
{kind=link}
领域概念的三层递进筛选方法研究*
[余凡1 , 楼雯2  ]
]
]
|
|


楼雯,提出研究思路,设计领域概念筛选方法与分析过程,起草论文。余凡,实验的具体实施,论文修订,楼雯, 余凡,清洗、分析数据。
[Objective] To improve the efficiency of concepts filter by using three concept filter method with thesaurus and text. [Methods] This paper proposes a method for domain concepts triple-layer filter. Extract domain concepts from data sources containing thesaurus and text. Focuse on calculating the concepts properties and field properties of domain concepts through concepts correlation, concepts context and concepts territoriality. [Results] Experimental results show that the precision reaches 74.71% and the recall reaches 71.25% based on triple-layer filter method. [Limitations] Data sources are only about mapping, this paper doesn’t use the data in other fields to demonstrate the feasibility of method. [Conclusions] This paper improves the precision and recall of domain concepts filter. Comprehensive efficiency is higher than other methods. This method could filter domain concepts from different subjects with high efficiency.
领域概念能够为领域研究者提供领域知识, 使得他们能够更加便利地从事科学研究, 发现科学规律。领域概念通常来自于文献, 如何高效地从文献文本中筛选出领域概念是迫切需要解决的问题。不同的数据源和概念属性都有各自特点, 使用某一种概念筛选方法效率偏低, 如果综合利用多种数据源, 同时考虑以上两个属性, 也许能够提高筛选效率。本文基于此思路展开研究, 利用概念相关性、上下文和领域性以点到面三层递进的方式计算领域概念的组词属性和领域属性, 以期提高领域概念筛选的效率。
领域概念筛选的数据源分为叙词表和文本。基于两种不同数据源的筛选方法各有不同。
(1) 基于叙词表的领域概念筛选
