

{kind=link}
{kind=link}
{kind=link}
{kind=link}
查询专指度特征分析与自动识别
[唐祥彬1 , 陆伟2  , 张晓娟
, 张晓娟1 , 黄诗豪1 ]
, 张晓娟|
|


作者贡献声明:
唐祥彬: 文献调研, 分析数据, 起草论文, 论文多次版本以及最终版本修订;
陆伟: 提出研究思路, 论文多次版本以及最终版本修订;
张晓娟: 文献调研, 分析数据, 论文初稿修订;
黄诗豪: 标注系统构建, 实验数据处理。
【目的】基于Sogou查询日志构建人工标注集, 实现查询专指度的特征分析与自动识别, 并对识别效果进行分析与评测。【方法】选取用户查询串基本特征与内容特征进行统计分析, 并分别训练决策树、SVM和朴素贝叶斯分类器对专指度进行自动识别。【结果】使用以上特征的识别效果良好, 十折交叉检验的宏平均F-measure均高于0.8。【局限】 分类特征的选择未考虑用户点击信息; 朴素贝叶斯的独立性假设在本实验中是否可以忽略仍需进一步验证。【结论】利用查询串基本特征和内容特征, 可以有效识别弱、略和强专指度查询。
[Objective] This paper constructs a human-annotated collection on the basis of Sogou query logs, aims at feature analysis and automatic identification of query specificity, as well as evaluates and compares the identifing results.[Methods] The queries’ basic features and content features are selected and analyzed. And then the decision tree, SVM and Naive Bayes classifiers are built and trained to achieve the automatic query specificity classification.[Results] Using the features mentioned above, an effective query specificty identification is obtained. Finally, the macro average F-measures of the identification effects are all above 0.8.[Limitations] Users’ clickthrough information is not selected during the feature selection, and the ignorance of the conditional independence assumption of the Naive Bayes classifier in this particular experiment should be further verified.[Conclusions] The queries’ basic features and content features, by themselves, can well distinguish broad, medium, and specific queries.
随着互联网的蓬勃发展, 搜索引擎Google、Yahoo!、百度等已成为用户访问网络信息资源的主流工具[1]。传统的搜索引擎通过提供整个互联网或多个主题网站上与用户提问相关的各种信息, 然后由用户判断哪些返回结果相关, 哪些无关。但相关并不一定使用户信息需求得到满足, 若返回的结果范围过大或过小, 都会导致用户花费更多时间和精力在大量繁杂信息中寻找有用信息。因此, 自动识别用户查询专指度(Query Specificity), 返回与其信息需求限制范围相符的个性化查询结果, 成为改善综合搜索引擎性能、提高用户检索体验的重要途径。
