{kind=link}
{kind=link}
{kind=link}
{kind=link}
领域科技文献创新点句中主题属性实例识别方法研究
[张帆1, 2  , 乐小虬
, 乐小虬1 ]
, 乐小虬|
|


作者贡献声明:
张帆: 设计并实施技术方案、技术路线, 数据采集、清洗, 实验分析、验证, 论文起草;
乐小虬: 提出研究方向和研究思路, 论文修改及最终版本修订。
【目的】识别创新点句中主题属性实例, 进一步挖掘创新点句中的知识关系。【方法】采用语义角色标注以及依存句法分析方法, 借助领域本体中属性类目下主题词, 从依存树中识别创新点句中的核心主题词以及属性实例; 针对依存句法分析的特征, 设计组合术语识别模块以及连接词关系识别模块以改善识别效果。【结果】创新点句中核心主题词识别的F值达到77.94%; 创新点句中属性实例识别的平均F值在90%左右。【局限】使用Stanford依存句法分析工具对肿瘤领域进行句法分析造成的偏差影响识别效果; 使用NCIt本体属性类别时, 有待进一步过滤与规范。【结论】实验结果表明, 该方法对领域创新点句中的主题属性实例具有较好的识别效果。
[Objective] This article aims to extract concept attribute instances in innovation sentences, and then to explore the relationship between concepts.[Methods] A method of recognizing core concept and concept attribute instances from dependency tree is presented. This method is based on the results of semantic role labeling and dependency parsing, and takes advantage of property of classes in domain Ontology. Considering the feature of dependency parsing, a concept combination module and a conjunction relationship detection module are designed to improve the effect of concept attribute instances recognition.[Results] The results show that the F value of core concept recognition is 77.94%, and the average F value of concept attribute instances recognition is around 90%.[Limitations] Stanford parsing tool leads to wrong parsing results which may result in inaccurate recognition. The class of Properties or Attributes in NCIt is not well filtered and standardized.[Conclusions] This method can effectively extract core concepts and concept attribute instances in innovation sentences.
学术论文是研究者研究中创新成果的文字体现[1], 对领域论文中创新点句的识别与整合有助于研究者迅速把握当前研究方向的主要研究进展和突破点。句子是创新点描述的基本单元, 内含丰富的主题属性信息, 可以深度揭示创新点内容。因此, 识别创新点句中的属性实例, 从细粒度上挖掘领域创新点的知识结构及其内容是创新点挖掘的重要手段。
