{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种基于加权LDA模型和多粒度的文本特征选择方法
[李湘东1, 2 , 巴志超1 , 黄莉3  ]
]
]
|
|


作者贡献声明:
李湘东: 提出研究思路, 设计研究方案;
巴志超: 采集、清洗、分析数据, 完成实验, 撰写论文;
黄莉: 探讨、分析研究思路及方案的可行性。
【目的】为改善图书和期刊书目信息的分类性能, 结合书目文本的体例结构特点, 提出一种基于加权LDA模型和多粒度的文本特征选择方法。【方法】在点互信息(PMI)模型的基础上, 结合词性、位置等要素修正特征词的权重并扩展至LDA的生成模型中, 以抽取表意性较强的粗粒度特征; 结合TF-IDF计算模型采用一定策略获取细粒度特征, 基于多粒度特征作为核心特征词集表征书目文本; 采用KNN、SVM等算法实现书目文本的分类。【结果】在自建图书、期刊材料上进行分类实验, 与LDA方法以及传统特征选择方法相比, 该方法分类准确率分别平均提高3.60%和4.79%。【局限】实验材料的数量以及丰富度有待进一步扩展; 需探索更多的加权策略模型进行实验, 以提高书目文本的分类效果。【结论】实验结果表明, 该方法是有效的、可行的, 能够提高特征选择后的特征词集对文本的表示能力, 从而提高文本分类的准确率。
[Objective] To improve the classification performances of bibliographic information such as books, academic journals, combining with the structure characteristics of bibliography texts, this paper proposes a new feature selection method based on weighted Latent Dirichlet Allocation (wLDA) and multi-granularity.[Methods] On the basis of Pointwise Mutual Information (PMI) model, the method improves the feature weights from the elements of location and part of speech, and extends the process of feature generated by LDA model to get more expressive words. This paper adopts a certain strategy to obtain fine-granularity combined with TF-IDF model and uses multi-granularity features as the core feature sets to represent bibliographic texts. Realize bibliographic texts classification by applying KNN and SVM algorithms.[Results] Compared with the LDA model and traditional feature selection methods, the classification performances on the classifiers of the self-built corpuses for books and journals increase by an average of 3.60% and 4.79%.