
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于用户分类的协同过滤个性化推荐方法研究*
[祝婷, 秦春秀 , 李祖海]
, 李祖海]
, 李祖海]
|
|


作者简介:祝婷: 提出研究思路, 设计研究方案, 采集、清洗和分析数据; 李祖海: 进行实验; 祝婷, 秦春秀: 论文起草及最终版本修订。
[Objective] To solve the problem of low efficiency of the algorithm with the increasing number of users. [Methods] This paper proposes a method of collaborative filtering based on user classification. Firstly, the huge users are classified into several groups according to a rule-based classification method. Then, with the guarantee of recommendation accuracy, the local neighbor users are discovered for users. Finally, based on the discovered local neighbors, personalized recommendation is conducted. [Results] User classification and recommendation accuracy are evaluated by F1and MAE separately. The algorithm efficiency is evaluated according to the time complexity. Experimental results show that with the adoption of a rule-based user classification, collaborative filtering algorithm significantly improves with the guarantee of user classification accuracy and recommendation accuracy. [Limitations] The recommendation accuracy is reduced a little bit. The proposed method is only tested on MovieLens data set, and it needs further validation in other data sets. [Conclusions] This method reduces the computation of local neighbors user identification, while improves the efficiency of the algorithm.
在Web2.0时代, 网络信息资源呈爆炸式增长, 用户想要在如此大量的网络资源中找到自己感兴趣的资源, 需要花费大量的时间和精力。在这种情况下, 如何快速而准确地为用户推荐感兴趣的资源越来越受到相关研究者的重视。为了解决这个问题, 个性化推荐日渐产生。协同过滤技术是目前应用最为广泛和成功的个性化推荐技术, 它从用户自身出发, 通过计算用户之间的相似性, 寻找与目标用户有相似兴趣爱好的近邻用户, 根据近邻用户的评价为目标用户推荐。由于协同过滤可以发现用户本身没有发现的兴趣爱好, 因此推荐精度较高。然而, 第34次中国互联网络发展状况统计报告[1]中显示, 截至2014年6月, 我国网民规模达6.32亿, 较2013年底增加1 442万人, 由此可见, 网络上的用户数在急剧增加。在这种情况下, 协同
过滤方法在计算用户相似性的过程中就需要耗费大量的时间, 从而导致效率降低。本文尝试采用基于规则的方法对庞大的用户群分类, 在用户群内部进行局部的协同过滤推荐, 在保证一定的推荐精度前提下以提高个性化推荐的速度。
目前的推荐算法主要有基于内容的推荐技术、基于规则的推荐技术以及协同过滤推荐技术。
(1) 基于内容的推荐
对用户建立兴趣模型来描述其兴趣爱好, 同时对项目的内容进行特征提取形成特征向量, 根据用户的兴趣模型与项目的特征向量的相似性大小进行推荐。例如文献[2]提出基于内容的热点微话题推荐方法, 通过计算用户与微话题的相似性为用户提供微话题推荐。基于内容的推荐不需要获取用户对项目的评分, 也不需要获取其他用户的兴趣爱好, 可以处理项目的冷启动问题, 并且响应时间短。基于内容的推荐也存在缺点, 例如模型建立是一个难点, 系统只能给用户推荐与历史兴趣相似的资源, 缺乏对用户潜在兴趣的挖掘, 并且不能处理用户的冷启动问题。
(2) 基于规则的推荐
根据用户浏览过的感兴趣的内容, 通过规则推测出用户没有浏览过但可能感兴趣的内容。可见基于规则的推荐关键就是规则的制定。规则可以通过关联规则的挖掘方法实现, 其中关联规则挖掘的过程主要分为寻找频繁项集和产生关联规则。例如文献[3]提出基于项目支持度的关联规则推荐算法, 有针对性地对用户推荐商品。由于基于规则的推荐可以离线建模, 因此可以提高系统的实时性。但是如果规则的支持度和置信度选取不当就会降低推荐质量, 并且也不能处理项目的冷启动问题。
