
{kind=link}
{kind=link}
一种基于邻近节点影响强度标签传播社区发现方法*
[刘郝霞1 , 彭商濂2  ]
]
]
|
|


刘郝霞: 提出研究思路, 设计研究方案, 分析数据, 论文撰写及最终版本修订; 彭商濂: 提出研究思路, 采集、清洗和分析数据, 进行实验验证。
[Objective] This paper aims to enhance quality and efficiency of community detection in recommandation system by controling propagation direction of labels. [Methods] A community detection algorithm via neighborhood node influence based label propagation is proposed to optimize label propagation paths and update nodes labels stably and effectively. [Results] The experimental analysis on artificial and real social network datasets verifies that updating and propagating labels based on neighborhood influlence can reduce labels updating space and time. [Limitations] The dataset used in this paper is not enough due to the restriction of the website, and the notion of neighborhood node influence needs to be generalized. [Conclusions] This study proposes a feasible solution to enhance community detection quality by reducing label propagation instability based on neighborhood influences.
随着移动互联网的广泛应用, 社交网络已成为人们日常生活中不可缺少的信息交换工具。在社交网络中, 社区是一种重要的结构。所谓社区是指社交网络中的节点被分为一些团组, 团组成员(节点)之间具有较强的联系, 而不同的团组之间的节点则具有稀疏的联系。
在大型复杂网络中进行社区发现 (Community Detection)具有重要的实际意义。在社会网络中, 社区信息显示了社区成员的兴趣、职业、地域、背景等特征。利用这些信息可以进行人物性格特征分析、就业推荐、好友推荐和精准广告营销。在引文网络中(如LinkedIn、DBLP), 用户根据搜索主题词、作者信息、内容、单位等搜索文章, 系统则可以按照用户的搜索词进行相关推荐, 这些推荐的基础就是社区发现理论。在生物化学网络中, 某一类型的功能单元可以看
成社区, 检测这些社区有助于理解网络的进化和发展, 例如可以进行食物链和人类基因分析等。此外, 社区发现还广泛应用于万维网、协同网络和通信网络分析。社区发现在计算机科学领域已经研究多年, 主要使用基于图划分(Graph Partition)的方法寻找团组, 这类方法一般认为是NP难问题, 其社区发现的效率不高, 且迭代次数较多。
文献[1-4]提出了寻找社交网络中社区的质量较好且合理的算法, 这些算法得到了大量的改进和扩展。主要可分为:
(1) 分割类算法[2]。该类算法递归地将网络中的边移除, 得到满足条件的社区。
(2) 聚集类算法[3, 4]。该类算法反复地将小的组归并为大的组。社区一般具有局部性, 而该类算法的计算往往是全局的, 因此复杂度较高。
(3) 模块度最大化(Modularity Maximization)算法[5, 6, 7, 8]。该类算法使用谱聚类(Spectral Clustering)、模拟退火算法或其他的优化方法对模块度(Modularity)进行建模。社区发现中检测到的社区质量由模块度来衡量[9]。例如, 如果一个网络的模块度在0.3-0.7之间, 则说明该网络具有很强的社区结构。对于较大的社交网络, 寻找社区的算法复杂度为O(n2)(n为网络中节点的数目), 因此该类方法计算量非常巨大, 耗费时间较多。
Raghavan等[10]提出了基于标签传播的社区发现算法(Label Propagation Algorithm, LPA), 该算法的复杂度与网络的边的数目成线性关系。在稀疏网络中, 算法复杂度与网络节点数目成线性关系。LPA算法在每次的迭代过程中, 节点的标签更新为其临近节点中标签出现最多的标签。算法结束时, 具有相同标签的节点组成一个社区。LPA算法具有无参数、易于实现、执行迅速等特点, 得到了普遍的关注。文献[11]则采用启发式(Heuristic)的标签更新算法提高LPA的效率, 配合参数调整使得算法适用于不同规模的社交网络。尽管对LPA算法的改进取得了一定进展, 但LPA算法的标签传播更新的随机性未得到较好解决, 算法的健壮性在一定程度上也被随机性破坏, 社区结构的稳定性也不能得到保障。为了对LPA的标签更新算法进行改进, 减少随机标签传播的影响, 本文利用临近节点的强度关系限定标签更新的范围。