文献[2]利用领域本体与语言规则从科技文献中识别可以揭示论文创新点的新知识声明句, 但该研究还没有揭示创新点句的内部具体主题概念的知识关系, 缺乏对创新点句的有效组织和利用。为了解决这一问题, 本文以肿瘤领域为例, 从识别创新点句中的主题入手, 将句子中蕴含的创新知识进一步拆分和细化。本文中的主题是指借助领域本体或词表识别出的具有层级关系的主题词, 通过梳理创新点句中主题的语义关系以及属性实例, 挖掘领域科技文献中创新点句内部的知识关系, 为创新点句的进一步利用和组织奠定基础。
属性抽取隶属于细粒度知识抽取的研究范畴, 以揭示实体之间的关系、将分散的实体关联起来为目标。就抽取对象类型而言, 属性抽取主要分为对实体(如人物[3]、商品[4]等)的属性抽取以及对概念的属性抽取[5], 其中针对概念的属性抽取又可分为通俗概念的属性抽取以及学术概念的属性抽取[5, 6]。本文研究对象为肿瘤领域论文创新点句, 待抽取对象为学术概念(领域概念)的属性实例, 对生物医学领域而言, 其领域概念也可理解为一系列生物医学命名实体[7](如基因、蛋白质、疾病等)。因此, 本文从领域学术概念属性抽取以及领域命名实体的属性识别两方面对属性抽取的相关研究进行介绍, 后者将聚焦在生物医学领域中生物医学命名实体的属性识别。
生物医学领域中识别生物医学命名实体属性时, 采用的方法以自然语言处理技术与机器学习相结合的方式为主, 但其中自然语言处理程度不尽相同。
(1) 基于规则的方法
采用手工或者自动构建的方式, 识别关系与概念之间的语言模式并依此制定抽取规则。Jones等[8]以纳米医学领域文献为实验对象, 由领域专家从相关领域本体中选定树枝状分子相关的属性, 在GATE中手工标注部分属性和属性值, 并利用GATE中的JAPE语法规则文件书写规则, 结合ANNIE组件实现属性及其对应数值型属性值的抽取。Fundel等[9]从100万MEDLINE摘要中提取基因-蛋白质关系, 针对关系描述在句法分析结果中呈现的特征, 制定三条抽取候选关系的规则: A-relation-B; relation-of-A-by-B; relation-between-A-and-B, 利用基于规则的方法从句法分析的结果中选取候选关系对; 并在此基础上制定过滤规则去除不符合条件的关系对。其局限在于: 需要编制限定候选关系词表对候选关系进行限定(人工选定); 开源词性标注工具的使用可能会造成一定的错误率、有限的关系词限定词表会造成召回率的损失等。为了改善大量人工干预所带来的不便, Tang等[10]将少量人工处理后的样本模式作为种子, 采用基于统计和机器学习的方法自动构建识别模式。
(2) 基于机器学习的方法
将属性抽取问题转化为分类问题或标注问题, 需选取特定特征并利用预先标注好的数据训练模型。Pechsiri等[11, 12]以句子或基本话语单元为单位, 从问答系统中回答疾病治疗的相关技术文本中识别草药的医药学属性(该药物的生理效应或作用疾病)。采用基于自然语言处理和统计的方法识别文本中草药的医药学属性; 考虑到技术文本描述草药生理效应时存在动词省略和结束线索词省略现象, 利用基于机器学习的方法确定该属性的边界。该方法识别属性边界时需要大量人工标注产生训练集; 没有考虑动词的上下文环境, 造成部分边界的识别错误; 此外, 应用范围较窄, 对问答系统中针对草药属性或特性问题回答的技术文本有较好效果。
Feng等[13, 14]以神经医学领域中示踪实验数据记录为抽取对象, 采用一种双层的CRF识别记录中的语义属性信息, 利用词序列的标注解决属性抽取问题: 利用一个句子级的CRF模型标注句子, 特征项包括词汇知识、当前词语、所属范围、临近词语以及依存特征5项, 定义的语义属性包括注射位置、化学示踪剂、标注位置、标注描述4种; 在此基础上, 构建基于句子级的CRF属性标注和当前词语相结合的语言模型(如三元组location-of-< tracerChemical> ), 并认为该语言模型可以在一定程度上揭示示踪实验记录的结构。该方法的不足有: 采用有监督的识别方法, 依赖人工标注训练集; 没有充分考虑和利用相关的领域本体知识等。