(3) 协同过滤推荐
利用用户间兴趣爱好的相似性对目标用户进行个性化推荐。协同过滤是目前最被广泛应用于推荐系统的一种策略。协同过滤分为基于用户的协同过滤和基于项目的协同过滤。基于用户的协同过滤是指通过搜集用户信息, 找到与目标用户相似的近邻用户, 根据近邻用户的兴趣爱好对目标用户进行推荐。文献[4]就是在传统的基于用户的协同过滤的基础上提出了基于用户间多相似度的协同过滤算法, 根据用户对不同项目类型的多个评分的相似度计算用户对未评分项目的预测评分。基于项目的协同过滤是指用户对项目进行评价得到评分高的项目, 计算项目之间的相似性, 找到与评分高的项目相似的项目推荐给用户。文献[5]就是将基于项目的协同过滤推荐算法与构建项目的时效性评价模型结合, 同时考虑项目的时效性和用户的兴趣来寻找近邻项目, 从而进行高时效性的推荐。
协同过滤同时也存在一些问题。例如系统中出现新用户及新项目所造成的冷启动问题[6], 以及项目数的增多导致用户对项目评分较少所造成的稀疏性问题[7]。而且在协同过滤推荐方法中, 用户之间相似度计算是该方法最重要的一步, 但由于用户数量越来越庞大, 导致算法在整个用户空间进行近邻查找时产生巨大的计算量, 影响算法效率。因此本文根据用户的特征, 例如性别、年龄、职业对用户进行分类, 相近的用户分为一类, 在保证一定的推荐精度的前提下, 相似性计算时仅考虑同类别中的局部用户, 这是因为同类别的用户具有较大的相似度。在性别上, 不同性别的用户会选择不同类别的事物, 例如在观赏电影方面, 女性喜欢观看情感片, 而男性则喜欢观看战争片。在年龄上, 不同年龄阶段的用户心理成熟程度不同, 对事物的认识也就不同, 导致选择不同类别的事物。在职业上, 不同职业的用户所处的职业场景不同, 在同一职业场景中用户对事物会逐渐形成统一的理解角度, 从而倾向选择同一类别的事物。
常见的分类算法有决策树分类算法、贝叶斯分类算法、基于关联规则的分类算法以及支持向量机分类算法[8]。其中基于关联规则的分类算法[9]将分类器的构造与属性的相关分类集于一体, 发现的规则相对比较全面, 并且分类准确度也较高, 所以本文采用基于规则的分类算法, 按照用户的属性对用户进行分类。
协同过滤推荐思想十分简单, 生活中人们在购买物品时, 经常会先咨询一下有相同兴趣爱好的同伴, 根据他们的推荐选择性地购买物品。协同过滤就是将这种思想运用到互联网中, 将近邻用户的兴趣爱好推荐给目标用户。该推荐方法主要分为4个步骤:
(1) 基于规则的用户分类。搜集用户信息, 按照用户的属性, 利用基于规则的分类方法对用户进行分类;
