

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向论文相似性检测的数据预处理研究
[刘伙玉1, 3 , 王东波2  ]
]
]
|
|


作者贡献声明:
刘伙玉: 提出研究思路, 设计并实现研究方案, 起草论文;
王东波: 论文审阅及最终版本修订。
【目的】探究论文相似性检测中数据预处理的数据问题及相关方法。【方法】对数据进行细致的分析, 采用基于规则的方法、基于统计的方法、基于语义的方法进行预处理。【结果】揭示论文相似性检测中原始数据存在的数据质量问题, 并在此基础上给出数据预处理模型。【局限】语料规模有限, 且暂未考虑对语料中图表内容的预处理。【结论】数据预处理有助于提高论文相似性检测结果的准确性; 有效结合基于规则、统计、语义的三种方法有助于提高数据预处理效果。
[Objective] Explore the data issues and methods of data preprocessing on paper similarity detection.[Methods] This paper makes a deep analysis to original data, and briefly introduces three data preprocessing methods, namely rule-based method, statistics-based method and semantic-based method.[Results] There are many data problems in the original data, based on which it describes the model of data preprocessing.[Limitations] The number of the corpora is limited and the preprocessing of figures and tables is not included.[Conclusions] Data preprocessing can help to improve the accuracy of paper similarity detection, and using the three methods together can improve the effect of data preprocessing.
大数据时代的到来, 各行各业的决策从“ 业务驱动” 开始向“ 数据驱动” 转变, 从海量数据中获取潜在的、有价值的信息成为学术、商业、军事等领域关注的重点。然而数据中存在的质量问题, 直接影响了数据的信息服务质量。论文相似性检测就是判断一篇论文的内容是否与其他某篇或多篇论文相似, 并给出相似度结果, 其检测数据中存在的质量问题也严重影响了检测结果的准确性。
关于自然语言文本相似性检测的研究开始于20世纪90年代, 自1991年Richard采用关键词匹配算法开发Word Check[1], 该领域研究取得了较大的进展, 出现了多个抄袭检测系统。目前针对文本相似度问题的检测方法主要有基于统计学和基于语义理解的相似度计算方法。然而由于论文相似性检测对象的特殊性, 其算法也有相应的特殊性; 国内学者提出了相应的算法, 包括金博等[2]提出基于篇章结构相似度算法, 王森等[3]提出基于文本结构树的检测算法, 秦玉平等[4]、赵俊杰等[5]提出基于局部词频、段落词频的检测算法, 赵俊杰等[6]提出基于自动文摘的论文抄袭检测算法等。
