

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
本体推理在关联数据链接发现中的应用研究*
引用本文
梁艺多, 翟军. 本体推理在关联数据链接发现中的应用研究* . 31(4): 87-95
Liang Yiduo, Zhai Jun. Research on Application of Ontology Reasoning in Linkage Discovery of Linked Data. New Technology of Library and Information Service, 31(4): 87-95
Permissions
Liang Yiduo, Zhai Jun. Research on Application of Ontology Reasoning in Linkage Discovery of Linked Data. New Technology of Library and Information Service, 31(4): 87-95
Copyright©2015, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
本体推理在关联数据链接发现中的应用研究*
梁艺多: 设计研究方案, 收集与分析数据, 开展实验, 起草论文; 翟军: 提出研究思路, 建立模型并绘制图表, 论文最终版本修订。
摘要
目的利用本体推理实现关联数据的链接发现。【应用背景】以图书馆领域为应用背景, 以图书资源为研究对象, 探索应用本体推理建立图书资源之间的链接关系。方法提出含本体推理的链接发现框架, 给出框架各个层次的描述, 并使用Fuseki、Jena、Pubby和PHP等技术实现该框架, 设计并执行链接发现框架的有效性检验方案。结果实验结果表明, 利用该框架能有效建立图书资源的链接关系, 与基于相似度匹配方法相比, 该框架可将链接发现的平均查全率提高约15%, 并可实现语义层次上的知识发现。结论本体推理可有效实现关联数据的链接发现, 具有较高的工程应用价值。
关键词:
本体推理; 关联数据; 链接发现
中图分类号:TP391
Research on Application of Ontology Reasoning in Linkage Discovery of Linked Data
Abstract
[Objective] Take advantage of Ontology reasoning for linkage discovery of linked data. [Context] Based on the application in library and with book resources as research object, Ontology reasoning is applied to establish the linkage relationship between resources. [Methods] The linkage discovery framework is proposed and description of each layer is given. Fuseki, Jena, Pubby and PHP are used to implement the framework, and effectiveness