(2) 用户-项目评分表示。将用户与用户对项目的评分表示出来;
(3) 局部近邻用户的识别。利用修正的余弦相似性计算用户间的相似性, 从而计算近邻用户;
(4) 个性化推荐。根据近邻用户对未评分项目的评分来预测目标用户对该项目的评分, 从而产生推荐。
分类算法首先人工确定一些类别形成训练集, 通过对训练集进行分析, 发现分类规则, 利用分类规则判断检验集的类别。基于规则的用户分类过程如图1所示:
 | 图1 用户分类过程 |
(1) 训练集的获取
获取用户记录, 将其表示为U1(A1, A2, A3, …, AK), 其中, U表示用户, A表示属性。本文选择性别、年龄、职业三个属性对用户进行分类, 同时为了确保每个用户可以唯一被识别, 因此添加用户编号, 即用户记录可以表示为U(id, age, gender, occupation)。规定具体的属性取值如表1所示:
| 表1 用户属性表格 |
在用户属性取值过程中, 为了减少用户类别数目, 从而在提高算法效率的同时保证推荐精度, 因此, 在属性年龄上, 将0-29岁(含29岁)设为年龄段1, 将30岁及以上设为年龄段2。在属性性别上, 分为女性(F)、男性(M)。在属性职业上, 为了方便进行分类, 将职业划分为服务类、技能类与其他三类。
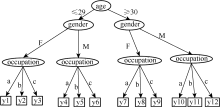
在人工分类形成训练集的过程中, 由于不同的年龄段最能体现出用户不同的兴趣爱好, 其次是性别, 最后是职业。所以本文给不同的属性赋予不同的重要性, 进行用户分类。也就是说先考虑年龄, 再考虑性别, 最后考虑职业。分类过程如图2所示:
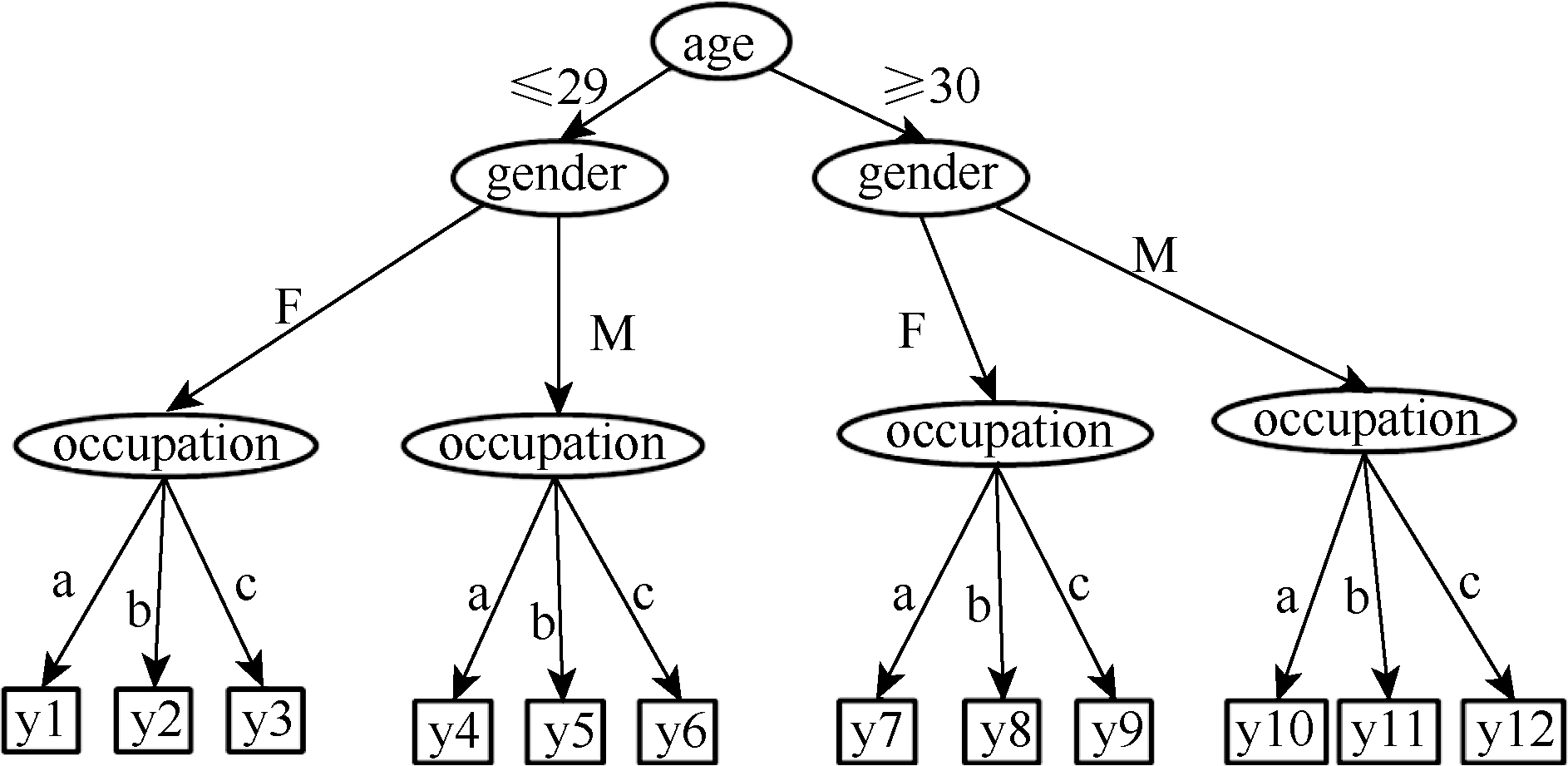 | 图2 用户分类的决策树 |
其中, a表示occupation中的服务类, b表示技能类, c表示其他类。最终将用户分为y1, y2, …, y12共12个类。通过以上方法则可以人工形成训练集。
(2) 分类规则的提取
形成训练集后, 需要分析训练集从中提取分类规则。基于规则的分类使用“ if…then…” 的规则对记录进行分类, 最终产生一个规则集R, 规则集R=(r1∨ r2∨ …∨ ri∨ …∨ rk), 其中ri称之为分类规则。每一个分类规则可以表示为如下形式:
ri: (A1 op v1)∧ (A2 op v2)∧ …∧ (Ai op vi)∧ …∧ (Ak op vk))→ yi其中(Ai, vi)表示一个属性-值对, op表示比较运算符。如果用户U1的属性与规则的前件匹配, 则规则被触发, 用户将归为类别yi。
