
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Drupal数据采集在构建特色数字资源中的实践*
[李丹 , 闫晓弟, 魏青山]
, 闫晓弟, 魏青山]
, 闫晓弟, 魏青山]
|
|


解决特色数据库建设过程中数据抓取困难、多类型数字资源难以整合等问题。【应用背景】特色资源信息生命短暂, 陕西省已建特色库平台差异较大, 支持RSS接口有限, 数据格式复杂。
方法利用Drupal Feeds, XPath Parser, Crawls, Image Grabber等Web数据采集技术, 结合数据清洗、剔除手段, 实现Web数据采集的系统化和专业化。
结果对Feeds RSS 采集, HTML/XML网页分析自动采集, 特别是数据采集中需要针对不同特色资源修改规则及采集网页中流媒体等问题进行探讨。
结论丰富陕西省特色数字资源平台的数据来源, 部分解决数据采集困难、数据格式不规范、数据来源途径有限的问题。
[Objective] To address the problems of Web data collection, difficult to integrate multiple types of digital resources etc. in characteristic database construction. [Context] The life of characteristic digital resources information is short, each heterogeneous database platform in Shaanxi has great difference, supports limited RSS interface, contains complex data formats. [Methods] Using Web data collection technology such as Drupal Feeds, XPath Parser, Crawls, Image Grabber, combined with data cleaning and removing, to achieve specialization and systematization for Web data collection. [Results] Explore feeds RSS collection, HTML/XML automatic acquisition, rules for different characteristics of resource modification specially, and Web streaming media collection. [Conclusions] This study can rich platform data sources, partially provide solutions to difficult data collection, data formats unstandardized, data source route limited and so on.
特色数字资源建设是地域历史文化特色展现和保存的重要手段, 近年来, 公共文化机构、文化产业集团、科研教学单位、旅游文化部门通过多种渠道, 利用各种信息技术, 建立了品种繁多的特色数字资源, 数量和质量都取得突破性进展。以笔者所在的陕西省为例, 截至2013年2月, 参与建设特色数字资源的单位有100多家, 建立了以陕西省文化、历史、景观等为主题的近100个特色资源库[1]。如“ 陕西帝王陵、陕北民歌数据库、秦派二胡资源数据库” 等特色数字资源, 这些特色资源以虚拟立体方式展现了整个陕西省悠久的历史文明, 为进一步研究特色资源采集策略提供数据源。
本文以西安交通大学图书馆自建的“ 陕西省特色数字资源库” 为例, 利用开源软件Drupal, 实现了特色数字资源库数据自动采集、查重、纠错等功能, 结合人工筛选、标引, 达到快速、高效建立以陕西省民俗文化为主的特色数字资源库的目的。
