




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
同义词抽取结果的噪音清洗方法研究*
[刘伟 , 王星, 宋培彦]
, 王星, 宋培彦]
, 王星, 宋培彦]
|
|


作者简介:刘伟: 提出研究思路, 完成算法设计, 撰写论文; 王星: 设计与实施实验; 宋培彦: 论文最终版本修订。
[Objective] There are lots of noises in synonym extraction results, and the noises would hurt the availability of extraction results. [Methods] This paper proposes a noise cleaning solution based on synonym graph. The proposed method firstly transforms synonym extraction results into an undirected synonym graph, and then detects the noises in the graph. The method is improved by incorporating the distribution similarity. [Results] The terms randomly selected from the technique field are used in the experiments, and the experiments show that this method can remove noises from the synonym extraction results to some extend. [Limitations] Only part of noises is cleaned, hence the accuracy of detecting noises needs be increased by improving the methods. [Conclusions] This is a feasible approach to clean the noises in the synonym extraction results, which is worth further study.
同义词群是自然语言处理等研究和应用领域的重要基础资源, 在信息检索、机器翻译等应用系统中都发挥着重要的作用。由各学科专家手工构建同义词群则存在成本高、周期长、难以维护等缺陷。因此, 主要的相关研究集中在利用计算机从大规模自然语言语料库中自动抽取同义词的方法, 这些方法总体来说可以分为两大类: 基于分布相似的方法和基于句法模式的方法。
在进行准确性评估时, 同义词抽取结果中与被检索词汇是同义关系的词汇是正确的同义词, 否则被称为噪音。在语言学中, 同义关系是一个主观的判断, 难以量化表示, 与近义关系没有明确的界限。但在目前同义词抽取的研究中, 一般不区分同义和近义关系, 只把抽取结果划分为同义词和噪音两部分。由于自然语言表达自由灵活, 抽取结果无法达到100%的准确, 这在所有该方面文献的实验结果中都得到了验证。比如, 在2012年自然语言处理与中文计算会议举办的中文词汇同义关系抽取评测[1]中, 国内8个高校和研究机构提交了10份评测结果, 可以看出目前的抽取结果整体准确率较低。