
{kind=link}
{kind=link}
{kind=link}
{kind=link}
带权复杂图模型的专利关键词标引研究*
[李军锋 , 吕学强, 周绍钧]
, 吕学强, 周绍钧]
, 吕学强, 周绍钧]
|
|


作者简介:吕学强: 提出研究命题; 周绍钧: 采集、清洗和分析数据, 设计研究方案; 李军锋: 设计研究方案, 进行实验, 论文起草及最终版本修订。
[Objective] Patent keyword indexing plays an important role in nature language processing and is widely applied in many fields, such as patent retrieval, translation and automatic summary. [Methods] Using K-proximity coupled graph to transfer patents into complex graph model, and average connectivity weight is proposed with the average path variation, the average clustering coefficient, and the current node’s liquidity effect. Considering the location information, the word-gap information and the inverse document frequency of keywords, a patent comprehensive correlation calculation method for quantitative analysis of keyword importance is proposed. [Results] Experiment of patent literatures in sensor domain obtains the precision of 60.9% on top-8, and the recall rate of 73.4% on top-10. [Limitations] The result of keywords with low frequency is not good enough, which affects the indexing result. [Conclusions] Experimental results show that this method is effective and has active significance for patent indexing.
专利文献作为信息化社会的重要资源, 所反映的技术信息内容涉及人类生活的诸多方面。专利关键词作为专利文献核心要素, 不仅能为用户提供简洁内容摘要, 而且使专利信息定位更加快速、便捷和准确。专利关键词标引(Patent Keyword Indexing, PKI)在专利领域具有越来越广泛的应用, 如专利信息检索、专利翻译等。专利信息检索通过对用户的查询字段与专利信息进行相似度计算, 展示出用户所需要的信息, 通过专利关键词标引进一步提升与精炼专利信息, 因此专利关键词标引可以有效提高专利信息检索的性能[1]。Fujii等[2]提出长句子与关键词是影响专利翻译正确率的关键要素, 由此可见专利关键词对专利文献翻译也起着重要作用。
专利关键词标引, 致力于从专利文献中自动抽取词组或者短语表达专利信息的主题内容。国内外学者对关键词标引做了大量研究, 依据关键词标引采用的理论方法, 主要分为:
(1) 统计分析方法, 主要利用专利信息中术语的显著特征, 如共现、逆文档频次、互信息等。Wartena等[3]在TF-IDF的基础上, 结合词间共现分布和词间语义关系进行关键词抽取, 相比传统的TF-IDF方法提高了抽取关键词的精度与广度。罗准辰等[4]在边界参数与互信息结合的基础上提出了分离模型, 显著提高了关键词标引质量。
(2) 语义分析方法, 此类方法从自然语言的语义角度探索关键词标引。索红光等[5]将《知网》作为知识库, 结合词汇间语义信息提出构建词汇链的算法, 有效改善了关键词标引的性能。Noh等[6]利用主题相关度, 通过分析候选关键词的语义信息从句子抽取关键词, 取得了较好的抽取效果。
(3) 人工智能分析方法, 主要从机器学习的角度对自动标引进行研究。章成志[7]将机器学习模型与集成学习方法进行整合, 基于多分类模型的加权投票方式对文档进行自动标引, 取得了较好的标引效果; Chen等[8]提出一种基于Co-training的中文专利语义标注方法, 解决了已标注语料规模较小的问题, 在保证标引正确率的前提下提高其召回率。
