
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
本体上下位关系在招生问答机器人中的应用研究*
[余昕聪1, 2  , 李红莲
, 李红莲1 , 吕学强2 ]
, 李红莲|
|


作者贡献声明:余昕聪, 李红莲, 吕学强: 提出研究思路, 设计研究方案, 论文最终版本修订; 余昕聪: 程序开发实现, 数据采集、整理; 余昕聪, 李红莲: 论文起草。
[Objective] This paper aims at increasing the accuracy, and improving the satisfaction of question answer system. [Context] In the field of Natural Language Processing, question answering system has become an important research point, but the accuracy of system is low at present. How to improve the satisfaction of the system becomes the burning question. [Methods] This paper analyzes the source code of ALICE for modification by using the Chinese word segmentation. Based on the analysis of its internal reasoning, this paper puts forward a recommend method. [Results] Integrate the domain Ontology into ALICE robot, then analyze the user question, extract key words. Finally, search the Ontology and then give the recommends. [Conclusions] Experiments show that after introducing Ontology of recommended results, customer satisfaction is increased greatly.
随着高校生源的不断增加, 考生通常利用高校的招生咨询平台更全面地了解学校的资源配置、招生计划、报考要求等信息。高校可以全方位地展示学校实力与水平, 让考生、家长和社会更多地了解学校, 从而争取到更多更好的生源。然而传统的招生咨询工作面临着许多问题, 例如大部分考生或家长咨询的问题都类似, 客服人员重复性的工作浪费了许多人力、财力和时间资源。随着自然语言处理技术的深入发展与研究, 招生问答领域的自动问答机器人应运而生。
目前的对话机器人, 其处理问题的基本流程是: 获取用户问题、对用户问题进行分析并获取用户意图、从语料库中选择相应的问题答案。然而当前的问答机器人的模式是一问一答, 结构单一; 而且通常由于语料规模的限制以及对用户查询意图的推测不准确等问题, 并不能对所有的问题给出回答结果, 也没有给出相关联的推荐内容。本研究针对招生问答领域的人机问答系统存在的一些不足, 将ALICE开源聊天机器人进行二次开发, 并利用构建的领域本体的上下位关系对用户所提问题进行用户意图挖掘, 进而给出相关内容推荐, 使得考生在没有获取到相关问题答案时也能得到一些相关联内容的推荐结果, 从而提高问答系统的满意度。
自动问答系统的研究已有50多年的历史, 并成为自然语言处理和信息检索的一个重要分支和研究热点[1]。现有的问答系统可以分为聊天机器人、基于知识库的问答系统、问答式检索系统、基于自由文本的问答系统等[2]。
国外在智能聊天机器人方面研究较早, 而且也更成熟。如密歇根大学的AnswerBus, 是一个面向开放领域的问答系统, 接受自然语言提问, 从Web中提取问题可能的答案, 并支持多种语言的提问方式[3]; START是由麻省理工大学人工智能实验室研发的, 采用基于知识库和信息检索的混合模式, 如果用户的问题在知识库中可以找到, 则直接返回; 如果找不到, 则通过搜索引擎检索并返回查询结果[4]; ALICE是由美国宾夕法尼亚大学研发的基于经验的人工智能聊天机器人, 其对应的AIML知识库具有丰富的标签, 在英文领域具有较好的应用前景[5]。
在国内的自动问答技术研究中, 由于汉语本身的原因, 使得中文领域的自动问答更加困难, 比如中文分词、词性歧义等问题。国内的研究通常采用句子相似度匹配的方法, 从问题库中获取与用户问题相似度最高的问题答案作为回答内容。冯德虎[5]实现了基于ALICE的研究生招生咨询智能聊天机器人, 在ALICE中嵌入中文分词模块, 对分词的算法进行改进, 并构建AIML知识库对问题和答案进行组织。该系统利用模糊匹配的方式, 根据内部推理机制从AIML知识库中寻找相似度最高的问题并返回问题答案。周永梅[6]实现了基于本体的自动问答系统, 通过对用户问题进行分词、停用词处理和相似度计算, 从FAQ库中寻找与用户问题相似度最大的问题, 其在语义相似度计算和句子相似度计算过程中利用本体的概念结构, 提升了利用知网相似度计算的准确度和问答系统的准确率。陈小宾[7]通过将领域本体加入移动问答中, 应用主题识别等技术将问句中的概念提取出来, 应用领域本体中概念之间的语义关系和层次关系进行综合匹配, 进而确定主题概念, 从而提高问句主题分析的准确性。
①http://www.pandorabots.com/pandora/talk?botid=f5d922d97e345aa1.