关于数据预处理的研究已经很成熟, 这方面的成果也较多。数据预处理一般包括数据清洗、数据集成、数据变换、数据归约4个方面, 每个方面都有不同的技术手段。数据预处理技术应用领域广泛, 如生物、物理、化学、地质科学等, 同时在大数据时代其重要性更加突显, 如在数据挖掘[7]、Web日志挖掘[8]、数据仓库[9]等方面的应用。
然而目前论文相似性检测的研究主要集中于相似性检测核心阶段, 着眼于相似性检测算法的研究与探讨以及系统的开发, 而忽视了对数据预处理的研究。面向论文相似性检测的数据预处理方面的研究相对较少, 在文献[10]中采用XML技术对数字报刊中的数据进行存储, 并对数据进行标准化、消除重复项、补全缺失数据等处理, 但未涉及对具体的学术论文进行结构化处理以及其他针对性的处理。在学术论文构成要素识别与抽取方面较多采用机器学习的方法[11, 12], 未涉及其他数据质量问题的预处理。
本文基于以上内容, 重点针对论文相似性检测中的数据预处理进行分析与研究。数据预处理是论文相似性检测前的数据准备工作, 它以领域知识作为指导, 用新的数据模型组织原始数据, 去除与相似性检测无关的要素, 调整数据格式和内容, 一方面使得数据更符合检测算法的需要, 减少了检测内核的数据处理量, 提高了检测效率; 另一方面也提高了相似性检测结果的准确度和可信度。
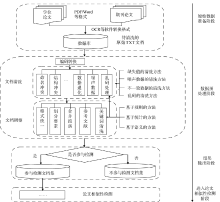
论文相似性检测针对的是所有现有的学术论文, 而大部分学术论文最初都是以纸质形式存在的, 在将其转换为电子文档格式时, 数据出现了较大的质量问题。笔者通过对大量原始TXT文档语料进行分析, 初步确定了针对论文相似性检测数据预处理的范畴, 如图1所示。需要特别说明的是, 本文主要针对中文学术论文相似性检测的数据。
 | 图1 论文相似性检测中数据预处理的范畴 |
根据论文相似性检测中的数据预处理的范畴, 给出数据预处理模型如图2所示。由于针对常见数据问题的分析处理方面成果较多, 本文只重点对论文相似性检测中特有的编码问题、要素划分、乱码问题、段落合并的分析与处理进行详细阐述。
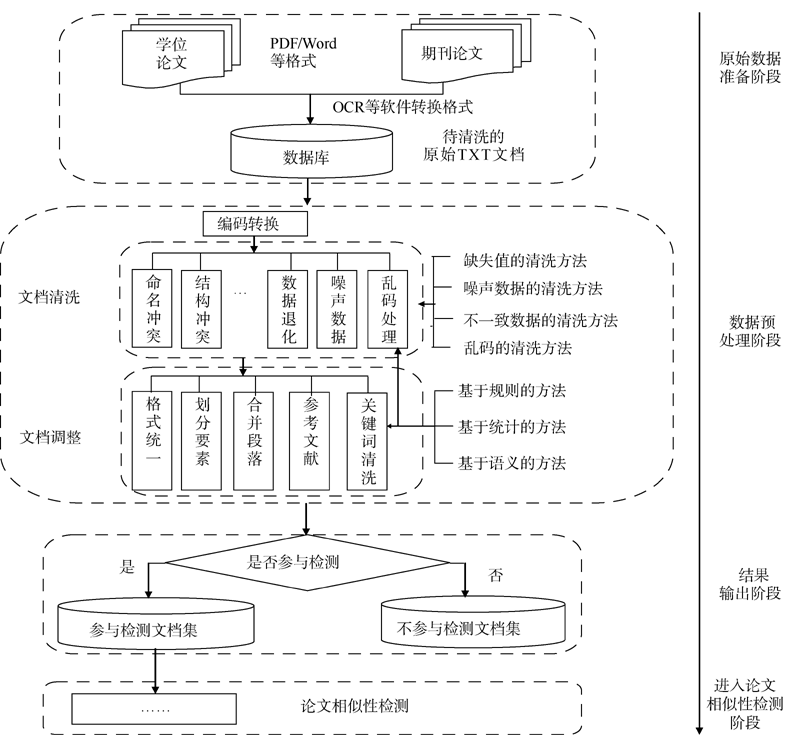 | 图2 论文相似性检测中数据预处理模型 |
在实际操作中, 要想打开一个文本文件, 就必须知道它的编码方式, 否则用错误的编码方式解析, 就会出现乱码。编码的转换也必须建立在以正确的编码方式解析一个文本文件的基础上, 否则也会出现乱码现象。在论文相似性检测中, 一旦出现编码问题导致的乱码, 将会产生极其严重的后果, 因为这种情况下, 一般整个文件都会是乱码, 无法进行相似性检测。因此在相似性检测之前必须对文件的编码方式进行转换, 这种转换主要涉及两个方面: 从数据库中导出文件时统一编码方式, 这是最有效的方式; 在相似性检测前的数据预处理阶段对文件编码方式进行转换。但在读入文件阶段必须事先获取文件编码方式, 获取的方法主要有两种: 由于文件最开头的三个字节中一般存储着编码信息, 因此可编写程序自动读取文件头信息来判断编码方式; 或者依次使用不同的编码方式解析文件, 若内容正常显示即表示为该种编码方式。
规范的学术论文一般都有其相对固定的组成要素, 包括两个部分: 前置部分, 例如标题、分类号、摘要、关键词等要素; 主体部分, 一般是以绪论(引言)开始以结论结束, 最后是参考文献。
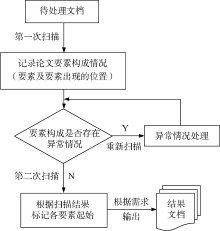
要素划分问题的处理具体流程如图3所示:
 | 图3 要素划分问题处理流程图 |
其中的异常情况主要是指类似扫描到摘要的标识, 却未扫描到关键词或扫描到Keywords却未扫描到Abstract的情况, 此时需要对文档重新扫描, 根据某些规则添加相应要素的标识。
由于参考文献和关键词自身的特殊性以及两者对于论文相似性检测的重要影响, 笔者在预处理模型中也将这两个要素单独罗列出来。
(1) 对于参考文献, 若作者在撰写论文时未按著录规则书写, 同一条参考文献可能会出现不同形式, 或在文件转换过程中出现信息丢失或乱码, 这都会导致最后检测结果的不准确, 因此不仅应该在检测算法编写阶段考虑这些因素, 在数据预处理阶段也应进行针对性处理。目前的处理方法是尽可能通过正则表达式匹配参考文献的各个要素, 一方面尽可能修改格式转换导致的字符错误, 另一方面按照著录规则重新编写规范的参考文献。
(2) 关键词清洗主要指两个方面: 在要素划分阶段将关键词要素识别出来; 若在关键词要素识别阶段出现较大问题, 如关键词丢失、将非关键词内容识别为关键词、出现较多乱码现象等, 则需进行关键词自动抽取。这涉及到关键词自动抽取技术, 是指利用计算机从文本中自动提取出能够代表该文本主题的词汇或短语集合以实现文本表示的过程[13]。该技术在文本分类、知识挖掘、自动摘要、信息检索等领域有着广泛应用, 因而该技术也相对较成熟。目前, 关键词自动抽取方法可以分为三类: 基于统计学的方法、基于语言学的方法和人工智能方法[14]。
乱码是造成文本处理效果不佳以及检测结果不理想的重要因素之一, 必须采取有效的方法将文本中的乱码自动识别出来并剔除。由于乱码类型较多, 情况复杂, 对于乱码的识别与处理比较困难。本文主要采用针对不同类型的乱码建立不同处理规则的方法:
(1) 将疑似乱码段切分成8字及以上字符串(必须以标点符号或空格结尾, 连续符号需在同一个字符串中);
(2) 分别计算出每个字符串或子句中低频单字词、单字词、乱码汉字、标点符号、英文字母、英文单词等的个数;
(3) 根据制定的规则判断该字符串或子句是否为乱码或部分为乱码。由于要保证规则对于大数据集的普遍适应性, 规则的制定是一个非常繁琐、费时费力, 且需要不断完善的过程。
论文相似性检测的粒度可以分为整篇文章、段落、句子、定长字符串、词或短语、单个字符或字[15]。通常一个段落都是围绕一个主题或中心论点进行阐述, 段落内句子的关联性较大, 以段落作为检测粒度是相对较好的选择, 不但检测效率较高, 检测结果的可信度也较高。
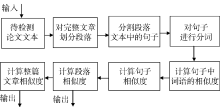
图4为论文相似性检测计算过程的一个简单模型, 可以看出划分段落是论文相似性检测中的一个重要过程。中文句子的划分一般是以句末标点如‘ !’ 、‘ 。’ 、‘ ; ’ 、‘ ?’ 等作为划分标识的; 词语的划分即分词一般使用相应的分词算法或分词系统, 本文使用中国科学院计算技术研究所开发的汉语词法分析系统ICTCLAS①(①http://ictclas.nlpir.org/.)。但是在粗糙的原始文档中, 排版分栏、跨页、页眉页脚等都可能将一个完整的词语、句子、段落分割开来, 因此句子划分和分词都需要建立在段落准确合并的基础上, 否则句子划分和分词都会出现错误。因此, 进行段落合并具有重要意义。
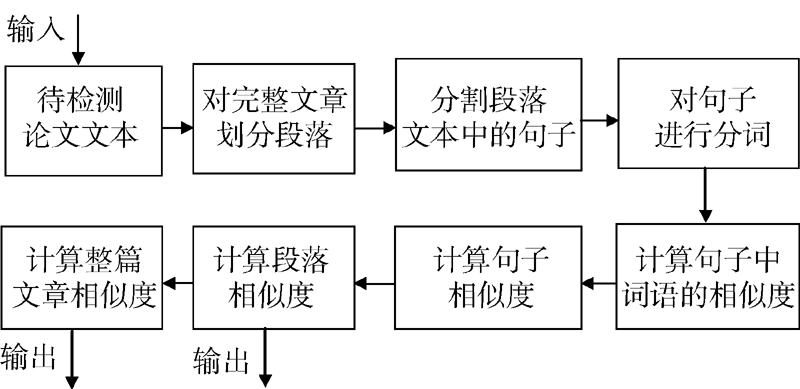 | 图4 论文相似性检测计算过程 |
