

{kind=link}
{kind=link}
{kind=link}
{kind=link}
产品评论中的隐式属性抽取研究*
[张莉1  , 许鑫
, 许鑫2 ]
, 许鑫|
|


作者贡献声明:张莉: 数据采集、清洗和标注, 完成整体框架和实验, 论文起草及最终版本修订; 许鑫: 修改论文, 提出建设性的意见和关键问题的解决思路。
[Objective] Opinion mining in product areas draws more and more attention and becomes a hot research topic. The outcome of opinion mining can be used widely just like harmful information filtering, society opinion analysis, user consumption guidance and product improvement and so on. Implicit feature identification plays an important role because implicit features are common in network comments and the identification of them is difficult. [Methods] This paper uses the comments against a certain automobile brand which only have the explicit features to get refined multi-POS opinions and generate opinion clusters by using Synonyms Forests. Meanwhile identify opinions based on field common phrases. Dictionary in the form of {Feature, Opinion, Weight} is generated by using features and opinions, and the weight is calculated. Then deploy explicitly multi-strategy property extraction algorithm based on a dictionary and consider similarity of the opinions in unmatched comments including implicit features and dictionary. [Results] Implicit features can be extracted effectively and the F-value is 75.55% which reaches the good result of the identification of implicit features. [Limitations] Data labeling is a time-consuming job. [Conclusions] Experiment of the new algorithm shows positive result and has some practical value.
随着互联网技术和大数据的飞速发展以及普通用户、政府和商业公司等对数据内涵的需求越来越高, 意见挖掘(Opinion Mining)研究如火如荼。Kim等[1]认为意见(Opinion)由4个元素组成, 分别是主题(Topic)、持有者(Holder)、陈述(Claim)和情感(Sentiment), 这4个元素之间存在着联系, 即意见持有者对某主题发表具有某情感的陈述, 目前意见挖掘的主要任务是抽取评价对象(Feature)、意见(Opinion)、评价对象与意见的搭配及意见的情感倾向(Positive褒义和Negative贬义等)。评论句早期抽取的评价对象通常是对象本身, 随着发展逐渐开始抽取粒度更细的评价对象即对象的属性, 例如关于奥迪Q5的评论句“ Q5的动力很强劲, 外观也招人喜欢。” , 抽取的评价对象为Q5的两个属性“ 动力” 和“ 外观” , 属性抽取的难度高于对对象的抽取。
在产品领域, 用户可以通过意见挖掘的结果获知商品各方面性能的评价从而指导自己的消费, 商家则可以知晓用户对产品各方面属性的评价从而改善商品质量或服务, 因此产品领域的意见挖掘成为信息检索和自然语言处理等相关领域的一个热门话题。
