

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向关联数据集的本体匹配方法研究*
[高劲松 , 程娅, 梁艳琪]
, 程娅, 梁艳琪]
, 程娅, 梁艳琪]
|
|


作者简介:李胜: 确定研究方向及研究方法, 提出论文的修订意见;王叶茂: 进行算法设计及实验分析, 撰写与修订论文。
[Objective] The paper analyzes the characters of linked data set to improve the traditional Ontology matching method. [Methods] Combine the Ontology matching methods as matching rules from three aspects, which are method of data transformation, similarity of name and similarity of the description information, then use the genetic algorithm to extract the best matching rules, finally use Jena to test. [Results] Construct an Ontology matching framework for linked data set, and realize the interconnection between Ontologies of linked data set. [Limitations] The Ontology matching process mainly solves the problem of heterogeneous Ontologies, failed to match the Ontologies in different fields and languages. [Conclusions] The method can realize the correlation of the linked data set and improve the links of linked data set.
根据关联数据发布的“ 四大基本原则” [1], 关联数据的核心思想是建立Web化的、关联化的RDF表示, 因此该阶段会产生由多个分布的LOD数据集构成的数据集群, 但它们之间是独立自治的, 弱关联的, 缺乏操作接口。随着这些关联数据集之间, 以及与其他数据集(如非关联数据化的网络数据库)不断构建联系, 当最终能形成一片几近没有“ 缝隙” 的数据集云时, 就可以认为语义网的基础已经奠定。
