



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种应用多储备池回声状态网络的图像语义映射研究*
[王华秋1  , 王斌
, 王斌1 , 聂珍2 ]
, 王斌|
|


作者简介:王华秋: 提出研究命题、研究思路和实验方案, 论文最终版本修订; 王斌: 采集、分析数据, 算法设计及实现, 论文起草;聂珍: 文献检索及综述。
[Objective] The mapping between low-level visual feature and high-level semantic information is built up to fill the “semantic gap” of image retrieval and improve accuracy. [Methods] Referring to the idea of ensemble learning, Multiple-Reservoirs Echo State Networks (MESN) is applied to semantic mapping model. After the low-level visual features of images are divided by feature types and trained by different reservoirs, the training results are combined linearly. [Results] Compared to BP Neural Network and traditional Echo State Network, the average error rate of MESN decreases by 31.64% and 19.28% respectively, the precision rate increases 4.56% and 1.86% respectively. [Limitations] The parameters of reservoirs are set artificially. Parameter optimization algorithm isn’t constructed. [Conclusions] Experimental results show that the semantic mapping model of Echo State Networks with Multiple-Reservoirs is effective.
随着计算机技术、Internet网络以及存储技术的发展, 各种形式的数字信息正在以惊人的速度增长。数字图像作为数字信息的重要成员之一, 以其内容丰富、形象生动、清晰明了等特点在社会生活中扮演着越来越重要的角色, 与此同时, 人们对图像检索的需求也越来越高。20世纪90年代, 基于内容的图像检索技术(CBIR)应运而生[1], 该技术与图像识别技术进行了深层次的结合, 但单纯的图像低层特征无法表示图像的内在本质, 深层语义得不到很好的体现, 也就是存在所谓的“ 语义鸿沟” [2]。
由于机器学习技术能够很好地获取图像低层特征和文字描述之间的对应关系, 越来越多的研究者将机器学习技术应用于图像的语义映射之中[3, 4, 5], 以解决“ 语义鸿沟” 问题, 并取得了一定的成果。Li等[3]将模糊支持向量机(FSVM)应用于图像分类与检索中, 通过模糊支持向量机计算出样本x对i类的归属程度 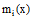
将样本x归属到 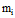
针对上述问题, 本文结合语义映射框架, 尝试性地将回声状态网络分类模型[7]应用于图像语义映射之中。由于回声状态网络以随机稀疏连接的储备池作为隐藏层, 结构相对简单, 并且只需训练储备池至输出层的权值, 训练过程简单快速, 有效地解决了传统神经网络训练速度慢、结构复杂等问题。同时, 为解决图像特征数据间关系复杂、维数较高的问题[8], 引入集成学习思想, 对图像特征按相关性进行划分, 针对划分后的图像特征分别构造储备池形成多个分类器, 并对各分类器得到的分类结果进行集成, 使得各分类器对特征数据更具针对性, 并且能够提高分类器的泛化能力和鲁棒性。
图像的低层特征主要包括图像的颜色、纹理、形状等。本文主要利用图像的颜色矩、灰度共生矩阵以及Gabor小波变换提取图像的低层视觉特征。
(1) 颜色矩[9]能够很好地描述颜色的分布特征。通常提取颜色分量的一阶矩、二阶矩和三阶矩表示图像的颜色分布。一阶矩表示每个颜色分量的平均强度, 二阶矩表示待测区域的颜色方差, 三阶矩表示颜色分量的偏斜度及不对称性。本文提取图像R、G、B三种颜色分量的三个低阶矩, 共9维。
