
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
甲骨文大规模基础数据的语义挖掘研究
[熊晶 , 高峰, 吴琴霞]
, 高峰, 吴琴霞]
, 高峰, 吴琴霞]
|
|


作者贡献声明:
熊晶: 提出研究思路, 设计研究方案;
熊晶, 高峰: 进行实验;
吴琴霞: 采集、清洗和分析数据, 甲骨文语料标注;
熊晶, 高峰, 吴琴霞: 论文起草;
熊晶: 论文最终版本修订。
【目的】从大规模的甲骨文基础数据中发现实体间的语义关联, 为甲骨文研究提供语义支持。【方法】在文本挖掘的基础上, 结合语义Web技术, 将实体及其关系RDF化并在生成的RDF集合中进行语义搜索, 利用本体关系和本体推理挖掘RDF对象间显式或隐式的语义关系。【结果】该方法在甲骨文文献和甲骨卜辞上的语义挖掘平均F1值分别达到74.49%和70.61%, 满足甲骨文信息处理的需求。【局限】 利用本体实现语义挖掘时分别基于本体库中的三个不同本体, 未将本体进行集成。【结论】实体RDF化可以提供规范的结构化语义描述; LarKC体系适用于甲骨文大规模语义处理。
[Objective] Find the semantic relations among large-scale Oracle Bone Inscription (OBI) data in order to provide semantic analysis function for OBI research.[Methods] Based on text mining, combined with the semantic Web technology, implement semantic search on the data set of RDF-based entities and their relationships. And using Ontology relationships and Ontology reasoning to extract explicit or implicit semantic relationships among RDF objects.[Results] Experimental results show that the F-Measure can reach 74.49% on OBI literature semantic mining and 70.61% on OBI semantic mining, which satisfy the need of OBI information processing.[Limitations] Semantic mining is based on three different Ontologies instead of an integrated one.[Conclusions] RDF can provide a structured semantic specification description and the LarKC system is suitable for large-scale OBI semantic processing.
