{kind=link}
中文网络客户评论可信度研究
[郝玫1  , 杨晓媛
, 杨晓媛2 ]
, 杨晓媛|
|


作者贡献声明:
郝玫: 提出研究思路, 设计研究方案, 论文最终版本修订;
杨晓媛: 采集、调整和分析数据, 进行实验;
郝玫, 杨晓媛: 论文起草。
【目的】针对中文网络客户评论, 给出一种评论可信度排序模型, 辅助消费者决策。【方法】构建评论可信度指标体系, 借助Visual Studio程序开发平台对指标进行预调整和数值优化, 进而采用问卷调查法获取指标打分, 结合模糊层次分析法构建可信度排序模型。【结果】发现与网站原始评论排序相比, 按模型获得的评论排序更科学合理, 而无“有用性投票”的评论未必不可信, 实验间接表明“有用性投票”对评论可信度重要, 但非唯一的影响指标。【局限】 指标权重设置存在主观性, 应加强权重打分的专业性。【结论】本文的排序模型综合考虑多项指标及其预调整方法, 为中文网络客户评论提供一种兼顾评论客观信息和语义特性的可信度排序方法。
[Objective] This paper proposes a review credibility sorting model in order to assist customers to make the best shopping decision.[Methods] The review credibility indexes are adjusted and optimized on the Visual Studio application development platform. Through questionnaire investigation to obtain the indexes score, credibility sorting model is constructed by Fuzzy Analytic Hierarchy Process.[Results] The experiment resualts show that compared with the Web original reviews, the new reviews sorting method is more scientific and reasonable. Those reviews without “helpful vote” are not necessarily unreliable, so the “helpful vote” is important to review credibility, but not the only factor which determines the credibility.[Limitations] People have different attitudes on factor’s weight, so the future work should attach more importance to the expertise of rating factors.[Conclusions] The sorting model in this paper synthesizes several indexes and adjustment methods, thus it provides a new credibility sorting method which considering objective information and semantic features for the Chinese online customer reviews.
网络时代的到来, 促使网上购物日益盛行, 但与传统购物相比, 网上购物的风险依然很大[1]。因此多数消费者会在做出购买决策前浏览评论, 从而知晓商品或服务的信息。然而, 海量评论信息加剧辨识可靠信息的困难程度, 阅读评论时, 消费者往往面临两个问题: 一是推测商品或服务的特点, 二是识别评论者的诚信态度和意图[2]。因此, 快速地从大量客户评论中获取可信度高的评论是本研究的实际意义所在。