利用叙词表筛选概念的研究中, 出现最多的两个词是规则和映射。叙词表的内容会根据领域的不同有所不同, 但叙词表结构都十分规范, 能够根据具体的叙词表规范制定相应规则, 完成映射[1, 2]。在领域概念筛选的过程中通常会耗费大量时间, 基于叙词表的概念筛选往往会直接利用简单的规则完成概念筛选, 因此, 此方法能够大幅度提高概念筛选的速度。当然, 此方法缺点也十分明显, 叙词表往往是通过专家经验制定的, 其发布存在一定的滞后性, 无法覆盖本领域的新兴概念。
(2) 基于文本的领域概念筛选
与叙词表不同, 文本中的字词之间没有明显的间隔, 无法通过制定简单的规则筛选概念。文本概念筛选研究集中在如何对文本切词, 如何利用组词规则、词汇出现的频率以及分布情况提取、筛选领域概念[3, 4]。文本中出现的概念没有规范, 需要使用多种方法进行筛选, 提取的效率相对低下。此方法的优点是能够筛选出本领域的新兴概念。
领域概念筛选方法很多, 可以归纳为以下两种。
(1) 基于规则的概念筛选
基于叙词表的概念筛选都是通过制定规则完成筛选的。在文本概念筛选中, 也会利用概念的组词规则筛选概念。通过制定常用的组词规则筛选出正确的概念, 例如: “ 名词+名词” 组成的概念经常出现, 可以抽象出这条规则[5]。
(2) 基于统计的概念筛选
基于统计的概念筛选利用概念在整个文本集合中出现的频率以及分布情况, 结合相应的数据模型提取概念, 常用的数据模型有: TF-IDF、互信息、最大熵等[6, 7]。除此之外, 概念筛选还需要计算概念之间的相似度, 以进行聚类运算, 常用的相似度算法有: 余弦向量法和欧式距离法[8]。
基于规则的概念筛选效率是非常高的, 但是规则需要大量的专家制定, 并且不同领域的组词规则存在差异性, 因此很难进行大规模的规则概念筛选。基于统计的概念筛选方法适合处理大规模数据, 因为统计方法与概念本身的结构无关。该方法的缺点同样明显, 计算量非常大, 对机器的要求比较高; 错误率也比较高, 需要对结果进行优化。因此, 研究者会同时混合使用两种方法。文献[9]同时运用《汉语主题词表》和关键词词频分布两种方法获取通用概念。同样, 本文利用这两种概念筛选方法优势互补, 扬长避短, 提出一种领域概念的三层递进筛选方法, 从而提高数据处理规模并降低错误率。
领域概念三层递进筛选流程分为两部分, 如图1所示:
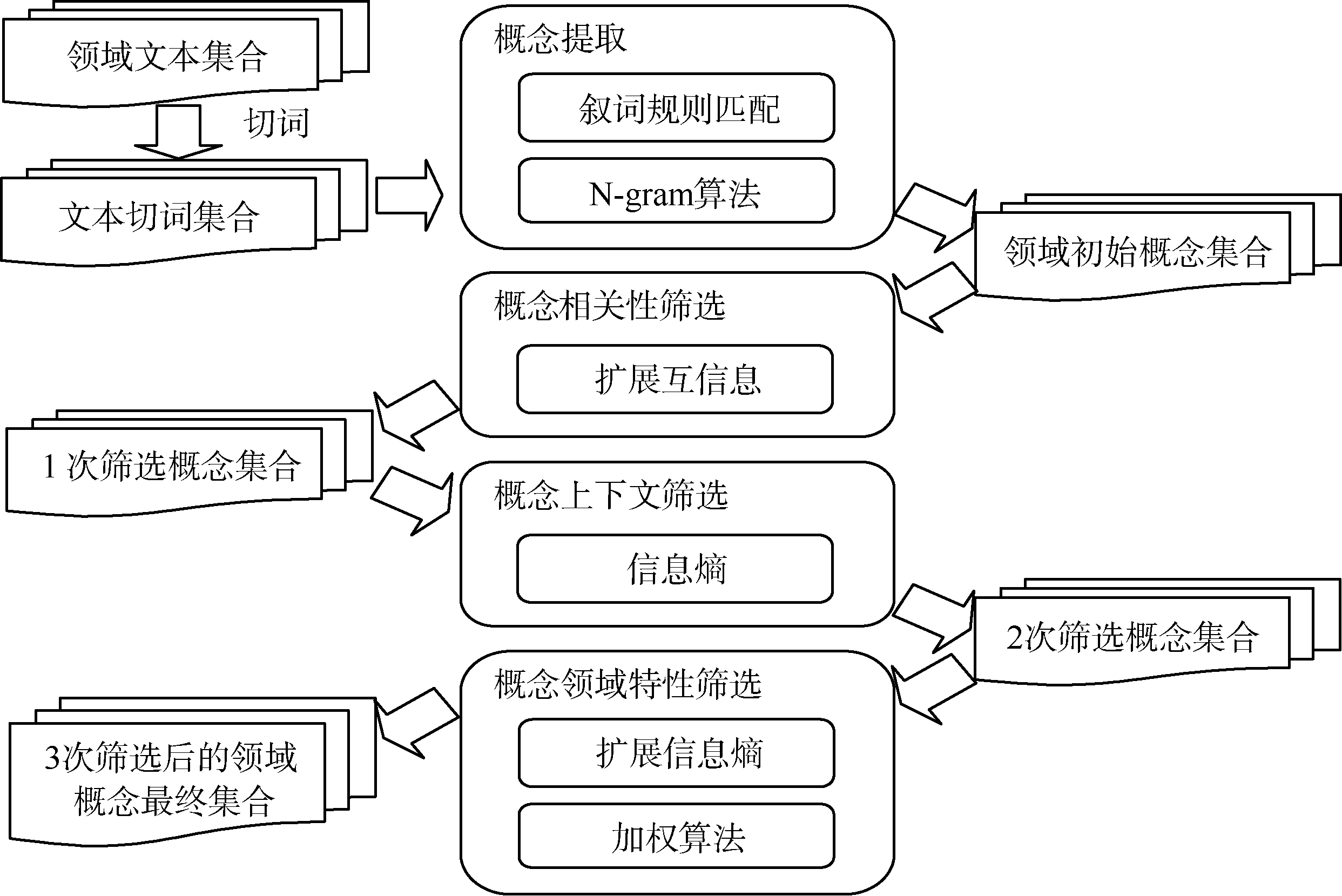 | 图1 领域概念三层递进筛选的总体流程 |
(1) 领域概念提取。领域概念提取的目的是从领域文本集合中提取领域初始概念。本部分可以细分为文本切词和概念提取。文本切词利用切词工具对领域文本进行切词和词性标注。概念提取利用叙词规则匹配和N-gram算法同时对切词后的文本提取概念。
(2) 领域概念筛选。领域概念筛选的目的是在领域初始概念的基础上对其进行过滤, 去掉提取错误的概念, 保留正确的概念。本部分采用三层过滤方法分别从概念相关性、概念上下文和概念的领域特性三个递进层面由浅入深地对领域概念进行三层递进过滤, 最终高效地获取领域概念。