专指度作为用户查询意图的10大维度之一[2], 指的是“ 用户通过查询语句对其自身信息需求或某查询主题的限制范围程度” , 反映用户对所检索信息的专一性、详细性和确定性要求。另一个与专指度相关的概念是查询模糊度(Query Ambiguity)[3], 但查询模糊度与专指度并不能简单地看作一个问题的正反两面, 实质上, 两者具有相似点但又各有侧重。查询模糊度
侧重于分析查询串中是否含有一词多义的词项或者查询串本身是否有多种解释[4], 而专指度研究侧重于探讨用户对信息需求范围的界定是否明确清楚, 即专指度主要是分析用户查询中使用了哪些限制, 如数量限制、名字限制、时间限制、位置限制等。
然而“ 如何对查询语句的专指度强弱进行判别” 及“ 如何实现专指度自动识别” 等问题, 尚未引起学界的足够重视。基于此, 本文对查询专指度进行分类; 深入分析用户查询语句查询串特征; 利用综合搜索引擎Sogou查询日志, 在人工标注数据集的基础上实现查询专指度的自动识别。
查询意图分类与识别作为解决“ 信息过载” 、“ 主题偏移” 等问题的有效途径, 已成为现代Web信息检索、智能搜索领域的一个研究热点。意图识别可以从多个角度进行, 如查询目标、查询所涉及的主题、组合查询的多个维度等。如Broder[5]通过对用户查询及AltaVista日志进行分析将用户查询意图(查询目标)分为三类, 即信息类、导航类和事务类。Web查询意图的相关研究大多沿用Broder分类体系或改进该分类体系, 如Rose等[6]认为“ 事务类” 不足以概括网上的所有资源, 提出以“ 资源类” 将其取代, 指出“ 资源类” 不再局限于一般的Web活动, 而是包括网页上可获取的任何资源, 并在此基础上提出了更细致的层次化意图分类体系。Gonzá lez-Caro等[2]提出应从题材(Genre)、主题(Topic)、任务(Task)、目标(Objective)、专指度(Specificity)、范围(Scope)等10大维度对用户查询意图进行分类和识别, 本文所讨论的就是根据专指度这一维度进行意图分类。
用户向搜索引擎等信息检索系统提交的查询语句表达了其潜在的信息需求, 因此, 学界主要从信息需求角度对专指度进行了相关研究。Donato等[7]在研究用户信息搜寻行为时表明专指度是影响查询语句可表达性的主要因素之一。Chang等[8]认为导航类和事物类查询往往比信息类查询表达得更加详细、明确, 更有可能是强专指度查询。Calderó n-Benavides等[9]的研究表明当查询含有多义词时, 不到1%的查询为强专指度查询, 而38%的查询为弱专指度查询。可见, 用户查询目标或查询语句类型与专指度之间存在一定的关联, 如非歧义查询大都不是弱专指度查询[10], 问题类查询[11]往往是强专指度查询。然而, 以上研究主要是对专指度某一类别做了关联分析, 并没有专门探讨专指度识别这一问题。近年来, 也有学者直接针对专指度这一维度进行研究, 如Phan等[12]发现查询语句长度与用户查询语句专指度有关, 且长查询串通常是强专指度查询。Hafernik等[13]仅提出了“ 专指度关联属性列表” 并以此将专指度分为强、弱两类。该文虽然认识到专指度并不是一个简单的二值分类问题, 但未做深入考虑, 对于专指度识别效果也未做详细对比和分析。
以上研究表明, 专指度的识别存在以下问题:
(1) 专指度尚无统一定义, 以致缺乏统一的标准构建分类体系;
(2) 用以实现有效分类的属性特征有待进一步挖掘;
(3) 多数研究仅停留在专指度某一特定类别的描述上, 缺乏各类别特征的综合分析;
(4) 尚未探讨查询目标与专指度之间的关联。
针对以上问题, 本文经过文献调研明确了专指度分类体系, 在前人研究成果的基础上完善分类属性特征。且在不借助其他外部资源的情况下, 利用Sogou查询日志, 构建查询专指度标注集, 并分别利用决策树、SVM、朴素贝叶斯分类器实现专指度的自动识别。
