
{kind=link}
{kind=link}
搜索日志中命名实体识别*
[任育伟1  , 吕学强
, 吕学强1 , 李卓2 , 徐丽萍2 ]
, 吕学强|
|


作者简介:吕学强: 提出研究命题; 任育伟: 提出研究思路, 设计研究方案, 完成实验, 分析数据, 起草论文; 李卓: 修改论文;徐丽萍: 论文最终版本修订。
[Objective] Recognizing the named entity in the search logs provides great value and significance for enhancing the quality of search service. [Methods] Extract candidate named entity by using seed named entity and template matching principle. After clustering the candidate named entity, extracte the recognition feature of candidate named entity, including the frequency, the number of different templates and template weight. Fuse these features to construct calculation formula of named entity recognition weight and adjust feature influencing parameters reasonably. [Results] By marking and counting the extracted named entity, the average value of P@500 reaches 75% and is higher than Paşca method by 7%. [Limitations] The named entity which has weak sensitivity for the template can not be extracted correctly. [Conclusions] Calculate the P@N index value of the extracted results, which shows the effectiveness of this method.
据CNNIC的统计报告[1]显示, 截至2014年6月底, 我国搜索引擎网民规模达到6.32亿, 较2013年底增长1 442万人, 互联网普及率为46.9%。搜索引擎作为互联网的基础应用, 是网民获取信息的重要工具, 用户规模达5.07亿, 使用率达到80.3%, 使用率在所有应用中稳居第二。