(4) 基于图模型的方法, 该方法给关键词标引带来了新的方向与思路。马力等[9]在小世界模型的基础上, 使用平均聚类系数以及平均路径变化量作为评价标准抽取关键词。翟周伟等[10]以K-最邻近耦合图的方式将文档表示成词语结构图, 结合聚类系数以及TF-IDF衡量词语的重要性, 从而完成关键词标引。夏天[11]利用TextRank的思想构建候选关键词图, 并提出利用覆盖影响力、位置影响力和频度影响力计算候选关键词间的转移概率来抽取关键词, 取得了较好的关键词抽取效果。Wang等[12]以候选关键词为节点, 并以词间相似度为边的权重构建出图模型, 在医学文献中取得了较好的关键词标引效果。
上述方法从不同角度进行关键词标引, 取得了较好的效果。但专利文献具有半结构化特性, 例如层次结构明显、描述规范、主题明确, 具有复杂网络特性。因此, 本文首先从专利文献中获取候选关键词作为复杂图模型的节点, 在此基础上将专利文献映射成复杂图模型, 采用评价网络拓扑结构节点间依赖关系的拓扑势[13], 计算专利文献复杂图模型边的权重。其次, 将关键词全局重要性的平均路径变化量与考虑关键词局部重要性的平均聚类系数变化量作为关键词节点的重要性评价指标。同时, 在分析节点对整个复杂图模型流动性影响的基础上, 提出将平均连通权重作为节点重要性评价指标。此外, 融合关键词位置信息、关键词跨度信息以及关键词逆文档频率信息, 提出专利综合相关特征计算方法, 定量分析关键词重要性, 并将此特征与复杂图模型评价指标相结合, 完成关键词标引工作。
专利文献由专利术语与停用词构成, 相邻停用词间的语块可作为专利术语[14]。专利术语作为专利文献的核心知识, 能够完整地描述专利文献中包含的新技术或者新方法。对专利文献进行标引的关键词需要表达专利文献的主题, 体现专利文献的核心知识, 此外, 在抽取术语的过程中, 关键词抽取也可作为术语抽取的一部分[15], 因此, 可以认为标引关键词集合包含于专利术语集合, 即{标引关键词} 
复杂图模型以候选关键词为节点, 以网络的形式展示节点之间的相互关系, 采用评价网络图中节点重要性的相关指标衡量关键词的重要性; 专利综合相关特征从关键词的位置、跨度以及逆文档频率角度对关键词进行度量。本文结合复杂图模型与专利相关特征进行专利标引。
语法元素作为构成自然语言的基本要素, 指的是词、词组以及短语。语法元素是有限的, 但是通过对其进行有效排列组合可形成不同语义的句子。上述过程可以抽象为以语法元素为节点, 其关联关系为边的自然语言复杂图模型。在对专利文献进行描述时, 某些关键词通常会聚集起来表述当前段落局部主题, 不同的局部主题相互关联构成整篇专利文献主旨, 即专利文献具有复杂网络特性。因此, 本文将专利文献映射为复杂图模型, 并采用拓扑势对边加权, 再结合衡量关键词全局重要性的平均路径变化量与测定关键词局部重要性的平均聚类系数变化量作为节点重要性评价指标, 提出平均连通权重衡量当前节点在整个网络中的重要性。
