{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于LDA主题关联过滤的领域主题演化研究*
[秦晓慧1, 2  , 乐小虬
, 乐小虬1 ]
, 乐小虬|
|


[Objective] To detect the birth, extinction, development, merge and split of topic evolution of the literatures in a certain field. [Methods] This paper divides time windows according to the publication data of the literatures, and LDA model is applied to extract topics from each time window automatically. The topic association filter rules are used to determine evolution relationships between topics in adjacent time windows. Form a topic evolution path in a continuous time period. [Results] Considering the continuity of the topics, different types of topic evolution could be detected with high accuracy. [Limitations] This method fixes the size of time windows without considering the diversity of topic evolution cycles. [Conclusions] This method can effectively reduce the interference of topics with smaller similarity in LDA, and enhance accuracy of evolution relation recognition.
领域主题演化指一个领域的主题内容与强度在研究过程中变化的现象[1], 能够帮助研究者深入了解主题产生、发展的过程。近年来, 有关领域主题演化的研究涌现出许多新思路和新方法, 其中改进LDA主题模型[2]是重要途径之一。常见的处理方式是利用LDA模型获取不同时间段出现的主题, 将相邻时间窗口的主题采用阈值法[3, 4, 5, 6, 7]或最大相似度法[8, 9]等进行关联。这种方法虽然能描述主题内容随时间的演化过程, 但其准确性存在瑕疵, 经常会使无关主题引入到演化关系中。