除生物医学领域之外, 领域概念或领域命名实体属性抽取在其他自然科学领域以及社会科学领域皆有较为广泛的应用。在自然科学领域中(如计算机[15]、植物学[16]、纳米材料学[17]等), 领域命名实体属性抽取通常在本体构建、问答系统、自动摘要系统中起到重要作用。其中较为有代表性的研究有: Pham等[15]利用基于涟波下降规则的方法构建文本标注规则, 该规则的基本形式为“ IF α THEN β ” , 其中α 称为条件, β 称为结论。规则的条件部分包括标注模式和标注限定两部分: 标注模式部分利用预先规定好的标注类别, 采用正则表达式书写规则; 标注限定部分限定了不同标注类别的具体特征值。规则的结论部分即对文本分类的结果。Pechsiri等[16, 18]将问题聚焦在植物领域概念实体的“ 因果” 属性上, 并认为特定实体的原因和结果描述由因果关系动词链接, 重点识别以因果关系动词作为连接词的原因与结果, 标注格式为动词-原因或结果, 利用贝叶斯分类器判断动词是否为因果性动词, 利用SVM判断每个动词对应的描述是否是原因或结果。Xiao等[17]以纳米材料对环境的影响为研究点, 预先选定与纳米毒害性相关的6种实体以及3种属性, 在提取实体与属性之间的关系以及属性值时, 为避免数据表或句子造成的稀疏性, 选取段落作为抽取对象。
在社会科学领域, 部分学术概念属性较为抽象或具有主观性[6], 抽取前需确定属性的各类特征(如语言描述特征以及位置分布特征等)。代表性的研究有: 丁君军等[6]采用人工阅读的方法从情报学文献中识别描述学术概念属性的句子, 分析其中的语言描述特征并进行统计和归类, 在此基础上构建规则并对规则进行优化和噪声处理, 并对抽取的属性描述进行情感分析, 抽取最好结果的准确率、召回率以及F值都在60%左右; 王璐等[19]发现学术定义中蕴含该学术概念的领域属性与区别属性, 因此采用一种基于术语共现的方法从市场营销文献中抽取术语的属性, 将在定义中与学术概念共现的术语作为候选属性, 学术概念与其属性共现矩阵的权值反映概念与对应属性的共现概率, 进一步可确定属性的重要程度或核心程度。
针对创新点句中分散的领域主题词以及属性, 借助领域知识实现句子中主题词的识别和属性实例(属性词及语义关系)识别; 采用基于依存句法分析的方法实现主题词与属性实例匹配。本文的基本思路为: 通过分析领域科技文献摘要中创新点句的语言特征和位置特征, 参考不同类别创新点的表达方式, 分析领域本体的结构, 对创新点句进行语义标注; 采用基于依存分析的方法识别创新点句中的核心主题词, 并对依存树中蕴含的主题词及其对应属性实例进行抽取。
语言学中, 论元对动词谓词进行补充说明, 谓词及其论元可以构成谓词-论元结构(PAS)[20]。在此基础上, 语义角色标注(SRL)是指识别句子中的谓词(动词)的语义成分, 并对该谓词所属的特定语义类型进行标注[21]。早期研究和系统在进行语义角色标注时以动词为主(如FrameNet[22]等), 后期逐渐扩展到在标注动词语义角色的基础上进一步标注出与该动词相关的其他语义成分, 如施事、受事、时间和地点等论元(如PropBank[23]、NomBank[24]等)。本文借鉴谓词-论元结构及语义角色标注的思想标注创新点句中的主题词及属性实例, 标注主要从以下两个角度展开: 基本语义角色标注; 基于领域本体和词表的语义标注。
(1) 基本语义角色标注
结合科技文献摘要中创新点句的特点, 确定语义标注对象以动词与名词为主, 以创新点句的语言学特征为基础, 选择基本语义角色类别为: 目的、创新点类别以及其他三类。
①对科技文献目的标注
科技文献摘要中研究目的部分主要阐述该研究要解决的问题或揭示该研究的动机, 因此可以从侧面体现本研究创新点主要解决的问题或攻克了何种当前研究的难点或瓶颈。研究者通常采用特定的语言表述方式(特征名词、动词以及短语等)对其写作目的进行描述, 为读者揭示论文立意, 如: objective、aim at等。