鉴于类分布不平衡的特点, 本文采用决策树进行规则提取以完成最终的用户分类。
用户分类后, 需要将每类用户及用户对项目的评分表示出来。本文采用Rm× n矩阵表示用户-项目评分, 其中共有m个用户, n个项目, 行向量代表某个用户对各个项目的评分信息, 列向量代表不同用户对某个项目的评分信息。用户-项目评分矩阵如下所示:
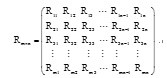
其中, Rmn表示用户m对项目n的评分。评分分为显示评分与隐示评分。显示评分是指用户主动地对项目进行评分, 分值处于0到5之间, 表示用户对该项目的喜爱程度, 0表示用户未对该项目评分, 分值越大表示越喜欢, 反之越不喜欢。隐示评分是指用户在无意识中浏览网页, 通过获取用户在网页上停留的时间、点击的次数即用户与系统的交互来形成分值, 分值类似显示评分[10]。由于隐示评分在获取上存在一些困难, 所以本文采用显示评分, 隐示评分暂不考虑。
另外, 当有新用户产生时, 可以随机抽出一些项目让用户进行评分, 从而形成新的行向量添加到用户-项目评分矩阵中。当有新的项目产生时, 可以提供给部分用户进行评分, 从而形成新的列向量添加到用户-项目评分矩阵中。这样可以在一定程度上解决用户和项目的冷启动问题。
获取每一用户类群的用户-项目评分矩阵后, 就可以在各个用户-项目评分矩阵中进行用户间的相似性计算以获取用户的局部近邻用户。传统的相似性计算方法有三种: 余弦相似性, 修正的余弦相似性和相关相似性[10]。本文采用修正的余弦相似性度量方法。因为在相似性度量方面, 不同的用户具有不同的评价尺度, 对一个项目具有相同喜爱程度但是由于评价尺度的不同而给予不同的评分, 而修正的余弦相似性改善了此缺陷, 通过考虑用户评分的平均值消除由于评分尺度而造成的差异。
用户u1和u2的相似性计算方法[11]如下所示:
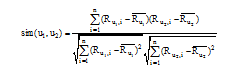 |
其中, 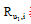
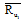
利用修正的余弦相似性度量计算出同类别中用户的相似性后, 就可以对目标用户产生局部近邻用户, 局部近邻用户的个数可以预先设定, 假设定义为k, 则近邻用户集合可以表示为nei=(u1, u2, …, uk)。
在对目标用户产生局部近邻用户后, 算法的关键部分已经完成, 接下来是对目标用户产生推荐。
目标用户u对未评分项目i的预测评分可以用公式(2)[12]计算:
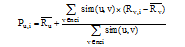 |