[Limitations] The experimental materials need to be expanded and more weighted strategies need to be explored to improve the classification performances.[Conclusions] Experimental results show that the method is effective and feasible, and can increase the expressive ability for the feature sets after feature selection, so as to improve the classification effect of text classification.
文本分类是模式识别、机器学习及数据挖掘领域研究的重要课题, 其主要任务是通过建立能够描述和区分数据类或概念的模型, 实现对未知标签数据的分类[1]。目前, 主要采用向量空间模型进行文本信息结构化表示, 然而该模型存在特征空间的高维性和数据稀疏性问题。高维的特征空间不仅增加系统运算开销, 而且包含大量无效、冗余的特征, 降低了文本分类的精度。因而, 在文本分类中寻求一种有效的特征选择方法显得至关重要。有效的特征选择方法可以降低特征向量的维数, 去除冗余特征, 保留具有较强类别区分能力和表意性较强的特征, 从而提高分类的精度和防止过拟合[2]。
本文实现一种基于加权LDA模型和多粒度的文本特征选择方法。鉴于不同词性、位置的特征词对书目文本信息的表示能力不同, 本文综合考虑图书书目文本信息的标题、摘要、关键词等要素差异并构造复合权值, 将特征加权扩展至LDA模型中, 试图使获取的特征词不局限于高频词而更能代表书目的文本信息, 同时避免点互信息(PMI)模型中低频词作用被放大的缺陷; 在此基础上, 结合TF-IDF计算模型采用一定策略获取多粒度粗细特征, 作为书目文本信息的核心词特征集, 以增强特征词对书目文本的描述能力, 采用KNN、SVM等算法实现对书目文本的分类。
特征选择是在原始特征集中依据某种评估函数选出对分类贡献较大的特征词集, 常用的方法有文档频率(DF)、信息增益(IG)、互信息(MI)、卡方统计(CHI)等。然而基于传统的统计方法忽略特征词在文本中的含义, 且无法获取文本中的语法、组织结构等语义信息。基于LDA模型[3]可有效挖掘文本隐含语义信息等优势, 目前被广泛应用于文本分类领域, 并在实际问题中得到大量应用, 取得较好的效果[4, 5, 6, 7, 8, 9, 10]。李峰刚等[4]利用LDA主题模型进行建模和特征选择, 实现对新闻文本集的分类; 胡勇军等[5]通过LDA模型对特征空间进行语义扩展, 实现对短文本的分类; 黄小亮等[6]使用LDA主题模型实现对软件缺陷的自动分派; Chen等[7]基于LDA模型用于计算文本间的相似性, 从而对搜索记录数据集进行分类; Ni等[8]、Bao等[9]、Elhadad等[10]也都将LDA主题模型应用于文本分类中。
上述研究大多是直接将LDA模型应用到文本分类中, 标准LDA模型同等对待每个特征词而不考虑特征词的权重, 其模型通常假设特征词权重并不是需要的, 从信息理论学和语言学的观点角度来讲, 这种假设是不成立的[11]。不同词性、位置的特征词对书目文本的贡献程度不同。对于图书而言, 书名、目录、内容提要等要素中的特征词往往更能有效代表图书的主要内容, 而对于期刊, 标题、摘要和关键词, 是对学术研究的概况和提炼, 相对更能反映文章的主要思想。因此, 区别对待不同词性、位置等要素的特征词对文章的贡献度, 根据不同的特征信息赋予特征词不同的权重, 并将加权策略扩展至LDA模型特征词的生成过程中, 有助于获取更具表意性的特征词, 提高书目文本分类的效果。合理的加权策略已应用于LDA模型研究中, Wilson等[11]通过实验证明基于LDA模型合理的加权策略会使高频词汇(非停用词)自然分配, 而不会被强制分配或随机分散到各主题中; Ramage等[12]提出一种基于LDA模型的文档标签词频加权策略; 李湘东等[13]将加权LDA模型应用于对新闻文本数据的挖掘。