②对科技文献创新点类别标注
对创新点类别进行语义角色标注主要有以下两个优点: 其一, 细化文献[2]中的研究, 通过分析和总结不同类别创新点特征, 可以进一步细化和扩展抽取规则, 提高创新点句识别的准确率; 其二, 为后续的创新点句汇聚以及评估提供基础。参考周露阳[25]、田丽等[26]对创新点的分类, 结合不同类别创新点的语言表达方式特征, 选取新发现、新方法以及新观点作为创新点类别标注的代表。标注时通过统计和人工标注相结合的方式选择可以揭示创新点句具体类别的特征动词和名词, 如application、methodology等。
③其他类型语义角色类别标注
在对创新点类别标注后, 发现创新点句中仍包含很多无法明确标注为以上三个创新点类别的名词和动词, 这些动词和名词高频出现, 表明它们也是创新点句的特征词, 因此归为其他类。
(2) 基于领域本体和词表的语义角色标注
将领域知识(例如领域本体、领域词表等)引入到标注过程中, 使得标注结果更具领域针对性的同时语义更加丰富。依照其中术语是否经过组织和规范进行分类, 领域知识载体可以分为领域本体(或主题词表)以及关键词两类。以肿瘤领域为例, 本文所使用的领域知识载体主要分为经过特定处理的领域词表或领域本体以及未经规范化处理的关键词和缩写词两类。
①论元的标注
创新点句中的论元既可能是该句的主题词, 也可能是与主题词相关的属性词。本文在对论元进行标注时, 利用领域本体NCIt[27]、领域关键词集合以及从文章标题和摘要中识别出的缩写词对领域主题词进行标注, 此外利用领域本体NCIt对属性词进行标注。NCIt由美国国立癌症研究所编制, 以主题词表形式提供有关癌症及癌症相关的生物医药信息, 包括肿瘤及相关概念的同义词、近义词以及上下位词等信息。
在对语义角色类别进行选择时, 选择NCIt顶级类目Properties or Attributes对句子中出现的属性词进行标注; 确定研究主题为肿瘤, 定位为NCIt中20个顶级类目之一Diseases, Disorders and Findings的子类; 确定与肿瘤主题词相关的其他类目主题词。在确定其他类目与肿瘤类目相关关系时, NCIt提供的语义关系有Associations和Roles两种, 其中, Associations类型的关系可通过父类继承; 通过分析NCIt本体可以发现与Diseases, Disorders and Findings类通过Associations类型语义关系产生联系的类主要有7类, 如表1所示; 由于NCIt是由上下位概念及其相互间关系构成的树状结构, 提供的关联关系并没有给出相应的实例(如Disease_Excludes_Abnormal_Cell等), 因此很难利用NCIt的语义关系从自然语言的数据集中识别此类语义谓词。
| 表1 NCIt中肿瘤相关类目 |
②语义谓词的标注
语义谓词(Semantic Predication), 也称语义预设、语义断言、语义谓述等, SemRep[28]中的语义谓词即为一种逻辑主语-谓词-逻辑宾语的三元组, 其中主、宾论元来源于UMLS超级叙词表(Metathesaurus)中的概念, 谓词所代表的语义关系为UMLS语义网(Semantic Network)的扩展。
针对NCIt语义关系没有实例的不足, 本文借助UMLS中语义工具SemRep对创新点句中的语义谓词进行识别。考虑到效率问题, 利用SemRep标注了100 000条文献[2]处理过程中的摘要句子并对其中的语义谓词实例进行汇总, 综合考虑实例数量比重以及与肿瘤相关程度, 采用基于词频统计的方法选取语义谓词类型(部分语义谓词类型如表2所示), 此外考虑到语义谓词的表现形式, 人工筛选出一些表述方式过于复杂或特殊的语义谓词, 如语义关系TREATS (SPEC), 该类别标注出表达方式整体词频过低(小于2次), 应予以剔除。
| 表2 SemRep语义谓词类别 |
最终得到标注后例句1如下:
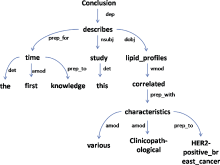