LPA[10]算法的思想很简单: 为网络中的节点赋予唯一的标签, 确定节点标签的更新顺序, 按照公式(1)[10]更新每个节点的标签:
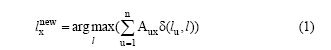
其中, A是网络的邻接矩阵, 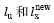 分别是节点x的原标签和新标签,
分别是节点x的原标签和新标签,  是一个布尔函数。节点的标签更新过程按照公式(1)重复进行, 直到满足某个收敛阈值, 算法停止, 具有相同标签的节点划归同一个社区。在LPA算法中, 节点的更新顺序是随机的。当两个或多个邻接节点的标签频率相同时, LPA算法随机选择其中的一个标签, 这种随机性的引入严重破坏了算法的健壮性和社区的稳定结构。
是一个布尔函数。节点的标签更新过程按照公式(1)重复进行, 直到满足某个收敛阈值, 算法停止, 具有相同标签的节点划归同一个社区。在LPA算法中, 节点的更新顺序是随机的。当两个或多个邻接节点的标签频率相同时, LPA算法随机选择其中的一个标签, 这种随机性的引入严重破坏了算法的健壮性和社区的稳定结构。
Barber等[11]提出了一种基于模块度的标签传播算法, 以避免LPA算法将所有节点划分到一个社区; 而Liu等[12]将基于模块度的LPA算法与贪心算法融合, 避免标签更新算法陷入局部极大值, 该算法为LPAm。本文中应用到的模块度计算公式如公式(2)所示[12]:
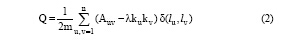
其中, Auv是网络图对应的邻接矩阵, m是网络中边的条数, kx是网络中节点x对应的度数, 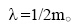 对于无向图, 其模块度计算如公式(3)所示[13]:
对于无向图, 其模块度计算如公式(3)所示[13]:
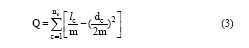
其中, nc是当前的社区数目, m是图中边的数目, 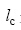 是社区C中所有内部边的条数, dc是社区C中所有顶点的度之和。
是社区C中所有内部边的条数, dc是社区C中所有顶点的度之和。
LPAm扩展了标记传播算法, 解决了LPA算法可能存在的平凡解问题。LPAm在模块度计算时也可能因局部最优解而陷入内部循环, 影响社区划分的进程, 导致社区识别的结果未能真正反映网络的结构。此外, LPAm算法对标签的更新次序比较敏感。
针对经典的LPA算法及相关的改进算法存在的不足, 鉴于网络中相互关联的节点呈团的特性, 且团中的节点在结构上具有相似性等特点, 通过引入临近节点的紧密度来衡量节点之间的关联关系, 并利用此关系优化标签传播的方向及标签更新的方法。下面给出网络中临近节点的强度模型的定义, 该模型是网络中节点间的链接强弱关系的度量[2, 14]。
定义1(结构相似度): 给定一个无向网络, 对于G中任意一对节点(u, v), 它们之间的结构相似度如下[3, 4]:

其中, 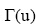 是节点u的临近节点的集合, W(u, x)是节点u和节点x之间边的权重。如果G是无权图, 则公式(4)可以简化为[4]:
是节点u的临近节点的集合, W(u, x)是节点u和节点x之间边的权重。如果G是无权图, 则公式(4)可以简化为[4]:

针对LPA算法存在的问题, 在结构相似度的基础上, 提出了邻接紧密度公式。
定义2(邻接紧密度): 对于G中任意一对节点(u, v), 它们之间的邻接紧密度定义为:
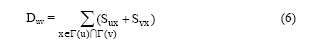
定义2表明, 如果节点u和节点v具有共同的邻接节点, 则这些邻接节点的结构相似度之和就是u和v的邻接紧密度。邻接紧密度从节点周围的结构相似点的维度度量了两个节点的紧密关系。将邻接紧密度引入到模块度约束的标签传播过程中, 以提高标签传播的健壮性。公式(1)是基于邻接矩阵的标签更新公式, 引入邻接紧密度计算, 可得公式(7):
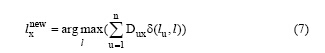
下面引入目标函数H。在标签传播过程中, 对目标函数H实现最大化, 即增加相同标签的顶点之间边的条数。目标函数如公式(8)所示[15]:
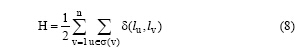
在公式(8)中引入定义2的邻接紧密度计算公式, 得到:
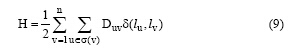