客户评论对消费者决策的制定起着至关重要的作用, 不仅影响消费者对产品的选择, 还在一定程度上影响其对网购平台的选择[3]。当前一些电子商务网站根据评论发布时间或“ 有用性投票” 对评论排序, 试图给消费者展示评论排序集, 但仅仅根据某一项指标得出的排序结果显得太过片面, 无法排除某些低可信度的评论扰乱消费者判断的情况, 导致评论排序失去其原本的价值。而网站的评论排序可信度降低使得消费者失去重要的参考标准, 从而引发网购信誉危机, 影响网购市场的健康发展。
基于此, 本文综合前人的研究成果, 从影响评论可信度的多种指标出发, 通过数据预调整和文本挖掘, 对评论可信度影响指标进行量化计算, 结合模糊层次分析法构建可信度排序模型, 对纷繁复杂的评论信息进行重新排序, 获取高可信度评论, 帮助消费者做出更理性的购物决策, 同时也为电商网络平台的评论管理提供全面有效的甄别和排序方法。
近年来, 关于评论可信度的研究, 部分学者从管理科学的角度出发, 研究哪些指标影响网络客户评论的可信度。同时, 一些学者运用语义挖掘、机器学习、统计学中的回归模型及假设检验理论等方法对评论进行分类, 但这只能识别出可信度低的垃圾评论, 给出高质量评论和低质量评论的区分界限, 然而非垃圾评论数目依旧庞大, 仍无法实现可信度的排序, 消费者不能以较低的信息搜索成本快速获取商品或服务的真实口碑和客户评论。当前学术界对可信度排序的研究相对较少。
(1) 评论可信度的影响指标
本文将评论可信度定义为电子商务平台上客户评论的真实可靠程度, 能够为消费者提供准确有效的商品认知, 辅助其理性决策。在信任的基础上, 消费者的行为会随着自主性及信息交流模式的变化而改变, 从而有效降低认知风险、减少不确定性[4]。
在网络客户评论可信度或有用性的影响指标方面, 国内外学者所取得的研究成果为本文可信度指标选取提供了重要的理论支持。Liu等[5]认为对消费者购买决策有用的商品评论取决于三个指标— — 评论者的经验(Reviewer Expertise), 评论的写作风格(Writing Style)和评论的时效(Timeliness)。Mudambi等[6]通过对亚马逊网站上1 587条评论的实例研究发现, 评论深度、评论极性和商品类型会对评论有用性产生影响。刘逶迤等[7]详细分析了商品评论信息的可信度特征, 从信源、评论者本身、信息内容三个维度展开研究。孟美任等[8]选取内容完整性、情感平衡性、评论时效性以及发布者身份明确性4类特征, 采用CRFs模型对评论可信度进行分类, 通过实验得到最佳特征组合。龚思兰等[9]通过对大学生消费群体进行评论可信度影响指标的实证分析, 发现评论内容中产品描述信息的详细度、情感倾向的客观性、发布者身份的明确性、信息发布的及时性、其他评论阅读者的认同度等指标都会对评论可信度产生正面影响。李志宇[10]将评论效用指标分为已量化指标和评论语义特征, 其中已量化指标为评论长度、评论时效性、评论者信誉和评论得票数, 评论语义特征体现为产品属性特征词和情感特征词。
(2) 评论挖掘技术
国外研究者在英文评论挖掘领域取得了丰硕成果。Popescu等[11]将评论挖掘分解为4个子任务: 产品特征识别、基于产品特征的评论观点识别、评论观点的极性及强度判断、基于评论强度进行观点排序。Hu等[12]使用关联挖掘技术从客户评论中挖掘产品特征, 识别观点句, 判断每个观点句是积极或消极, 最后给出基于客户观点表达的产品特征汇总结果。由于语言表达和理解上的差异, 英文评论方面的研究成果并不能直接应用到中文评论。国内学者在中文网络客户评论挖掘领域也有相关研究, 李实等[13]拓展了基于关联规则的英文评论挖掘方法, 将其迁移到中文语境中, 提出面向中文网络客户评论的产品特征挖掘方法。
上述研究成果有助于本文对评论挖掘理论和技术的理解, 借鉴研究过程中的挖掘工具选取及相关处理步骤, 为本文属性特征词和情感特征词的抽取提供一定的经验方法。
(3) 模糊层次分析法
模糊层次分析法(Fuzzy Analytical Hierarchy Process, FAHP)通过引入模糊分析的概念, 将模糊数学与层次分析法相结合, 把两两比较得到的互补判断矩阵改造为模糊一致矩阵, 使其符合人类思维判断的一致性。本文建立的评论可信度排序模型选择了多项影响指标, 且指标之间的比较判断涉及人为的主观消费体验, 因此具有模糊性。为了较好地解决判断矩阵的一致性问题, 将模糊层次分析法引入可信度的排序模型, 使排序过程更加清晰。