Conclusion: For the first time to ||our||RF ||knowledge||KW , ||this study||TP ||describes||VB ||lipid_profiles||KW ||correlated||PR||AS||AF with various ||Clinicopathological||KW ||characteristics||PR of ||HER2- positive_breast_cancer||KW .
本文旨在通过识别创新点句中的主题词及其属性实例, 细化和拆分该创新点句中具体的知识关系, 并为后期领域中相关主题词下知识关系和属性的汇聚奠定了基础。创新点句的属性实例主要包括其中主题词蕴含的语义关系与属性/介词关系两种, 其中语义关系主要由语义谓词揭示; 属性与介词关系主要通过属性类别特征词以及通过介词构成的关系体现。主题词及其语义关系或属性关系类似谓词-论元结构, 考虑到依存句法分析所得结果与谓词-论元结构相近[29], 本文对创新点句对应的依存句法树进行分析, 识别其中有价值的语义关系或属性关系实例。
将标注句中识别出的多词主题词或术语中空格替换为下划线, 保持术语完整性, 记录术语和谓词对应的语义类别; 对处理后的句子进行依存句法分析, 得到依存句法树, 本文采用斯坦福大学开发的自然语言处理工具[30]进行依存句法分析。
对3.1节中的例句1进行依存句法分析, 结果如图1所示:
 | 图1 例句语义标注的句法分析树 |
(1) 核心主题词发现以及组合术语识别
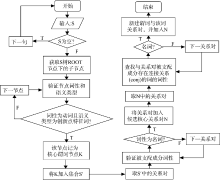
依存句法分析采用词语对的二元关系形式体现句子中的词语之间的依存关系, 通过定位语义标注类型为创新点句特征动词的谓词节点, 可以进一步识别被
其支配的主题词, 而这些主题词即为可以揭示创新之处的核心主题词。该识别算法主要分为两步: 从创新点句依存关系对集合S中识别出可以揭示句子创新之处的核心谓词节点集合S° ; 从S° 中识别符合条件的核心谓词关系对集合N, N中每个关系对中的被支配成分即为该句的核心主题词。该算法的具体流程如图2所示:
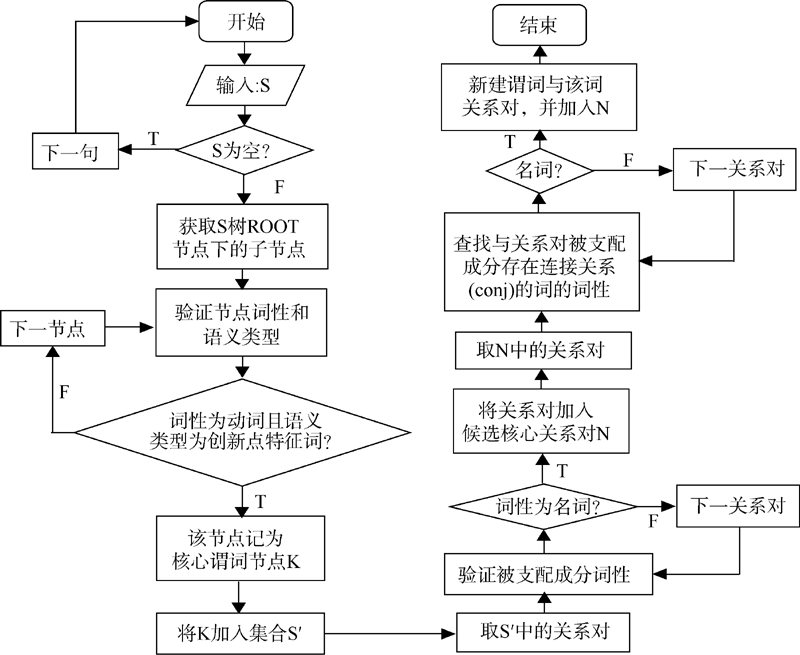 | 图2 核心主题词发现及其关系对识别流程图 |
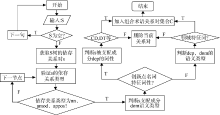
候选核心关系对中被支配成分为名词性词语, 并不一定是句子中语义标注出的主题词概念, 或其与主题词形成修饰关系, 因此需要对名词性词语进行扩展, 并去除无法揭示领域知识的关系对形成最终的核心关系对以及核心概念。因此需要对每个创新点句中主题词可能构成的组合术语进行识别。本文构建组合术语识别模块辅助和扩展关系抽取、优化术语表达方式, 使其更加明确和完整。组合术语识别模块算法描述如图3所示:
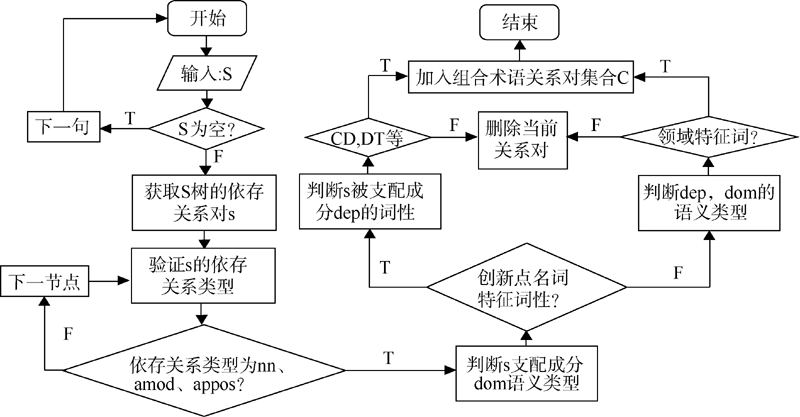 | 图3 组合术语识别模块算法流程图 |
考虑到依存句法分析的特性, 可能会造成并列、转折等通过连接词相关联的主题词形成的关系对遗漏, 因此, 本文构建连接词关系识别模块对被支配成分的连接词性的依存关系进行识别, 对已建立关系对的被支配成分的连接词关系对进行查找, 若与当前被支配成分构成连接词关系的节点类别为主题词, 则为该节点与当前支配成分构建新的属性对(即图2 中步骤“ 查找与关系对被支配成分存在连接关系(conj)的词的词性” )。
(2) 属性实例发现
利用SemRep标注得到的部分语义谓词类别过于宽泛(如AFFECTS等), 就语义而言几乎适用各种领域, 对肿瘤领域内部特殊关系和属性的揭示能力较弱。因此, 在利用SemRep语义谓词类别进行属性实例发现的基础上, 引入领域本体NCIt中属性类目, 以便更好地揭示肿瘤领域内部特有的属性和语义关系。
①利用SemRep语义谓词的属性实例发现