其中, 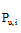
通过公式(2)可以计算出目标用户对各个未评分项目的评分, 按照值的大小对未评分项目进行排序, 取前几个项目推荐给目标用户。
采用MovieLens站点的数据集作为实验数据测试此方法, 该数据集包括943个用户对1 682部电影的100 000个评分, 其中每个用户至少评价了20部电影。整个实验数据划分为训练集和测试集, 选择其中80%作为训练集, 20%作为测试集。
(1) 基于规则的用户分类评估
对用户的分类影响着局部近邻用户的准确性, 进而影响最终推荐的精度, 为确保该分类方法的科学性和合理性, 有必要对其进行评估。
笔者采用准确率(P)、召回率(R)和F1作为用户分类的评价指标[13, 14]。表2显示了汇总分类模型正确和不正确预测的实例数目的混淆矩阵。
| 表2 分类问题的混淆矩阵 |
表2 中“ 1” 表示正类, “ 0” 表示负类, 通常将稀有类记为正类, 多数类记为负类。TP(True Positive)表示实例是正类而且也被预测为正类的数目, FN(False Negative)表示实例是正类被预测为负类的数目, FP(False Positive)表示实例是负类被预测为正类的数目, TN(True Negative)表示实例是负类而且也被预测为负类的数目。
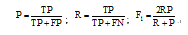
F1越大表示分类的性能越好。
(2) 个性化推荐结果评估
在完成推荐后, 有必要对推荐结果进行评估。平均绝对误差由于离差被绝对值化, 不会出现正负相抵消的情况, 因而, 平均绝对误差能较好地反映预测值误差的实际情况。因此在本文中, 采用平均绝对误差(MAE)对实验结果进行评估。
平均绝对误差[12]公式如下所示:
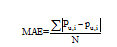 |
其中, 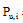
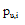
(3) 算法效率评估
从算法耗时和时间复杂度评估该算法的效率。
由表3的实验数据可以看到, 采用基于规则的分类方法按照用户的属性对用户进行分类, 分类的准确率、召回率和F1值都较高, 因此分类较精确, 结果令人满意。
(2) 算法效率对比
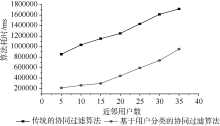
本实验的算法效率主要通过算法耗时与时间复杂度来衡量。结果如表4和图3所示。
由表4和图3可以看出, 每个不同的邻近用户数对应的分类后的算法耗时明显低于未分类的算法耗时, 为了更加准确清楚地对比两个算法的效率, 使用时间复杂度进行更精确的对比。