随着使用搜索引擎用户的大规模增加, 大量的搜索日志也相应产生, 如何从这些搜索日志中识别出命名实体对于准确定位搜索意图, 优化搜索引擎服务质量有着重要的意义。基于传统文本的命名实体识别研究已经取得了较大的进展, 相关技术已较为成熟, 而基于搜索日志的命名实体识别研究近年来刚刚展开, 由于搜索日志与传统文本有着巨大的差异, 如查询文本简短, 没有完整的语法结构和充足的上下文信息, 传统文本的实体识别方法不适用于搜索日志中的命名实体识别。近些年, 基于搜索日志的命名实体识别研究主要采用模板方法抽取, 利用分类模型进行候选命名实体的精确类别确定。利用统计模型(如CRF)进行命名实体识别的方法不属于主流抽取方法, 它不但需要大量的精确标注语料进行模型训练, 还需要有信息量大的上下文信息, 而搜索日志即使进行Session聚类后提供的上下文信息仍然很有限。因此, 简单有效的基于模板进行命名实体抽取的方法成为研究的主流。
本文在前人研究的基础上, 对命名实体抽取模板进行权重计算, 并丰富和优化命名实体的识别特征, 结合这些特征构造命名实体识别权重公式, 对候选命名实体按权重进行排序, 统计并分析抽取的最终结果。
基于传统文本的命名实体识别研究已有多年, 技术和方法已经较为成熟, 从早期的规则编写到大量监督或半监督统计方法的应用, 召回率和正确率得到较大的提高。基于传统文本的命名实体识别研究, 最初是基于规则的抽取, 后来基于统计模型的抽取。虽然面向短文本的命名实体抽取研究已经展开, 如王丹等[2]提出用HMM以词性做观察值进行初步命名实体识别, 并构建拼音同指关系库识别潜在实体。但是搜索日志的短文本和传统短文本在结构和语法方面还有很大的差别。
基于搜索日志的命名实体识别研究近年来已提出了一些较有效的方法, 曹雷等[3]提出了一种基于二部图的半监督排序方法, 该方法利用实体之间的共享模板, 将种子命名实体的类别所属信息通过共享模板传递给抽取出的命名实体, 从而改善命名实体识别的精确度。伍大勇等[4]在二部图构建实体和模板关联的基础上, 增加了URL信息, 从而建立URL、候选实体和抽取模板之间的三分图。并根据在该图上的随机游走计算候选命名实体属于指定实体类别的概率, 从而获取该类别的命名实体。翟海军等[5]利用Wikipedia数据, 结合转移学习方法构建目标类别的分类器, 提高了查询日志中命名实体抽取的准确性, 该方法借助于Wikipedia扩展了日志的相关文本信息, 从而能运用成熟的统计学习方法构建分类器实现命名实体的识别, 但识别效果较大程度上依赖于扩展文本的质量, 有其一定的局限性。翟海军等[6]通过将种子命名实体、抽取模板和候选命名实体信息模拟对应的文本主题信息, 并引入弱指导话题模型, 很好地解决了实体的类别模糊性, 与曹雷等[3]和伍大勇等[4]基于二部图、三分图解决类别模糊性的方法有很大的不同。曹雷等[7]利用实体和模板的信息引入SS-PLSA(半监督潜在语义分析模型)学习实体类别的模板分布, 从而解决类别模糊性问题。张磊等[8]通过种子命名实体和模板的关联关系, 优化模板并构造特征选择算法从而抽取命名实体, 但特征信息有很大的不足。Du等[9]将搜索日志进行用户Session划分, 利用搜索日志的上下文信息引入CRF模型实现统计方法抽取命名实体, 但需要标注语料进行训练。