inspection scheme is designed and executed. [Results] The experiment results show that the framework can establish the linkage relationship between book resources. By comparing with the similarity match method, the average recall ratio of linkage discovery can be increased by about 15%. Also, semantic knowledge discovery can be achieved. [Conclusions] Ontology reasoning can effectively be applied to the linkage discovery of linked data, which has high engineering application value.
Keyword:
Ontology reasoning; Linked data; Linkage discovery
1 引言
Berners-Lee于2006年7月首次提出关联数据的概念[1], 它作为语义网的轻量级实现方式[2]吸引了国内外众多研究人员加入其中。关联数据最大的价值在于通过RDF链接建立不同数据源之间的语义链接机制[3], 以获得更多、更全的语义信息和实现跨越异构数据源的资源融合。因此, 关联链接的生成机制成为关联数据领域中的研究热点。
针对关联链接的生成机制, 一种常规的研究思路[4]是: 无论是语义框架层面概念术语间的词汇型链接, 还是实体对象层面客观资源间的关系型链接, 都可以通过计算链接对象之间的相似程度以决定是否建立链接关系。因此, 许多学者围绕着相似度匹配开展了大量的研究。Tversky[5]首先提出基于特征的相似度计算方法, 该方法通过对某个概念的相同对象属性和不同对象属性的计数方式以实现相似度的计算。Mi等[6]在Tversky的基础上, 通过为特征赋予权重, 以区分不同特征在相似度计算过程中所体现的重要程度。张晓辉等[7]从属性权重角度出发, 使用概率方法建立链接数据之间的共指关系。邓兰兰等[8]在分析“ 唯一标识符法” 局限的基础上, 将相似度计算方法应用到同构数据源与异构数据源的关联创建过程中。刘彦斌等[9]采用RS模糊字符串比较算法, 通过计算属性间的相似性来计量资源间的相似度, 以实现生物信息数据库的资源链接。
通过分析可知, 上述方法虽然使用相似度计算方法实现了关联链接的发现, 但链接的结果只是将相似度较高的资源实现了互联, 并没有充分体现不同资源之间在语义层面上的内在联系。
随着本体技术的广泛应用, 以本体作为元数据描述的各种领域资源已经大量存在。同时, 随着本体建设的不断深入, 各领域也已构建了比较完善的以规则为基础的知识库。因此, 考虑如何借助已有的本体资源, 通过基于规则的推理操作以实现不同资源间语义层面的链接发现, 是本文着重解决的问题。
本文的思路如下: 提出含本体推理的关联数据链接发现框架, 介绍框架的具体实现细节; 为验证发现框架的有效性, 以图书资源为例, 展示关联链接的发现过程, 用查全率作为衡量标准, 与基于相似度匹配的链接发现方法作比较, 验证基于本体推理的关联数据链接发现方法的优势; 展示框架在语义知识发现领域的应用示例, 以证明本框架在工程领域中的应用效果。
