
{kind=link}
{kind=link}
基于知网语义相似度的中文文本分类研究
[刘怀亮, 杜坤 , 秦春秀]
, 秦春秀]
, 秦春秀]
|
|


作者贡献声明:
杜坤, 刘怀亮: 提出研究思路, 设计研究方案;
杜坤: 进行实验验证;
杜坤, 秦春秀: 论文起草;
秦春秀: 论文最终版修订。
【目的】准确计算中文文本间的相似度, 以提升文本分类的精度。【方法】利用TF-IDF算法计算特征词项权值, 并借助知网分析词项间的语义关系, 提出一种基于知网语义相似度的文本相似度加权算法, 并对该算法进行中文文本分类实验。【结果】实验结果表明, 该方法较传统的文本相似度计算方法在文本分类性能上有所提高。【局限】 该算法的时间复杂度较高, 文本分类的处理速度有待提高。【结论】该方法考虑特征项间的语义关系, 能够有效提升中文文本的分类精度。
[Objective] This is an algorithm for improving the classification precision of Chinese text classification, which can calculate the similarity between Chinese texts more accurately.[Methods] With the TF-IDF algorithm calculating item weight and HowNet analyzing the semantic relationships between lexical items, this paper proposes a text similarity weighting algorithm based on HowNet semantics similarity, and makes an experiment on its Chinese text classification.[Results] The experiment resualts show that the proposed method can improve the text categorization performance comparing with the traditional ones.[Limitations] This algorithm is quite high in its time complexity, and its speed of text classification needs to be improved.[Conclusions] It is proved to be an effective algorithm for enhancing the classification accuracy of Chinese text by analyzing the semantic relationships between feature items.
随着计算机及手机的普及和网络的迅速发展, 互联网上的文本信息正在以指数级的速度增长。中国互联网络信息中心(CNNIC)于2014年7月发布的第34次《中国互联网发展状况统计报告》[1]中显示, 截至2014年6月, 中国网站数量为320万, 网民规模达到6.32亿, 较2013年底增加了1 442万。面对网上海量半结构化和非结构化的文本信息, 如何快速有效地进行分类组织管理, 为用户提供有用信息变得非常重要。
作为一种有监督的学习, 文本分类是文本挖掘的关键技术之一, 其目的是对文本进行有效的组织与管理, 便于用户准确定位所需信息。在自动化文本分类过程中, 文本相似度计算是进行文本分类的关键环节。文本相似度是表示两个或多个文本之间匹配程度的一个度量参数, 相似度越大, 说明文本相似程度越高, 反之文本相似程度越低。传统的文本处理大部分是根据词频和逆向文档频率将文本表示成向量空间模型(Vector Space Model, VSM), 实践证明这种模型确实简单高效并且得到了广泛应用, 但这种模型表示缺乏对语义的理解, 忽略了词与词之间的语义信息, 丢失了很多重要的语义信息。