为了解决上述问题, 本文提出通过制定主题关联过滤规则, 对相邻时间窗口间的主题进行关联分析, 以期减少非关联主题的干扰问题。将对处理流程、实现方法以及实验结果进行具体阐述。
LDA模型[2]是一个三层贝叶斯生成模型, 其基本思想为: 主题是一个在词表上的多项式分布, 而每篇文献对这些主题有一个特定的分布。由于它可以很好地模拟大规模语料的语义信息, 在主题演化领域有一定的优势, 学者们对其进行了一系列扩展工作, 如动态主题模型DTM[10]、在线主题模型OLDA[11]、连续时间模型TOT[12]等; 其应用涉及电子邮件[2]、科研文献[13, 14]、微博[15]、作者[16, 17]等主题演化。
为全面分析主题内容的演化趋势, 常见的处理方式是根据文献的出版时间离散到相应的时间窗口[18], 利用LDA获取不同时间窗口出现的主题, 将相邻时间窗口间的主题关联, 进而获得主题的演化过程。其中相邻时间窗口的主题关联是主题演化分析的重要步骤, 主题能否关联决定着主题之间是否存在演化关系, 对主题演化结果有直接影响。本文归纳了4类常见的主题关联方法, 如表1所示:
| 表1 主题关联方法 |
对于相邻时间窗口间主题的关联, 直接关联法无需计算主题相似度, 但必须固定时间窗口的主题数, 不能有效地反映新主题的产生、旧主题的消亡等现象; 其他三种方法可根据经验值、困惑度[2]等将时间窗口中的主题数设为可变量, 通过计算主题相似度或主题距离决定主题是否存在关联, 相对来说应用更灵活。但也各有不足之处: 在相似度阈值法中, 主题演化关系的确定依赖于一个固定的阈值, 且对阈值的大小比较敏感, 例如, 相似度阈值太大会导致相邻时间窗口间存在演化关系的主题过少, 而相似度阈值法太小会使无关主题引入到主题演化中, 因此阈值的设定需要较强的专业知识; 最大相似度法可能会丢失相似度比较大的主题关联, 而误将相似度小的主题关联在一起。基于以上原因, 本文采用主题关联过滤方法判别主题间是否存在较强的关联, 进而分析主题的演化。
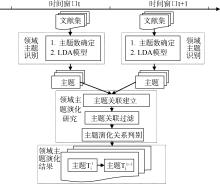
(1) 将时间序列划分为若干个长度固定的不重叠时间窗口, 根据文献的出版时间把文献划入到相应的时间窗口, 利用LDA主题模型识别不同时间窗口出现的主题;
(2) 计算相邻时间窗口中主题的相似度, 建立主题关联;
