
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
查收查引服务支撑需求驱动下的高校机构知识库建设
[严潮斌, 陈嘉勇 , 侯瑞芳, 李玲, 周婕]
, 侯瑞芳, 李玲, 周婕]
, 侯瑞芳, 李玲, 周婕]
|
|


作者贡献声明:
严潮斌:: 提出研究思路, 论文最终版本修订;
陈嘉勇: 提出研究思路, 设计研究方案, 功能开发, 论文最终版本修订;
侯瑞芳: 数据整理和分析, 论文起草;
李玲, 周婕: 数据整理, 功能测试。
【目的】以查收查引为灵感, 通过其与机构知识库的关联性, 推动机构知识库的建设。【方法】自主研发机构知识库, 设计数据模型, 提出作者认领模式, 并通过学科馆员的批量认领和对作者进行邮件营销等方式来实践认领。【结果】实现文献与作者实体之间可持续的间接精准关联机制, 精准关联出作者被收录和引用的文献列表。【局限】查收查引工作可能会因为数据问题而不准确, 需要到数据库中实际验证。【结论】本研究有利于降低机构知识库管理和运营的难度, 并为查收查引服务提供支撑。
[Objective] Be inspired by paper index and citation service, improve development of institutional repository by relevances between the institutional repository and the paper index and citation service.[Methods] Design data model, develop institutional repository based on paper-entity relationship model, and propose a new pattern for author claim.[Results] The new pattern is practiced via batch claim of subject librarian and email marketing to authors, implements inaccurate data correlation between paper and author entity.[Limitations] Because of data problems, paper index and citation service still need to verify in the databases.[Conclusions] This study reduces the difficulty of management and operation for institutional repository, and also provides support for the paper index and citation service.
机构知识库是将科研人员创造的数字知识进行永久保存, 集典藏、展现与服务为一体的平台[1]。近年来, 国内高校图书馆视其为值得探索和研究的领域, 然而发展多年后效果仍不理想, 其原因主要在于: 对机构知识库的用户需求分析不足, 挖掘潜力思考不明, 未将机构知识库的建设融入图书馆的日常工作中; 对机构知识库来源数据的选择与处理不足, 缺乏对机构知识库模型和系统的顶层设计; 认领模式、服务模式等运营管理机制没有得到高校师生和馆员的认可。虽然多所高校图书馆陆续推出了机构知识库, 但并未引起高校师生的广泛关注和使用, 对高校内部来说, 相关部门和研究人员能从中利用和挖掘的高质量、有价值的数据有限, 对外也没有很好地起到为高校和研究人员的学术成果进行展现和推广的作用。