然而, 很多与同义词群相关的实际应用系统对噪音是非常敏感的, 比如构建同义词典、扩检等。如果在使用之前, 没有将噪音识别出来并清除, 会严重影响最终结果的可用性, 但还未有相关噪音清洗的方法。因此, 笔者针对这一问题, 研究噪音自动清洗方法。本文方法不依赖任何领域知识, 因为领域知识虽然可以提高清洗的准确性, 但使用代价比较高, 通常需要人工的参与, 不适合大规模使用, 而且还受到领域的限制。本文方法基于当前抽取结果, 对结果中的每一个词汇进一步抽取同义词, 根据抽取关系建立起同义词抽取网络, 通过分析计算网络中节点之间的连通情况, 识别出抽取结果中的噪音。
基于大规模语料库抽取同义词资源, 是近年来同义词计算新的研究方向, 国内外已经开展了大量的研究工作。从实现方法角度主要可以分为两大类: 基于分布相似的方法[2, 3]和基于句法模式的方法[4, 5, 6, 7]。基于分布相似的方法也可以叫做基于特征词集的方法, 其基本思想是用特征向量表示词语的上下文语境, 通过计算特征向量之间的距离表示词语之间语义的相似性。Pantel等[2]将同义术语发现看作社区聚类问题, 根据词之间的相似性构建社区, 认为在同一社区的术语为同义术语。Cheng等[3]提出一个自动的实体同义词生成框架, 通过对用户访问日志的挖掘实现用户查询扩展。Berry等[4]建立词典语义图模型, 通过在这个图模型上计算词汇之间定义的语义相似度, 从词典中实现同义词的识别。Bø hn等[5]根据维基百科网站中页面之间的链入链出关系, 计算词汇之间的语义关系和相似程度, 识别出同义但表达形式不同的词汇。基于句法模式的方法, 其基本思想是利用同一语句中同义术语之间存在的特定的句法模式将同义术语对抽取出来。陆勇等[6]将同义术语出现的模式归纳总结为正面模式和负面模式, 按照模式的可信度和覆盖度评估同义术语的抽取结果。于娟等[7]采用句法结构分析方法对词和短语中的原子词进行等价分析, 克服了因重心后移带来的同义词识别偏差问题。
上述两类方式探索了较为有效的同义词词群构建方法, 在小规模、封闭测试环境下取得了一定的效果。从实验结果来看, 基于分布相似的方法一般具有较高的召回率, 但准确率较低, 而基于句法模式的方法则正好相反。基于分布相似的方法依赖于词汇的上下文或者特征词向量, 一词多义、特征词向量的表达以及相似性计算等都会造成准确率的下降, 而基于句法模式的方法则利用较为严格的句法模式或规则从符合的语句中识别同义术语, 具有较高的准确率和较低的召回率。因此基于分布相似的方法和基于句法模式的方法具有一定的互补性, 可以将两种方式集成起来以期取得更好的效果[8, 9, 10]。Hagiwara等[8]为了避免分布相似性计算中阈值设置存在的弊端, 结合句法模式分析将同义词识别转换为传统的分类问题。Kaji等[9]把句法分析中词汇的共现作为特殊的约束特征, 利用隐马尔科夫随机域模型结合到分布相似性中。陆勇等[10]使用字面相似度方法、特征模式匹配方法、PageRank链接分析方法分别从字面、句法和语义角度实现同义词的抽取, 然后将抽取结果加权合并。
此外, 还有其他的同义词抽取方法, 但同义词的来源不是普通的语料, 而是叙词表或在线词典。叙词表以规范化的、受控的叙词(主题词)为基本成分, 其中大多数的用代项可以作为同义词的来源, 但有的用代项之间是属分、相关甚至是反义关系等。从互联网中可公开访问的在线词典中抽取同义词也是一种有效的方法, 刘伟等[11]对该方法的实现技术作了详细的介绍。