(2) 灰度共生矩阵[10]是对图像上保持距离d的两像素分别具有某灰度的状况进行统计得到的。假设图片共有M× N个像素点, 从某像素点(x, y)开始, 该像素点的灰度级为i, 灰度共生矩阵即统计与其方向角为θ 、距离为d、灰度级为j的像素点同时出现的概率, 假设 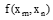
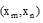
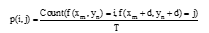 |
其中, T表示灰度共生矩阵元素个数。本文取通过灰度共生矩阵得到的能量、对比度、相关值以及熵4个特征值分别在0° 、45° 、90° 、135° 方向的最大值、最小值、平均值及标准差值作为训练集, 共16维。
(3) Gabor小波变换[11]与人类视觉系统中简单细胞的视觉刺激响应非常相似。在提取目标的局部空间和频率域信息方面具有良好的特性。Gabor函数是一个用高斯函数调制的复正弦函数, 能够在给定区域内提取局部的频域特征, 本文所用的Gabor滤波器对应的实部如公式(2)所示, 虚部如公式(3)所示。
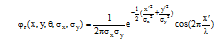 |
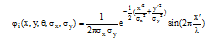 |
其中:
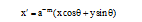 |
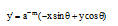 |
通过实部及虚部滤波后得到的图像如公式(6)所示:
其中, (x, y)为空间域像素坐标, 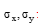
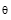
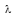
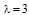
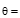
 | 图1 6个不同方向的二维Gabor小波 |
 | 图2 经不同方向Gabor小波过滤后图像 |
本文提取不同方向的Gabor小波变换过后结果的能量均值及标准方差作为特征, 共12维。