(1) 带权专利文献复杂图模型构建
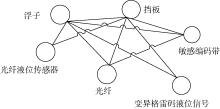
目前研究的网络模型多为K-最邻近耦合图[10], 它是一种稀疏的规则网络。每个节点仅与其左右K/2个节点相连接, 其中K为偶数, 当K值较大时, 此网络表现出高聚类性。该模型在复杂图模型构建的方法中是较为有效的一种, 其考虑了词序位置信息, 能较好地度量文档各节点间的关联关系。因此, 本文采用该方法构建专利文献复杂图模型, 利用文献[14]提出的方法获取专利术语作为候选关键词节点, 候选关键词之间的关联关系作为边, 设置参数K为4, 即在同一句子中, 间隔不大于2的关键词建立关联关系[9]。经过如上处理, 可将专利文献映射为K-最邻近耦合图, 如“ 本发明提供的光纤液位传感器, 利用浮子上特制的挡板与光纤对构成一个敏感编码带, 通过浮子跟踪液位运动来带动挡板移动获得变异格雷码液位信号” , 其中加黑部分为候选关键词, 其K-最邻近耦合图如图1所示。
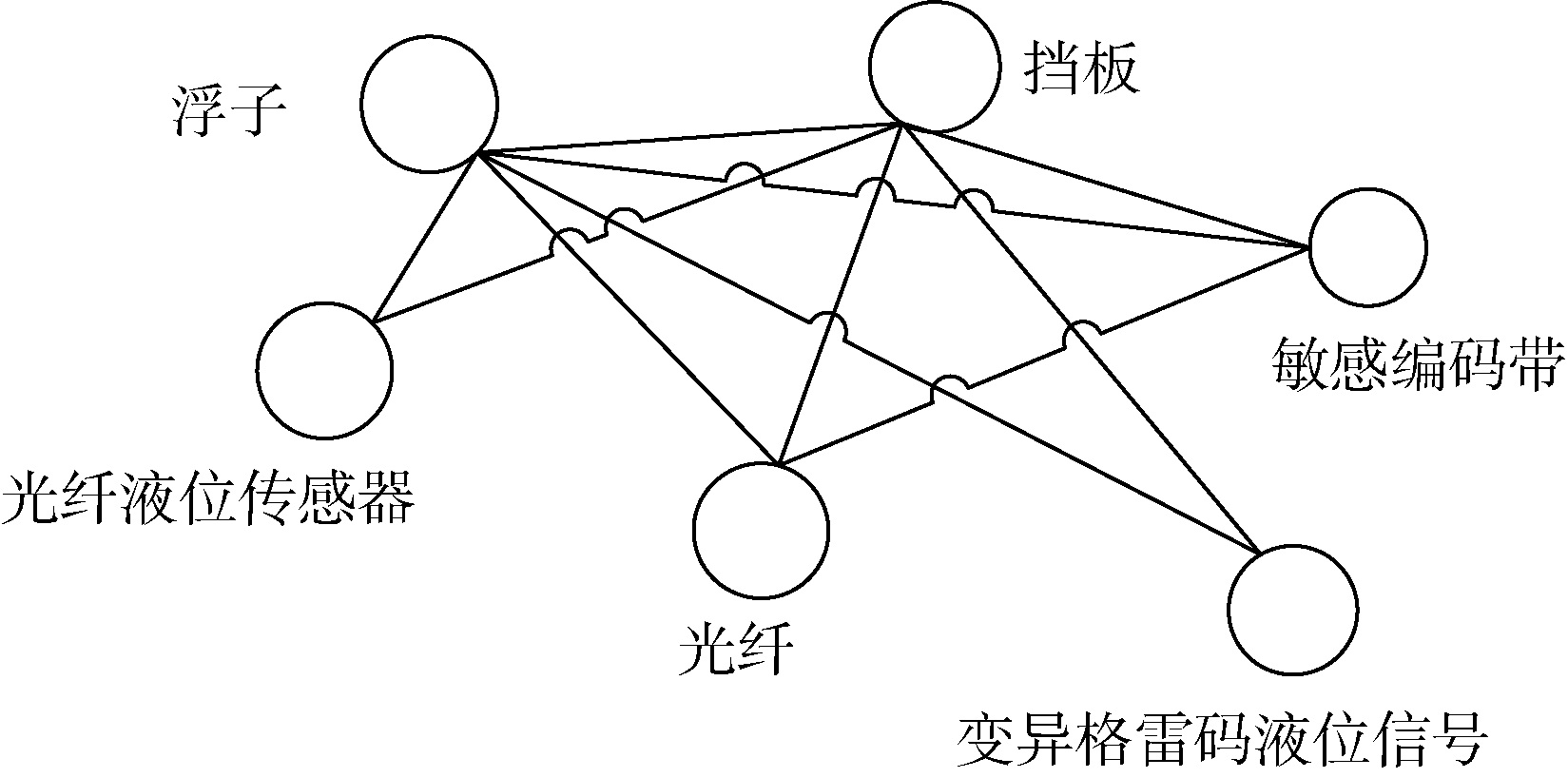 | 图1 复杂图模型示例 |
文献[9]采用的小世界模型为无权网络模型, 节点间的边表示其间是否存在关系。而节点自身的强度以及节点相互关联强度的差异往往对节点重要性评价具有关键作用, 因此节点间关联关系是节点重要性评价不可或缺的因素。
拓扑势是物理学中的概念, 用于计算空间中任意点与场源的势值, 且势值与场源距离成反比[13]。基于拓扑势的原理, 可以将复杂图模型作为具有n个节点以及其关联关系组成的物理场。其中每个节点作为场源, 关联关系为节点场源作用的范围。同时, 结合实际中物理网络的模块性以及聚合特性, 可以认定节点场源与其他场源存在相互作用, 但此相互作用会随着节点场源间距离的增加而急剧减少。基于以上分析, 本文提出拓扑势边权计算方法, 公式如下:
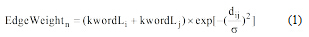
其中, EdgeWeightn为关键词kwordi与关键词kwordj之间连边的权重, kwordLi为kwordi的词长, kwordLj为kwordj的词长, dij为kwordi与kwordj在专利文献中的间隔长度。
(2) 平均路径变化量与平均聚类系数变化量
