{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于项目评分预测的混合式协同过滤推荐*
[盈艳, 曹妍 , 牟向伟]
, 牟向伟]
, 牟向伟]
|
|


作者简介:曹妍: 提出研究方向, 设计研究方法; 盈艳: 设计算法, 实验及分析, 论文撰写; 牟向伟: 收集数据, 论文修订。
[Objective] By improving the traditional collaborative filtering recommendation algorithm to alleviate the existing data sparseness problem, thus enhance the prediction precision. [Methods] This paper proposes a hybrid collaborative filtering recommender framework and KSUBCF algorithm integrated K-means clustering and Slope One algorithm. Firstly, this algorithm uses the Slope One algorithm based on K-means clustering to predict item default rating. And then, to implement recommendation by the collaborative filtering recommendation algorithm based on users. [Results] The experimental results show that with the increase of neighbors numbers, this algorithm is better than the original Slope One algorithm, which MAE value is reduced by 8.8% to 21% and RMSE value is reduced by 17% to 28.1%. [Limitations] This algorithm still relies on user-project score data matrix. [Conclusions] Compared with other traditional collaborative filtering algorithms, the decreases of the MAE value are 10% and 43.8% respectively and the decreases of the RMSE value are 20.1% and 37.4%. The proposed method can improve the prediction precision.
近年来, 推荐系统已经被广泛应用到电子商务(如Amazon, 当当网等)和一些社会化站点(包括音乐, 电影和图书分享, 如豆瓣, Flickr等)。这也进一步说明在Web2.0环境下, 面对海量数据, 用户需要更加智能的, 能够将无用的信息进行过滤, 只留下他们需求信息的发现机制。作为传统推荐技术的一种, 协同过滤算法因其简单高效的特点, 在应用中获得更多青睐, 同时也得到许多研究者的关注。然而, 在实际系统中存在用户评分数据过于稀疏的问题, 很多研究人员针对该问题提出了改善方法, 主要包括: 设定缺省值、降维、图论方法、奇异值分解等[1]。Huang等[2]提出将评分矩阵转化为用户和物品的双向图, 并且使用一种称为扩展激活的特殊图搜索方法分析图。这种基于间接关系的方法在评分矩阵稀疏时能提高推荐质量, 但是当评分矩阵达到某种密度之后相比标准算法推荐质量也会有所下降。