(3) 经主题关联过滤, 筛选出有效的主题关联;
(4) 针对相关联的主题, 经过沿时间序列向前或向后的推理, 判别主题的演化关系类型。
(1) 领域主题识别。针对不同时间窗口的文献集, 经LDA模型得到该时间窗口中的主题, 此处的主题表示为一个分布在一组主题词上向量;
(2) 主题关联建立。对步骤(1)中得出的主题向量, 计算相邻时间窗口间主题的相似度, 然后根据相似度建立主题关联;
(3) 主题关联过滤。制定三条主题关联过滤规则, 对步骤(2)中形成的主题关联进行过滤, 若经过滤后的主题关联仍有效, 则认为主题之间存在演化关系;
(4) 主题演化关系判别。分析已建立的主题演化关系, 依据时间先后顺序向前或向后推理, 确定主题的演化关系类型。
整体分析框架如图1所示:
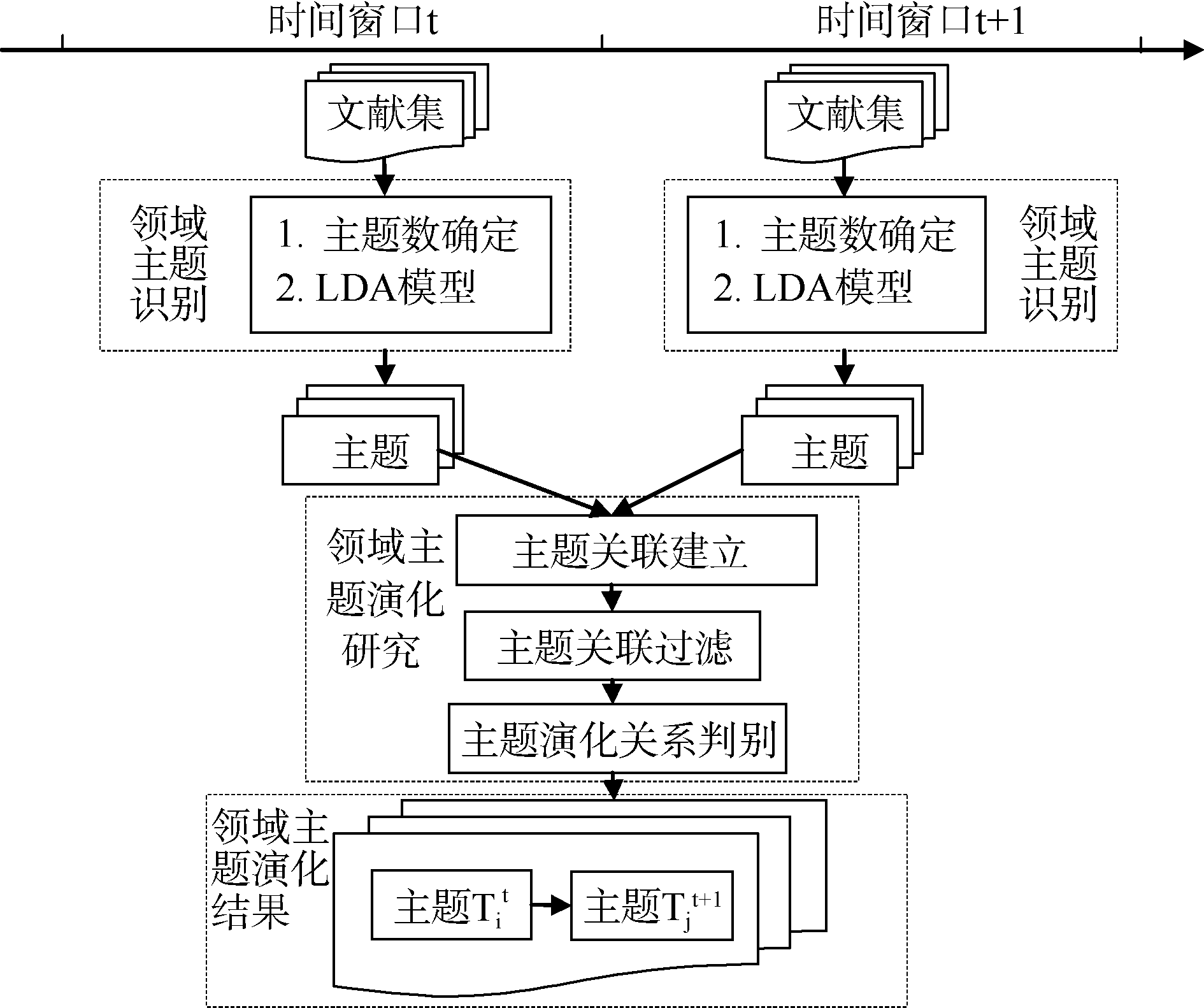 | 图1 领域主题演化分析框架 |
将时间序列划分为若干个长度为L的时间窗口, 依据文献的出版时间划入到相应的时间窗口。假设时间窗口t的文献集为Ct, 每个时间窗口内的文献数不同, 相应的主题数也应随着时间动态变化。因此作为LDA模型的输入参数之一, 主题数目K必须事先确定, 本文借鉴文献[20]的方法确定各时间窗口的主题数。
本文定义主题是分布在一组主题词上的向量, 即:
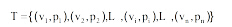
其中, vi是与主题T相关的词, pi是主题T在该词上的分布概率。在LDA中, 时间窗口t中的第i个主题可以表示为:
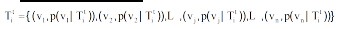
其中, vj∈ V, V为Ct的词表, p(vj|Tit)为主题Tit中词vj的概率。文献则定义为在这些主题上的多项分布, 因此文献d可表示为:
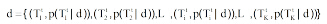
其中, p(Tit| d)为主题Tit在文献d中的概率。
经LDA识别出的不同时间窗口间的主题是相互独立的, 为分析主题的演化需对相邻时间窗口的主题建立关联。本文认为主题的演化过程中必然存在内容的延续与改变, 即相邻时间窗口间存在关联的两个主题具有内容相似性。通过计算相邻时间窗口间主题的相似度来衡量主题间内容的延续性, 并建立主题关联。
(1) 主题相似度
LDA中每个主题在词汇上的概率分布可看作一个1× |V|的向量, 可采用余弦相似度[21]计算主题间的相似程度。主题Tit与主题Tjt+1的相似度为:
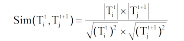 |
