{kind=link}
{kind=link}
基于比较句的网络用户评论情感分析*
[彭浩1 , 徐健1  , 肖卓
, 肖卓2 ]
, 肖卓|
|


[Objective] In order to select competitive products in the market and mine useful information for both enterprises and customers. [Methods] This paper proposes a model of sentiment analysis based on comparative sentence, which can compute feature scores of comparative products and visualize the comparative relations between these products. In order to verify the effectiveness of this model, an experiment on smart phones is conducted with the help of Baidu search engines. [Results] The experiment selects 9 pairs of competitive smart phone products from 28 pairs, thus the results can help smart phone enterprises identify competitors. And also visualize the comparative relations between these products and provide suggestions for customer purchase. [Limitations] The accuracy of feature extraction is not high. The recognition rate of comparative sentence in this model need improvements. [Conclusions] The result of this experiment is consistent with facts, which proves the effectiveness of this competitiveness analysis mothed presented in this paper and its great value to enterprises.
比较句是一种常见的表达方式。通过比较, 人们能直观表达自己的情感倾向。在比较句中一起出现的产品可以视为竞争产品, 企业可以从相关产品的比较句中, 识别竞争对手, 发现自身产品的不足, 提升产品竞争力。同时, 这些比较句可用于分析不同产品的特征优劣, 客观地为消费者提供参考意见。
以往的情感分析研究多基于用户评论语句[1, 2], 而非比较句, 有的研究通过机器学习的方法建立分类器, 以判断评论的有效性, 帮助网站识别虚假评论; 也有研究[3]通过分析商品评论中的用户情感倾向, 统计不同用户在同一件商品上的情感倾向, 以此反映商品优劣。然而用户的情感具有主观性, 针对同一个事物, 不同的个体会有不同的情感表达。单独分析不同用户的情感倾向得出的结论不够客观。例如, 在考虑上市时间等因素的情况下, 苹果手机获得100个好评, 不一定就比获得70个好评的三星手机强。
比较句正好弥补了这个缺陷, 通过对比关系反映出的用户情感倾向具有更高的可信度。例如: 比较句“ 苹果手机外观更好看, 但是比小米手机价格贵太多” 就明确表达了苹果和小米手机在“ 外观” 和“ 价格” 上的差异。因此, 基于比较句的情感分析将更加客观地得出竞争产品间的差异。社交网络中有着丰富的比较句资源, 这对于文本挖掘、网络用户情感分析具有非常重要的价值, 如何从比较句中挖掘出有价值的信息已经成为数据挖掘领域亟待解决的问题之一。
