地理空间信息共享与服务元数据标准(CJJ/T 144-2010)、土壤科学数据元数据等, 以及生命科学领域的生态元数据语言(Ecological Metadata Language, EML)、达尔文核心元数据(Darwin Core)、生态科学数据元数据(GB/T 20533-2006)等。英国数据监护中心列举的主要研究领域的科学数据元数据标准如表1所示[11]。本文重点对生物科学、地球科学及社会与人文科研领域的典型元数据标准进行概述分析。
目录交换格式DIF [12]是一个交换科学数据集信息的标准格式, 主要用于说明遥感数据, 特别是卫星遥感数据的一个实际应用的元数据标准。它是一种发现格式, 格式信息可以帮助用户决定一个数据集是否适合他们的需要。DIF是建立时间最长的元数据格式之一, 源于1987年成立的地球科学与应用数据系统工作组(ESADS), 1988年第一版本标准发布。
| 表1 主要科研领域的科学数据元数据标准一览 |
DIF由一系列字段组成, 详细说明有关数据的信息。通过特殊的“ 容器” 包装了一套描述数据集的元数据项从而补充与其他元数据标准差异。这套元数据记录包括8个必选项、17个高推荐项和11个可选项[13]如表2所示:
| 表2 DIF元数据标准数据项构成 |
其中一些元数据项取值采用自由文本, 而另一些采用受控词表, DIF标准与ISO 19115元数据标准兼容。
DIF虽然并不是采用XML定义, 但目前开发的XML Schema是可以应用的。DIF包括其Schema目前由NASA哥达德空间飞行中心负责开发维护。DIF当前仍然局限于数据字典范畴, 重点从数据存储的角度说明数据, 缺乏数据分发、数据使用等方面的信息。
Darwin Core(DwC)是一个生物学领域的元数据标准[14, 15]。它基于 Dublin Core(DC)[16]标准而产生, 被当作DC的生物学扩展。
Darwin Core具有可扩展性和灵活性。一个更加严格和通用的格式被称为简化版Darwin Core。这个标准通过命名空间机制同样具有扩展性, 可应用到其他生物学科方向。两种Darwin Core都具有XML和文本域两种组织格式。它通过制定一个术语的词表, 以方便发现、检索、整合有关生物、时空信息, 以及生物的收藏品, 从而提供一个稳定的生物多样性信息共享标准。
Darwin Core给出的术语表, 旨在通过提供一些参 考定义、例子和评论促进有关生物多样性的信息共享。Darwin Core主要基于类群、关于它们在自然界出现的观察记录、标本、样品, 以及一些相关信息。该标准包含一系列的文档, 用来描述如何管理这些术语, 如何为新的用途扩展术语, 以及如何使用这些术语。Darwin Core 2.0包含的元素多达50个, 如机构代码、馆藏代码、编目号、学名、界、门、纲、目、科、属、种、亚种、鉴定日期、采集号、场地号、采集者、采集日期、国家、性别、个体数目、相关编目条目等。