考虑到在计算过程中, 文献集合不断引入新词汇, 两个时间窗口中的词表不完全相同, 根据LDA思想与Gibbs[20]抽样的估计方式, 对于时间窗口t内未出现的词汇w, 主题Tit在w上的概率不为0, 而是符合一个统一的概率分布, 笔者定义该分布公式为:
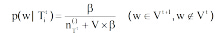 |
其中, V是Vt与Vt+1的并集, β 是LDA模型参数, 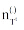
(2) 建立主题关联
针对时间窗口t中的主题Tit, 设时间窗口t+1内的主题按照与Tit的相似度从大到小排序, 其中, 与Tit相似度最大的是Tjt+1, 记Tjt+1为Tit的后向主题:
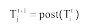
针对时间窗口t+1中的主题Tjt+1, 时间窗口t内的主题按照与Tjt+1的相似度从大到小排序, 其中, 与Tjt+1相似度最大的是Tit, 记Tit为Tjt+1的前向主题:

以上两种情况均认为Tit与Tjt+1之间存在主题关联。
主题关联建立后, 能够找出可能存在演化关系的主题对, 文献[8-9]直接将上述主题关联认定为演化关系, 但其结果会导致存在演化关系的两个主题相似度较低, 主题延续性不明显。为提高主题演化关系的准确度, 本文采用主题关联过滤规则去除无效的主题关联。
笔者定义以下三条过滤规则:
(1) 设定相似度阈值ε , 时间窗口t+1内的主题与Tit相似度的最大值为 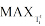
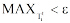
(2) 如果Tjt+1是Tit的后向主题, 即时间窗口t+1内的主题按照与Tit的相似度从大到小排序, Tjt+1的排序位置为第1; 设时间窗口t内的主题按照与Tjt+1的相似度从大到小排序, Tit所在的排序位置为第s (s> 2), 若存在主题Tkt所处的排序位置是ρ ∈ (1, s), 且post(Tkt)≠ Tjt+1, 即Tkt与Tjt+1不能建立关联, 则认为Tjt+1与Tit的关联无效;
(3) 时间窗口t内的主题与Tjt+1的相似度最大值为 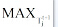
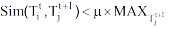
对于建立的主题关联, 采用以上三条规则过滤, 将过滤后仍存在关联的主题判定为具有较强的关联性, 即主题具有演化关系。