| 表3 用户分类结果评估 |
| 表4 算法耗时对比(ms) |
经过计算, 未分类算法的时间复杂度为O(n^4× m^2), 其中m为用户数, n为项目数。由于分类后算法运行时, 12个小组同时运算, 算法的运行时间是分类的时间加上12个类别中运行最慢的时间, 分类时Clementine决策树的时间复杂度为O(m^2.5), 所以分类后算法的时间复杂度为O(n^4× m^2)+ O(m^2.5), 即O(n^4× m^2)。由于分类后的用户数m和项目数n远远小于分类前的用户数和项目数, 因此, 分类后算法的效率相比于未分类算法的效率明显提高。
(3) 不同近邻用户数k的选择对推荐结果的影响
本实验旨在对比分析对用户进行分类和未分类情况下, 邻近用户选择的个数对推荐算法精度的影响。以初始近邻个数为5, 每次以5为间隔进行递增, 直到邻居个数为35为止, 一共进行了7次对比。实验结果如图4所示。
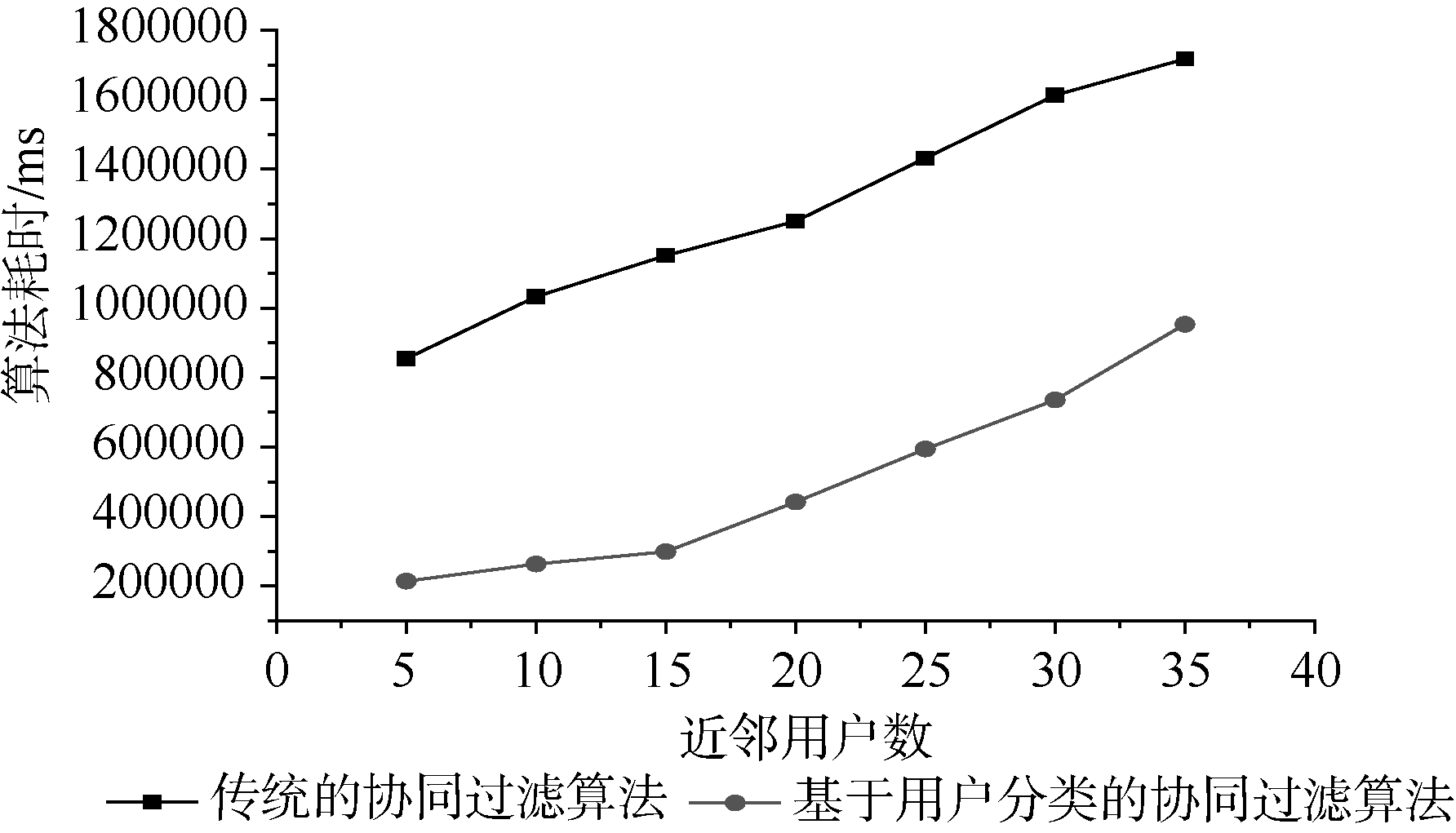 | 图3 本文算法与传统协同过滤算法耗时对比 |
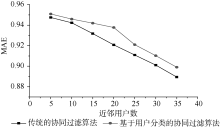
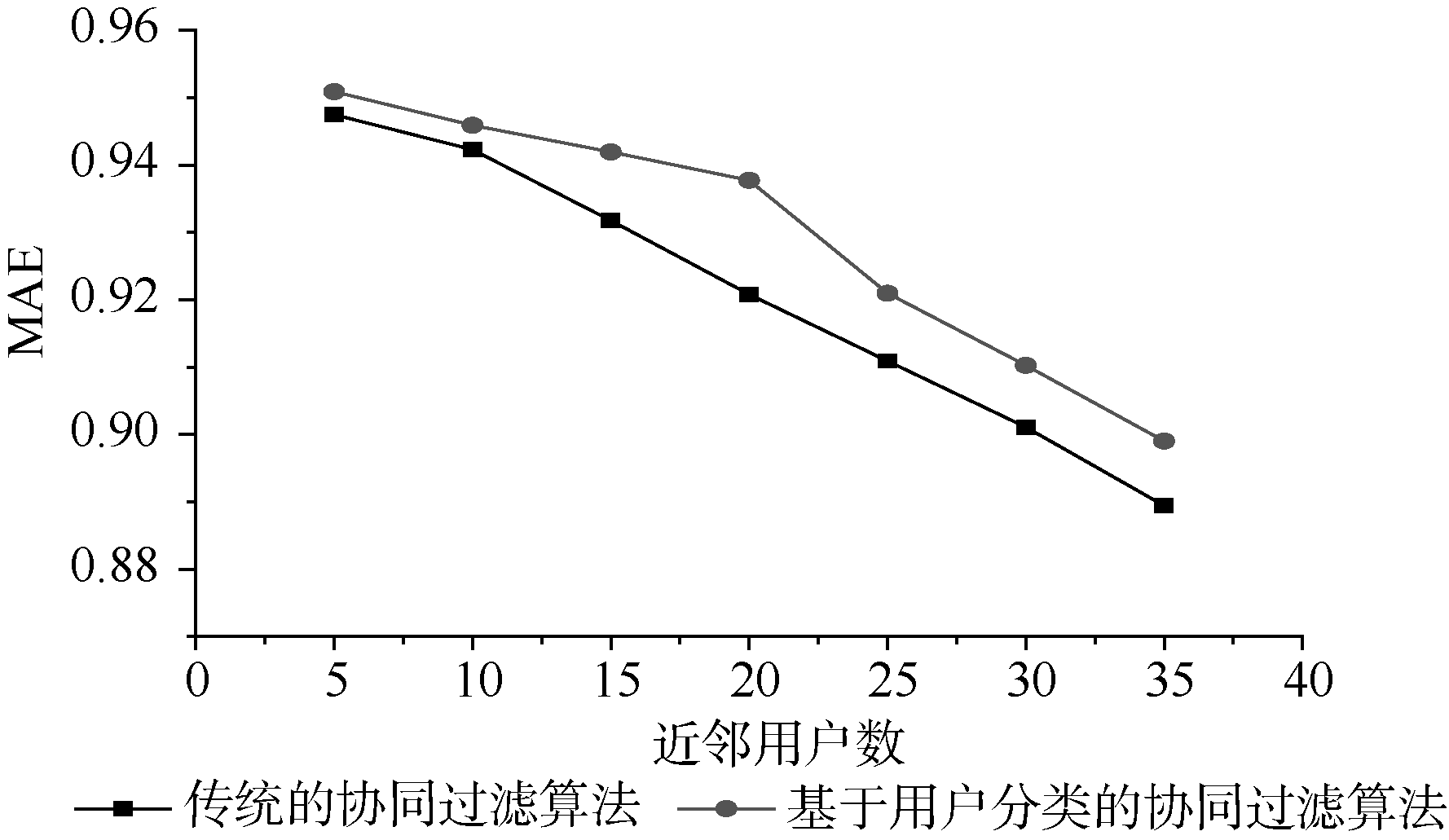 | 图4 本文算法与传统协同过滤算法预测精度对比 |
根据图4可以看到:
①基于用户分类的协同过滤算法与传统的协同过滤算法都随着近邻个数的增加, MAE值减少, 也就是说推荐精度增加。
②在近邻个数相同的情况下, 基于用户分类的协同过滤算法的MAE值相对传统的协同过滤MAE值较高, 但差别不大。误差率为 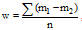
由于虚拟社区用户数量急剧增加而导致协同过滤算法计算量大、效率低。为了解决以上问题, 本文将基于规则的分类运用到协同过滤算法中, 使得在寻找近邻用户时对所有用户的相似性计算转化为对各个类别中用户的相似性计算, 这样在一定程度上减少了计算量并提高了算法效率。本文还利用平均绝对误差对推荐结果进行评估。与此同时, 研究也存在一些待改进的问题, 例如加入用户分类后提高了算法效率, 但
会在一定程度上减少推荐精度, 这个问题可以通过增加隐示评分来缓解。另外, 还存在用户对项目的评分少导致推荐不准确, 即协同过滤的稀疏性问题, 还有可扩展性问题[15], 用户的兴趣随时间的变化影响推荐结果以及用户是否接受推荐结果即信任问题[16], 这些都是下一步工作需要研究的内容。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|