Darwin Core是一个广泛使用的重要国际化标准, 由生物多样性信息标准化组织(TDWG)[17]管理。该组织前身为分类学的数据库工作组, 是一个非盈利的科教机构, 隶属于国际生物科学联盟组织。
Darwin Core的各种发布版本如表3所示, 目前最新版本的数据项包括[18]: 记录级元数据19项、发生信息元数据22项、材料样品信息元数据1项、事件信息元数据15项、位置信息元数据44项、地理上下文信息元数据18项、标识信息元数据8项、分类信息元数据33项、补充词汇元数据16项。
| 表3 Darwin Core的各种版本[19] |
DDI(Data Documentation Initiative)[20]是一个描述社会和行为科学数据文档的标准, 该标准提供了内容交换和信息保存的格式标准进而可以促进文档间的共同操作。DDI标准采用XML组织, 由国际数据文档倡议联盟组织(DDIA)[21]负责开发。
DDI于1995年首次发布, DDI 2.0版在2002年发布, 它以文档为中心, 主要聚焦于传统社会科学的标准词库元素, 3.1版本在2009年10月发布, 聚焦于数据和元数据的生命周期。其设计不仅考虑获取信息, 同时考虑采用机器可读的格式去表达数据的处理、发现及分析全过程。
2014年2月15日, DDI 3.2版本发布。它包括覆盖DDI生命周期的22 项Namespaces和42项XML Schemas。同时包括1 181项元素, 473项复合元素, 68项简单类型, 71项元素组, 7项属性和70项属性组。其中超过一半的XML Schemas和全部的元素组、属性、属性组用于支持XHTML或DC元数据使用[22]。
TEI(Text Encoding Initiative)[23]是社会科学、语言和人类学领域的元数据标准。该标准于1987年首次发布。到1994年已经发布了多个版本。早期的版本基于SGML组织, P4版本同时基于SGML和XML发布。当前版本是P5仅采用XML组织, 其中融入了XSLT和XQuery标准。
TEI适用于对电子形式的全文的编码和描述, 同时也规定了可供数据交换的标准编码格式, 使用SGML 作为编码语言。TEI定义了一套XML标签标记文件, 包括大约500个元素。这套标签具有很大限度的灵活性、综合性、可扩展性, 能支持对各种类型或特征的文档进行编码, 可以表达任何时期的任何文本。尽管在某些特定的文档里只应用了很少部分的标签。TEI的XML标签划分为两部分, 一部分用于表达文本的细节(例如作者、目录信息和溯源信息等); 另一部分用于描述文档的结构(节、头等)。