本文以2012年《北大中文核心期刊目录》为期刊选取的参照标准。在《北大中文核心期刊目录》中找到有关“ 测绘学” 的8种期刊: 测绘学报、武汉大学学报(信息科学版)、测绘科学、测绘通报、大地测量与地球动力学、测绘学学报、测绘科学技术学报、地球信息科学学报。选取中国科学引文数据库(CSCD)作为论文题录下载数据库。之所以选择CSCD, 是因为它是专门针对自然科学文献检索的数据库, 数据非常全面。另一方面, CSCD还存储了每篇文献的被引频次, 以这些题录信息为基础, 利用被引频次对文献进行过滤。本文的检索策略是“ SO=(期刊名称)” , SO表示出版物名称。考虑到被引的时滞问题, 选择检索时间为“ 2001年-2010年” 。共检索到8 814篇文献, 选择被引次数大于等于2的文献作为数据提取对象, 共有2 300篇文献。另外, 在概念提取阶段使用叙词组词规则匹配的方法, 该方法依托于武汉大学图书馆提供的《测绘学叙词表》电子版。
(1) 文本切词和词性标注
文本切词是领域概念提取的基础和前提, 但这并不是本文研究的重点。目前存在很多非常成熟的中文分词软件。本文利用中国科学院计算技术研究所开发的ICTCLAS 2011[10]进行文本的切词。ICTCLAS 2011为各种主流编程语言都提供了函数调用接口, 如: C、C++、Java等。本研究的系统基于Java开发, 因此只需要实现Java接口就能够充分调用ICTCLAS 2011中的切词方法。具体而言, 通过调用ICTCLAS 2011中的切词方法, 运用该方法遍历《测绘学叙词表》中的所有叙词, 并对其进行切词和词性标注, 统计出现频率最高的前15组叙词组词词性, 如表1所示:
| 表1 出现频率排名前15的叙词组词词性规则 |
表1列出了出现频率排名前15的叙词组词规则。可以看出, 由2-3个通用词汇组合而成的领域概念是最常见的, “ 名词+名词” , “ 名词+动名词” , “ 名词+动词” 的出现频率最高, 超过100次。三种组词规则与其他规则差距较大。出现频率大于等于10的组词规则共有37组, 由2个、3个通用词汇组成的领域概念分别有15个和17个, 占整个规则的80%以上。由1个“ 名词” 、“ 动词” 组成叙词的出现频率也非常高。
(2) 基于叙词组词规则匹配的概念提取
以测绘学为例进行实验分析。利用《测绘学叙词表》进行叙词组词规则的匹配。从《测绘学叙词表》中所得的词汇总数是2 981个, 对所有词汇分词后统计, 结果如表2所示:
| 表2 《测绘学叙词表》叙词组词规则统计 |
从统计结果来看, 叙词表的领域专业词汇与通用词汇在长度上有着明显区别。4字词、5字词和6字词都比2字词多, 4字词尤为明显。而通用词汇主要由2字词和3字词构成, 以2字词居多。为此, 本文假设领域词汇存在与通用词汇不同的组词规则, 并且叙词组词规则能够代表该领域的组词规则。在此假设上, 本文利用叙词组词规则匹配的方法提取概念。
在表3中, “ 矿产资源勘察” 和“ 方差分量估计” 等词的提取效果比较好, 也存在“ 导航主体” 和“ 景观类型” 等不理想的结果。由三个通用词汇组成概念的提取效果比由两个通用词汇组成概念的提取效果好很多, 因为条件约束更强。而由两个通用词汇组成的概念中, 出现错误的情况主要集中在经常出现的规则。表3中出现错误最多的是“ 名词+名词” 的规则。从表1中不难看出, 名词出现的概率最高, 因此两个名词同时出现的概率也相应提高, 错误概念容易一并被提取出来。基于1个叙词组词规则的概念提取约束更少, 效果也更差, 同样以名词居多。在分词中这类名词切分得过细, 而出现的频率也高, 出错率同样较高。例如: 在叙词表中包含“ 地震” 一词的词汇非常多, 有“ 地震图” 和“ 地震测量” 等, 因此当“ 地震” 一词被单独切分出来后, 出现的频率自然会非常高。单纯基于叙词组词规则和N-gram算法提取的概率效果并不理想, 需要对结果进一步筛选, 去掉错误的概念。