自Berners-Lee提出关联数据以来, Web上的关联数据集越来越多。关联数据发布者大都使用不同的本体描述同一领域的信息, 本体借助结构化的术语增加RDF的领域资源表达能力, 规范了领域术语的类和属性关系; 同时本体作为重要的网络资源可利用关联数据进行发布和互联, 使用RDF技术表达的本体词汇表之间可以很容易地进行映射和互操作。其中, FOAF[2]、SKOS[3]等通用本体已在一些数据集中推广普及, 但由于种种原因, 大部分数据集使用自行设计的领域本体或应用本体, 本体之间的异构不可避免, 这无形中增加了数据冗余。
考虑到当前匹配工具单一化的匹配模式难以适应复杂各异的关联数据集, 笔者在遗传算法的启发下, 结合关联数据集的构建特点, 尝试将本体匹配方法分解为数据转换方式、名称相似度和描述信息相似度三部分。在关联数据集的匹配过程中, 将三部分匹配方法对应的子方法动态组合, 生成适合待匹配数据集的匹配规则, 以适应多元化的关联数据发布模式。
近些年, 关联数据在技术标准、发布原则、发布流程等方面的研究已经比较成熟, 但是由于关联数据在定义时的主观性较强, 导致关联数据集本体之间异构性问题突出。在实际运用中, 关联数据集的链接往往局限于单个本体, 本体之间的链接则常常被忽略。本体匹配是解决本体异构性的主要方法, 是语义网的研究热点之一, 主要包括以下几种技术: 基于名称的技术、基于结构的技术和基于实例的技术[4]。其中, 在研究关联数据的名称相似度时, 主要匹配的实体对象为类、属性和实例; 而基于结构的匹配技术需要参考元素间的层级关系, 针对关联数据的概念语义关系则主要表现在实体的描述信息上, 其中常用的是Equivalent Classes (等价类)、Equivalent Properties (等价属性)、Super Classes (子类)、Super Properties (子属性)以及Members(成员)等[5]; 基于实例的匹配思想是指当两个元素具有共同的实例时, 这两个实体可能是相似的。
与传统本体匹配不同, 面向关联数据集的本体匹配面对的数据类型更加复杂, 关联数据使用的本体框架也多种多样, 加之关联数据实体对象的定义主观性较强, 使关联数据集的本体匹配需要考虑更多的因素。在国外, Hogan等通过关联数据集, 用可扩展、分布式的方法实现实体匹配、合并和消歧[6]。Raimond等研究了一种在语义网上自动互联音乐相关数据集的互联算法[7]。Sheth等提出符合RDF数据模型规范的语义关联表示模型, 即基于数据间的属性使用统计方法进行数据间语义相似性的推导[8]。国内学者对关联数据集的互联研究主要集中于本体层面, 潘有能等提出了一种利用本体映射技术在数据集之间建立关联的方法, 从而使得实例层面的数据可以实现自动建立链接[9]。王颖等提出一种基于RDF图的本体匹配方法, 用RDF图表示本体, 使本体间的匹配问题转化为RDF图的匹配问题, 通过匹配树计算出两个本体中各实体之间的相似度[10]。马费成等提出一个基于关联数据的网络信息资源集成框架, 并依据此框架, 设计和实现了以武汉大学为基本单位的免费网络学术资源集成实验系统[11]。贾丽梅等提出基于动态权值的关联数据语义相似度计算方法, 在计算属性的权值后依据属性取值类型选用匹配相似度算法, 结合动态权值对概念进行实例的相似度计算[12]。以上研究大都是针对特定领域的特定关联数据集进行互联, 算法的通用性不强, 并不适于用复杂多样的关联数据集。