SemRep中提供的语义类型可以揭示生物医学领域中不同类别实体之间的关系, 通过抽取句子中语义谓词与NCIt主题词之间的依存关系, 可以发现主题词在领域中的语义知识关系。此外, 识别SemRep类型语义关系时, 也应考虑被支配成分是否有相应的组合术语。对创新点句中NCIt主题词相关的语义关系提取过程如下:
1) 对创新点句依存树中的动词节点以及标注为SemRep语义类型的节点进行汇总, 得到起始节点集S;
2) 遍历依存树, 获取S中每一个候选谓词节点为支配成分的依存关系对;
3) 对S中每个节点对应的依存对进行判断, 若其被支配成分标注类别为NCIt主题词或具有组合术语, 则认为该依存对是关于该主题词类别的有效语义关系。
此外, 对当前依存树中已抽取的关系对中的被支配成分的连接词关系进行查找, 对符合条件的主题词构建新的属性对。
考虑到利用SemRep标注实例的不完备性, 将符合识别算法但未标注为SemRep的动词节点作为候选语义关系, 并通过词频过滤配合人工处理将其分配到对应的SemRep语义类别中。
②利用NCIt本体属性类别的属性实例发现
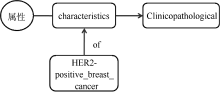
NCIt属性类目(Properties or Attributes)下属性主题词有5 500多条, 属性类型分布不明显, 属性词词性包含了形容词、名词等, 语义含义较为分散, 但可以对主题词的相关属性进行一定揭示, 因此考虑从创新点句中抽取与主题词相关的属性依存对。识别依存树中的属性关系对主要分为以下两个步骤: 对树中的主题词-属性关系对进行识别; 利用具有介词关系的依存对识别对主题词的属性关系进行补充。利用介词关系对对属性进行补充, 主要考虑到介词作为揭示词与词之间关系的虚词, 可以进一步揭示属性的状态(如部位、时间、方式等)。如例句中属性“ characteristics” 对应的主题词为“ Clinicopathological” , 此外, 依存对中与属性“ characteristics” 存在介词关系的依存对有“ characteristics-prep-to- HER2-positive_breast_cancer” , 主题词“ HER2-positive_breast_ cancer” 对属性“ characteristics” 的具体种类进行补充和细化, 如图4所示:
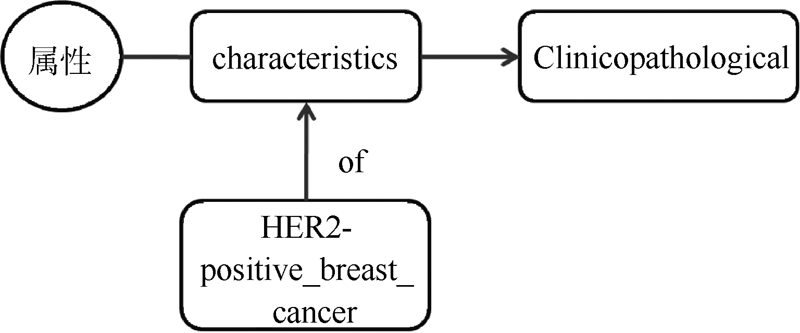 | 图4 属性-介词关系示意图 |
实验数据来源于Web of Knowledge中20种肿瘤领域期刊的文章摘要, 采用文献[2]中的方法识别其中的创新点句, 并采用Solr构建索引。选取NCIt中主题词“ Breast Carcinoma” 及其所有同义词作为检索词, 构建Solr检索式“ (domainField:cancer) AND ((sentence_ content:Breast Neoplasm) OR (sentence_paperTitle: Breast Neoplasm) OR (sentence_concept:Breast Neoplasm)) AND (year:{2011 TO 2014}) AND (sentence_ property_str:* )” , 对索引中相关的创新点句进行检索, 选取前200条检索结果进行实验与分析。
(1) 核心主题词发现实验
采用3.1节中的方法提取200条检索结果中的核心主题词以及组合术语, 得到核心主题词关系对178对, 实验结果如表3所示。观察表3的结果可以发现: 添加组合术语识别模块方法的准确率、召回率以及F值皆高于不添加组合术语识别模块方法的对应指标。分析其原因为: 句法依存树的特点是将具有依存关系的二元组识别出来, 若不考虑被支配词的其他修饰性的依存关系, 则很可能因为对被支配词的语义标注不满足抽取要求而错误地过滤有效的关系对。
| 表3 核心主题词发现实验结果 |
此外, 具体对未发现核心主题词的句子进行跟踪和分析, 发现其核心主题词未被识别的原因主要有以下两点:
①识别出的核心主题词不属于NCIt主题词, 也不存在相关的组合术语, 且并未对其下一级节点中包含的主题词进行提取, 导致该句提取的核心主题词为空。
