{kind=link}
基于医学本体的术语相似度算法研究*
[范雪雪1  , 王志荣
, 王志荣1 , 徐晤1 , 梁银2 , 马小虎3 ]
, 王志荣|
|


作者贡献声明:范雪雪: 提出研究思路, 设计并实现算法, 撰写论文; 王志荣, 徐晤: 提供实验数据, 进行数据分析; 梁银: 数据分析, 论文修订; 马小虎: 论文修订。
[Objective] Based on the comprehensive medical Ontologies, this paper proposes a new algorithm to enhance the precision of semantic similarity estimation of medical terminology. [Methods] On the basis of the hierarchy and semantic relationships of concepts of SNOMED CT and MeSH, the semantic parameters such as depth and distance are extracted. Then the depth factor and the distance factor are obtained weighted by the concept density, and the function of semantic similarity is thus established. [Results] The algorithm is applicable to both distinctive medical Ontologies, and the experimental results demonstrate that this algorithm has higher correlation coefficient with manual scoring versus conventional algorithms. [Limitations] This algorithm is subject to hierarchy of Ontologies. [Conclusions] The new algorithm benefits the enhanced precision of semantic similarity estimation of medical terminology.
词语语义相似度计算是自然语言处理的一项基础性工作, 在信息检索[1]、词义消歧[2, 3]、机器翻译[4]、自动问答、信息提取[5]、文本分类和聚类[6, 7]、语义标注等领域有广泛的应用。在医疗领域, 随着全民电子健康记录和电子病历等信息技术在医疗领域的大规模应用, 提高海量医疗文本资源的检索效率和利用率成为一项重要的研究课题。医疗术语相似度计算对于提高医疗文本资源的检索、聚类和挖掘的效率具有重要意义[8, 9]。在传统的数字图书馆领域, 语义检索还是要借助交互式的术语提示来实现概念之间的检索, 而不考虑概念之间的其他属性关系, 检索结果往往不能满足用户需求[10]。基于本体的语义相似度计算可以解决这个问题。医学系统命名法-临床术语(Systematized Nomenclature of Medicine-Clinical Terms, SNOMED CT)和医学主题词表(Medical Subject Headings, MeSH)是目前世界上应用最为广泛的医疗领域术语表和主题词表, 它们都拥有庞大的概念术语集和复杂的结构。我国医学界也对这两个本体进行了大量的研究, 但以它们为基础的术语语义相似度计算研究还不够充分, 计算方法往往直接移植自基于通用本体的方法, 缺少针对性, 计算精度不高, 且在不同本体中计算结果差异较大, 无法满足需求。
本文依据本体的结构特征和概念间的语义关系, 将概念的语义距离、语义深度和密度等语义特征进行融合, 提出深度系数和密度系数的概念并采用加权的方法进行计算, 最后构造了新的相似度计算函数。在实验阶段, 以Pedersen和Hiaoutakis两种评估标准进行测试, 结果表明本文提出的算法与传统算法相比和人工评分有更高的相关系数, 且在两本体中的计算结果接近, 能够在一定程度上弥补本体未收录术语问题。
词语语义相似度(Semantic Similarity)是指词语在分类上的相似程度, 在本体中一般表现为具有上下义关系。比如心脏病和心肌梗死。此外, 词语之间还存在着其他更为广泛的关系, 叫做词语语义相关度(Semantic Relatedness)。如硝酸甘油有助于治疗心绞痛, 它们具有相关度而不存在上下义关系。相似度是相关度的一种特殊情况[11], 本文主要对相似度进行研究。