上述研究中, 国外的研究内容大多采取模式匹配以及基于经验的问答模式, 在英文领域具有较好的前景, 而在中文发展方面还有一定的不足之处。国内的一些研究中, 基于FAQ库的方法虽然实现了基本的用户问答, 然而目前的语义相似度计算和句子相似度计算准确率较低, 而且在用户问句较长、问句特殊的情况下, 往往得不到准确的回答。在基于ALICE的问答机器人中, 其采用推理和模糊匹配的方式准确率较高, 然而中文的AIML知识库的构建成为了系统的瓶颈。领域本体在词的概念层面的语义关系计算较为准确, 然而在问句中的应用和问题匹配有一定的局限性。上述问答系统中, 都是采用一问一答的模式, 缺少与用户的交互和用户意图的挖掘。本研究以ALICE机器人为基础, 将领域本体作为问答系统的附加知识库, 在实现基本问答的基础上, 利用本体的上下位信息对用户提问给出相关内容推荐。
本研究利用开源的ALICE智能聊天机器人, 并对其进行修改以适应在招生领域的应用。实验包括三个方面的内容: 对原始ALICE聊天机器人的开发, 使其支持中文字符处理; 加入中文分词模块; AIML知识库构建模块。并最终实现中文的自动问答。
(1) ALICE简介
ALICE (Artificial Linguistic Internet Computer Entity)①是由美国宾西法尼亚州利哈伊大学的Wallace博士开发的一个基于经验的人工智能聊天机器人。最初版本的ALICE支持英语、德语、法语等语言, 却不支持中文。在对ALICE源码进行分析时发现, 其预处理时的筛选机制把汉字排除在外, 因而需要在源码中加入中文文字支持的代码。
(2) AIML标签语言
ALICE内部包含推理及模式匹配机制, 采用AIML(Artificial Intelligence Markup Language)作为知识库描述语言。它目前利用一种类似于XML的标签型语言结构对知识库内容进行组织[8]。
