
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种基于项目聚类的自主推荐多样性优化算法
[姜书浩1  , 潘旭华
, 潘旭华1 , 薛福亮2 ]
, 潘旭华|
|


作者贡献声明:
姜书浩: 提出研究思路, 设计研究方案, 起草论文;
潘旭华, 姜书浩: 实验过程设计;
薛福亮, 姜书浩: 数据采集和分析, 算法的多样性分析由薛福亮完成, 算法比较以及复杂度的运算由姜书浩完成;
姜书浩, 潘旭华: 论文修改及最终版本修订。
【目的】通过聚类权重再分配算法优化推荐列表的多样性。【方法】提出一种提高推荐多样性的方法, 依据项目评分进行聚类, 参照阈值采用聚类权重再分配算法重新分配各聚类集的权重, 根据权重大小从各聚类集中筛选项目生成最终推荐列表。【结果】实验结果表明, 调整阈值由20缩小到1, 本文方法将三种算法在MovieLens数据集上生成的推荐列表的z-多样性值分别提高0.46、0.65和1.88, Book-Crossing数据集对应的z-多样性值分别提高0.38、0.49和0.76。【局限】仅适用于提高推荐列表的多样性, 对于总体多样性并没有涉及。【结论】有效提高推荐的多样性, 同时保证推荐的准确率和较低的时间复杂性。
[Objective] To optimize the diversity of the recommendation list by clustering weight redistribution.[Methods] This paper presents an algorithm to improve the recommendation diversity. Clustering is based on item scores. Clustering weight redistribution algorithm is used to reassign each clustering weight, and final recommendation list is generated from each cluster according to the weight.[Results] Experimental results show that z-diversity values of the recommendation list generated is increased by 0.46, 0.65 and 1.88 respectively for three algorithms on MovieLens data set, and z-diversity values is increased by 0.38, 0.49 and 0.76 respectively on Book-Crossing data set, when threshold is reduced from 20 to 1.[Limitations] This algorithm only applies to improve the recommendation list and does not involve the aggregate diversity.[Conclusions] This algorithm effectively improves diversity, while ensuring accuracy and lower time complexity compared with bounded greedy algorithm.