受效率低的限制, 通过人工(借助领域知识工具)清洗抽取结果中的噪音早已无法满足实际需求。本文提出一种快速的自动清洗噪音的方法, 该方法将一次抽取结果中的词汇转化成无向图的结构, 通过分析计算无向图中节点之间的关联特点, 识别出其中的噪音词汇。
同义关系无向图S-Graph(Synonym Graph)定义为: 设节点集合为W={w1, w2, …, wn}, 每个节点wi对应一个词汇, 因此节点集合也可以看做是一个词汇集合; 设边集合为E, 如果wi的同义词抽取结果中存在wj或者wj的同义词抽取结果中存在wi, 则eij
从以上定义可以看出, 对一个词汇集合, 生成的无向图结构依赖于特定的同义词抽取方法。不同抽取方法, 对同一个词汇的同义词抽取结果是不相同的。如果同义词抽取方法已经给定, 则可以利用下面的步骤为一个词汇的同义词抽取结果构建S-Graph(W, E), 其中W和E分别为节点集合和边集合。S-Graph构建过程如下:
输入: 词汇w
输出: S-Graph(W, E)
Initialize S-Graph(W, E) // W和E初始化为空集合
W=F(w) //对词汇w的同义词抽取结果
For each wi
Wi= F(wi)
For each wj
If wj
Put eij into E
Return S-Graph(W, E)
理想情况下, 一个词汇的抽取结果所生成的S-Graph应该是一个完全图, 这是因为如果抽取结果完全正确, 那么抽取结果中任意两个词汇都互为同义词, 可以表示为: 
由于实际中语料、抽取方法等原因, 很难出现上述的理想情况。在语料方面, 通常是人工筛选并整理, 规模尽可能大, 但也无法做到真正的全面和客观。比如, 语料中分别存在wi是wk同义词和wj是wk同义词的证据, 没有wi是wj同义词的证据, 这就使得节点集合W={wi, wj, wk}的S-Graph不是一个完全图, 如图1所示。虽然有的抽取方法利用同义传递的方式能够为图1中的wi和wj建立同义关系[12], 但如果wk是噪音, 反而会产生错误的传递。
 | 图1 S-Graph示例 |
如果把一次抽取结果W划分为抽取正确的同义词Wsynonym和噪音Wnoise两部分, 那么对应地可以把S-Graph切分为S-Graphsynonym和S-Graphnoise两个子图。S-Graph具有以下三个特征:
(1) 在S-Graphsynonym中, 节点之间连接紧密;
(2) 在S-Graphnoise中, 节点之间没有或只有少量边连接;
(3) S-Graphsynonym和S-Graphnoise之间没有或只有少量边连接。
第一个特征是因为S-Graphsynonym中的同义词相互也为同义关系, 第二个特征是因为噪音之间成为同义关系的可能性非常小, 第三个特征是因为同义词和噪音之间不可能为同义关系。
基于以上三个特征, 提出噪音的自动清洗方法。其基本思想是: 将S-Graph根据连通关系划分为若干连通子图, 判断每个连通子图属于S-Graphsynonym还是S-Graphnoise, 主要根据子图的规模和连通度。下面给出清洗方法的流程:
输入: S-Graph(W, E)
输出: Wnoise
Initialize Wnoise //将噪音词汇集合初始化为空集合
//把S-Graph切分为连通子图集合{G1, G2, …, Gm}
SG=GraphPartition(S-Graph)
For each Gi
ri=Synonym_Reliability(Gi)
//评估每个连通子图为同义词的可信度
rj=Max{ri | 1≤ i≤ m}
