
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
《红楼梦》词和N元文法分析*
[肖天久 , 刘颖]
, 刘颖]
, 刘颖]
|
|


肖天久: 进行实验, 分析数据, 起草论文; 刘颖: 提出研究思路, 设计研究方案, 论文最终版本修订。
[Objective] Research on the relationship between the first 80 chapters and the last 40 chapters of “A Dream of Red Mansions”. [Methods] Combined quantitative with qualitative method, compare the first 40 chapters, the middle 40 chapters and last 40 chapters with each other to calculate the ratios of the unique words of every part. Clustering is conducted respectively by utilizing the function words, N-gram model of words and part-of-speech, all content words and the word length, compute the similarities among the first 40 chapters, the middle 40 chapters and last 40 chapters according to high-frequency words. [Results] There are differences between the first 80 chapters and the last 40 chapters. There are less long words in the first 80 chapters and it is more readable and coherent than the last 40 chapters. The first 80 chapters pay more attention to description of details, while the last 40 chapters focus more on the description of actions and scenes. [Limitations] Only consider words and N-gram models, semantic and pragmatic features are not utilized. [Conclusions] The author of the first 80 chapters and the author of the last 40 chapters are not the same according to these features.
《红楼梦》在中国文学史上拥有重要地位。对其作者的争论, 尤其是后四十回作者的归属问题一直是《红楼梦》研究的重点。而前八十回与后四十回究竟是否为一人所作, 时至今日, 也依然是《红楼梦》研究中非常核心的问题, 学界的争论始终不断。
许多学者对《红楼梦》的风格进行了计量研究。陈大康运用特殊词语、虚词以及句长分布对《红楼梦》的前八十回与后四十回关系进行考察, 认为其并非一人所作[1]。张运良等利用向量空间模型, 以句类为特征, 使用K最近邻分类算法得出《红楼梦》前八十回与后四十回作者不同的结论[2]。韦博成通过《红楼梦》前八十回与后四十回中对海棠花关注的程度, 认为前八十回与后四十回差异巨大[3]。施建军以42个虚词作为特征向量, 使用SVM算法对《红楼梦》全一百二十回进行分类, 由此认为并非一人所作[4]。Li等比较了《红楼梦》前四十回、中四十回与后四十回的N元字串, 并利用名词的拓扑图和随机森林分类器得出前八十回与后四十回存在差异[5]。刘颖等系统地比较了《红楼梦》全一百二十回的用词、平均词长、词类、虚词和词长变化等情况, 并利用高频词、实词和虚词词类进行聚类, 发现前八十回与后四十回在所选特征上存在差异[6]。
对于其他作品风格的计量研究, 国内外学者从字符、词汇、句法和语义等层面进行了探索和研究。Zheng等利用字母字符、数字字符等字符层面的特征对网络文本的风格进行分析和研究[7]。Grieve则以词首、词尾中字母的频率和包含各个字母的单词频率作为特征[8]。Argamon等认为功能词最容易反映作者的风格, 并提出675个功能词[9]。为了克服词语作为特征所忽略的上下文信息, 研究者引入N元文法模型。Peng等建立了一个基于字符的N元文法模型, 研究希腊语、英语和汉语文本的风格[10]。Gamon利用词类的三元文法模型以及动词的时态、体态语义特征研究作品的计量风格[11]。王少康等选取了10位现代作家的作品, 利用点积相似度度量节奏特征矩阵之间的差异[12]。李惠等利用字的N元字串、词语搭配、词语重合以及主成分分析对郭敬明和庄羽的小说进行分析和比较, 得出郭敬明的《梦里花落知多少》抄袭庄羽的《圈里圈外》的结论[13]。