回声状态网络(Echo State Network, ESN)由Jaeger[12]于2001年提出, 其独特之处在于将随机稀疏连接的神经元构成的储备池作为隐藏层, 用以对输入进行高维的、非线性的表示[13]。ESN是一种新型的递归神经网络, 由输入层、储备池、输出层组成, 其结构如图3所示:
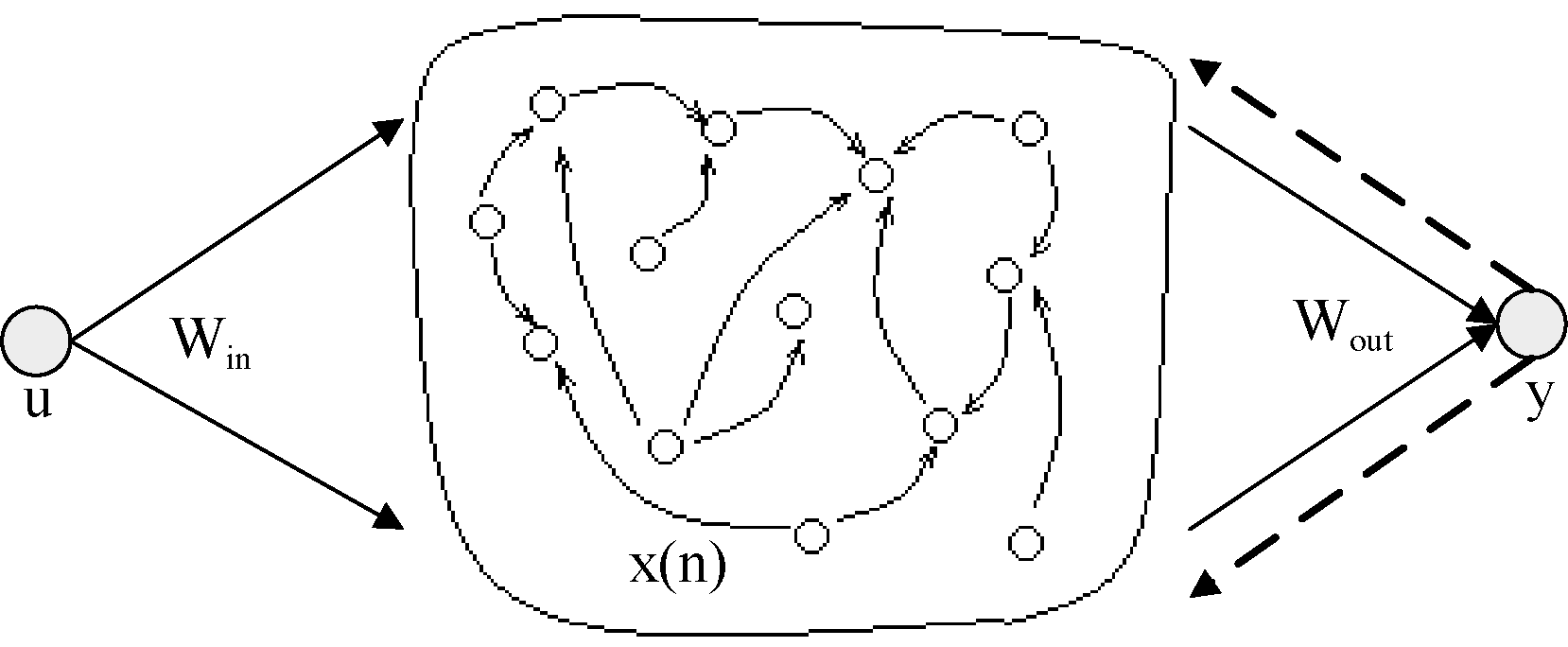 | 图3 回声状态网络结构 |
假设该网络中输入层有K个输入, 储备池有N个内部连接单元, 输出层有L个输出, 储备池内部单元状态更新方程如公式(7)所示:
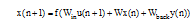 |
其中, 
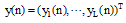
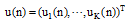
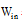
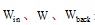
网络输出如公式(8)所示:
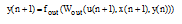 |
其中, 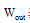
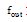
回声状态网络常用于解决时间序列预测方面的问题, 2009年, Alexandre 等[7]提出面向静态模式分类的回声状态网络方法。在此基础上, 彭喜元等[14]提出了随机子空间多储备池分类模型, 提高了传统回声状态网络分类模型的泛化能力及分类性能; 郭嘉等[8]提出了基于相应簇的回声状态网络静态分类方法, 将储备池子簇与需分类数据类别数量建立对应关系, 能够更好地满足对不同数据有针对性的分类需求。
分类模型不同于预测模型, 各数据间并不存在依赖关系, 所以回声状态网络分类模型在训练某特征数据对应的状态变量 
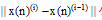
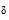
状态变量调整公式如下所示[7]:
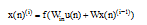 |
其中, i表示训练迭代次数, n表示样本下标, 一般情况下, 激励函数选择双曲正切函数tanh, 训练完成的条件如下:
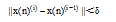 |