王洋等[3]提出基于径向基函数(RBF)神经网络的解决方法, 采用一种动态自适应的方法选择隐含层中心节点, 从而设计隐含层构建RBF神经网络用来预测评分矩阵中的空缺值填充到原始矩阵, 利用填充的矩阵计算用户相似度, 但是该方法需要建立复杂的神经网络模型。Zhang等[4]利用预测公式通过加入适当的权重和递归次数预测矩阵中的空缺值, 其中最重要的参数就是递归次数, 随着递归次数的增加计算代价也随之增加。
以上方法虽然在一定程度上缓解了稀疏性问题, 但是也存在其他问题, 主要表现在: 算法过程复杂实现困难, 增加资源消耗等。本文提出基于项目评分预测的混合式协同过滤推荐算法不仅能缓解稀疏性问题, 而且简单易实现。该方法整合K-means聚类和Slope One[5]两种算法, 试图有效缓解评分矩阵稀疏性问题。
本研究是基于协同过滤推荐算法和Slope One推荐算法的相关研究成果, 已有研究成果总结如下。
协同过滤推荐技术主要包括基于内存和基于模型两大类。其中, 基于内存的推荐包括基于用户的推荐和基于项目的推荐两种方法, 其核心思想都是根据用户评分矩阵计算用户间或项目间的相似度从而实现推荐。协同过滤推荐技术主要包括以下三个步骤:
(1) 构建用户-项目评分矩阵。收集用户在进行浏览或购买行为后的评价信息, 并对数据进行清洗、转换和录入后得到用户-项目评分矩阵, 如表1所示:
| 表1 用户-项目评分矩阵 |
其中, Rm, i表示用户Um对项目Ii的评分数据。Rm, i的取值范围可以是[1, 5], 也可以是其他范围。比如: Jester网的评分数据范围是[-10, 10]。通常用来表示用户对项目的喜好程度, 如果用户没有对项目进行评分, 则用空值或者零值表示。
(2) 寻找用户最近邻居集。采用相似性度量方法计算用户间相似度, 协同过滤推荐算法中度量相似度的方法有很多, 比较常用的有三种[6, 7, 8]: 余弦相似性、修正的余弦相似性和相关相似性。在协同过滤算法中针对不同的研究对象各种相似性度量会有不同的表现, 相关相似性度量方法适合User-based的协同过滤算法, 而修正的余弦相似性度量方法适合Item-based的协同过滤算法。总之, 这两种度量方法具有良好的推荐性能。根据用户间相似度矩阵选择目标用户的K个最相近邻居作为实现预测的集合, 或设定一个相似度阈值, 选择超过阈值的用户作为目标用户的邻居。