在前人研究的基础上, 本文以人民文学出版社2000年出版的《红楼梦》[14]为基础, 使用汉语词法分析系统ICTCLAS[15]对《红楼梦》整部小说进行分词和词性标注, 并在此基础上进行风格分析。除了利用传统的虚词作为特征外, 还提出了独有词的比例公式, 并将反映文本短语结构的词的N元文法和反映文本语法结构的词类的N元文法应用于《红楼梦》的研究中。同时利用实词词类和词长分布作为特征项分别进行K-means聚类。与前人主要以每回为单位进行比较不同, 本文利用虚词、文本的短语结构、文本的语法结构、实词词类以及词长分布等特征, 系统地比较了《红楼梦》每十回的异同。并详细地比较了《红楼梦》前四十回、中四十回和后四十回两两之间独有词比例的差异以及这三个部分的相似度。
笔者认为, 在一部小说中, 作者使用词语应该是一贯的、连续的, 因此, 对《红楼梦》而言, 前、中、后四十回的绝大部分词语也应该保持一致。设A, B分别为《红楼梦》两个部分词语的集合, A与B相比, A有B无的词语叫做A部分的独有词, 即A部分独有词=A-  。使用公式(1)计算A部分独有词所占比例Fd:
。使用公式(1)计算A部分独有词所占比例Fd:
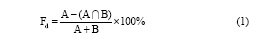
即A部分独有词的比例等于A部分独有词的数量与A、B两部分词语之和的百分比。
利用公式(1)先分别两两比较前、中、后四十回, 计算各自独有词所占比例; 再以前、中、后四十回分别为一个整体, 与余下的八十回比较, 计算各自独有词所占比例, 如图1所示:
 | 图1 《红楼梦》各部分独有词的比例 |
图1中, 横向为相互比较的两个部分各自独有词的比例, 如最后一行表示中四十回与前四十回相比较, 两部分独有词的比例分别为1.94%和2.01%。可以发现, 在将《红楼梦》分为前、中、后四十回三个部分两两比较时, 后四十回独有词的比例要小于前四十回和中四十回, 而中四十回与前四十回非常接近; 将前、中、后四十回两两组合成为八十回并与剩余的四十回相比较时, 前八十回独有词比例要高于后八十回与除中四十回外的其余八十回; 与之相对应, 后四十回独有词的比例要低于前四十回与中四十回。这反映出后四十回新出现词语较少, 并且前八十回使用而后四十回不再使用的词语较多; 而前八十回用词则相对比较连贯: 前四十回与中四十回相比, 独有词所占比例大致相当, 并且前四十回和中四十回分别与剩余的八十回相比, 独有词所占比例也相差不大。
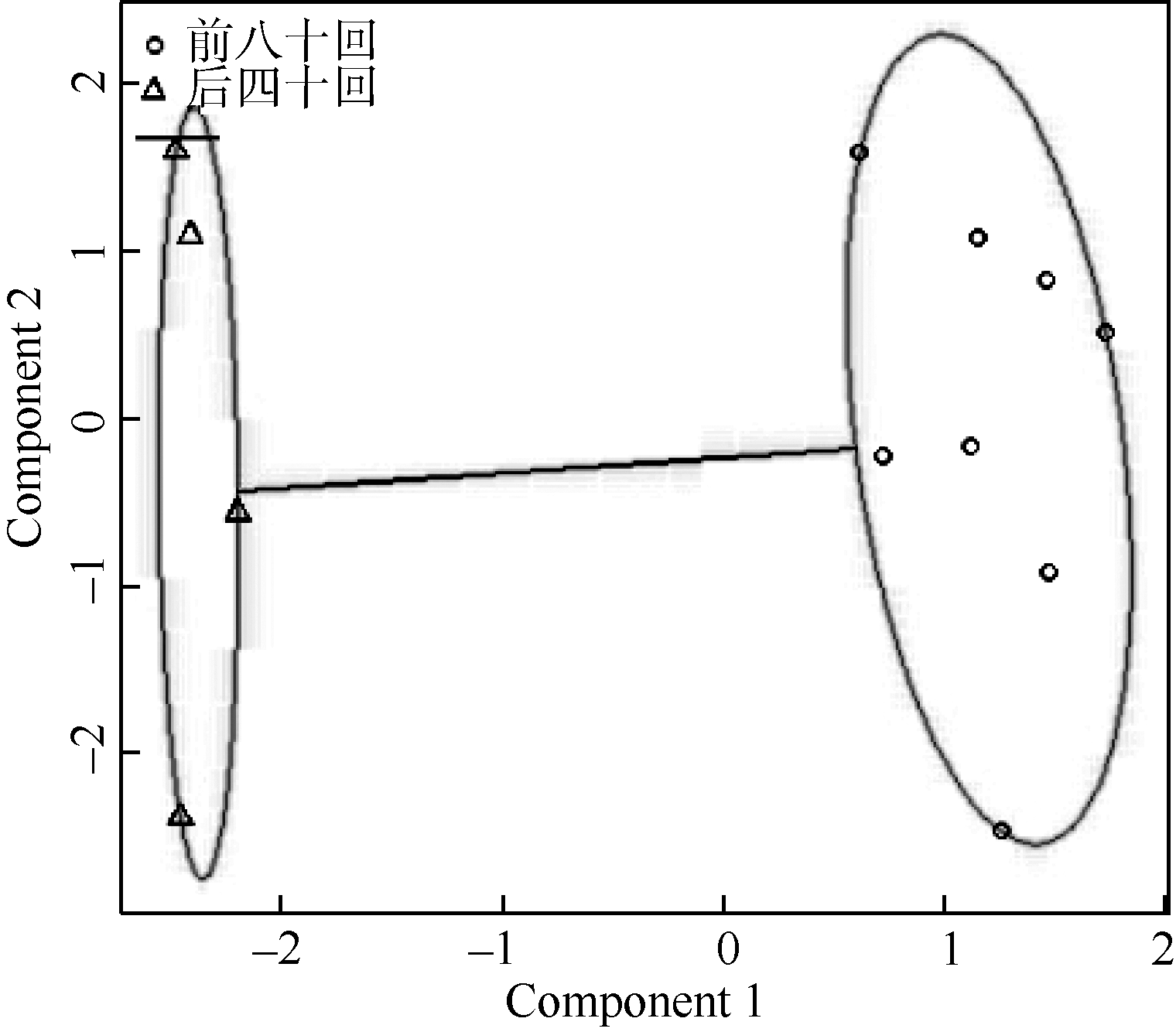
聚类是一种无指导的机器学习方法。文本聚类是聚类分析技术在文本处理领域的一种应用。其要求将众多文本按照内容的相似性(文本间的距离)分为若干类, 使得同一类的文本相似性尽可能高; 而不同类之间的差异尽可能大[16]。通过文本聚类, 可以很清楚地反映出不同类的文本在所选特征项上的总体差异。本文使用欧氏距离计算不同文本间的距离, 公式如下[16]:
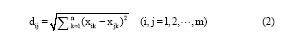