甲骨文距今已有3 500多年的历史, 记载了商代王室的占卜记录, 其中涉及王事、农业、天象、吉凶、祭祀、征伐、使令、往来、婚娶等广泛的社会活动, 有着非常丰富的历史内容, 因此具有重要史料价值。甲骨文的深入研究, 对语言文字学、历史学、考古学、社会人类学、古代科学技术史等学科有着深刻的影响[1]。甲骨文研究已形成一门具有严密规律、有丰富研究资料和多方面研究课题的学科— — 甲骨学。然而, 从事甲骨文研究的难度很大, 目前, 甲骨文字只有少数人能够辨识和翻译, 我国的甲骨文专家很少, 培养一名甲骨文专家需要一二十年甚至更长的时间[1]。计算机技术的发展为改善传统的甲骨文研究手段提供了有效途径, 因此计算甲骨学应运而生。随着大量甲骨文研究资料的数字化整理以及学术论文的发表, 甲骨文基础数据的规模越来越大, 逐渐体现出海量的、异构的分布式特征。单纯考虑字形特征已无法满足甲骨文理解、考释的研究需求, 必须充分考虑甲骨文语义信息。在此环境下的甲骨文语义信息挖掘是一项极具研究意义的课题。
甲骨文研究面临的首要问题是如何识别和理解甲骨文字, 因此甲骨文的考释和释读是两个重要的研究内容。计算机技术的发展使得甲骨文数字化整理成为可能, 但是, 由于甲骨文记录载体老化以及在考古发掘过程中的损坏等因素, 大量的文字出现模糊和残缺现象。所以单纯从甲骨文的字形上去考释甲骨文难度极大, 结合上下文语义环境来辅助甲骨文考释是一种有效手段。另外, 在甲骨文释读和理解过程中, 也需要充分考虑语义信息。
甲骨文研究积累的数据已体现出海量的、多样化、异构的分布式特征。自1899年甲骨文被发现以来, 大量的研究资料都逐渐进行了数字化整理, 包括甲骨文考古数据、图像、视频、动画、论文著作的电子版、网络数据等。目前发现的甲骨片有15万片左右, 这些甲骨片少则一两个字, 多则几十字, 针对这些甲骨片的数字资源包括照片资料、拓片图像、临摹图像等。增长较快的甲骨文数据包括甲骨文数字书法、甲骨文文献资料数字化整理、甲骨文网络评论信息(如“ 最萌甲骨文” )、古文字应用(如2014年湖北省高考语文卷甲骨文考题)等。甲骨文数据的类型分为结构化数据、半结构化数据和非结构化数据三类, 包括文本、图像、视频、动画、甲骨文条形码等多种存储格式。另外, 基于动态描述库的甲骨文字形自动生成[2]、甲骨碎片缀合[3]、甲骨文可视化输入法[4]等也为甲骨文研究贡献了大量形式多样的异构的数据。
然而, 甲骨文基础数据的价值密度较低, 目前发现的甲骨文单字约4 500个, 其中可以识别的约2 500个, 并且大量的甲骨片图像很不清晰甚至没有甲骨字的信息, 单从字形匹配的角度很难考释出未释字。这就需要从语义角度出发, 通过数据挖掘的手段, 并借助语义推理辅助进行甲骨文字的考释。