张吉军[14]在模糊层次分析法的研究领域做出了突出贡献, 给出模糊一致矩阵的定义、性质、变换步骤等, 还对模糊一致矩阵排序的三种方法进行比较, 阐释了基于模糊一致矩阵判断矩阵元素与权重关系式的排序方法的科学性和可行性, 以及方根法、按行求和归一化法存在的不足[15]。李志宇[10]综合考虑特征选取要素, 通过对评论数据的信息挖掘与处理, 采用模糊层次分析法确定指标的相对权重, 计算评论的效用总分, 实现评论效用的排序。
李志宇[10]基于模糊层次分析法对网络客户评论进行重新排序, 为本文提供了研究思路。但对指标的处理、“ 有用性投票” 的分析及模糊层次分析法的应用方面, 存在一定的改进空间。因此, 本文基于李志宇的效用排序模型, 综合分析评论客观信息和语义特性, 改进指标预调整与数量化计算方法, 完善模糊层次分析法的具体应用, 给出中文评论可信度的排序方法, 并结合实际探讨“ 有用性投票” 的缺失对可信度排序结果的影响, 这也是当前领域较少涉及的研究内容。
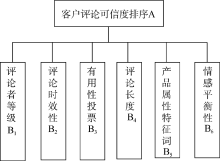
综合分析相关文献, 发现目前对于评论可信度影响指标的研究主要从评论者、评论时间、评论有用性以及评论内容4方面考虑, 确定影响评论可信度的6项指标: 评论者等级、评论时效性、“ 有用性投票” 、评论长度、产品属性特征词和情感平衡性。
(1) 评论者等级体现了消费者在电子商务平台上购物的经验丰富程度, 等级越高, 表明其在网络客户评论领域的行为越积极, 对产品或服务的体验更可信, 从而使阅读者的感知信任度更高[9]。
(2) 评论的时效性指评论信息发布时间和消费者阅读评论时间的差值, 差值越小, 说明评论越新, 时效性越强。因此在研究评论可信度时, 需考虑时间的渐变因素, 认为近期发表的评论参考价值更高[16]。
(3) “ 有用性投票” 反映了多数阅读者对于评论的认同度, 能够帮助当前阅读者判断评论的真实性。评论获得“ 有用性投票” 越多, 说明其他阅读者对该评论的认同度越高, 评论可信度越高[9]。然而, 在网络客户评论中, 由于没有特定的激励动因促使阅读者自发投票, 存在部分评论无“ 有用性投票” , 但无法据此断定这些评论的可信度低。“ 有用性投票” 是影响可信度的指标之一, 却不能作为衡量评论价值的唯一指标。
(4) 评论长度反映了评论发布者对产品的详细了解程度、内心深处对该产品的褒奖或批判态度以及希望其他潜在消费者获得哪些真实信息。在一定阈值范围内, 评论长度对于评论可信度影响是积极的, 评论字数越多, 其可信度越高[17]。
(5) 产品属性特征词用来客观性地描述产品质量、功能等固有特性, 评论内容里包含的产品属性特征词越多, 说明该评论越可靠, 对潜在消费者的辅助决策作用越大[8, 9, 10]。
(6) 情感特征词体现了评论者对产品的真实感受和情感倾向, 蕴涵积极或消极的态度。评论内容的正负情感混杂度对评论可信度存在正向影响, 情感极性越平衡, 评论的可信度越高[8, 9, 10]。
本文使用网页信息提取工具MetaSeeker[18]进行规则定义及信息提取, 获得各项指标信息, 进行预调整并优化处理。
(1) 评论者等级分组
亚马逊网站上的“ 最佳评论者排名” 综合考虑每位评论者发表评论的整体质量及评论数量, 体现其在该网站的等级。若评论者的排名进入前1 000名, 就会获得一个优秀评论者的标识。亚马逊网站给出相应的标识: 千佳评论者、五百佳评论者、百佳评论者、五十佳评论者。例如, 某评论者的排名是498, 则会得到一个“ 五百佳评论者” 的标识。在数以万计的评论者中, 能位列千名之内的评论者必定有着丰富的网购经验和可信的商品评论, 因此给予该部分评论者较高的等级。
对于位列1 000名之后的评论者, 本文引入统计分组的概念, 对评论者排名进行分组处理, 按组别划分。分组的关键是选择分组标志和划定各组界限, 将总体数据按一定的差异范围进行区分。具体步骤为:
①统计排名在1 000之后的数据, 作为分组对象;
②按照Sturges[19]提出的经验公式确定组数K, 其中n为总体数据的个数:
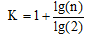 |
③根据总体数据的最大值Max、最小值Min以及组数K(由排在1 000名之后的评论数据确定)确定组距G:
 |
④划定各组上下限, 将实际数据对应到相应组中。
应用该法将评论者排名转化为评论者等级, 排名越靠前, 等级越高, 如表1所示:
| 表1 评论者等级分组对照表 |
(2) 评论发布时间转化
由于当前阅读时间的多变性, 本文采用当前评论发布时间与最早评论发布时间的差值作为衡量可信度的时效性指标。实际应用中, 先找出所有评论中发布时间最早的评论R, 记它的发布时间为Earliest, 接着计算每条评论发布时间Date与最早发布时间Earliest的差值, 记为TimeSpan, 应用上述分组法将天数差值TimeSpan转化为时效性, 间隔天数越多, 说明评论距离当前阅读时间越近, 则其时效性越强。
(3) “ 有用性投票” 处理
本文对有用性投票的处理, 借鉴了国外相关研究中的方法。Zhang[20]选取总投票数超过10的评论作为样本, 通过比值法处理有用性投票数与总投票数之间的关系, 以此衡量评论有用性。结合研究实际, 为了保证算法的健壮性, 将无有用性投票或总投票数低于5的评论的该指标值设为0, 分配给获得较多投票数的评论更高权重, 有用性指标值的计算公式为[16]:
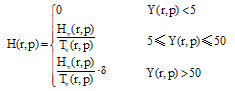 |
其中, r是产品p的评论, Hv(r , p)是针对评论(r, p)有用投票数, Tv(r, p)是总投票数, δ (δ > 1)是赋给投票数超过50的评论的增加权重。从采集的样本来看, “ 有用性投票” 数超过50的评论较少, 为了不使该权重对排序结果造成较大影响并保证指标权重的合理性, 本文适当取δ =1.5。
(4) 评论内容挖掘
采用NLPIR汉语分词系统[21], 通过中文分词、词性标注、关键词统计等功能对客户评论信息进行挖掘。
①产品属性词库构建
选取中关村在线论坛作为词库构建的基础, 因为它是一个影响力较高的IT资讯平台, 能够提供丰富、专业、精确的产品属性信息。产品属性特征词提取包括两个部分: 产品本身固有特征, 从详细参数中提取; 客户评论特征, 由客户评论内容中提取。两者结合提取的产品属性特征词更有代表性, 据此构建的产品属性词库才更完备。
产品属性词库构建过程:
1) 从亚马逊网站中提取待研究产品的具体型号、品牌等基本信息, 作为关键词在中关村在线平台上进行检索, 找到同样的产品, 查看其详细参数及客户评论;
2) 提取产品的详细参数信息, 用NLPIR进行分词、词性标注, 保留所有名词、名词性短语和动词, 作为产品固有特征词集合, 定义为F1;
3) 提取所有评论内容, 导入分词系统, 在分词和词性标注的基础上, 系统自动统计词频并按照词频降序排序, 词频较高的词作为候选词, 得到客户评论中的产品特征词集合F2;
4) 合并两个集合得到产品属性特征词集合F = F1∪ F2, 删除与产品不相关或重复出现的词, 构造出产品属性词库。
②产品属性特征词匹配
将评论内容导入分词系统, 进行自动分词处理。对于每条评论, 将分词结果逐词与产品属性词库中的特征词进行匹配, 若匹配成功, 则该评论的产品属性特征词个数增加1。统计匹配成功的词汇总数, 作为评论的产品属性特征词指标值。
③情感词典构建及特征词匹配
以知网(HowNet)发布的“ 中文情感分析用词语集” 为基础构造情感词典, 包含正面词语4 566个、负面词语4 370个。将分词后的评论逐词与正负情感词库进行匹配, 统计匹配成功的正面情感词数和负面情感词数, 二者的比值作为衡量评论正负情感平衡性的指标, 如公式(4)所示:
 |
其中, Balance为评论的正负情感平衡性, P_count为正面情感词数, N_count为负面情感词数, 若N_count = 0, 则令N_count = N_count+1。实际应用中, 若Balance > 1, 则采用Balance的倒数(1/Balance)表示情感平衡性。Balance的值越接近1, 说明评论内容的正负情感越平衡。
(5) 评论长度