在需求层面, 构建机构知识库的初衷和目标是高校图书馆需要考虑的关键问题, 高校图书馆不能仅仅以建立一个供高校师生搜索高校科研成果的数据库为目标, 而是需要从图书馆的日常服务工作中提炼出对机构知识库的直接需求, 让机构知识库能支撑相关工作, 同时也能让机构知识库持续地运营下去。
在技术层面, 不论是使用DSpace[2]还是中国科学院的CSpace[3]等软件, 高校图书馆构建机构知识库时无法回避的技术难题是数据来源与组织, 主要涉及到题录数据的来源和预处理, 以及题录数据中实体之间的精准关联, 以实现从机构或学者的角度揭示与之相关联的其他实体的数据, 为图书馆自身的服务和高校的科研、人事等部门提供数据支持。目前, 许多高校图书馆正是由于忽视或无力实现机构知识库各实体间的精准关联, 而延缓了机构知识库的有效使用和推广。
北京邮电大学图书馆信息咨询部根据查收查引服务的需求, 凭借日常工作中积累的对文献题录预处理的经验, 在图书馆信息化管理平台的顶层设计下, 基于文献实体关系模型设计研发了机构知识库, 实现机构知识库各实体间的精准关联, 并提出一种可持续的作者认领模式, 在机构知识库建设初期对作者进行的批量认领工作即可实现未来作者和文献的自动关联, 以实现优化查收查引服务和持续运营机构知识库的目标。
Web of Science、EI、CSCD、CSSCI等数据库因被广泛应用于高校科研成果评价而成为查收查引服务常用的检索工具。这些数据库收录的期刊、会议论文的元数据经过专业数据机构的质量把控, 可以保证相关实体的精确检索和导航, 很适合成为机构知识库的数据来源。
然而, 各种学术实体在不同数据库的题录数据中有着不同的表达方式, 如学科分类体系、主题词、标引词等字段, 而图书馆员在完成查收查引时发现作者名称和作者地址字段变体更多。作者和作者地址根据不同期刊和数据库的要求呈现了不同的表达方式, 如姓名顺序、姓名与地址的全称与缩写、中英文的表达甚至拼写错误。
在进行查收查引时, 为了提高查准率和查全率, 一般用AND和OR逻辑, 将多种形式的作者名称和作者地址关键词组合起来检索, 如在Web of Science中查询北京邮电大学黎嘉音老师的成果时, 需要在作者栏输入以OR连接的黎老师英文名称的不同变体, 在地址栏输入以OR连接的邮编100876、简称bupt, 以及高校英文名称中罕见而邮电类高校特有的单词Posts等能代表北京邮电大学地址的关键词, 最后用AND逻辑组合检索。
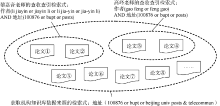
虽然上述方式能很好地完成检索工作, 但查收查引服务多是站在作者的角度进行检索, 在下一次职称评定或申请项目等查收查引高峰时期需要将某位作者的历年成果重新检索一遍, 存在较大的重复劳动。而机构知识库是站在机构的角度, 与查收查引有相当程度的关联性, 分别从不同的角度看待科研成果。以北京邮电大学某位老师进行查收查引时使用检索式获得的检索结果是北京邮电大学机构知识库数据来源的子集, 如图1所示:
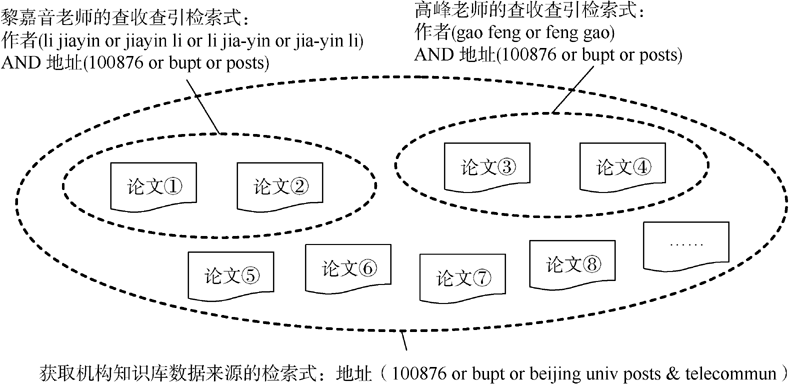 | 图1 查收查引和机构知识库的集合关系 |