平均路径长度(Average Path Length, APL)是指复杂图模型中任意两个节点的最短路径上边数的平均值, 用于衡量复杂图模型的紧凑度及关联特性, 长度越短则复杂图模型越紧凑, 关联性也越高。同时, 平均路径长度能体现出复杂图模型的小世界特性[9], 很多复杂大型网络的节点较多, 但平均路径长度却非常小, 说明复杂大型网络具有小世界特性。
聚类系数用于描述复杂图模型中节点的汇聚特性, 其通过节点所在子图的边数与子图中节点个数的比值进行度量。平均聚类系数(Average Cluster Parameter, ACP)是复杂图模型中各节点聚类系数的平均值, 表明复杂图模型中节点的相互聚集程度。
平均最短路径从全局角度对当前节点进行度量, 而平均聚类系数通过当前节点所在子图对节点进行局部性度量, 因此将其结合能全面地衡量节点的重要性。由于具有复杂网络特性的专利文献中, 关键词常在较短的路径上出现, 具有较高聚类系数的情况, 当去除这些关键词后, 专利文献所呈现的复杂网络特性会减弱, 即平均路径长度会上升, 平均聚类系数下降, 且节点重要性越大则其相应变化量越大。因此, 本文将这两者之和作为节点重要性评价指标, 公式如下:
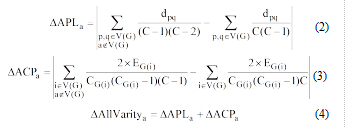 |
其中, Δ APLa表示节点a的平均路径变化量, Δ ACPa表示节点a的平均聚类系数变化量, Δ AllVaritya表示节点a的总变化量; C为图G中的节点数, V(G)为图G中节点的集合, dpq为图G中节点p与q间最短路径的长度, CG(i)为子图G(i)的节点数, EG(i)为子图G(i)中的边数。
(3) 平均连通权重
节点的度指在复杂图模型中与当前节点存在关联关系边的数量, 是衡量复杂图模型节点连通性及重要性的指标。节点的度越大则与其关联的边越多, 其对复杂图模型的流通影响越大。
在实际复杂图模型中, 度相同的节点也会有不同的权重, 如图 1中关键词“ 敏感编码带” 与“ 光纤” 具有相同的度, 但其影响力及其在专利文献中的作用不同。因此若仅考虑节点的度, 就会忽略与当前节点相连节点之间的关联强度信息, 本文综合考虑节点度信息以及与当前节点相邻节点之间的关联信息, 即边权重信息, 提出平均连通权重指标, 公式如下:
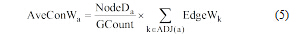 |
其中, AveConWa为节点a的平均连通权重, NodeDa为节点a的度, GCount为图G的全部节点数量, ADJ(a)为与节点a相邻节点集合, EdgeWk为节点k与节点a之间边的权重。
