

{kind=link}
{kind=link}
专利检索日志的同义词获取
[谷威1 , 李超凡1 , 王洪俊2  , 肖诗斌
, 肖诗斌3 , 施水才3 ]
, 肖诗斌|
|


作者贡献声明:
谷威, 李超凡: 提出专利日志的词典获取算法, 设计研究方案;
王洪俊, 肖诗斌, 施水才: 完善多特征结合的同义词识别方法, 设计研究方案;
谷威, 王洪俊: 采集、清洗和分析数据, 实施实验;
谷威, 李超凡, 王洪俊: 论文起草;
王洪俊: 最终版本修订。
【目的】研究专利检索日志中的同义词获取方法。【方法】提出一种基于用户行为分析的语义关系获取算法, 利用检索式的逻辑运算符关系提取候选同义词对, 结合拼音、字型、缩写、简繁等特征, 从专利检索日志中挖掘出一部同义词词典。【结果】实验结果表明, 该方法识别同义词的准确率达到74.5%, 共生成17 495组同义词, 生成词典的规模超过目前已有研究中的一些方法。【局限】 该词典生成算法较适用于使用复杂检索式的图书情报检索领域。【结论】丰富了基于日志的语义词典获取领域的研究。
[Objective] This paper researches on the acquisition of synonym from patent query logs.[Methods] Propose a method based on the analysis of user behavior. Use logic expression parser to generate candidate synonym pairs, combine features such as pinyin, Chinese character pattern, abbreviation, traditional Chinese and simplified style to generate a synonym dictionary.[Results] Experiment results show that precision rate reaches 74.5%. This method generates 17 495 synonym pairs and the scale of dictionary exceeds some existing methods.[Limitations] This method is feasible for library and information retrieval with complex expressions.[Conclusions] This research provides a certain significant reference for log-based knowledge acquisition.
随着我国知识产权领域的蓬勃发展, 专利检索工具的开发和利用得到越来越多的关注。目前, 国内外已经出现了很多专利信息检索与利用方面的软件和工具, 如美国汤森路透集团的专利软件Aureka[1]和TDA[2]、知识产权出版社开发的PIAS专利信息分析系统[3]、保定大为软件开发的PatentEX[4]等, 这些软件和工具能够快速有效地对网络专利信息进行检索和利用, 不过这些系统大多采用关键字匹配的信息检索技术, 忽略了词间的语义关系, 不能解决同义词、多义词、词间上下位关系等问题, 造成信息检索不全面、不准确。针对这一问题, 国内外很多研究者从语义或概念的角度进行了广泛而深入的研究, 其中基于语义词典对用户检索式进行查询扩展是一种常用而有效的方法[5], 但是如何构造适合专利领域的高质量语义词典一直是个难题, 因此基于用户行为分析的知识库构建方法得到了越来越多的关注。
通常, 专利检索系统的日志记录了用户的检索工作轨迹, 包括专利检索过程中所使用的各种检索表达式、浏览过的各种专利记录等。这些日志里蕴含着丰富的专业知识, 集中体现了用户积累的检索经验。如何挖掘并利用这些知识来提升专利信息检索系统的效果, 这个问题日益得到研究人员的重视。