2 含本体推理的关联数据链接发现框架
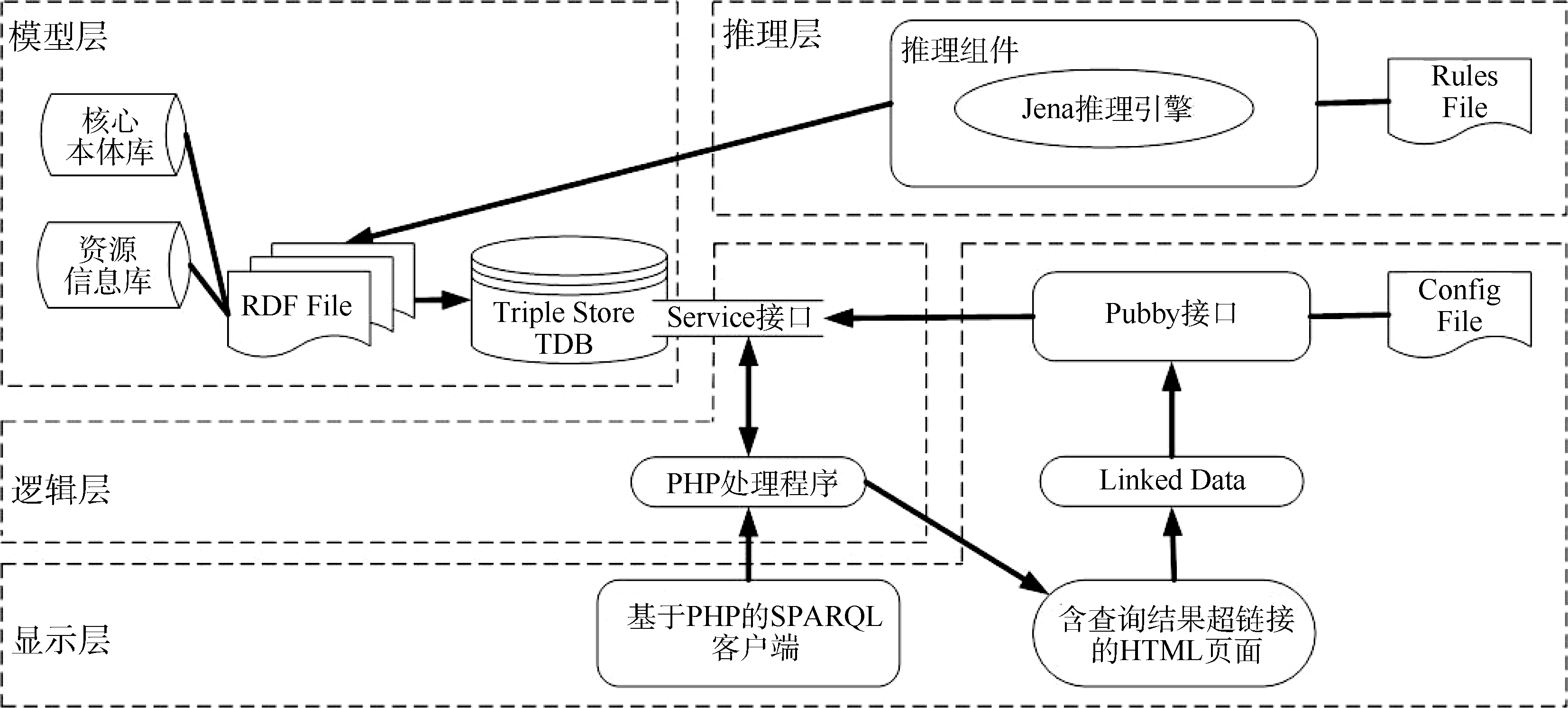
为了清楚地解释本体推理如何融合现有的关联数据技术以实现链接发现的过程, 本文提出含本体推理的关联数据链接发现框架, 如图1所示。该框架包含4个层次, 分别是模型层、推理层、逻辑层和显示层。
 | 图1 含本体推理的关联数据链接发现框架 |
2.1 模型层
模型层是基于本体推理的链接关系发现框架的结构基础, 提供了用于关联数据发布的核心本体库和资源信息库, 以及三元组存储器TDB。该层的核心组件如下:
(1) 核心本体库
核心本体库是根据领域知识构建的本体元数据集合, 它提供了一套用于描述资源的词汇表。在词汇表的选择上, 可优先重用已有的本体词汇表, 如不能满足需要, 可自定义新的本体词汇表。本文采用RDF文件格式存储本体词汇, 并定义统一的命名空间, 文件名为“ coreOntology.rdf ” 。
(2) 资源信息库
资源信息库采用本体词汇表中的词汇, 并按照“ 资源-属性-值” 的三元组形式对资源内容进行标识和描述。其中, 每个资源都使用HTTP URI进行标识, 以保证资源描述的唯一性和可访问性。本文采用RDF文件格式存储资源的描述, 并定义统一的命名空间, 文件名为“ resourceFile.rdf ” 。
(3) 三元组存储器TDB
Fuseki[10]提供了可存储三元组的TDB数据库和执行SPARQL查询的端点, 以及支持RDF文件上传的接口。其中, TDB数据库包括只读数据集和可读写数据集, 并通过自身的Service接口对外提供SPARQL查询和更新服务。本文将上述RDF文件上传至三元组存储器TDB中, 并通过Service接口执行对三元组的操作。
2.2 推理层
推理层是框架的核心部分, 该层包括供推理使用的规则文件和推理组件。规则存储在后缀名为.rule的文件中, 推理组件使用Jena[11]工具包开发, 并通过调用Jena自身携带的推理引擎实现推理过程。其中, 规则文件和推理算法是推理层的重要组成部分, 分别给予详细说明。推理层使用的规则文件的语法形式如下:
//采用正向推理规则
Rule := term, …, term term
//采用三元组模式
term := (node, node, node)
//节点采用变量或URI
node := ?varname or uri-ref
推理组件的核心算法如下:
输入: 核心本体文件(coreOntology.rdf)、原始的资源描述文件
(resourceFile.rdf)、规则文件(inferRules.rule)
输出: 推理后的资源描述文件(resourceFile.rdf)
//装载本体文件到模型中
Model schema = loadModel(“ …/filepath/…/coreOntology.rdf” );
schema = loadModel(“ …filepath…/resourceFile.rdf” );
//读取规则到列表容器中
List rules = rulesFromURL(“ …/filepath/…/inferRules.rule” );
//根据规则列表生成推理机对象
GenericRuleReasoner reasoner = new GenericRuleReasoner
(rules);