综上所述, 当前关联数据的发展状况与理想的关联数据目标还存在一定差距, 要缩小这一差距, 需要增强关联数据的语义关联。本体作为关联数据中人、机器和程序间知识交流的语义基础, 是增强数字资源语义互联的关键所在。但大多数研究者尚未认识到本体匹配在关联数据集中的作用, 他们通过语义化描述方法(RDFS/OWL)构造本体, 却忽视了本体间的语义互联, 因此, 很难挖掘出很多隐藏的语义关系。随着关联数据集的增多, 本体异质使得知识异质问题上升到一个更高的层次, 建立一个分布的、开放的系统实现知识间的语义关系, 解决本体异质问题迫在眉睫。
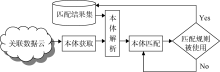
根据2014年发布的LOD数据云图[13], 现有的关联数据集已涉及地理、生命科学、医药、出版、媒体、社会网络等领域, 关联数据集的海量化、多元化与复杂化使得数据集之间的关联发现日益重要。目前本体匹配研究者主要致力于自动或半自动地建立本体间的关联。Studer等定义“ 本体是对一个特定领域中重要概念的共享的形式化的描述” [14]。结合本体语言的语法规范, 可以将本体理解为概念、属性、关系、实例和公理集合。其中, 属性即概念的属性, 关系即概念之间的关系。因此本体匹配主要任务是发现实体之间的对应关系。基于现有的匹配方法, 研究者大多是在分析本体领域特点以及本体描述方式的基础上确定本体匹配方法, 一般可以得到较好的映射结果, 但并不能确保该匹配方法适应所有领域的本体对象。鉴于现有的各种匹配算法之间并不排斥, 本文在遗传算法的启发下, 希望通过最优迭代原则选取出最适合待匹配关联数据集的匹配规则。具体而言, 面向关联数据集的本体匹配框架包括本体获取、本体解析以及本体匹配三大部分, 需要注意的是, 经过遗传迭代生成的匹配规则, 若适应当前匹配对象, 匹配结果将存入匹配结果集, 系统同时存储对应的数据映射关系, 否则重新组合新的匹配规则, 其框架如图1所示:
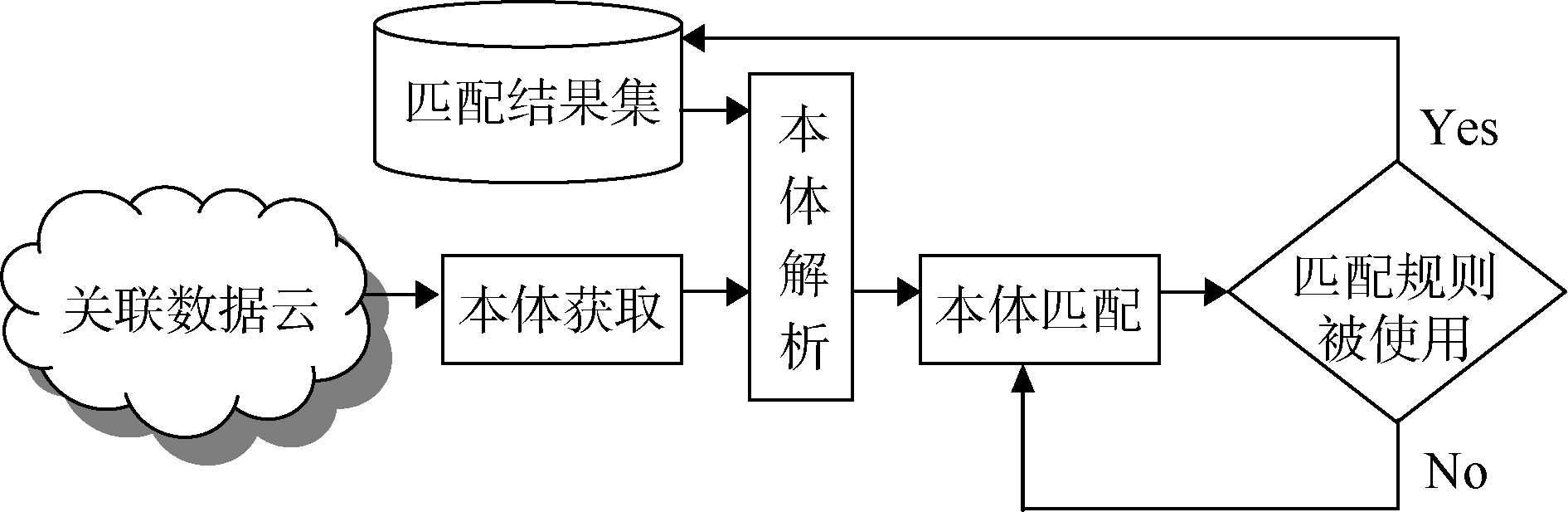 | 图1 面向关联数据集的本体匹配框架 |
LOD数据云图中收录了很多知名的数据集, 这些数据集涉及地理、生命科学、医药、出版、媒体、社会网络等领域。在本体匹配整个流程中, 要从这些已发布的关联数据集中获取本体文档。关联数据环境下的知识采用RDF描述领域知识模型和实例数据, RDF是一个资源对象和其间关系的语义数据模型, 该数据模型一般都采用RDF/XML语法编码。这些数据集均在Data Hub(数据集成交换)上进行注册, 从中可以下载到XML格式的本体文档。至此, 对关联数据集的匹配转为对本体的匹配。