电子商务推荐系统通过对用户历史交易记录、产品具体信息及产品评价等信息的处理, 发现用户购物偏好并向其推荐感兴趣的产品[1]。许多成功的推荐技术被不断地研发并应用于各个领域, 例如音乐、电影、旅游、电子商务和电子学习等[2, 3, 4, 5, 6]。
很长时间以来, 衡量一个推荐算法是否成功的标准是预测项目评分的准确率。但是除此之外仍然有很多因素在用户满意度中扮演重要角色, 其中一个因素尤其重要, 即推荐列表的多样性[7, 8]。关于信息技术对于消费者购买行为影响的研究表明, 购买多样化产品的消费者的购买力要强于购买商品种类比较单一的用户。还有一些研究表明, 购买多样化商品的用户的忠诚度更高, 因此增强推荐列表的多样性, 进而提升用户购买清单的多样性对于提高企业的利润具有重要的意义。
本文提出一种基于项目聚类的提高推荐列表多样性的算法, 在轻微降低准确率的前提下提高项目种类的多样性, 该算法的基本思想是将项目聚类为几个集合, 根据不同集合的聚类权重选择项目建立推荐列表。通过这样的方法可以不必在较大程度降低准确率的情况下最大化推荐的多样性。该方法的优势有以下方面:
(1) 采用预测算法对未评分的项目进行评分后进行推荐, 不会改变现有的推荐算法;
(2) 允许用户在线自主调整推荐列表的项目多样性水平, 因此推荐系统的算法复杂度低, 使其有更高的可扩展性;
(3) 算法包含一个可调参数阈值, 用户可以用它调整自己推荐列表的多样性水平, 用户个人的调整独立于其他用户。
一些推荐算法的研究人员已经认识到, 预测的准确率不再是衡量一个推荐系统是否成功的唯一标准, 例如, Herlocker等[9]讨论了评价推荐系统时新颖性和小众性的意义, 而新颖性和小众性与多样性的概念密切相关, 因此增加推荐列表的多样性也就增加了给用户推荐新颖和小众商品的机会。
针对多样性问题, 很多学者进行了研究, Zhang等[10]提出一种二次规划的方法在准确率和多样性之间权衡, 同时介绍了使用一个参数控制推荐列表中的多样性水平。其效果与Smyth等[11]提出的改进后的有界贪婪选择算法相似, 但其算法的时间效率略差。本文提出的基于项目聚类的多样性改进推荐算法其运算速度比有界贪婪选择算法快得多, 并且同时实现了推荐结果的多样化。
刘慧婷等[12]提出一种基于物品推荐期望的Top-N推荐方法, 在向用户进行Top-N推荐时, 可以通过控制全体物品的推荐期望, 达到提高推荐总体多样性的目的。Ziegler等[13]定义了一种基于类别的推荐列表内相似性计算的量度值, 更进一步提出基于相似性值的推荐列表多样性的启发式算法, 其最重要贡献是展示多样化的推荐列表能够让用户整体满意度增加。李颖等[14]提出一种基于双重阈值近邻查找的协同过滤算法, 在一定程度上提高了推荐准确率, 多样性方面却没有太多改进。
Boim等[15]指出, 大多数的推荐算法通过某个阈值参数的调整来平衡多样性和准确率, 这种设定阈值参数的方式是有问题的, 因为针对某一特殊数据集的调整非常耗时, 而且当数据集发生变化时, 这一阈值也不再有效, 因此提出一种不涉及阈值参数的多样化方法。本文算法也使用一个阈值参数, 这个参数是由用户设定并且可以根据用户的个人偏好在线调整, 它并不需要为某个特殊的数据集进行专门的设定, 解决了算法扩展性差的问题。
对于多样性的计量在不同的层面有不同的计量指标, 其中一种计量方式只针对特定用户的推荐列表计算多样性, 例如姜书浩等[16]曾采用该多样性方法进行推荐, 这种方法测量的多样性反映的是用户推荐列表中所有项目的平均差异性。设L为集合的所有项目, 而u是集合中的所有用户, 特定用户的推荐列表的多样性为D(L(u)), 计算公式[17]如下:
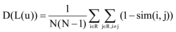 |
其中, L(u)∈ I是用户u的推荐列表, N=|L(u)|。 sim(i, j)是项目i和j的相似性值, 1-sim(i, j)被定义为项目的差异性值。
这一计量标准存在两个问题。一是由于推荐系统数据集的稀疏性, 遇到此类问题通常的方法是为缺少的评分设定默认值, 但是如果公式(1)中使用默认值替代缺少的评分值进行多样性计算, 对项目的评分预测虽然不会产生影响, 但是推荐结果会让推荐列表表现得非常多样化, 对用户造成很大的误导。例如在使用余弦相似性度量时, 评分的默认值一般都设置为0, 项目间相似性的计算结果便会接近于0, 而多样性值则接近于1。另一个问题是掩盖了多样化的难度, 原因是一些数据集本质上很难多样化。表1中显示了数据集中数据的两两相似值的平均值和方差, 该数据集采用的就是将0作为默认评分值, 并且采用余弦相似性计算, 表1的数据显示, Book-Crossing数据集的方差较低, 而MovieLens数据集的方差较高, 表明Book-Crossing数据集是难以多样化的, 原因是其数据的两两相似性具有较低的方差。
| 表1 数据的平均值和方差 |
本文提出一种有效的方法, 使用多样性的z-score测量数据, z-score也叫标准分数, 是统计学中的一种无因次值, 通过它可以准确表述数据在分布中的相对位置, 能够真实地反映一个数据距离平均数的相对标准距离。结合此方法计算出的多样性值称为z-多样性值, 而不是使用由公式(1)定义的绝对差异值。本文推荐列表中的z-多样性值的定义为:
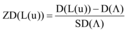 |
其中, 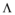
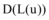
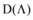

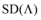
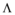
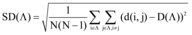 |
其中, N= 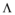
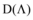
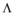
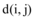
这种计量方法解决了以上两个问题: 虽然数据集中默认值也设定为0, 但计算得出的z-多样性值不会非常接近1, 并且更有利于增加多样性; 如果数据集中项目间的相似性标准差非常低, 那么根据公式(1)计算出的多样性值会误导研究者过低地评价多样性算法的效果, 但采用公式(2)计算出的z-多样性值, 能够独立于数据集中项目间的相似性方差, 更好地通过多样性值评价多样性算法。
与其他算法相似, 本算法也包含在线和离线两部分, 在算法的离线部分中, 除了构建模型之外, 还设定了N个项目聚类C = {C1, C2, …, Cn}, 其中N是推荐列表的大小, 该项目集使用标准的k-均值聚类算法建立[18]。项目依据系统内用户评分进行聚类分析, 并不涉及项目的具体特征。但是, 如果项目的内容信息比较完整并且可以根据其内容信息进行相似性计算, 则本文提出的算法也可以基于内容进行聚类。