①AIML语法构成要素
AIML是利用XML标准定义的一种服务于人工智能领域需要的特定语言, 它描述了被称为AIML对象的一组数据对象, 并且描述了处理这些数据对象的程序的行为。在AIML中, 基本的知识单元是由分类(Category)构成的, 而每一个分类又是由用户输入的问题、ALICE输出的答案和可选上下文环境(Optional Context)所组成。一个简单的分类如下所示。
< category>
< pattern> WHAT IS YOUR NAME< /pattern>
< template> My name is alice! < /template>
< /category>
其中, 模式< pattern> 部分代表用户输入的问话, 模板< template> 部分则代表用户输入这一问句后, 系统应该给出的答案。
②AIML知识树
AIML知识库是以树的形式存储在计算机内存中, 树的每个节点代表模式中的一个词组或通配符, 根据它在模板中出现的位置前后相连, 每个叶子节点包含一个模板属性, 当该模式匹配成功后将返回叶子节点的模板信息。许多包含不同领域知识的AIML文件可以合并成一个知识库, 提高系统的扩展性和兼容性。
③AIML推理过程
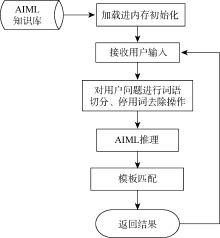
AIML的推理机制是根据用户输入的内容从分类中查询并找到匹配的模板内容。ALICE系统的工作流程如图1所示:
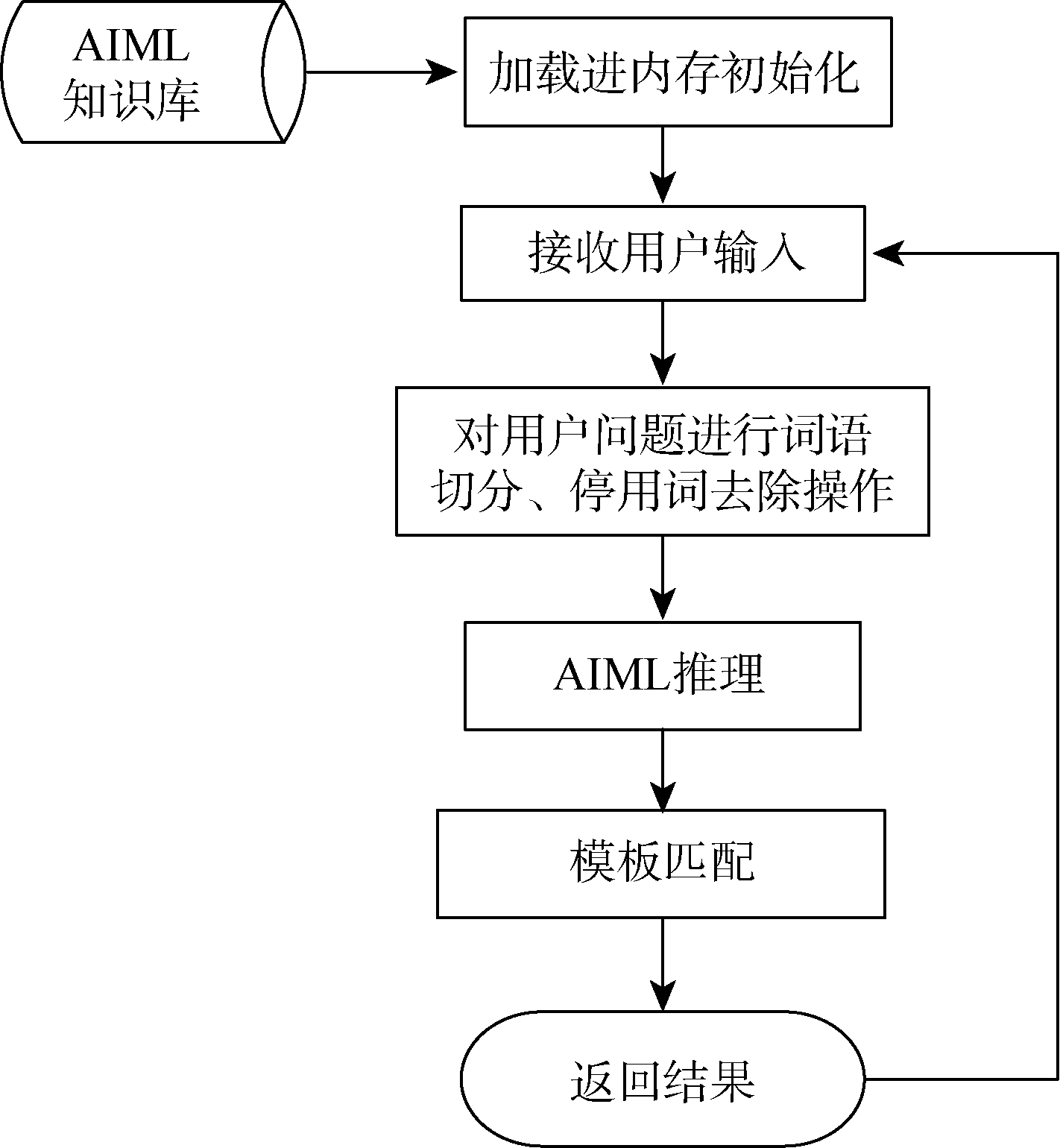 | 图1 ALICE工作流程 |
ALICE聊天机器人不能直接应用于招生问答, 因而需要将其进行修改以适应招生问答领域。基于ALICE的问答系统框架包含4个模块: 中文分词处理模块、ALICE知识库构建模块、答案获取模块、用户交互模块。
(1) 中文分词处理
①http://ictclas.nlpir.org/.