Web数据采集主要方式就是模拟浏览器访问行为, 将浏览器显示的数据按照一定规则提取出来, 以CSV、JSON、XML、SQL等结构化方式存储[2], 映射之后导入相应的特色库中供读者使用。
目前, 商业化的数据采集软件主要有火车头采集器、八爪鱼采集器等, 免费的数据采集则主要利用一些开源软件或自编程序搭建数据采集模块, 针对性采集公开发布的网页数据, 结合人工干预建立特色数据库[3]。
中华书局网上书店、中国科学院高能物理研究所利用Drupal Feed API抓取RSS[4]; 外语教学与研究出版社利用Drupal建立站群, 通过Drupal强大的采集功能实现信息主站和子站间信息以CSV等格式批量导入导出, 同时, 利用Drupal抓取京东图书信息, 采集新书封面和内容摘要[5]; 西安交通大学图书馆自编PHP程序, 根据ISBN号, 从亚马逊网站上通过页面分析采集书封[6]。Drupal在数据抓取、处理、整合及共享方面功能越来越强大。
陕西省特色数字资源平台是西安交通大学图书馆负责承担 “ 陕西省地方特色数字资源共建共享模式研究” 的项目平台, 旨在收集整理陕西省优秀的地方特色数字资源, 宣传陕西省优秀文化成果。项目建设过程中, 笔者发现陕西省现有特色数字资源格式异构, 标引和检索点不统一; 分布于不同机构的自建特色库之间不能共享数据, 大部分特色库无数据导出接口, 为数据采集带来一定困难, 陕西省图书馆建立的11个特色库都不提供RSS接口, 采集时需通过分析网页实现; 一些特色库建设需要把数据采集到元数据池中, 经人工干预处理之后才能导入到特色库中。
为了能以较低成本解决这些问题, 笔者采用Drupal模块搭建采集渠道, 分析特色数据源, 针对资源个体定制采集频率, 根据消息格式采取对应采集策略, 采集高质量资源, 且支持智能抓取和数据清洗, 解决资源漏采、重复采集以及可访问性等因素限制[7]。
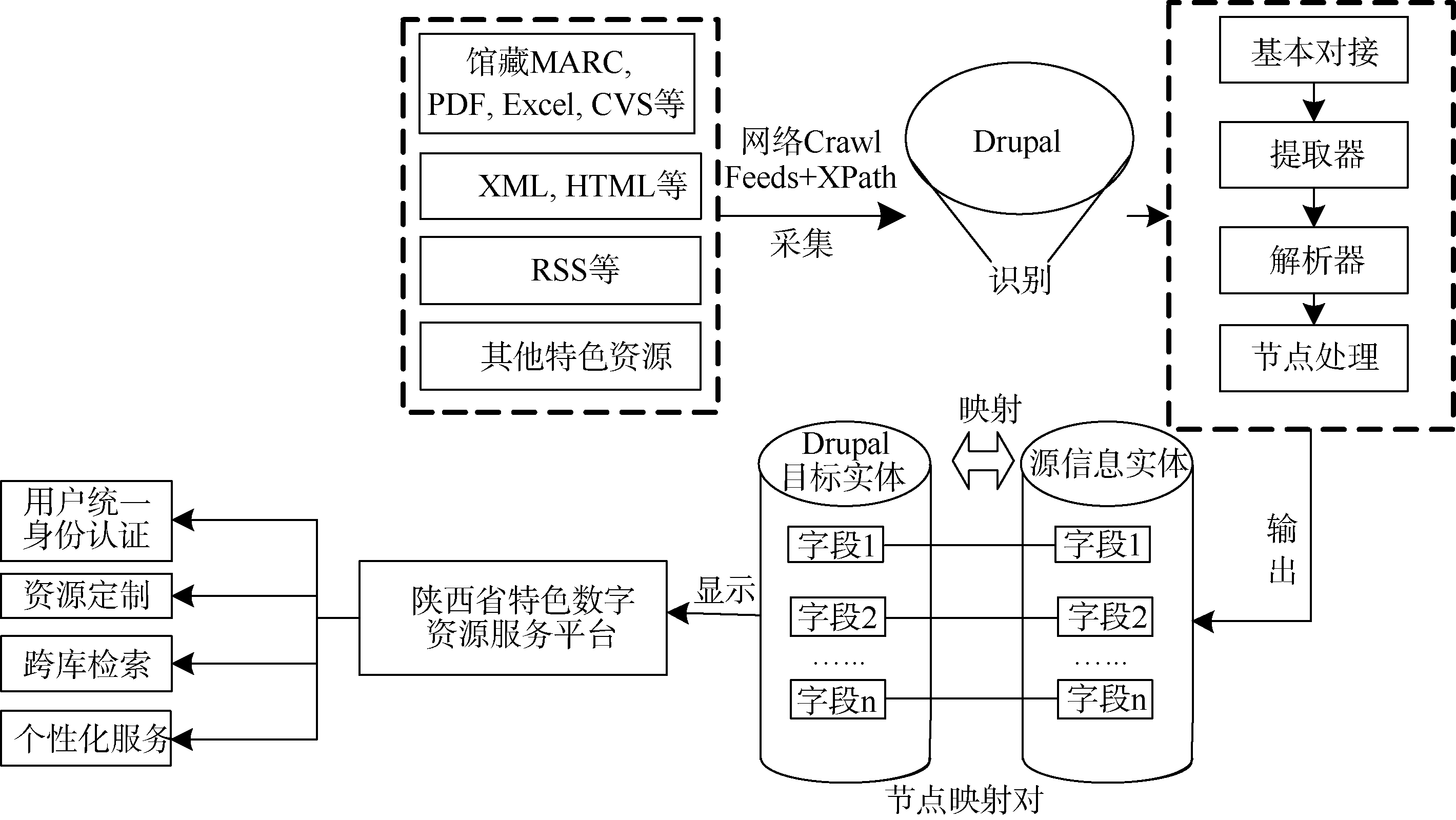