(3) 产生推荐。获得目标用户的最近邻居集合后, 将相似度作为权重可以得到目标用户对未评分项目的预测, 形成Top-N列表推荐给用户。
Slope One推荐算法是由Lemire等[9]提出的一个Item-based推荐算法。该推荐算法认为, 平均值可以调和不同用户对物品的评分差异, 而且虽然是协同过滤算法的一种, 但不用计算用户间或项目间的相似度。Slope One算法因其简单高效易实现的特点被应用到许多推荐系统中, 如: Hitflip DVD推荐系统, inDiscover MP3推荐系统, Value Investing News 股票新闻网站, AllTheBests 购物推荐等[10]。Slope One算法通过两个步骤实现预测:
(1) 给出一个训练集和任意两个项目Ii和Ij, Ui, j表示同时评价过项目Ii和Ij的用户集合, 则项目Ii和Ij评分的平均偏差如下[11]:
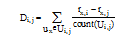 |
其中, rx, i表示用户X对项目i的评分, 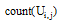
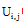
(2) 目标用户u对目标项目i的预测评分如下:
 |
其中, 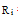
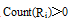
另外, Slope One算法一般有两种实现方式: 加权Slope One算法和双极Slope One算法。虽然该方法简单实用但是仍存在一些缺点: 忽略了用户间和项目间的相似性, 而且在数据稀疏时, 推荐效果不如传统协同过滤算法好。所以本文将整合K-means聚类算法和Slope One算法预测填充稀疏的评分矩阵, 再用协同过滤技术实现推荐。Wang等[12]提出将Slope One预测算法和基于用户的协同过滤算法合并, 但是没有考虑到项目间的相似性, 即使两用户很相似但如果他们分别喜欢不同类型的项目, 那么推荐效果也不乐观。因此, 将项目用K-means算法聚类后对每一类进行预测填充, 再结合协同过滤算法能够提高推荐的精确度。
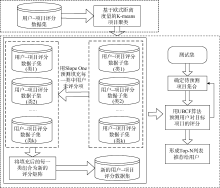
整合K-means聚类和Slope One算法的混合式协同过滤框架如图1所示。
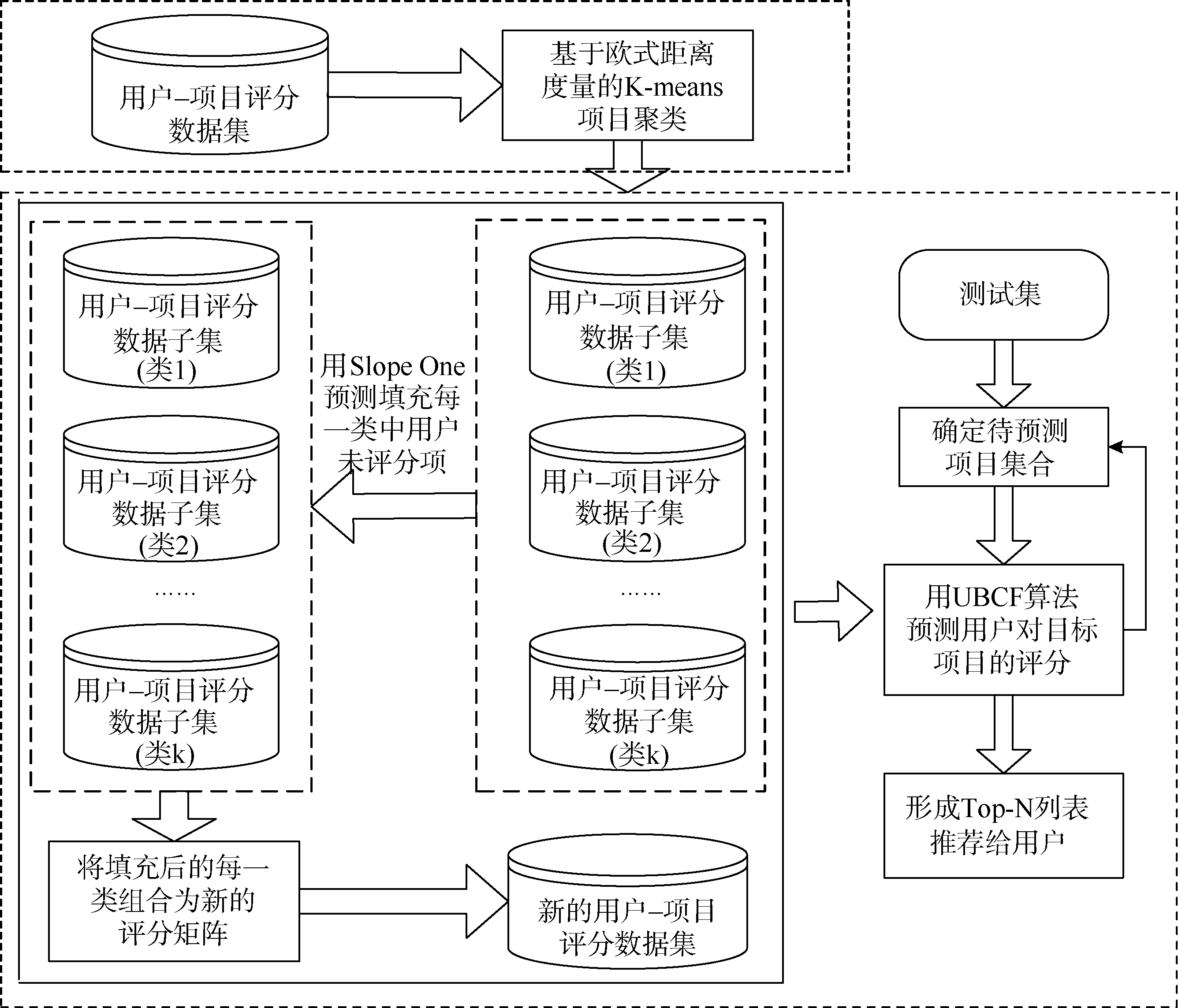 | 图1 整合K-means聚类和Slope One算法的混合式协同过滤框架 |
该框架可大致分为上下两部分, 上面一部分是将整理好的用户-项目评分数据集进行基于欧式距离度量的K-means项目聚类, 从而得到k类用户-项目评分数据子集。下面一部分又分为两步, 第一步将各个评分数据子集中的未评分项采用Slope One算法进行预测填充, 组合成新的不再极度稀疏的用户-项目评分矩阵; 第二步就是结合基于用户的协同过滤推荐算法预测目标用户对测试集中目标项目的评分, 产生Top-N列表推荐给用户。
根据以上分析并结合混合式协同过滤框架, 提出一种整合K-means聚类和Slope One算法的协同过滤算法KSUBCF。其具体实现步骤如下:
(1) K-means项目聚类。从用户-项目评分矩阵R(mxn)中抽取用户集合U、项目集合I, 用K-means聚类算法进行项目聚类, 但是由于用户评分矩阵是一个稀疏矩阵有许多未评分项, 计算两项目间距离时要求用户对这两个项目均有评分, 因此聚类过程中的欧氏距离度量公式需要改进, 即:
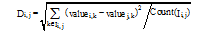 |