而因为用户在网络上使用的语言比较自由, 因此隐式属性(Implicit Feature)在网络评论中很常见, 例如“ Q5买不起啊, 太贵了。” , 这个句子中的意见为“ 贵” , 属性没有直接出现, 实际应为“ 价格” , 这种非字面的隐含在句子中的属性称为隐式属性, 而待评价的对象或待评价的对象属性(简称属性)如果是直接包含在句子中的, 这种属性则被称为显式属性(Explicit Feature), 例如第一段中Q5的“ 动力” 和“ 外观” 。在本文所抓取的爱卡汽车论坛的几千条用户评论中有15.99%的评论句中包含隐式属性, Hai等[2]使用的手机论坛的真实语料中有20%不包含显式属性, 隐式属性的抽取对意见挖掘系统和问答系统等的精度提升有重要帮助, 但其抽取较为困难, 目前的抽取结果尚未达到理想的程度。
Liu等[3]最早提出了构建显式的Feature-Opinion对, 通过此映射关系抽取隐式属性的思想。目前隐式属性的主要抽取策略仍然是先通过某种算法生成显式的Feature-Opinion对, 再寻找包含隐式属性的评论句中的意见以确定相应的属性。常见的算法有基于领域数据和字典、K-means等聚类算法以及正则化的PLSA方法等。例如Zhuang等[4]对电影评论中的特殊位置和长度的短语进行固定的属性确定, 并根据某些意见词的常见使用习惯将它们与电影相关的属性匹配构建Feature-Opinion对; Su等[5]在汽车领域定义了若干类属性, 通过PMI-IR算法对词典中的形容词及它们的同义词确定其对应的属性从而形成Feature-Opinion对, 基于这些匹配关系通过包含隐式特征的评论句中的形容词确定其对应的属性; Su等[6]又通过迭代地在事先创建好的属性和意见词上应用相互加强聚类算法得到属性簇和意见簇, 将单个属性和意见词之间的关联扩展到属性簇和意见簇之间的关联从而形成属性和意见之间的关系对; Hai等[2]使用句法结构产生属性和意见之间的共现矩阵从而产生关联规则, 并使用K-means算法进行属性聚类从而生成Feature-Opinion对; Zhang等[7]提出基于关联的共现矩阵方法, 不仅利用属性和意见之间的关系, 而且还利用特征和一些与特征有联系的词; 仇光等[8]提出一种基于正则化思想的新主题建模框架, 并在该框架下抽取评论信息中的Feature-Opinion对; Poria等[9]提出一种基于规则的方法, 利用常识性的知识和句子依存树来检测英文中的隐式和显式属性; Xu等[10]则通过扩展流行的主题模型LDA构建显式主题模型从而进行隐式属性抽取。
这些方法基本将评论句中的属性和意见词做了限制, 例如文献[5]中规定了动力性、操控性、外观、内饰、经济性、工艺性和市场性这7个与汽车相关的属性, 文献[8]中规定了Sound、Settings、Battery和Screen这4个手机、电视机、MP3播放器和数码相机领域的代表属性, 其他文献也大多选择形容词或带有领域特征的一些词作为初始的意见词, 限定了待评价对象和意见词的范围, 完整性和扩展性较差。针对这些问题, 本文提出基于多词性精简意见词簇和领域常用语的属性词构建“ {属性, 意见, 权重}” 字典抽取汽车评论句中隐式属性的方法, 同时考虑了基于相似度对意见词进行聚类等方面的必要性, 在利用字典中的意见确定隐式属性时又考虑了词性和句法结构等特征。
与主流方法一样, 本文同样利用包含显式属性的评论句构建若干个Feature-Opinion对(规则), 通过隐式属性评论句中的Opinion获取其隐藏的属性, 但是本文所使用的方法与现有方法相比主要有以下不同:
(1) 基于领域常用语对属性词进行聚类, 准确性更高;
(2) 意见词使用了动词、名词、非ADV结构的形容词和副词以及它们的组合, 并且考虑了不同词性的优先顺序, 这比以往方法大多只考虑一两种词性并不考虑词性的顺序在完整性和健壮性上有了提高;
(3) 在创建好Feature-Opinion规则后匹配意见词时使用相似度函数, 这种方法大大提高了匹配率。
利用包含显式属性的评论句构建字典, 字典的形式为:
{ 属性 意见 权重 }
实际构成若干条规则:
属性 → 意见 (权重)
(1) 多词性精简意见词簇的确定
Su等[5]利用PMI-IR算法对包含隐式属性的评论句中的“ 漂亮” 、“ 强劲” 和“ 昂贵” 等形容词确定隐式属性, Hai等[2]确定非状中结构(ADV)的形容词或副词作为候选意见词集, 但是实际其他词性的词也有可能是意见词, 例如:
例句1: 专门听了47.58的音响, 还可以
例句2: 刚提车的10多天一侧玻璃升降和后视镜的收放有异响
例句3: 音响很有质感!