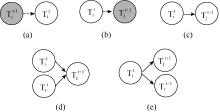
为解决主题演化中演化关系的判别问题, 本文对经关联过滤后的关联主题进行前向、后向的推理分析, 并把它们的关系分为新生、消亡、继承、分裂和合并5类, 如图2所示:
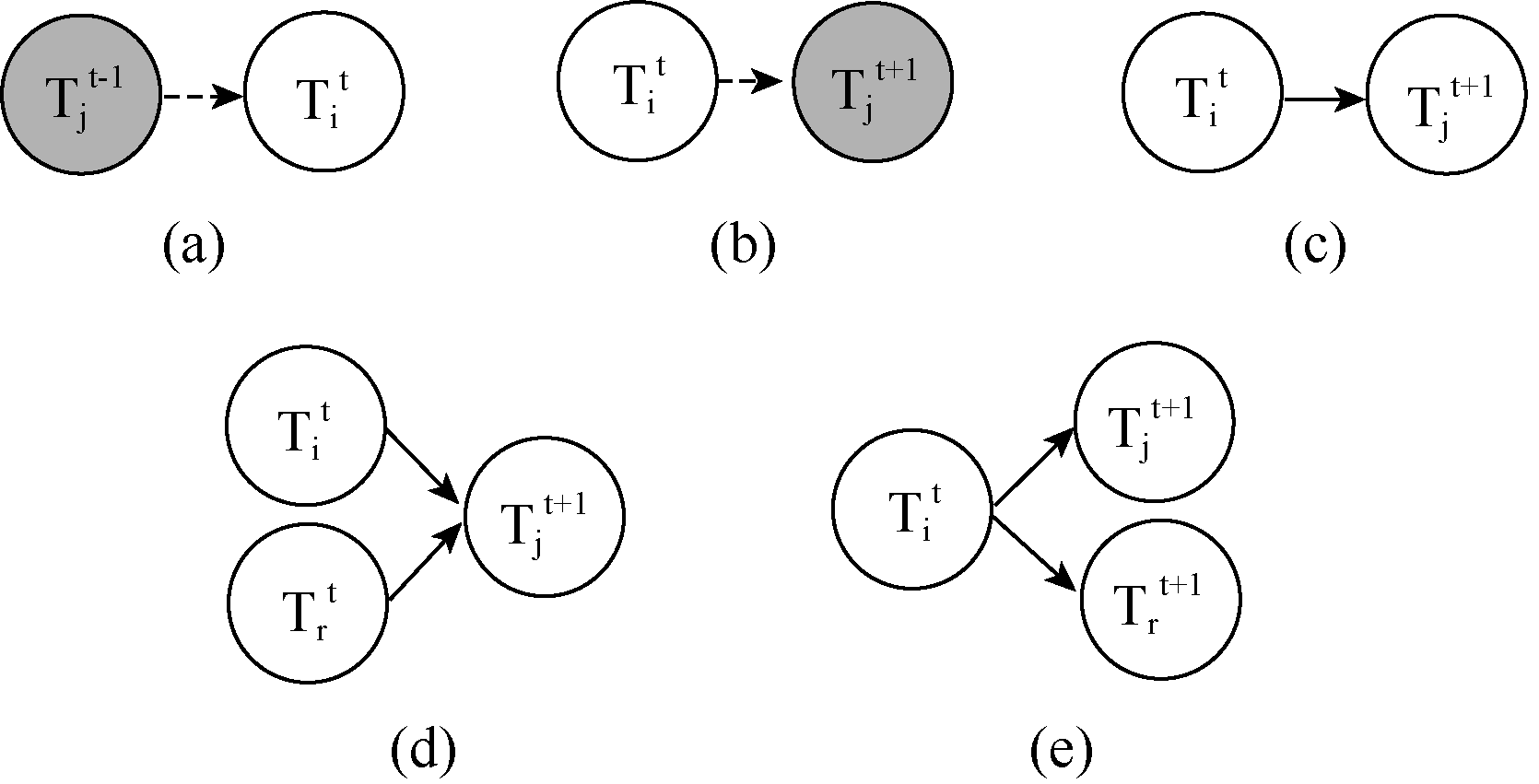 | 图2 领域主题演化形式 |
其中: a为主题新生; b为主题消亡; c为主题继承; d为主题合并; e为主题分裂。其中, 虚线箭头表示主题间演化关系不存在。
(1) 新生: 若主题Tit没有前向主题, 时间窗口t-1中也不存在后向主题是Tit的主题, 则认为Tit是t内新生的主题;
(2) 消亡: 若主题Tit没有后向主题, 时间窗口t+1中也不存在前向主题是Tit的主题, 则认为Tit是t内消亡的主题;
(3) 继承: 设主题Tit的后向主题是Tjt+1, 且Tjt+1的前向主题是Tit, 则认为Tjt+1、Tit是同一主题在不同时间段的表示, 即Tjt+1继承于Tit;
(4) 合并: 主题Tit的后向主题是Tjt+1, 而Tjt+1的前向主题是Trt, 且r≠ i, 则认为Tjt+1由Trt与Tit合并而得。若时间窗口t内有两个或两个以上主题的后向主题都是Tjt+1, 同样认为这些主题在时间窗口t+1中合并为Tjt+1;
(5) 分裂: 主题Tjt+1的前向主题是Tit, 而Tit的后向主题是Trt+1, 且r≠ j, 则认为Tjt+1、Trt+1由Tit分裂而得。若时间窗口t+1内有两个或两个以上主题的前向主题都是Tit, 则认为这些主题由Tit分裂而成。
为验证基于LDA主题关联过滤的领域主题演化方法的有效性, 本文从SCI下载2001年-2012年肿瘤领域20种期刊, 类型是Article与Proceeding Paper的文献共66 164篇。
利用NCI叙词表(National Cancer Institute thesaurus, NCIt)[22], 分别从标题、关键词、摘要中抽取肿瘤领域的词汇, 并把同义词归并为同一形式。此外还利用文献自身的关键词对词表进行扩充。
将时间序列划分为12个长度L为1年的时间窗口, 根据文献的出版时间把文献划入到相应的时间窗口。借鉴文献[20]的方法确定各个时间窗口的最优主题数。各时间窗口文献数、主题词数以及对应的最优主题数如表2所示:
| 表2 数据集各时间窗口所含文献数、主题词数 及最优主题数 |
利用LDA模型获取每个时间窗口的主题, 选取各个主题中分布概率Top8的词汇作为特征词表示主题内容。表3是2012年的部分主题:
| 表3 2012年部分主题 |
(1) 模型识别的主题具有明确的研究方向。观察T612012 “ 乳腺癌(Breast Carcinoma)” 、T832012 “ 免疫(Immunity)” 、T552012 “ 放射疗法(Radiation Therapy)” 三个主题, 发现主题间内容差别较大, 区分明显。
(2) 各主题中分布概率较高的主题词能够涵盖该主题的内容。以主题T612012“ 乳腺癌(Breast Carcinoma)” 为例, 美国国家癌症研究所发布[22]: 乳腺癌(Breast Carcinoma)是近些年常见癌症之一。另外根据实际文献观察, 近年来新辅助化疗越来越多地应用于可切除的乳腺癌治疗中, 但化疗对乳腺癌雌激素受体、孕激素受体的影响有很大争议, 不少学者为此展开研究。模型将雌激素(Estrogen)、雌激素受体蛋白(Estrogen Receptor)、助孕素(Progesterone)这些词汇归入同一主题中, 说明了该主题的涵盖内容。
按照3.4节中叙述的方法, 计算相邻时间窗口主题间的相似度, 并建立主题关联。根据3.5节的方法进行主题关联过滤, 其中过滤参数设置为: ε =0.20, μ =0.5。并与文献[9]中未经主题关联过滤的演化结果进行比较。
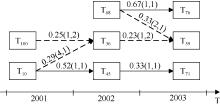
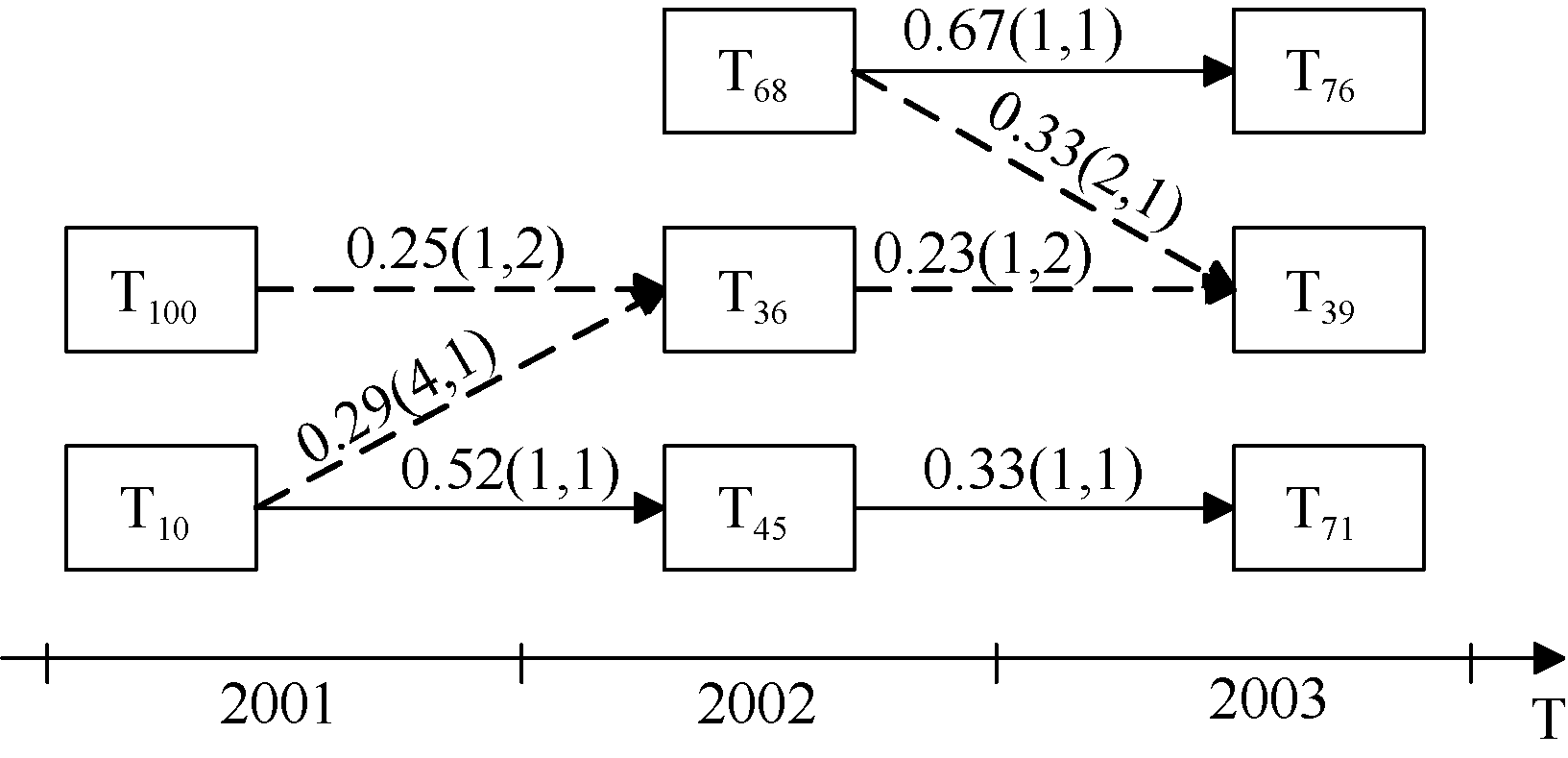 | 图3 2001年-2003年部分主题的演化关系 |
图3是从结果中选取的2001年-2003年若干个主题的演化图。箭头方向表示主题的演化方向, 其中实线箭头表示经本文方法过滤后的主题关联。箭头上数字表示箭头两端的主题之间的相似度大小及排序, 如T1002001与T362002之间的数字显示: 两主题的相似度为0.25, 2002年的主题按照与T1002001的相似度从大到小排序, T362002所处排序位置为第1; 2001年的主题按照与T362002的相似度从大到小排序, T1002001所处排序位置为第2。图3中各个主题内容如表4所示:
| 表4 图3中各主题内容 |
由图3可见, 未经主题关联过滤时: 2001年-2002年的主题演化中, 主题T452002继承于T102001, 同时T102001又与T1002001合并成T362002; 2002年-2003年的主题演化中, T712003继承于T452002, T762003继承于T682002, 同时T682002又与T362002合并生成T392003。而经本文方法的处理, T362002与T102001、T362002与T1002001、T392003与T682002、T392003与T362002的关联都被过滤。