语义挖掘是一种从非结构化数据中准确地提取有用信息和知识的新兴数据挖掘技术, 其利用基于语义的智能计算, 实现对海量非结构化信息的整理, 并从中挖掘有价值的信息[5]。杨洁[6]认为将语义Web应用到Web挖掘中, 可以加强挖掘效果; 将Web挖掘结果追加到语义Web中可使语义Web更趋完善。张辉等[7]将Agent技术和语义Web相结合设计了一种基于本体的可实现语义挖掘的多Agent系统, 用以提高Web服务的智能性。蔡皎洁等[8]基于企业本体, 从客户数据中挖掘出客户所感兴趣的产品或服务的概念和概念间关系, 实现客户兴趣的语义挖掘。Vavpetič 等[9]实现了一个语义挖掘系统g-SEGS, 并定义语义挖掘是一个通过给定的领域本体和用本体术语标注的数据集而获得一个预测模型或描述模式的过程。Jiang等[10]在文本挖掘过程中融入本体技术, 通过“ 概念-概念” 相关矩阵识别概念间的关系, 最终实现文本语义挖掘。Huang等[11]研究了临床及生物医学数据上的语义挖掘, 并将文本语义挖掘过程概括为符号化、词法分析、句法分析和基于本体的语义处理4个步骤。可以看出, 大多数语义挖掘研究是利用本体的语义优势补充和完善数据挖掘技术, 但相关研究较少关注语义挖掘的海量数据背景。
关联数据[12]的提出和应用, 推动了语义挖掘技术的发展。随着关联数据的爆炸式增长, 在海量数据集上的语义挖掘技术面临着挖掘效率的挑战。Jiang等[13]针对关联数据提出了等效压缩和依赖压缩两种图压缩策略, 并且验证了这两种策略在提高语义挖掘效率方面的有效性。从语义挖掘对象的角度来看, 针对甲骨文数据的研究还非常少, 但是, 现有的相关成果可为本文的研究提供借鉴。如吴琴霞等[14]研究了基于本体的甲骨文专业文档语义标注方法, 可作为本文的前期基础, 其他领域的已有研究成果对本文也有着重要的参考意义。
为了给甲骨文基础数据提供语义信息, 需要采取一种机器可读的表达形式。本文利用本体为甲骨文数据提供语义表达及推理功能。根据甲骨文数据涉及的不同领域, 分别建立甲骨文常识本体、甲骨文内容本体和甲骨文文献本体三个本体库。本体来源自权威的甲骨文专著、学术论文、甲骨卜辞①(① 占卜的内容刻在甲骨上就成为“ 卜辞” 。商代人遇事即占卜, 大到祭祀、征伐; 小到起居、杂事。)拓片、甲骨文图文资料库、甲骨文数据库等, 在构建过程中由专家进行指导和确认。
(1) 甲骨文常识本体描述的是甲骨文基础知识, 包括甲骨文发现历史、考古记录、文字特征、语法知识等。其核心部分是一个构建在知网(HowNet)[15]体系上的“ 甲骨文知网” , 即以甲骨文词语所代表的概念为描述对象, 以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。
(2) 甲骨文内容本体是描述经甲骨文专家及历史学家考释出来的, 反映商代社会人们的家庭关系、生活、农作、天气、战争、狩猎等事件及其相互关系的知识库。
(3) 甲骨文文献本体是依据甲骨文研究论文及专著建立的资源本体。
笔者在前期研究成果中叙述了基于“ 双向活动铰接法” 构建的甲骨文内容本体[16], 韩姣红[17]研究了甲骨文文献本体的构建及应用。本文着重描述甲骨文常识本体。
甲骨文专家研究发现: 甲骨文的句子结构和现代汉语之间的差别不大, 构成甲骨文语法相关的造字法、用字法、词的分类和句型等, 同现代汉语有许多相同之处。商代人对事物的认识也与现代大同小异: 甲骨文所载卜辞大体可分为名物类(包括地理、天象、建筑、时间、方位、物品、人、鬼神、动植物、组织、称谓等)、行为动作类(包括生产、生活、军事行动、占卜、祭祀等)、性质状态类、数量类等。董振东等[15]构造的HowNet规定了现代汉语最基本的运算单元, 即万物(包括物质和精神)、部件、属性、属性值、事件、时间和空间等; 冯志伟[18]构造的知识本体ONTOL-MT中初始概念有事物、时间、空间、数量、行为状态和属性等。可见甲骨文与现代汉语在概念的分类体系上是相容的, 本体作为语义分析的基础, 描述的是词汇背后的客观世界的本质概念及其关系, 因此可在HowNet基础上抽象出甲骨文的概念知识, 建立甲骨文常识本体。
