{kind=link}
{kind=link}
{kind=link}
一种基于Hadoop平台的并行朴素贝叶斯网络舆情快速分类算法
[马宾1, 2, 3  , 殷立峰
, 殷立峰1 ]
, 殷立峰|
|


作者贡献声明:
马宾: 确定研究方向及研究方法, 研究数据的获取与分析, 论文撰写;
殷立峰: 实验代码的编写, 提出论文的修改意见。
【目的】研究Hadoop平台下一种改进的并行朴素贝叶斯算法并实现网络舆情信息分类。【应用背景】网络舆情信息存在数据量大, 分散度高, 数据非结构化等特点, 现有技术难以实现网络舆情的准确、快速分类。【方法】利用Hadoop平台分布式数据存储与并行处理的优良特性, 实现朴素贝叶斯分类算法的并行化运行; 将采集的舆情文档依照HDFS架构进行本地化存储, 并通过MapReduce进程完成并行分类处理。【结果】对MapReduce封装后的并行朴素贝叶斯分类算法进行性能测试, 结果表明本算法分类效率比集中式舆情分类算法提升82%, 分类准确率达到85%以上。【结论】本算法能够有效提升网络舆情分类能力与分类效率。
[Objective] A new Network Public Opinion (NPO) classification method based on parallel Naive Bayesian Classification Algorithm (NBCA) in Hadoop environment is proposed.[Context] The NPO are high-volume, high-distribution and high-variety information assets, thus the accurate and fast classification is difficult to achieve.[Methods] According to the distributed storage and parallel processing features of Hadoop platform, the NBCA is parallel encapsulated and the NPO documents are locally stored under HDFS frame and parallel classified in MapReduce process.[Results] The performance of MapReduce packaged parallel NBCA is testified and the results show that the execution efficiency of proposed algorithm improves 82% compared to centralized method and its classification accuracy rate arrives more than 85%.[Conclusions] The proposed algorithm can effectively improve the NPO classification efficiency and ability.
网络舆情是指在互联网上形成的对社会现象不同观点的网络舆论[1]。随着社交媒体、智能终端等新技术的快速发展, 互联网每日产生的网络舆情数据正以几何形式增加, 因而, 对海量的舆情信息进行分类管理并及时发现敏感信息, 实现不同主题舆情信息的收集、分析、监测、预警成为迫切需求[2]。网络舆情因具有数据量大、信息分散度高、数据非结构化等特点, 传统的客户机/服务器(C/S)式集中数据处理方式以及基于关系型数据库的结构化数据分类方法难以实现网络舆情的有效分类[3]。以Hadoop为代表的云计算技术快速发展为大规模数据的分布式处理提供了可能, 成为近年来的研究热点[4]; 朴素贝叶斯分类算法作为一种简单、高效的统计分类算法, 广泛适用于非结构化数据的分类处理[5]。因此, 研究一种基于Hadoop平台的并行朴素贝叶斯分类算法实现的网络舆情快速分类处理, 提升网络舆情分类的响应速度和分类能力, 实现网络舆情在线分类、分析与监测, 对于引导网络舆情健康发展具有重要意义。