其中, 集合 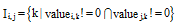
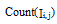

(2) 使用Slope One算法预测填充未评分项。由步骤(1)得到k类用户-项目评分数据子集, 对每一类执行以下操作:
For each 用户 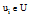
For each 项目 
If ( Ij not rated by ui)
用Slope One算法预测项目Ij的评分值Pi, j;
End if
End for
End for
(3) 将填充后的每一类按照原矩阵的列顺序组合成新的用户-项目评分矩阵 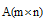
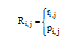 |
ri, j: if user i rated item j
pi, j: if user i not rated item j
(4) 计算用户间的相似度。根据新的用户-项目评分矩阵 
For each用户uiU
For each用户ujU
用Pearson公式计算用户间相似度Sim(ui, uj), 得到用户
相似度矩阵S(m× m);
End for
End for
(5) 对目标用户u的邻居集合c中的元素按从大到小的顺序排序, 选择前K个组成目标用户的最近邻居集Neighboru。
(6) 根据协同过滤算法的评分预测规则预测用户对目标项目集的评分从而产生推荐。用户u对项目i的评分Pu, i可以通过最近邻居集合 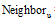
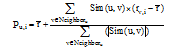 |
其中, 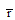
本文实验数据采用GroupLens研究组(http://www. grouplens.org)提供的电影评分数据集ML-100K中的一个数据子集, 该数据集包括943个用户对1 682部电影的10万条评分记录。由于每条记录都是以< UserID, ItemID, Ratting> 三元组的形式表示, 为了便于计算和获得比较直观的实验结果, 将原始数据转换为如表1所示的矩阵形式, 若用户未对某电影评分则设值为0, 评分标准为1-5, 评分越高表明用户越喜欢该电影。通过计算得出该数据集的数据稀疏度为6.3%, 在实验过程中将数据集按照80%和20%的比例划分为训练集和测试集进行检验。
实验采用的度量标准是MAE(Mean Absolute Error)和RMSE(Root Mean Square Error), MAE通过计算预测值与实际值的平均误差大小度量系统的推荐质量, RMSE是预测值与实际值偏差的平方和与观测次数n比值的平方根, 二者都是越小推荐质量越高。
(1) KSUBCF算法与Slope One算法比较
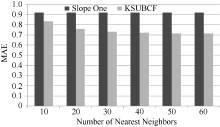
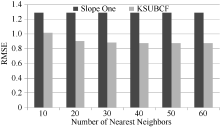
为了和该算法进行对比, 在实验中采用80%作为训练集的比例, K-means聚类时的k值取10。实验随机挑选100个用户的评分记录, 按照80%与20%比例构造训练数据集和测试数据集, 对测试数据集中每条评分记录进行预测, 求出其MAE值和RMSE值。选择10-60个目标用户的最近邻居, 每次递增10, 实验结果与测试集数据进行对比分析。测试结果如图2和图3所示:
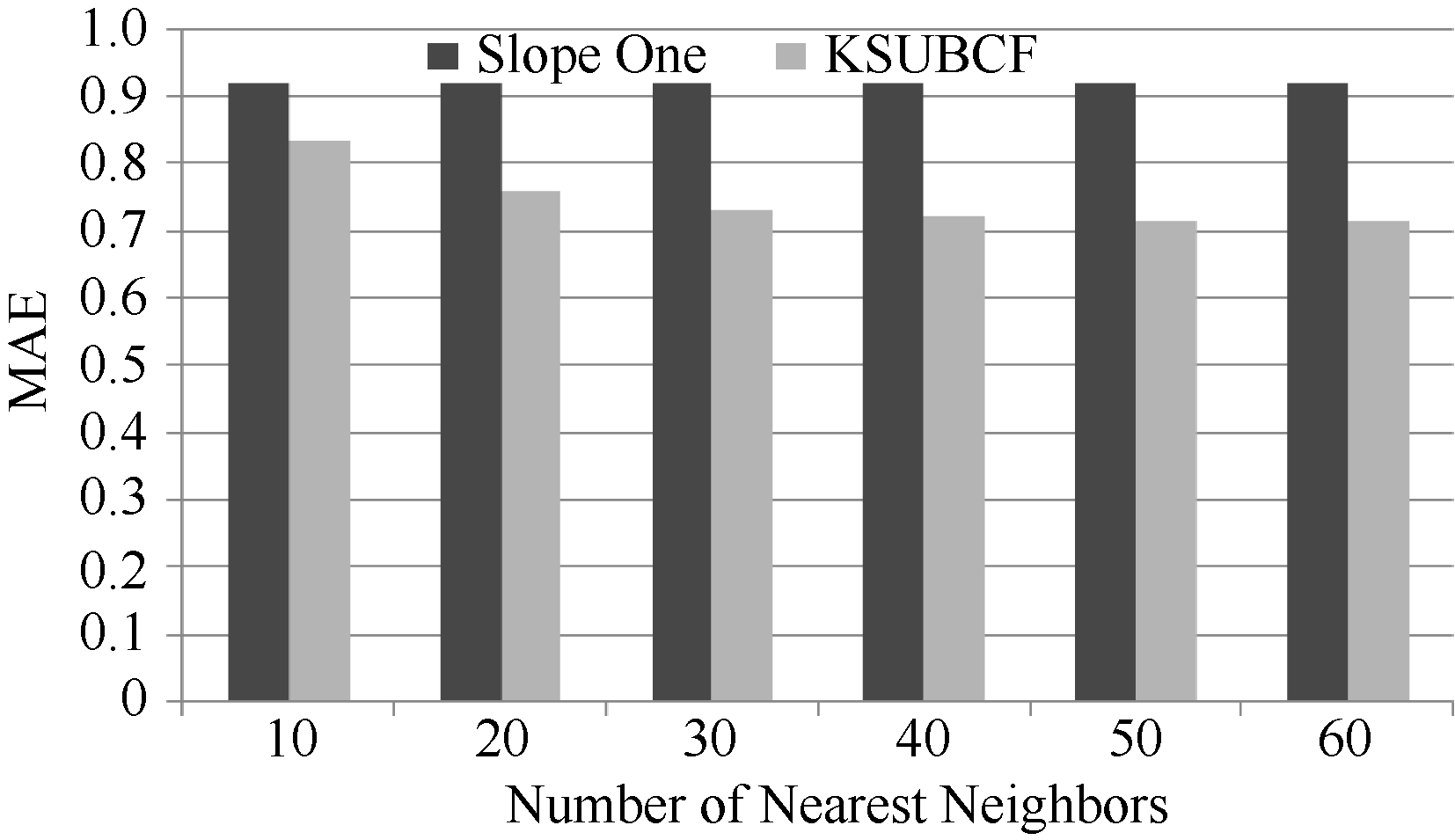 | 图2 KSUBCF算法与Slope One算法的MAE值对比 |
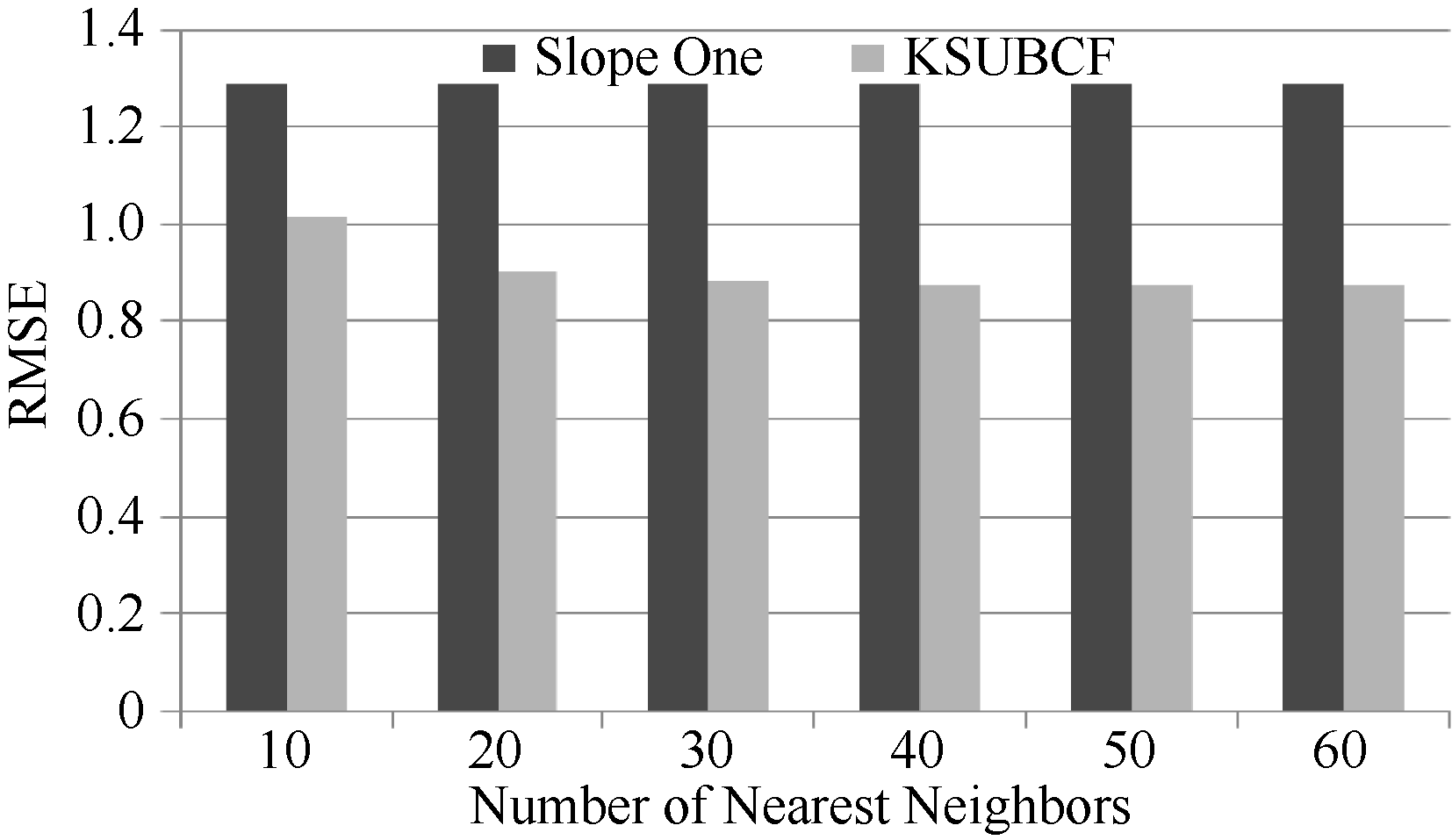 | 图3 KSUBCF算法与原Slope One算法的 RMSE值对比 |