评论长度对可信度的正向影响是在一定阈值内的, 有些评论字数虽多, 但其中含有大量的噪声或与产品无关的信息, 从而干扰对可信度的判断。因此从评论长度角度分析, 衡量可信度应重点考虑评论的有效长度, 即内容中真正有用的信息量, 这和能反映内容真实性的属性词与情感词有一定关联。因此本文通过评论中包含的属性词和情感词总数与评论总长度的比值来测度有效长度, 同时为了减弱某些评论因总长度过大而对实验结果造成的偏差, 运用对数方法弱化分母的取值差异, 计算公式如下:
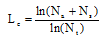 |
其中, Le是评论的有效长度, Na是属性特征词个数, Ns是情感特征词个数, Nt是评论总长度。
(1) 建立层次结构
评论可信度排序作为总体目标, 评论者等级、有用性投票、评论时效性、评论长度、属性特征词、情感平衡性6项评论属性作为评价指标, 构建层次结构, 如图1所示:
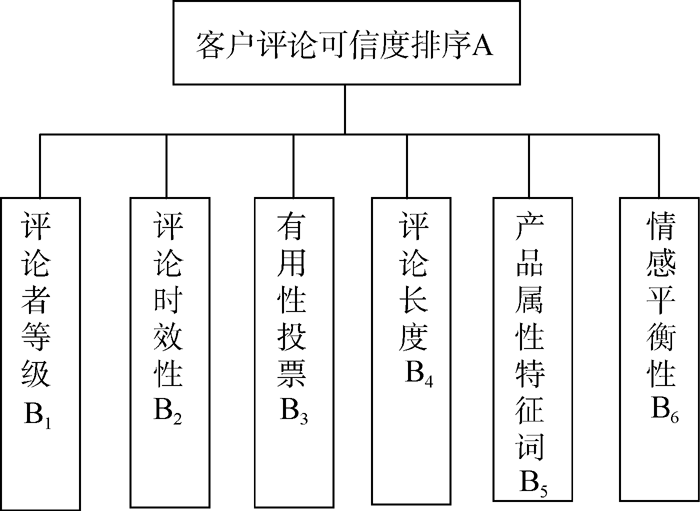 | 图1 评论可信度排序层次结构 |
(2) 确定指标权重
通过问卷调查法, 被调查者依据自身网购经验对指标进行两两比较打分, 以矩阵形式表达各指标相对于评论可信度的重要性。采用0、0.5、1标度法确定因素值, 该方法简单易行, 且极大简化了矩阵计算。具体如下。

将优先关系矩阵改造为模糊一致矩阵[14]:
①对优先关系矩阵(模糊互补判断矩阵)分别按行、按列求和, 即:


②再按公式(8)进行数学变换:
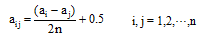
改造后的矩阵则为模糊一致矩阵, 再进行检验保证其一致性。研究结果表明, 与传统的方根法和按行求和归一化法相比, 模糊判断矩阵元素与权重的关系式排序法有着明显的优势: 计算复杂度低, 且计算结果分辨率高, 采用该方法计算各指标权重, 有利于提高决策的科学性[15]。根据模糊一致矩阵计算各指标ai对评论可信度的重要性权值wi, 计算公式如下:

为提高排序结果的分辨率, α 取值为α =(n-1)/2。至此, 影响评论可信度的各指标权重W=(w1, w2, …, w6)得以确定。
(3) 可信度排序
预调整和优化后的指标值存在量纲和数量级的差异, 通过无量纲化处理, 各指标值为S = (s1, s2, …, s6)。计算评论可信度的总分, 实现评论按可信度高低排序。
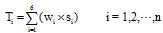
选取亚马逊网站上“ HUAWEI华为Ascend P6联通3G手机WCDMA/GSM(阿尔卑斯白)” 作为实证分析的对象, 截至2014年5月9日上午8:50, 提取该商品全部评论共计1 446条。以Visual Studio为程序开发平台, 用C#编程语言实现指标的提取和预调整。
对评论的“ 最佳评论者排名” 进行分组, 转化为“ 评论者等级” , 如表2所示:
| 表2 评论者排名分组实例 |
评论发布时间的分组方法同上。“ 有用性投票” 按照公式(3)进行处理, 情感正负平衡性、评论有效长度分别运用公式(4)、公式(5) 进行计算, 产品属性特征词的匹配统计参见上文相关论述。
据CNNIC 发布的2013年中国互联网络发展状况统计报告[22]显示, 学生依然是中国网民中最大的群体, 考虑到在校大学生网购经验丰富, 且在购物前会对评论信息进行反复对比分析, 对评论可信度有一定的判断。因此, 本文针对该人群开展网络问卷调查, 进行指标两两比较打分。共发放网络问卷250份, 回收230份, 基于网络问卷的设置属性, 230份问卷全部有效。
依据打分结果构造6项指标的优先关系矩阵如表3所示:
| 表3 评论可信度影响指标的优先关系矩阵 |
运用公式(6)至公式(8)将优先关系矩阵改造为模糊一致矩阵, 如表4所示:
| 表4 评论可信度影响指标的模糊一致矩阵 |
依据公式(9), 计算各指标权重为W = (0.163, 0.172, 0.195, 0.142, 0.178, 0.15)。根据公式(10), 将每条评论的6项指标数值分别与对应权重进行加权计算, 得出评论的可信度总分。例如, 本文采集到样本的第一条评论各项指标经过无量纲处理后的数值为S = (1.87, 0.45, 1.45, 1.04, 2.13, 0.72), 则可信度总分为:
0.163× 1.87+0.172× 0.45+0.195× 1.45+0.142× 1.04+0.178× 2.13+0.15× 0.72≈ 1.3
同理, 计算出所有样本评论的可信度总分, 按照总分高低实现评论排序。本文重点关注了无“ 有用性投票” 的评论处理, 因此给出另一种无“ 有用性投票” 指标的排序结果, 两者对比, 分析有用性投票对评论可信度的作用。计算得到5项指标权重分别为W’ = (0.202, 0.211, 0.176, 0.226, 0.186), 样本中第一条评论按照五项指标排序的可信度总分为:
0.202× 1.87+0.211× 0.45+0.176× 1.04+0.226× 2.13+0.186× 0.72≈ 1.26
(1) 与网站原始排序对比
亚马逊网站上给出的评论排序集是“ 按照最有用的评论排序” , 重点关注每条评论的有用性投票数及总投票数, 而本文的研究侧重于按照评论的可信度排序。限于篇幅, 选取亚马逊网站排序的前三条评论与可信度模型排序的前三条评论的各项指标进行对比, 分别如表5和表6所示:
| 表5 亚马逊原始排序前三条评论各指标值 |
| 表6 可信度模型排序前三条评论各指标值 |
总体来看, 除了“ 有用性投票” 外, 可信度模型排序前三条评论的其他5项指标值大部分都比原始排序前三条评论的指标值高或者与之相当。
具体对比两表中的第一行, 即原始排序第一的评论和可信度模型排序第一的评论, 可以发现, 前者虽然评论者等级与有用性投票两项指标值高, 但相比于后者, 其他4项指标值均较低, 尤其是产品属性特征词和情感平衡性两项指标值相差较大, 应用到本文的排序模型中, 可信度总分低, 排名下降。证实了原始“ 按最有用的评论排序” 方法的不足, 反映出“ 有用性投票” 对评论可信度重要但不是唯一因素。而本模型中排名第一的评论由于各项指标值都较为可观, 因此可信度总分高, 排名靠前。
对于没有“ 有用性投票” 的评论而言, 由于缺失该项指标的实际原因不明, 单纯将指标值设为0存在一定不合理性, 无法根据这一点说明评论可信度低。表7给出了网站原始排在第1 043位评论的各项指标值, 由于该评论无“ 有用性投票” , 在原始排序集中被置后, 在六指标排序模型中位列第40, 而在忽略有用性权重的五指标模型中排名为34, 由此可知, 无“ 有用性投票” 的评论未必不可信。
| 表7 原始排序第1 043位的评论各指标值 |
(2) 与其他可信度排序方法对比
本文在文献[10]的基础上进行改进和扩展, 为了进一步对比两种排序的差异, 设计如下实验: 采用文献[10]的指标处理方法及相对权重, 对本文获取的1 446条评论进行重新排序。限于篇幅, 仅选取排序结果中的前三条评论和后两条评论进行对比, 如表8所示:
| 表8 效用模型排序的评论各指标值 |
表8中, 评论者等级、有用性投票数和评论长度均是根据网站抓取结果直接获取的已量化数据; 评论时效性将当前评论发布时间转化为距离最早评论发布时间的差值; 产品属性特征词和情感特征词的数目分别从评论内容与词库的匹配过程中获得。
对比分析可知, 该模型的效用总分差距悬殊, 究其原因, 主要在于各指标的量化处理方法存在不足, 且建模过程中对无“ 有用性投票” 的评论处理欠妥。本文模型与之相比, 弥补了这些缺陷, 使可信度总分更具合理性, 因此在一定程度上优于文献[10]的效用模型。
本文基于模糊层次分析法研究中文网络客户评论可信度, 通过归纳构建可信度指标体系, 并对指标进行预调整及数学优化, 运用模糊一致矩阵的改造和排序方法, 实现依据可信度的评论排序。实证分析中, 对比原始排序集与可信度排序集, 证实了该排序模型的可行性和科学性; 针对无“ 有用性投票” 的评论, 给出另一种相对客观的排序模型, 验证了“ 有用性投票” 是重要但非唯一的影响指标; 对比可信度排序集与文献[10]效用排序集, 说明了本文排序模型在一定程度上具有优势。
通过对在校大学生的观点调查给出评论可信度影响指标的相对评分, 由于他们的网购经验存在差异, 无法忽略个人主观因素的影响。因此, 在未来的研究工作中将加强指标权重打分方面的专业性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|