由于ALICE原始内容没有包含中文处理模块, 因此需要加入中文分词解析器, 本文采用中国科学院计算技术研究所ICTCLAS分词器①, 其具有分词准确度高、速度快等优点且可以加入自定义词典, 比如“ 分数线” 、 “ 考研复试流程” 等。综上, 问答系统在获取到用户输入内容时, 调用中文处理模块进行分词和去除无关词操作。
(2) ALICE知识库构建
ALICE需要AIML知识库做支撑, 因而需要对招生问答领域的问题和答案构建为AIML知识, 在本实验中, 通过事先获取的某学校招生网站的内容, 将招生的内容进行组织并按照AIML语言的规范构建语料库。
例如, “ 贵校今年招生人数是多少?” 、“ 请问计算机专业自主招生吗?” 。那么这两个问题的构建的匹配模板分别为:
< pattern> * 招生 * 人数 * < /pattern>
< pattern> * 计算机专业 * 自主 * 招生 * < /pattern>
本实验对相关的招生内容进行组织并构建1 000条相关的匹配模板。
(3) 答案获取
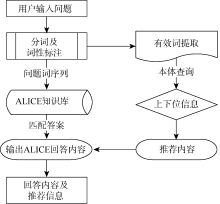
问答系统获取到用户输入后, 调用ICTCLAS分词器对输入问句进行分词、去除停用词操作并将问句提交给ALICE; ALICE获取用户输入内容后, 利用模糊匹配的方法以及内部推理机制从AIML知识库中选择最佳答案, 招生问答系统的工作流程如图2所示:
 | 图2 招生问答工作流程 |
(4) 用户交互
用户交互模块主要负责用户与机器人的交互, 用户输入问题, 机器人调用中文分词和去除停用词处理, 将处理后的结果交给机器人内部推理机制处理、再去除无关词以及分析推理后, 从模板中寻找匹配答案并最终将答案呈现给用户。
基于ALICE的招生问答机器人由于语料规模的限制以及对用户查询意图的推测不准确等问题, 并不能对所有的问题给出回答结果, 使得用户对问答系统的满意度下降。本研究将领域本体作为问答机器人的附加知识库, 根据用户的问题内容, 给出相关内容推荐, 从而提高问答系统整体的满意度。本研究对问答系统的改进包括两个方面的工作: 领域本体的构建与解析、用户推荐。
领域本体(Domain Ontology)是专业性的本体, 描述的是特定领域中的概念和概念之间的关系, 提供了某个专业学科领域中概念的词表以及概念间的关系, 或在该领域里占主导地位的理论[9]。Proté gé [10]是斯坦福大学为知识获取而开发的一个工具, 本研究首先获取一些有关招生领域的概念组建领域概念结构, 并利用Proté gé 工具进行本体的构建。在本体解析过程, 即获取词语上下位信息时, 本文使用Jena[11]工具对构建的领域本体库进行解析。