为此, 许多学者将知网引入到向量空间模型中, 使用知网的知识库计算文本中词语的相似度, 刘青磊等[2]通过统计义原集合间的共性和个性计算句子间的相似度, 但只是把词语的直接义原看成一个大的集合, 没有全面考虑义原关系; 唐歆瑜等[3]通过计算特征词间的语义相似度进行特征降维以提升文本分类的准确率, 但没有进行词义的消歧; 江敏等[4]考虑文本的感情色彩, 对词语进行极性识别, 提高词语相似度的准确性; 朱征宇等[5]利用知网中义原之间的线性关系, 结合二部图最大权匹配进行概念相似度的计算, 这些利用知网提高词语相似度的思想为文本相似度的计算提供了新的思路。此外, 也有学者利用知网义原和概念的相似度实现文本相似度的计算, 如肖志军等[6]和白秋产等[7]分别利用知网将文本表示为义原空间向量和概念空间向量, 但只是把词语用知网中的义原或概念表示, 没有考虑词语在文本中所占的比重。
本文将基于知网的语义相似度计算引入到中文文本分类中, 运用一种基于词语消歧的知网语义相似度计算方法, 提出加权的文本相似度计算方法。与文献[6, 7]不同, 本文综合考虑了特征词项在文本中所占的比重, 对文本相似度进行加权处理, 提出新的文本相似度计算公式, 以提升文本分类的精度。
向量空间模型是由Salton等[8]在20世纪60年代提出的, 最早成功应用于信息检索领域, 后来又在文本分类领域得到了广泛的应用。在向量空间模型中, 每一篇文档都视为N维空间中的一个向量, 每个向量由其特征项及其权值表示, 例如一篇文档d, 它可以表示成(t1, t2, t3, …, tn), 其中每一个ti(i=1, 2, 3, …, n)代表一个词条即特征项。对于每一个ti, 根据其在文档中的重要程度赋予一定的权值Wi, 这样可把(t1, t2, t3, …, tn)看成是具有N维坐标系的坐标轴, 而(W1, W2, W3, …, Wn)视为这n维坐标轴中的坐标值[9]。特征词的权值计算主要采用TF-IDF方法, 这样对于任一个包含n个特征词的文档d可以表示成二元组的形式, 即d=((t1, W1), (t2, W2), (t3, W3), …, (tn, Wn))。
通过对文档集合中的每一个特征项进行TF-IDF计算, 得到每一篇文本的N维特征项的权值。为了使模型具备可计算性, VSM假设词与词之间是不相关的, 以保证特征项之间的正交性, 通过计算两个文本向量之间的距离远近表示两个文本之间的相似程度。文本间的距离表示比较常用且效果较好的方法是余弦相似度, 如公式(1)[10]所示:
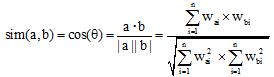 |
其中a、b表示文本向量, n为特征项个数, wai、wbi为同一个特征项Ti分别在两个文本中的权重, 如果某一文本中无该特征, 则此特征项在该文本中的权重为0。本文中的特征项权值采用TF-IDF算法并经过归一化处理, 取值范围在[0, 1]之间, 故任意两个文本的余弦相似度取值范围为[0, 1], 两个向量越靠近, 相似度数值越接近1, 越分开越接近0, 余弦相似度不考虑向量的绝对长度, 着重从方向上考虑它们之间的关系[10]。
向量空间模型假设特征项之间是正交的, 忽略了特征项之间的语义相似性和相关性, 从而导致两个相似文本的计算距离大于其实际的相似距离, 这就降低了文本分类精度。同时, 文本中的词汇数量是巨大的, 以每一个词汇作为一个维度, 容易产生维度灾难。
知网 ①(① http://www.keenage.com.
)是我国著名机器翻译专家董振东和董强历经10多年创建的一个知识系统。它是一个以汉语和英语的词语所代表的概念为描述对象, 以揭示概念与概念所具有的属性之间的关系为基本内容的常识知识库。知网有两个主要的概念: “ 概念” 与“ 义原” 。“ 概念” 是对词汇语义的一种描述。每一个词可以表达为几个概念。“ 概念” 是用一种“ 知识表示语言” 来描述的, 这种“ 知识表示语言” 所用的“ 词汇” 叫做“ 义原” 。“ 义原” 是用于描述一个“ 概念” 的最小意义单位[11]。