Jonnalagadda等[10]基于分布式语义自动生成的特征, 包括n近邻词、SVM区域和词聚类。它们的使用和依据人工标注的词典方法相比提高了命名实体的召回率。Gross等[11]提出了一种基于概念关联图的命名实体过滤方法, 通过将文档模型概念和目标命名实体相关联, 从而消除了命名实体的歧义性, 和基于支持向量机的方法相比, 提高了过滤的结果。Dalvi等[12]提出4个步骤进行命名实体抽取, 分词得到候选实体串, 在FreeBase里检索候选实体串, 使用基于查询概率值的语言模型进行候选命名实体排序, 得到命名实体。Wen等[13]对搜索日志进行Session划分, 使用Session上下文信息进行中文人名的识别。
在上述研究中, 一些通过扩展日志文本信息, 采用传统较为成熟的基于文本命名实体识别的方法, 一些利用候选实体和实体模板之间的关系构建二分图, 或者增加更多特征信息构建三分图实现命名实体的精确抽取, 或者利用它们之间的关系引入话题模型解决类别模糊性问题, 从而精化抽取结果。另外, 还有通过Session划分利用统计模型实现命名实体的识别。统计方法由于需要大量质量较高的标注语料, 使得可用性很大程度上有所降低。基于种子抽取命名实体虽然简单有效, 但是命名实体的左右边界确定, 类别模糊性问题都需要加以解决, 前人利用种子命名实体的模板分布, 模板信息引入二分图或三分图, 或者话题模型集中解决了抽取的实体类别模糊性问题, 但对于候选实体的片段划分正确性、左右边界的确定以及作为主要抽取信息的实体模板优化没有较好解决。本文在前人研究的基础上, 对抽取实体的模板进行权重计算并优化, 同时对候选命名实体进行聚类, 提取更多的命名实体识别特征, 根据特征选取实体片段划分较为正确同时特征权重高的候选实体作为抽取出的命名实体。
命名实体抽取需要确定抽取的类别, 对语料特点分析显得尤为重要。本文采用搜狗开放的2008年6月的搜索日志作为研究语料, 语料格式如表1所示:
| 表1 搜狗日志的记录信息项 |
使用该语料进行聚类后的统计分析, 发现资源类、教育就业类占较大比重, 资源类主要包括电视剧、电影、小说、游戏、图片等查询词的查询, 在聚类后的前25类的所有查询中, 占43.24%, 教育就业类主要包括大学、招生、高考、录取、学院等查询词的查询, 占25.92%。因此, 结合前人研究所用的实体类别框架和笔者所选择的语料特点构建实体类别框架, 包括电视剧、游戏、电影、人名、学校、歌曲名6类命名实体。
命名实体抽取过程包括种子命名实体搜集, 命名实体模板集抽取和过滤, 候选命名实体集特征抽取, 使用特征过滤候选命名实体得到最终的命名实体结果集等步骤, 如图1所示:
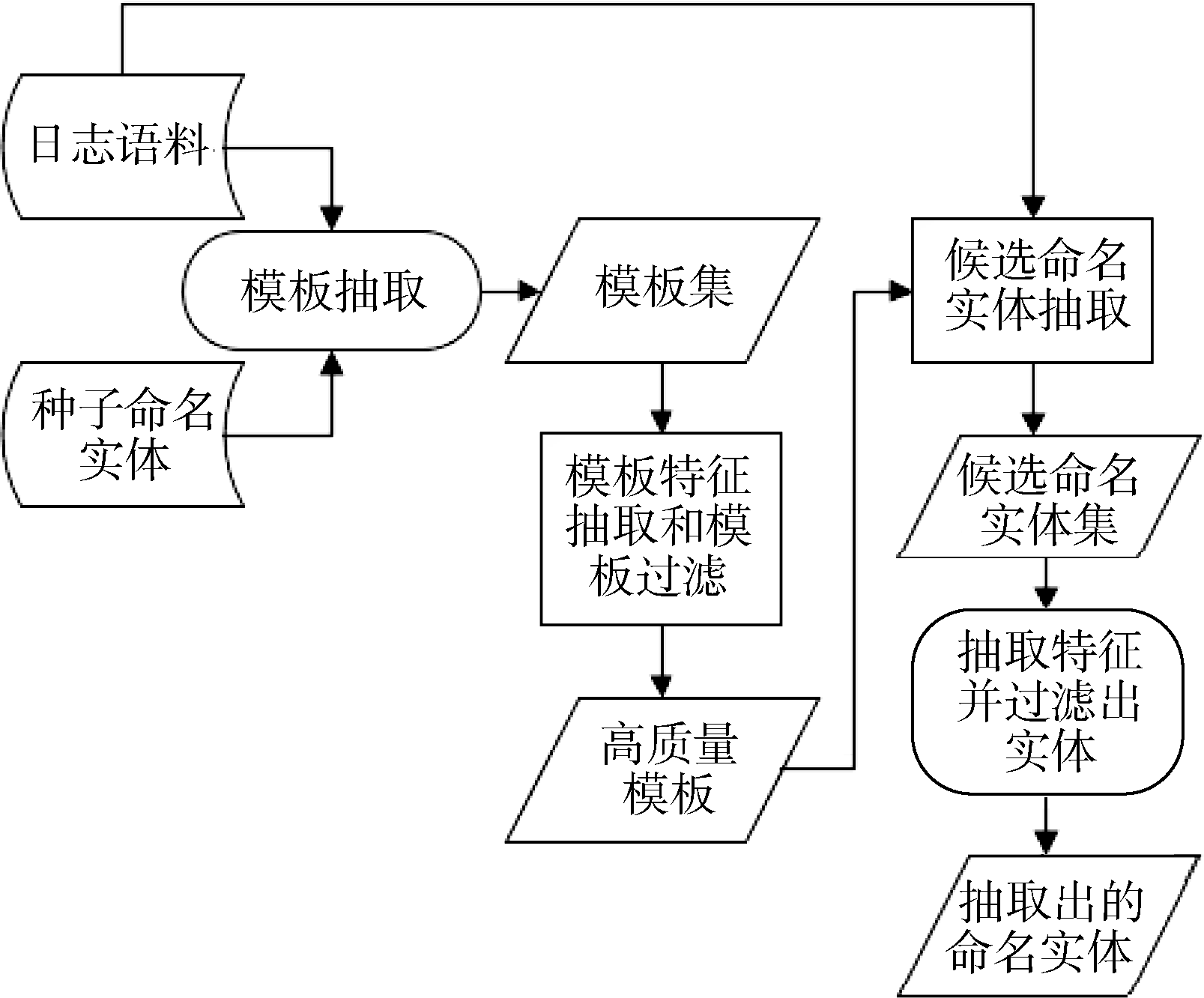 | 图1 命名实体抽取过程 |
(1) 种子命名实体搜集
候选命名实体的抽取主要通过构建种子命名实体, 通过种子命名实体在搜索查询串中抽取命名实体识别模板, 通过模板在搜索日志中抽取候选命名实体。种子命名实体的人工选择需要考虑其覆盖搜索日志查询串的覆盖率。