当前大量项目中使用TEI标准, 它对于数字化学术研究产生了重要影响。该标准的发展受国际文本编码倡议联盟组织(TEIC)[24]监督。
ISO 19115是一个由ISO技术委员会TC 211[25]开发的一项地理科学的国际元数据标准。它的作用是为数字化的地理科学数据集的描述提供一个清晰的过程。为了实现这个目标, 该标准定义了一套通用的专业术语, 解释和扩展了地理学的元数据。
ISO 19115第一版本于2003年发布。为了兼容早期的正规标准, 它定义了一套通用的专业术语, 新的和现存的格式通过各自发布元数据Profiles或者推荐元数据标准子集的形式进行扩展。ISO 19115是地理科学信息标准集之一, 受ISO/TC 211组织监督。
ISO 19115: 2003主要元素共409项, 其中元数据包数据字典包括333项, 数据类型信息共76项。具体分类统计如表4所示:
| 表4 ISO 19115: 2003 主要元数据项分布[26] |
数字化地理空间元数据内容标准CSDGM是地理空间科学领域的一项美国国家标准。该标准首次发布于1994年8月[27]。当前版本为1998年校验的版本。为了支持数字化的地理空间科学数据的发现、获取和转换, CSDGM提供了一套通用的专业术语定义。CSDGM由美国联邦地理数据委员会(FGDC)[28]负责维护。因此也通常被称作FGDC元数据标准。
在美国, 使用CSDGM标准记录地理空间数据集已经被明确写入所有联邦法律中。因此第一版CSDGM标准在全世界范围内广泛传播。CSDGM是可扩展的: 它的Profiles可以包括任何适于特殊应用领域及类型元数据的扩展元素。
第二版的CSDGM[29]规定:
(1) 自定义元数据的复合元素和数据元素;
(2) 提供所有实体/元素的缩写名或标签;
(3) 重写第4部分(Spatial Reference)使执行简化;
(4) 大多数的域被扩展, 以便可接受“ 自由文本” 作为输入值;
(5) 制定了完整的术语表。
CSDGM包含7个主要子集(Section)和3个辅助子集(如表5所示), 共有460个元数据实体(含复合元素)和元素。第8-10个辅助子集支持第1-7个主要子集, 辅助子集提供了引用、时间、联系信息的共同的方法, 但不能被单独使用。
| 表5 CSDGM元数据分类信息 |
CSDGM规定了三种性质的子集、复合元素和元素。这三种性质包括:
(1) 必需的, 即必需提供的信息;
(2) 一定条件下必需的, 即如果正在建立的元数据包含某子集、某个实体或某个元素说明的特征, 则必需提供的信息;
(3) 可选的, 即该信息是可选的, 由用户决定是否将其包含在元数据文件中。