例句1中的意见词是“ 可以” , 其词性为动词(v); 例句2中的意见词是“ 异响” , 其词性为名词(n); 例句3中的意见词是“ 有质感” , 其词性为动词+名词(v+n), 类似例句3这类意见词中包含这些词性的组合在评论句中也较为常见。为了提高字典的精确率、完整性和鲁棒性, 本文选择手工标注含显式属性的评论句中的意见词, 这些词的词性为非ADV结构的形容词和副词、动词和名词以及它们的组合, 同时为了提高后续利用词典抽取隐式属性的准确率, 在标注时尽量选择意见词的精简方式, 忽略一些修饰用的词, 如“ 十分好看” 中的“ 十分” 等, 并对否定形式进行特殊标注。
另外, 有些意见词是同义词, 如“ 好看” 和“ 美丽” 、“ 澎湃” 和“ 磅礴” 以及“ 结实” 和“ 扎实” 等, 如果将它们分开处理, 则后续的权重和意见词匹配都会受影响, 因此本文利用哈尔滨工业大学社会计算与信息检索研究中心同义词词林扩展版[11](简称同义词词林)基于同一词条属于同一含义这个基本特性将意见词中的同义词进行聚类, 同时将未在语料库中出现的同义词作为意见词的补充, 最终形成意见词簇。
(2) 基于领域常用语的属性词确定
文献[5, 7-8]选择了一些领域相关的属性词作为显式属性, 但在实际的评论句中不仅包含这些领域相关的属性词, 还常常会包含其他一些名词或名词词组。在显式属性确定上本文采用了两个步骤:
①构建属性词领域常用语表。
如车、外观、空间、舒适性、发动机、油门、刹车等。
②按领域常用语表标注并进行扩展。
例句4: 座椅还算舒服, 摩擦力一流, 电动靠腰也挺好
例句5: 座位是个问题, 感觉很宽, 驾驶位没啥包裹感
例句4和例句5中包含了“ 座椅” 和“ 座位” 属性词, 它们其实表达了同一含义, 因此本文按照领域常用说法进行标注, 将例句5中的属性词标为“ 座椅” , 这样在后续意见词与属性间的权重确定时可以更准确, 类似的词还有很多, 例如“ 外观” 、“ 外形” 和“ 样子” 等, 标注时根据领域常用语将它们都统一标为“ 外观” 。