在对一个节点的标签进行更新时, 目标函数H的大小随之改变, 则有:
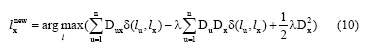
通过邻接紧密度的计算和目标函数优化上判断标签的传播方向, 可以减少标签传播的随机性, 使得社区检测的结果更加具有内部结构紧密性。
将邻接紧密度模型结合模块度计算应用在标签传播算法中, 可以提高社区发现的准确率。在文献[10]中进行了大量实验, 结果表明经过5次迭代, 95%以上的节点被划分到正确的社区。因此, 通过设置阈值条件, 判断标签传播过程是否收敛, 可以避免效率低下的循环迭代, 缩短社区发现的时间。
本文提出的DLPA (Neighborhood Density based Label Propagation Algorithm)算法的主要思想是: 计算社区中节点之间的邻接紧密度, 标签的更新依据为该节点周边邻接的紧密度最大的社区的标签。根据网络中节点的当前标签所在的社区及邻接节点的紧密度关系更新标签; 根据节点标签信息重新划分社区边界, 合并两个模块度提升最大的社区, 计算社区模块度的变化, 如果网络中模块度的变化大于某个阈值, 则继续进行节点的邻接紧密度计算并重新进行标签更新, 直至社区的模块度变化小于设定的阈值, 算法停止。为与文献[16]中的算法进行对比, 在DLPA算法中设置节点标签更新的迭代次数为n (n可以根据网络的特点进行设置, 本文设定为5)和稳定节点比例参数[16]。DLPA的算法描述如下所示:
输入: < V, E>
输出: < ei, Label(ei), C(ei)>
For each v in V
Label(v)=L1; //赋予每个节点唯一标记
End For
p0=0.99; //设置初始节点稳定比例参数
While i=1 & & i< 5 do
For each v in V
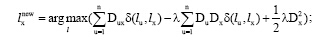
If i< 5 & & p> p0 Then
结束标签更新循环;
End For
End While
While True //计算模块度, 合并社区
For each Ct1, t2 do
计算 Δ Q=Max(Δ Qt1t2);
If Δ Q> 0 Then
合并社区Ct1和Ct2;
Else 结束循环
End For
End While
在DLPA算法中, 模块度最大的计算方法是一种基于贪婪思想的算法。算法过程如下:
(1) 将网络按照单节点分为n个社区;
(2) 对所有可能的社区对, 计算模块度的增量(减量)Δ Q;
(3) 将具有最大模块度增量的社区合并;
(4) 重复步骤(2)和步骤(3), 直到所有社区合并为一个社区;
(5) 切边操作。在社区的层次聚类图中, 从使得模块度Q达到最大值的一层进行边的切割, 得到网络的社区划分。
基于模块度的社区合并及划分如图1所示, 建立各个节点的模块度矩阵, 将模块度的计算转换为基于矩阵计算的最大化问题, 实质上是关于模块度矩阵的特征向量的求取问题; 根据特征向量进行K-means聚类, 根据最大的模块度(最大特征值), 得到在社区的层次聚类树上的一个划分, 即边的切割操作。
 | 图1 基于模块度的社区合并及划分 |
(注: (c)是模块度最优化对应的特征向量社区的划分使用了K-means聚类处理, 相关图引用自文献[17]。)
DLPA算法由标签传播更新和模块度计算两部分构成。在标签传播过程中, 迭代是线性的, 即每次都扫描了节点列表中的所有节点, 其时间复杂度为O(m), m为网络中节点的数目。假设DLPA算法中的迭代次数是n, 则标签更新的时间复杂度为O(m× n)。
在模块度计算过程中, 对标签传播过程中的小于某个模块度的社区进行模块度的增量计算, 需要搜索网络中的所有边, 时间复杂度为O(|E|), |E|为网络中边的数目; 合并当前社区中能够最大程度提高模块度的两个小社区, 计算社区与其他社区的模块度增量Δ Q, 时间复杂度为社区O(|E|), |C|为网络中当前迭代周期内社区的数目, 最坏情况下为网络中节点数n; 社区的合并次数最多为O(log|E|)次[15], |E|为网络中边的数目。模块度增量计算过程的时间复杂度为O(|C|× log|E|)[16]。
综上, DLPA的算法时间复杂度为O(|C|× log|E|)。另外几种算法: LPA、LHLC和LPAm时间复杂度为: O(m× n)[9, 10, 13], 其中k为迭代次数, m为网络中节点的数目。LPAm+的时间复杂度为: O(m× log2|E|)[12], m为网络中节点的数目, |E|为网络中边的数目。当网络中社区结构明显时, 本文算法的复杂度较低。
对DLPA算法进行实现并在人工数据集和真实网络数据集上进行测试。算法采用C++实现, 在Visual Studio 2008环境下编译, 硬件配置为: i5-2400M 2.3GHz CPU, 4GB内存。
为与文献[16]中的MLPA算法进行对比, 本文采用Lancichinetti生成节点数分别为1 000、10 000的人工网络, 网络的混合系数设置为0.1-0.8, 间隔为0.05。