对下载的本体文档进行预处理主要是选择一种解析技术提取文档中的概念及其描述信息, 为接下来的本体匹配提供一种数据规范。在解析XML文档时通常利用XML解析器对文档进行分析, 而应用程序就是通过解析器提供的API而得到XML数据。目前几乎所有的解析器都对两套标准的API提供支持, 即DOM和SAX。SAX虽然使用方便, 但不是W3C标准, 并且只能读取XML文档而不能写入它们。与SAX不同, DOM不仅可以读还可以写, DOM中的核心概念是节点, 它把XML文档的各个部分(元素、属性、文本、注释和处理指令等)都抽象为节点, 解析时通过访问节点来存取XML文档的内容。因此, 本文选择DOM技术进行本体文档解析。通过DOM解析后的本体文档将本体的各个部分(元素、属性、文本、注释和处理指令等)都抽象为节点, 这为本体匹配提供了可操作的数据模式。
本体匹配技术作为解决本体异构的重要手段, 在OAEI(Ontology Alignment Evaluation Initiative)竞赛的推动下, 产生了许多优秀的本体匹配系统。这些匹配系统的算法各异, 在设计时对名称、结构和实例三方面研究也各有侧重, 加之面向关联数据集的本体匹配面对的数据类型更加复杂, 关联数据使用的本体框架也多种多样, 一种固定的匹配策略已难以满足匹配要求。在归纳现有本体匹配方法时, 发现其算法多种多样, 各有利弊。如SF(Similarity Flooding)在结构匹配上表现突出, 而GLUE主要是侧重于基于实例的相似度匹配。除此之外, 匹配工具可接纳的数据处理量也各有差别, 近些年出现的YAM++、ServOMap在数据处理量上优于传统匹配工具。由此可知, 在面对不同类型、不同大小的数据源时, 各种匹配算法只有动态组合, 才能最大发挥算法效用。借助遗传算法思想, 笔者尝试在面对不同的关联数据本体异构问题时, 通过遗传算法的优化迭代思想, 在多种算法中选取最适宜匹配算法, 打破原有的单一匹配策略, 真正做到具体问题具体分析, 实现数据间的语义互联。
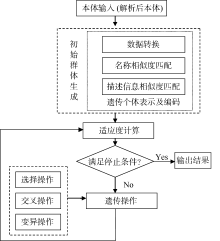
在本体匹配的过程中, 针对不同发布形式的关联数据特点, 从数据转换方式、名称相似度和描述信息相似度综合考虑匹配方法, 将每一个组合作为遗传操作个体, 而每个遗传操作个体就是一个匹配规则, 通过遗传迭代将查全率与查准率最高的遗传个体作为当前关联数据集的匹配规则, 从而完成对现有匹配方法的改进。需要指出的是, 将遗传算法引入本体匹配中, 遗传个体表示及编码、适应度计算与遗传操作有所不同。匹配流程如图2所示:
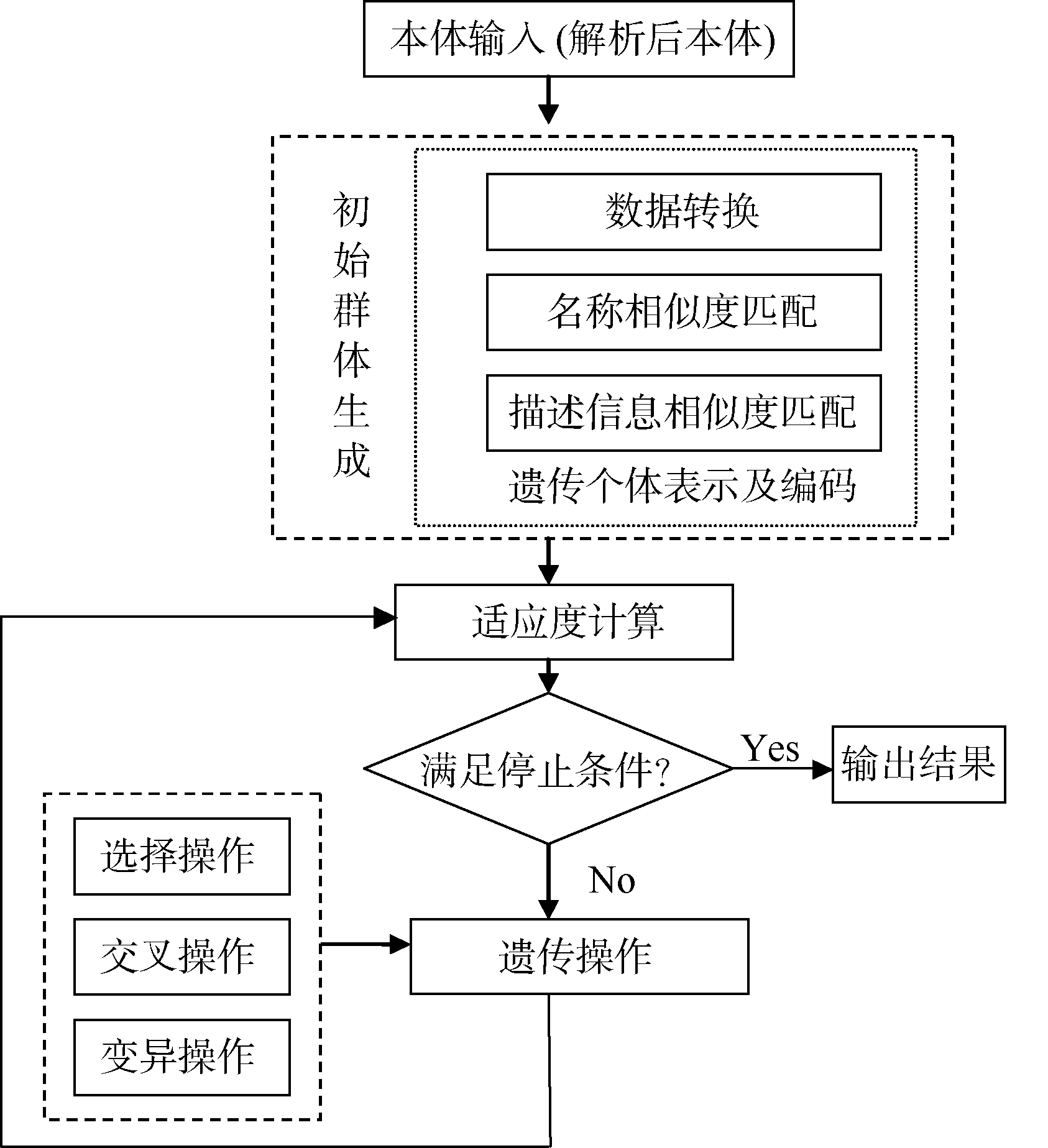 | 图2 基于遗传思想的本体匹配流程 |
(1) 遗传个体表示