本文提出一种基于用户行为的语义关系获取算法, 可以从检索日志中挖掘出一部同义词词典, 将该词典应用于查询扩展有助于提升专利检索效果。测试结果表明, 本文基于日志生成的同义词词典具有较高的质量。
目前国内外对于同义词自动识别的研究, 按采用的技术路线, 主要可分为基于字面相似度、基于语义词典、基于大规模语料库的词汇同现关系以及基于检索日志的方法。
(1) 基于字面相似度
该方法主要根据字面相似性原理, 即汉语中绝大多数同义词、近义词都含有相同语素这一特点, 根据两个词汇中相同字的个数计算词与词之间的关联程度。文献[6]通过字面相似匹配的方法查找新术语与主题词的相关关系, 并提出在计算中同时考虑匹配字数和词汇结构两方面的因素。文献[7]利用汉语词汇字面相似性原理进行词汇归类。由于汉字数量繁多, 存在一字多义现象, 容易产生歧义, 因此单一的基于字面相似度的算法准确度不高。
(2) 基于语义词典
这种方法借助已有的语义词典计算词汇之间的语义相似度。文献[8]使用自建的词素语义词典将待识别的词切分成多个词素, 以计算两词的相似度。文献[9]利用WordNet计算词语的语义相似度时, 除了节点间的路径长度外, 还考虑语义树的深度、区域密度等因素。文献[10]采用《知网》把两个词语之间的相似度问题归结为两个概念之间的相似度问题。基于语义的方法具备良好的理论基础, 但应用该方法的前提条件是具备一部词汇丰富、编制精良的语义词典以及准确的语义词素切分算法。
(3) 基于大规模语料库的词汇同现关系
这种方法将词汇出现的上下文语境表示成向量。文献[11]计算词汇向量的余弦相似度作为两词的语义相似度。文献[12]在此基础上引入浅层句法分析, 只处理名词, 将语料库中此名词的所有修饰词作为上下文, 用Jaccard相似度计算语义相似度。文献[13]提出一种基于互信息的方法计算两词的相似度。文献[14]对文献[12]的方法进行改进, 要求两词必须完全相邻, 并且过滤搭配和修饰等噪声, 提高了语义相似度计算的准确率。基于语料库方法所识别的同义词容易受语料库所属领域的限制, 并且存在数据稀疏的问题。
以上同义词识别方法还存在一个限制, 即需要先构建一部候选词词典, 才能进行词语之间的同义词识别。对于很多专业领域, 构造词典也不是一项简单的工作。
(4) 基于检索日志
检索日志中包含用户使用的查询词, 通过检索日志可以快速生成一部查询词典, 因此基于检索日志的方法节省了词典生成这一步的工作。
基于检索日志的方法可以通过分析查询词与内容文档之间关联关系, 发现同义词。文献[15]提出一种简单而有效的方法, 通过对查询日志应用协同点击分析方法, 即通过分析点击同一文档的不同查询词, 发现上下文敏感的同义词。这种方法存在一个限制, 即如果文档的点击量较少, 或者查询式中包含较多检索词的情况下, 难以准确确定词语之间的语义关系。
本文收集了某专利检索系统的检索日志, 日志里记录了用户提交的检索任务及检索结果, 包括任务编号、布尔查询条件、检索耗时、命中记录条数等信息。该批日志共包含149万多个查询表达式, 表达式的平均长度为24.9个字节, 其中包含逻辑“ 与” (and)的表达式1 169 513个, 包含逻辑“ 或” (or)的表达式366 150个, 包含逻辑“ 非” (not)的表达式20 821个, 包含逻辑“ 比较” (> , < , > =, < =, !=)的表达式19 431个。日志的格式及范例如表1所示:
| 表1 检索日志信息表 |
对检索日志分析可以发现, 用户的检索行为有如下特点:
(1) 用户具备较专业的检索能力, 能够使用复杂的布尔检索式进行检索, 检索式中包含丰富的检索词、逻辑运算符等信息, 检索表达式的平均长度及复杂程度明显高于互联网搜索日志。
(2) 用户构造检索式时, 会添加查询词的同义词、近义词、上下位词、搭配词等检索要素, 扩展检索范围, 使得检索结果更为全面, 避免疏漏。这一特点使得专利检索日志中包含丰富的同义词, 适合用来获取同义词词典。