不同粒度的特征词在表示文本时具有不同的描述能力[14]。词最常用来表示文本的特征, 也是最细粒度的特征。隐含主题模型则利用有限的K个隐含主题描述文本, 每个隐含主题承载着一个粒度较粗的主题, K越小, 表示的粒度越粗糙[15, 16]。如果仅使用词特征对文本进行表示, 会存在由于粒度太细而造成的稀疏性, 在计算两篇内容非常相近但措辞不同的书目文本时, 使得词向量间的相似度较小。通过隐含主题表示, 同义或相似的词会和相同的隐含主题相对应, 从而克服稀疏性。而仅使用粒度较粗、结果较泛化的LDA隐含主题模型表示文本时, 却又无法对书目文本内容进行细节的详细描述, 不能对同一主题下不同侧面的文本信息进行有效区分。如“ JAVA编程” 与“ 数据库教程” 都属于“ 计算机” 类, 但二者之间的区别无法仅用LDA模型进行有效描述和区分。因此, 本文将加权LDA模型和词特征表示相结合, 采用多粒度特征表示文本。
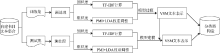
基于加权LDA模型和多粒度特征选择的书目文本分类流程如下:
(1) 对自建书目文本集合进行预处理。
(2) 结合书目信息的文本特点, 对特征词分别进行TF-IDF值计算和基于LDA模型的权重调整, 以获取粗细多粒度特征表示文本信息。
(3) 采用向量空间模型进行文本表示, 并采用KNN、SVM等算法构造文本分类器进行分类。
具体流程如图1所示:
 | 图1 基于加权LDA和多粒度特征选择的分类模型 |
文本预处理模块主要是针对自建书目文本集合进行分词、过滤和词性标注(去除标记词、虚词与标点符号)以及命名实体识别。本文主要采用中国科学院计算技术研究所的ICTCLAS分词系统①(①http://ictclas.nlpir.org/.)进行分词, 该系统可以进行中文分词、词性标注、命名实体识别, 同时支持用户词典, 具有较高的分词正确率, 能够保证较好的分词效果。
(1) LDA模型原理
LDA是一个三层贝叶斯概率模型, 通过将高维的文本集合映射到低维的潜在语义空间, 即认为文档是主题的混合, 主题是词空间上的分布, 将隐含主题看做是词特征的软聚类, 从较抽象的层面实现对文本信息的概括。模型通常采用Gibbs Sampling推理方法估计当前特征词wi的主题zi的后验分布。最终的参数采样公式[3]如下:
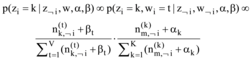 |
其中, zi表示第i个特征词对应的主题变量; ¬ i表示剔除其中的第i项; z﹁i表示所有主题zk(k≠ i)分配; 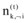
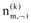
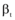
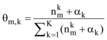 |
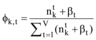 |
最终得到的 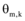

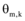
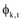