遗传个体作为一个匹配规则必须具有整体的数据处理功能, 不仅能处理不同模式的数据集, 也能根据数据特点合理选择匹配算法。本文主要从数据转换方式、名称相似度和描述信息相似度综合衡量匹配规则的适应度。
①数据转换方式
上文已指出不同的关联数据集可能会使用不同的本体描述同一领域的信息。例如FOAF在编写人名时采用foaf:firstName和foaf:lastName格式, 而DBpedia本体在表示人名时只使用dbpedia:name。为了计算不同模式数据集的相似度, 需要转换数据模式。上面的例子中, 可以使用concatenate方法将foaf:firstName和foaf:lastName合并为单一名称, 也可以使用tokenize方法分解dbpedia:name。根据关联数据集的特点, 总结出4种数据转换方式, 具体描述如表1所示。
| 表1 数据转换方法及其遗传编码 |
②名称相似度匹配
目前基于名称的相似度研究已趋于成熟, 表2列举了5种主流方法。这些方法在数据处理效率上各有优缺点, 如Jaro-Winkler Distance[15]适合于较短字符之间的相似度计算; Levenshtein Distance[16]通过对源数据进行插入和删除操作转换为目标数据, 算法简单, 但准确率较低。Jaccard Distance[17]难以识别像aunt和ant这样虚假相似的概念对。ISUB[18]不仅记录数据之间的相同字符, 同时也计算其差异度。它可以捕捉到如number of pages与numpages这样缩写的相似概念。q-gram[19]适合处理大规模的数据集, 它先对字符串进行q切分, 通过建立切分单元与数据的索引计算相似度, 这种算法比较复杂, 计算量大, 需要较大的存储空间。鉴于上述分析, 在匹配方法选择时, 应在综合考虑数据的表达形式、数据集规模等因素的情况下合理选择算法。
| 表2 名称相似度匹配方法及其遗传编码 |
③描述信息相似度匹配
根据关联数据发布的“ 四大基本原则” , 关联数据的核心思想是建立数据结构化的、关联化的RDF表示, 因而对关联数据语义关系的分析必不可少。关联数据的语义关系主要表现在描述信息上, 关联数据的描述信息包括Equivalent Classes(等价类)、Equivalent Properties(等价属性)、Super Classes(子类)、Super Properties(子属性)以及Members(成员)等, 在计算关联数据集的语义关系时, 可以引入结构相似度匹配方法, 大致可分为两大类: 基于树的结构匹配方法和基于图的结构匹配方法, 如表3所示。ASCO[20]算法来源于ASCO匹配工具, 它综合计算概念的临近节点、概念路径与概念属性的相似度, 易移植于RDF数据模式上, 但不适于处理结构复杂、层次高的本体对。TreeMatch[21]和MassMatch[22]都是基于树的匹配方法, 这两种方法适合处理结构复杂的本体对, 在数据处理量上MassMatch略低于TreeMatch方法。SF[23]是一对一的相似度匹配算法, 从数据输入、图构建、数据映射到数据过滤形成一个完整的匹配系统, 算法独立性强, 但计算时间较长。