图1展示了高校图书馆的查收查引和机构知识库在文献数据来源方面的密切关系, 机构知识库要为查收查引服务提供强有力的支撑, 只需站在机构角度, 定期导入高校整体科研成果的纯文本元数据, 转换到机构知识库的结构化数据模型中。针对某位作者的查收查引工作不再需要从单个作者的角度进行数据库检索, 历年来的文献列表只需从机构知识库中勾选导出数据即可。要实现以上描述的机构知识库和查收查引服务紧密结合的愿景, 还需要以机构知识库的数据模型作支撑, 以作者与文献的精准关联为前提, 基于关键技术, 提出并实现作者认领模式。
机构和作者是机构知识库中最重要的两个实体, 要实现机构知识库的构建以及对查收查引等服务的支撑[4], 需要做到文献与机构和作者实体的精准关联, 解决机构和作者的归一化、作者重名判断等问题。相关的研究推动着机构知识库的发展, 作者名称规范[5]和数据关系模型[6]的相关研究可以借鉴到机构知识库的建设中。
纯文本格式是数据库中一种通用的文献题录格式, 本研究定期从Web of Science、EI、CSCD、CSSCI等数据库中以高校地址为检索式获得科研成果的题录数据, 并导入到机构知识库中。纯文本格式记录了文献以及作者等学术实体的数据, 导入的过程涉及到对各种类型题录数据的预处理, 其中作者重名以及作者名多种表达形式是预处理过程需要解决的关键问题。以同一个机构中一般不存在同名作者为前提假设, 从题录数据中识别出作者与作者地址之间的关系, 将作者与作者地址的组合视为作者标识, 如表1所示:
| 表1 将作者和作者地址的组合作为作者标识解决作者重名问题 |
在表1中, 第1条和第2条记录为两位名为黎嘉音和李佳茵的作者, 由于其作者地址的不同而被识别成不同的作者, 解决了作者重名的问题。然而, 根据第1条、第3条和第4条, 以及第2和第5条记录可以看出, 在不同的数据库中, 黎老师和李老师的作者和作者地址使用了不同的表达形式。在查收查引时, 一般会使用上文中提到的检索式, 这样会容易混淆这两位作者的科研成果, 需要通过仔细查看题录数据中的作者地址进一步判断, 而如果有机构知识库作为支撑, 人工判断作者地址的问题则可以通过机构知识库后续的作者认领工作来解决。
不同格式标准的纯文本题录数据都能提取出文献数据中隐藏着的文献与学者、机构、学科和主题等关联实体及其关系。本研究对Web of Science的题录格式做了深入分析, 并提出了文献实体关系模型[6], 实现了从半结构化纯文本文献数据向结构化关系数据库格式的完整无损转换, 为机构知识库融合了不同来源格式的文献数据。
文献的题录数据经过预处理后, 表1中作者和作者地址组合的作者实体与文献实体在文献实体关系模型中有了直接的关联, 其他实体和作者实体一样, 实体的数据和关系被完整地保存在文献实体关系模型中。如图2所示, 每一位非重名的作者标识都与文献有了直接关联。
 | 图2 使用文献实体关系模型将文献与作者实体进行关联 |
然而, 从图2可以看出, 黎老师发表的多篇文献关联到了以不同方式表达的黎老师的作者标识, 这些有多种表达的数据导入机构知识库后会被识别成不同的实体存在, 在不同的数据库中有若干种不同写法的作者都属于黎老师。同样, 可能会有上百条类似但不同格式的机构实际上是同一个学院, 某个学科在不同学科体系中可能以不同的名称存在。
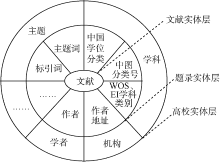
文献实体关系模型虽然完整地保存了文献和各实体的数据和关联, 但仍无法做到与某学者、机构等高校规范实体的精准关联, 在图2中, 黎老师有三种不同形式的作者实体, 无法方便地检索出黎老师的所有成果。因此有必要对其进行扩展, 让数据模型能融合不同的数据来源, 即在这些来源数据的外部关联高校自身的机构、学者、学科、主题等真实数据的高校实体, 将题录实体和高校实体相关联。