国内外学者的情感分析研究大多集中在句子层面和属性层面, 句子层面包括判断用户评论的极性[4]、识别评论的有效性[5]、基于机器学习建立评论分类模型[6]等。属性层面包括利用中文分词[7]、词性标注等工具(如ICTCLAS[8]、Stanford Parser[9, 10])进行产品特征识别。这些研究使用到的技术可分为非监督方法[11]和监督方法[10]。前者经常创建一个情感词典, 并通过统计正向和负向短语的数量确定极性[3, 4, 5, 6, 7]。后者则使用标注的数据训练分类器[12](如Naï ve Bayes, Maximum Entropy或SVM)预测未标注的数据。
近年来, 研究者逐渐认识到比较句的情感优势, 开始利用各种方法进行比较句情感分析研究。Xu等[13]将比较句定义为比较关系, 并提出一个新颖的图模型抽取和可视化消费者评论中产品间的相对关系。黄高辉等[14]在比较句的识别过程中, 利用 CRF 算法与规则相结合的方法抽取比较句, 取得了很好的效果。杜文韬[15]则在微博情感倾向研究中利用关联特征词表进行比较句识别, 利用CRF模型进行比较关系抽取, 并利用情感词典对比较实体进行倾向性计算, 取得了一定的效果。这些研究利用比较句定量分析了用户情感倾向, 得出的结论相对客观。
然而, 上述研究多注重于比较句抽取算法的实现, 对于比较句应用方面的研究相对较少。李建军[16]在比较句与比较关系识别的基础上, 提出产品评论挖掘的框架和流程, 实现在产品评论挖掘中的比较句与比较关系识别的应用。
本文从产品的角度出发, 利用比较句筛选行业竞争产品, 帮助企业识别竞争对手; 同时通过比较句计算竞争产品的特征得分并将其可视化, 以此分析竞争产品的特征差异, 给消费者提供参考意见。
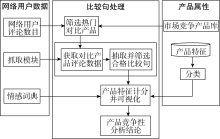
对于企业来说, 市场竞争日益激烈, 如何快速识别竞争对手意义重大。本文将“ 热门对比产品” 定义为“ 具有很强对比性的热门产品” 。为了筛选热门对比产品、可视化竞争产品的特征差异, 本文提出基于比较句的情感分析模型, 如图1所示:
 | 图1 基于比较句的情感分析模型 |
图1展示了比较句情感分析模型的思路, 该模型由“ 筛选热门对比产品” 、“ 抓取模块” 、“ 抽取并筛选合格比较句” 、“ 产品特征计分并可视化” 、“ 产品竞争性分析结论” 等模块组成。本文旨在通过该模型识别热门对比产品, 帮助企业识别竞争对手, 并分析产品特征差异, 给消费者提供决策支持。
(1) 筛选热门对比产品模块
为了筛选出竞争产品, 帮助企业识别竞争对手, 该模块根据搜索引擎检索到的网络用户对产品的评论页面总数, 结合具体的观测指标从市场竞争产品中筛选出热门对比产品。
(2) 抓取模块
为了获取网络用户评论, 该模块以“ A比B” 、“ B比A” (A、B指筛选出的某对热门对比产品)为检索词, 抓取搜索引擎检索结果的摘要, 将检索结果的摘要数据储存在本地文件中, 用于抽取热门对比产品的比较句。
(3) 抽取并筛选合格比较句
该模块将上一步获取到的摘要进行分句、分词、产品词替换、比较词替换, 统一每个分句中的产品词和比较词, 再用规则匹配方法抽取热门对比产品的比较句, 并将结果存储为本地文件。并不是所有包含比较词的句子都是合格的比较句, 例如: “ 更多 关于 苹果 比 三星 的 结果 请 点击 这里” 。该分句虽然包含比较词“ 比” , 但其不反映产品的特征对比关系, 因此需要筛选出符合语义且包含产品特征对比关系的比较句(如: “ 小米 手机 操作性 比 三星 好” )。
(4) 产品特征计分并可视化
为了定量分析竞争产品的特征差异, 本文将比较句按不同特征分类, 利用“ 特征计分” 模块结合情感词典计算热门对比产品在不同特征下的分值。为了直观展示竞争产品的对比关系, 模型利用“ 可视化分析” 模块对产品特征分值作图, 可视化其特征对比关系, 客观分析产品优劣, 为消费者提供参考意见。
综上所述, “ 基于比较句的情感分析模型” 旨在从各行业中筛选出热门对比产品, 帮助企业识别竞争对手; 模型通过比较句计算热门对比产品的特征得分并将其可视化, 从中挖掘出对企业和用户有价值的信息。
为了验证模型的效果, 本文利用百度搜索引擎, 以市场上的手机产品为对象展开实验, 选取8个产品词表: 苹果手机、三星手机、小米手机、诺基亚手机、中兴手机、华为手机、酷派手机、联想手机, 共组成28对产品和56个检索词(如“ 三星手机比小米手机” 、“ 小米手机比三星手机” 等), 实验过程如下:
(1) 观测指标
为了从28对手机产品中筛选出当前市场上的热门对比产品, 本文提出了两个观测指标, 其计算公式如下:
热门指数= pageCount(X比Y)+pageCount(Y比X) (1)
差距指数=
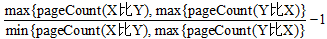 |
其中, pageCount (X比Y)、pageCount (Y比X) (均不为零时)分别指搜索引擎检索“ X比Y” 、“ Y比X” 得到的页面数(X、Y指产品名)。“ 热门指数” 等于X、Y正反对比检索到的页面总数, 指数越大, 两个产品的热度越高, [X-Y]越可能是一对热门产品; “ 差距指数” 等于X、Y正反对比检索到的页面数比值(不小于1)减1, 在产品对“ 热门指数” 较大的情况下, “ 差距指数” 越小, 说明两者的品质相当、可比性强, [X-Y]越可能是一对竞争产品。
为了验证比较句“ A比B” 表达A比B强的比例以及上述公式的可行性, 本文以“ 苹果手机-三星手机” 和“ 苹果手机-小米手机” 两组产品为例进行随机抽样实验, 利用4.2节的抓取模块随机抽取其对比检索结果的1 000条摘要, 人工计算A比B强的比例均值为82.5%, 明显高于50%, 说明公式(1)和公式(2)的合理性和可行性。实验结果如表1所示:
| 表1 随机抽样A比B强的符合比例 |
(2) 筛选过程及结果
利用本文4.2节的抓取程序, 批量从百度搜索引擎抓取56个检索词检索到的页面数①, 用脚本②计算28对产品的“ 热门指数” , 并按该指数降序排列, 结果如表2所示:
| 表2 28对产品的热门指数表 |
表2中, 包含“ 酷派手机” 、“ 诺基亚手机” 、“ 中兴手机” 的产品对热门指数都较小, 其前50%(14对产品)的热门指数非常高, 因此将前14对产品确定为“ 热门产品” 。同理, 计算28对产品的“ 差距指数” , 按该指数升序排列, 结果如表3所示(产品名均省略了“ 手机” 二字):
| 表3 28对产品的差距指数表 |
表3中关于“ 诺基亚” 的产品对“ 差距指数” 都偏大。比如“ 苹果-诺基亚” 的“ 差距指数” 为1.323870, 远远偏离0, 说明苹果手机比诺基亚手机强太多, 两者不属于竞争产品。这与常识相符, 从侧面反映了实验数据的合理性。同时, 表3中后10对产品的“ 差距指数” 与“ 1” 更接近, 表明后10对产品差距太大; 而前18对产品的“ 差距指数” 几乎为“ 0” , 说明其竞争关系非常强烈, 因此将前18对产品确定为“ 竞争产品” 。
实验从14对“ 热门产品” 和18对“ 竞争产品” 中筛选热门对比产品。比如产品对“ 三星-华为” 、“ 三星-中兴” 、“ 三星-联想” 、“ 三星-小米” 的“ 差距指数” 分别排第1、1、14、17, 属于18对“ 竞争产品” ; 其“ 热门指数” 分别排第4、11、5、3, 也属于14对“ 热门产品” , 因此将这4对产品确定为热门对比产品。
同理, 实验从28对产品中共筛选出9对热门对比产品, 并按共同竞争产品分成以下三组(省略“ 手机” 二字):
(1) 苹果手机竞争产品: [苹果-小米; 苹果-三星]。
(2) 小米手机竞争产品: [小米-华为; 小米-联想; 小米-中兴]。
(3) 三星手机竞争产品: [三星-中兴; 三星-华为; 三星-联想; 三星-小米]。
本实验开发的爬虫程序①以检索词构造检索URL, 通过百度搜索引擎抓取检索页面源码, 利用正则表达式提取页面源码中的检索页面数、下一页的URL, 递归爬取前N个检索页面, 并提取每页结果的摘要。
筛选出的9对热门对比产品共构成18个检索词(产品正反对比), 实验利用爬虫程序抓取每个检索词的前30页检索结果, 并把1对产品的2次检索结果的摘要数据写入同一文件, 用于比较句抽取。
由于比较句类型较多, 本文选取最具代表性的“ 差比” 类型中的“ 高下” 类别比较句进行研究。本实验利用规则匹配方法抽取比较句, 4.2节构造的检索词保证了产品摘要中都包含两个产品词和比较词“ 比” ; 然而“ 比” 字会出现在“ 对比” 、“ 相比” 、“ 总比” 等词中; 另外, 产品词如“ 苹果” 会有“ Iphone” 、“ ip” 、“ 水果” 等形式的变体。因此需要统一摘要中的产品词, 并把比较词替换为“ 比” 。