本算法的核心在于聚类权重(CW)的设置, CW是一个包含(u, i)个元素的矩阵, 聚类Ci用于生成用户u的推荐列表, CWui为该聚类在最初推荐列表中项目的数量。例如, 如果CWui=5, 这就意味着聚类Ci向用户推荐列表中贡献5个推荐项目(预测评分最高的5个), 聚类权重之和对所有用户都应该等于推荐列表的长度N。
聚类权重再分配算法:
输入: L(u):用户u的推荐列表, C: 项目聚类集
输出: CWu: 用户u的各聚类权重
①CWui =count(Ci ∩ L(u))
②for all Ci ∈ C do
③ while CWui > 阈值 do
④ k = argmin (CWu)
⑤ CWuk = CWuk + 1
⑥ CWui = CWui - 1
⑦ end while
⑧end for
该算法计算了每个特殊用户的聚类权重, 包含两个参数: 由预测算法产生目标用户u的推荐列表, 以及聚类集C ={C1, C2, …, CK}。
算法的第①行为初始化聚类权重。每个聚类权重CWui都被设定为聚类Ci与最初推荐列表项目交集的个数, 也就是每个用户u由聚类生成的最初的项目集中与预测算法生成的推荐列表中相同项目的个数。这一设定保证了由最初预测算法生成的项目集合成为最终推荐列表成为可能。在第②行, 算法开始分配那些比给定的阈值大的聚类的权重, 通过调整阈值, 用户可以在准确率和多样性之间进行权衡。如果阈值设定得较大, 用户会得到准确率更高但多样性较差的推荐结果; 如果阈值设定得较小, 则用户得到的推荐结果更加多样化, 但准确率会有一定的损失。在极端情况下, 如果阈值等于N, 则由预测算法生成的推荐列表也就是最后的结果。算法将大于阈值的聚类的权重分配给那些具有最小权重值的聚类, 如算法中③-⑦行所示, 如果在第④行查找到的最小阈值不止一个, 则对其中一个进行阈值再分配, 选择的方式采用随机方法, 这样不会影响算法的结果。通过这样的方式, 算法尽可能地将权重分配给不同的聚类以增加推荐结果的多样性。
在生成用户u的聚类权重之后, 接下来为用户生成推荐列表。采用方法如下: 将用户u的各聚类集内部的项目按照预测评分从高到低的顺序排列, 判定该聚类的权重是否大于0, 如果大于0, 则取出一个项目放入最终推荐列表, 并将其权重减1。对所有聚类重复前面的操作直到所有的聚类权重都为0。因为所有权重之和与推荐列表的大小相同, 所以当所有的聚类权重都为0时, 最后的推荐列表也随之生成。
召回率表示一个用户喜欢的产品被推荐的概率, 是反映推荐效果的一个重要指标。因此实验采用召回率测定推荐的准确率, 随机选取2%的评分生成子样本作为探测集, 其余的评分作为训练集。而测试集T是由探测集中所有5星评价数据组成的。训练集的召回率计算方法如下:
在测试集中, 对于每一个用户u给出5星评价的项目进行如下操作:
(1) 由用户u随机选择300个未评分的项目;
(2) 对这300个项目和测试集中5星评价的项目同时进行预测评分;
(3) 从这301个项目中选择N个具有最高评分的项目组成推荐项目列表, 如果测试项目在推荐列表中, 则测试成功, 否则失败。
实验中生成的最初推荐项目集采用三种不同的协同过滤算法, 分别是基于项目的协同过滤算法[1]、基于用户的协同过滤算法[19]和基于奇异值分解的协同过滤算法。每一种算法在具体应用中虽然会有些变化, 但是这些算法的基本表述如下: 基于项目的协同过滤算法是通过用户对不同项目的评分来评测项目之间的相似性, 基于项目之间的相似性做出推荐; 基于用户的协同过滤算法通过不同用户对项目的评分来评测用户之间的相似性, 基于用户之间的相似性做出推荐; 基于奇异值分解(SVD)的协同过滤算法采用SVD方法将不同用户分解为不同的特征以及这些特征对应的重要程度, 利用用户以及项目之间的潜在关系, 使用初始评分矩阵的奇异值分解法抽取一些本质的特征[20]。