通过网络舆情来挖掘和理解别人的观点由Dave等[6]于2003年在WWW会议上发表的论文中提出, 理想的舆情观点挖掘工具应能够将主题搜索结果生成不同属性类别的集合, 整合出观点的情感倾向。2008年, Allan等[7]采用向量空间模型(VSM)表征新闻文本, 通过特征词和频率构成文本特征向量, 利用自然语言处理技术(NLP)实现话题监测任务。随着现代社会复杂程度的提高, 恐怖主义的威胁等因素, 西方国家对舆情监测的重视程度不断提高。美国舆情研究协会①(① http://www.aapor.org.)(American Association for Public Opinion Research), 欧盟舆情分析委员会②(② http://ec.europa.eu/public_opinion/index_en.htm.)(Public Opinion Analysis Sector of the European Commission), 加州大学伯克利分校社会科学研究中心③(③ http://socialwelfare.berkeley.edu/research.)(Center for Social Service Research of Berkeley)等机构纷纷开展了基于网页统计、文本分析等方式的舆情研究工作, 并推出了相关的舆情分析算法与系统。
国内在网络舆情检测与挖掘方面的研究开展得相对较晚, 由于中文语法结构与英文差别较大, 词语之间不像英文以明显的空格作为分隔符, 存在词汇提取困难、分词结构复杂等问题, 舆情监测难度大。中国科学院计算技术研究所研制的“ 天玑(Golaxy)互联网舆情监测系统” 拥有国际先进的汉语词法分析器(ICTCLAS), 能够对网络舆情进行快速获取、有效分析、持续跟踪和及时预警[8]。北大方正技术研究院结合内容管理、知识管理与互联网监测技术, 提出了“ 方正智思互联网信息监控分析系统” , 主要针对离线的网页数据进行舆情自动分析、预报与前景分析信息[9]。深圳乐思软件开发的“ 乐思网络舆情监测系统” 可以实现对任意网页内任意数据的精确采集, 对于转载文章可以选择自动去重, 并能够基于用户的关键词设置对检索内容进行自动分类和聚类处理[10]。
现有的舆情分类技术也存在局限, 具体表现在:
(1) 由于集中式舆情信息处理能力的限制, 舆情监测主要针对离线数据进行, 未考虑舆情分析的时效性, 在海量的互联网非结构化数据面前, 现有的监测技术不能快速适应网络舆情变化;
(2) 由于结构化数据库自身特征的限制, 舆情数据分析多限于基本的频率统计和关键词匹配的方法, 信息挖掘深度不够, 抽取不全面, 分析误差大;
(3) 舆情信息检索主要针对已知主题的被动数据采集与分析, 缺少适应互联网信息流动特性的潜在舆情的主动挖掘技术, 舆情的漏报和误报几率较高。
近年来, 以适应网络数据快速增长为代表的大数据处理技术迅速发展, 通过大数据的并行处理与分布式存储技术, 大大增加了系统信息处理能力[11]。Apache提出的云计算生态系统架构Hadoop, 包括文件系统(HDFS), 数据库(HBase Cassandra)与数据处理(MapReduce)等功能, 能够线性地提高数据并行计算的能力[12]。朴素贝叶斯分类算法作为一种基于统计学规律的分类方法, 适用于非结构化数据分类与数据挖掘[13]。本文将Hadoop平台的分布式存储与并行处理能力和朴素贝叶斯分类算法相结合, 利用朴素贝叶斯算法对复杂数据的分类能力与Hadoop平台的并行处理特性, 提升网络舆情分类的执行速度和分类性能, 具有较高的研究价值。
朴素贝叶斯(Naive Bayes)分类法基于统计学分类原理, 通过假定分类对象的单一属性值在给定类上的影响独立于其他属性的值, 计算给定对象隶属于不同类别的概率来预测类隶属关系[14]。
设D是训练对象与其相关联的类标号的集合。每个对象用一个n维属性向量 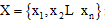
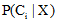