如图3所示, 文献实体关系模型经过扩展后由文献实体、题录实体与高校实体三层组成。文献实体关系模型在图3中简化为文献实体层与题录实体层, 这两层的数据与关系来源于对文献题录数据的预处理。高校实体层来源于高校的统一信息标准或接口数据, 题录实体层与高校实体层之间的关系可以由科研秘书或学科馆员人工关联, 但更需要一种作者和文献间关联关系的确定机制, 即通过学者的主动认领来确定。
 | 图3 扩展高校实体后的文献实体关系模型 |
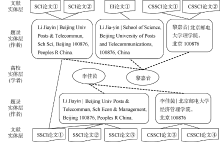
使用扩展高校实体后的文献实体关系模型, 李佳茵和黎嘉音两位学者和其多种形式的作者实体有了直接关联, 和文献有了间接精准关联, 如图4所示。SSCI论文①是两名作者合著的文献, 该文献会分别关联每位作者的题录实体层数据, 并间接关联到相应的高校实体层, 即文献会记在每一位合著者名下。此外, 文献也会与作者地址产生关联, 作者地址再与二级机构产生关联, 用于文献与二级机构的间接精准关联, 可用于学院级别的统计。
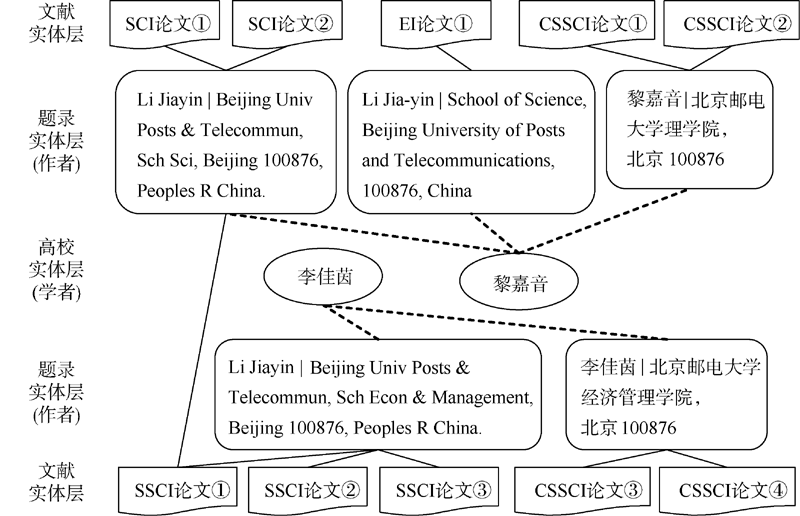 | 图4 使用扩展高校实体后的文献实体关系模型将作者和文献间接精准关联 |
虽然理论上有更强大的预处理技术能将文献题录数据进行批量转换或替换, 或将多语种数据统一, 让文献实体与高校实体直接关联, 从而免去题录实体层。然而, 题录实体层的存在是文献题录数据自然形成的桥梁, 用于连接文献实体和高校实体。本研究不推荐使用批量替换或其他任何方法破坏科学评价数据库所提供的题录数据, 强调题录数据的完整无损转换, 目的在于记录高校科研成果在数据库中的原貌和规律, 让新的题录数据按照自然形成的规律对应到学者认领的作者实体中, 即新成果的题录数据如果关联上已被认领过的作者和作者地址, 学者与新成果就自动产生间接关联。
本研究实现了数据预处理的关键技术, 基于灵活设计的机构知识库数据模型自主研发了机构知识库之后, 需要确定作者和文献之间关联关系的确认机制, 即作者认领模式。目前的研究大多采用学者自行认领新成果的模式[3], 即进行“ 作品认领” , 这种机制虽然可行, 但是需要不断地由学者人工地进行认领工作, 而且这种被动等待学者认领的模式需要相关部门的制度推动, 也需要机构知识库在新论文入库时能自动推送给学者进行认领确认, 否则较难落实。本研究提出的“ 作者认领” 是指用户对自己各种形式的作者和作者地址组合的作者标识进行认领, 用户认领的是作者实体, 而非文献实体。这将是一种一劳永逸的认领模式, 在机构知识库建设初期让作者对其自身的数据进行识别和认领就能实现今后可持续性的作者与文献的精准关联。
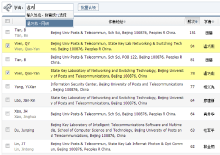
图3所示的扩展高校实体后的文献实体关系模型具有较强的扩展性和灵活性, 文献实体层与题录实体层的关系完全由数据库导出的文献题录数据完整无损地转换而成, 而题录实体层与高校实体层的关系由学者主动认领, 也可由科研秘书、学科馆员进行批量设置, 学科馆员对作者进行批量认领的操作界面如图5所示:
 | 图5 学科馆员在机构知识库后台对作者进行批量认领 |
李老师和黎老师认领相应的作者和作者地址后, 学者和机构关联的论文则是根据高校实体层、题录实体层与文献实体层逐级关联的结果, 学者和文献之间就形成了如图4所示的间接精准关联。
互联网领域中常用邮件营销[9]的形式向用户推送与用户密切相关的信息, 以促进用户获得相关的资讯, 并且定期关注或回访网站。本研究在机构知识库中引入营销和社交等互联网因素, 在机构知识库建设初期通过邮件营销推送作者和作者地址组合供学者认领, 推动作者认领模式的顺利实施。