陕西省特色资源库根据消息类型采取对应的采集策略, 结合XPath规则, 依据Web页面结构的模式匹配实现特色资源采集, 灵活地添加各种内容分析器, 即可将不同来源特色资源轻松地导入到各种实体中。基于以上思路, 笔者提出如下采集流程:
(1) 信息识别, 将异构特色资源库中的数据按格式分类, 筛选出高质量且受用户关注的信息。
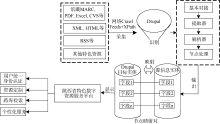
(2) 数据匹配映射, 通过Feeds+XPath Parser+ Crawls+Image Grabber等模块, 按照数据标准和建库映射规则, 对信息源进行基本对接、提取、解析和节点处理后可进行源信息各异构特色库实体字段与Drupal实体字段的映射, 编写映射规则, 清洗数据, 主要采用RSS接口聚合深度整合数据、HTML/XML网页语义分析提取以及不同格式数据转换批量导入等方法(如表1所示)将数据自动采集到特定主题实体下, 进一步通过VBO或Drupal API自行编写程序批量深度更新采集数据。
| 表1 陕西省特色数字资源平台采集策略 |
(3) 将采集到的特色资源展现到读者面前, 为读者提供跨库检索、资源定制等服务, 采集流程如图1所示。
(1) RSS接口聚合技术实现
利用Drupal Feeds构建RSS采集器, 针对提供RSS接口如中国国家图书馆在线展览、科学网等特色门户网站实现网站中以“ 陕西资源” 等为主题的RSS页面采集, 通过与RSS 接口对接进行采集, 实现个性化信息聚合, 保持和信息源数据同步更新。
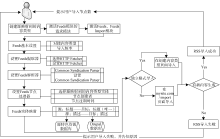
以科学网特色资源研究文献采集为例, 将采集RSS限定为包含“ 陕西” 关键词的页面。采集流程如图2所示。
①创建RSS导入后匹配的内容类型“ 特色资源研究文献” , 设置Feeds, 根据需求选择是否对接特定内容类型, 从而决定导入方式, 根据RSS更新频率设置定期采集频率。