| 表3 描述信息相似度匹配方法及其遗传编码 |
定义1: 匹配规则Sv={DTl, NSm, DSn} (0< l≤ a, 0< m≤ b, 0< n≤ c), 其中v表示种群的大小, DT表示数据转换的方法, NS表示基于名称相似度的方法, DS表示描述信息相似度的方法, l、m、n表示当前匹配操作选择的匹配方法数量, a, b, c分别表示相对应的匹配方法的种类数量, 其值会随着研究的深入而发生变化, 在当前研究现状下, 依据表1-表3数据, a的取值为4, b的取值为5, c的取值为4。
需要指出的是, 不同于传统遗传算法, 在对融合规则的三个基因位进行遗传操作时, 由于各基因位代表不同类别的算法, 变异操作不能跨基因位进行, 否则会造成同种类别匹配算法的重复选择, 降低系统的匹配效率。如第二个基因位的算法内容只能在基于名称相似度的5种算法中选取。在迭代最初, 系统会自动根据给定的初始群体大小生成初始群体, 从数据转换方式、名称相似度和描述信息相似度三方面随机组合匹配规则进行遗传评估操作。
(2) 遗传个体编码
遗传个体有很多种编码方式, 目前应用最多的是二进制编码。鉴于匹配规则的特殊性, 本文选择符号编码法。在遗传个体长度给定的情况下, 遗传个体中每个基因的取值为该基因位所对应的算法类别的编号。
每个准则由三种不同的分类方法(DTl, NSm, DSn)组合而成, 对应每种分类方法的子方法数量为 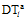
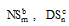
subAspNum = 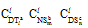
表1-表3已罗列出数据转换方式、名称相似度和描述信息相似度匹配方法, 笔者相信随着研究的深入, 基于这三方面的算法会更加丰富充实。依据表1-表3的数据, 确定染色体的长度为3, 基因位的取值为1-5, 如产生遗传个体: {3, 2, 2}, 则这个遗传个体将使用stripUriPrefix方法转换数据形式, 选用Levenshtein方法计算名称相似度, 用TreeMatch计算描述信息相似度。
(3) 适应度函数
适应度函数直接关系到遗传个体的质量, 也就是匹配规则遗传到下一代的概率。一个有效的融合规则应该是可以尽可能地发现知识之间的关联, 消除知识的歧义与异构。在测验匹配规则效率时, 匹配规则会作用到已被专家建立关联的本体对上, 若匹配规则可以生成与专家相同或相似的关联, 则认为该匹配规则适用于当前匹配集。鉴于遗传个体的特殊性, 本文选择综合评价指标(F-measure)评估匹配规则的适应度, 在检测遗传个体的适应度时, 从数据源中抽取部分数据作为训练数据, 并在专家的支持下建立这两个本体的关联, 将进化生成的匹配规则作用于训练数据, 查全率(R)与查准率(P)最高的遗传个体成为当前数据源的匹配规则。其计算公式如下:
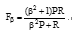
其中, β 是参数, 一般取值为1。
(4) 遗传操作
遗传算法通过一系列算子决定后代的适应度, 算子对当前群体中选定的成员进行重组和变异, 是遗传算法的主要操作部分。在进行遗传操作时, 需要设置种群规模、迭代次数、阈值、交叉概率以及变异概率等基本参数, 其中种群规模指初始群体的数量, 由于关联数据集之间的不一致性, 要根据归一化之后的结果确定, 维数小的集合可用NULL补齐; 迭代次数表示遗传运算最大迭代次数; 阈值的设定是为排除不能进行匹配操作的遗传个体; 交叉概率和变异概率应根据实际情况合理设置。不同于传统遗传算法, 本文将匹配规则作为遗传个体。根据对匹配规则的定义可知, 基于本体匹配的遗传个体包含三个基因位, 它们分别对应数据转换方式、基于名称的相似度匹配和基于描述信息的相似度数据转换方式、名称相似度和描述信息相似度匹配。遗传匹配算法描述如下:
输入: 匹配规则Sv, 种群规模n, 交叉概率Pc, 变异概率Pm, 迭代次数T, 阈值θ , 适应度函数Fβ 。
输出: 匹配规则集S。
①初始化种群P={S1, S2, …, Sn}, 并对遗传个体编码;
②将遗传个体作用于已建立关联的本体对, 计算其适应值Fβ ;
③选择, 若Fβ (Si)≥ θ , 则 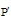
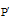
④交叉, 从当前群体中随机抽取两个遗传个体Sj和Sk, 按给定的交叉概率Pc进行交叉操作, 得到两个新个体 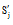

⑤变异, 按照变异概率Pm进行变异操作, 变异后产生的遗传个体进入下一代种群 
⑥判断迭代次数是否达到预定值T, 若达到则进入步骤⑦; 如果种群 
⑦输出结果;
⑧匹配规则提取。
由算法描述可知, 初始化群体生成后, 系统采用联赛选择算法(Tournament Selection)选择操作个体, 它在交配池中竞争每一位基因遗传, 适应性最好的将获得该基因的遗传权, 保证当前群体中适应度最高的个体结构完整地复制到下一代群体中, 使得遗传算法终止时得到的最后结果是历次迭代中出现的最高适应度个体。交叉算子是生成新匹配规则的重要步骤, 单点交叉是目前普遍使用的方法, 它将随机确定的交叉点的前后部分进行交换, 生成两个新的遗传个体 

实验以OAEI提供的测试集为数据源, OAEI 数据集中的每个测试案例是由两个待匹配本体和一个参考映射结果组成。实验通过利用关联数据技术和本体匹配技术, 展示了基于遗传算法的本体匹配过程。