| 表3 基于叙词组词规则的概念提取部分结果 |
(3) 基于N-gram算法的概念提取
作为概念提取的经典算法, N-gram凭借无须字典支持、适应任何数据等优势受到研究者的青睐。N-gram比规则提取的词汇过滤量小, 能够获取无法匹配规则的词汇[11]。叙词组词规则以2词、3词和4词居多, 因此本文也只计算2-gram、3-gram和4-gram。N-gram算法是常用算法, 在此不再对算法的具体步骤做详细介绍。
领域概念通常都是由多个通用词汇组成的。利用规则和N-gram算法很可能将两个碰巧一起出现的通
用词汇当作领域概念提取出来。为了避免这种情况, 需要对两个一起出现的通用词汇进行判断和衡量, 检验通用词汇之间存在多大的相关性。本文采用互信息计算概念的相关性。互信息是一种定量衡量信息相关性的方法。计算两个信息源的互信息, 如果互信息的值越大, 则两个信息源的相关性越高。相反, 如果它们的互信息越小, 则相关性越低[12]。当互信息应用到文本中的信息时, 就直接映射到文本中具体的字符串, 也就是词汇, 用以衡量两个词汇的相关性。如果两个通用词汇组成的词是一个真正的领域词汇, 则这两个词汇的互信息应该非常大, 否则这个领域词汇不成立。
利用互信息(Mutual Information, MI)衡量两个词汇的相关性, 词汇分别用 W1和W2表示。利用P(X)表示一个词汇出现的概率, 则有:
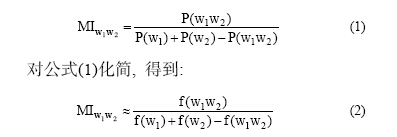
公式(2)只能计算两个词汇的互信息。领域概念大部分是由2个通用词汇组成的, 但是也存在3个、4个的情况。因此, 需要对公式(2)进行扩展, 使其能够计算多词的互信息, 从而能够更好地解决领域概念互信息的问题。根据叙词组词的特征统计发现, 由2个、3个和4个通用词汇组成的领域概念是最常见的。下面根据两个词汇的互信息数学模型推导出3个、4个词汇的互信息数学模型。从公式(2)中可以得到, 计算2个词汇之间的互信息, 其数学模型是一个分式, 其中分子是词汇共同出现的部分, 即交集; 而分母是两个词汇的并集。根据这个思想, 3个、4个词汇的互信息公式如下:
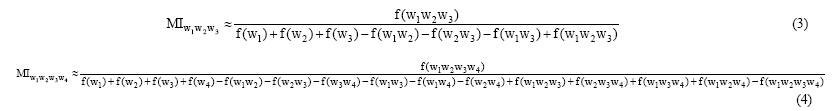
2个、3个、4个通用词汇出现的概率依次递减, 如果使用同一个互信息阈值筛选, 可能3个、4个通用词汇的互信息值都达不到要求。通过反复实验, 通过加权的方法调节3个、4个通用词汇的互信息阈值。
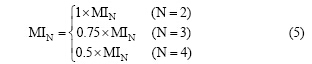
其中, N表示通用词汇的数量。通过反复测试, 发现当2词、3词、4词互信息值分别取0.5、0.375、0.25时, 结果最佳。
如表4所示, 概念相关性筛选通过互信息把“ 景观类型” 等明显错误的概念筛选掉。需要注意的是“ 黑潮水” 等概念互信息值虽然大于阈值, 但这个概念只在一篇文本中出现。一篇文章集中讨论一个问题时, 会频繁使用一类词, 就会出现以上情况。仅在一篇或者几篇文章里出现的频率词汇不一定是本领域词汇, 还需要考虑概念的领域分布特点。