对于段落合并问题的解决方案, 详见如图5所示的处理流程, 其中最大的难点在于准确识别段落结束的位置, 页眉页脚、跨页、图表的起始位置。需要说明的是, 目前的论文相似性检测方法大部分是针对文档中的文本而言, 对于结构化的表格、图片还不能进行有效处理, 因而处理过程中将图表内容暂且输出到指定的文档中, 若需对图表进行相似性检测, 可调用指定文档的内容。
 | 图5 段落合并问题处理流程图 |
上文针对论文相似性检测中原始TXT文档存在的数据质量问题进行了具体阐述, 据此给出数据预处理模型, 对主要的处理模块进行详细介绍并给出处理的一般流程图。在处理过程中, 还需运用到相关的数据预处理技术, 本文将对笔者实际处理过程中使用的方法进行总结, 主要有: 基于规则的方法、基于统计的方法、基于语义的方法。
绝大多数相关领域的研究人员认为, 要想很好地完成数据预处理过程, 一定要结合特定应用领域的知识; 因此, 人们通常将领域知识用规则的形式表示出来[16]。论文相似性检测中针对的检测对象是学术论文, 而学术论文有其特殊性, 因此可结合其自身特点在预处理阶段定义相关处理规则。
在数据预处理过程中, 较多地采用基于规则的方法进行处理。以要素划分为例, 笔者根据学术论文的规范等, 制定相应的规则如下:
(1) 如果该文档有中文摘要, 那么也应该有中文关键词;
(2) 如果该文档有英文摘要, 那么也应该有英文关键词;
(3) 在中文关键词和英文关键词之间的大段英文有可能是未识别出来的英文摘要;
(4) 目录出现在正文之前;
(5) 参考文献、责任编辑必须出现在正文内容之后;
(6) 无法使用正则表达式匹配要素的起始位置时, 可利用形式特征进行判断, 如参考文献有其特有的著录规范; 目录中一般每行含有多个‘ .’ , 或者连续多行结尾为数字。
由于原始论文在写作、编辑出版时可能出现的不规范以及在转换成TXT文档之后出现的脏乱情况, 想要制定完善的规则非常困难。笔者先利用随机抽样的方法从巨大的数据集中取出小量样本, 在此基础上通过人工参与产生初步规则, 之后把它们应用到样本数据上, 通过观察处理结果, 进而修改已有规则或者添加新的领域知识, 如此反复, 直到获得相对满意的结果为止; 这时, 就可以将这些规则应用到整个数据集中。本文涉及的规则都由人工总结与完善, 使用Java将规则转换为程序代码, 通过计算机实现自动化处理。
基于统计的方法, 需要准备大量的训练语料, 通过统计方法得到某类事物出现的概率。以乱码处理为例, 在前期分析乱码的过程中总结了乱码的主要类型, 如低频单字词过多、标点符号比例过高、英文段落中夹杂汉字等, 通过统计的方法得到相应的处理规则和方法如下:
(1) 概率小于10-6的单汉字的比例大于35%时, 认为该子句为乱码;
(2) 英文字母比例大于75%且汉字比例小于20%时, 若子句中出现汉字, 则该汉字为乱码; 当英文字母比例小于40%, 若子句中出现汉字, 且该汉字左右两边都是英文字母时判定该汉字是乱码。
继而通过大量语料对以上处理方法进行训练, 不断调整相关的比例指标, 并产生新的处理方法。
基于统计的方法侧重于语料的定量描写, 通过不断记录和统计真实的语言现象不断生成新的规则和方法, 该方法适应性强, 且受非语言因素影响小, 可信度较高。但该方法对语料的依赖性较强, 且仅仅是基于数据的统计, 因此总结出来的规则和方法稳定性较弱, 是浮动、似然的, 也很容易出现片面性, 在实际应用中需要人工参与, 对最终的规则方法进行把关。