xik, xjk分别表示第i和第j个文本在第k维空间中的值。其计算的是在由n个特征构成的n维空间中任意两个文本 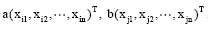 之间的距离。
之间的距离。
在进行聚类前, 需要对数据进行归一化处理, 将数据格式化, 使之在指定范围内(如[0, 1]), 避免某一维或几维数据对结果的影响过大, 同时保证数据的收敛性。本文使用公式(3)[17]对数据进行归一化处理:
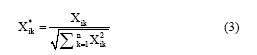
其中, 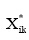 为第i个文本在第k维空间中的新值, 即归一化后的数据, Xik是第i个文本在第k维空间中的原始值,
为第i个文本在第k维空间中的新值, 即归一化后的数据, Xik是第i个文本在第k维空间中的原始值, 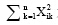 为样本在n维空间中所有值的平方和。
为样本在n维空间中所有值的平方和。
本文使用层次聚类与K-means两种聚类方法实现对文本中部分特征项的聚类。
层次聚类指按照一定层次进行聚类[16]。具体步骤如下:
(1) 将每个文本作为单独一类, 并计算文本间的距离, 将距离最小的两个文本聚为一类;
(2) 重新计算新生成的类与其他类的距离, 并继续进行归并;
(3) 如此往复, 直到所有的文本都聚成一个大类。
层次聚类既要度量文本与文本之间的距离, 又要度量类与类之间的距离。距离的远近与文本间的相似性是一种相反的关系, 距离越远, 相似性越小; 距离越近, 相似性越大。
在使用欧氏距离计算出任意两个文本相似性的基础上, 使用最大距离法度量类与类之间的距离, 即以两类文本之间的最大距离作为两类的距离。
(1) 基于虚词特征的文本聚类
虚词经常被认为是最能反映作者风格的特征项, 因为其与文本内容无关, 并且作者使用虚词往往是无意识的行为[9]。在《红楼梦》风格分析和作者判定中, 多以虚词作为特征项。区别于前人主要利用其对全一百二十回进行聚类或分类, 本文以虚词作为特征项, 以每十回为一个文本, 对整部小说进行聚类。共选择41个虚词, 分别为:
介词(10个): 被、从、于、因、在、向、以、比、与、往;
助词(6个): 之、者、或、的、得、过;
语气词(4个): 罢、呢、么、罢了;
副词(17个): 便、就、亦、未、很、也、别、更、且、还、必、皆、方、忽、只、不、偏;
连词(4个): 所以、因此、连、既。
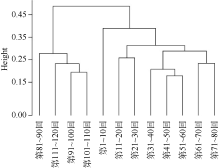
笔者首先对每十回中每个虚词使用的次数进行统计, 然后对统计数据进行归一化处理, 再对得到的结果进行层次聚类, 结果如图2所示。