Return Gj
该方法选择可信度最高的子图, 其中的词汇为同义词, 而不在所选择子图的词汇则为噪音。方法的关键在于可信度的评估。本文提出的可信度评估的公式如下:
 |
其中, W和E分别是指连通子图Gi的节点集合和边集合, α 和β 分别是W和E的权重系数。显然, 这是正比例函数, 即一个连通子图的规模越大, 该连通子图中的节点为同义词的可信度越大。β 一般取值是α 的1.5倍到2倍, 因为边的密度(边和节点的数量之比)越大, 说明节点之间互为同义词的可能性也越大, 噪音之间很难形成稠密的边。当一个连通子图中仅有一个节点时, 可信度计算为0。在有的情况下, 所有子图都是只有一个节点, 这说明搜索结果中很可能没有同义词或者仅有一个同义词。遇到这类情况时, 就需要人工或借助领域知识, 这也将作为后续的研究内容。如果语料规模较小, 也有可能出现多个连通子图中的节点都为同义词的情况, 这是因为没有在语料中不同连通子图之间建立起同义关系。因此, 当语料规模较大时, 可以选取可信度最大的连通子图, 如果语料规模较小, 可以设定阈值, 选取可信度超过阈值的所有连通子图, 对噪音清洗方法相应的改动不再细述。
这种朴素的方法能够从同义词抽取结果中将大部分的噪音清洗掉, 但被选择的连通子图中仍然经常存在噪音。原因是有的抽取方法对同义词定义得较为宽松(比如相关关系), 使得有些噪音仍然能够与同义词在S-Graph中建立关联。针对这个问题, 下面对朴素的噪音清洗方法进行改进。
通过考虑多种不同的因素可以消除连通子图内的噪音。在S-Graph中, 对于有边相连的两个词汇, 才会计算它们互为同义词的可能性, 但这样的方式存在局限性。比如, 词汇wa出现在词汇wb的同义词抽取结果中, 但词汇wb并没有出现在词汇wa的同义词抽取结果中, 就会使得对词汇wa和词汇wb互为同义关系的判断具有较大的不确定性。另外, 两个词汇即使在S-Graph中没有直接的边相连, 如果存在较多的路径连通, 也存在互为同义词的可能性。如图2所示, 词汇wa和词汇wb之间虽然没有边直接连接, 但通过其他词汇存在多条连通的路径: e(a, x1)e(x1, x2)e(x2, b)、e(a, y)e(y, b)、e(a, z)e(z, y)e(y, b), 因此也存在互为同义词的可能性。为了消除局限性带来的问题, 需要综合多种因素, 通过为边加权, 权衡两个词汇互为同义词的可能性。
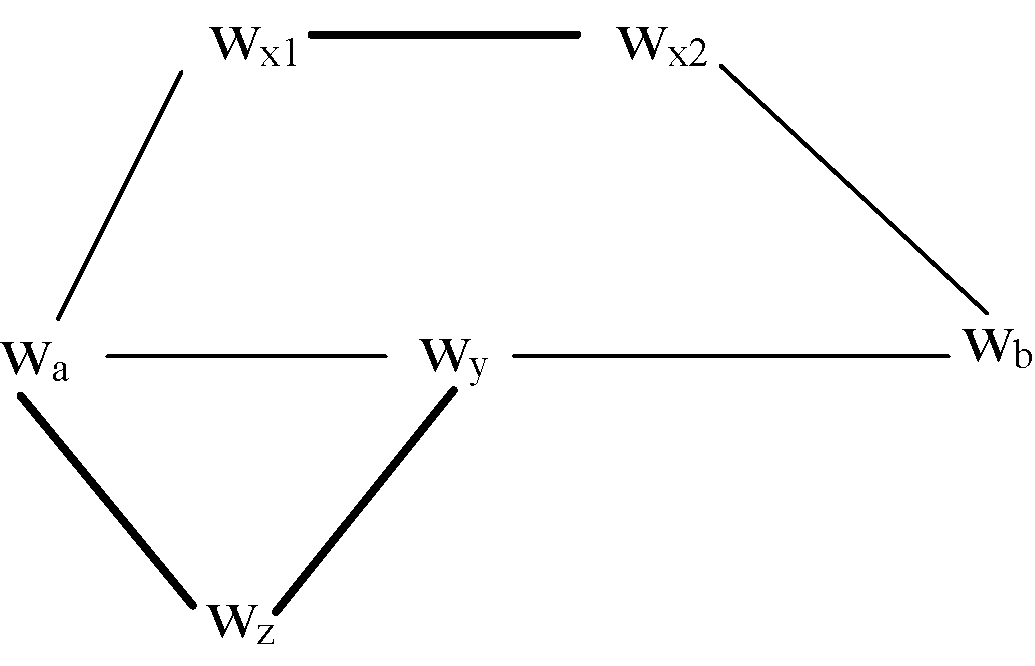 | 图2 S-Graph中词汇之间的双向检索、 节点距离和连通度示例 |
本方法主要考虑三个方面因素: 双向检索、节点距离、连通度。双向检索是指S-Graph中两个邻接的词汇之间的边是否为双向, 即是否同时出现在对方的同义词抽取结果中。显然, 双向边比单向边更有可能使得被连接的两个词汇互为同义词。直观上, 双向边连接的两个词汇是同义词的概率应为单向边的两倍, 但事实上并不一定, 可能小于两倍, 也可能远高于两倍, 这依赖于具体的同义词抽取方法, 可以通过对标注的样本进行统计来估计二者的比例。这种概率作为权值赋给对应的边, 比如边e(i, j)对应的权值为vij。节点距离是指两个词汇在S-Graph中的最短路径的长度。如果两个词汇有边直接连接, 那么距离为1, 如果没有任何路径连接, 那么距离为+∞ , 在实际应用中设置一个足够大的数值即可。图2中, wa和wb之间的节点距离为2。显然, 两个词汇之间距离越短, 它们互为同义词的可能性越大。连通度是指两个词汇在S-Graph中连接路径的数量。图2中, wa和wb之间存在三条路径, 其中两条路径存在重叠。由于同义词具有传递性, 尽管两个词汇没有直接连接, 但路径上的词汇作为桥梁使得同义关系能够从路径的一端传递到另一端。在S-Graph中两个词汇之间路径越多, 说明它们是同义词的可能性越大。因此, 综合以上三个方面的因素, 提出改进的噪音清洗方法。