//设置基于Rete算法的正向链推理模式
reasoner.setMode(GenericRuleReasoner.FORWARD_RETE);
//执行推理并将结果保存在InfModel对象中
InfModel infmodel = ModelFactory. CreateInfModel
(reasoner, schema);
//将推理得到的结果回写到资源描述文件中
infmodel.write(new FileOutputStream(“ …/filepath/…
/resourceFile.rdf” ));
2.3 逻辑层
逻辑层使用PHP语言开发, 是框架中用于查询关联数据和验证链接发现结果的中间层。该层接收由显示层传递的SPARQL语句, 通过调用ARC2[12]类包和访问TDB的Service接口对Data数据集中的三元组进行查询。同时, 该层对查询结果对象的原始URI按照Pubby的重定向规则进行必要的重写, 以实现对Pubby提供的关联数据界面的访问。该层的核心代码如下:
//设置远程访问的Service接口
$config = array('remote_store_endpoint' => 'http://localhost:3030/
data/query', );
//调用ARC2的相关方法实例化远程存储对象
$store = ARC2::getRemoteStore($config);
//执行查询过程并返回结果集的行项目
$rows = $store-> query(SPARQL语句, 'rows')
//对行项目中三元组的各部分重写URI
foreach($rows as $row){
URIOverwrite($row[$subject]); //对主体重写URI
URIOverwrite($row[$predict]); //对谓词重写URI
URIOverwrite($row[$object]); //对客体重写URI
}
其中, URIOverwrite方法针对查询结果对象的原始URI执行重写操作, 具体的过程将在第3节中结合实例给予说明。
2.4 显示层
显示层提供了使用PHP语言编写的可视化的SPARQL查询模板, 是整个框架与用户的接口部分。用户根据需求编写SPARQL语句并提交给逻辑层执行查询, 显示层将返回由查询结果对象的原始URI构成的HTML页面, 与原始URI对应的超链接属性(< a href=“ …” > )将设置为由URIOverwrite方法重写的URI。
显示层的核心部分是Pubby组件[13], 它是基于Tomcat的Web应用程序, 通过配置Pubby的config.ttl文件可实现关联数据中最重要“ URI重定向” 机制。该文件的核心配置信息如下:
//设置访问关联数据页面的基准URI前缀
conf:webBase < http://example.dlmu.edu.cn:8080/LinkedData/> ;
//配置可供访问的数据集属性
conf:dataset[
//设置可供访问数据集的SPARQL查询端点
conf:sparqlEndpoint < http://localhost:3030/data/query> ;
//设置数据集中可供访问资源的URI前缀
conf:datasetBase < http://example.dlmu.edu.cn/> ;
//设置Web资源的前缀
conf:webResourcePrefix "resource/";