(1) 比较句抽取
实验利用“ 结巴分词” [17]工具, 结合用户词典①, 对摘要分句、分词, 替换产品词、比较词。使用的匹配规则为: 同时包含两个产品词和“ 比” 字的分句是一个比较句。用脚本程序②从抓取数据中抽取比较句, 每个比较句均包含两个产品词和比较词“ 比” 。程序以非句号对摘要分句, 因此筛选出的比较句多数只包含一个情感词, 比如: “ 三星 的 屏幕 比 苹果 大太多” 、“ 三星 的 简直 太水” , 这两个比较句本是一个包含“ 大太多” 和“ 太水” 两个情感词的比较句, 但是被分成这两个短句后, 每个短句只包含一个情感词, 这样便于计算特征得分。
(2) 合格比较句的筛选
观察上一步抽取的比较句, 发现有的句子虽然包含产品词、比较词, 但它不是基于产品特征的比较句, 比如分句: “ 毫无疑问 三星 的 规模 已 远远 比 苹果” 、“ 但是 苹果 并 不会 因此 而 消亡” , 虽然包含产品词“ 三星” 、“ 苹果” 和比较词“ 比” , 但语义上没有对比产品的属性特征, 因此人工去除这一类“ 伪比较句” 。实验得到各对竞争产品的合格比较句数如表4所示:
| 表4 热门对比产品比较句数量统计表 |
表4中各组产品筛选出的比较句数基本持平, 说明组内产品的品质相当, 竞争关系强烈。每对产品的比较句识别率约为10%, 比如产品对“ 三星手机-小米手机” , 其摘要共分为846个分句, 抽取、筛选得到80个比较句, 本文认为这个数目的比较句能够反映竞争产品的信息。
为了可视化分析竞争产品的特征差异, 需要识别产品的特征并计算产品的特征得分。
(1) 热门对比产品特征分类和特征抽取
实验观察到产品的比较句涉及到的特征很多, 若对每个特征单独计分, 则某些特征得分太低, 不具参考价值。结合人工, 将在所有产品对中被比较次数少于10次的特征, 按照产品属性聚成三个“ 大类特征” , 提高产品特征得分, 使得出的结论更具说服力; 并把在某对产品中被比较次数不少于10次的特征作为该产品对的“ 热门对比特征” , 从而识别出产品对的核心竞争点。实验选取的三个“ 大类特征” 如表5所示:
| 表5 大类特征分类结果 |
实验利用字符串匹配方法从分词后的比较句中抽取产品特征, 将特征名替换成其所属的大类名称, 比如将“ 知名度” 替换成“ 总评” ; 再从不含“ 大类特征” 的比较句中抽取该对产品的“ 热门对比特征” , 即比较次数不少于10次的特征。以4.1节筛选出的“ 三星手机竞争产品” 为例, 该组产品的“ 热门对比特征” 如表6所示。这样各对产品的特征得分就由“ 大类特征得分” 及其“ 热门对比特征得分” 组成。
| 表6 “ 三星手机竞争产品” 热门对比特征 |
(2) 热门对比产品特征计分
本实验利用情感词典③并开发脚本程序④, 将比较句按特征分组, 计算产品不同特征的得分。该词典来源于中国台湾大学NTUSD-简体中文情感极性词典①和人工整理, 本文将正向情感词、负向情感词均按程度副词分别赋予不同量度的正分和负分, 单情感词为1分, 有一般程度副词修饰(如: 不少, 一些)加1分, 有中等程度副词修饰(如: 很、很多)加2分, 对“ 非常” “ 太多” 等副词加3分, 极性副词如“ 极” 加4分。情感词典部分内容如表7所示:
| 表7 部分情感词典及其分值 |
热门对比产品A、B在特征F下的得分公式如下:
 |
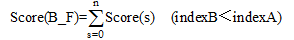 |
Score(s)=dict[Key](0< s< n) (5)
公式(5)中key表示比较句中出现的情感词, Score(s)=dict[Key]是该比较词的情感分值(正向情感为正分, 负向情感为负分)。本文4.3节处理过程保证了每个比较句只包含一个情感词, 即Score(s)是该比较句的情感分值, n是特征F的比较句总数。indexA、indexB分别为产品词A、B在比较句中出现的索引, Score(A_F)、Score(B_F)分别是产品A、B在特征F下的得分值; 若inexA< indexB, 则Score(A_F)增加Score(s); 反之, Score(B_F)增加Score(s)。