| 表4 概念相关性筛选结果 |
一个概念能够出现在一篇文献中, 必定有它存在的必要性。概念与邻近词汇必定存在某种联系, 这种联系使得概念和邻近词汇共同构成了一句话, 从而能够完整地表达某种意思, 传达信息。从这个角度出发, 本文认为可以从概念的邻近词汇考虑, 计算出邻近词汇出现的数量和频率, 判断概念与邻近词汇的紧密程度。如果邻近词汇出现的数量越多, 频率越高, 说明概念与邻近词汇的紧密程度低, 概念成为独立词的可能性越大。一个概念的邻近词汇有很多, 并且不同词汇出现的频率也不一样。为了便于定量化计算, 本文引入信息熵。信息熵是用来衡量信息价值的一个单位。信息熵越大, 能够获取的信息量就越大。相反, 信息熵越小, 能够获取的信息量就越小。对信息熵的作用进行延伸, 如果邻近词汇的数量越多, 频率越高, 说明概念的信息量越大, 信息熵越大, 概念能够与越多的邻近词汇组合表达完整语义, 因此成为独立词的可能性越大。反之亦然。信息熵的计算公式[13]如下:
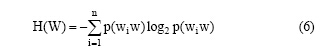
其中, H(W)表示邻近词汇集合的信息熵总和, 邻近词汇有左右之分, 可以分别计算左右邻近词汇的信息熵, 分别进行比较。 P(WiW)表示概念W与邻近词汇Wi出现的概率。
系统计算左、右相邻数量为4的词汇信息熵。信息熵细分为左信息熵和右信息熵。通过反复测试, 发现当互信息值取0.4, 左信息熵取3.5, 右信息熵取4时, 结果最佳。
概念上下文筛选主要针对基于N-gram算法概念提取的结果进行筛选过滤, 如表5所示:
| 表5 概念上下文筛选结果 |
“ 圆环段” 、“ 单历元” 等组词规则不常见的概念被互信息和信息熵方法筛选出来, 较高的信息熵值说明这些词非常稳定地出现在文章中, 能与其他许多词配合使用, 表达各种含义。“ 网点面积” 的互信息大于阈值(0.4), 但是左、右信息熵均小于阈值(3.5、4), 最终被过滤掉。
有些领域概念有可能只在一篇或者几篇文献中出现几次, 而有些领域概念则可能在大部分文献中经常出现, 这两种领域概念对于领域知识表达的贡献率是不一样的。当一个概念在该领域的大部分文献都经常出现时, 说明其对于领域的贡献非常大, 它提供的信息非常重要, 应该是该领域的核心词汇。
虽然信息熵在一定程度上能反映概念的领域核心度, 但是利用信息熵计算的核心度也存在一些问题。一些均匀分布在整个领域但出现频率非常低的概念, 其信息熵也非常高。这些概念虽然对领域的知识表达起到一定的作用, 但还没有达到核心的地位。因此需要把这些概念剔除。根据以上问题本文在信息熵的基础上加以改进, 加入了平均值参数。如果概念的平均值越高, 并且分布越均匀, 说明其领域核心度越高, 成为领域概念的可能性越高。扩展信息熵公式如下:
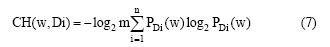
其中, CH(W, Di)表示概念W在领域Di的核心程度。 PDi(W)表示概念W在领域Di中出现的概率。 CH(W, Di)值越大, 表示概念W处在领域Di越核心的位置。m 表示概念w在整个领域文本集中出现频次的平均值, 求对数是为了减少平均值对于整个数学模型的影响。