关键词的跨度信息, 即当前关键词在专利文献中首次出现与最后出现位置间包含句子的数量。关键词跨度对专利关键词标引提供了重要信息, 跨度越大其作用范围越大, 影响范围越广。
关键词在专利文献中出现的位置蕴含着不同的信息。关键词在专利文献标题中出现时, 其作为标引关键词的概率最大; 技术领域与背景技术分别介绍当前技术所处的领域以及背景, 其所含的技术关键词是该领域的核心概念; 发明内容则阐述当前专利文献的核心内容, 其中出现的关键词能比较准确地反映主题; 附图说明及具体实施方式则是从细节角度对专利的技术进行阐述。由于标题和发明内容均能较好地反映技术主题, 因此标引关键词出自这两部分的可能性较大, 在调整位置权重时, 应赋予这两部分较高的权值。本文根据专利文献不同的结构赋予不同的权值, 根据反复测试不同组合的识别效果, 最终采用的位置权重如表 1所示:
| 表1 专利文献各结构位置权值 |
逆文档频率(Inverse Document Frequency, IDF), 在信息检索领域应用较为广泛。专利文献是专利作者对其提出的创新性技术的阐述, 因此其关键词应具有较高的逆文档频率, 即在其他专利文献中出现的频率较少。本文结合关键词位置信息、跨度信息以及逆文档频率信息, 提出专利综合相关特征计算方法, 公式如下:
 |
其中, PTIa表示关键词a的专利综合相关特征权重, wordGapa为关键词a的词跨度, 此跨度以句子为计算单位, maxGap为专利文献中最大的跨度, 即所有专利文献中包含句子的数目, wordLoca为关键词a的位置权重, Total为所有专利文献的数目, IDFa为出现关键词a的专利文献频率的倒数, 即逆文档频率。
复杂图模型展示了专利文献中节点之间的关联关系, 并采用平均路径变化量、平均聚类系数变化量以及平均连通权重指标考核关键词的重要性; 专利综合相关特征融合了关键词的位置、跨度以及逆文档频率信息, 对关键词进行度量。上述两种方法分别从不同角度分析了关键词的特点, 因此, 本文结合复杂图模型指标与专利综合相关特征计算候选关键词的权值, 根据关键词权值排序结果, 抽取Top-N结果作为标引关键词, 公式如下:
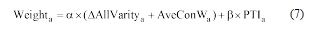 |
其中, Weighta表示关键词a的综合权值, ɑ 与β 为调节因子, Δ AllVaritya为a在复杂图模型中的总变化量, AveConWa为a的平均连通权值, PTIa为a的专利综合相关特征权值。