(3) 权重的确定
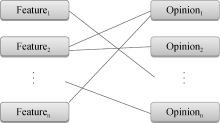
在评论产品属性时, 说法会有很多种, 例如形容汽车的外观时常常使用“ 大气” 、“ 漂亮” 和“ 时尚” 等词, 但是“ 漂亮” 这样的词也可以用来形容汽车的内饰, 同时, “ 漂亮” 或“ 大气” 等词一般不会用来形容“ 发动机” 和“ 油门” 等属性, 因此可以基于语料库确定某些意见词簇对某个属性的贡献程度。例如对于属性和意见词簇搭配如图1所示:
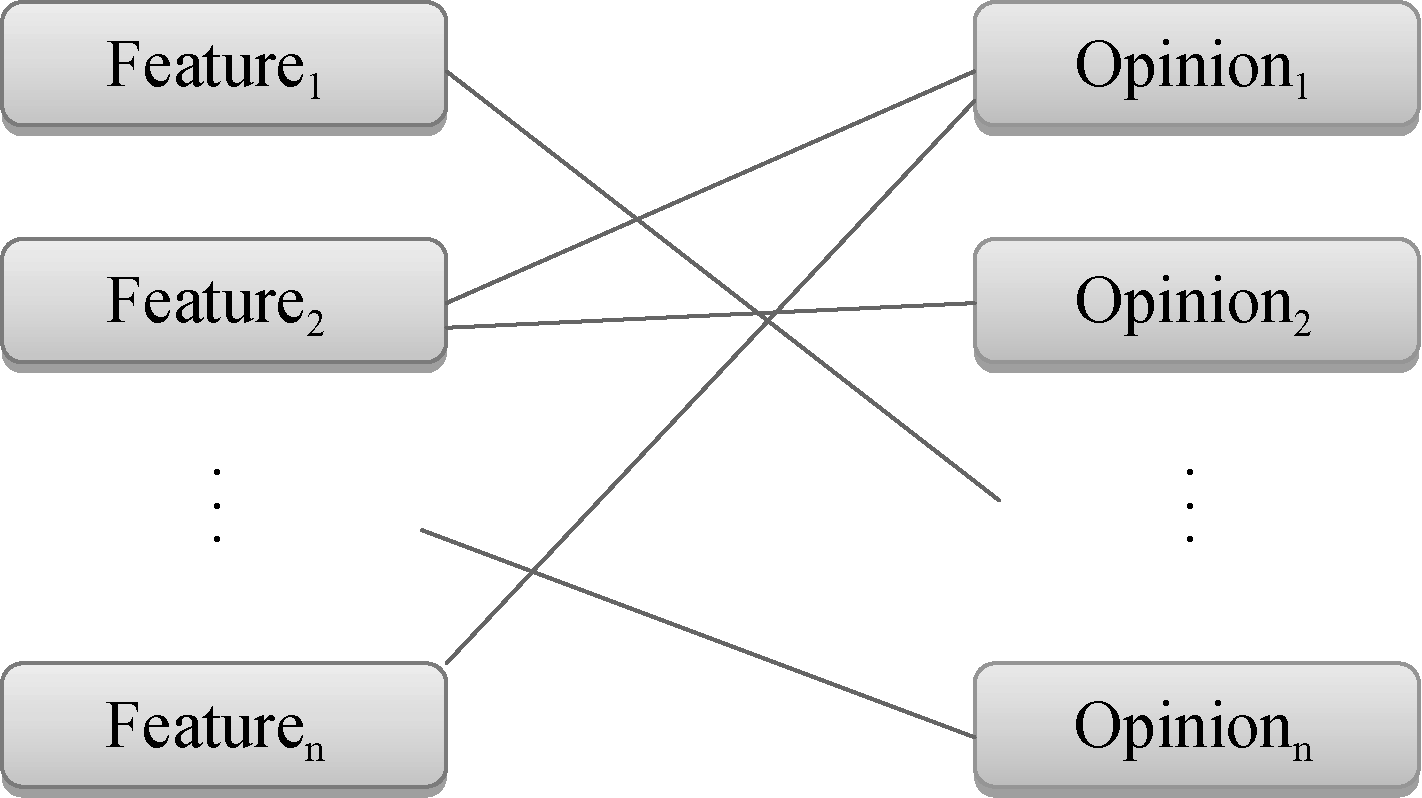 | 图1 属性-意见匹配关系 |
对Opinioni来说, 假设其与各Feature之间的匹配总次数为N, 与某一个Featurej的匹配次数为k, 则基于此属性和意见簇(同一意见簇内的意见词若对应同一属性, 则按总计值计算)构建的一条记录为:
{ Featurej, Opinioni, k/N }
分数越高表明该意见词出现时对应属性的可能性越大, 并且对于任意一个意见词簇, 与其匹配的所有属性满足以下条件:
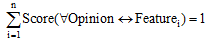
对于包含隐式属性的评论句来说, 可以通过寻找句子中的意见词匹配已创建的字典, 获取相应的隐式属性, 由于评论句的复杂性, 因此实际处理过程中往往需要考虑多方面的问题。
(1) 意见词的确定
意见词的确定可以仍然使用3.1节中创建字典时使用的若干词性和句法结构要求的词或短语, 并且由于形容词表示意见的情况最多, 所以在匹配时优先考虑形容词, 同时还需要基于不同的词性选择不同的阈值进行处理。
(2) 意见词匹配算法
在实际处理过程中不能仅简单地进行匹配, 因为句子中意见词的复杂程度不一, 如果进行完全匹配的话往往会导致很多意见词无法匹配的情况。例如对于以下的评论句:
例句6: 坐进去就感觉很美观
例句7: 不是我说, 一钻进去就觉得美观大方!