(2) 特征词权重调整
基于LDA模型进行文本分类时, 获取的主题-特征词分布会向高频词倾斜, 导致能够代表文档的多数词被少量高频词淹没, 降低了模型对文本信息的描述能力[17]。为此, 使用LDA模型时通常做法是借助停用词表的方法去掉这些高频词(如停用词、虚词等), 但此方法并不能完全过滤掉这些表意性较差的特征词, 它们仍会以较高的概率分配到各主题中, 不能很好地表达文本的语义信息。
基于互信息特征选择方法具有时间复杂度低、便于理解等优势, 但存在分类精度较低、忽略特征词位置差异等信息的缺陷, 而且在该模型中低频词的作用往往被放大[18, 19], 导致许多对文本表示能力有限甚至是噪音的低频词被选中用于文本表示。这不仅使得数据稀疏性问题难以解决, 同时也影响了特征词集对文本的表示能力。为降低这些特征词在各文本中出现的概率, 提高标题、关键词、摘要等位置上的表意性较强的特征词出现的概率, 本文在点互信息模型基础上, 通过对LDA模型扩展改变模型生成特征词的过程, 以提高频次较低但表意性较强的特征词在生成过程中的采样分布, 此举也相应地降低了频次较高但表意性较差的特征词在生成过程中的采样分布。
一个特征词的生成不仅同采样公式 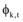
 |
为此, 本文将特征词的权重weight(t, d)与采样公式 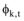
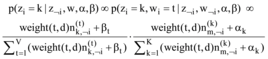 |
为区分书名文本信息关键位置上的特征词和其他特征词对文章的贡献度, 在点互信息的基础上, 综合考虑词性和词的位置等因素, 根据不同的特征赋予特征词不同的权重, 将基于权重调整的互信息模型扩展至LDA模型中。特征词wi与文档d的点互信息计算公式[20]如下:
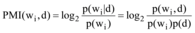 |
根据书目文本的结构特点, 将每个文本划分成三个文本特征子集T1、T2、T3, 对于图书实验材料, T1由书名、目录及内容提要的特征词构成, T2由前言及段首句部分的特征词组成; 而对于期刊而言, T1由标题、摘要、关键词部分的特征词组成, T2由副标题和段首句部分的特征词组成, T3=T-T1-T2。根据研究表明[21]: 三个特征子集里, 特征词对文本表示能力上的重要性比例大约为2.5:2:1。根据公式(6)分别计算特征词wi在每个特征子集Tj(j=1, 2, 3)的点互信息值PMI(wi)j, 最后笔者在公式(6)的基础上对文档d的点互信息计算公式调整如下:
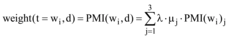 |
其中, 参数 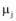
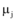
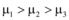
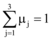
在基于LDA模型对特征词进行权重调整时, 同时对每一个文本中的特征词进行TF-IDF值的计算并进行排序。由于在进行向量空间模型表示时维度较高且极度稀疏, 本文选取TF-IDF值大于δ (δ 为百分比)的特征词作为较细粒度的特征来表示文本, 对于书目文本di, 其细粒度特征向量表示为di=(wi1, wi2, wi3, …, win)。这样在保证不影响文本特征提取的前提下, 最大可能地减少文本特征向量表示的维度。