知网使用了2 600个义原, 分为10个类别, 根据属性把义原分为三组: “ 基本义原” 用于描述单个概念的语义特征, “ 语法义原” 描述词语语法特征, “ 关系义原” 描述概念和概念间关系。知网描述了义原之间的8种关系, 在这8种关系中最重要的是上下位关系, 基本义原通过上下位关系组织成一个树状义原层次体系, 这是语义相似度计算的基础[11]。
考虑到文本中的虚词(如代词等)在文本分类时的影响较小, 故在文本预处理中需去掉虚词, 只保留实词。实词之间的词语语义相似度计算是本文着重考虑的问题, 知网中实词概念主要是由第一基本义原描述式、其他基本义原描述式、关系义原描述式、关系符号描述式4个描述式进行表达, 基于此, 刘群等[11]提出实词概念之间的相似度计算公式, 如公式(2)所示:
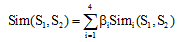 |
其中, β i(1≤ i≤ 4)是可调节的参数, 且有: β 1+β 2+β 3+β 4=1, β 1≥ β 2≥ β 3≥ β 4, 反映了Sim1到Sim4对于总体相似度所起到的作用依次递减。由于第一基本义原描述式反映了一个概念的最主要特征, 所以应将其权值定义得比较大, 一般在0.5以上。考虑到如果Sim1非常小而Sim3或Sim4比较大, 将出现整体相似度仍然比较大的不合理现象, 因此刘群等[11]修改公式(2)为公式(3):
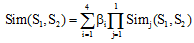 |
词语W1、W2相似度表示为各个概念的相似度的最大值。
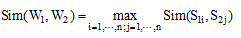 |
这种算法没有考虑到词语在上下文中的具体含义, 只是简单地选择词语的概念相似度中最大的作为词语相似度结果, 这就影响到歧义词相似度计算的准确性。
如果两个文本相似词语越多且相似词语在文本中的权值越高, 则这两个文本相似程度越高。基于上述观点, 根据刘群等[11]提出的词语相似度计算方法, 同时为保证歧义词相似度计算的准确性, 引用文献[12]的词语歧义消除方法, 在此基础上, 提出一种加权文本相似度计算方法以提高文本分类的精度。
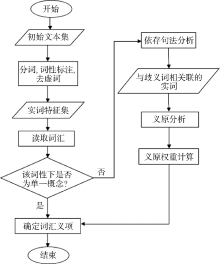
为确保词语语义相似度计算的准确性, 需要对有歧义的词语进行歧义消除, 确定该词语在文本中的准确义项。具体的消歧方法如下:
对待分析的文本进行分词和词性标注, 去掉句子中的虚词、保留实词, 保留词性为名词、动词、形容词等。对于某个存在歧义的词语, 如果歧义词语在该标注的词性下只有一个概念, 则该词语可以直接消歧。如果歧义词语在该标注的词性下有多个概念解释, 则根据句法分析得到与该词语所有关联的实词。
通过依存句法分析提取出歧义词W所在句子中与其相关联的实词(W1, W2, …, Wm), 设这m个实词分别有R1, R2, …, Rm个义项即概念, 每个Ri分解成K1i, K2i, …, Kji等j个义原(j≤ 6), 对歧义词所对应的n个义项进行同样的处理, 定义每个义原的初始权重为Weight(Kji)=1。
判断歧义词的每个义原与关联词语的某个义原是否存在知网规定的8种义原关系或者为相同义原。如果存在以上关系, 则歧义词的相应义原权重加1, 最后计算该义原所在义项的权重Wt(Ri)。如公式(5)[12]所示:
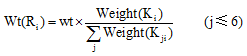 |
其中, 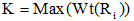
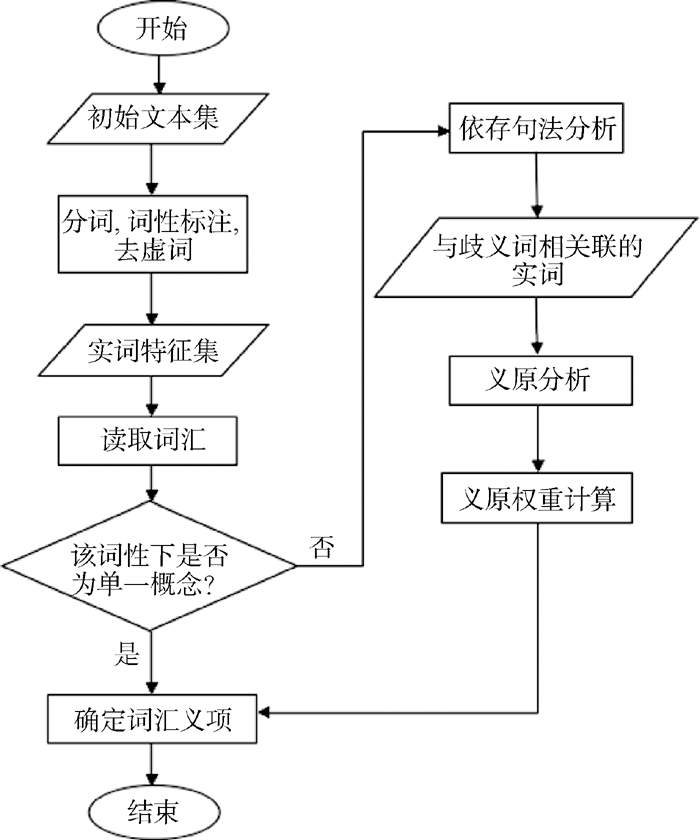 | 图 1 词汇语义消歧流程 |
确定词汇的义项后, 每个词汇的义项具有唯一性, 利用刘群等[11]提出的词汇语义相似度计算方法即公式(3)计算词语间的语义相似度, 确定词语之间的相似程度。