HowNet用义原和角色关系描述概念。义原在HowNet中是重要的概念之一, 它是从所有汉语词语中提炼出的可用来描述其他词语的不可再分的基本元素。HowNet中的义原分类树把各个义原及它们之间的联系以树的形式组织在一起为语义计算提供了方便。本文借鉴HowNet的构建体系, 建立了一个融合甲骨文和现代汉语的语义知识库。构建步骤如下:
(1) 选取科学发掘的甲骨文语料为研究对象, 整理甲骨文的已释字和未释字信息, 并进行统一的编码, 给出每个甲骨字的唯一ID。
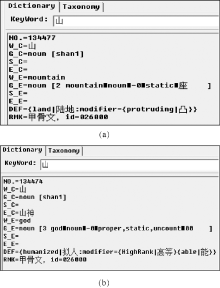
(2) 建立甲骨文的基本语义知识词典。词典样式遵照HowNet的描述体系, 完成语料中涉及的甲骨字所对应的DEF和RMK记录。图1以已释甲骨字“ 山” 为例显示了“ 甲骨文知网” 的构建。
 | 图1 已释甲骨字“  ” (山)的两个义项操作 ” (山)的两个义项操作 |
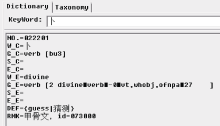
(3) 建立隶定字与HowNet的映射表。在每个隶定字与HowNet中意思相同的记录之间建立一个映射关系, 并且把这个隶定字的ID记录到HowNet的“ RMK” 项中, 如图2所示:
 | 图2 隶定字“ 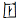 ” (隶定为“ ” (隶定为“  ” (卜))的操作 ” (卜))的操作 |
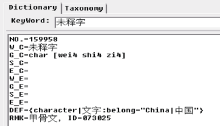
(4) 未释字在甲骨文知网中的表示。目前还有大量的甲骨字尚未考释出来或者未得到专家的一致认可, 这些字的语义尚不确定, 因此, 采用统一的表示方法, 仅以ID区分不同的未释字, 如图3所示:
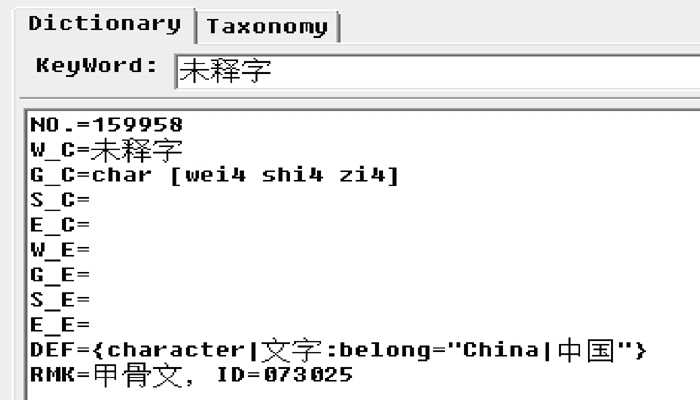 | 图3 未释甲骨字“  ” 的操作 ” 的操作 |
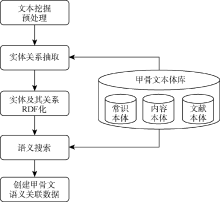
甲骨文数据语义挖掘是指: 在文本挖掘的基础上, 从不同的甲骨文数据集中抽取出实体及实体之间的语义关系, 包括时间、空间、事件、人物关系、从属关系、上下位关系、整体与部分关系等, 利用资源描述框架 (Resource Description Framework, RDF)三元组[19]的形式< 主语 谓词 客体> 进行表示的过程。将自然语言形式描述的文本抽象成具有语义的RDF三元组形式化表示过程称为实体及其关系的RDF化。选择甲骨文本体作为语义关联描述框架, 在大规模的RDF集合中通过语义搜索发现实体间显式的或隐式的语义关系并建立联系, 最终获得语义关联数据。甲骨文语义挖掘流程如图4所示:
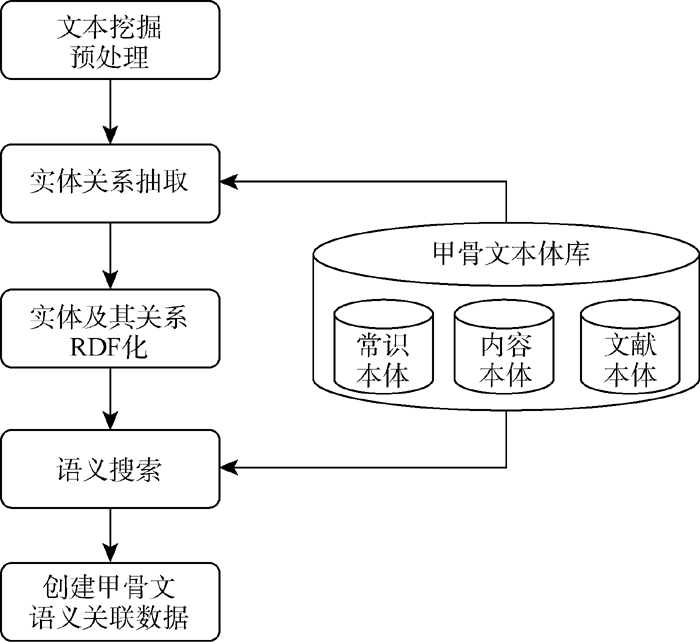 | 图4 甲骨文语义挖掘流程 |
图4描述的过程中, 文本挖掘预处理包括文本分类和数据清洗, 其中文本分类采用文献[20]的方法实现。实体关系抽取通过文本挖掘方法辅以本体来实现, 由于本体描述了概念或实例间的关系, 如果实体能映射到本体实例, 则将本体关系作为实体关系, 这一阶段暂不考虑基于本体推理发现实体间的隐含关系。实体及其关系的RDF化是挖掘过程的关键技术, 其目的是让实体及其关系具有规范的结构化的语义描述, 从而方便机器理解。语义搜索阶段的任务是获取RDF三元组间的语义关联, 包括甲骨文记载的人物关系、地理位置关系、祭祀关系、时空关系、事件关系等, 这些关系可通过RDF的SPARQL[21]查询实现。本体推理有助于语义关系的发现, 包括基于本体关系的推理和基于规则的推理。本体关系是显式定义的概念或实例之间的关系, 这些关系描述了实体间的语义关联。在本体中没有显式定义的关系将通过推理得到, 如: (?x subclass of ?y) (?y subclass of ?z) → (?x subclass of ?z) 即是通过关系的传递性获取的新关系; 超出本体描述范围的关系则需要借助推理规则完成, 因此需要建立甲骨文语法规则库。
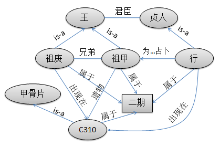
现以甲骨文研究中的分期断代为例说明语义挖掘过程。分期断代①(① 研究哪一片甲骨属于殷商时期哪一世哪一王时的遗物, 便于进行商史研究, 更清楚地了解商代社会。
)是甲骨学上的专题, 涉及到贞人②(② 商代占卜, 有一些专门从事占卜问神的人, 叫“ 贞人” , 是当时的高级知识分子, 深得商王信任, 因为他们是传达神的意旨之人。
)、世系、称谓、人物、事类、辞例、字形、书体等多个方面。例如: 编号C310的甲骨片上有一句卜辞释文③(③ 针对甲骨片上的甲骨原文, 考证出对应的现代汉字, 并对缺失部分进行补充, 对目前尚未考证出来的仍然以甲骨文原文表示。释文已经添加了句读符号。因此, 释文不同于甲骨文的白话翻译。)为“ □□卜, 行, [贞]: [王]宾兄庚, [亡]尤?” , 该句经甲骨文专家翻译为“ 某日占卜, 贞人行问卦, 时王宾祭他的哥哥名庚的, 没有什么不顺利的吧?” 根据甲骨文知识, “ 行” 是二期贞人, 因此该片是二期甲骨文。又知道二期有两位王: 祖庚和祖甲, 王位的继承规则是“ 父死子继” 、“ 兄终弟及” 。而祖庚是祖甲的哥哥, 则甲骨片上的兄庚必然是祖甲对祖庚的称呼, 因此, 进一步可以推断该甲骨片是祖甲时期的遗物。
将上述推断涉及的实体RDF化, 并通过其间的语义关联, 可以得到最终的语义关联数据如图5所示:
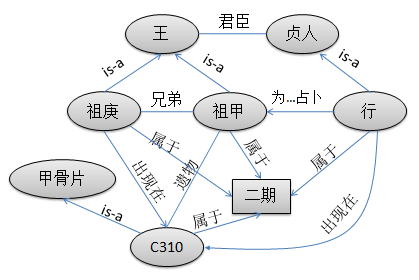 | 图5 语义关联示例 |
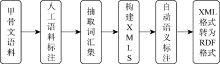
本文采用RDF三元组作为统一的语义结构单元。实体及其关系的RDF化主要有两种手段: 人工标注和自动标注。其中, 前者需要甲骨文专家的参与, 主要标注识别和理解难度较大的语义信息。甲骨文数据的自动标注包括两个方法: 基于XML Schema的RDF转换和基于关系数据库的RDF自动转换, 但自动标注后也需要辅以人工校对。