同时, 选取LDA建模结果主题-特征词矩阵中的Top-N个主题特征词作为表示书目文本的较粗粒度的特征。 对于文本di, 其粗粒度特征向量表示为di=(ti1, ti2, ti3, …, tim)。采用多粒度特征表示书目文本, 既克服了粒度太细造成的稀疏性问题, 同时也保证向量表示对文本细节的描述能力。因此文本最终可表示为di=(wi1, wi2, wi3, …, win, ti1, ti2, ti3, …, tim), 且尽量保证每个书目文本核心词特征向量的维度相同。由于某些特征词既可以作为细粒度特征, 又可以作为粗粒度特征, 若win与tim指向同一特征词时, 按不同粒度特征对待。
为验证该方法对图书和期刊等书目信息的适用性和有效性, 本文采用信息管理领域的真实数据作为实验材料, 由笔者从某大学图书馆的馆藏目录OPAC和中国知网的电子期刊数据库中, 分别选取分类在《中图法》体系下体育、计算机技术和军事三个类别中的部分图书和期刊文献进行实验。
每一条图书文本信息主要取其书名、目录、内容提要等作为分类实验材料, 文本平均长度在150字左右, 期刊文献取标题、摘要、关键词等作为一个文本, 每个文本平均长度约为280字。三个类别共2 940篇文本, 图书文献共1 350篇, 期刊文献1 590篇。采用三折交叉实验法, 将图书、期刊文本分为三份: 两份为训练集, 一份为测试集; 循环测试三次, 取平均值为测试结果。
由于本研究需要分类过程中各环节透明化, 以减少中间过程的不可控因素, 因而选取KNN、Naï ve Bayes以及SVM三种算法构造分类器。分类效果评估指标使用文本分类中常用的查准率、查全率以及F1值。
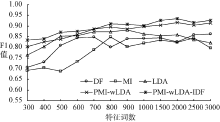
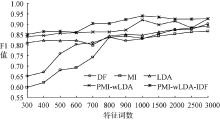
为综合评估本文提出的基于加权LDA模型和多粒度的文本特征选择方法的有效性, 将基于文档频率、互信息、LDA模型作为Baseline方法, 与本方法(简称PMI-wLDA-IDF)进行对比实验。LDA模型采用Gibbs Sampling推理方法进行超参数的估计, 其模型中的参数设定为: k=3, α =50/k, β =0.01[3], 迭代次数设置为1 000次。根据文献[21]中的实验结果, 实验中设置μ 1=0.45, μ 2=0.35, μ 3=0.2。限于篇幅, 本文只展示基于SVM对期刊、图书的分类效果。针对SVM分类器, 采用十折交叉验证寻找最优参数, 最终获得最优惩罚因子: C=32, RBF核参数: g=0.125。针对自建图书、期刊分类材料, 各特征选择方法在不同特征词数下的分类效果, 如图2和图3所示:
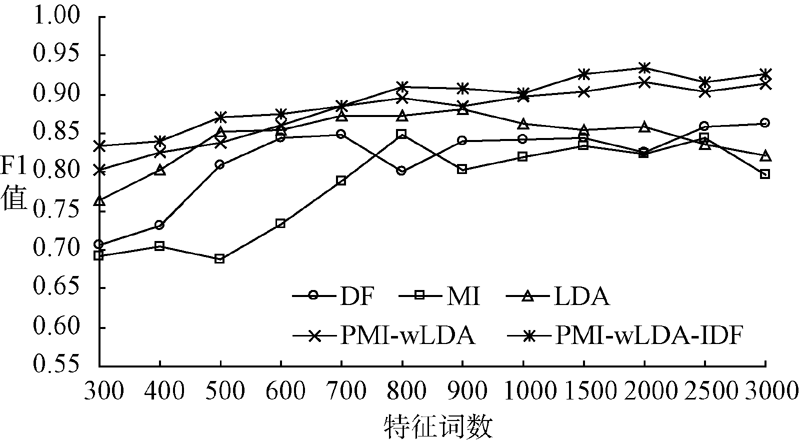 | 图2 期刊材料下不同特征选择方法分类效果对比 |
 | 图3 图书材料下不同特征选择方法分类效果对比 |
从实验结果可以看出, 针对图书、期刊实验材料, 基于LDA模型的方法都要好于基于传统的文档频率、互信息特征选择方法。针对期刊实验材料, 本文提出的在点互信息模型的基础上, 将加权策略扩展至LDA模型的特征选择方法(简称PMI-wLDA), 相对于传统的LDA模型, 分类准确率平均提高了2.31%; 针对图书实验材料平均提高了3.75%, 这说明该方法通过提高表意性较强的特征词出现的概率, 降低频次较高但表意性较差特征词和低频词的权重, 能够提高最终的分类准确率。在此基础上结合TF-IDF模型获取多粒度粗细特征表示文本时, 针对图书、期刊实验材料分类准确率相对于传统的LDA模型分别平均提高3.60%、4.79%, 说明基于多粒度粗细特征表示文本时, 既克服了粒度太细而造成的稀疏性, 同时可以对文本从细节方面进行详细的描述, 提高了特征选择后的特征词集对文本的描述能力。基于该方法针对期刊实验材料特征词的权重变化如表1所示, 只列出计算机类别下Top-20特征词的权重变化情况。