举例来说, 对于大类特征中的“ 创新力” , 有如下比较句: s =“ 小米 比 三星 创新力 好太多” 。由于“ 创新力” 属于“ 总评” 特征大类, 因此“ 创新力” 会被替换为“ 总评” , 比较句会变成: “ 小米 比 三星 总评 好太多” 。则:
Score(s)=dict[好太多]=4
index(小米)=0< index(三星)=2
Score(小米_总评)+=Score(s)
即“ 小米” 在“ 总评” 特征大类的得分增加4。
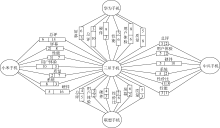
以“ 三星手机竞争产品” : [三星-华为、三星-联想、三星-小米、三星-中兴]为例, 这组产品特征得分均包含三个大类特征: “ 总评” 、“ 硬件” 、“ 用户体验” 和各对产品的“ 热门对比特征” 。根据产品特征得分画出其特征对比图如图2所示:
 | 图2 三星手机竞争产品特征对比 |
分析“ 三星手机竞争产品” 的特征得分, 实验得出以下结论:
(1) 三星手机与小米手机各项分值最大, 分别为59、36分, 说明这组产品里三星与小米的竞争最为激烈, 从侧面反映小米是国产手机里的佼佼者。三星在总评、硬件上得分超出小米很多(比分为15 : 6、16 : 5), 然而其用户体验、系统均不及小米(比分为3 : 10、3 : 8), 因此三星需要在其操作系统和用户体验上发力, 解决其广受诟病的“ 卡慢” 问题; 小米则要在屏幕以及性能方面提升自己, 缩小与国际品牌的差距。
(2) 联想手机在“ 性价比” “ 总评” 方面优于三星手机, 中兴手机在“ 硬件” “ 性价比” 方面优于三星手机, 两者在其他方面均不敌三星, 说明它们之间比较关系不强烈。相比而言, 华为对三星构成更大的威胁, 其在“ 用户体验” 和“ 硬件” 上超过三星不少(比分分别为8 : 6、9 : 3), 反映三星手机定价高、用户体验较差; 而三星在“ 质量” 和“ 性能” 上的得分使其总评反超华为, 这反映出国产手机的通病: 高性价比总是以牺牲产品质量为代价。建议国产手机不要一味追求低价, 在提高产品性价比的同时, 注重产品质量。
(3) 除了“ 性价比” , 三星手机各方面都要比国产手机强, 建议对价格不敏感的消费者购买三星手机; 建议关注性价比的消费者考虑国产手机, 因为他们大都在性价比、硬件方面占优势; 此外, 小米手机的用户体验比三星手机好不少, 二者比分为10 : 3, 推荐注重用户体验的消费者购买小米手机。
综上所述, 本实验通过基于比较句的情感分析模型从8个手机产品(构成28对产品)筛选出三组共9对热门对比产品, 帮助手机厂商识别出了竞争对手。由于手机市场实际竞争情况难以确定, 本文以人工浏览评论得出的结论为参考, 实验筛选出的9对热门对比产品与实际情况非常符合。同时, 实验以“ 三星手机竞争产品” 为例可视化分析了4对竞争产品的特征差异, “ 三星手机-小米手机” 、“ 三星手机-华为手机” 、“ 三星手机-中兴手机” 、“ 三星手机-联想手机” 的特征总得分分别为: 59:36、36:34、22:20、24:21; 同时人工浏览计算出的该组产品特征总得分分别为54:40、35:35、21:22、25:23; 两者较相符合, 说明实验结论能够给消费者购买提供决策支持, 实验结果验证了基于比较句的情感分析模型的有效性和可行性, 从一定程度表明该竞争性分析方法对企业有较高的利用价值。
本文提出基于比较句的情感分析模型, 可帮助企业识别竞争产品和对手, 并能为消费者购买提供决策支持。为了验证模型的效果, 本文以手机产品为实验对象, 结合百度搜索引擎, 利用该模型从28对手机产品中筛选出9对竞争产品, 并计算竞争产品的特征得分、可视化分析竞争产品的特征差异, 挖掘出对企业和消费者有价值的信息。实验结果与人工浏览所得出的结论非常符合, 证明该模型能有效识别竞争产品, 并对可比较产品间的具体特征差异进行较为客观的可视化呈现和比较分析, 该分析方法可从比较句中挖掘出竞争情报, 对企业有较高的利用价值。下一步研究需要扩大数据来源、提高比较句抽取准确率。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|