目前, 学界关于查询专指度分类并无统一说法, 较为常见的是将查询语句专指度划分为两类或三类。如Igwersen等[14]从信息需求角度出发将“ 知识陈述明确性(Knowledge State Specificity)” 分为“ 宽泛的(Generic)” 或“ 具体的(Specific)” 两种。类似的, Ramí ez等[15]使用“ 广泛(Broad)” 和“ 狭隘(Narrow)” 两类描述信息需求类型。以上二值分类较为简单, 部分查询语句可能并没有得到正确分类。为使分类体系能覆盖绝大部分的查询语句, 本文采用Calderó n-Benavides等[9]提出的分类方法, 按专指度强弱程度依次分为“ 强专指度(Specific)” 、“ 略专指度(Medium)” 、“ 弱专指度(Broad)” 三类。
(1) 强专指度查询: 用户具有明确的信息需求, 且该信息需求可以界定在某一特定范围内, 可以在查询语句中表达得非常清楚。比如用户想到达某网站, 想知道某话题具体信息, 想对比某事物, 想了解关于某一具体问题的答案、建议和方法等。如查询“ baidu.com” 、“ 哈利波特6最新剧照” 、“ 番茄鸡蛋的做法” 、“ 2008年北京高考时间” 等。
(2) 略专指度查询: 自身信息需求不够明确, 无法在查询语句中表达得非常清楚, 或用户仅需要了解相关信息, 不必在查询语句中表达清楚。比如用户想知道关于某话题的某一方面, 查询语句范围限定并不严格。如“ 哈利波特剧照” 、“ 骏捷+油耗” 、“ 番茄小炒” 等。
(3) 弱专指度查询: 用户信息需求较为宽泛, 只是想获取关于该查询的信息即可, 或用户对所检索信息不熟悉, 需要进一步搜索。因此, 在查询语句中基本没有限定范围。如“ 哈利波特” 、“ 高考招生” 、“ 骏捷” 、“ 家常菜” 等。
专指度分类体系构建完成后, 如何选取合适的特征对专指度进行自动识别, 是本节需要解决的问题。查询串是用户经过思考后提交给搜索引擎的, 对其进行分析有助于识别用户的查询意图。于是, 本文选取查询串基本特征和内容特征作为专指度的分类特征。
查询串基本特征主要包括查询串长度、词项个数、词项长度等信息。通常而言, 查询串或词项长度越长、词项个数越多, 往往是强专指度查询; 反之, 则为略或弱专指度查询。然而, 经统计分析笔者发现, 即使用户提交的查询串只有一或两个词, 也有可能是强专指度查询。比如“ 百度” 、“ 竹石, 诗” 、“ 中国人口” 等专指性强的查询, 查询串非常简短, 而“ 长篇小说” 、“ 高考分数线” 、“ 赞保罗皮尔斯” 等专指性不太强的查询, 查询串相对较长。可见, 虽然长查询串通常是强专指度查询, 但反之并不成立。于是, 除考虑以上基本特征外, 在结合Hafernik等[13]研究的基础上, 本文列出了10个与专指度相关的内容特征, 并将其作为区分强、略、弱三种专指度的重要依据, 如表1所示:
| 表1 查询串内容特征及举例 |
查询日志是用户行为的载体, 由一系列信息需求组成, 是用户查询意图分析的重要数据来源。本实验所采用的原始数据集为2008年6月的Sogou查询日志(含25天)[16], 其数据格式为: 用户访问时间+用户ID+查询词+该URL在返回结果中的排名+用户点击的顺序号+用户点击的URL。为保证样本无偏性, 首先用KNIME数据挖掘工具[17], 使用“ 用户ID= 1400500473350” 为随机种子, 以日为单位分层抽取288条查询语句, 25天共计7 200条查询语句。然后, 去除重复和无法识别的查询语句(如纯日语、纯符号等)后, 得到6 456条查询语句作为实验数据集。
相对于时间[18, 19]、地理[20, 21]等维度, 查询专指度的标注工作更为复杂。考虑到有些类别不易从字面上理解其具体含义, 在标注界面中不仅给出三种专指度类别的定义(见3.1节), 且对每个意图类别也进行简单说明:
(1) 信息类(Informational)
①有指导性的(Directed): 用户想知道关于某个话题的特定信息。
②无指导性的(Undirected): 用户想了解关于某个话题的任何信息。
③建议(Advice): 用户想得到一些建议、想法、指南或其他方面的指导。
④位置(Locate): 用户想知道哪里可以获取某现实产品或服务的地理位置。