如“ In ||this study||TP the ||relation||AS between ||adipose tissue||AN||EA ||composition||PR and ||breast cancer||KW||DI was ||investigated||VB||OB .” 中识别出核心主题词为relation, 该词既不是NCIt语义标注出的主题词也不存在组合术语, 该关系对被剔除。
②NCIt中属性类别中主题词较为不规范, 应对属性词进行过滤, 避免对核心主题词对发现的干扰。
如“ Accordingly , ||we||RF ||documented||PR a ||positive|| PR ||correlation||AS||AF||PR between levels of||MTA1||GE||AB and||STAT3||GP||GE in publicly available ||breast cancer||KW|| DI ||data||FP sets .” 中documented被标记为NCIt属性词, 但该词在句中词性为动词, 因此应对NCIt属性词标注后本身词性进行过滤。
(2) 属性实例发现实验
采用3.2节中的创新点句属性实例发现方法提取200条检索结果中的语义谓词属性实例以及本体属性实例, 得到非核心主题关系对661对, 其中利用语义谓词识别的关系对502对, 利用本体属性识别的关系对159对。观察表4的结果, 并对错误识别以及遗漏的属性关系对进行分析, 得到如下结论:
①基于语义谓词以及领域本体属性类别的识别方法都取得了较好结果, 说明该方法可以有效地识别创新点句中蕴含的语义关系对和领域属性关系对。
②识别结果受句法分析或标注结果影响。如“ ||We||RF ||undertook||VB a ||study||VB to ||correlate||PR||AS||AF ||lipid profiles||KW with||heterogeneous||PR||clinicopathological features|| KW of ||HER2-positive breast cancer||KW .” 在依存句法中将correlate词性错标为JJ, 导致关系抽取错误。“ ||This study|| TP ||investigated||VB||OB the ||interaction||IA||KW between ||MAPK||GP||GE||AB and ER alpha in ||breast cancer||KW||DI .” 中主题词“ ER alpha” 未识别为主题词类别, 因此遗失有意义的属性关系对。
③未考虑否定词。如“ There was no evidence for an ||association||AF||AS with postdiagnosis ||alcohol intake||KW and ||breast cancer survival||KW .” 中未考虑否定词“ no” 的作用, 对包含否定含义的关系对应予以剔除。
④基于本体属性类别识别准确率较低的原因为: NCIt中属性词类别纷杂, 有待进一步的规范和整理, 对不符合要求的属性词进行过滤。
| 表4 属性实例发现实验结果 |
针对领域科技文献, 分析创新点句的结构特征和语义特征, 借助领域本体, 在对句子进行语义角色标注的基础上, 采用一种语义标注、依存句法分析以及领域本体属性类相结合的方法, 对创新点句内部的核心主题词以及主题词对应属性实例进行识别, 并针对依存句法分析的特点, 设定组合术语识别模块以及连接词识别模块以提高主题词及对应属性实例识别的准确性。下一步的主要工作为: 探讨如何进一步利用领域知识提高属性识别的效果并对现有的属性实例进行整合, 以及将领域中分散的创新点句通过其属性汇聚起来的方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|