在时间窗口2003内, T682002的相似主题中, T392003排序在第2位, 两者的相似度是0.33, 不足第一位T762003(0.67)的1/2。根据3.5节中过滤规则(3), T392003与T682002的关联无效。另外, T392003与T682002、T712003与T452002的相似度同为0.33, 但两个演化关系的判定结果不同, 观察两对主题的主题词, 可发现T712003与T452002中概率较高的相同词更多, 延续性更强。反映出本文的过滤方法可以针对不同数据、不同主题特征灵活取值, 无需通过较强的专业知识设定固定阈值。
主题过滤方法还能够自动识别相似度较低的关联, 并将其过滤。如2002年中的主题按照与T102001的相似度的大小排序, T362002仅占第4位, 而第2位和第3位的主题未与T102001建立关联, 根据3.5节中过滤规则(2), T362002与T102001的关联无效。另外在表4中可以看到, T102001与T452002都是关于免疫与抗体的内容, 关系更为密切, 而T362002主要内容为缩氨酸, 与免疫的相关性不强。
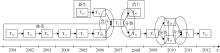
以主题“ 免疫(Immunity)” 为例分析其自2001年-2012年的演化情况, 如图4所示。可以看出T612005是2005年的新生主题, T442008在2008年后消亡; 主题在整个时间段上的演化过程中, 2001年-2006年逐年继承, 在2007年、2011年分别发生一次合并, 在2008年、2010年分别发生一次分裂。图4中各主题的内容如表5所示。
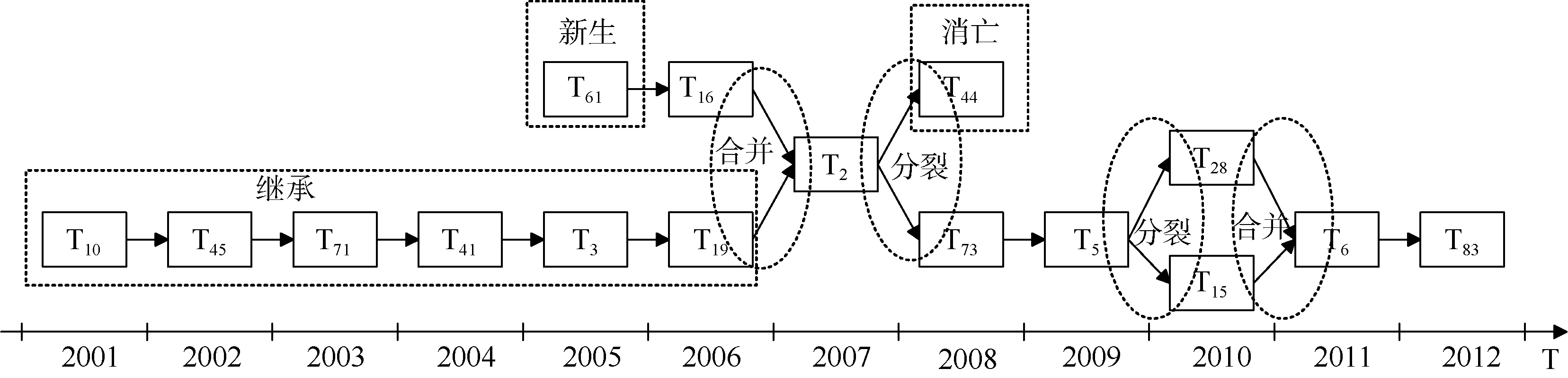 | 图4 主题“ 免疫(Immunity)” 2001年-2012年演化图 |
| 表5 主题“ 免疫(Immunity)” 的主题内容 |
(1) 根据图4与表5所示, 主题演化过程中主要内容明显, 而每年内容有细微变化。
由表5可以看出, 主题在整个时间段上的演化中免疫(Immunity)、抗体(Antigen)、CD8B1等位基因(CD8B1)、免疫疗法(Immunotherapy)等主题词出现概率较大, 说明该主题主要内容是免疫的物质、方法等。同时, 随着时间变化, 主题中词汇概率每年都有上下波动, 如CD8B1等位基因(CD8B1)、CD4基因(CD4 Gene)在2001年-2006年的概率排序逐年升高, 反映该主题的研究中有很多微观基因的讨论。