]
上述配置信息的作用将在第3节中结合实例给予说明。
3 链接发现框架的有效性验证
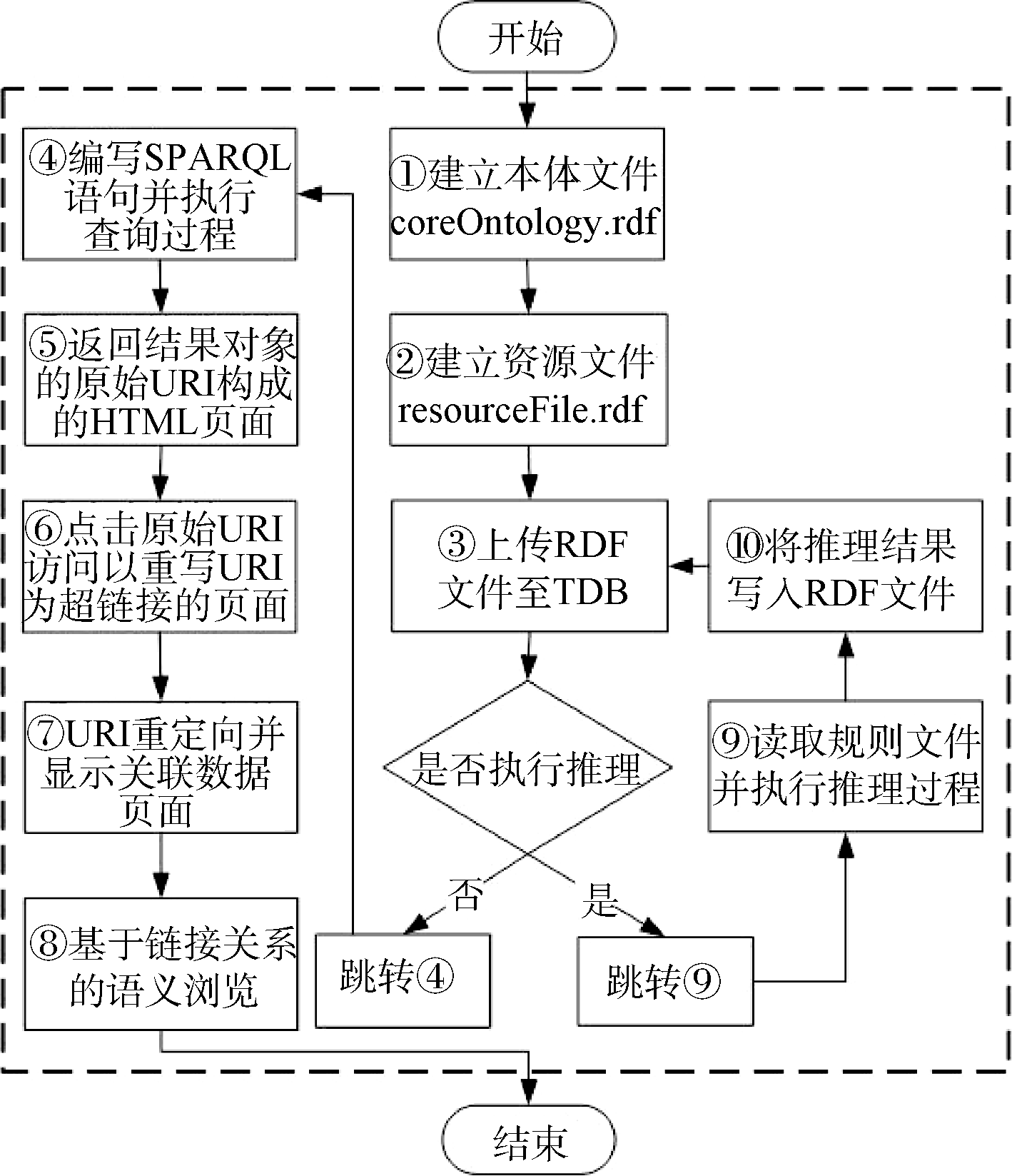
以图书馆领域的图书资源为例, 通过运行含本体推理的链接发现框架以及对链接发现效果的分析, 验证框架的有效性, 有效性检验流程如图2所示:
 | 图2 链接发现框架的有效性检验流程 |
3.1 检验方案的设计
(1) 检验目的: 验证框架的各个组成部分能否有效协同工作以实现关联数据链接关系的发现。
(2) 检验流程: 为了保证检验过程的完整性和有序性, 设计了链接发现框架的有效性检验流程。
(3) 预期效果: 通过运用含本体推理的链接发现框架, 有效地提高链接发现的查全率。
3.2 检验流程的实现
(1) 建立本体文件
执行图2所示检验流程中的步骤①。通过对图书馆领域图书信息进行分析, 整理出与图书相关的核心概念、属性和关系, 如表1所示。其中, 继承关系使用< 子类, 父类> 形式表示, 其他关系使用映射函数σ 将对象属性映射为核心概念笛卡尔积的子集。
| 表1 图书本体的概念、属性和关系 |
将上述本体词汇使用OWL语言描述并保存在coreOntology.rdf中。为了便于表示, 定义命名空间前缀coreOntology: http://example.dlmu.edu.cn/coreOntology#。
(2) 建立资源文件
执行图2所示检验流程中的步骤②。具体过程如下:
选取与“ ERP” 主题相关的图书数据作为实例, 建立相应的资源文件。具体的实例信息如表2所示:
| 表2 图书数据实例 |
对选取的图书数据使用OWL语言并结合coreOntology.rdf文件中的定义本体词汇加以描述, 将描述的结果保存在resourceFile.rdf文件中。为了便于表示, 定义命名空间前缀bookNotation: http://example. dlmu.edu.cn/bookNotation/。以《ERP原理与应用》一书为例进行描述, 代码片断如下所示:
< owl:NamedIndividual rdf:about="& bookNotation;
9787508335056 ">
< rdf:type rdf:resource="& coreOntology; Book"/>
< rdfs:label xml:lang="zh"> ERP原理与应用< /rdfs:label>
< coreOntology:YearOfPublication rdf:datatype=
"& xsd; dateTime"> 2005
< /coreOntology:YearOfPublication> < coreOntology:BookISBNrdf:datatype="& xsd; string"
> 9787508335056
< /coreOntology:BookISBN>
< coreOntology:CreatedBy rdf:resource="& bookNotation;
桂海进"/>
< coreOntology:PublishedAt rdf:resource="& bookNotation;
中国电力出版社"/>
< coreOntology:hasSubjectTerm rdf:resource="
& bookNotation; ERP"/>
< /owl:NamedIndividual>