改进的噪音清洗方法的基本思想是: 对S-Graph中的任意两个词汇, 分别基于每一条路径计算这两个词汇是同义词的概率, 取其中概率最大的路径。其中, 对于给定的一条路径e(a, k1)e(k1, k2)…e(kn, b), 两个词汇为同义词的概率可以计算得出:
 |
需要指出的是, S-Graph中相邻的两个词汇, 它们是同义词的概率不一定由直接相邻的边得到。例如图2中wa和wy之间的路径e(a, y)和e(a, z)e(z, y), 如果e(a, y)是单向的, 而e(a, z)和e(z, y)是双向的, 那么基于路径e(a, z)e(z, y)得到wa和wy为同义词的概率可能反而大于基于路径e(a, y)得到的概率。当S-Graph较大时, 对任意两个词汇分别计算会因大量重复的计算而导致效率低。为了避免这种情况, 本文提出的方法是同时计算S-Graph中任意两词汇之间的同义词概率。改进的噪音清洗方法如下:

改进的方法实现思路与求最短路径的Floyd算法类似, 利用动态规划的思想, 对于任何两个词汇wi和wj, 它们之间的最大概率的路径不外乎存在经过wi和wj之间的wk和不经过wk两种可能, 因此可以令k=1, 2, 3, …, n(n是词汇的数目), 检查p(i, j)与p(i, k)× p(k, j)的值; 在此p(i, k)与p(k, j)分别是目前为止所知道的wi到wk与wk到wj的路径的最大概率, 因此p(i, k)× p(k, j)就是wi到wj经过wk的路径的最大概率。所以, 若有p(i, j)< p(i, k)× p(k, j), 就表示从wi出发经过wk再到wj的距离要比原来的wi到wj概率大, 因此把wi和wj的p(i, j)重赋值为p(i, k)× p(k, j), 每当检查完一个wk, p(i, j)就是目前的wi到wj的最大概率。重复这一过程, 当查完所有的wk时, p(i, j)就是wi和wj为同义词的最大概率。同义词是语义相同或相近的词汇, 实际上只有很少的词汇之间语义完全相同, 大部分或多或少总会有些差别, 两个词汇的语义到底多相似才能算做同义词, 这很难给出一个统一的标准。因此, 在改进的方法中设置一个阈值δ , 作为区分同义词和噪音的边界。阈值δ 可以通过对样本标注来设定, 与边的概率的设定一起完成。
(1) 同义词抽取系统
使用工程技术类的《英文超级科技词表》编制平台作为同义词抽取系统。图3是该平台的主要界面, 用户在术语列表中选择一个词汇, 在同义词候选列表中就会显示该词汇的候选同义词, 专家从候选同义词中选择正确的同义词。该平台采用多种同义词抽取技术以保证抽取的召回率, 可以将其视为“ 黑盒子” , 即输入一个词汇, 获得该词汇的一组候选同义词。为了表达简单, 本文用SE(Synonym Extractor)来指代该系统。
(2) 数据集
为了保证实验结果的客观性, 数据集是从工程技术类术语库中随机选取的300个经过专家审核的术语, 其中50个术语作为训练集, 剩余250个术语作为测试集。训练集用于清洗方法中参数取值的设定, 测试集用于测试去噪方法的性能。