本文实验中6大类种子命名实体都由手工构建, 考虑命名实体在搜索日志中的覆盖率, 专门构建了和搜索日志同年份的大量种子命名实体。通过百度搜索日志生成时间属于热门搜索的命名实体作为种子命名实体, 选取7大类的种子命名实体各150个。
(2) 命名实体模板抽取和模板过滤
通过种子命名实体在搜索日志中抽取命名实体抽取模板, 如“ 下载天下无贼观看” 查询串, 如果电影种子命名实体中有“ 天下无贼” 命名实体, 通过将查询串中的命名实体替换为“ #” , 就可以抽取出“ 下载#” 和“ #观看” 两个左右模板。通过将搜索日志语料中的所有查询串的种子命名实体替换为“ #” , 从而抽取出各类别的命名实体识别模板。该模板用于实现搜索日志中的候选命名实体抽取。
由于有的模板并不具有较强的实体抽取能力, 需要对模板的重要性进行评估, 得到过滤后的较高权重的模板集。通过抽取与模板共现的候选命名实体数、模板和种子模板的平均相似度值、模板的频次、模板的倒排文档频次这些特征, 并寻找各特征和模板质量的关系构建合适的模板权重评估公式。本文模拟tf-idf公式的特点, 构建类似于tf-idf的权重计算公式。其中, 模板频次、与模板共现的候选命名实体数、和种子模板的平均相似度值三个特征和模板质量呈正相关, 相当于tf-idf公式中的tf值。而模板的倒排文档频次和模板质量呈负相关, 相当于tf-idf公式中的倒排文档数, 该特征表征模板的类别属性。使用该模板权重评估公式对原模板集进行过滤得到高质量的模板集。
(3) 特征和命名实体抽取
通过抽取出的高质量的模板集进行候选命名实体抽取, 用类K-means进行候选命名实体的聚类, 类K-means方法借鉴K-means方法的优点, 即动态更新聚类核心串。同时该聚类方法避免预设类别数导致的聚类粒度过大或过小的问题。将候选命名实体聚类后, 抽取候选命名实体频次、和候选命名实体共现的不同模板数、以及平均模板权重(该值通过对模板权重值求平均得到)这三维特征。该三维特征和命名实体权重呈正相关, 但各特征的权重值并不相同, 因此采用三个参数具体化各维特征的权重影响。用这三维特征构建命名实体抽取公式, 并调整三个参数的具体组合值, 通过计算各组值抽取的命名实体准确率得到最好的参数组合结果。
使用该方法抽取出的结果集和Paş ca[14]的方法实现的结果集进行比较, 证明了该方法的有效性。
将抽取出的模板进行权重计算得到较高权重的命名实体抽取模板。通过抽取出的命名实体识别模板进行候选命名实体的抽取, 将查询串中的模板部分去除, 剩下的就是候选命名实体。统计候选命名实体的特征得到候选命名实体的特征向量, 进行命名实体选取特征权重计算得到排名较高的命名实体, 即识别出的命名实体。