主题词将用于推理操作, 对主题词采用同样的方式进行描述, 代码片断如下:
< owl:NamedIndividual rdf:about="& bookNotation; ERP">
< rdf:type rdf:resource="& coreOntology; SubjectTerm"/>
//指定“ ERP” 的正式主题词为“ 企业资源计划”
< coreOntology:hasNormalTerm rdf:resource=
"& bookNotation; 企业资源计划"/>
//指定“ ERP” 的相关主题词为“ 信息化实施”
< coreOntology:hasRelativeTerm rdf:resource="& bookNotation; 信息化实施"/>
< /owl:NamedIndividual>
(3)上传RDF文件至TDB
执行图2所示检验流程中的步骤③。具体过程如下:
制作批处理文件start.bat, 在文件中保存命令“ java -jar fuseki-server.jar -config=config-tdb.ttl” , 双击批处理文件以启动Fuseki。其中, config-tdb.ttl文件用于配置TDB的各种数据集及每个数据集提供的服务, 本例使用名为data的数据集, 它是TDB的可供读写的数据集。启动Fuseki后, 在浏览器中输入http://localhost: 3030/, 访问Fuseki的主界面, 点击主界面中的“ 控制面版” , 进入data数据集, 选择coreOntology.rdf和resourceFile.rdf文件并点击Upload按钮完成文件的上传。
(4) 查询推理前的关联数据页面
执行图2所示检验流程中的相关步骤, 顺序为: ④→ ⑤→ ⑥→ ⑦。具体过程如下:
编写用于测试的SPARQL语句, 查询未经推理的图书信息, 例如查询名称为“ ERP原理与应用” 的图书信息可使用如下语句:
SELECT ?s WHERE{?s rdfs:label "ERP原理与应用"@zh.}
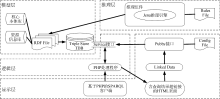
将上述语句填充至使用PHP编写的SPARQL查询生成模板中, 如图3所示:
 | 图3 基于PHP的SPARQL查询生成模板 |
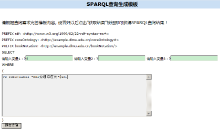
点击“ 提交查询” 按钮, PHP脚本将执行查询, 并返回包含查询结果超链接的HTML页面, 如图4所示。
 | 图4 SPARQL查询结果 |
在2.3节中提到, 在逻辑层构建时, PHP程序将调用URIOverwrite方法针对查询结果对象的原始URI执行重写操作; 在2.4节中也提到, 显示层将返回由查询结果对象的原始URI构成的HTML页面, 与原始URI对应的超链接的属性值将设置为由URIOverwrite方法重写的URI, 重写的规则在Pubby的config.ttl配置文件中。
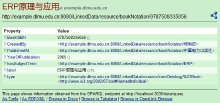