实验语料采用从国家知识产权局下载的含有“ 传感器” 的中文专利文献, 通过人工筛选得到传感器领域专利文献4 352篇, 最终得到78MB纯文本格式的专利文献语料, 从中随机抽取120篇作为实验评测语料。经多次实验后, 将公式(7)中调节参数 ɑ 和β 的值均设为0.3。人工对评测语料中每篇专利文献均标记8个正确的标引关键词, 从评测语料的每篇专利文献中抽取Top-N个关键词进行评测, N的范围设定为1-10的整数。实验分为两组, 第一组为分别考核复杂图模型指标、专利综合相关特征以及二者相结合的实验结果; 第二组是本文方法与文献[9]方法的对比实验。实验中对结果进行评价时, 采用信息检索领域经典的评价指标: 准确率(P)、召回率(R)以及F值(F)。
表2为第一组实验的结果, 其中复杂图模型指标方法以CG(Complicate Graph)表示, 专利综合相关特征方法以PCI(Patent Comprehensive Information)表示。二者相结合的方法, 用CG+PCI表示。Top-N表示从评测语料的每篇专利文献中抽取前N个关键词。
| 表2 CG、PCI、CG+PCI实验结果对比 |
由表2实验结果分析, 在P和R两个指标上, CG+PCI在不同Top-N级别上均优于CG、PCI方法。实验采用人工标记每篇专利文献8个正确的标引关键词进行评测, 当N=8时准确率与召回率相等, 在Top-8级别上CG方法准确率较PCI方法提高7.8%, CG+PCI方法较CG方法提高6.2%, 进一步说明CG+PCI方法的优越性。CG+PCI方法将CG复杂图模型中评价节点重要性指标与PCI专利相关特征中关键词跨度、位置、逆文档频率信息相结合, 全面分析关键词特征, 因此实验结果优于单独使用CG方法以及单独使用PCI方法。
第二组实验以文献[9]的方法为对比实验, 记为Baseline, 实验结果如表3所示。CG+PCI方法在准确率、召回率以及F值均优于Baseline方法。在Top-9级别上CG+PCI方法的准确率较Baseline方法提高12.8%, 召回率提高14.4%, 进一步说明CG+PCI方法的有效性。CG方法通过分析语言结构, 深层次地挖掘节点间关联关系, 对具有复杂图模型特性的专利文献具有较好的效果; PCI方法则利用关键词位置信息、关键词跨度信息以及关键词逆文档频率信息进行计算, 对CG方法进行补充, 同时避免了高频次、局部重要的关键词对标引结果的影响, CG+PCI方法综合了两种方法的优势, 相比Baseline取得了更好的效果。
| 表3 CG+PCI与Baseline实验结果对比 |
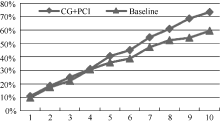