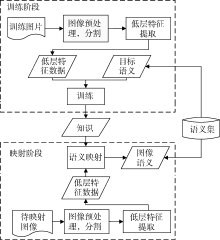
图像的语义映射主要是通过分析训练集中图像的特征, 并通过机器学习的方式将训练集中的图像低层特征和语义关键词建立联系, 得到一定的知识或者规则, 之后通过这些知识对新图像进行语义映射, 从而获得新图像的高层语义描述。整个框架主要包括图像低层特征提取、语义训练、样本图片语义映射等环节。本研究采取的语义映射框架如图4所示:
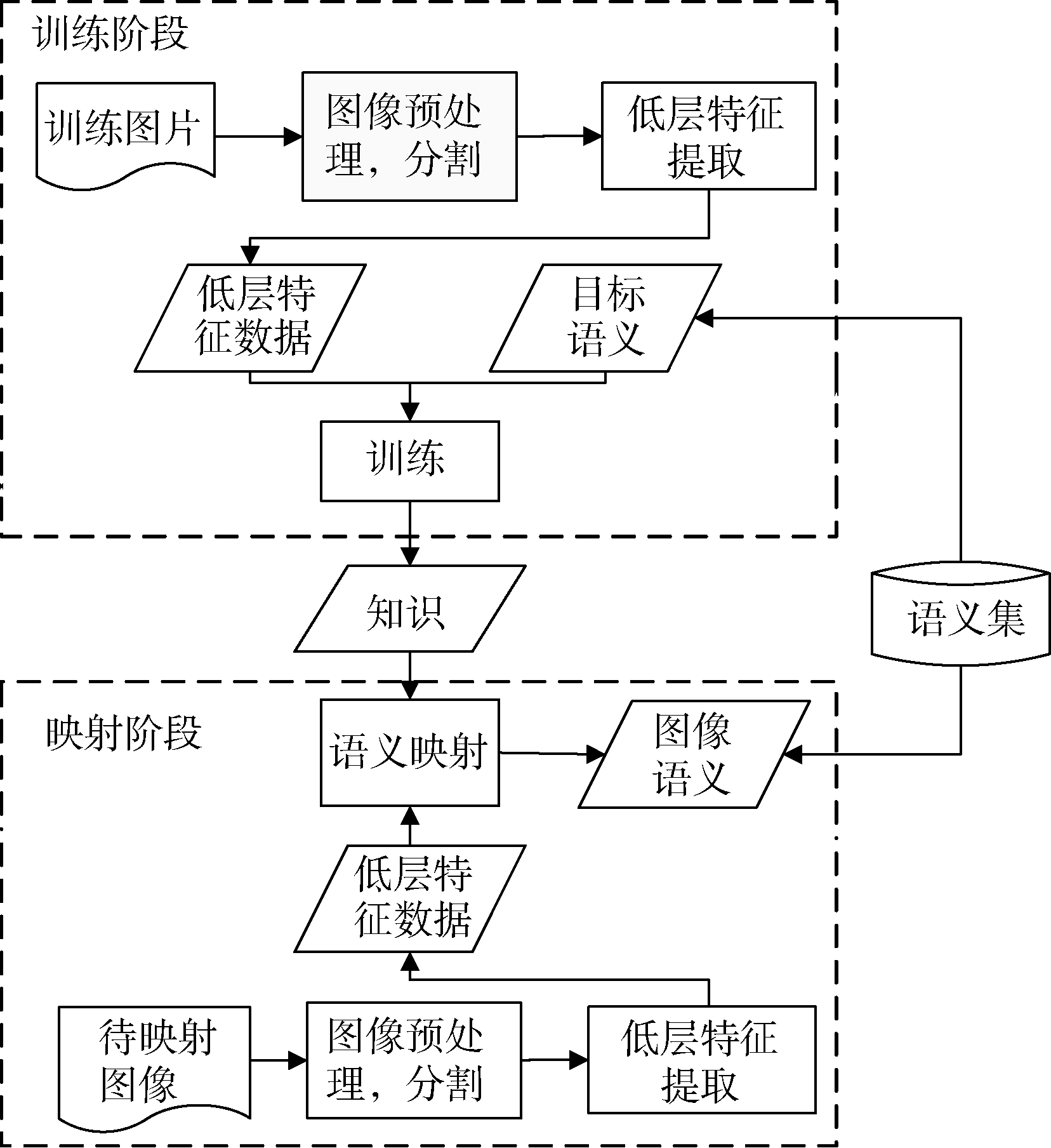 | 图4 图像语义映射框架 |
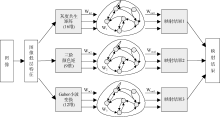
集成学习能有效地提高学习器的泛化能力[15, 16], 是目前机器学习领域重要的研究方向之一。本文借鉴集成学习思想, 针对不同特征提取算法得到的特征数据之间相对独立的特点, 提出多储备池回声状态网络分类模型。该模型将提取出的低层图像特征按类划分, 对不同类型的数据分别构造与其相对应的储备池, 在仿真时将各储备池的映射结果进行线性融合, 提高分类器与特征数据的适应性。其主要结构如图5所示:
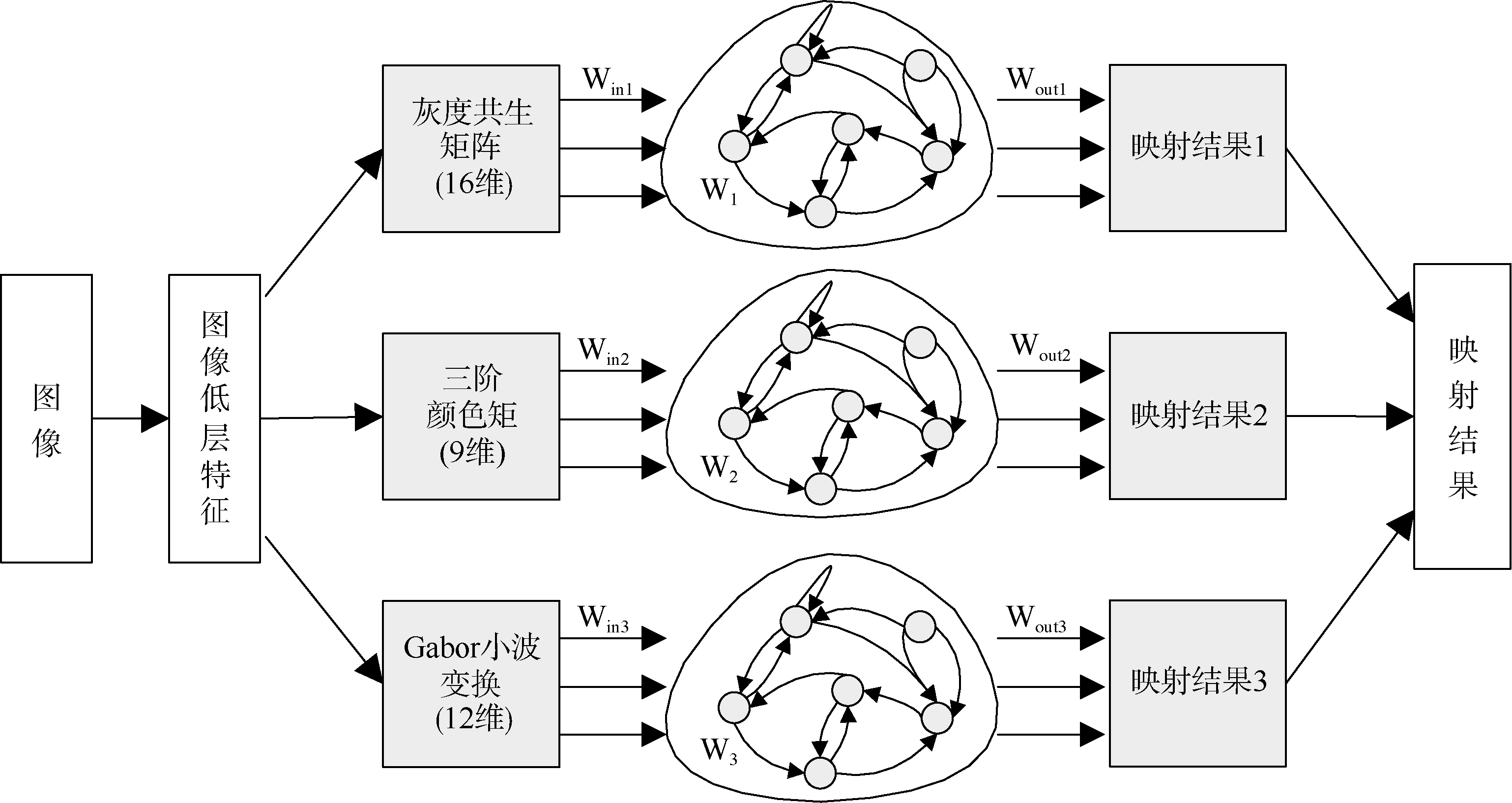 | 图5 多储备池回声状态网络语义映射模型 |
本文将37维图像低层特征按照提取特征的方法划分为三组, 包括根据图像灰度共生矩阵得到的16维特征, 计算颜色矩得到的9维特征以及通过Gabor小波变换得到的12维特征。
在回声状态网络语义训练过程中, 需要提供训练样本及对应的目标向量, 训练样本即通过计算得到的图像低层特征, 本文用T1、T2、T3表示三个储备池对应的训练样本, 以T1为例, 其组成结构如下:
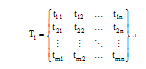
其中, n代表训练集中样本数量, m代表特征维度。
目标向量主要表示训练样本对应的语义类标号, 各储备池对应的目标向量相同, 本文用D表示目标向量, 定义如下:
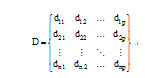
其中, n表示训练样本数量, p表示类别数量, 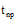
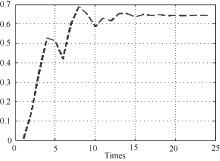
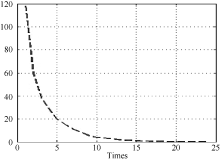