针对本例而言, 查询结果对象的原始URI为http:// example. dlmu.edu.cn/bookNotation/9787508335056。根据config.ttl配置文件的设定, 将使用“ http://example. dlmu.edu.cn:8080/LinkedData/” 替代“ http://example.dlmu. edu.cn/” , 并在执行替代部分的后面追加“ resource/” 片断, 则重写后的URI为http://example.dlmu.edu.cn:8080/ LinkedData/resource/bookNotation/9787508335056, 并将其设置为原始URI的href属性值。点击此超链接后, Pubby将自动实现重定向, 将上述URI中的“ resource/” 修改为“ page/” , 并显示资源对应的关联数据页面, 如图5所示:
 | 图5 资源的关联数据页面 |
(5) 执行推理过程
执行图2所示检验流程中相关的步骤, 顺序为: ⑨→ ⑩。具体过程如下:
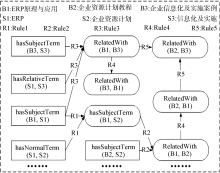
调用推理组件读取规则文件inferRules.rule中的\规则, 针对resourceFile.rdf文件执行推理操作。inferRules.rule文件中所含的规则如表3所示。其中, 变量? B1、?B2、?B3表示图书对象, 变量?S、?S1、?S2表示主题词对象。
| 表3 推理规则示例 |
以《ERP原理与应用》图书资源为例, 说明推理的具体执行过程。该资源的主题词(hasSubjectTerm)是“ ERP” , 而“ ERP” 的正式主题词为“ 企业资源计划” , 根据规则1可知, 该资源包含主题词(hasSubjectTerm)“ 企业资源计划” ; 而资源《企业资源计划教程》的主题词(hasSubjectTerm)为“ 企业资源计划” , 根据规则2可知, 资源《ERP原理与应用》和资源《企业资源计划教程》是相关的(RelatedWith), 从而实现了资源间基于推理的链接发现的目的。
其他对象的推理执行过程如图6所示。其中, 直角矩形表示已知的事实, 圆角矩形表示推理出的链接关系。
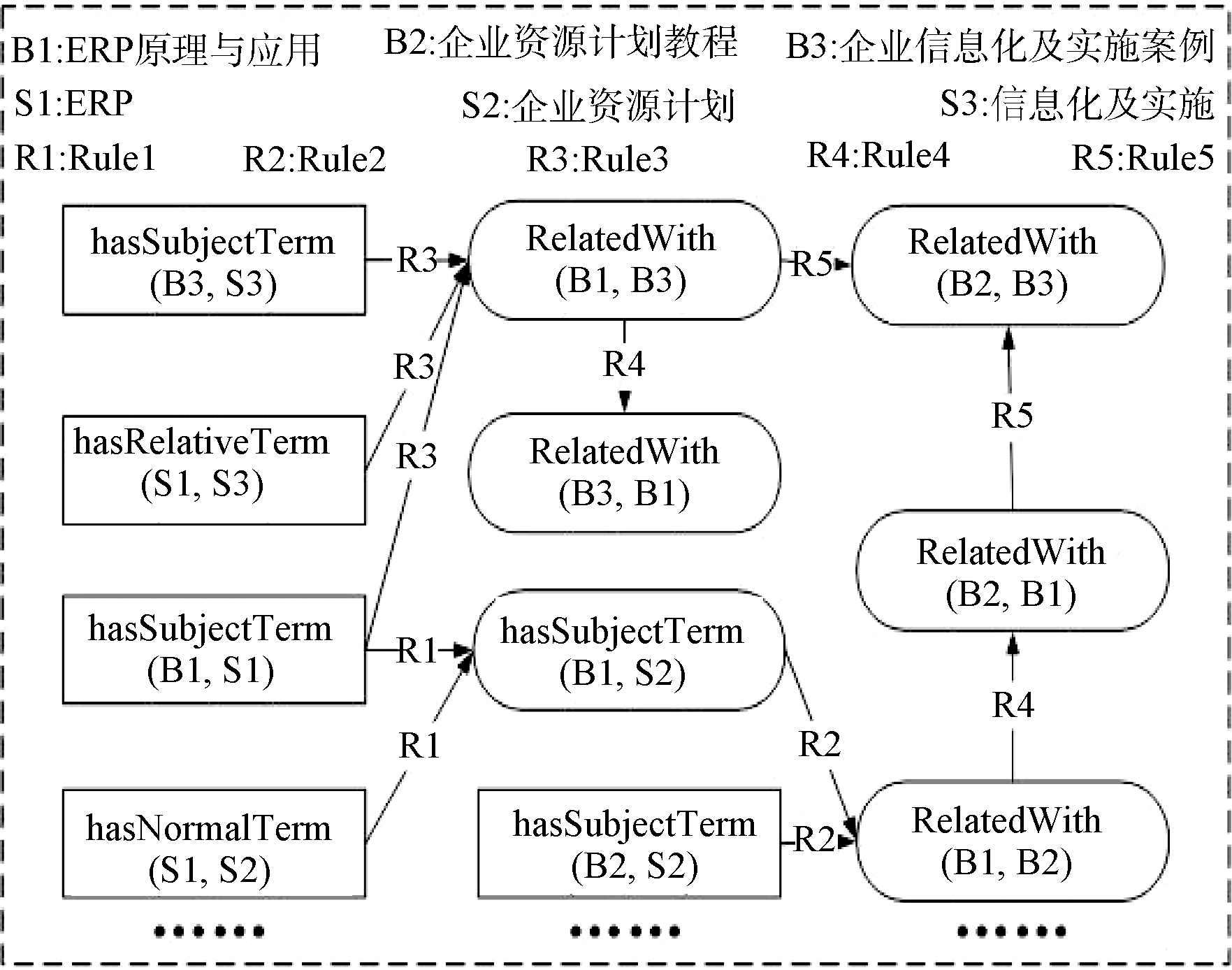 | 图6 基于本体推理的链接发现过程 |
推理全部完成后, 可使用下述语句将推理的结果回写到资源描述文件中:
infmodel.write (new FileOutputStream(“ …/filepath/…/resourceFile.rdf” ));
(6) 查询推理后的关联数据页面
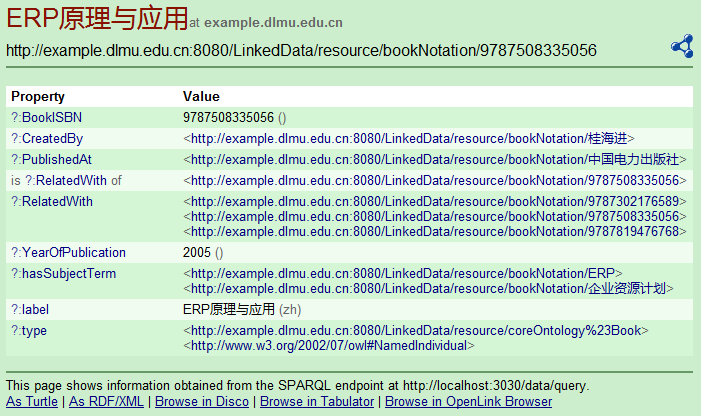
重复之前的过程(3)和(4)所含的步骤, 可得到同一资源推理后的关联数据页面, 如图7所示:
 | 图7 推理后的资源关联数据页面 |
由图7可知, 《ERP原理与应用》经过推理后得到了与其相关的(RelatedWith)图书资源的信息, 并以“ 属性-值” 的形式将发现的链接关系显示在关联数据的页面中。
(7) 基于链接发现的语义浏览
执行图2所示检验流程中的步骤⑧。具体过程如下:
点击ISBN号为“ 9787302176589” 的图书资源URI, 可跳转至资源《企业资源计划教程》的关联数据页面, 如图8所示:
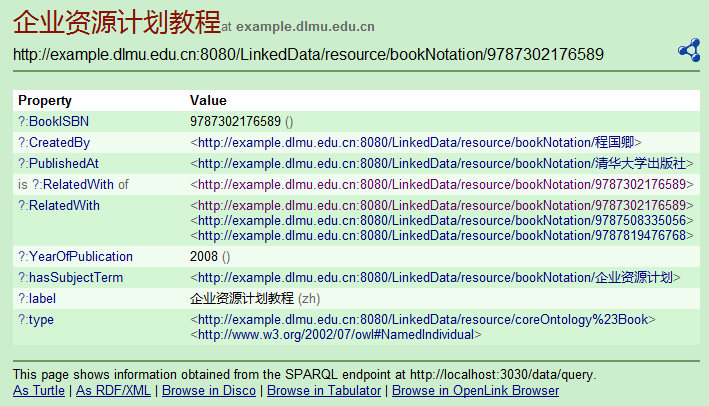 | 图8 通过语义链接访问的关联数据页面 |
3.3 检验结果分析
检验结果表明, 本文提出的关联数据链接发现框架可利用本体推理有效地实现资源之间链接关系的发现。同时, 为了从定量的角度分析链接发现的效果, 笔者将本文的方法与文献[9]中基于相似度匹配的链接发现方法进行对比, 并采用查全率指标来评价实验结果。具体过程如下:
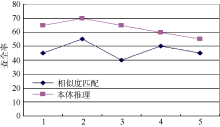
笔者从大连海事大学图书馆的公共检索系统[14]中随机选取100篇与ERP主题相关的图书信息, 划分为5组, 针对3.2节中使用过的“ ERP原理与应用” 资源对象, 分别采用两种方法执行关联链接发现实验, 并计算每次实验结果的查全率。两种方法的实验对比结果如图9所示:
 | 图9 实验对比结果 |
由图9可知, 在5次实验中, 基于本体推理的链接发现的查全率均高于基于相似度匹配方法的结果。原因在于: 前者借助本体关系和推理规则实现了语义层面的关联发现, 而后者只是在技术上实现了字符串的相似度比较, 如: 《ERP原理与应用》与《企业资源计划应用教程》, 使用相似度匹配方法的结果是两者属于不相关的对象, 降低了链接发现的查全率。
同时, 针对基于本体推理的链接发现方法所存在的漏检情况, 通过分析发现, 主要原因在于某些图书的主题词, 如“ 信息化建设” , 没有在本体文件resourceFile.rdf中显示声明与主题词“ ERP” 的hasRelativeTerm关系, 导致语义关系的缺失。通过建立相应的语义关系, 可进一步提高基于本体推理的链接发现的查全率。
4 链接发现框架在知识发现领域的应用
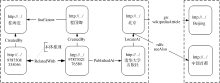
链接发现框架通过本体推理实现了资源之间链接关系的建立, 它不同于传统Web页面的超链接, 是一种建立在语义层面上的链接关系, 为实现基于语义的知识发现提供基础。链接发现框架在知识发现领域中的具体应用如图10所示:
 | 图10 框架在知识发现领域中的应用示意图 |
由图10可看出, 从资源“ http://…/9787508335056” 出发, 可以浏览此图书作者“ http://…/桂海进” 的关联数据页面。通过本体推理, 建立资源“ http://…/9787508335056” 与“ http://…/9787302176589” 的关联链接, 进而可以浏览作为图书作者的资源“ http://…/程国卿” 的关联数据页面, 并且发现“ 程国卿” 了解(foaf:know)“ 桂海进” 的事实。由资源“ http://…/9787302176589” 出发, 可以浏览资源“ http://…/清华大学出版社” 的关联数据页面, 再进一步浏览资源“ http://…/北京” 的关联数据页面。
如果异构的数据源之间存在关联链接, 则可实现跨越异构数据源的知识发现, 如图10所示, 由资源“ http://…/北京” 出发, 通过链接关系, 可浏览维基百科中关于“ 北京” 的介绍页面和其他数据源中关于“ 中国首都” 的介绍页面。
由此可知, 借助本体推理实现的链接发现是一种语义上的融合, 可挖掘和建立不同资源之间的语义关联关系, 进而有效地实现更多的知识发现。
5 结语
本文构建了含本体推理的关联数据链接发现框架, 以图书资源为例, 借助本体推理实现了资源间链接发现, 与基于相似度匹配的方法相比, 本文的方法具有较高的链接发现的查全率。同时, 将本文的方法应用于语义知识发现领域, 验证了其工程应用价值。下一步工作是借助推理技术实现异构数据源的语义混搭, 以及如何优化本体推理过程的性能和效率等问题。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|