使用两个公开数据集评估本文的算法:
(1) MovieLens数据集: 此数据集共包含6 040个用户对3 900部电影的1 000 000条评分记录。
(2) Book-Crossing数据集(Book-Crossing图书社区): 包含278 858用户对271 379本书籍的1 149 780个评分(1-10)。由于计算和存储容量的限制, 实验中选择评分次数大于或等于22次的用户, 以及被评分大于或等于10次的书籍作为实验的数据集。缩减后的数据集包含41 524个评分, 3 946个用户, 以及2 021种书籍。
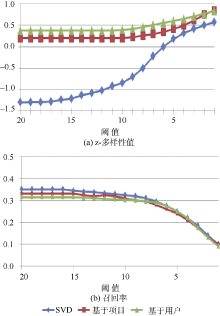
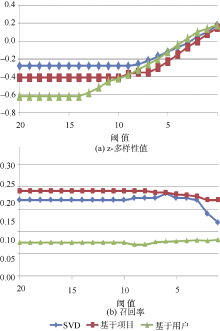
图1和图2分别为两个数据集在设定阈值函数的情况下所有的多样性结果。
 | 图1 MovieLens数据集测试结果 |
 | 图2 Book-Crossing数据集测试结果 |
图1(a)显示了在MovieLens数据集中z-多样性值随阈值的变化情况。实验中降低阈值时, 三个预测算法的z-多样性值都会增加。增幅最大的是SVD方法。这是因为使用SVD方法产生的前20推荐项目相比其他方法具有更低的初始多样性。此外, z-多样性值小于0, 表示该推荐列表的多样性低于数据及整体多样性的平均值, 也意味着该列表的多样性更容易提升。同时说明, 基于项目和基于用户协同过滤算法产生的推荐列表的前20个项目的多样性高于数据集的平均多样性, 所以用这两种方法增加多样性会受到更多的限制。三种预测方法能够达到的最大z-多样性值是非常接近的, 也就是说, 无论初始的z-多样性值取值如何, 在经过基于聚类的多样性优化算法修正之后, z-多样性值都能达到相同的水平, 这是因为随着阈值变小, 推荐列表逐渐趋向于由相同的聚类集合产生。
图2(a)显示了Book-Crossing数据集中z-多样性值随阈值的变化情况, 随着阈值的减小, z-多样性值逐渐增大。对于Book-Crossing数据集, 所有的预测算法产生的最初的z-多样性值都为负值, 也就是最初的推荐列表的多样性是低于数据集的平均多样性值的。图2所示多样性优化算法增加了所有预测算法的多样性。
图1和图2显示, 对于所有的数据集, 当阈值变大时, 多样性很小或几乎没有变化, 当阈值变小时, 多样性会明显增加, 但召回率会降低。当调整阈值由20减小到1时, 本文方法将以上三种算法在MovieLens数据集上生成的推荐列表的z-多样性值分别提高了0.46、0.65和1.88, Book-Crossing数据集对应的z-多样性值分别提高了0.38、0.49和0.76。但在这两个极端数值之间有很大的空间供用户调整, 用户可以在不采用极端小的阈值情况下, 根据自己兴趣偏好在多样性与准确率之间进行权衡, 保证有效多样性的同时轻度降低召回率。这里阈值参数的调整并不是由系统管理员完成, 而是由每个用户独立自行调节。
虽然本文提出的基于项目聚类的自主推荐多样性优化算法是一种项目多样化的快速算法, 但是其多样化效果相对于其他方法的表现也是研究的一项重要内容。下文将该方法与其他的多样性算法进行比较。
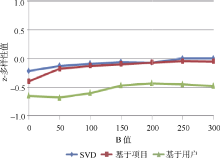