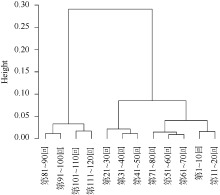
 | 图2 《红楼梦》虚词使用情况聚类 |
图2横轴为全部120回, 纵轴为任意两类(将每十回构成的文本看作最小的类)的欧氏距离, 如第51-60回与第61-70回的欧氏距离小于0.01, 这两类聚成的小类与第71-80回的距离约为0.01, 而前八十回与后四十回这两个大类之间的欧氏距离则约为0.10。可以看出, 第1-10回与第11-20回、第51-60回与第61-70回、第31-40回与第41-50回, 第81-90回与91-100回以及第101-110回与第111-120回之间的距离最近, 说明这些文本之间的相似性较高。《红楼梦》前八十回与后四十回之间的距离最远, 从而可以清楚地分为两类; 而在前八十回内部, 前四十回与中四十回是有混合的, 存在较高的相似性。从所选的41个虚词的整体使用情况来看, 前八十回与后四十回有着较大的差异。
(2) 基于词的N元文法模型的文本聚类
N元文法指由N个字、词或词类组成的序列[13]。对词的N元文法来说, 当N=1时, 为一元文法, 相当于词表, 表示文本中使用的所有词; 当N=2时, 为二元文法, 表示文本中邻接两个词的使用情况; 当N=3时, 为三元文法, 表示连续三个词在文本中的使用情况。二元文法和三元文法可以反映文本中短语结构情况。
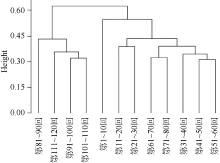
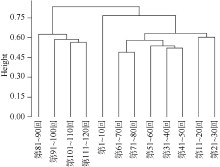
本文将词的N元文法应用到《红楼梦》的研究中, 利用词的二元和三元文法进行聚类, 分别统计词的二元和三元文法的前500个词序列在每十回中的出现次数, 并进行归一化处理, 分别进行层次聚类, 结果如图3和图4所示。
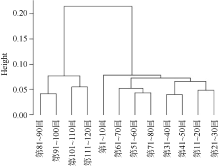
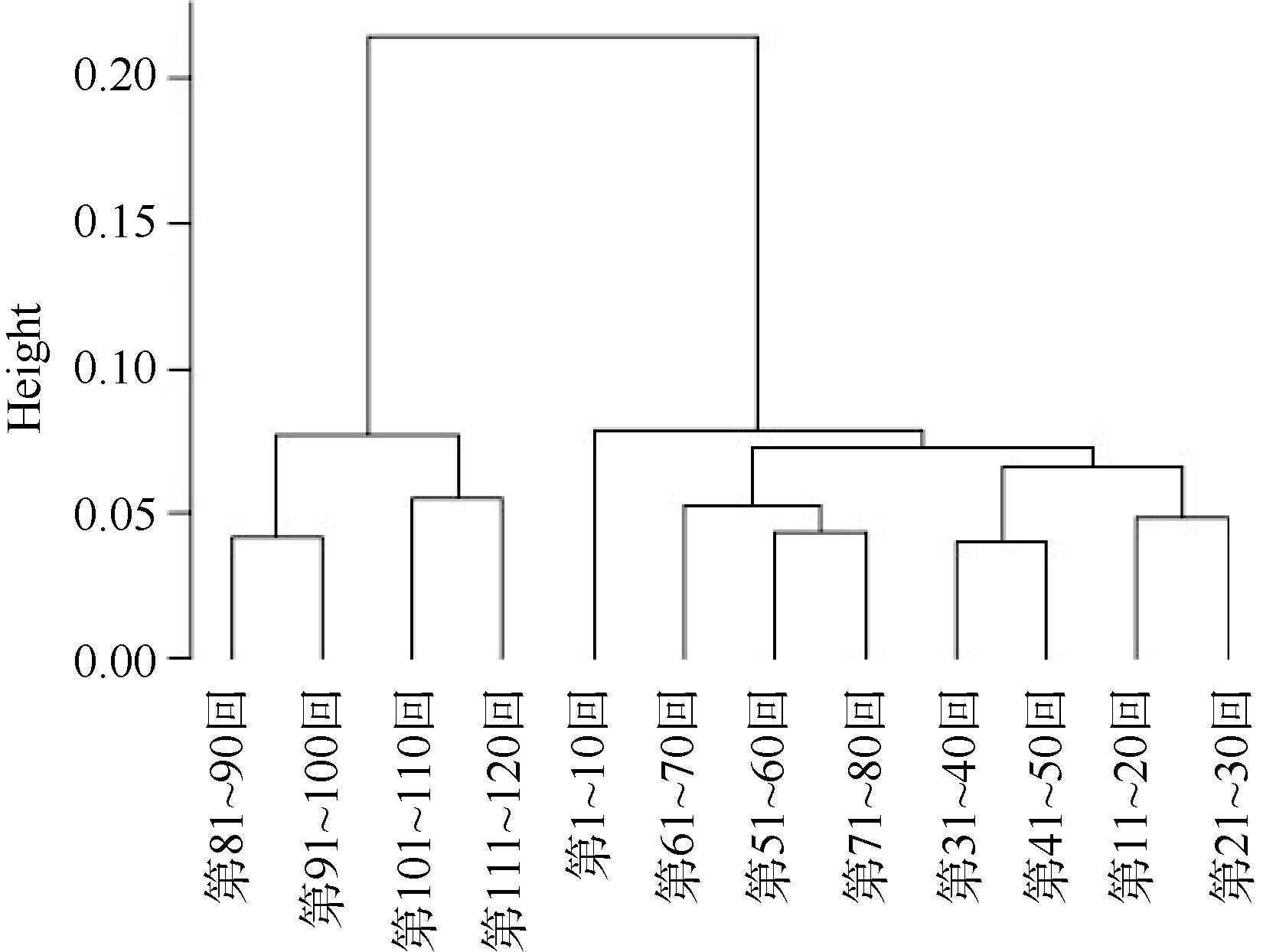 | 图3 《红楼梦》词的二元文法聚类 |
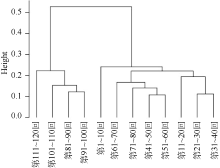
 | 图4 《红楼梦》词的三元文法聚类 |
图3、图4中, 横轴表示《红楼梦》的全一百二十回, 纵轴为每两类之间的欧氏距离。可以发现, 从词的二元和三元文法来看, 前八十回与后四十回的距离均较远, 相似性很低, 明显可以分为两个部分, 而前八十回内部与后四十回内部每两个文本间的距离较近, 相似性较高。由此可以认为, 从词的二元和三元文法来看, 前八十回与后四十回的差异非常显著。值得注意的是, 从词的二元到三元, 类与类之间的距离越来越大, 如第81-90回与第91-100回, 在二元文法中距离约为0.04, 而在三元文法中, 距离超过0.1; 前八十回与后四十回两个大类的距离在二元文法中超过0.2, 而在三元文法中超过0.5, 反映出随着词的元数增加, 类与类之间的相似性逐渐降低。