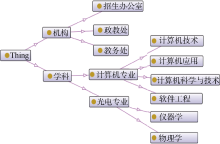
实验中所用到的本体库是针对招生领域的领域本体库, 内容涉及学科、机构等内容。比如概念“ 学科” 下的分支有计算机学、经济学、会计学, 计算机学下边又有分支软件工程、计算机应用等, 再比如概念“ 机构” 下的分支有招生办公室、教务处、政教处等。利用Proté gé 构建的部分领域本体展示如图3所示:
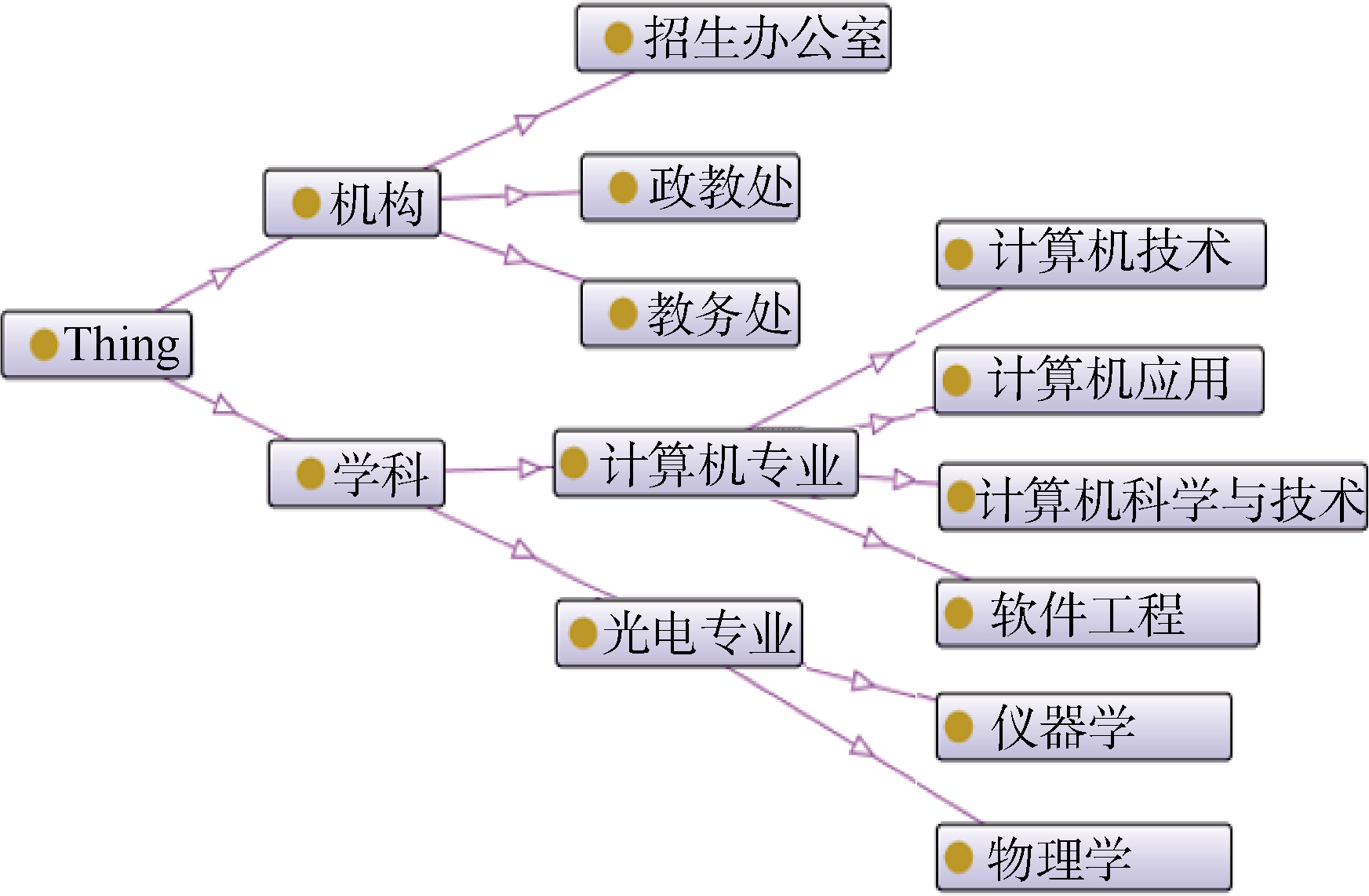 | 图3 领域本体部分内容示意图 |
原始的ALICE源码中并没有对本体的解析模块, 因而需要将源码进行改进, 添加解析本体的接口, 其中包含获取上位关系的接口getSuperClass和获取下位关系的接口getSubClass。
在用户输入问题后, 将用户问题进行分词, 采用哈尔滨工业大学停用词表去除其中的停用词。通常在句子中, 用户所提问题中的名词和动词在句子中起着比较重要的作用, 并且名词往往比动词承载着更多的信息量。在关键词提取时, 可适当赋予名词和动词一定的权重值。有效词以及权重定义如下:
定义1有效词, 即能体现句子核心词的词语, 主要由名词、动词性成分组成。
定义2 有效词权重, 即对句子中有效词的数值化表示。
有效词权重的计算如公式(1)所以:
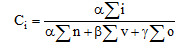 |
其中, n表示句子中的名词, v表示句子中的动词, o表示其他词, i表示词的数目, 系数α =0.5, β =0.3, γ =0.2, 代表不同词性的重要程度。
利用有效词计算之后, 将所得到的关键词按照权重从大到小的顺序排列, 作为本体查询的候选词, 从本体知识库中查询有效词的上下位信息, 得到的推荐结果返回给用户。
推荐方法的流程如图4所示:
 | 图4 推荐方法流程 |
ALICE获取到用户输入后, 共有两条处理流程: 从知识库中获取问题答案; 将用户输入内容提取关键词列表, 根据关键词, 利用ALICE中融入的Jena工具从领域本体库中获取上下位信息并返回给用户。
下面以具体例子(问句) “ 请问计算机专业怎么样?” 为例进行验证。
问句: 请问计算机专业怎么样?
分词结果: 请问计算机专业怎么样?