训练过程中的关键环节为调整储备池中的状态变量x(n), 由于每组特征数据与储备池中的每个处理单元均对应一个状态变量, 假设储备池中共有N个处理单元, 对所有状态变量进行统一处理, 定义状态变量变化量 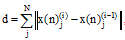
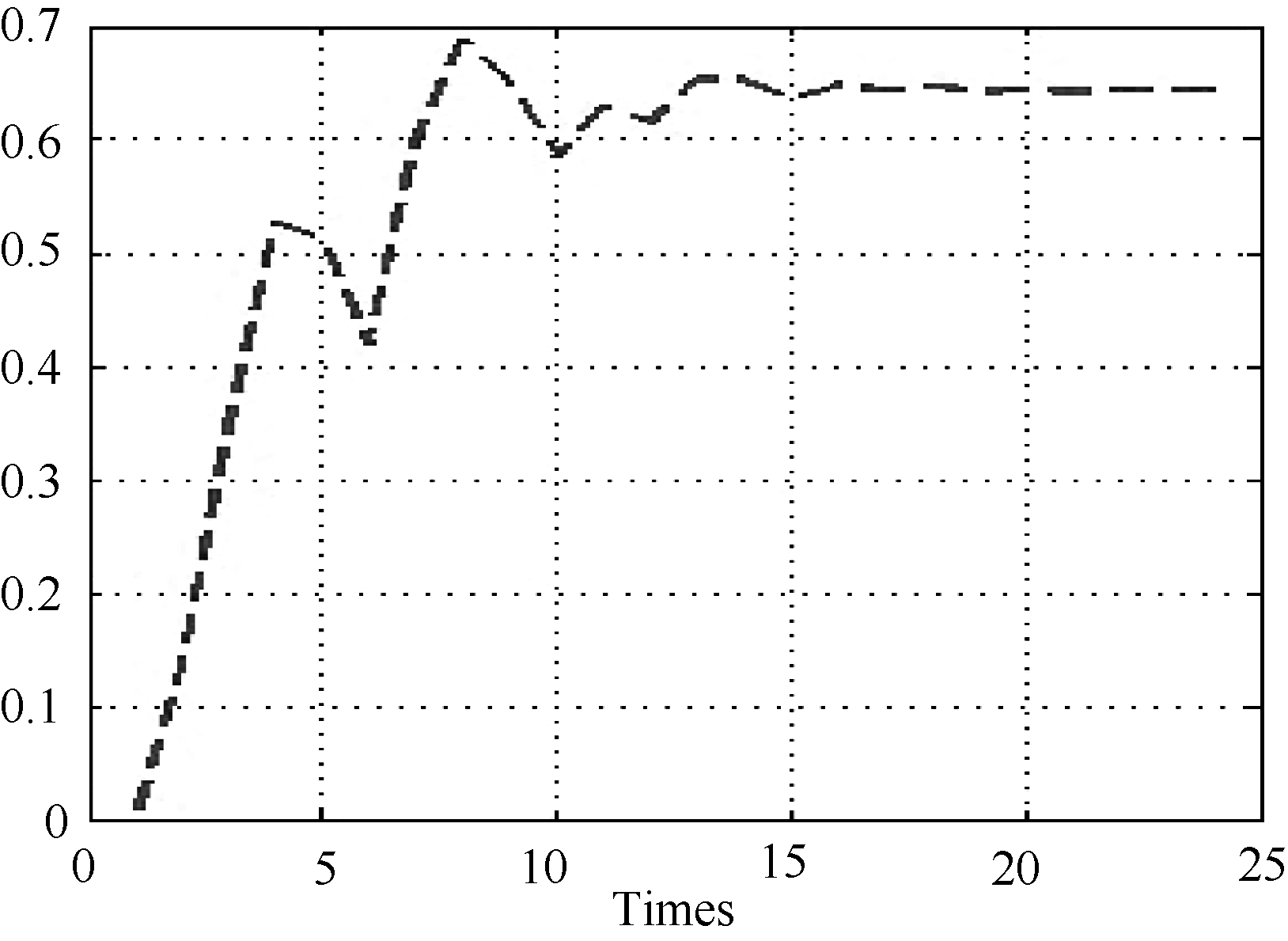 | 图6 状态变量曲线 |
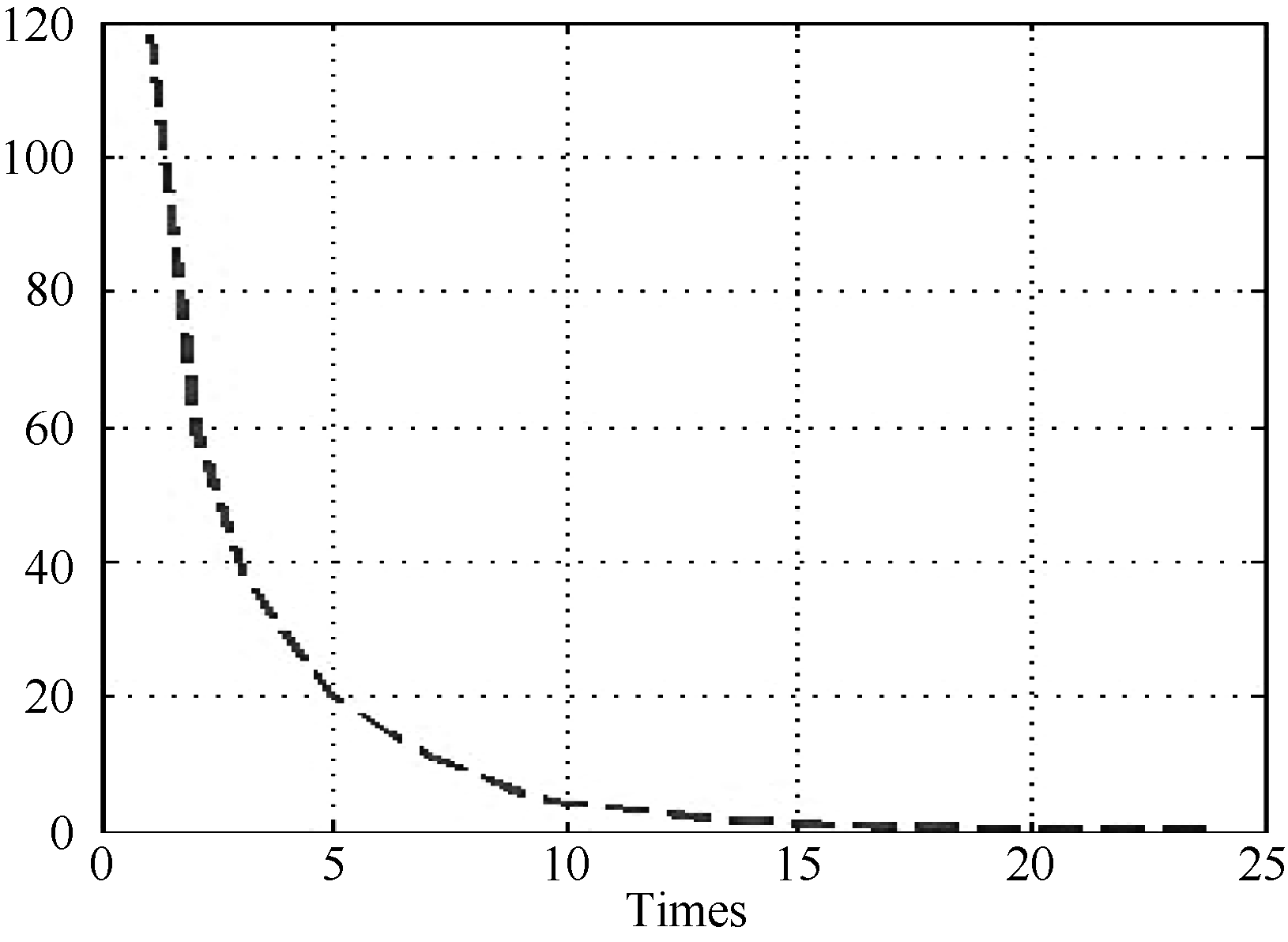 | 图7 状态变量变化量曲线 |
由图6和图7可知, 当通过一定次数的训练之后, 状态变量会逐渐趋于稳定, 因此可以设定阈值 
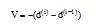 |
正常情况下, V为正值, 当V值趋于0时即说明状态变量趋于稳定, 当V< 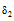
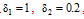
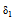
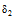
当状态变量训练完毕后, 将x(n)收集至X, 由于集成学习环境易产生过度拟合的情况。因此, 本文采用岭回归[17]的方式计算, 其公式如下:
 |
其中, k为岭回归参数, I为单位矩阵, 其维度与储备池中处理单元个数N相同。
当得到Wout后, 即可对待测试图像进行语义映射。对待测试图片按照第2节提出的方法进行特征提取, 为适应多储备池分类模型, 同样需要对提取到的特征按照数据提取方式进行划分, 并将划分后的特征数据分别输入至语义映射模型中, 按照训练过程中获取状态变量的方法计算状态变量, 并将状态变量收集至X, 其对应的语义特征向量如下:
 |
计算出各个储备池对应的语义特征向量后, 对其进行线性求和, 得到最终待测试图像对应的语义信息。
实验在Windows7 64位操作系统下进行, 测试软件为Matlab 2010b。硬件环境: CPU为Intel酷睿2 2.2GHz双核处理器, 内存为4GB。