| 表1 各方法下特征词及权重变化情况 |
从表1可以看出, 基于互信息(MI)方法的Top-20特征词, 无法看出该类别是关于计算机的类别, 对于“ 认为” 、“ 受到” 等词都为表意性较差、对文本的理解贡献度较低的特征词。而在LDA模型方法的Top-20特征词中, 一定程度上增强了特征词的表意性, 从“ 视觉” 、“ 计算” 等词可以大致看出该类别为计算机类别, 通过LDA模型可以挖掘文本隐含主题, 从较抽象层面实现对文本的概括。然而该模型获得的主题-特征词分布为较粗粒度特征, 获取的特征词较为笼统, 无法从较细层面理解类别的文本信息, 无法具体知道关于计算机哪方面的内容。结合传统的特征选择方法, 并将特征加权策略扩展至LDA模型中的PMI-wLDA方法, 能够使获取的特征词更具有表意性, 从“ 图像” 、“ 基因” 、“ 粒子” 等词可以看出该计算机类涉及的具体研究方向。在此基础上结合TF-IDF模型采用多粒度粗细特征表示文本, 从两方面对文本信息进行描述, 一定程度上增加了特征词对文本的表述能力, 从而提高文本的分类准确率。
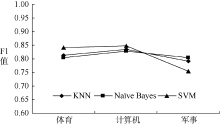
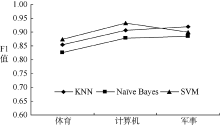
为分析不同分类算法针对不同材料在各类别上的分类性能, 本文采用KNN、Naï ve Bayes以及SVM三种算法构造分类器, 对图书、期刊实验材料进行分类, 针对KNN算法, 经过实验比较, 最终选择K=11, 相似度计算采用余弦相似度方法, 实验结果如图4和图5所示, 分别显示采用KNN、Naï ve Bayes、SVM分类器基于该方法对图书、期刊实验材料的分类效果。可以看出, 基于不同分类器采用该方法对期刊的分类效果要好于对图书的分类效果。这是由于期刊相对于图书实验材料而言, 内容学术性较强, 用词比较严谨, 因此三种分类算法在期刊材料上的分类效果要好于在图书材料上的分类效果。另外, 图书、期刊实验材料由笔者直接取自于馆藏目录或电子期刊数据库, 类别间界定不够严谨和清晰, 专业性质及文本表述上也不够正规, 不如搜狗、复旦等专门语料库那样经过众多专家挑选、审查、讨论并严格筛选。但基于该特征选择方法针对图书、期刊材料的分类准确率几乎都达到了80%以上, 说明该方法在图书、期刊等书目信息的分类中具有一定的有效性。
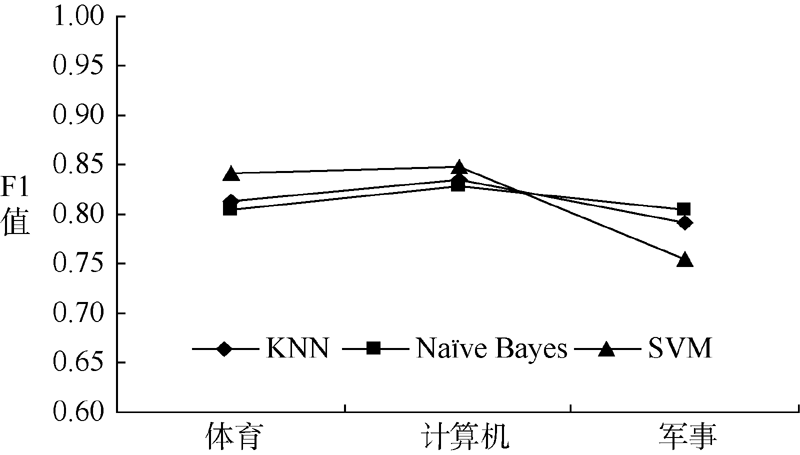 | 图4 图书材料下不同分类算法的分类效果比较 |
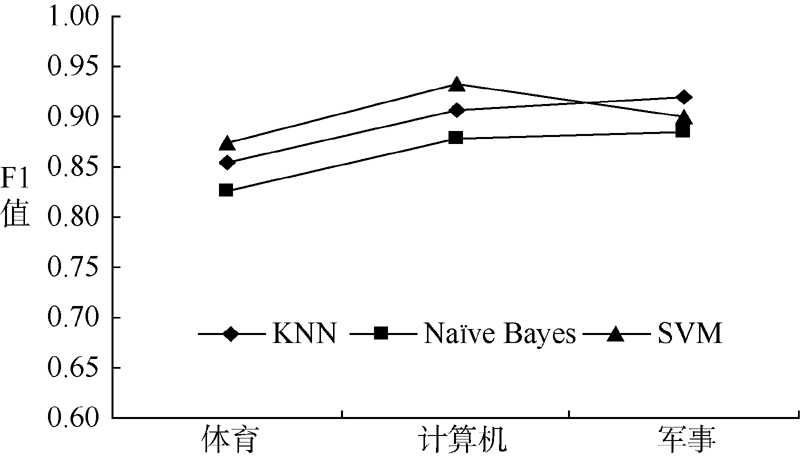 | 图5 期刊材料下不同分类算法的分类效果比较 |
基于向量空间模型进行文本表示时, 需将文本表示为词频数和文本数大致相同的矩阵, 而矩阵中的行列向量都具有较高的维度且极度稀疏, 最终导致计算非常低效。而通过特征选择方法可以有效降低文本表示模型的维度, 减少算法运行的开销。因此, 本文提出一种基于加权LDA模型和多粒度的特征选择方法, 在点互信息模型的基础上, 将加权策略扩展至LDA模型的生成过程中, 以提高标题、摘要等位置上特征词的权重, 获取表意性较强的特征词; 同时结合TF-IDF模型计算方法获取多粒度粗细表征书目文本信息。通过在真实语料上的实验, 验证了该方法在书目文本分类中的有效性。该方法能有效增加特征词对书目文本的表示能力, 相对传统特征选择方法, 最终的分类准确率有所提高。今后的研究工作中, 将探索更多的特征加权策略模型, 将传统的特征选择方法和LDA方法相结合, 以提高文本分类的准确率; 同时在多种类型数据集上进行实验验证, 以推广该改进方法的适用性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|