采用Eclipse为开发环境, 该平台为编程人员提供了一流的Java集成开发环境, 同时选择基于Java语言的开发包Jena作为解析OWL文档的工具。实验数据采用两个描述参考文献信息的本体O1和本体O2, 但它们的专业术语并不完全一样, 而且它们的侧重点也不一样。实验数据源包含36个类, 73个属性, 57个实例, 其部分实验数据如图3所示。
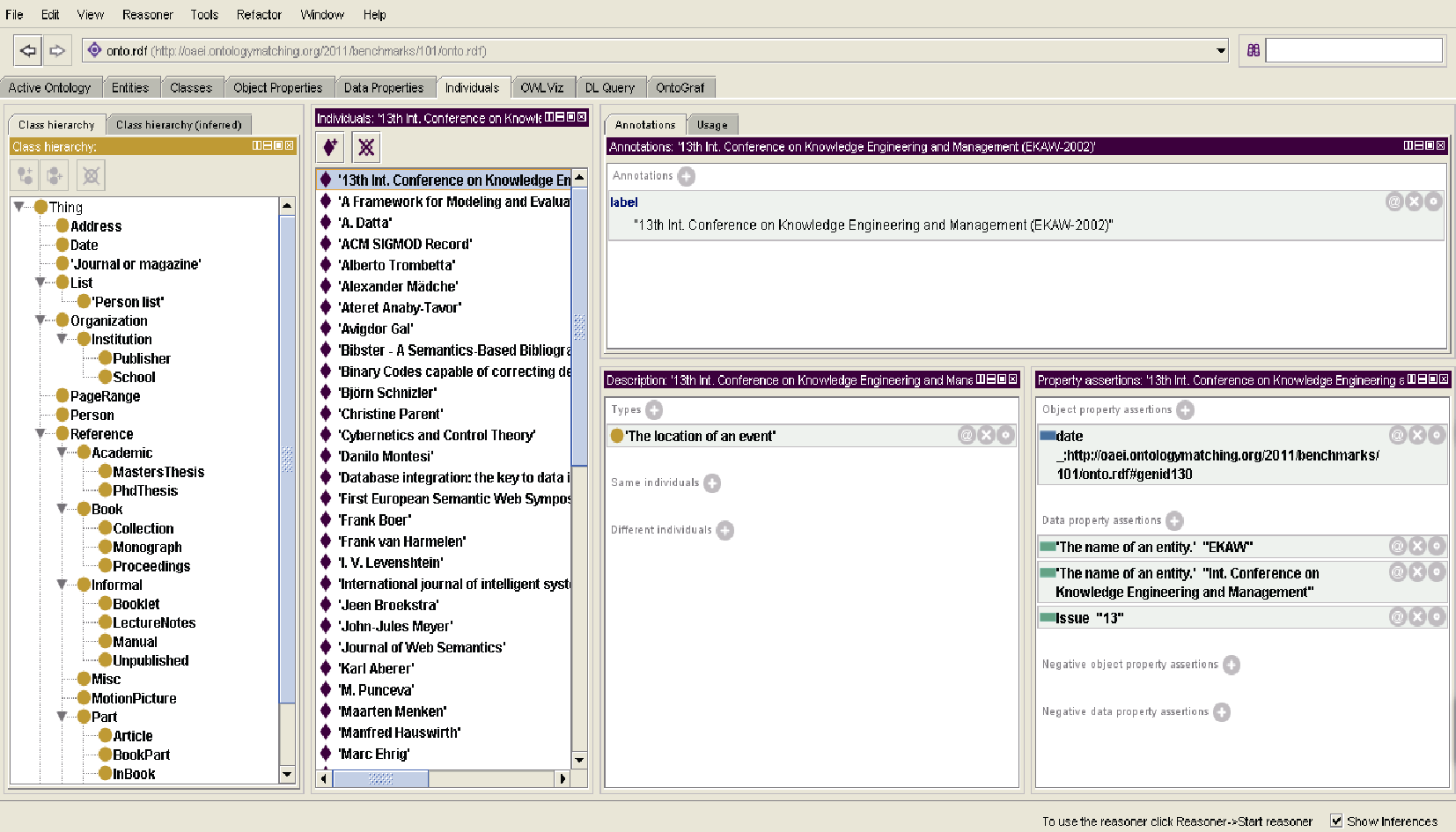 | 图3 部分实验数据 |
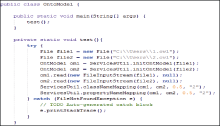
将实验数据源通过Jena解析为OWL文档后, 使用Eclipse开发环境, 对匹配算法动态组合, 编写选定的本体匹配算法。通过相似度输出判断当前匹配组合的查全率与查准率, 若当前匹配组合和测试集的映射关系高度相似, 则选取, 否则继续迭代, 选择最优的匹配算法组合。图4、图5分别为部分相似度算法及部分相似度输出。
 | 图4 部分本体匹配算法 |
 | 图5 部分相似度输出 |
通过遗传思想的迭代规则, 动态组合得到最优的匹配组合, 数据转换方式选择LowerCase, 名称相似度匹配选择Levenshtein方法, 并采用ASCO的结构算法计算节点之间的相似度, 得到匹配结果。为了进一步评价算法性能, 本文所提算法和单独使用Levenshtein算法进行了对比, 两种算法实验中得到的匹配结果如表4所示。
| 表4 匹配结果 |
可以看出, 实验中基于遗传算法的本体匹配方法获得的Fβ 的值高于Levenshtein算法的匹配结果。考虑到概念定义的主观性, 本文提出在本体匹配过程中, 通过转换数据方式实现对数据的预处理, 在计算概念相似度时采用基于名称的匹配方法; 综合考虑关联数据的构建特点, 通过分析关联数据集的描述信息获取概念的结构关联。实验结果表明, 该本体匹配方法可以利用遗传迭代思想实现数据源之间的关联, 进一步提高关联数据集的链接水平。
目前关联数据的研究中不乏解决本体异构的案例。如美国国会图书馆利用SKOS(简单知识组织系统)将传统的主题标目的知识关联转换成Web可用的关联数据形式, 这些SKOS数据可以从多层面与外界互操作, 如LCSH概念链接、GeoNames等[24]。又如, 瑞士国家图书馆开放的关联数据使用的词汇表创建了到LSCH和DBpedia的外部链接[25]。然而, 这些基于关联数据的知识互联案例普遍处于起步阶段, 其互联框架各异, 导致各自的知识链接数据难以共享互联。在遗传思想的启发下, 将现有的本体匹配方法分类组合, 迭代生成适合待匹配数据集的匹配方法, 以解决关联数据集的本体之间异构问题, 但是改进的方法无法兼顾多领域与跨语言的本体匹配。因此, 如何构建通用的本体匹配框架, 有待进一步研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|