实验选取Corel图片库[18]中的汽车(Bus)、恐龙(Dinosaur)、花(Flower)、马(Horse)、山川(Mountain)以及食物(Food)各100张图片, 共600张图片作为图片库, 每类随机抽出其中的50张作为训练集, 另外50张作为测试集。在实验中, 储备池处理单元数N均为40, 储备池内连接权值W均采用随机生成的方式。BP神经网络采用一层隐藏层, 隐藏层中包含90个神经元, 训练精度目标为10-10, 为确保实验数据的准确性, 全部采取交叉验证的方式进行。
为了验证本文的特征提取算法在语义映射中的效果, 首先对比了在回声状态网络模型下, 分别以灰度共生矩阵特征(Glcm), 颜色矩特征(Color_Moment), Gabor小波特征(Gabor)为特征数据时的分类准确度。不同数据特征在回声状态网络分类模型中的映射错误率如图8所示:
 | 图8 单特征映射效果对比 |
从图8看出, 不同类型的图像特征在不同种类图像的语义映射中表现各有优劣, Mountain类和Food类图片的映射错误率较高。本文将6类图片的映射错误率按三种特征分别计算平均值, 得到每一类特征的整体错误率All, 从整体映射错误率All来看, 通过Gabor小波变换得到的图像特征具有较优的映射效果, 但单一的图像特征得到的语义映射效果不够理想。
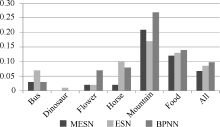
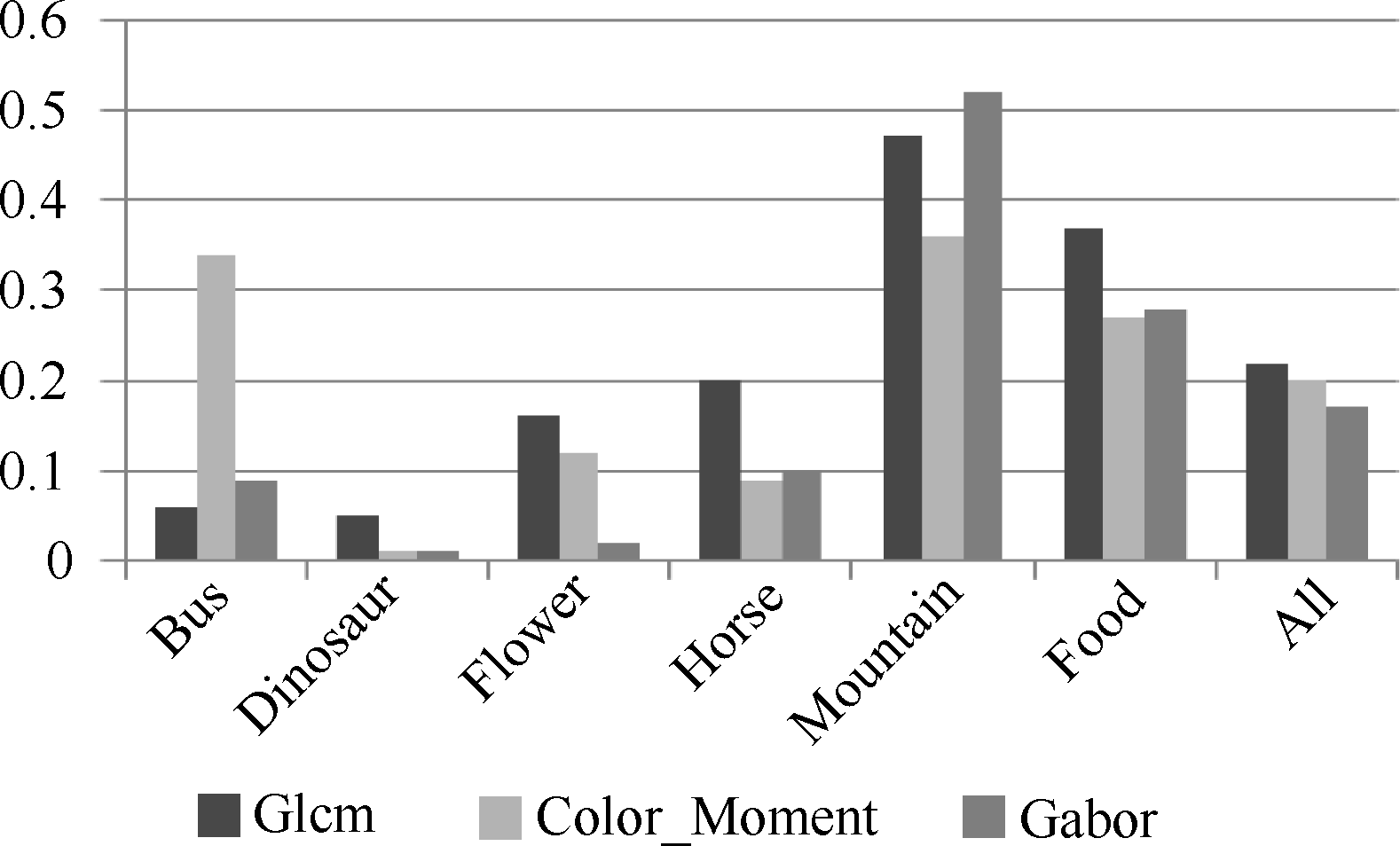
图9显示了特征融合后各分类器的映射错误率, MESN对应多储备池回声状态网络语义映射模型, ESN对应单储备池回声状态网络语义映射模型, BPNN对应BP神经网络语义映射模型。
 | 图9 不同分类器语义映射效果对比 |
从图9可以得出以下结论:
(1) 多储备池回声状态网络模型具有最低的语义映射错误率, 相对于传统回声状态网络及BP神经网络, 平均错误率分别相对下降了19.28%和31.64%。具体计算方法是:
|ErrorESN- ErrorMESN| / ErrorESN= 19.28%
|ErrorBPNN- ErrorMESN| / ErrorBPNN= 31.64%
(2) 对比图9中MESN、ESN以及图8中的数据可以看出, 多储备池回声状态网络具有较强的泛化能力, 能够有效提高语义映射精度。
(3) 特征融合后的分类效果明显优于单一特征的分类效果。
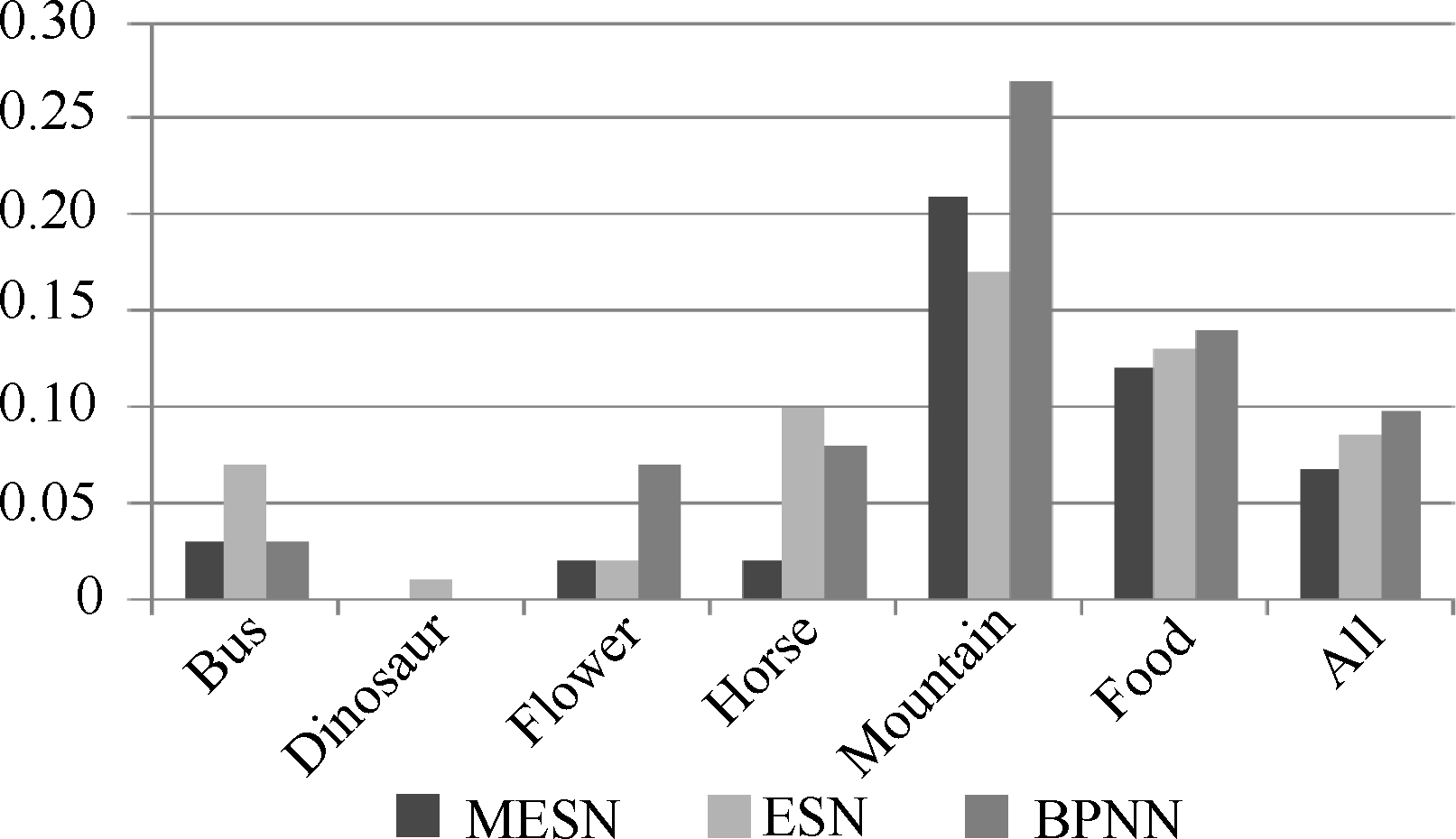
为了更直观地显示映射得到的语义信息与目标语义之间的相似程度, 在这里定义样本n与第q类目标语义的相似度程度 