汉语是语义型语言, 重意合而轻形式, 且汉语复杂灵活, 语言知识难以规则化, 因此中文文本较英文文本在结构、词序、处理等方面都存在特殊性。文本的语义是基于概念的, 词是构成这些概念的基本单位[17]。因此一般进行语义分析的第一步就是对文本进行分词, 并在分词基础上完成词性标注。本文采用ICTCLAS对文本进行分词及词性标注。
利用基于语义的方法进行数据预处理主要是在段落合并阶段和乱码处理阶段。以段落合并为例, 一般情况下根据句末标点及字符串长度等规则进行处理即可, 但对于章节标题或跨页问题中的段落合并则需要结合基于语义的方法。以下示例都是原始语料中出现的实际情况。例1-例3分词及词性标注结果如表1所示。ICTCLAS所采用的汉语词性标记集(部分)如表2所示。
例1: 1.1材料
与方法
例2: 3.2 流域污染综合整治评价指标体系的
构建
例3: 果、应急防治能力和整体控防水平, 确保农(下转190页)
夜10— 13℃。随着天气转暖要加大通风量, 超过30℃要……
(上接118页)业生产安全、农产品质量安全、生态环境安全。……
(上接130页)仔细分析、研究, 探索出高效、环保的控防新方法……
| 表1 分词结果及词性标注 |
| 表2 ICTCLAS所采用的汉语词性标记集(部分) |
例1和例2是同一段的内容被分成两行且无法用一般的规则判断下一行是否与上一行属于同一段的内容。例3中根据一般规则无法判断“ 下转” 之后应该接哪个“ 上接” 的内容, 第一种情况为“ 下转” 之后接第一个“ 上接” , 第二种情况为“ 下转” 之后接第二个“ 上接” 。因此对当前行与下一行的内容合并后进行分词, 并进行词性标注。根据表1的分词及词性标注结果, 例1、例2中根据一般中文的语义知识库, 比如哈尔滨工业大学同义词林或者HowNet, 基于语义相似度计算, 可以判断下一行极有可能与上一行内容属于同一段内容。例3中, 第一种情况上一行的“ 农” 与“ 业” 恰好组成一个名词, 且整个短语是“ 动词+名词” 结构, 而第二种情况“ 农” 作为一个名词性语素, 整个短语结构为“ 动词+名词性语素+副形词+动词” , 综合考虑第一种情况的可能性极大。该方法同时需要结合中文句法规则, 建立现代汉语句型规则语义知识来判断。
基于规则、统计、语义的三种方法, 是本文进行数据预处理中使用的主要方法, 三种方法之间相互区别, 但也密切联系; 在实际运用中, 通常会将三者结合起来使用。基于统计和基于语义的方法都需要建立相应的规则完成预期目标, 而利用基于统计和基于语义的方法又能生成新的有价值的规则, 只有将三种方法相结合, 才能取得更好的预处理效果, 保证处理结果的合理性、准确性、有效性。
由于原作者书写、出版社编辑排版、文件格式转换等多种原因, 论文相似性检测的原始数据存在大量数据质量问题, 严重影响相似性检测的准确性和有效性。在对原始论文数据进行详细分析的基础上, 总结存在的数据质量问题, 并给出数据预处理模型, 发现编码方式、要素划分、乱码和段落合并问题是面向论文相似性检测的特有数据问题, 最后本文总结了基于规则、统计、语义三种对数据进行预处理的方法。
本文重点对面向论文相似性检测的数据质量问题进行总结并给出相应的解决方法, 对于提高论文相似性检测的准确性、合理性, 以及为论文相似性检测提供新的思路等方面具有重要意义。但也存在一定的局限性, 如本研究基于的原始语料规模有限; 对于图表内容未能提出有效的处理方式; 对于某些数据质量问题的处理仍存在缺陷。后续的研究中将针对这些问题进行重点分析, 并更多地应用数据挖掘技术、机器学习方法进行数据预处理, 以期获得更好的处理效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|