(3) 用户能够使用不同的检索要素如分类号、发明人等进行组合检索, 通过限制检索范围, 使得检索结果更为精确。
对大量的专利检索日志数据进行研究后, 本文将专利检索领域具有代表性的同义词分为以下7类:
(1) 中文与对应的外文翻译
这类同义词主要是对同一品牌、机构、技术术语的中文和外文的不同表达, 例如: computer-计算机, Suramin-舒拉明。
(2) 外文同义词
这类同义词主要指某个概念的外文的不同表达, 如dc-digital camera, phone-telephone。
(3) 全称与简称
这类词指一个概念的完整名称与简写、缩写形式。例如: 电动机-电机, 维生素C-维C, 枸杞子-枸杞。
(4) 简繁体同义词
这类词由用户分别使用繁体字和简体字表示。专利库中有中国大陆专利、中国台湾专利、中国香港专利及中国澳门专利, 为了完整检索不同地区的专利, 用户会使用词语的简体写法和繁体写法。例如, 頻域-频域, 天綫-天线。
(5) 异体同义词
这类词一部分由同一外文词在中国不同地区的翻译用词差异所引起。例如, 计算机领域的外文词在中国大陆和中国台湾的翻译有较为明显的差异, 软件-软体; 芯片-晶片。
另一部分由高频使用的错别字引起, 若专利文本中包含很多类似的因用户录入错误产生的错别字, 则此错别字也不可忽略。例如: 板蓝根-板兰根(读音相似), 阈值-阀值(字形相似), 活性炭-活性碳(异体字)。
(6) 传统同义词
指两词都较常用且指同一事物, 且不归入以上类别的词。例如, 电脑-计算机, 搜索-查询。
(7) 特定领域的同义词
专利领域的一个显著特点是同一词汇在不同领域中有不同的语义, 从而有不同的同义词。例如: 终端一词, 在计算机领域下, 其同义词可能是监视器、键盘或打印机。在移动通信领域, 其同义词则是手机。
根据以上分析并结合现有的同义词识别方法, 本文对基于专利检索式的同义词识别方法有如下总结:
(1) 可通过简繁词识别技术识别简繁体同义词。
(2) 可通过拼音编码比对技术识别同音异体词。
(3) 用户检索式中的同义词有些可以通过字面相似度识别, 如四氯二氰苯、四氯间苯二腈、四氯间苯二甲腈。
(4) 有些同义词无法通过字面相似度识别, 如百菌清和四氯间苯二甲腈。
(5) 由于专利信息检索领域文献量巨大, 新术语层出不穷, 很难找到一部完备的语义词典应用于基于语义的同义词识别算法。
(6) 专利检索式的自身特点有助于对同义词进行识别。
因此, 本文借助基于用户行为分析的同义词识别算法, 从专利检索日志中获取同义词。
本文以专利检索日志为基础, 研究专利检索用户的行为特点, 提出一种基于用户行为分析的同义词自动识别方法。根据检索式中蕴含的逻辑关系获取同义词候选集合; 根据用户输入行为特点识别词语的简繁同形关系、同音关系、字面形似关系、缩写相似等特征; 借助多特征加权打分判断是否同义。
算法流程如图1所示:
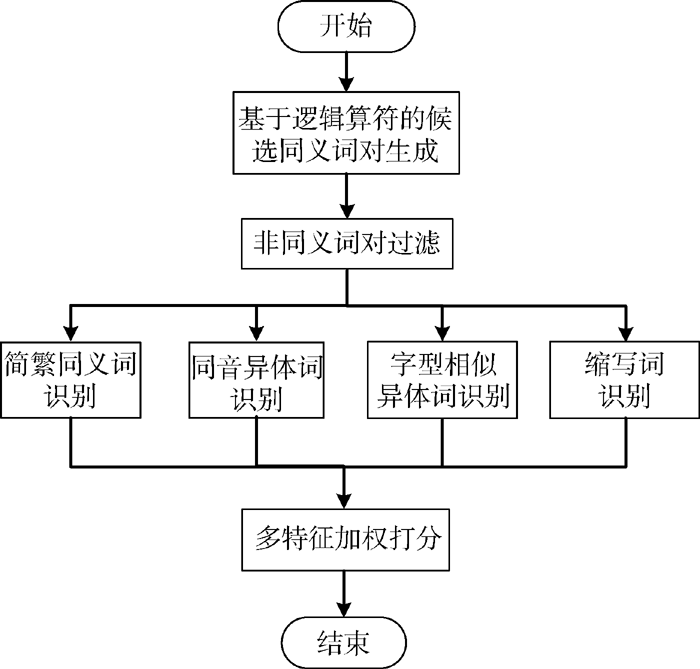 | 图1 基于用户行为分析的同义词识别 |
布尔检索模型是专利领域最常使用的一种检索模型, 它采用布尔表达式查询, 即通过“ 与” (and)、“ 或” (or)、“ 非” (not)等逻辑运算符将词项连接起来进行查询。逻辑运算符“ 与” 、“ 或” 、“ 非” 等提供了一种有效的手段, 帮助用户准确地表达自己的检索意图。经验丰富的用户能够使用同义词、上位词、下位词、近义词、分类号等检索要素构造一个有效的布尔检索表达式, 快速得到准确的检索结果集。
经过对专利日志中布尔检索式的分析, 可以发现逻辑运算符与检索要素之间的语义关系如下:
(1) 逻辑运算符“ 与” 连接的两个词多是相关关系
例1 断桥and保温and保护and墙
(2) 逻辑运算符“ 非” 连接的两个词多是相关关系
例2 柱and梁and角码and限位槽
(3) 逻辑运算符“ 或” 连接的两个词多是同义关系
例3 (香蕈or香信or香菇or冬菇or椎茸or香菌or平庄菇) and (白灵菇or阿魏蘑or阿魏侧耳or阿魏菇or白灵蘑) and (饮料or A23L2/ic or饮品)