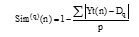 |
其中, 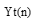
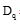
本文将n个样本相对于p类图像的语义相似程度矩阵定义为S, 结构如下:

对Sn, p矩阵每一列进行排序, 可以得到每一类中与目标语义相似度最高的图像, 通过查准率表示语义映射能力的大小, 定义如下:
 |
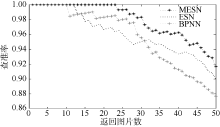
通过返回不同数量的图片计算各种情况下的查准率, 得到平均查准率曲线如图10所示:
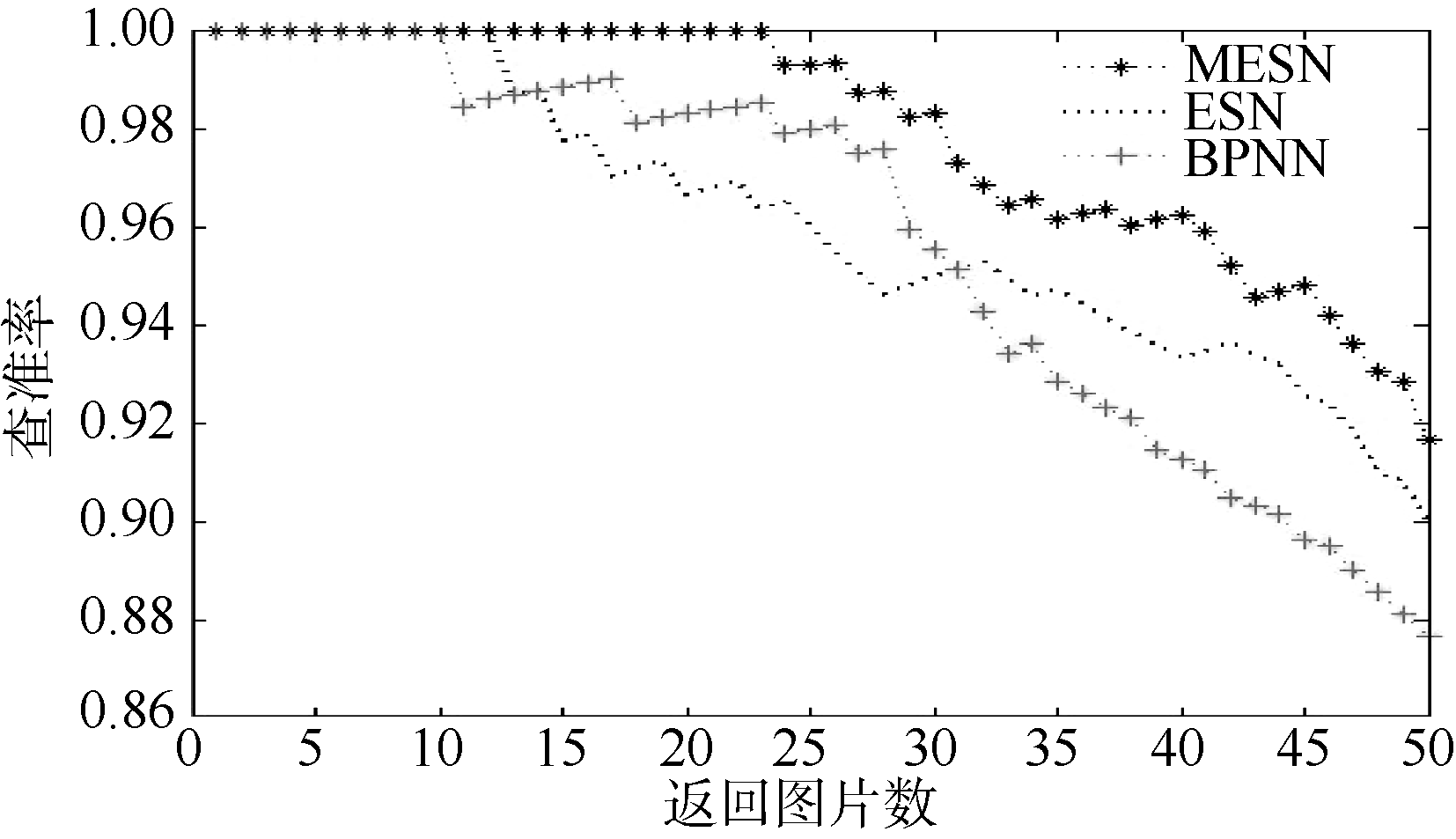 | 图10 平均查准率曲线图 |
通过图10可以看出, BP神经网络模型以及单储备池回声状态网络模型分别在返回11张、13张图片时出现错误样本, 而多储备池回声状态网络在返回24张图片时出现错误样本, 且在各返回图片数下均保持最高的准确率。因此, 通过多储备池回声状态网络模型得到的语义信息更具鲁棒性。当返回50张图片时, ESN及BPNN对应的查准率分别为90%和87.67%, 而本文提出的MESN模型对应的查准率为91.67%, 查准率分别相对提高1.86%及4.56%。具体计算方式为:
|MESN-BPNN|/BPNN=|91.67%-87.67%|/87.67%=4.56%
|MESN-ESN|/ESN =|91.67%-90%|/90%=1.86%
回声状态网络语义映射模型在具有较高映射精度的情况下同时具有较快的训练速度, 在实验中MESN的平均训练时间仅为1.53s, 而BP神经网络的平均训练时间为48.24s。
本文将多储备池回声状态网络分类模型应用于图像语义映射中, 实验提取图像灰度共生矩阵的能量、对比度、相关值、熵4个标量, RGB颜色空间的颜色矩以及Gabor小波变换后图像的均值及方差作为图像特征, 分类器采用多储备池回声状态网络分类模型, 并对储备池中状态变量的调整方式进行优化。实验结果表明本文提出的语义映射方法是可行的、有效的。下一步工作将在大型图像数据库中进行实验, 并提取更具区分力的图像低层特征, 扩展特征向量。与此同时进一步优化回声状态网络储备池的结构, 使其对特征数据更具针对性及适应性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|