在之后的运营过程中, 机构知识库会对新收录的成果自动识别关联的学者与机构, 同时还挖掘出学者个性化的学术需求(如文献中高频使用的关键词、经常投稿的期刊、经常参加的会议等), 同样通过邮件和微信营销等方式将最新成果的收录情况以及校外相关研究动态推送给学者, 吸引学者到机构知识库中获得最新科研动态, 了解校内外最新科研成果, 并将自己研究成果保存在平台中。
在机构知识库的用户界面中, 用户可以方便地通过数据来源、语种、学科、年份、学者、主题等实体与文献的直接或间接的关联关系, 快速检索出所需文献的列表, 界面如图6所示:
 | 图6 机构知识库前台用户界面 |
虽然在认领阶段学者需要对题录实体层中的多种表达的作者和作者地址数据进行识别和确认, 但是用户在机构知识库的用户界面中看到的学者与机构等信息来自于高校实体层, 不会受到题录实体层中有着多种表达的实体数据干扰。李老师和黎老师认领相应的作者和作者地址, 形成图4中的关联后, 用户就可以从李佳茵学者实体, 经过学者和作者、作者与文献的逐级关联, 快速检索出李老师的科研成果。
本研究的灵感来自于查收查引服务, 成功构建机构知识库后也能为查收查引服务提供支撑。在查询文献的收录情况的流程中, 图书馆员不用和以往一样去科学评价数据库中重复检索, 而是和用户一样, 可以在机构知识库通过文献与作者的精准关联快速筛选出某位查收查引申请人的收录文献列表, 并进行勾选后按照相应的格式打印。如果是用户打印的列表, 只需图书馆员审核即可。
在查询文献的被引用情况时, 图书馆员可根据机构知识库的数据对比文献的LCS和GCS指标。当LCS和GCS相等时, 可以直接从机构知识库中导出被引文献实体的列表; 当LCS小于GCS时, 需要到Web of Science等数据库中检索, 并导入新的施引文献, 充实机构知识库的数据。本文将非本校成果的施引文献进行标记, 使其仅用于查引工作, 以避免对机构知识库造成干扰。LCS和GCS指标能显示出馆员上次和本次查询某文献时, 其被引频次是否增加, 并免去重复劳动, 提高了查引工作的效率。
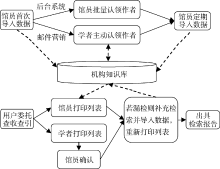
引入机构知识库之后的查收查引服务不再是一次性的, 而是机构知识库生态圈中的一环, 避免了重复劳动, 与机构知识库的建设相互促进。如图7所示, 机构知识库的日常管理和查收查引服务都可以向机构知识库中导入数据, 机构知识库中的作者认领工作会为查收查引服务提供作者与文献的关联, 查收查引的数据来源于机构知识库, 同时也会不断充实机构知识库的数据。
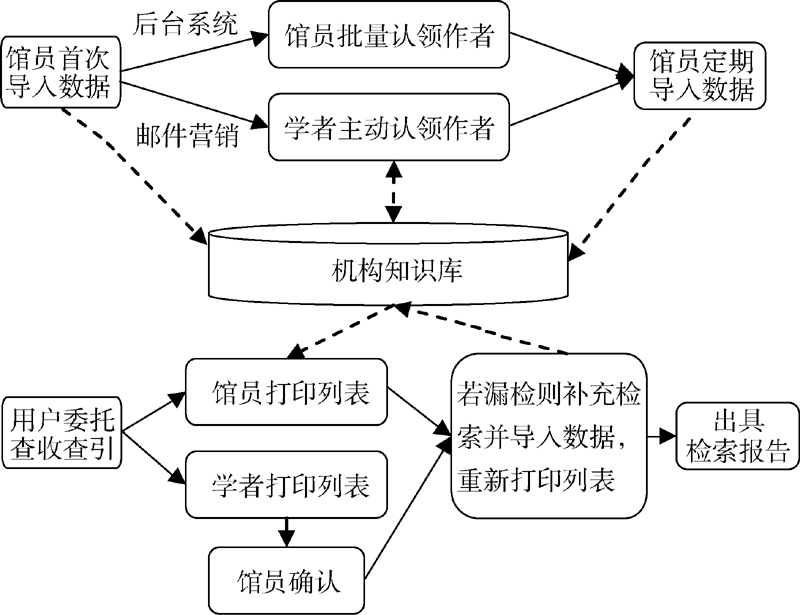 | 图7 机构知识库和查收查引服务相互促进的流程 |
然而, 由于Web of Science、EI等数据库可能偶尔会出现剔除期刊的现象, 或数据标注有误的问题, 所以馆员在机构知识库的支撑下进行查收查引工作虽然提高了效率, 但是为了确保数据的权威性和正确性, 需要到数据库中进行适当的验证。
研究成果的产生是变化的, 但作者地址是相对固定的。本研究主张的“ 以不变应万变” 的作者认领模式使得作者认领的工作量大大减少, 能够持续有效地解决成果与学者、机构等实体之间可持续的间接精准关联机制, 降低了机构知识库的管理和运营难度, 同时与图书馆的查收查引服务相互促进。除了查收查引服务外, 机构知识库中的数据还可用于更多的图书馆工作中, 有待图书馆员和高校师生的发现和挖掘。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|