(2) 主题在整个时间段的演化过程中, 存在主题的新生、消亡、继承、分裂和合并5种类型的演化关系。
主题T612005的主要内容为抗体(Antibody)、缩氨酸(Peptide)等, 由于在2004年没有与其关联的主题, 被判定为新生主题; 同样, 由于在2009年没有与T442008相关联的主题, 判定T442008为消亡主题。
主题T192006概率较高的主题词为: CD8B1等位基因(CD8B1)、CD4基因(CD4 Gene)、细胞活素(Cytokine), T162006概率较高的主题词为: 缩氨酸(Peptide)、子宫内膜(Endometrial)、免疫疗法(Immunotherapy), 可了解到前者更侧重于基因等微观物质的研究, 后者则更侧重于免疫方法的讨论。这两个主题的主题词与T22007都有较大的重合度, 相似度分别为0.38和0.44, 可以推测T22007是由T192006与T162006合并而成的。
2010年, 主题T52009分裂成两个主题T152010和T282010。根据其主题词可看出T152010主要内容为抗癌抗菌素(Antitumor)、CD8B1等位基因(CD8B1)等免疫物质, 而T282010主要内容是针对种痘(Vaccination)、疾病反应(Disease Response)等现象的讨论。但两个主题均未脱离关于主题“ 免疫(Immunity)” 的分析, 可看作“ 免疫(Immunity)” 的两个子主题, 这些结果与对该领域的理解是一致的。
本文选用LDA主题模型, 采用主题关联过滤方法对领域主题的演化进行探索, 并以SCI中肿瘤领域的相关文献为例对该方法的有效性进行验证, 可以得出如下结论:
(1) 本文的方法有效地区分了主题的演化关系类型, 探测领域文献中主题的新生与消亡, 揭示主题继承时内容的变化, 反映主题的合并与分裂原因、合并内容以及分裂方向。
(2) 主题关联过滤有效地降低了LDA主题模型中相似度较小的主题的干扰, 从而提升主题演化关系(新生、消亡、继承、分裂和合并)的识别准确性。
(3) 过滤方法针对不同数据、不同主题特征灵活设定主题关联阈值, 解决了演化关系确定时对固定阈值大小过于敏感的问题。
但是, 本文把时间窗口大小设置为不可变, 未考虑主题演化周期的多样性。因此下一步的研究中将考虑根据不同主题的特点, 灵活设置时间窗口的大小, 以提高主题演化分析的合理性与准确性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|