在候选命名实体中抽取特征, 如候选命名实体频次特征。另外, 通过观察候选命名实体和模板的共现关系, 以及模板对命名实体识别的支持信息, 提取深层的模板特征作为候选命名实体的另一特征。模板抽取的候选命名实体片段划分并不都正确, 如“ 天龙八部下载” 、“ 天龙八部下载观看” 、“ 天龙八部观看免费” 这三个查询串, 通过模板“ #下载” 、“ #观看” 、“ #免费” 分别抽取出“ 天龙八部” 、“ 天龙八部下载” 、“ 天龙八部观看” 三个候选命名实体, 但只有第一个是正确的命名实体, 把它们聚类后会得到以“ 天龙八部” 为核心串的一类, 同时进行该类的特征统计, 抽取出正确的命名实体“ 天龙八部” 。因此, 将候选命名实体简单聚类后抽取聚类的集合总特征, 增强候选命名实体特征识别度的同时使得命名实体界限能正确确定。
(1) 命名实体识别模板权重计算
命名实体识别模板对于确定命名实体有很大的参考价值, 在初提取的模板中, 一些模板和候选命名实体共现度不强, 对实体抽取不具有较强的支持度, 需要对模板进行过滤。通过对模板进行权重计算, 从而依据权重值筛选出质量较高的模板。提取命名实体识别模板的各项特征, 构造模板权重衡量公式, 计算出模板权重, 作为候选命名实体识别的一维特征, 用于命名实体识别。模板特征包括模板频次、和模板共现的不同命名实体数、模板所属的不同类别数、模板和种子模板的平均相似度值构成模板特征向量
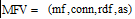
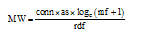 |
其中, conn是和模板共现的候选命名实体数; as是和种子模板的平均相似度值, 该值是通过编辑距离(算法1)计算和每个种子模板的相似度值(见公式(2))后, 求和取平均值得到; mf是模板的频次; rdf是模板的倒排文档频次。模板权重和conn、as、mf成正相关, rdf反映该类模板和其他类别模板的区分度, 因此应作为分母。公式(1)是通过模板特征向量和tf-idf公式原理得到的, 并经过实验验证该公式是有效的。
根据权重大小将模板排序, 抽取出前150个模板特征, 使用该模板抽取候选命名实体, 并把模板权重值作为命名实体识别的一维特征。
(2) 候选命名实体聚类及特征提取
由于模板片段划分的模糊性使得提取出的候选命名实体的界限确定不正确。通过观察, 抽取出的候选命名实体包含命名实体较多, 但是该候选命名实体不是正确的命名实体, 因此将候选命名实体聚类, 不但增强了候选命名实体的特征信息支持, 也能正确确定命名实体的左右边界。如“ 天龙八部下载” 是抽取出的候选命名实体, 但它的边界划分有误导致它不是命名实体, 而只是包含命名实体“ 天龙八部” , 如果聚类后, 产生以“ 天龙八部” 为核心串的聚类, 那么就能纠正边界划分的错误, 同时使得该命名实体受到更多的特征支持。聚类方法采用类K-means聚类方法, 将每个候选命名实体作为核心聚类串, 对其他的候选命名实体和它采用编辑距离法进行相似度计算, 将相似度达到一定阈值的候选命名实体聚集到该候选命名实体串中, 同时更新类中心核心查询串, 即利用K-means动态更新类中心查询串的优点, 更新步骤如下。聚类后, 统计每个核心串即候选命名实体的频次特征、不同模板数、平均模板权重构成特征向量ACCNFV = (ef, comn, amw), 并最终将它们的值归一化为[0, 1], 用于最后的命名实体识别权重计算。用于聚类的相似度计算采用编辑距离方法, 具体算法如下:
算法1: 整数 Levenshtein距离[15](字符串str1, 长度为n, 字符串str2, 长度为m)
①str1或str2的长度为0, 返回另一个字符串的长度。If(n==0) return m; if (m == 0) return n。
②初始化(n+1)× (m+1)的矩阵d, 并让第一行和第一列的值从0开始增长, 增长幅度为1。
③扫描两个字符串(n× m级), 如果str1[i]==str2[j], temp记录值为0.否则temp记录值为1。将d[i-1][j]+1, d[i][j-1] +1, d[i-1][j-1]+temp三者的最小值赋于d[i][j]。
④扫描完成后, 返回矩阵的最后一个值d[n][m]即是它们的编辑距离。
相似度计算公式如下:
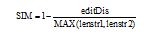 |
其中, editDis是通过算法1计算出的两个字符串编辑距离, 分母MAX(lenstr1, lenstr2)是最长字符串的长度值。SIM是通过编辑距离和字符串长度信息得到的相似度值。
类别 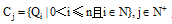
1将类中的每个无平均相似度值的查询串Qi和其他查询串 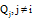
②将步骤①计算出的相似度值求和并除以n-1, 得到该查询串Qi和其他查询串的平均相似度值。
③重复步骤①-②直到类Cj中的所有查询串都有各自的平均相似度值。
④找到平均相似度值最大的那个查询串就是该类的类中心查询串。
命名实体识别需要对候选命名实体进行权重计算, 从而提取出精确度高的命名实体。提取出的命名实体识别特征向量 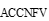
(1) 命名实体权重计算与抽取
相关性实验验证是通过对候选命名实体在每维特征上的排名, 并观察候选命名实体的排名靠前的部分为正确命名实体的概况, 从而确定该维特征与命名实体识别的相关关系以及支持度, 同时也为权重公式的参数调节提供参考。通过初步验证每维特征与命名实体识别的关系, 结果为每维特征都与命名实体识别成正相关, 且支持度有所不同。特征权重公式构造如下:
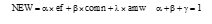 |
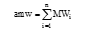 |
其中, ef, comn, amw分别是向量 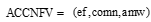
按照计算出的权重值将候选命名实体降序排序, 靠前的候选命名实体即是抽取出的候选命名实体。通过观察发现抽取出的命名实体存在常用词的情况, 即其权重较高, 但是并不是确切意义上的命名实体, 这些词的存在影响了抽取结果的正确率, 本文利用HowNet常用词库进行过滤, 以提高最终抽取结果的准确率。