利用XML Schema模板将甲骨文语料自动标注为XML文档, 再将其转换为RDF格式。转换流程如图6所示:
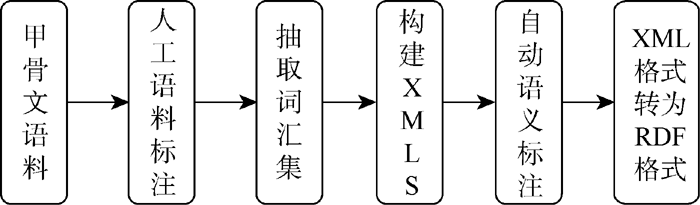 | 图6 基于XML Schema的RDF数据转换 |
基于笔者已整理的甲骨文语料库, 在甲骨文领域专家的帮助下, 对甲骨文语料库进行语料标注, 标注时需要抽取出有助于甲骨文考释的关键信息, 这些信息可以作为XML文档的词汇集, 词汇集间的关系通过建立XML Schema模型来明确标出各个词汇之间的关系。通过定义好甲骨信息对应的XML Schema, 就可以基于此使用XML对甲骨文信息进行结构化标注, 而且可以准确地描述数据的结构[22]。通过转换模块完成从XML到RDF数据的转换。
在甲骨文信息处理研究过程中, 建立了一些甲骨文数据库。包括甲骨文字形数据库、甲骨文刻辞基础词典、甲骨文语义词典等。通过抽取关系数据库中的ER关系, 利用关系映射规则, 能够将关系数据库中的实体记录转化成RDF三元组形式。转换流程如图7所示, 转换方法参见笔者的前期研究成果[23]。
 | 图7 基于ER模型的RDF数据转换 |
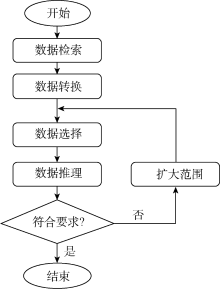
为解决语义网面临的海量语义数据处理问题, 欧盟第7研究框架开发了的LarKC平台[24, 25](Large Knowledge Collider), 其目标是开发大规模知识对撞机。基于LarKC的语义处理流程[24], 整理出甲骨文语义处理流程如图8所示:
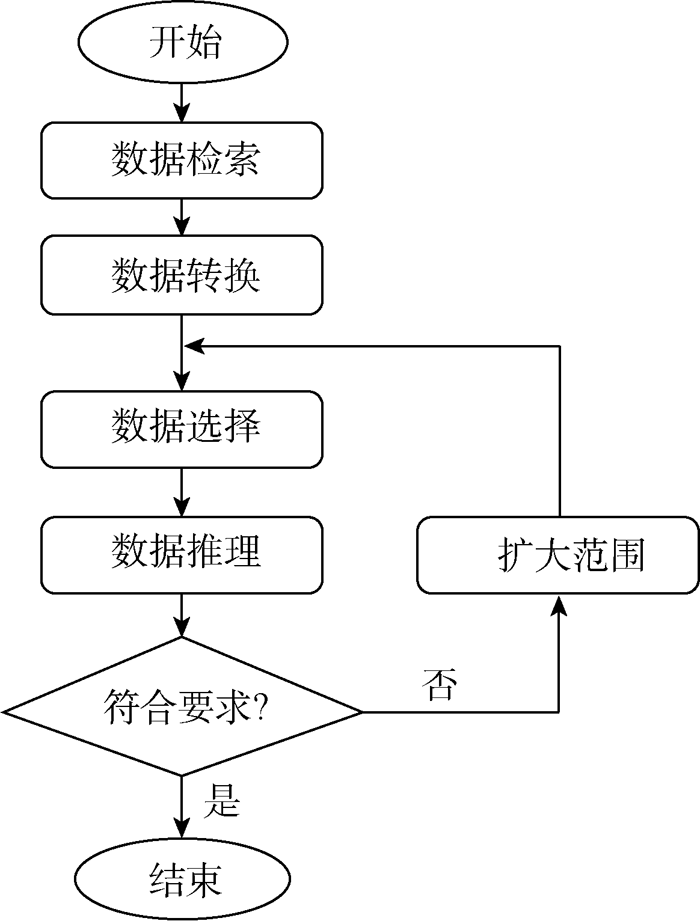 | 图8 甲骨文语义处理流程 |
图8所示的过程中, 首先通过检索技术从海量的甲骨文基础数据中定位或识别与需求相关的数据。这些数据可能是异构的, 即有的数据是符合指定规则的语义数据, 有的数据是非规范的数据。然后, 需要根据被定位的数据进行相应的转换, 使其变成统一的语义数据, 用RDF三元组描述。转换之后, 可能面临着大规模的语义数据, 因此, 还要根据处理的需要选择直接相关的部分语义数据, 并对这一部分的语义数据进行推理。根据推理结果进行判定或决策, 如果不符合要求, 则扩大被选择的数据, 再次进行推理, 直到结果符合要求。
实验样本由已经过文本分类后的500篇甲骨文学术论文的文献格式元数据(选取题目、关键词、摘要等元数据信息)和来自350片甲骨文拓片上的共790条表意较完整的甲骨卜辞释文数据组成。实验样本全部已经过语义关系标注, 关系分类有时间、空间、事件、人物关系、材料关系、从属关系、上下位关系、整体与部分关系、其他共9类。对上述两类实验样本分别采用前文所述的语义挖掘框架进行处理, 将得到的语义关系结果同已标注的关系进行比较, 以准确率、召回率和F1值为评价标准。文献元数据的语义挖掘对比实验结果如表1所示:
| 表1 文献元数据的语义挖掘对比实验结果 |