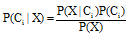 |
由于 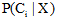

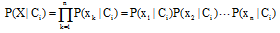 |
其中, 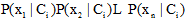
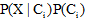
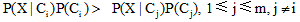
由上述分析可知, 对于网络舆情信息, 通过准确抽取舆情文档的特征词汇构建特征向量, 比较每个向量的类别隶属度, 即可依据朴素贝叶斯算法实现舆情文档的分类。由于网络舆情数据量大, 依靠服务器集中处理模式难以满足舆情数据实时监测的要求。Hadoop作为一个分布式应用程序框架, 同时还是一个用于信息存储的分布式文件系统, 其通过信息的分布式存储和并行处理, 能有效降低信息移动代价并提升系统运行效率。因而, 将朴素贝叶斯算法与Hadoop大数据处理平台相结合, 实现朴素贝叶斯分类算法的并行化运行, 构建基于MapReduce的并行化舆情数据分类方法, 可以提高算法对网络舆情的处理能力。基于MapReduce并行封装朴素贝叶斯分类算法, 可以将分类任务在由多台计算机组成的集群环境下自动并发, 通过Map过程完成原始数据的特征抽取与映射操作, 进行数据混洗后, 经过Reduce实现数据合并, 计算出最终的分类结果; 降低数据移动与交换的开销, 有效提升分类算法的运行速度, 并在系统层面解决了系统的扩展性问题。
同时, 通过本地化舆情信息存储与特征抽取, 可以增加本地特征词汇的抽取与存储数量, 提升特征向量的代表性和区分度, 在不同主题类别的分类过程中采用不同的特征词汇与不同权值构建特征向量, 从而提高舆情信息分类的准确度。另一方面, 朴素贝叶斯算法作为一种机器学习算法具有较强的自学习能力, 可以通过样本训练保障系统的分类性能, 而且训练后的分类系统还可以在使用过程中通过新样本的学习, 不断提升系统分类能力与数据挖掘能力。基于MapReduce的改进朴素贝叶斯并行分类算法如下:
(1) Map函数
输入: 训练数据集
输出: < Key’ , Value’ > 键值对, 其中key’ 是类别标签或标签、属性名称和值的组合, Value’ 为频率。
Map(Key, Value)
{
for(i = 0, i< 样本总数, i++ )
{
分配类别标签并计算每个属性的值;
将标签值赋给Key, Value为属性值;
输出键值对< Key, Value> ;
for(每个属性值)
{
搜索与测试样本一致的属性;
构建标签、属性名称和属性值的连结字符串;
将字符串赋值Key’ ; Value’ 置为1;
输出键值对< Key’ , Value’ > ;
}
}
}
(2) Reduce函数
输入: Key’ 和Value’ (由Map函数输出的Key’ 和Value’ )
输出: < Key” , Value” > 键值对, 其中Key” 为标签、属性名称与值的组合, Value” 为频率。
Reduce(Key’ , Value’ )
{
初始化计数器Sum=0, 记录Key’ 的当前统计频率;
while( pKey’ ) // pKey’ 为变量Key’ 的指针;
{
Sum+=Value. get();
pKey’ =pKey’ +1;
}
把Key’ 值赋给Key” , Sum值赋给Value” ;
输出< Key” , Value” > 键值对;
}
通过构造基于MapReduce的网络舆情数据并行处理算法, 完成舆情信息特征词汇的抽取与合并。根据舆情文档的特征词汇出现的频率、文档样本的数量等特征信息采用信息增益算法进行排序, 根据不同的分类主题赋予特征词汇不同的权值, 选取指定数量特征词汇构建文档特征向量, 作为朴素贝叶斯分类算法的输入信息进行训练, 构建文档分类器, 实现网络舆情文档分类处理。