⑤列表(List): 用户想得到一组可信的网站列表, 以便进一步查询。
(2) 资源类(Resource)
①获取(Obtain): 用户想获得一个不是必须通过电脑才能使用的资源, 如歌词、菜谱等。
②下载(Download): 用户想获得需要安装在本地电脑或者在其他电子设备上才能使用的资源(如某软件APP)。
③娱乐(Entertainment): 用户只是想查看或获取网页上的娱乐资源。
④交互(Interact): 用户想通过在结果页上所得到的动态程序或服务与其它资源进行交互, 如地图查询、股票收益等。
(3) 导航类(Navigation)
用户想访问已知的某特定网站或主页。McCreadie等[22]研究表明, 将与查询相关的内容(如点击文档)融合到标注界面中能提高标注结果的准确度。基于此, 本文在标注界面添加了用户提交查询后在Sogou查询日志中排名前4的点击结果页。若通过以上信息, 标注者对该查询的判定仍具有模糊性, 或用户点击列表中存在死链接, 可利用该界面中的“ 百度搜索” 或“ 搜狗搜索” 链接在搜索结果中对专指度类别进行判定。对于查询串每条内容特征(见表1), 笔者要求标注者一一选择, 若符合要求, 则选择“ 是” 选项; 否则选择“ 否” 选项。
因此, 本实验标注内容包括三大部分: 专指度类别标注、查询意图类别标注和查询串属性特征标注。标注工作由10名武汉大学信息管理学院图情专业硕士研究生分10个小组完成, 每人负责一个小组的标注工作: 前9个小组每组标注646条数据, 最后一个小组标注642条数据, 形成标注数据集。
Cohen[23]提出用KAPPA系数作为评价判断的一致性程度指标。为此, 实验从标注数据集中以小组为单位随机抽取了10%的查询(共计646条数据)由另一名图情专业学生进行标注, 并计算其标注结果与抽样数据集标注结果的KAPPA值, 以评价标注者之间对专指度分类的一致性, 检验个人主观因素对分类标注的干扰程度。实验表明强专指度和弱专指度的KAPPA值都高于0.85(分别为0.912和0.879), 而略专指度约为0.754, 平均值为0.8483。可见, 本实验标注结果一致性较高, 且6 456条查询语句中强、略、弱专指度查询分别占查询总数的56.1%、25.5%和18.4%。
(1) 查询串属性特征分析
①查询串基本特征分析。通常, 在文本分类中, 停用表主要包括英文字符、数学字符、标点符号以及使用频率特高的单汉字[24]。而在专指度这一特定维度中, 英文字符、数学字符以及虚词等都会对分类结果产生较大影响, 因此, 本实验进行统计时仅将标点符号作为停用词进行过滤, 其他情况不做考虑。强、略、弱专指度下查询串的基本特征如表2所示。由于三类专指度在查询串长度、词项长度和词项个数上的最小值均为1, 因此主要列出其平均值、最大值和标准差。
| 表2 查询串基本特征分析 |
分析表2可知, 强专指度的查询串长度分布并不集中: 最多40个字, 最少1个字(如查询“ 天” ), 平均约7个字。而略专指度的查询串长度分布相对集中: 最多8个字(如查询“ 中国股份公司+中国” ), 最少1个字, 平均为4.35个字。弱专指度的查询串长度分布更加集中: 最多5个字(如查询“ 什么都能干” ), 最少1个字, 平均2.45个字。而且, 强、略、弱专指度查询平均分别包含3.97、2.47和1.39个词项。随着专指度强度增加, 词项长度平均值和标准差都略微降低, 而词项个数平均值和标准差都明显升高。也就是说, 专指度与查询串长度、词项个数在一定范围内成正相关, 与词项长度成负相关。因此, 可以选用查询串长度(字)、平均词项长度(字)和平均词项个数作为区分强、略、弱三类专指度的特征。
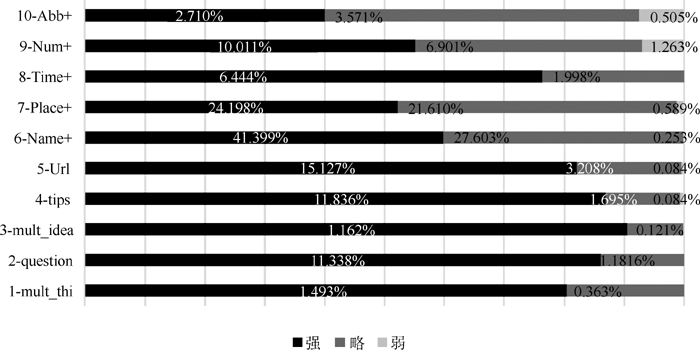
②查询串内容特征分析。在查询串内容特征分析方面, 首先统计分析每一类别专指度下符合某一内容特征(即被标注为“ 是” 的查询数目)占该类专指度查询总数的比例。如在强、略、弱专指度查询中, 包含“ 英文缩写词及其他词项” 的查询语句分别占2.71%, 3.571%和0.505%。且从图1可知, 强、略专指度在“ 包含地理坐标/地方名及其他词项” 、“ 包含数量词及其他词项” 两项特征的比例接近。对于其他特征, 强专指度查询所占比例显著高于略专指度, 而弱专指度在以上特征中所占比例很小, 换言之, 不含以上10项内容特征的查询更有可能属于弱专指度类。