例句8: 试坐了下感觉包裹性一般, 要再考察下
例句9: 我坐了下感觉还行, 包裹性不错
例句6和例句7、例句8和例句9中两组形容词对应的属性都一样, 但两者不能完全匹配, 这种情况下如果给出一个所有情况都不匹配后的默认值例如“ 车子” 则过于简单。可以看到这两组词比较相似, 由此本文认为只要两者的相似度大于或等于某个阈值则可以认为两个意见词对应的属性是一致的。利用Jaccard相似系数计算词对之间的相似度。
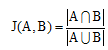
样本A和样本B是两个n维向量, 这里是两个词或短语, 所有维度的取值都是0或1。如果按照两个词对(首先进行分词)的向量为A(1 0)和B(1 1)(例如J(“ 美观” , “ 美观大方” ) = 1/2, )、A(1 1 0)和B(1 0 1)(例如J(“ 包裹性一般” , “ 包裹性不错” ) = 1/3)等考虑, 本文设置1/3为阈值。
(3) 算法框架
创建好字典后, 将网络上爬虫抓取的隐式评论句分词, 将每一条评论句按预定词性和句法选择意见词获得候选意见词集, 利用多策略融合算法与字典中意见词进行匹配获得相应的属性。
每一条评论句中的候选意见词在字典中进行意见词匹配时均使用多策略融合算法, 该算法涉及词性、句法结构和相似度等内容, 具体的算法步骤如下:
①将词性为非ADV结构的形容词(包含形容词的词组)的候选意见词(可以有多个)与已经创建好的字典中的意见词进行匹配, 选择完全匹配和相似度大于阈值的记录, 根据权重选择属性; 如果步骤①未找到合适的属性, 则转步骤②;
②选择大于一定阈值的余下的词或短语(非ADV结构的副词、动词、名词词组、形容词+名词等)按顺序进行匹配, 与步骤①一样进行匹配, 抽取合适的属性;
③如果步骤②也未抽取成功, 则将属性设为默认值“ 车子” 。
本文采用的数据为爱卡汽车论坛上某品牌汽车2013年3月至2015年3月的5 077条用户评论, 使用哈尔滨工业大学社会计算与信息检索研究中心的语言技术平台LTP[11, 12]进行分词和句法结构分析, 由于LTP对句子的长度有限制, 因此去掉超长的231条句子, 最后得到4 846条评论句。在4 846条评论句中, 只包含显式属性的有4 076条, 其他包含隐式属性的有770条, 隐式属性评论句约占所有评论句的15.9%。
(1) 生成字典
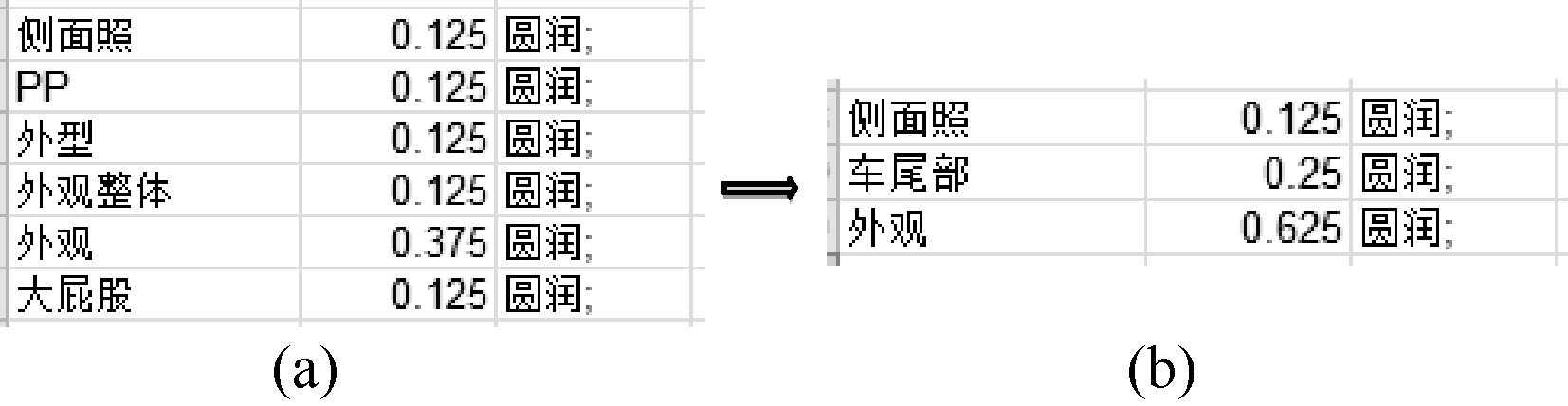