首先, 采用网络爬虫工具对抓取到的网页数据进行分析去噪处理, 过滤网页广告、图片、链接等信息; 然后, 根据信息增益算法抽取文档特征词汇, 构建具有文档类别区分度的特征向量; 根据文档特征向量的类别隶属度进行分类处理, 对改进的并行朴素贝叶斯算法进行舆情文档分类性能评估。
利用5台计算机(联想扬天M4800, Intel G3220双核处理器, 2 GB内存)构建基于Hadoop的舆情信息监测平台, 1台作为Master节点, 具有NameNode和Jobtraker功能, 其余4台作为Slave节点, 实现DataNode和Tasktraker功能。Master节点实现任务的调度与结果的汇集, 各子节点对信息处理的结果进行本地化存储, Master节点从各个Slave节点上收集处理结果并进行归并处理。
为验证基于Hadoop平台的并行朴素贝叶斯算法分类性能, 选取SogouT①(① SogouT是搜狐搜索技术联合实验室推出的互联网语料库, 主要应用于中文互联网信息检索、数据挖掘方面的研究。
)整理的互联网中文文本分类语料库, 语料来源于搜狐新闻网站保存的大量经过编辑手工整理与分类的新闻语料与对应的分类信息; 其分类体系包括几十个分类节点, 网页规模约为10万篇文档。选取1 000篇文档作为语料, 主题内容涉及体育、财经、旅游、教育、交通、科技、社会、娱乐、政治、军事等10大类别, 每个类别100篇, 其中80篇用于训练分类系统模型, 20篇用于系统性能测试。采用分词系统ICTCLAS对语料进行分词处理和词性标注, 根据信息增益算法计算特征词的词频及其权重, 发现每篇语料中的特征词汇平均有186个, 根据不同类别文档特征词汇的权重排序, 取特征词汇前500项建立类别特征词汇库, 对剩余200篇测试样本进行特征词汇提取, 选取权重值前20项构建文档特征向量。通过基于Hadoop平台的朴素贝叶斯分类算法进行分类测试, 验证分类算法性能, 测试结果如表1所示:
| 表1 数据分类测试结果 |
由表1可知, 基于MapReduce封装的并行朴素贝叶斯舆情分类算法能够实现测试样本的正确分类; 算法的查准率和查全率都在85%以上, 达到了理想的实验效果, 说明算法具有良好的边界分类特性和容错能力。其中对社会和娱乐两种舆情的分类能力相对较低, 经样本分析发现, 在SogouT语料库中, 社会舆情与娱乐信息内容有较多的重合度, 如“ 成龙参加希望工程助学” 等语料文本信息。本方案通过本地化特征抽取与信息增益算法, 针对不同主题类别采用不同的特征词汇与权值, 提升了特征向量的代表性和区分度, 从而有效提升了舆情信息分类的准确度。
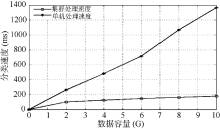
为验证改进的并行朴素贝叶斯分类算法的执行效率, 在由5台计算机组成的Hadoop平台和一台独立的服务器上采用朴素贝叶斯分类算法进行分类性能测试(服务器采用联想ThinkServer TS540, Intel E3-1225至强四核处理器, 8 GB内存), 从SogouT语料库中随机抽取舆情文档进行分类测试实验, 并采用ICTCLAS对舆情文档进行分词处理, 舆情分类测试库文件大小分别为2 GB、4 GB、6 GB、8 GB、10 GB。对比两种情况下系统的分类效率, 结果如图1所示:
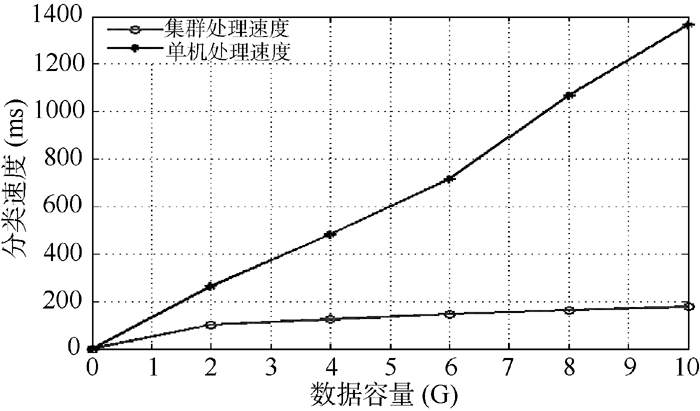 | 图1 算法执行效率比较 |
由图1可知, 基于Hadoop平台的并行朴素贝叶斯分类算法和独立服务器运行朴素贝叶斯分类算法相比, 运行速度明显提高。当分类数据容量较小时, 二者速度差别并不明显; 当分类内容大于4 GB时, 分类时间差开始明显增大; 当数据容量达到10 GB时, 本算法的分类能力达到集中式舆情数据分类处理速度的6倍以上。这是因为改进的并行朴素贝叶斯分类算法通过HDFS分布式存储与MapReduce并行化处理, 降低了分类数据的移动与存取时间, 使得数据分类效率明显上升。
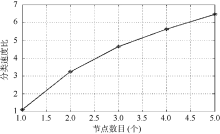
将Hadoop平台运行节点分别从1增加到5, 对比基于独立服务器与基于Hadoop平台并行封装的朴素贝叶斯算法的运行速度, 测试本分类算法的运行效率。定义二者分类速度比公式如下:
 |