通过实验结果对比分析可以看出, 本文提出的KSUBCF算法的MAE值和RMSE值远小于原Slope One算法的MAE值和RMSE值, 尤其是当目标用户的最近邻居数目在20到60之间的时候对比更加明显, 随着邻居数目的增加MAE值有8.8%-21%不等的下降, RMSE值有17%-28.1%的下降, 说明本文提出的算法优于原Slope One算法。
(2) KSUBCF算法与传统协同过滤算法的比较
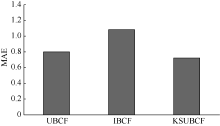
本组实验的目的是将KSUBCF算法与两种传统协同过滤算法UBCF和IBCF进行对比。
实验设置: 仍然采用上述实验的数据, 不过在进行相似度计算时基于用户的协同过滤算法(UBCF)采用的是Pearson相关相似性度量方法, 而基于项目的协同过滤算法(IBCF)采用的是修正的余弦相似性度量方法。本文提出的方法以及UBCF和IBCF算法在选择邻居用户时均采用基于前k项最近邻居的方法, 并设k值为40, 另外KSUBCF算法中项目聚类时阈值k取值为10, 前后两个k意义不同。实验结果如图4和图5所示:
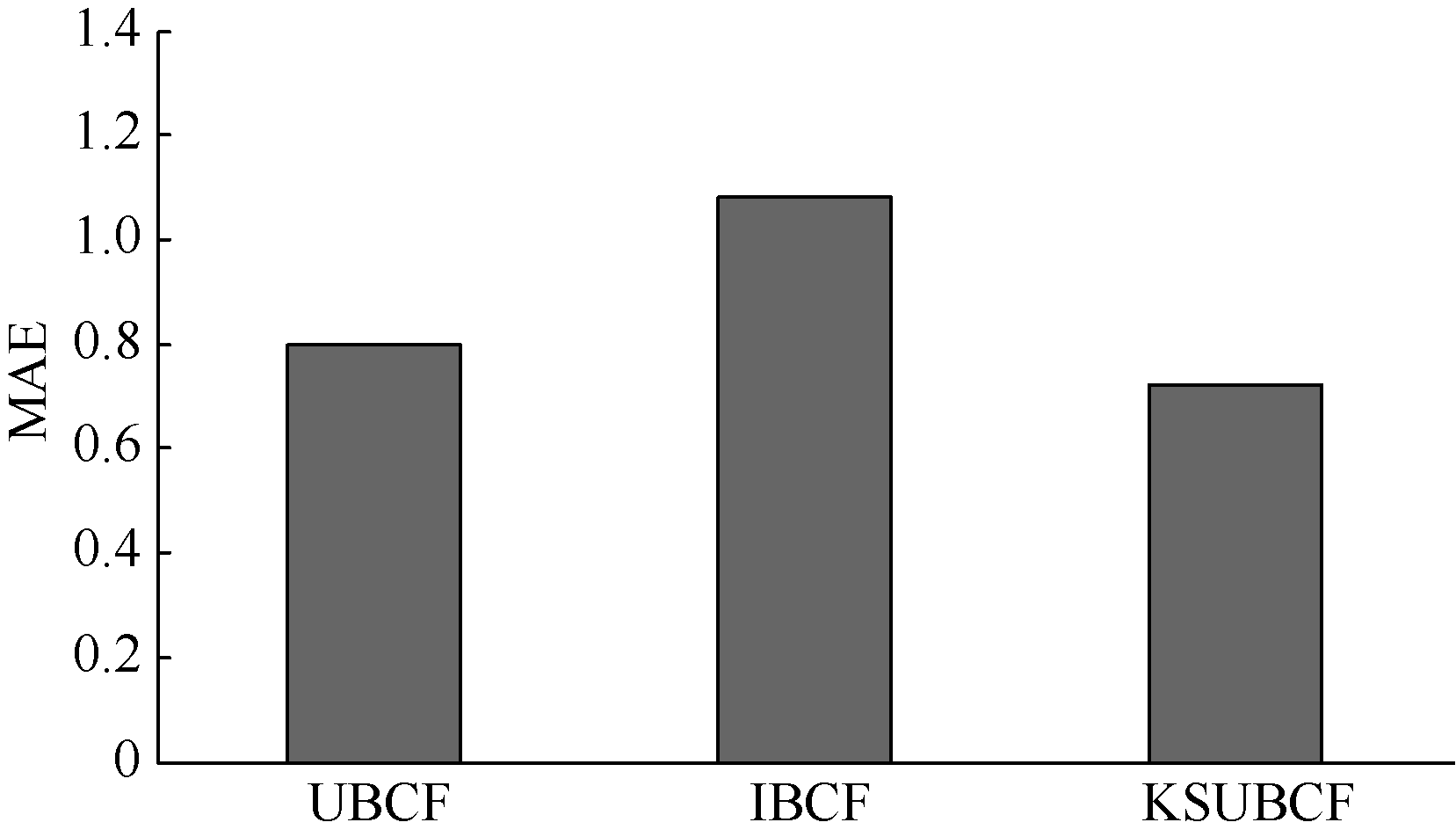 | 图4 三种不同协同过滤算法间MAE值比较 |
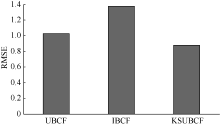
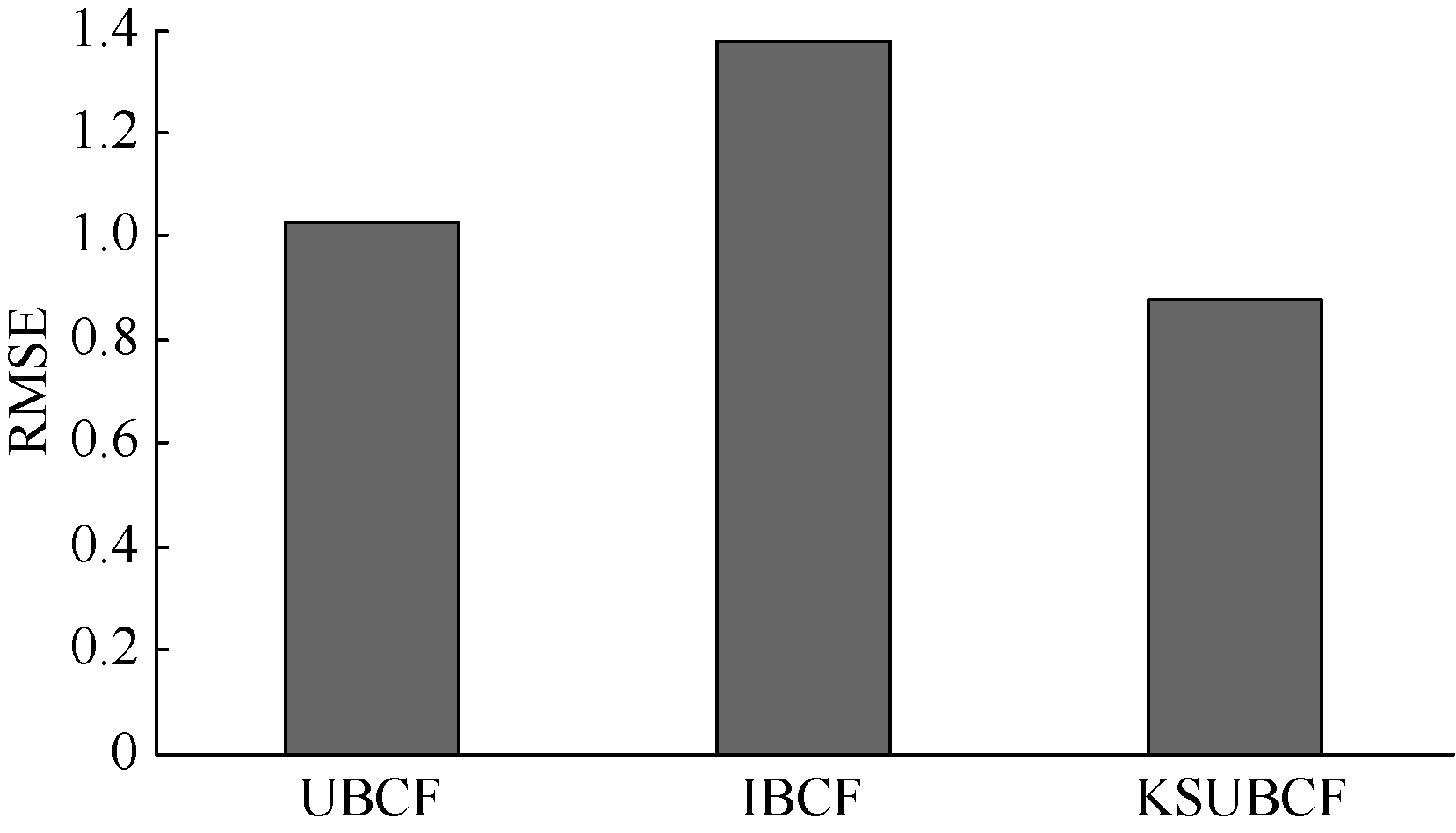 | 图5 三种不同协同过滤算法间RMSE值比较 |
分析实验结果可知, 本文提出的KSUBCF算法的MAE值较UBCF和IBCF两种算法分别有10%和43.8%的下降, 而其RMSE值较UBCF和IBCF两种算法分别有20.1%和37.4%的下降, 说明本文提出的这种新的预测填充方法提高了预测精度。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|