词语语义相似度算法可根据背景知识的来源不同分为两种类型: 一种是基于语料库的方法, 这类方法以非结构化或者半结构化的文本语料(如病人的电子病历等)、Web网页等为基础, 用统计学的方法计算出词语的分布特征并构造相似度函数[12, 13, 14, 15]; 另一种是基于本体(Ontology)的方法, 通过本体中概念之间的关系、属性或者层级结构对词语进行相似度计算[11, 12]。前者对语料库要求很高, 数据稀疏和词语歧义问题严重影响计算精度。后者基于本体, 概念之间语义逻辑关系清晰, 但也存在较为依赖本体的问题。随着SNOMED CT、MeSH等医学本体越来越完备, 为基于本体的医学术语相似度计算的研究奠定了坚实的基础。
基于本体的语义相似度算法按照计算理论的不同可以分为4种类型: 基于信息量(Information Content, IC)的方法、基于语义距离的方法、基于属性的方法、混合方法。Lord等[16]和Resnik[17]提出以概念最近公共祖先节点(Least Common Subsume, LCS)的信息量度量词语语义相似度, 但该算法对所有拥有相同祖先的概念计算出的相似度都相同。Lin[18]和Jiang等[19]在Resnik的基础之上提出改进, 但算法精度受语料库影响较大。近年来, 有学者提出基于纯本体信息量的算法[20, 21, 22], 但由于不能充分体现概念之间的语义关系, 精度受到影响[11]。基于语义距离的算法首先由Rada等[23]提出, 将本体看做一个由概念组成的语义网, 提出用概念节点之间的最短距离来计算相似度。Leacock等[24]和Wu等[25]对Rada等的方法进行改进, 尽管该种算法理论简单, 但是精度不高[11]。基于属性方法则是直接通过概念属性的重合程度进行计算, 代表方法如文献[26-29]。该类方法是一种将相似度和相关度混合计算的方法, 但由于没有充分利用本体结构信息, 计算结果精确度受到限制[11]。混合算法是以上三种方法的综合考虑, 具有代表性的是Li等[30]提出的方法。由于充分利用了概念的语义信息, 该类方法近年来涌现出大量的研究成果[11]。以上算法大部分都是基于通用本体, 由于通用本体只包含了非常有限的医学词汇, 因此直接应用到医学本体中会受到限制。
目前, 在医学领域使用最为广泛的本体包括SNOMED CT和MeSH。SNOMED CT 2014版涵盖311 000多条活跃概念, 它包含1个根概念和19个顶层概念, 每个顶层概念又分为若干子层, 概念从一般到具体逐级分类, 形成层级结构。SNOMED CT的核心是概念, 每个概念具有唯一的标识符、名称和概念描述。其中, 概念描述包括一条首选术语和一条或多条同义词。概念和术语之间形成一对多的关系。概念之间通过“ 关系” 逻辑被形式化地组织在层级结构中。在SNOMED CT中存在很多种关系, 其中最重要的就是上下义关系, 其他还有概念模型属性关系等。MeSH则将主题词按照范畴和学科属性将它们划分为16个大类, 每个大类再层层划分, 逐级展开。在MeSH中, 每个主题词都拥有唯一的标识符和一个主题词详解, 拥有一个或多个入口词(可以理解为同义词)。每个主题词都按照分类和逻辑关系安排在树形结构的某一节点上, 上下义关系也是MeSH中最主要的关系。
在本体中, 概念之间的相似程度可以利用它们在层级结构中的距离、深度和所处部分的密度等参数衡量。一般来说, 概念间的距离和它们的相似度成反比, 距离越小则概念之间的相似度越高; 对于语义距离相同的两个概念来说, 其所处位置越深, 表示概念越具体, 相似度越高; 所处区域的密度越大, 表示概念细化程度越大, 相似度越高[11, 12, 23, 24, 25, 30, 31]。本文算法也采用了上述语义参数, 并进一步提出深度系数、距离系数的概念和计算方法, 同时提出以密度作为参数对语义距离和语义深度进行加权, 最后构造了新的术语相似度计算函数。
定义1 深度系数。若概念c1, c2的最近公共祖先节点(LCS)在本体中的深度为dept(lcs), 经过LCS和两概念节点的路径的长度分别为dept(t)1和dept(t)2, 令dept(t) = max[dept(t)1, dept(t)2], dept(lcs)与dept(t)的比值定义为深度系数, 记为depf(LCS(c1, c2)), 可表示为:
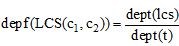 |
定义2 距离系数。令从概念c1到c2且经过它们最近公共祖先节点的最短路径的长度为path(c1, c2), 若path(c1, c2)≠ 0, 则定义距离系数为path(c1, c2)的倒数, 用q表示, 即q=1/path(c1, c2)。当path(c1, c2)=0时, 表示c1, c2完全相同。
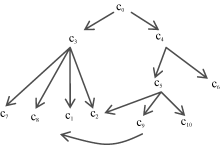
概念节点所在区域的密度也会影响相似度, 表现如图1所示:
 | 图1 本体层级结构 |
若不考虑密度因素, 概念c1, c2和c5, c6的深度和距离相等, 相似度应该相等。但因c1, c2所处区域概念密度大, 其相似程度应该大于c5, c6。这种现象映射到边上就是密度大的区域其概念对应边的长度应该小于密度小的。同样, 深度对相似度的影响映射到边上就是层次较深的概念对应的边的长度应该小于深度浅的。为此, 本文构造权值函数来满足以上要求。若Lci表示概念ci对应的边, 其权为W(Lci), 计算公式为:
 |
其中, dept(ci)=1表示ci为根节点, dept(ci)> 1表示ci为非根节点, s表示ci的孩子节点的数量, 且s≥ 1(若s=0则说明该节点为叶子节点, 叶子节点不计算权值)。γ 为权值系数, 取值为0.9, 为保证下层节点对应边的加权长度不大于上层节点, 规定当W(Lci)> 1时, 令W(Lci)=1。概念节点ci对应边的加权长度就可以表示为:
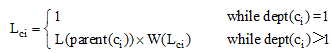 |
其中, L(parent(ci))表示ci的父节点对应边的加权长度。公式(2)和公式(3)保证了下层节点对应边的加权长度不大于上层节点; 密度大区域节点对应边的加权长度不大于密度小的区域的节点。
若设概念节点在不加权的情况下对应的边长度为1, 概念c1, c2的dept(lcs)由m1个节点对应的边组成, dept(t)由m2个节点对应的边组成, path(c1, c2)由m3个节点对应的边组成, 则加权后的深度系数depf (LCS (c1, c2))和距离系数q可以分别表示为:
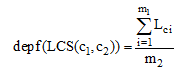 |
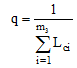 |
其中, 公式(4)中的分母对应公式(1)中的dept(t), 为其不加权的长度m2。
在本体中概念是不存在歧义的, 但是由于概念存在多种不同的分类, 往往存在多继承的情况。如图1所示, 概念c1, c2继承自c3和c5两个最近公共祖先节点(LCS), 但两个LCS在本体结构中所处的深度不同, 最短路径也不相同。由于缺乏具体语境, 本文认为这些情况出现的概率是相同的, 因此对各种情况的相似度进行平均。
若概念c1, c2存在n个最近公共祖先节点, 则它们就存在n个深度系数。根据深度系数的概念, 选取几种情况下长度最长的dept(t)用dept(t)max表示(如图1中的dept(t)max即为路径(c0 c4 c5c9c1)的不加权长度)。则概念 c1, c2的第i个最近公共祖先节点的加权深度系数的计算公式为:
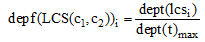 |
若c1, c2最近公共祖先节点的最大的深度为1, 即max[dept(lcs)]=1, 则二者不相似。
同样地, 若概念c1, c2存在n个最近公共祖先节点, 则它们就存在n条最短路径, 其中第i条最短路径的加权长度用path(c1, c2)i表示, 距离系数用qi表示。
综合以上语义特征参数, 概念之间的相似度计算公式为:
 |
其中, sim(c1, c2)表示概念c1, c2的语义相似度, n是c1, c2的最近公共祖先节点的数量。α 和β 是随着本体的不同而变化的参数, depf(LCS(c1, c2))i和 qi分别表示加权的深度系数和距离系数。若max[path(c1, c2)]=0, 即最大的最短路径的长度为0, 则表示两个术语完全相同, 相似度为const。const为常数, 表示概念完全相同时的相似度。
输入: 概念c1, c2
输出: 概念c1, c2的相似度
①搜索概念c1, c2在本体中是否存在, 若存在则进入步骤②, 否则停止并提示。
②寻找概念c1, c2的n个最近公共祖先节点LCS, 得到最大的最短距离max[path(c1, c2)]和LCS的最大深度max[dept(lcs)]。
③若max[path(c1, c2)]=0, 则sim = 4, 即完全相同, 算法结束。否则进入步骤④。
④检查c1, c2的max[dept(lcs)], 若为1, 则进入步骤⑤, 否则进入步骤⑥。
⑤检查概念c1, c2是否为相关词, 即仅具有相关度不具有相似度的词。若是则令sim=3, 否则认为两概念之间不相似也不相关, 令sim=1, 算法结束。
⑥分别计算概念的深度系数和距离系数, 并根据公式(7)计算两概念之间相似度。
⑦算法结束。
本文讨论的是概念的相似度, 但为了与更多的算法比较, 对于仅具有相关度而不具有相似度的概念, 借鉴文献[27-29]的方法: 分别搜索c1和 c2的概念描述或者相关概念中是否出现另外一个概念, 若出现, 则判断二者是相关词, 且令其相似度为一定值。根据两本体结构特点和人工评分结果, 取该定值为3。
由于本文算法的主要运算是查找运算和简单的线性运算, 且多为一次性运算, 仅仅在计算权值时使用简单的迭代。整个算法仅依赖本体局部结构信息, 且不需要反复遍历整个本体, 算法时间复杂度较低。
对算法精度评价的方法一般是将算法结果与人工评分相比较。在医学领域有Pedersen等[32]和Hiaoutakis等[33]创建的两种评估标准。前者是由Pedersen和梅奥诊所(Mayo Clinic)的医师们合作, 组织9名医学编码员和3名医学专家分成两个小组, 对30对术语进行评分, 1表示不相似, 4表示完全相同。该评估标准和SNOMED CT能准确地比较出评估结果, 近年来已经成为医学界应用最为广泛的评估标准[20, 21, 32, 34, 35]。Hiaoutakis等[33]的评估标准是从MeSH中选出36对术语, 由8位医学专家进行人工评分, 0表示不相似, 1表示完全相同。本文首先实现了上述算法, 以SNOMED CT 2014和MeSH 2014作为本体, 对这两种评估标准中的术语进行相似度计算, 并与常用算法进行比较。