如图2所示, 随Hadoop平台子节点数量的增加, 系统分类处理速度呈单调上升趋势, 而且运算效率的提升超过了运算节点增加的速度, 这是由于基于并行模式运行的朴素贝叶斯算法通过对舆情信息本地化特征抽取与增益处理, 有效降低了Slave节点与Master节点间的数据交换量, 节约了数据交换时间。可以通过增加运算节点的方式, 快速提升平台的舆情信息处理能力, 基于Hadoop平台的并行朴素贝叶斯分类算法具有良好的扩展能力。
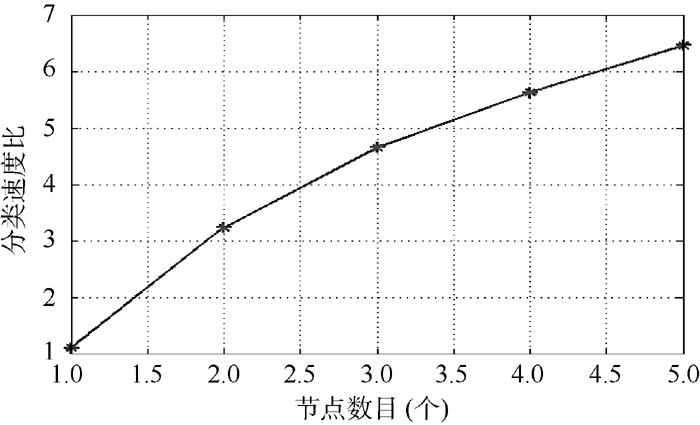 | 图2 分类执行速度比较 |
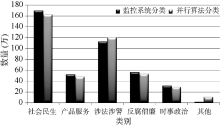
新闻报道都是进过加工后的信息, 不能直接反映网民真实想法。微博与论坛信息是网民思想的快速反应, 但由于信息较短, 舆情采集与分类相对困难。为验证本算法的分类处理能力, 实验中针对微博与论坛舆情信息进行收集与分类处理, 选取搜狐、新浪、腾讯、网易、人人等网站作为目标站点, 使用网络爬虫工具获取2013年10月1日-31日博客与论坛上的网络舆情信息, 采用基于Hadoop平台的并行朴素贝叶斯分类算法对采集到的舆情信息进行分类, 共采集到舆情信息4 231 832条。按照社会民生、产品服务、涉法涉警、反腐倡廉、时事政治、其他等几个方面对舆情信息进行分类, 并将分类结果与广泛使用的“ 乐思网络舆情监测系统” 分析结果进行比较, 如图3所示:
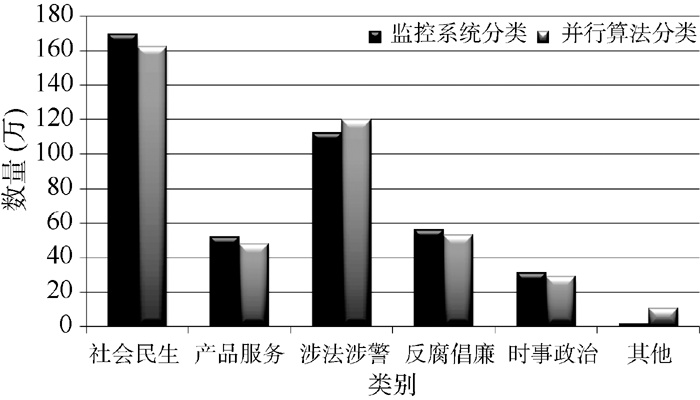 | 图3 网络舆情分类结果 |
由图3可知, 基于Hadoop平台的并行朴素贝叶斯分类算法可以很好地解决当前网络舆情分类技术中存在的问题。利用Hadoop平台分布式存储技术对不断变化的网络舆情信息进行保存与分类处理, 解决了结构化数据库对多元、异构的网络舆情数据分类效率低的问题, 使得舆情信息的挖掘能力和分类能力显著提高。本算法分类结果与“ 乐思网络舆情监测系统” 基本一致, 分类结果中“ 社会民生” 、“ 产品服务” 、“ 反腐倡廉” 几方面分类准确率较高, “ 其他” 不能确定类别的舆情信息项目比“ 乐思网络舆情监测系统” 稍多, 这是由于本算法采用的构成文档分类向量的关键词数量较少, 通过增加文档特征向量的属性项及权重修正, 可以进一步提升系统的分类性能。实验结果显示2013年10月份有关“ 社会民生” 的问题占舆情信息的38.5%, 涉法涉警问题占24.2%, 这与新华网发布的月度网络舆情信息分类统计结果相一致[15]。另一方面, 实验结果表明基于MapReduce架构的并行数据处理技术可以实现网络舆情的快速分类。实验中基于独立服务器运行的“ 乐思网络舆情监测系统” 实现信息分类用时112分32秒, 而基于Hadoop平台的并行网络舆情分类系统用时18分26秒, 舆情分类效率提升82%以上。基于Hadoop平台的网络舆情分类算法具有更高的分类效率, 适用于快速变化网络舆情的在线分类处理。
此外, 利用朴素贝叶斯算法的自学习功能还可以实现不同主题的舆情信息自动聚类。针对新出现的舆情信息和关键词汇进行聚类, 主动挖掘潜在网络舆情, 快速发现网络舆情中的新情况、新问题, 提升网络舆情预报能力是下一步的重要研究内容。
本文提出了一种基于Hadoop平台的并行朴素贝叶斯分类算法, 来实现网络舆情信息采集与分类处理。利用朴素贝叶斯算法简单、高效、适用于非结构化数据分类的特点, 结合云计算平台分布式存储与MapReduce的并行处理能力, 对朴素贝叶斯分类算法进行并行化封装处理, 降低了分类过程中数据移动与交换的开销, 提升了分类算法的运行效率。利用舆情信息的本地化存储特性增加特征词汇的抽取数量, 通过信息增益算法赋予特增词汇不同的权值, 增强特征向量的区分度, 同时利用朴素贝叶斯算法的自学习能力不断提升系统的分类能力。实验证明, 基于Hadoop平台的并行朴素贝叶斯网络舆情信息分类算法可以实现网络舆情的快速、准确分类处理, 对开展网络舆情在线监测、及时掌控社会舆情发展、维护社会和谐稳定具有重要意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|