 | 图1 每一专指度下符合某一内容特征的查询数目占该类专指度查询总数比例 |
再统计分析每一类别专指度下符合某一内容特征占符合该特征的查询语句总数的比例。例如, 当查询语句包含“ 数量词及其他词项” 时, 强、略、弱专指度查询约占总数的73.735%、23.22%和3.05%。图2表明随着专指度从强到弱, 各项内容特征在每类查询中的百分比明显降低。其中, 诸如包含内容特征第1项-第5项(见表1)的查询很可能属于强专指度类; “ 包含英文缩写词及其词项” 、“ 包含坐标/地方名及其词项” 的查询较有可能属于略专指度类; 而弱专指度基本不符合任一特征。可见, 除查询串基本特征外, 选择以上10项内容特征有效识别专指度是十分必要的。
 | 图2 每一专指度下符合某一内容特征的查询数目占符合该特征的查询总数的比例 |
(2) 查询专指度与查询意图分析
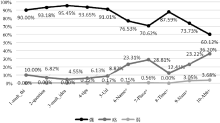
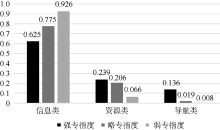
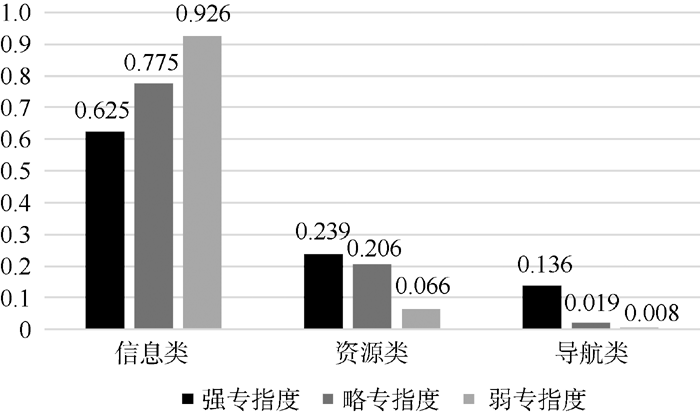
Baeza-Yates等[25]指出查询意图(即查询目标)是查询语句的最重要维度。为了更好地理解专指度与查询意图类别间的关系, 进一步讨论专指度在各意图类别及其子类别下的分布情况及所占比值, 分析所采用的意图类目体系为Rose二层查询意图类目体系, 如图3和图4所示:
 | 图3 专指度查询在三大意图类别中的比值 |
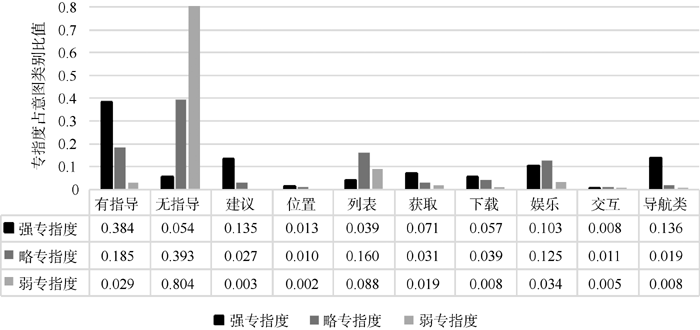 | 图4 专指度查询在子意图类别中所占比值 |
从图3、图4分析可知, 不管查询语句属于哪一种专指度类别, 大多数查询的目标为信息类, 资源类次之, 最后为导航类。而且, 随着专指性强度降低, 查询目标为信息类的比例显著增加, 为导航类的比例显著减少, 为资源类的比例虽逐渐减少但波动不大。
具体而言, 有指导类、建议类、导航类在强专指度查询中所占比例明显高于略、弱专指度查询。而无指导类在弱专指度查询中所占比例显著高于其他两类专指度。
第4节主要选取查询串基本特征和内容特征共13个属性特征作为分类特征。在识别阶段, 基于以上特征利用已标注的数据集选用常见的Web文本分类器实现专指度的自动识别。最后, 采用十折交叉检验对实验结果进行分析、比较与评测。
目前, 在众多的Web文本分类模型中, 应用最为广泛的是决策树[26]、支持向量机(Support Vector Machine, SVM)[27]和朴素贝叶斯模型[28]。因此, 本文分别训练上述三种分类器对专指度进行自动识别。
(1) 利用决策树算法识别专指度
采用C4.5[29]决策树分类法对6 456条查询语句进行强、略、弱三类专指度自动识别。分类特征共13个, 包括3个查询串基本特征及10个查询串内容特征(如Mult_thiCompare, Mult_idea, IsUrl)。根据以上特征所构造的决策树分类效果良好: 宏平均准确率为0.853, 强、略、弱专指度准确率分别为0.888、0.724和0.927。
(2) 利用SVM算法识别专指度
SVM模型建立在小样本统计理论基础上, 在解决有限样本、非线形及高维模式识别问题中具有特有的优势。而且在进行文本分类时, SVM的总体分类效果往往好于决策树[30]。因此, 本文在原标注数据集上训练SVM分类器完成识别。实验结果表明当核函数为径向基函数, cost、gamma值分别为1 024、1时, 强、略、弱专指度准确率分别为0.9、0.72和0.935, 宏平均分类准确率为0.86。与利用决策树算法识别专指度相比, SVM分类效率略好于决策树, 但在略专指度识别效果方面, 两者表现都不够好。