(3) 基于词类的N元文法模型聚类
词类的N元文法模型指以词类为单位的词类组合: 当N=1时, 为一元文法, 表示文中词类列表; 当N=2时, 为二元文法, 表示邻接两种词类在文中使用的情况; 当 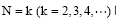 时, 表示连续k种词性在文中出现的情况, 反映的是文本的语法结构。
时, 表示连续k种词性在文中出现的情况, 反映的是文本的语法结构。
本文引入词类的N元文法, 利用词类的二元到五元文法进行聚类。分别统计词类二元、三元、四元、五元文法的前500个词类序列在每十回中出现次数, 对统计数据进行归一化处理, 并分别进行层次聚类, 得到结果如图5至图8所示。
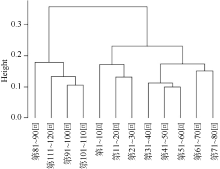
 | 图5 《红楼梦》词类二元文法聚类 |
 | 图6 《红楼梦》词类三元文法聚类 |
 | 图7 《红楼梦》词类四元文法聚类 |
 | 图8 《红楼梦》词类五元文法聚类 |
图5至图8中, 横坐标为《红楼梦》全一百二十回, 纵坐标为类与类之间的欧氏距离。可以看出, 从词类的二元到五元, 前八十回与后四十回距离均较远, 说明二者的相似性很低; 而前八十回内部距离则较近。由此可以认为, 从词类的二元到五元文法来说, 《红楼梦》前八十回与后四十回并不一致, 语法结构存在差异。值得注意的是, 从词类的三元到五元, 前十回距离其余七十回的距离都较远, 反映出前十回的语法结构与其他章回存在不同。同时, 从词类二元到五元, 类与类之间的欧氏距离越来越大, 反映出随着词类元数的增加, 不同文本的相似性逐渐降低。
K-means聚类是一种划分聚类。其基本思想是: 从文本中随机选择k个文本作为聚类中心, 并根据与中心的远近将其余文本划分为k类, 再重新计算每类的中心并作为新的聚类中心; 根据与中心的距离对所有文本重新分类; 一直迭代下去, 直到聚类中心不再改变。其最终目的是实现类内文本之间相似性最大, 而类与类之间的相似性最小[16]。
目前对于《红楼梦》的主流看法大多认为其有可能是由两位作者创作。因此, 本文将每十回作为一个样本, 确定两个聚类中心, 考察全一百二十回的自动聚类情况。同时, 采用欧氏距离计算文本与聚类中心之间的距离。
(1) 基于实词的文本聚类
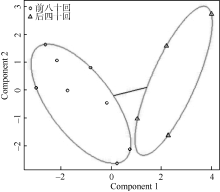
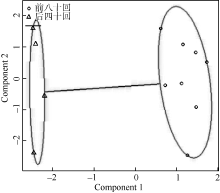
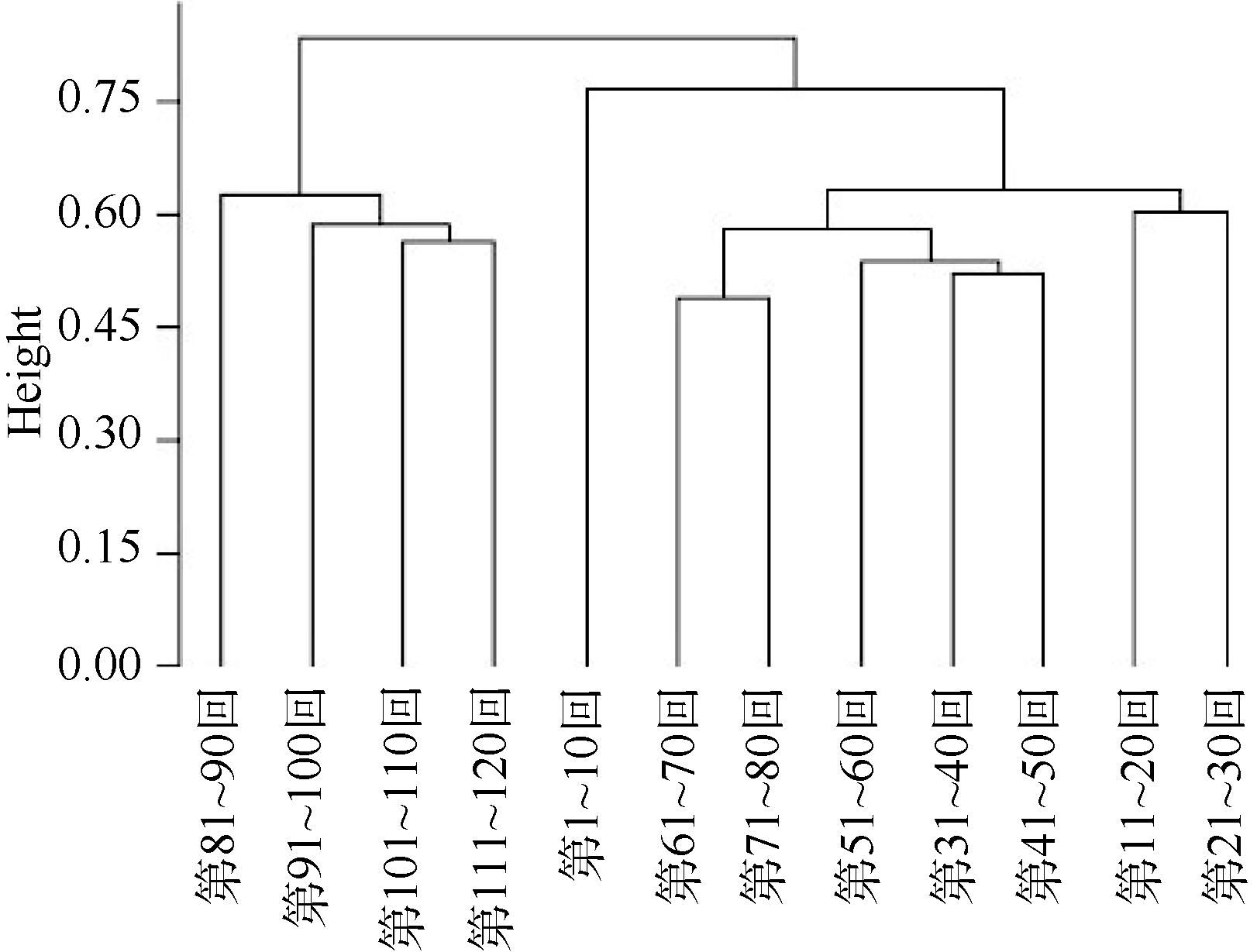