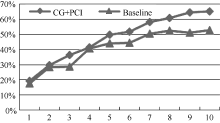
CG+PCI与Baseline对比如图2至图4所示。可知CG+PCI方法在Top-1至Top-10级别上均优于Baseline方法, 在Top-4级别上Baseline方法的准确率、召回率以及F值均贴近CG+PCI方法, 可见在Top-4级别上衡量关键词重要性的指标平均最短路径变化量以及平局聚类系数变化量占据主导因素。由图 2可知, CG+PCI方法在Top-4至Top-8级别上准确率表现较好且较平稳, 说明CG+PCI方法在此范围内具有较好性能, 而关键词标引所需的关键词数也在此范围内; 由图 3、图 4可知, CG+PCI方法的召回率与F值在Top-4至Top-8级别上相比Baseline方法表现出了较好的性能。因此, 总体上本文方法的专利关键词标引效果明显优于Baseline方法。
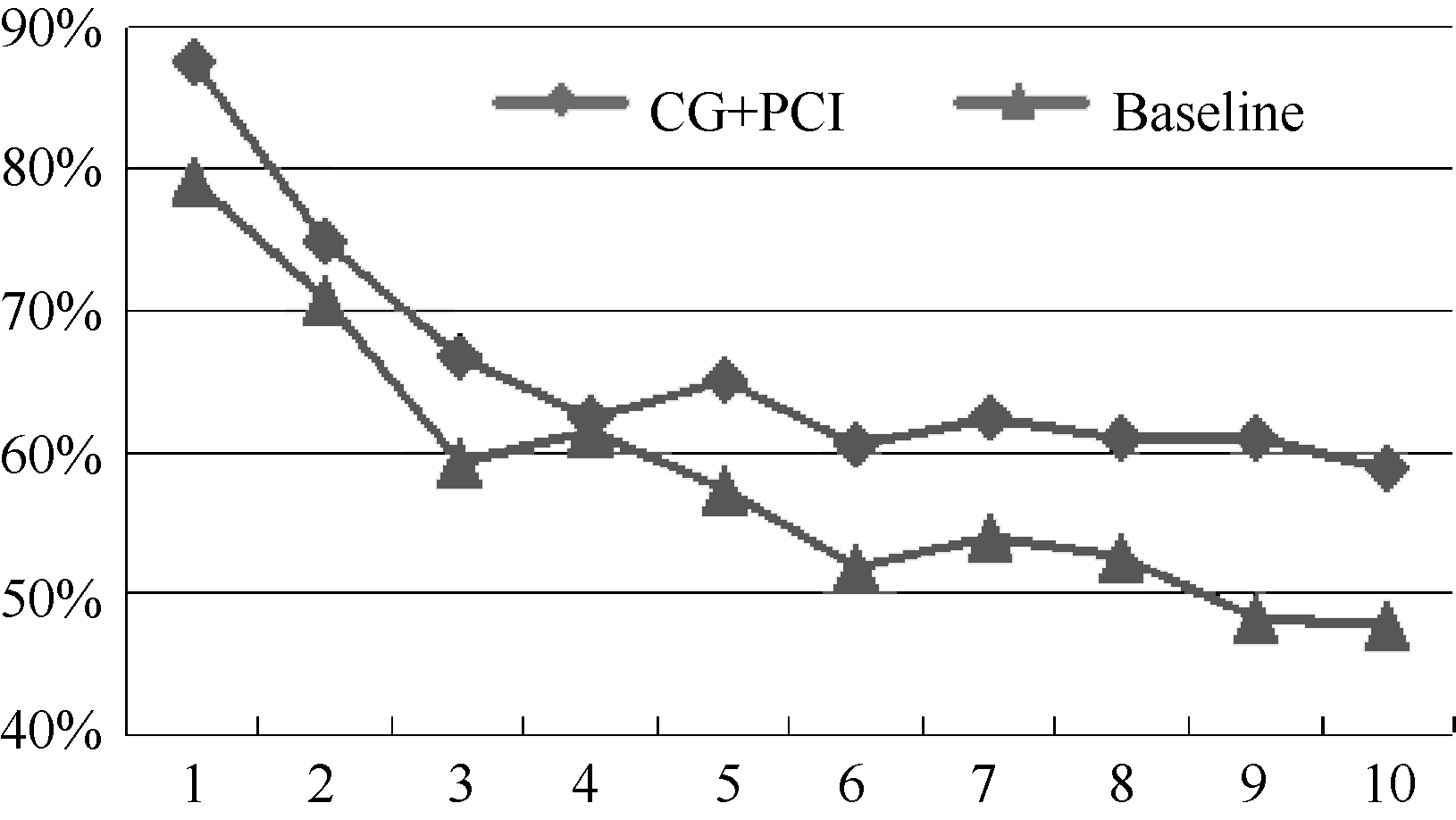 | 图2 CG+PCI与Baseline准确率对比 |
 | 图3 CG+PCI与Baseline召回率对比 |
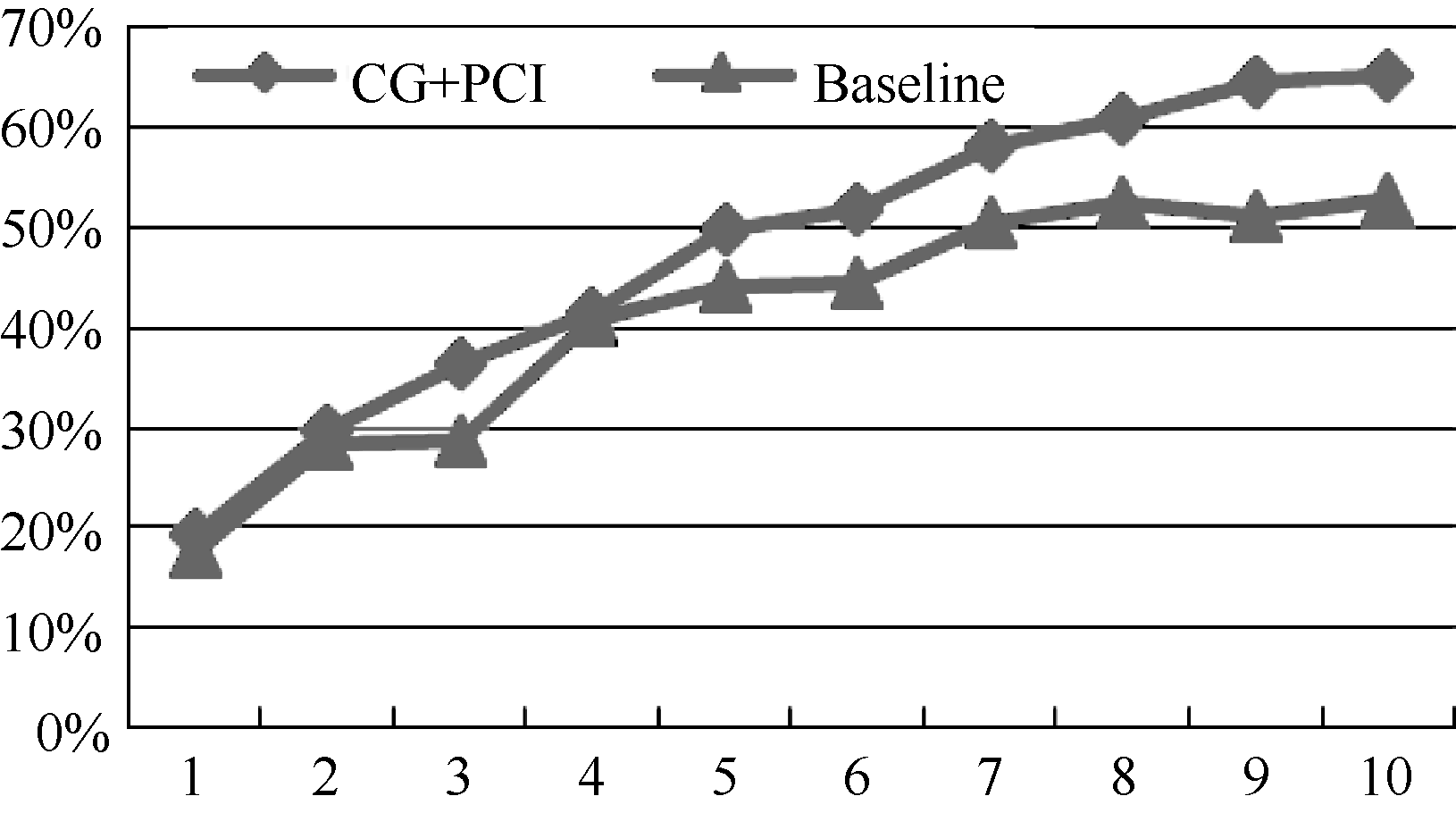 | 图4 CG+PCI与Baseline的F值对比 |
本文融合复杂图模型的关键词重要性评价指标与专利综合相关信息进行专利关键词标引。
(1) 采用K-最邻近耦合图将专利文献映射成复杂图模型, 引入评价网络拓扑节点间依赖关系的拓扑势, 计算专利文献复杂图模型边的权重;
(2) 结合测定关键词全局重要性的平均路径变化量和其局部重要性的平均聚类系数变化量作为节点重要性评价指标, 在进一步分析节点对整个复杂图模型流动性影响的基础上, 提出平均连通权重作为节点重要性评价指标;
(3) 通过分析关键词位置信息、关键词跨度信息以及关键词逆文档频率信息, 提出专利综合相关特征计算方法衡量关键词重要性, 并将复杂图模型评价指标与专利综合相关特征相结合, 完成专利关键词标引工作。在评测语料中的专利文献中取得了较好的专利关键词标引效果。
本文方法仍存在一些不足之处: 处理低频关键词的效果不够理想; 未能对复杂图模型节点重要性评价指标与专利综合相关信息之间的关系进行定量分析。针对上述不足, 未来工作主要从以下两个方面展开:
(1) 进一步研究专利文献的语义映射模型;
(2) 定量分析复杂图模型节点重要性评价指标与专利综合相关信息之间的关联。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|