对于以上概述的科学数据元数据标准, 进行归纳统计, 如表6所示:
| 表6 几个典型元数据标准比较分析 |
通过比较以上典型的元数据标准, 笔者发现目前各个学科领域及机构知识库的元数据标准格式、组织、表达方面差异明显, 这为科学数据的集中统一管理与服务带来以下问题:
(1) 由于学科领域元数据的差异, 科学数据难以集中统一管理。目前主要依靠复杂的映射转换模式, 进行不同元数据标准间的互操作。
(2) 由于学科领域元数据的差异, 科学数据难以集中统一服务, 以数据检索为例, 必须进行多个标准间的转换映射才能实现相关的集成检索。
(3) 尽管Dublin Core (DC)作为一种通用的元数据标准可以被广泛映射, 但DC及其扩展元数据项比较局限, 不足以满足科学数据集中管理与服务的需求。
在这种背景下笔者考虑基于现有的学科领域及机构知识库元数据标准, 利用统计的方法, 设计一套初步指导科研数据通用化管理的元数据最佳实践— —
“ 通用科研元数据标准” , 便于实现科学数据的规范化管理与集中服务。这种元数据标准要能比DC更深入表达科学数据的特征与关系。
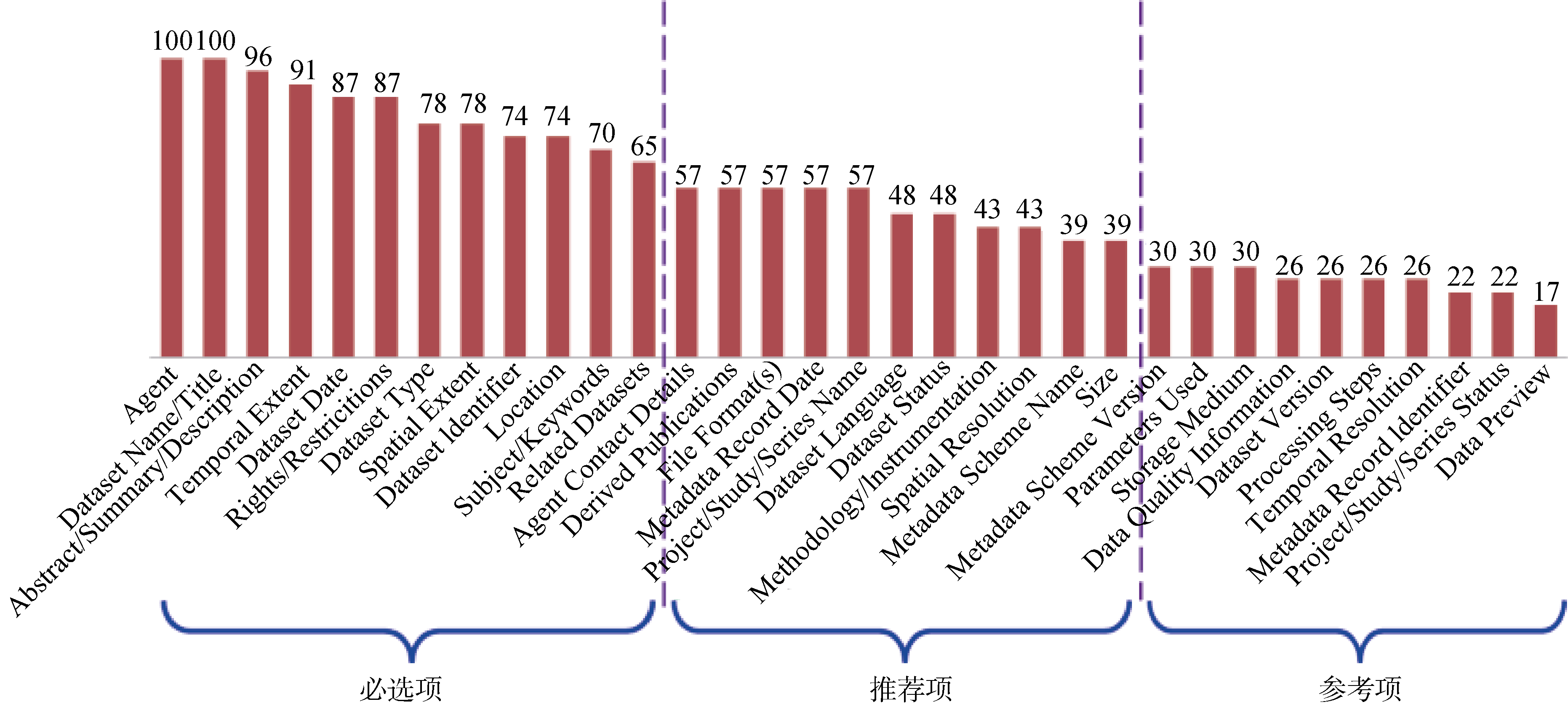
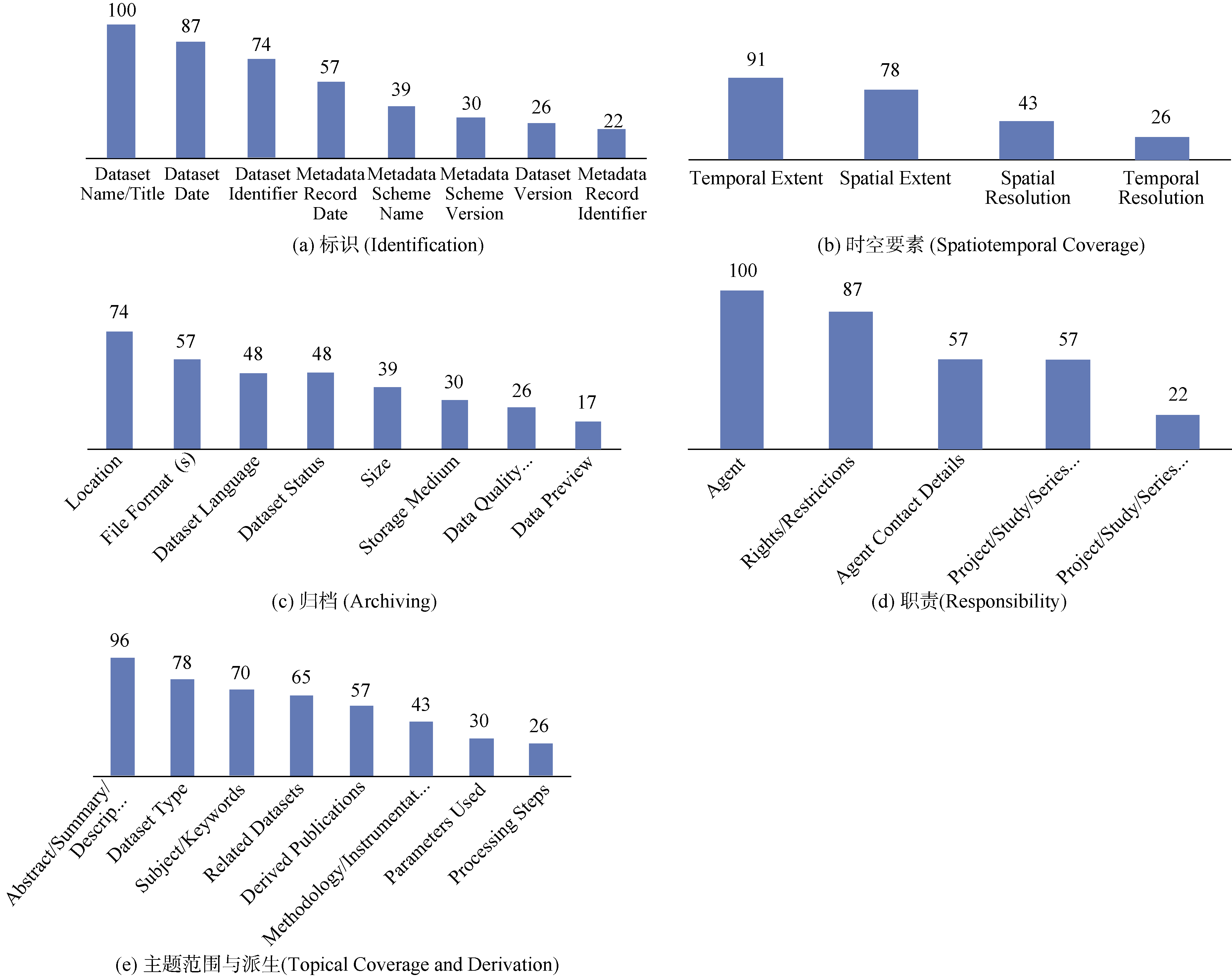
如前面分析显示, 各领域元数据标准间差异明显, 但通过文献[30-31]的研究结果, 发现各元数据标准其构成要素间也存在很多相似性, 可以依据此构建通用科学数据元数据规范, 因此笔者在其所研究的元数据标准的基础上, 进一步扩展了7项目前应用广泛的元数据标准; 累计统计的元数据标准共22项, 如表7所示(其中16-22项为扩展元数据标准, 覆盖了地学、生物、物理、空间、社会与人文等多个学科领域)。统计过程中对于相似的元数据表述项进行统一规范化。
| 表7 22项参考元数据标准统计 |
面向学科领域的科学数据元数据促进了科研的发展。本文简单概述了元数据的概念、分类及特点, 通过选取生物、地球、人文等学科领域典型应用的元数据标准进行实例分析, 重点对国际科学数据元数据标准的研究及制定情况进行述评。内容上还不够全面深入, 但是从中不难得到一些有益的启示: 科学数据元数据对于数据管理和数据服务(发现数据、使用数据等)都是极为必要和重要的。它是数据组织与应用的基础核心。
同时, 本文对目前科学领域众多、元数据标准复杂多样, 进而带来的数据管理与服务方面的挑战进行了概要分析, 并参考已有的研究进展, 扩展并归纳了一种基于统计的通用科学数据元数据项标准。希望这个标准框架能够对于统一的科学数据管理与应用服务提供有意义的参考和启发。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|