利用基于领域常用语的属性词和多词性精简意见词进行标注, 通过Python编写的程序, 利用同义词词林进行意见词的聚类并计算权重。结果样例如图2和图3所示。图2(a)中显示的是评论句中原始属性、意见词和权重的结果, 图2(b)则是考虑了领域常用说法后重新标注后的结果, 本文利用Python程序将它们直接写入CSV文件中, 可以看到“ 外型” 、 “ 外观整体” 和“ 外观” 都统一标注成“ 外观” , “ PP” 和“ 大屁股” 统一标注成“ 车尾部” , 属性统一标注后权重利用3.1节中的公式进行计算。
 | 图2 基本领域常用词的标注及权重变化 |
 | 图3 利用同义词词林聚类 |
进一步利用同义词词林进行聚类, 图3(b)是同义词词林扩展版中的一条记录, 其中的词都是同义词, 图3(a)中的第一行(属性为“ 做工” )和第三行(属性为“ 内饰” )都是因为同义词“ 精致” 和“ 精细” 均对应了同一个属性“ 做工” 和“ 内饰” , 由此进行了聚类, 以第一行为例, 原先Feature-Opinion的对应关系有“ 做工” -“ 精致” 和“ 做工” -“ 精细” 。
本文还将未在语料库中出现的同义词作为意见词的补充形成意见词簇。
(2) 多策略隐式属性抽取
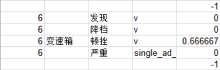
对770条含隐式属性的评论句利用LTP进行分词和句法分析, 按照3.1节和3.2节中要求的词性和句法形成候选意见词集。将候选意见词逐句按照3.2节所述的策略与词典进行计算和匹配。样例如图4所示:
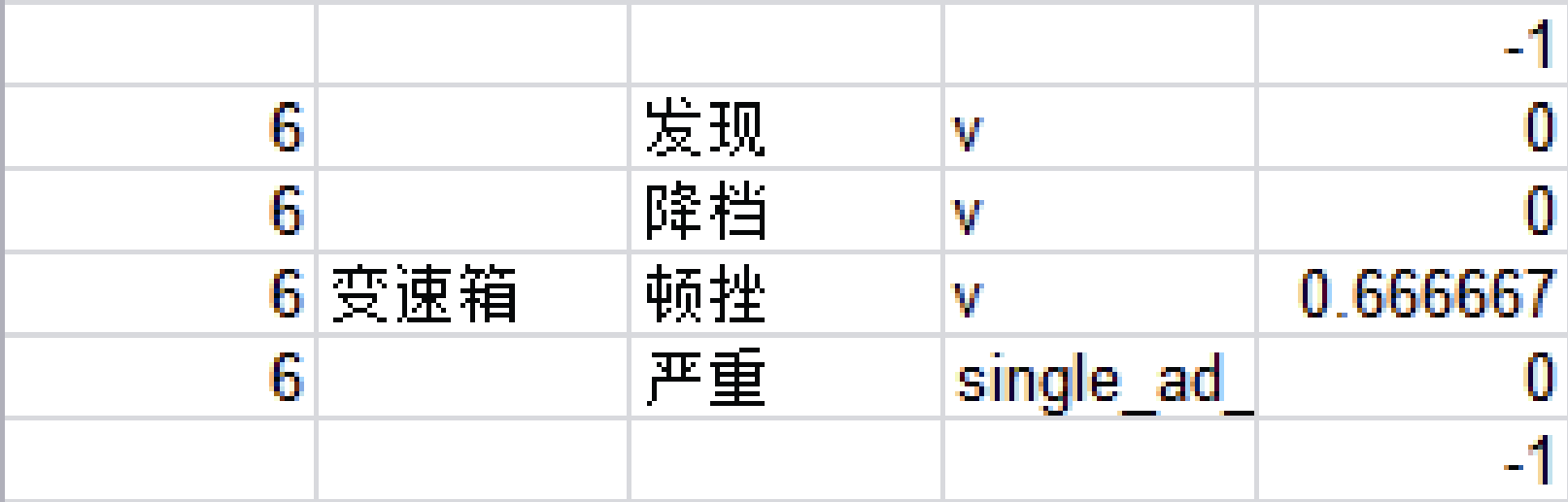 | 图4 正确的隐式属性抽取例 |
图4中“ 发现降档顿挫” 为三个动词组合成的短语, 因为它与字典中的“ 顿挫” (属性为“ 变速箱” )的相似度为1/3, 因此对应的属性为“ 变速箱” , 而句子中的形容词“ 严重” 未找到匹配对象, 另一方面“ 变速箱” 和“ 顿挫” 的权重为0.666667, 超过设定的阈值, 因此本句的属性标注为“ 变速箱” , 这是一个正确的标注。
(1) 实验结果
770条含隐式属性的评论句中实际包含792个隐式属性, 共标注出了786个结果, 其中正确的有596条, 精确率和召回率如表1所示:
| 表1 实验结果 |
(2) Baseline
互信息和信息检索算法(PMI-IR算法[13])通过搜索引擎的返回结果来比较词与词之间的共现, 词与词之间的PMI(word1, word2)定义为:
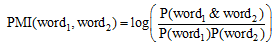