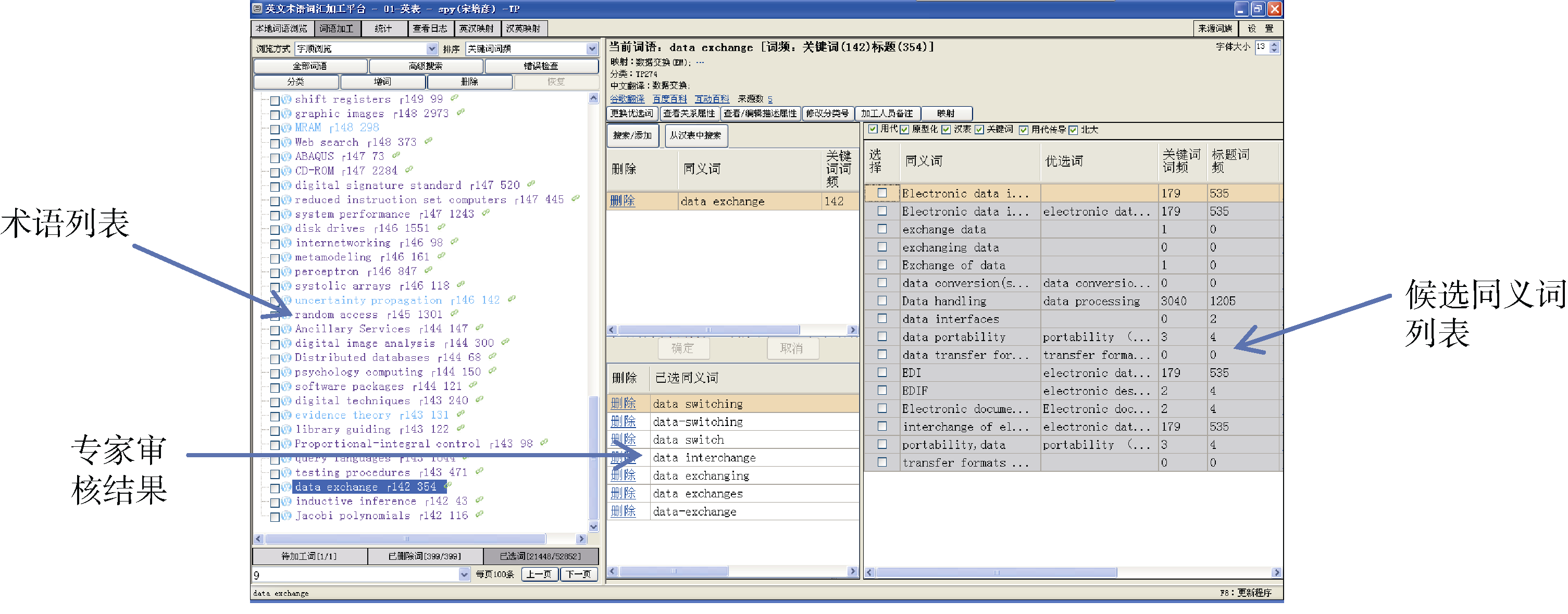 | 图3 工程技术类的《英文超级科技词表》编制平台 |
(3) 参数取值的设定
在开展实验之前, 需要设定: 朴素噪音清洗方法公式(1)中参数α 和β 的值; 改进噪音清洗方法中单向边和双向边分别对应的概率, 以及阈值δ 。参数取值的设定过程较为简单, 对训练集中的每个术语按照以下几个步骤设定即可:
①获得候选同义词和专家审核结果;
②生成同义关系无向图;
③在无向图中, 根据专家审核结果, 从无向图中将包含同义词的子图标注出来;
④调整朴素噪音清洗方法公式(1)中参数α 和β 的值, 使得两类子图恰好分开; ⑤在包含同义词的子图中, 根据专家审核结果, 标注出为正确同义词的节点, 计算单向边、双向边分别对应的概率;
⑥阈值δ 的设定是在单、双向边的对应概率基础上, 使得噪音清洗比例最高。
基于设定好的参数, 使用朴素方法和改进方法分别在测试集上展开实验。对实验结果使用准确率、召回率和F值进行评估, 识别准确率是指去除的噪音中真正的噪音所占的比率, 噪音召回率是指去除的真正的噪音占全部噪音的比率, F值是对二者的加权平均综合。总体的实验结果如表1所示:
| 表1 总体实验结果 |
朴素方法在准确率上较高, 在召回率上则较低, 与之相比, 改进方法在准确率上略低于朴素方法, 但在召回率上明显高于朴素方法, 因此在F值上改进方法也要明显高于朴素方法。这是由于同义词大都集中在最大的子图上, 朴素方法保留最大子图, 而改进方法是在朴素方法去噪结果基础上进一步去噪。
如图4所示, “ abrasive” 对应的同义关系无向图有5个子图, 其中4个子图为只有三个节点或一个节点的子图, 按照朴素方法将这4个子图作为噪音去除, 按照改进方法将最大子图中概率较小的“ dirty” 、“ slay” 等作为噪音去除。同时, 也对将同义词识别为噪音和没有识别出来的噪音这两类错误情况进行分析。将同义词识别为噪音是影响识别准确率的主要因素, 其原因是该同义词与其他同义词没有连接或只有单边连接。与其他同义词没有连接的同义词, 会被朴素方法误识别为噪音; 而与其他同义词只有单边连接的同义词则可能被改进方法误识别为噪音。没有识别出来的噪音是影响噪音召回率的主要因素, 这些噪音主要存在于最大的子图中, 与某个同义词存在连接, 使得改进方法误识别为同义词。对前一类错误需要扩大语料库的规模, 使得同义词之间能够建立连接; 而对第二类错误则依赖于同义词抽取方法的准确率, 比如有的方法将相关的词也抽取出来, 导致大量的噪音。
 | 图4 实验结果分析示例 |
由于去噪方法是基于同义关系无向图, 分析节点之间的连接关系, 因此噪音识别的准确性与图的复杂性成正比关系, 而图的复杂程度依赖于抽取结果的多少。把测试集中的术语按照抽取结果的数量分为1-10、11-20、21-30、31以上4个部分, 并比较朴素方法和改进方法在不同部分上F值的表现, 如图5所示。可以看出, 随着抽取结果数量的增加, 无论是朴素方法还是改进方法的F值都有明显上升。
 | 图5 F值与抽取结果规模的关系 |
对同义词抽取结果中的噪音进行清洗, 可以提高抽取结果的可用性。把抽取结果转化为同义关系无向图, 并基于该图提出朴素去噪方法和改进去噪方法, 可以去除同义词抽取结果中的部分噪音, 提高抽取结果的准确性。未来将进一步对现有去噪方法优化, 并在测试集和不同抽取方法两个方面扩大实验规模, 提高噪音识别的准确性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|