根据候选命名实体权重值对候选命名实体降序排序, 并通过观察靠前的识别结果和多次实验最终确定命名实体抽取的权重阈值。标注抽取出的结果, 并用P@N指标衡量抽取的精度。同时, 通过比较不同特征抽取的结果P@N值表明使用特征的有效性, 通过不同参数组合的设定确定最终合适的参数组合。并与Paş ca[14]的方法比较, 表明了该方法在命名实体识别方面有一定的有效性。
通过设定权重参数的不同组合并统计抽取出的结果进行对比, 选择合适的参数组合。
当α 为0.2, 
| 表2 参数组合结果统计 |
当α 为0.4, 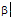
| 表3 参数组合结果统计 |
从上述P@N的对比结果中, 得出当γ 权重值减小, α 和 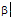
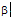
通过对识别出的结果进行P@N统计, 发现在电视剧、电影、人名和学校名的识别在前500中达到70%以上, 人名的识别在前500中达到85%以上, 有着较高的识别率。游戏和歌曲虽然不如其他类别的命名实体识别率高, 但也达到60%以上。充分说明了该识别方法的有效性。
为了进一步说明本文方法的有效性, 在同样的数据集上, 实现了Paş ca[14]的方法, 结果如表4所示。
| 表4 Paş ca方法结果统计 |
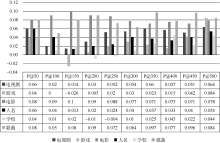
为了直观地对比本文方法和Paş ca方法, 将表3和表4的对应项数据做减法并将得到的结果以图的方式呈现出来, 如图2所示:
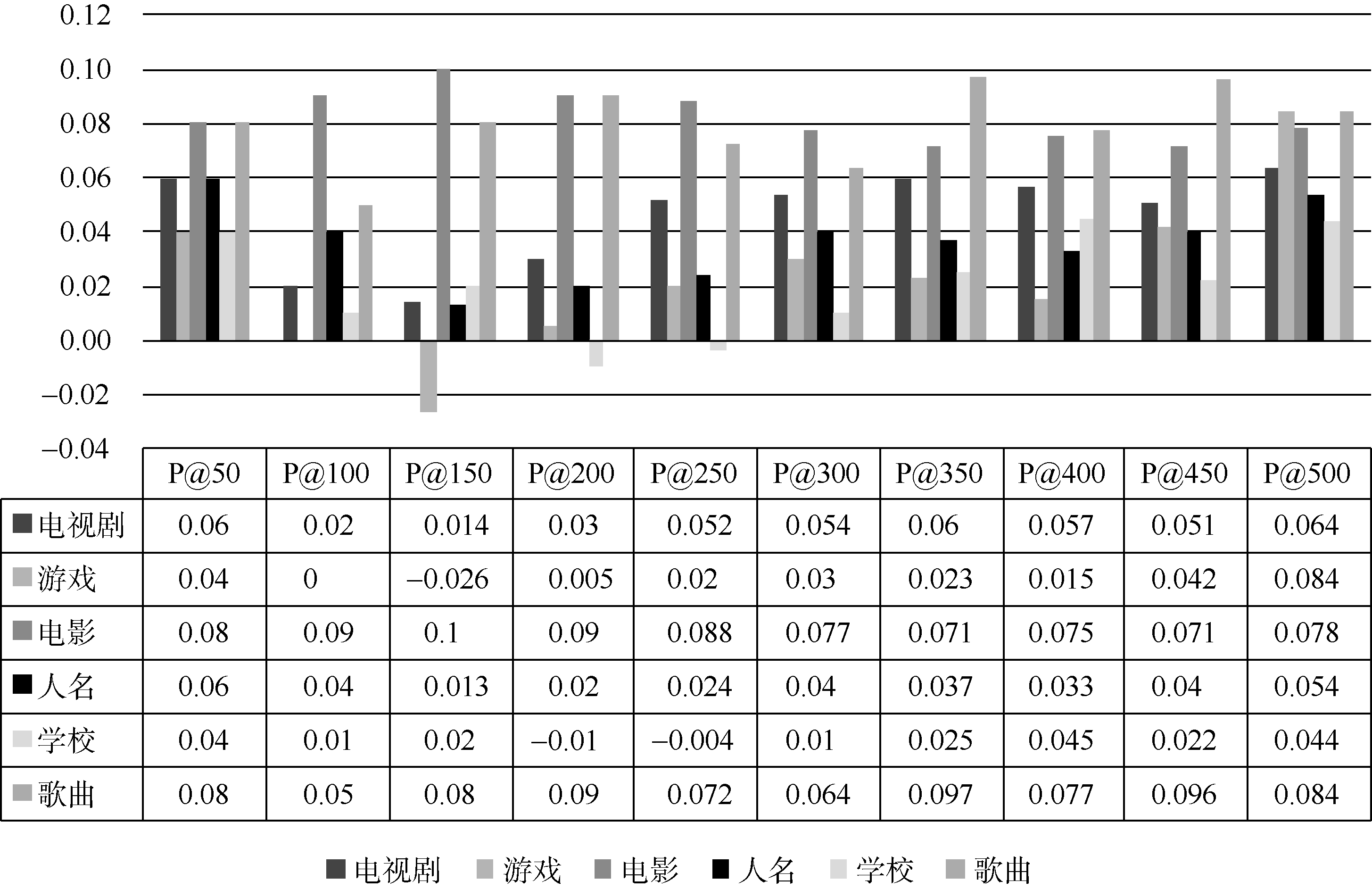 | 图2 对比结果图 |
如图2, 结果只有游戏P@150、学校P@200和P@250三项数据小于0, 其他都大于0, 表明本文方法几乎在各项类别命名实体的P@N值均大于Paş ca方法, 表明了该方法优于Paş ca方法。
本文利用种子命名实体抽取出候选命名实体模板, 并将模板进行权重计算得到种子模板, 进而通过种子模板抽取出候选命名实体。在候选命名实体中提取识别命名实体的支持特征, 如候选命名实体频次、和候选命名实体共现的不同模板数、模板平均权重值。其中, 一些特征是在候选命名实体完成聚类后进行提取的, 聚类方法对于正确分离日志记录中的命名实体有很大的作用, 同时累积了各项特征的支持度, 对于更精确地识别命名实体有很大的帮助。将这些特征融合到命名实体识别公式中, 计算出最终的命名实体识别权重值, 排序并抽取出识别出的命名实体。通过对识别结果进行P@N的标注, 并优化最终参数的调节, 同时与Paş ca方法比较, 表明了本文方法抽取结果的有效性。由于命名实体特征的有限性, 使得某些抽取的结果并不确切, 特征的丰富可以进一步提高抽取的正确率, 这需要接下来进行更加深入的研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|