文献[5]利用PMI-IR算法获取评论句中的隐式属性, 本文也以此作为Baseline。自编Python程序查找含隐式评论句中的所有候选意见词与字典中的属性在百度上搜索后的共现情况, 实验结果在所有792个隐式属性中标出非“ 多媒体系统” 的32个属性, 正确抽取成功的仅有8个, 其余所抽取出的隐式属性均为“ 多媒体系统” 。分析可能的原因是因为多媒体系统本身在百度所有文档中的包含比例非常高, 且其可能在一些推荐广告中也会有, 导致搜索返回的页面数高, 因此PMI值非常高。为了避免这种情况, 简单地将“ 多媒体系统” 设为不可见属性重新进行实验, 共正确抽取了132个属性, 召回率提升至16.7%, 仍然不甚理想, 进一步分析其原因是PMI-IR算法需要大量的语料, 而本文只使用了4 000多条评论句, 所以效果较差。
(3) 结果分析
通过实验结果可以看到, 本文算法效果较好, F值达到75.55%, 现有公开的算法中较好F值一般在75%左右, 且本文算法实现简单, 计算代价小, 因此具有一定的实用价值。但是算法中还存在一些问题, 还有一定的提升空间, 主要问题集中在以下三点:
①由于语料不足, 导致有些Feature-Opinion对出现次数很少, 有些出现次数较多也存在权重计算值相近或相同的情况。
②一些常见词如“ 好” 、“ 漂亮” 、“ 喜欢” 和“ 不舒服” 等意见词可与很多类属性搭配, 导致计算时常常无法确定明确的属性。
③评论文本中网络用语灵活, 如“ 顿挫” 在字典中出现, 而含隐式属性的评论句中出现了意见词“ 顿挫感” , 它们虽是两种说法但其实表达了同一种意思, 但分词工具有自己的规则, “ 顿挫感” 会分成“ 顿” 和“ 挫感” , 利用本文的相似度算法这种情况的相似度不会超过1/3, 因此无法通过相似度寻找到相应的属性。
这几个问题的解决不仅需要通过丰富领域语料库提高典型搭配的权重, 也需要进一步细化和改善字典构建和相似度算法设计, 从而提高算法性能。
本文利用包含显式属性的汽车评论语料构建形如“ {属性, 意见, 权重}” 的字典, 并以字典为基础利用多策略隐式属性抽取算法抽取隐式属性, 实验结果表明本文算法效果较好。将从以下方面开展后续研究:
(1) 补充该品牌相关的评论句, 丰富低频的搭配关系, 加强字典中典型搭配的体现。
(2) 对现有的相似度计算方法进行改进, 以期更适应多种形式的意见词。
(3) 将本文提出的算法在其他领域进行实验, 检测方法的领域适应度, 并进一步考虑其是否可以用在通用领域。
(致谢: 本研究使用了哈尔滨工业大学社会计算与信息检索研究中心研制的语言技术平台LTP, 特此感谢!)
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|