去除停用词后, 问句的关键词为: 计算机专业怎么样
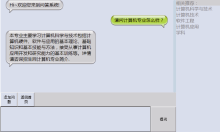
其中, 在AIML语料库中存在匹配模板“ < pattern> * 计算机专业 * 怎么样 * < /pattern> ” 。问答系统会给出对应模板中的问答内容, 在加入领域本体后, 从问句提取到的关键词有计算机专业、录取、分数线三个关键词, 从构建领域本体库中获取这些关键词的上下位信息后的查询结果为: 软件工程, 计算机科学与技术, 计算机应用等内容。查询到初步结果后, 对结果按照不同词类依权重排序, 相同词类自然排序返回给用户。加入领域本体后的回答内容如图5所示:
 | 图5 加入领域本体库后的回答内容 |
本实验的结果评价利用推荐关联度和用户满意度两个方面进行综合衡量。推荐关联度RC (Recommended Correlation)和用户满意度US(User Satisfaction)的定义如下:
定义3 推荐关联度, 指推荐的结果中与用户所提问题是否相关的度量。其计算公式如下:
 |
推荐关联数目的计算以用户对推荐条目的判断计量。
定义4 用户满意度, 指用户对问答系统的回答及其推荐内容的满意程度, 分别由系统回答的准确率和推荐的关联度构成。其计算公式如下:

其中, N表示用户所提问题的数目, n表示回答准确的问题数目。
在上文所举例子中, 推荐数目为5, 由于考生咨询的是某专业的分数线, 因而认为计算机科学与技术、软件工程、计算机应用与推荐的内容是相关的, 而与其所属的父类即上位学科是不相关的, 其他的词语暂无推荐内容, 其最终的推荐关联度为0.8。
目前国内的基于ALICE的问答机器人相对较少, 实验与已上线的基于ALICE的招生问答系统进行对比。实验过程中, 事先从网上获取关于招生的一些问题, 将其加入到问题列表中, 并将问题列表中的问题进行分类, 最终问题分布为: 常见简单问题列表Q1, 119条; 复杂问句列表Q2, 47条。
简单问句形式如“ 有计算机历年真题吗?” 、“ 学院招生分数线是多少? ” ; 复杂问句形式如“ 请问贵校计算机专业招生人数是多少, 是自主招生吗?” 、“ 请问计算机学院的专业有哪些, 录取分数线是多少?” 。
采用分组测试模式对问答内容进行评分, 实验分为三组, 每组8人根据获取到的问题列表中的问题对系统进行提问, 提问的问题为简单问句和复杂问句, 并对答案进行正确度统计。
传统的评价方式采用中国科学院自动化研究所的汉语问答系统评测方法(简称EPCQA), 使用准确率来衡量问答系统的好坏, 公式如下:
 |
以目前已上线的招生问答系统[5]作为Baseline实验, 与本文方法进行对比。三组实验设置如下:
(1) 第一组: 简单句70句、复杂句10句。
(2) 第二组: 简单句70句、复杂句20句。
(3) 第三组: 简单句80句、复杂句10句。
各分组的简单句和复杂句中, 数目重叠部分的问题内容相同, 数目多于其他分组的简单句和复杂句是从问题库中随机挑选的不重复问题。所得结果如表1所示。其中, B表示Baseline实验结果, S表示本文方法结果。由表1可得, 第一组和第三组的实验结果中, 本文方法比Baseline略高, 而对于第二组实验, 低于Baseline。通过前两组实验所得, 随着复杂问句数目的增多, 系统回答的准确率有所下降; 由第一组与第三组实验可得, 在复杂问题数目相同的条件下, 系统对简单问题的回答准确率较高。整体来看, 本文方法准确率略高于Baseline。系统的回答准确率较低的原因是目前的问答系统中, 对于用户输入问题的正确理解和问题处理过程仍然存在一些不足, 问题理解的效果对整个问答系统的性能有至关重要的影响。其次, 本研究所采用的基于ALICE的AIML语料库有限, 不能包含全面的匹配模式, 这也是准确率较低的因素。
| 表1 问答结果统计 |
在加入本体推荐的模块后, 相同条件下采用本实验设置的用户满意度对Baseline和本文方法进行对比, 结果如表2所示:
| 表2 加入推荐后的实验结果 |
由实验结果可知, 第二组实验的推荐关联数目较多, 分析是由于复杂问句中包含较多的关键词信息, 因而利用关键词在领域本体中能够获取到较多的相关内容推荐。从最终的用户满意度来看, 在加入了本体上下位信息推荐的问答系统中, 有些问题虽然没有给出准确的回答, 但是根据提取的关键词推荐的内容却是和问题相关的, 这在一定程度上提高了用户对问答系统的整体满意度。通过本文的关联推荐方法, 可以减少因问答系统对复杂问句得不到准确回答而降低用户使用满意度的问题, 从而提高问答系统的有效性。
目前, 问答系统的准确率还比较低, 在TREC会议中, 一般问答系统的准确率都在30%左右[12]。虽然当前问答系统仍处于比较初级的阶段, 但广阔的发展前景正推动着自动问答系统技术的完善和进一步发展。在本文中, 利用本体上下位的关系, 对问答系统进行了扩展应用, 改善了问答内容不全面的缺陷, 提高了用户对问答系统的整体满意度。然而, 虽然根据关键词给出了相关内容的推荐结果, 但是其推荐结果的关联度仍然不高。因此, 在后续工作中, 如何提高推荐结果的关联度将成为研究重点, 而且可以结合用户历史问题对用户所关心的问题进行综合推荐也成为一个研究方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|