在一篇文献中, 出现在标题、关键词、摘要和全文的概念对于文献的重要程度是不一样的。出现在标题、关键词、摘要和全文的概率是依次递减的, 其重要程度也是依次递减的。通过反复测试, 设概念出现在标题中权重为6, 出现在关键词中权重为5, 出现在摘要中权重为3, 出现在全文中权重为1, 得到加权公式如下:
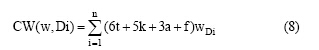
其中, CW(w, Di)表示概念W在领域Di的核心程度。t、k、 a 和f分别表示一篇文献里的标题(Title)、关键词(Keywords)、摘要(Abstract)和全文(Full Text)。
将扩展信息熵和权重计算的结果进行加权求和, 得到最终的概念核心度, 公式如下:
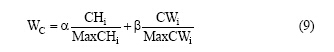
其中, WC表示词汇的最终概念核心度, 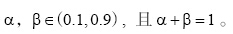 通过反复测试, 确定
通过反复测试, 确定 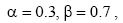 , 概念核心度的阈值为0.3。
, 概念核心度的阈值为0.3。
如表6所示, “ 小波变换” 、“ 空间分辨率” 和“ 地球动力学” 等词的概念核心度非常高, 说明它们不仅在正文中经常出现, 还出现在文献标题或关键词等关键位置。相反, “ 平滑系数” 和“ 二阶微分方程” 等词的概念核心度相对偏低, 说明它们仅在全文中偶尔出现, 并且没有出现在标题等关键位置, 领域核心度偏低。
| 表6 概念领域性筛选结果 |
本文使用横向和纵向两种方式比较三层概念筛选方法的效率: 横向比较是将其他研究者提出的筛选方法与本文提出的筛选方法进行比较; 纵向比较是将本文的一层、两层和三层筛选方法进行比较, 使用准确率、召回率和F值三个指标比较方法的效果。准确率是指筛选出的正确的概念数量与筛选出的所有概念数量的比率, 召回率是指筛选出的概念数量与所有文献中概念数量的比率, F值是指准确率和召回率的调和平均值。
如表7所示, 样本1、样本2的方法分别来自文献[14]和文献[15]。样本3、样本4、样本5为本文依次采用的概念相关性、上下文和领域性方法累积计算的结果。随着筛选方法的增加, 准确率上升, 召回率下降, 准确率的提高是以牺牲召回率为代价的。样本3、4、5随着筛选种类的增加, F值稳步提升, 并且3种方法均高于样本1和2, 其中样本5的F值最高, 说明本文的方法在一定程度上提高了文本领域概念筛选的效果。
| 表7 概念筛选方法结果比较 |
领域概念的提取是学科知识概念化、组织化、可视化、应用化的重要基础工作。然而概念提取方法的准确率和召回率不够理想。本文尝试从数据源和提取方法两方面入手, 利用叙词表的组词规则和N-gram算法共同提取概念; 利用概念相关性、上下文和领域性以点到面三层递进的方式依次对提取的概念进行过滤筛选; 以测绘学领域期刊的文献对提取方法进行实验检验。实验结果证明, 三层递进的概念筛选方法能够提高概念筛选的精度。概念筛选除了以上步骤外, 还需要处理同义词问题, 本文主要讨论如何筛选出词汇, 没有过多讨论如何筛选同义词, 后续的研究将利用相似度算法对同义词进行筛选。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|