为此, 本文计算出专指度分类结果的混淆矩阵, 表示某一类别被判别为另一类别(包括本类别)的数目, 如表3、表4所示。例如, 对于强专指度查询, 有3 384条被决策树算法正确分类, 有236条被错误分类成略专指度查询, 有2条被错误分类成弱专指度查询。分析表3、表4可知, 强、弱专指度之间绝大多数都能正确分类, 而强、略专指度之间和略、弱专指度之间错误分类的查询数目较多。
| 表3 决策树分类结果的混合矩阵 |
| 表4 SVM分类结果的混合矩阵 |
(3) 利用朴素贝叶斯算法识别专指度
决策树或SVM分类器均已取得了较好的识别效果。但为了降低略专指度被错误分类的影响, 本文考虑将查询语句与各类专指度之间的映射关系以概率的形式表现出来。朴素贝叶斯算法假设实例的所有属性之间相互独立, 并独立地学习每个特征在每一给定类别下的条件概率, 分类器应用贝叶斯公式计算某特定实例在给定属性值下各类别的后验概率, 并返回使后验概率最大的类别[31]。然而, 该算法的独立性假设在实际研究中很少满足, 但文献[32]表明朴素贝叶斯算法的表现与独立性假设是否满足没有必然联系。因此, 最后选用朴素贝叶斯分类器实现专指度自动识别。
实验中, 朴素贝叶斯分类器计算查询语句被判断为某一特定类别的概率, 选择具有最大后验概率的专指度类别作为该查询语句所属的类别。表5列出了一些略专指度查询被识别成强或弱专指度类别的后验概率值。可知, 以概率的形式表示查询专指度比将查询语句直接判定为某类别, 能够在一定程度上降低略专指度被错误分类的影响。
| 表5 略专指度查询被分类为强或弱专指度查询的后验概率值 |
在评估分类效果时, 为减少实验误差, 均采用十折分层交叉验证[33]的方法, 选取准确率P、召回率R、F-measure[33]三个参数评估实验结果, 如表6所示。其中F-measure是一个综合考虑准确率和召回率的测试参数, 本文认为P和R有相等的权值, 因此采用常用的F1。
| 表6 十折交叉检验的实验结果 |
从表6可知, 三种分类器的F-measure均高于0.8, SVM分类效果最好, 决策树次之, 最后为朴素贝叶斯。具体而言, SVM对查询专指度的分类宏平均准确率略好于决策树(约0.7%), 且前两者都好于朴素贝叶斯(分别为4.4%和5.5%)。然而, 朴素贝叶斯分类器计算所得的后验概率值能够更直观地表示并区别查询语句属于某一专指度类别的可能性。总之, 以上三种识别方法应视具体情况进行选取。SVM分类器鲁棒性好但内存开销大、运行时间长, 而决策树和朴素贝叶斯算法简单, 运行时间快但难以处理大数据[26]。在不考虑内存开销、训练时间的情况下, 为保证较高的分类准确率, 选用SVM分类器; 否则选择决策树。当需要以概率的形式表示分类结果以便应用到检查模型中时, 优先选择朴素贝叶斯分类器。
本文基于综合搜索引擎Sogou查询日志, 人工构建查询专指度标注集, 统计分析各类别下查询串基本特征及内容特征, 并以此作为专指度的分类特征。选用决策树、SVM和朴素贝叶斯分类器实现查询专指度的自动识别。通过实验发现:
(1) 专指度确实与查询串长度在一定范围内成正相关。长查询串一般是强或略专指度查询, 但短查询串也有可能是强专指度查询。
(2) 当用户查询语句含有某一内容特征尤其是前5项中任一项(见表1)时, 很可能是强专指度查询, 当含有内容特征6、7、10时也有可能是略专指度查询, 当不含上述内容特征时, 有较大可能是弱专指度查询。
(3) 专指度与查询目标之间关系密切, 弱专指度查询大都属于信息类, 略专指度查询基本不属于导航类, 而强专指度查询属于各类别均有可能。
尽管本文尝试对专指度进行全面透彻的分析, 但仍存在以下不足, 也是后续研究的主要方向:
(1) 除查询串属性特征外, 如何借助外部资源挖掘其他特征(如点击结果页), 进一步提高专指度识别准确率。
(2) 尽管有研究表明朴素贝叶斯分类器的表现与独立性假设是否满足没有必然联系, 但在本实验中是否如此仍需验证。
(3) 除查询目标外, 如何将专指度与其他维度(如时间、地理等维度)结合起来, 综合分析多维度之间的相互影响。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|