(1) 与Pedersen评估标准比较
Pedersen评估标准共有30对术语, SNOMED CT 2014中收录了29对, MeSH 2014中收录了25对。对于未收录的术语, 文献[34]的处理方法是在本体中找到与其最为相近的概念代替, 然后再进行相似度计算。参考这种做法, 本文最终计算了29对术语的相似度。由于两本体结构存在很大差异, 经实验, α 、β 在SNOMED CT中取值为α =1, β =1, 在MeSH中取值为α =0.8, β =0.8时结果最接近人工评分。一般采用皮尔逊相关系数衡量各种算法的效果, 将文献[20-21, 32, 34]中测评的算法及本文算法同Pedersen评估标准的相关系数进行比较, 结果如表1所示。
| 表1 各种算法与Pedersen评估标准的相关系数 |
表1囊括了目前大部分常用的词语相似度和相关度算法。其中基于本体的方法均以SNOMED CT或MeSH作为本体, 基于语料库方法均使用Mayo Clinical Corpus of Clinic Notes[32](MCCCN)语料库, 因此具有可比性。其中, 第1-3行是经典的基于信息量的算法, 第4-6行是基于纯本体信息量的算法, 第7-18行是基于语义距离的算法和混合算法, 第19-21行是基于信息量的语义距离改进算法。第22-25行是基于内容向量的方法, 这是一种基于语料库的方法。其中第22、24行所用语料选自于MCCCN语料库的诊断术语部分, 选取规模分别为100万条和10万条词语, 第23、25行选自整个语料库, 规模与前者相同。第26-27行是本文提出的算法。
(2) 与Hiaoutakis评估标准比较
Hiaoutakis评估标准中包含36对从MeSH中挑选的概念术语, 由人工从0-1进行打分。文献[36]选取其中的32对术语并列举了以MeSH为本体的Dice, Jaccard, Rodriguez & Egenhofer以及Cosine算法的计算结果。笔者同样选用这32对术语并首先以MeSH为本体进行计算。此外, 也以SNOMED CT作为本体进行了计算, 但由于其中有两对术语未被收录且无相似概念可代替, 因此在以SNOMED CT为本体时仅计算了30对术语。表2是各种算法与Hiaoutakis评估标准的相关系数。
| 表2 各种算法与Hiaoutakis评估标准的相关系数 |
从表1可以看出:
(1) 几乎所有算法结果都与编码员评分更为接近, 这是因为医学编码员是经过训练的具有医学分类知识的专业人员, 对于医学词汇的分类能做到更加客观准确, 文献[34]则只与编码员评分结果进行比较。
(2) 经典的基于信息量的算法(第1-3行)和基于语料库的算法(第22-25行)受语料库的规模和专业程度影响较大。
(3) 经典的基于距离的方法与混合算法(第7-18行)在不同的本体中表现差异较大, 尤其在SNOMED CT中表现不佳。
(4) 改进的基于纯本体信息量算法(第4-6行, 第19-21行)比经典信息量算法表现有所提升, 这从一个方面说明基于领域本体的方法精确度优于基于语料库的方法。
(5) 本文算法(第26-27行)在两个本体中均能得到更高的相关系数且结果相近, 两本体结果相关系数为0.978(见本篇论文网络版本支撑数据), 这说明本文算法具有更高的精确度与更好的通用性。
从表2可以看出, 由于评分专家采用的标准和打分区间的不同, 本文算法计算结果与人工评分有一定差异, 但从相关系数值可以看出本文算法较其他算法在以MeSH为本体时计算结果更加接近人工标准。对于SNOMED CT而言, 由于目前还没有以之为本体的30对术语相关测评结果因而无法进行比较, 但本文算法在两本体中计算结果的相关系数为0.983(见本篇论文网络版本支撑数据)。
本文提出一种基于复杂医学本体的术语相似度算法。该算法依据医学本体的结构特征, 运用加权的深度系数、距离系数等语义特征变量计算医学术语相似度。采用Pedersen评估标准和Hiaoutakis评估标准并分别以SNOMED CT和MeSH为本体进行测试, 该算法得到了比传统算法更高的相关系数, 同时也证明了该算法能够运行在SNOMED CT和MeSH两个本体中, 且表现较为相近, 能够在一定程度上弥补单一本体中因未收录术语而无法进行计算的问题。由于该算法依赖本体结构, 当本体结构发生改变时, 需要重新计算。但该算法中的运算多为线性运算, 且不存在反复遍历本体的问题, 能够较为快速地重新完成计算。由于任何一个单独的本体都无法收录所有术语, 如果能够联合不同的本体(包括一般领域本体)进行术语相似度计算, 则能够在更大程度上解决未收录术语的问题, 这是今后需要进一步研究的工作。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|