向量空间模型假设特征项和特征项之间是正交的, 这种假设是为了方便向量之间的余弦相似度计算而考虑的, 这种方法在提出之初确实方便了文本的相似度计算并且实际的应用效果也很不错, 但随着对文本分类精确度要求的提高, 假设特征项之间正交而不考虑特征项之间的语义情况已不能满足人们对文本分类的精度要求。
为此, 本文提出一种加权的文本相似度计算方法。在基于词语消歧知网语义相似度计算的基础上, 定义一个相似度阈值, 大于这个阈值即认为这两个词语具有相似性。如果两个文本所具有的相似词语越多, 而且相似词语在文本中的权值越高, 则这两个文本的相似程度就越高。本文采用余弦相似度作为基本的文本相似度, 并在此基础上赋予权值wf, 如公式(6)所示。
 |
根据文本向量中满足相似度阈值条件的特征项的权值在整篇文本中的权值总和中所占的比例进行加权, 具体的加权因子wf如公式(7)所示:
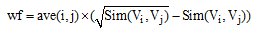 |
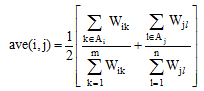 |
在公式(6)和公式(7)中, Vi, Vj表示向量空间模型中的两个文本向量, Vi=((ti1, Wi1), (ti2, Wi2), …, (tim, Wim)), Vj=((tj1, Wj1), (tj2, Wj2), …, (tjn, Wjn)), Sim(Vi, Vj)表示两个文本向量的余弦相似度, 由于Sim(Vi, Vj)的值在0和1之间, 故wf一定大于0。公式(8)中, Wik表示Vi文本向量中特征词项tik的TF-IDF权值, Wjl表示Vj文本向量中特征词项tjl的TF-IDF权值。如果文本向量Vi中的特征项tik属于集合Ai, 则把tik的权值求和并除以所有词项的权值总和, 同理处理文本向量Vj。公式(8)主要表示文档向量中所有满足相似度阈值的特征词项权值在所有词项的权值总和中所占的百分比。
集合A i, Aj的表示意义如下: 如果Vi中的特征词项tik和Vj中的特征词项tjl之间的语义相似度超过用户设定的阈值μ , 则把特征词tik加入到集合Ai中, 以同样的方法对Vj中的所有特征词进行计算, 形成集合Aj。Ai, A j可定义成如下形式:
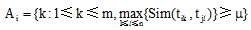
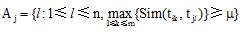
特征词项之间的语义相似度的计算要先根据知网确定词语义项, 消除词语歧义, 再利用知网根据公式(3)和公式(4)进行运算。
在词汇排歧的基础上, 利用上述知网的词语语义相似度计算方法, 确定两个文本之间的文本相似度加权系数, 以提高中文文本的分类精度。算法描述如下:
输入: 训练文本集D1和测试文本集D2。
输出: 带有类标签的测试文本集D2。
过程:
(1) 文本预处理, 对训练文本集D1和测试文本集D2进行分词和词性标注, 保留动词、名词、形容词等实词, 去除感叹词、连词、介词等虚词, 得到初始的文本特征集合。
(2) 利用知网语义词典的义原义项关系, 排除词汇语义歧义, 确定词汇语义义项。
(3) 对训练集中每类文本进行词频统计, 去除词频小于5的词语, 为了达到降维的目的, 使用CHI特征选择方法, 计算每类文本下词语的CHI值并按照降序排序, 分别取每一类CHI值排序在前500的词, 形成数据词典。
(4) 根据数据词典, 计算训练集和测试集中每篇文档中词的TF-IDF值, 形成特征向量, 每篇文档保存为HashMap键值对的形式, 其中词语为键, 对应的TF-IDF权值为值。
(5) 按照公式(7)、公式(8)计算两个文本间的相似度加权系数, 利用公式(6)计算D2中的一个文本d与训练文本集D1中的每一个文本的相似度。将计算得到的相似度值降序排列, 选取值排在前面的K篇训练集D1中的文本, 根据这K篇文本的类别对测试集文本进行分类。
(6) 在选取的与待分类文本d最近邻的K篇文本中, 利用以下公式[13]计算文本类别C j对待分类文本d的权重:
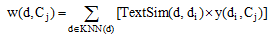 |
其中, Cj为某一文本类别, KNN(d)表示待分类文本d的K个最近邻的文本, TextSim(d, di)为本文改进的文本相似度计算公式(6), y(di, Cj)表示类别属性函数, 取值如下:
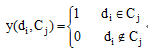
即如果训练文本di属于类别Cj, 则y(di, Cj)=1, 如果di不属于类别Cj, 则y(di, Cj)=0。将待分类文本d的类标签标记为权重最大的类别中, 返回分类结果C。
(7) 对测试文本集D2中的每一个文本重复步骤(4)和步骤(5), 得到每篇文本的类别标签。
实验数据采用从新浪、搜狐网站上爬取的6 000篇新闻文稿, 分为财经、体育、汽车、娱乐、科技、教育6个类别(其中财经、体育、汽车来自搜狐网站, 娱乐、科技、教育来自新浪网站), 每个类别1 000篇文本, 从6 000篇文本中每个类别选取800篇文本共计4 800篇作为训练集, 其余的1 200篇文本(每个类别200篇)作为测试集。选用中国科学院计算技术研究所的ICTCLAS[14]进行分词, 选取哈尔滨工业大学中文停用词表[15], 包含767个中文停用词, 采用KNN分类器, 经过反复测验, K取15时实验效果最佳, 使用CHI特征选择方法进行特征降维, 特征项权值计算采用TF-IDF算法, 词汇相似度阈值定为0.8。
对比实验中, 第一组实验采用传统的文本相似度计算方法即不考虑语义的文本相似度计算公式进行文本分类; 第二组实验采用本文所述的基于知网语义相似度加权的文本相似度计算方法。
文本分类评价指标采用使用广泛的准确率(Precision, P)、召回率(Recall, R)和Fb测度值。准确率P、召回率R公式如下:
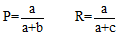
其中a、b、c表示满足一定条件的文档数量, 如表1所示:
| 表1 分类评价二元表 |
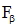
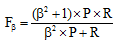
其中β 是一个调整准确率和召回率重要程度的参数, 即当β =1时, 准确率和召回率同等重要; 当β < 1时, 召回率比准确率重要; 当β > 1时, 准确率比召回率重要[16]。本文认为准确率和召回率同等重要, 故采用F1值衡量中文文本分类精度。
传统的文本分类和基于知网语义相似度的文本分类的实验结果比较如表2所示, 其中F1值对比如图2所示:
| 表2 实验结果比较 |
 | 图2 F1值对比 |
本文中测试集和训练集的比例是1:4, F1值大多处于80%左右, 而个别的像汽车、体育等类别其专业术语较多, 具有较高的区分度, F1值达到90%以上。在表2中, F1值无论是在各个类别上还是在平均值上都有所提高。这主要是因为在计算文本相似度时充分考虑了词与词之间的语义关系, 从而提高了文本相似度计算的准确性, 体现在最终分类的结果上就表现为分类精度的提高。由图2 可以看出, 对于传统分类方法分类精度相对较低的类别, 例如财经、娱乐、科技、教育等类别, 使用本文提出的方法其分类精度能得到改善, 而像体育、汽车等类别, 其分类精度的改善虽不是很明显但亦有所提升, 这主要是因为其使用传统方法的分类精度已经很高, 达到90%以上。
互联网时代, 中文信息海量增长, 而文本相似度是文本信息处理的基础和关键, 其计算的准确度直接影响文本处理的结果。本文提出一种基于知网语义相似度的文本相似度计算方法, 在传统计算的基础上, 考虑了特征项间的语义关系。通过中文文本分类实验表明, 这种方法能够有效提高分类的精度, 为文本相似度的计算提供了一种新思路。但由于加入了语义相似度计算, 导致文本分类的处理速度不是很快, 接下来会进一步探索降低文本分类时间复杂度的问题。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|