此外, 本文算法也在真实网络数据上进行了测试。第一个数据集是Political Books (http://networkdata.ics.uci.edu/data.php?id=8)[17], 是亚马逊上的美国
政治书的销售情况网络, 该网络是一个无权无向图, 有105个节点, 441条边, 节点代表一本美国政治相关图书, 边代表被购买者频繁一同购买的图书。该网络被分成“ 自由派” 、“ 保守派” 和“ 中间派” 三个社区结构。第二个数据集是NCAA College Football (http://networkdata.ics.uci.edu/data.php?id=5)[2], 该网络是美国大学足球赛社交网络, 有115个节点, 1 232条边, 节点代表足球队, 边代表两个球队在2000年常规赛期间打过比赛, 球队属于12个社区。
社区质量的评价有多种标准, 本文采用规范化交互信息(Normalized Mutual Information, NMI)和 ARI (Adjusted Rand Index)。NMI的取值范围为[0, 1], NMI值越大, 社区的划分结果越接近真实情况。NMI定义如下[16]:
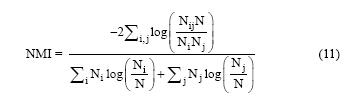
其中, Nij是类簇Ci和Cj的公共节点数, Ni是混合矩阵N第i行之和, Nj是混合矩阵N中第j列之和。
ARI用来评价社区聚类的效果, 其定义如公式(12)所示[14]:
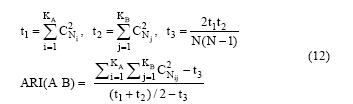
其中, A和B是数据集的两个划分, 分别有KA和KB个簇(社区类别); Nij表示在划分A的第i个簇中的数据同时也在划分B的第j个簇中数据的数量; Ni和Nj分别表示A中第i个簇和B中第j个簇的数据的数量。从ARI的定义可以看到, ARI (A B) 越接近于0, 则它们之间的关系越独立; 如果 ARI (A B) 越接近于1, 则两个划分的关系越紧密。ARI可以用来评价基于邻接紧密度的社区发现算法的效率。
对于人工网络和真实网络应用算法DLPA、MLPA[16]、LHLC[18]、LPAm[11]和LPAm+[14]进行社区结构划分, 计算社区划分准确率, 并对结果进行分析。
(1) 人工数据集
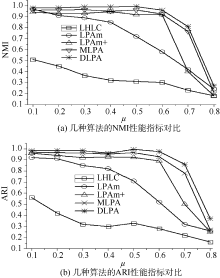
将本文算法和另外4种算法在人工生成的网络上进行测试, 对比这些算法的社区发现稳定性。算法在人工网络上运行多次, 网络的规模设置相同(1 000/ 10 000)。5种算法的平均准确率曲线如图2所示(实验次数为10次, 节点数为1 000, 节点的平均度为5):
 | 图2 社区划分准确率曲线 |
从图2可以看出, 在相同网络规模、不同混合系数情况下, 5种算法的划分准确率都随着混合系数的上升而下降。当混合系数小于0.7时, DLPA算法的NMI值始终大于0.8。ARI值也类似, 此处不再多述。
为了测试算法在大规模网络上的可扩展性, 对几种算法在网络节点数为10 000的人工数据集上进行测试, 由于LPAm和LPAm+不适合大规模网络的社区发现, 故此次测试主要针对LHLC、MLPA和DLPA, 结果如表1所示:
| 表1 几种算法在节点10 000、不同混合系数的 人工网络上的准确率(NMI) |
从表1可以看到, LHLC、MLPA和DLPA三种算法的NMI在不同混合系数时, 变化比较平稳。三种算法的ARI值趋势也类似, DLPA算法在社区发现准确率方面较好。
(2) 真实数据集
为了对比几种算法在真实数据集上的性能, 对两个网络数据进行测试。对于Political Books网络和College Football网络, 几种算法的社区发现准确率如表2所示。由于Political Books网络中, 社区的结构不确定, 所以社区的质量评价指标NMI值和ARI值都不是很高。而College Football社区的结构性较强, NMI值和ARI值都比较高, 最高可达到0.92, 能比较准确地体现每个球队的联盟属性。
| 表2 几种算法在真实网络上社区发现的 NMI和ARI对比 |
在人工数据和真实数据集上的实验表明, DLPA算法利用临近节点的紧密度关系, 在社区稳定性和标签更新过程中NMI和ARI都得到了提升, 适合用于比较大的社交网络社区发现。
本文提出基于邻近节点影响强度标签传播的社区发现算法(DLPA)。采用邻接度紧密模型, 融合到模块度的计算和标签的更新判定, 通过最优化模块度计算函数实现社区的快速有效划分。该方法避免了经典标记传播算法LPA对更新次序的敏感、存在平凡解及模块度计算的局部最优化不稳定的问题。DLPA算法的准确率和速度均有所提高。在人工社交网络及真实数据集上的实验结果表明, 本文提出的社区发现算法是有效的, 能够较好地应用于实际网络的社区发现中。目前测试的数据集规模较小, 未来的工作是将算法在分布式的计算平台上进行测试和优化。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|