增加多样性的最简单直接的方法是在推荐过程中增加一些随机因素, 具体的方式是根据评分对推荐项目进行排序, 在推荐项目的前B个项目中随机选择N项(B> N), 设定N为20。
图3和图4分别显示了两个数据集相对于变量B取值时z-多样性值的变化情况。对于MovieLens数据集, 随机方法在SVD算法中z-多样性值有小幅度增加, 而在基于项目和基于用户算法中z-多样性值又有小幅度减少, 如图3所示。从图中的曲线可以得出, 当增加备选集合B的数量时, 推荐列表的z-多样性值趋于接近数据集的平均z-多样性值。这是因为如果采用z-多样性值进行表示时, 推荐列表的z-多样性值趋于0。从这些结果中可以得出, 随机算法在增加多样性方面并没有明显效果。
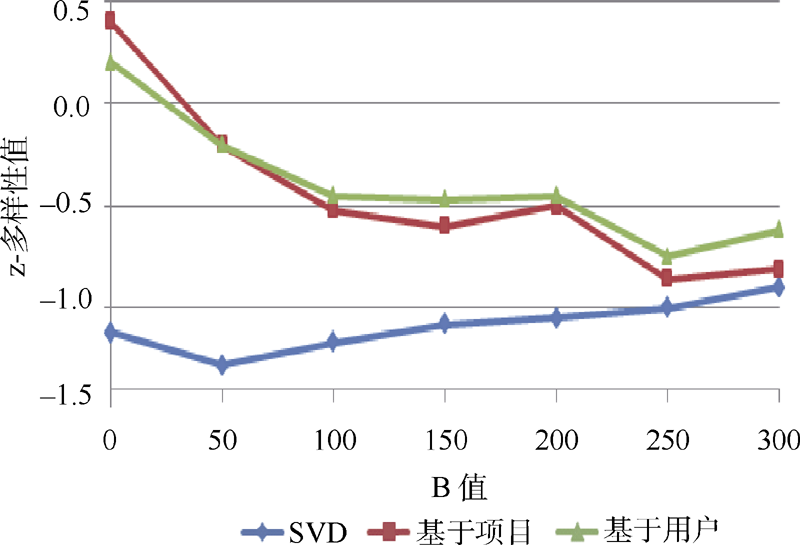 | 图3 MovieLens数据集 |
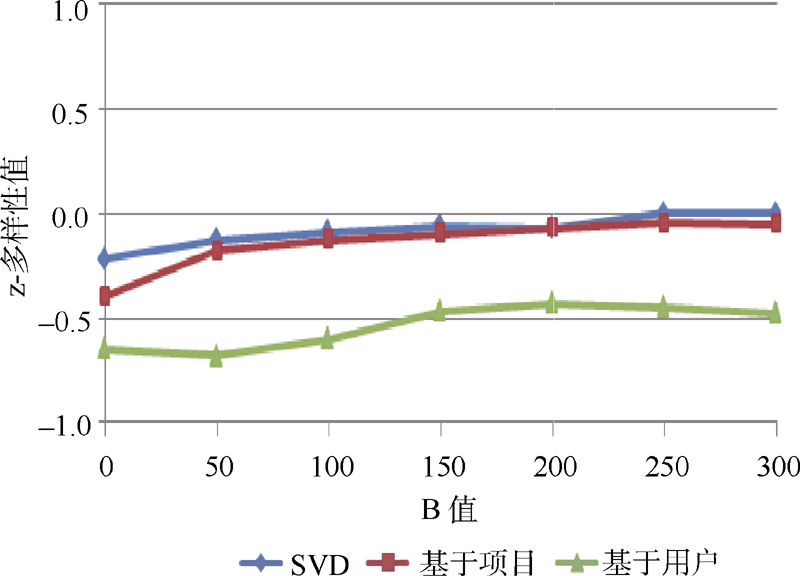 | 图4 Book-Crossing数据集 |
基于项目聚类的多样性优化算法在时间和空间复杂度方面都是非常高效的。该算法在离线状态下建立项目聚类, 采用的方式是k-均值聚类算法, 其中k-均值复杂度为O(INmn), 其中I是迭代的次数, N是聚类的数目, m是项目数, n是用户数。I值可以有效地界定[21], N又明显小于m, 所以离线状态下的聚类时间复杂度可以记为O(mn)。
在线状态下, 推荐系统使用离线状态下的数据结构为特定用户创建一个推荐集合, 进行多样化过程。使用聚类权重再分配算法, 对特定阈值下聚类权重进行计算, 这一步的时间复杂度为O(N), 其中N为聚类的数目并且已假定花费的时间是恒定的。从推荐集合中根据其预测评分从高向低取出一个项目判断该项目所属聚类的权重, 如果权重大于0则将其减1, 并将该项目放入最终推荐列表, 否则丢弃该项目。重复上面的操作, 直到所有聚类权重均为0为止。因此在最坏的情况下, 列表前N项多样化的时间复杂度为O(m), 其中m为项目集中项目的个数。表2显示了本文提出的多样性算法与有界贪婪算法[11]时间复杂度的比较数据, 该算法生成用户推荐列表的时间远低于有界贪婪算法, 其中有界贪婪算法后面的数字是指候选项目的数目。
| 表2 生成用户推荐列表的时间(毫秒) |
基于项目聚类的多样性优化算法对空间要求也非常低。仅需要额外O(m)大小的内存空间, 用于存储离线状态下项目的聚类信息, 以及O(n)大小的空间, 用于存储在线状态下的聚类权重, 其中m是项目的数量, 并且n是聚类的数目。
本文提出一种提高推荐列表多样性的方法。实验结果表明, 该方法在轻度降低推荐准确率的同时有效地提高了推荐列表的多样性水平, 同时为每一个用户提供了自己调整推荐列表多样性水平的接入点, 该方法在实现多样化的同时还具有较低的计算时间复杂度。当然这一方法要真正用于现实推荐系统中, 还需要提供一个交互界面以方便用户通过设定阈值来调节推荐列表的多样性水平。
在上述的实验中, 采用的是基于项目评分的聚类策略, 如果系统中提供了有关项目的内容信息, 并且用该信息进行项目之间的相似性计算, 那么系统可以采用基于内容的聚类策略, 而本文提出的方法仍然适用于基于内容聚类的多样性推荐。
除了用户列表的多样性之外, 多样性的另一个标准是总体多样性。总体多样性反映推荐系统向所有用户推荐结果的覆盖情况, 较高的总体多样性不仅能给用户带来更好的推荐体验, 同时能带来更加合理的经营模式[22]。在未来的工作中, 将分析本文提出的方法对总体多样性的影响。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|