表1的结果显示, 大多数关系经挖掘后得到的数量超过标注数量, 主要原因是基于本体实现了潜在关系的发现。在9种关系中, 上下位关系的F1值最高, 主要原因是上下位关系是本体关系中最普遍、最易获取的关系之一; 时间和空间的F1值较高, 主要原因是这两种关系的特征词较为明显; 事件关系的F1值最低, 说明在语义挖掘中, 事件关系的挖掘是一个值得继续深入研究的方面; 大部分错误的关系均划归到其他关系中, 因此, 该类关系的挖掘数量最多。
影响语义挖掘准确率及召回率的一个重要因素是实体的识别正确率。如“ 唐兰是继孙诒让、罗振玉、王国维、郭沫若等人之后研究甲骨文成就较高的学者之一” 一句中人物“ 唐兰” 被错误地识别为“ 唐兰是” , “ 王国维” 被错误地识别为“ 王国” ; 在分析“ 甲骨文文例” 时, 得到错误的实体为“ 甲骨” , “ 文文” , 且“ 例” 被当作停用词过滤; 刊名《中原文物》被错误地识别为关系 < 文物 空间 中原> 。
另一方面, 语义挖掘得到的关系中, 有一部分关系经人为判定是正确的, 而该关系在人工标注阶段却并没有标出, 因此在计算召回率时拉低了分值。这暴露了人工标注的局限性, 因为在标注时无法全面关注所有文献元数据并建立它们之间显式或隐式的关联。甲骨卜辞的语义挖掘对比实验结果如表2所示:
| 表2 甲骨卜辞的语义挖掘对比实验结果 |
从表2可以看出, 甲骨卜辞的语义挖掘准确率较文献元数据普遍高。主要原因之一是甲骨文字绝大部分为单字词, 分词操作简单, 且甲骨字单义词占多数, 因此实体的识别率更高; 原因之二是语义挖掘基于甲骨文内容本体, 在建立内容本体时已经获取了大量的实例, 而这些实例大多数可以映射到提取的实体上。
9种关系中从属关系的召回率最低, 主要原因是大量的从属关系连接的是甲骨片与分期断代实体, 而这些关系是后世对甲骨文研究才有的, 并不反映在甲骨卜辞中; 人物关系和事件关系的F1值最高, 这与甲骨卜辞主要记录商王遇事占卜的事实是一致的。影响准确率和召回率的原因之一是甲骨卜辞中有为数不少的实体及关系是重复的, 由于出现在不同的甲骨片中, 因此在人工标注时未能做到完全去重; 原因之二是甲骨文考释结果的不一致导致了分类错误, 如卜辞“ 丙子卜, 韦, 贞: 我受年(翻译为: 丙子日占卜, 贞人韦问卦, 贞问: 我商王朝会得到好年成吗?)” 中, 有专家认为“ 我” 是方国名; 原因之三是分类的不确定性带来的影响, 如卜辞“ 丙戊卜, 大, 贞: 告执于河?燎…沉三牛? (翻译为: 丙戊日占卜, 贞人大问卦, 贞问: 向河神行祷告执俘胜利之祭, 以火烧…还是以沉水之祭用三条牛为献牲呢?)” 中, “ 牛” 被标注为“ 材料关系” 的实体, 但在语义挖掘中被归为“ 其他关系” 的实体。
从上述实验结果看, 本文方法用于甲骨文基础数据的语义挖掘是可行的, 挖掘结果满足甲骨文信息处理研究的需要。
本文描述了甲骨文数据特点, 研究了甲骨文语义挖掘和大规模语义处理流程, 并验证了基于本体的语义挖掘性能, 实验结果表明该方法是可行的。但也存在一些局限, 如语义挖掘过程是分别基于甲骨文常识本体、内容本体和文献本体三者, 而没有将三个本体整合在一起; 也没有对运行效率进行研究。下一步, 将研究本体集成问题, 将三个本体集中在一起进行研究, 并考虑大规模数据环境下的运行效率问题。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|