统计《红楼梦》中的全部实词— — 名词(n)、动词(v)、形容词(a)、代词(r)、数词(m)、量词(q)、方位词(f)、处所词(s)、时间词(t)、区别词(b)在每十回中的使用次数, 对其进行归一化处理, 对得到的结果进行K-means聚类, 如图9所示:
 | 图9 《红楼梦》实词使用聚类 |
图9中, 圆圈与三角形分别代表前八十回与后四十回, 椭圆表示不同的类。可以看出, 后四十回全部聚在一个椭圆之中, 而前八十回则聚在另外一个椭圆里, 二者并无混淆。可见, 从实词的使用上来看, 前八十回与后四十回是有差异的。事实上, 《红楼梦》全一百二十回以每十回为单位对实词的使用频率进行比较, 前八十回的全部章回中名词、动词、处所词的使用频率上均要低于后四十回, 在数词、量词的使用频率上均要高于后四十回; 前八十回的大部分章回中代词、形容词的使用频率上均要高于后四十回, 在时间词的使用频率上均要低于后四十回。在方位词与区别词上, 前八十回与后四十回的区别并不明显。可见, 前八十回更加注意细节的描写和刻画, 通过详细而具体的描写增强小说的真实性; 而后四十回则注重对动作和情景的描写。
(2) 基于词长分布的文本聚类
将《红楼梦》的词长分布应用于聚类分析中。对《红楼梦》每十回不同词长(即不同音节数)的词语进行统计, 并使用公式(3)对统计结果进行归一化处理, 再进行K-means聚类, 得到结果如图10所示。从图10可以看出, 前八十回聚在一个椭圆中, 而后四十回聚在另一个椭圆中, 二者并无混淆并且距离较远。可见, 在词长分布上, 二者的差异很大。事实上, 《红楼梦》前八十回一字词(只有一个音节的词)使用比例高于后四十回, 而二字词(两个音节的词)使用比例则低于后四十回, 并且平均词长也低于后四十回。反映出前八十回长词较少, 文本的复杂度较低, 可读性强; 而后四十回的长词相对较多, 文本复杂度较高, 可读性较弱。
 | 图10 《红楼梦》词长分布聚类 |
对《红楼梦》前四十回、中四十回、后四十回的相似性进行比较, 并以高频词作为比较的特征项。笔者认为高频词是反映内容和作者用词习惯的重要特征。统计《红楼梦》前四十回、中四十回、后四十回的前200个高频词, 然后分别使用夹角余弦、欧式距离利用高频词为特征对前、中、后四十回两两之间的相似性进行计算。
夹角余弦是利用所选特征构成向量空间, 并考察两个文本构成夹角的大小, 判定文本的相似程度: 余弦值越大, 夹角越小, 则文本也就越相似。设由n个特征构成的向量空间中的两个文本分别为:
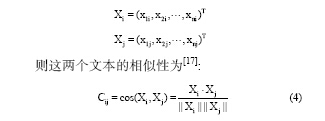