除了同义关系外, “ 或” 连接的语义关系还包括近义关系、上下位关系等。
例4 氧化铁or四氧化三铁or fe2o3 or fe3o4
例5 (聚合物or橡胶or塑料)
例6 百合or薏苡仁or茯苓or枸杞or中药
根据上述分析, 本文决定采用表达式分析技术, 根据逻辑运算符“ 或” 关系提取检索式中的同义关系。采用开源的词法和语法分析工具Lex & Yacc[16]进行检索式的语法分析。
词法分析程序生成器Lex可以根据词法规则说明书的要求生成单词识别程序, 由该程序识别出输入文本中的各个单词。
通过Lex可以识别出检索式中的各个组成要素, 包括运算符、保留字、字段名、字段值、检索词等, 为后续的表达式分析做准备。如例3的检索式切分结果如表2所示:
| 表2 检索式的词法分析结果表 |
语法分析程序生成器Yacc可以将有关某种语言的语法说明书转换成相应的语法分析程序, 由该程序完成对相应语言中语句的语法分析工作。
通过Yacc可以识别出表达式的语法结构, 在此基础上, 把检索式的语法结构由二叉树表示出来。每个检索要素对应二叉树的叶子节点, 每个逻辑算符对应二叉树的中间节点。之后需要对二叉树进行压缩, 对相邻的二叉树节点进行合并。如果相邻的两个二叉树中间节点具有相同的运算符, 如or 或 and, 则对两个中间节点进行合并, 把它们的叶子节点归并到一起, 从而把二叉树变成多叉树。二叉树压缩的理论依据是两个or或两个and的运算顺序是可交换的, 不影响最终的运算结果。
经过压缩后, 最终得到如图1所示的一棵分析树:
 | 图2 检索式的分析树 |
最后, 对多叉树进行遍历, 把父节点为“ 或” 算符的同一组子节点两两输出, 作为同义词候选词对, 供后续进行处理。
以上布尔表达式分析方法生成的候选同义词对数量较多, 因此, 进行如下过滤处理。
(1) 暂不考虑中文与对应的外文翻译以及外文同义词, 对包含外文的同义词候选对做过滤处理。
(2) 对表达式中的人名对(申请人或发明人)、数值对进行过滤。
同义词是指向同一事物的两个不同的词语, 常常含有共同的语素, 例如, 荧光灯-夜光灯, 玻纤-玻璃纤维, 因此可以根据字面特征计算相似度。
另外, 专利申请文本中常出现错别字, 如中药“ 白茅根” , 专利申请人由于输入错误使用“ 白毛根” , 当很多人都习惯于如此输入时, 专利审查员在构造检索式的时候也会考虑这个问题。另外, 为了同时检索中国大陆和中国台湾的专利, 审查员会同时输入简体和繁体的词语。
因此, 本文在考虑简单字面特征的基础之上, 着重选择与用户行为相关的特征。经过分析与试验, 选择简繁体输入转换、拼音输入相似、缩写相似和五笔输入相似4种常见的与用户输入行为相关的同义词特征。
(1) 简繁输入特征
对用户输入的简繁体差异进行识别, 方法是采用简繁转换软件, 对候选同义词进行简繁转换, 观察转换后的词语字型是否相同, 如果相同, 则判定为简繁异体词。
(2) 拼音输入特征
采用汉字拼音编码表为候选同义词对的两个词标注拼音, 计算两个词语的拼音编码是否一致。如果一致, 则判定为同音异体词。
另外, 还做了卷舌音和平舌音的检测, 例如 sh-s, zh-z, ch-c, 如果两个词语的拼音编码仅有卷舌音和平舌音的差异, 也可判定为同音异体词。
(3) 缩写词识别
缩写词的识别主要采用基于规则的方法, 识别规则有如下两种:
①从词对中任选一个词进行分词, 提取分词结果中每个词语的首字或尾字, 拼接后得到一个缩写词, 比较缩写词与词对的另一个词是否一致, 如果一致, 则认为候选同义词对是缩写词的关系。例如: 电路板-电板, 电风扇-电扇, 公共密钥-公钥。
②检测候选词对中的一个词是否带“ 子” 等后缀, 去掉该后缀后, 是否可以生成词对的另一个词, 如果可以, 则可以识别出一些简单后缀的缩写词。如枸杞子-枸杞, 决明子-决明。
(4) 相似字形特征识别
相似字形识别主要考虑用户在输入过程中可能发生的错误, 识别方法有以下三种:
①计算互为词对的两个查询词之间的编辑距离, 如果两个词都是三个字以上, 且编辑距离小于1, 则可能是字型相似的异体词。
②采用五笔字型编码表为词对的两个词标注五笔编码, 计算两个词语的五笔字型编码的编辑距离, 如果编码的编辑距离小于等于2, 则可以判定为两个词语为字型相似的异体词。例如: 阀值-阈值, 黄岑-黄苓。
③另外, 用户输入时, 有时会把词语中的两个字颠倒位置, 如: 蚀刻液-刻蚀液, 压紧-紧压。对于这种情况, 可以通过增加词语位置检测规则的方法进行识别。
为了把简繁同形关系、同音关系、字面形似关系、缩写相似等多种识别方法结合起来, 本文采用一种多特征集成的同义词对评分算法, 把上述多种方法的评分结果以线性加权的方法结合起来, 给不同方法的计算结果分别赋予合理的权重, 经过加权组合后得到优化的相似度值, 从而实现比单一特征更好的识别结果。
主要思路是: 使用不同的特征计算方法计算每个候选同义词对之间的相似度, 把不同相似度计算方法的结果作为输入特征, 采用基于线性加权的方法或分类器的方法进行打分, 将打分结果作为最终的相似度值。其中, 线性加权方法的打分公式如下:
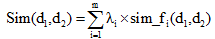
其中, m是不同计算特征的个数, λ i是加权系数, sim_fi(d1, d2)表示不同的特征计算方法, d1、d2指候选同义词对的两个词。加权系数λ i的权重可以根据经验设置, 也可以采用机器学习方法自动获得。本文采用根据经验进行设置的方法。
本文收集了某专利检索系统的149万多条检索日志, 经过布尔检索式逻辑运算符分析得到26万多对候选词汇, 进行英文、数字串、人名对过滤等操作后, 得到23万多对候选同义词对。
将23万多候选同义词对分别计算简繁特征、同音特征、同形特征、缩写特征、翻译结果相同等特征, 并采用多特征加权算法进行打分, 根据打分结果对候选同义词对按分值大小排序, 并根据人工确定的阈值(如0.8)筛选, 最后得到17 495对同义词。对同义词结果采用抽样方法, 随机选择3 000对进行人工判断, 正确的同义词对数为2 235个, 识别准确率为74.5%。
同义词识别的部分结果如表3所示:
| 表3 同义词对识别结果表 |
从测试结果可以看出:
(1) 基于多特征打分的同义词对识别算法是一种有效的算法, 具有较高的准确率。
(2) 布尔“ 或” 算符蕴含的语义关系, 除了同义关系外, 还有上下位关系、同类并列关系、从属关系、词组搭配关系等语义关系。同音、同形等用户特征的引入, 可以更准确地提取同义词, 排除掉这些语义关系的影响。
(3) 本文提出算法的同义词产出量较高, 100多万条日志中就可以产生1万多组同义词对。以往的一些同义词获取算法虽然得到了较高的同义词准确率, 但其产出量较低, 生成的同义词规模多在千词以内。
以上实验结果表明, 本文基于用户行为的同义词获取算法具有较好的应用价值。
自动构建大规模的机器可读的知识库是信息检索的一个重要研究方向。本文对基于专利检索日志的同义词获取进行了研究, 取得了如下进展: 提出一种基于用户行为分析的多特征结合的同义词识别算法, 根据逻辑运算符关系从检索表达式中获取同义词候选词对, 根据词对之间的同音关系、字形相似关系、缩写关系、简繁同形关系等特征计算词语的相似度值, 通过多特征加权模型对候选集的词对进行同义词判定。实验结果表明, 生成的词典具有较高质量, 本文提出的同义词识别方法是一种有效的算法。
下一阶段的工作方向主要包括两个方面:
(1) 布尔“ 或” 算符蕴含的语义关系, 除了同义关系外, 还有上下位关系、同类并列关系、从属关系、词组搭配关系等语义关系, 将这些语义关系分别提取出来, 将有助于更好地识别同义关系。
(2) 引入基于语义的词语相似度计算特征, 以进一步提升同义词的识别效果。
希望本文的工作可以为专利检索系统的研究与开发利用提供有益的帮助。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|