其中, “ · ” 表示向量点积, 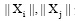 分别表示两个向量的长度。与夹角余弦不同, 利用欧式距离(公式(2))考察文本的相似性, 两个文本距离越大, 说明相似性越小; 反之, 距离越小, 则相似性越高。在计算之前, 笔者利用公式(3)对数据进行归一化处理, 计算前四十回、中四十回、后四十回的相似性, 结果如表1所示:
分别表示两个向量的长度。与夹角余弦不同, 利用欧式距离(公式(2))考察文本的相似性, 两个文本距离越大, 说明相似性越小; 反之, 距离越小, 则相似性越高。在计算之前, 笔者利用公式(3)对数据进行归一化处理, 计算前四十回、中四十回、后四十回的相似性, 结果如表1所示:
| 表1 前、中、后四十回两两之间的相似性 |
从夹角余弦值来看, 前四十回与中四十回的值为0.991, 而后四十回与前四十回、中四十回的值分别为0.978, 0.981; 而从欧式距离来看, 前四十回与中四十回的距离也更近一些, 而后四十回与前四十回、中四十回的距离要稍远一些, 说明后四十回与前、中四十回两两之间的距离都较近, 但前八十回的相似度更高一些。
对于《红楼梦》后四十回作者归属的判定, 是《红楼梦》的重要课题。本文在前人工作的基础上, 除选取虚词作为特征项外, 还引入独有词比例, 并将反映文本短语结构的词的N元文法以及反映文本语法结构的词类N元文法、实词词类、词长分布、高频词等特征也应用进来, 使用层次聚类、K-means聚类和文本相似性比较等方法对《红楼梦》整部小说风格进行研究, 并对前八十回与后四十回关系进行判定。
统计并计算了各部分独有词所占比例, 后四十回的独有词所占比例要低于前四十回与中四十回, 反映出后四十回新出现的词较少, 而前八十回在词语使用的连贯性上较高。利用选取的41个虚词、词的二到三元文法的前500个词序列和词类的二到五元文法的前500个词类序列对全部12个文本分别进行层次聚类, 发现前八十回与后四十回差异极大, 而前八十回内部则相似度很高, 并且词从二到三元、词类从二元到五元, 类与类之间的欧氏距离逐渐增大, 相似性降低: 反映出前八十回与后四十回的句子结构和语法结构的差异较大。对全部实词的整体使用以及词长分布情况进行K-means聚类, 发现前八十回与后四十回之间的距离较大, 属于不同的类。在此基础上, 利用前200个高频词对前、中、后四十回的相似度分别进行两两比较, 计算其夹角余弦和欧式距离, 证实前四十回与中四十回具有很高的相似性, 而前四十回与后四十回、中四十回与后四十回则差异较大。总之, 以上差异说明, 前八十回与后四十回很可能并非出自同一作者。
本文从词、词类、N元文法的角度对《红楼梦》前八十回与后四十回的关系进行考察, 下一步, 可以从语篇、语义的角度对《红楼梦》风格进行研究, 并在此基础上进一步判定后四十回作者的归属。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|