②设置Feeds 提取器HTTP Fetcher和解析器Common Syndication Parser, 设置Feeds节点处理器参数, 选择RSS需映射到Drupal里的内容类型, 根据管理员角色设置节点创建者和节点有效时间。
③进行Feeds实体映射, 逐条添加目标Drupal内容类型字段与源RSS字段的映射, 设置源RSS Node ID映射到的Drupal“ 特色资源研究文献” 字段GUID为唯一项。
④执行导入, 通过对接内容类型“ Feed” 来导入RSS, 访问创建“ Feed” 内容类型页面, 通过源RSS数据的入口地址导入RSS特色资源。
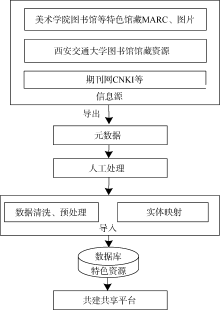
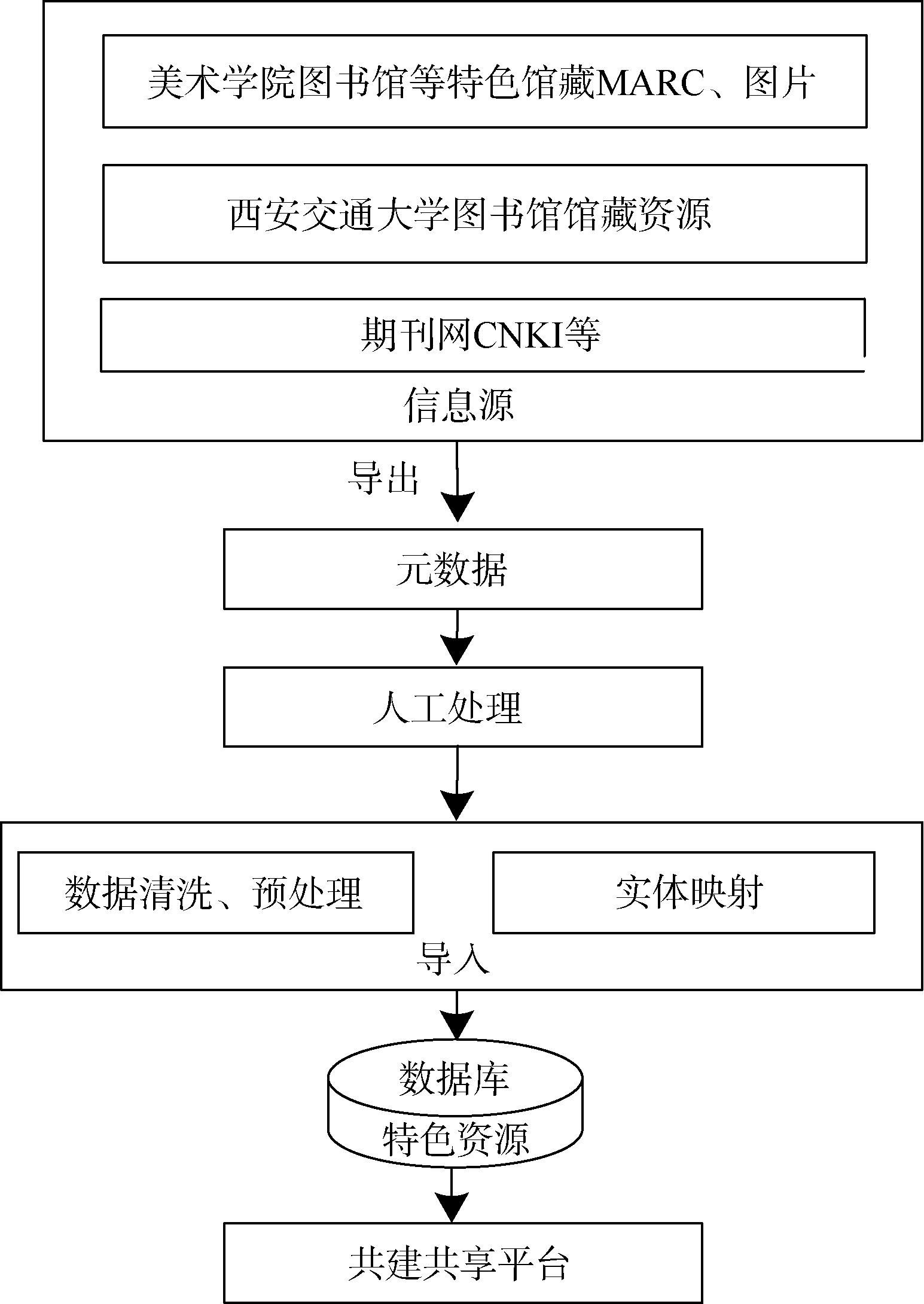
 | 图1 陕西省特色数字资源平台数据采集流程 |
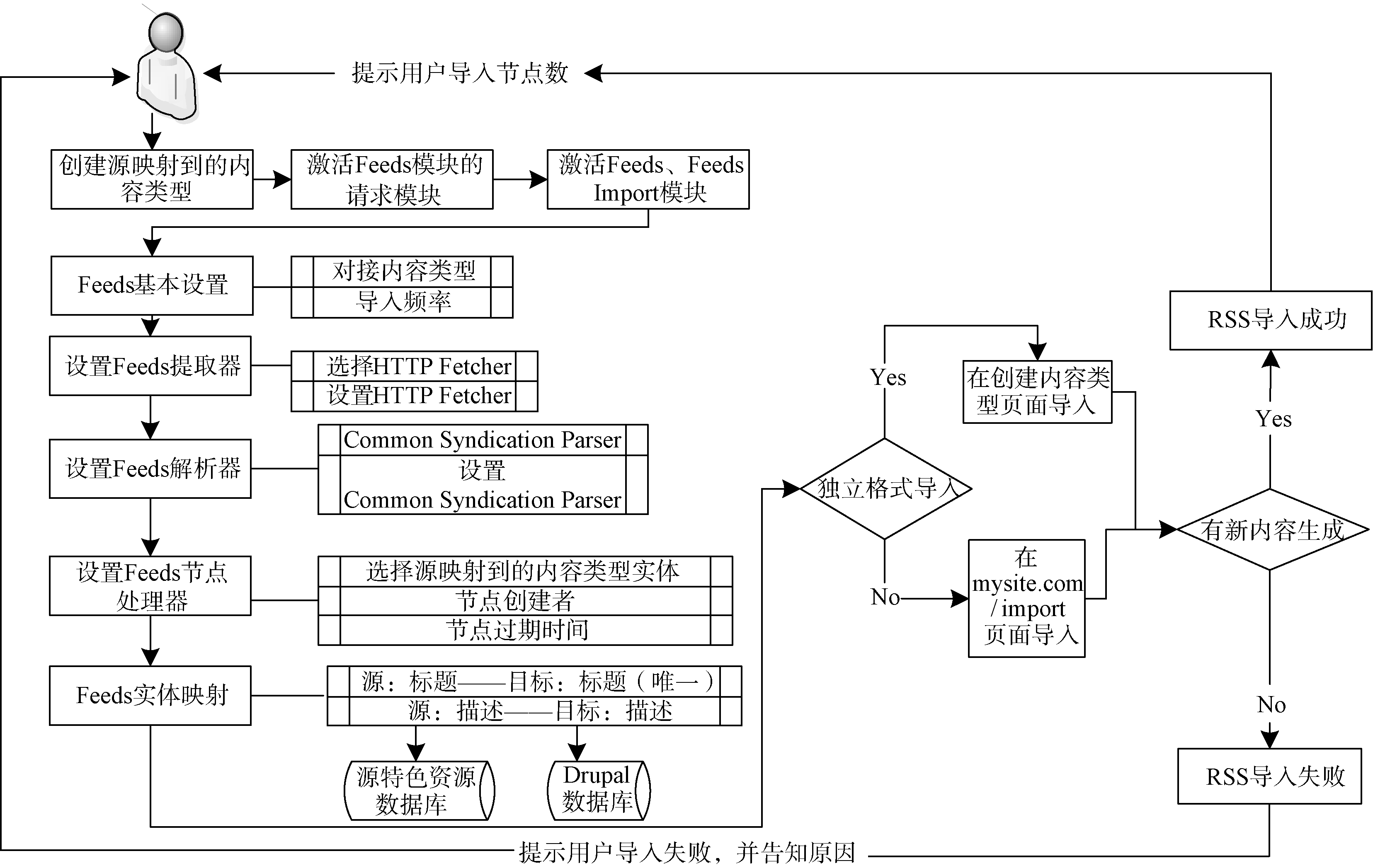 | 图2 RSS数据采集流程 |
(2) HTML/XML网页分析自动采集
该策略采用Feeds作为导入器, 引入插件Feeds XPath Parser, 针对陕西省数字博物馆特色资源数据库、陕西省图书馆已建8个特色库中的指定栏目下的网页内容进行采集。
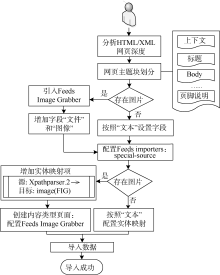
HTML/XML导入流程基本和RSS导入相同, 不同的是解析器的选择、Feeds XPath Parser的设置、实体字段的映射以及XPath路径表达式[8]的编写。通常特色资源HTML网页中图片和文字共同出现, 此时采集工作复杂。该采集方法的关键是需要开发者充分分析HTML/XML网页主题块划分、代码层次, 选择可以定义标题等主题块链接的区域代码, 确定实体中的字段映射, 编写合适的XPath路径表达式。Feeds根据人工配制结果, 调用对应XPath规则和映射关系, 通过在用户接口创建内容类型页面引入Feeds Image Grabber(FIG)抽取网页中的图片。
以采集陕西省数字博物馆特色资源“ 凤翔遗珍— — 凤翔县博物馆藏品精粹” 为例, 采集流程如图3所示。
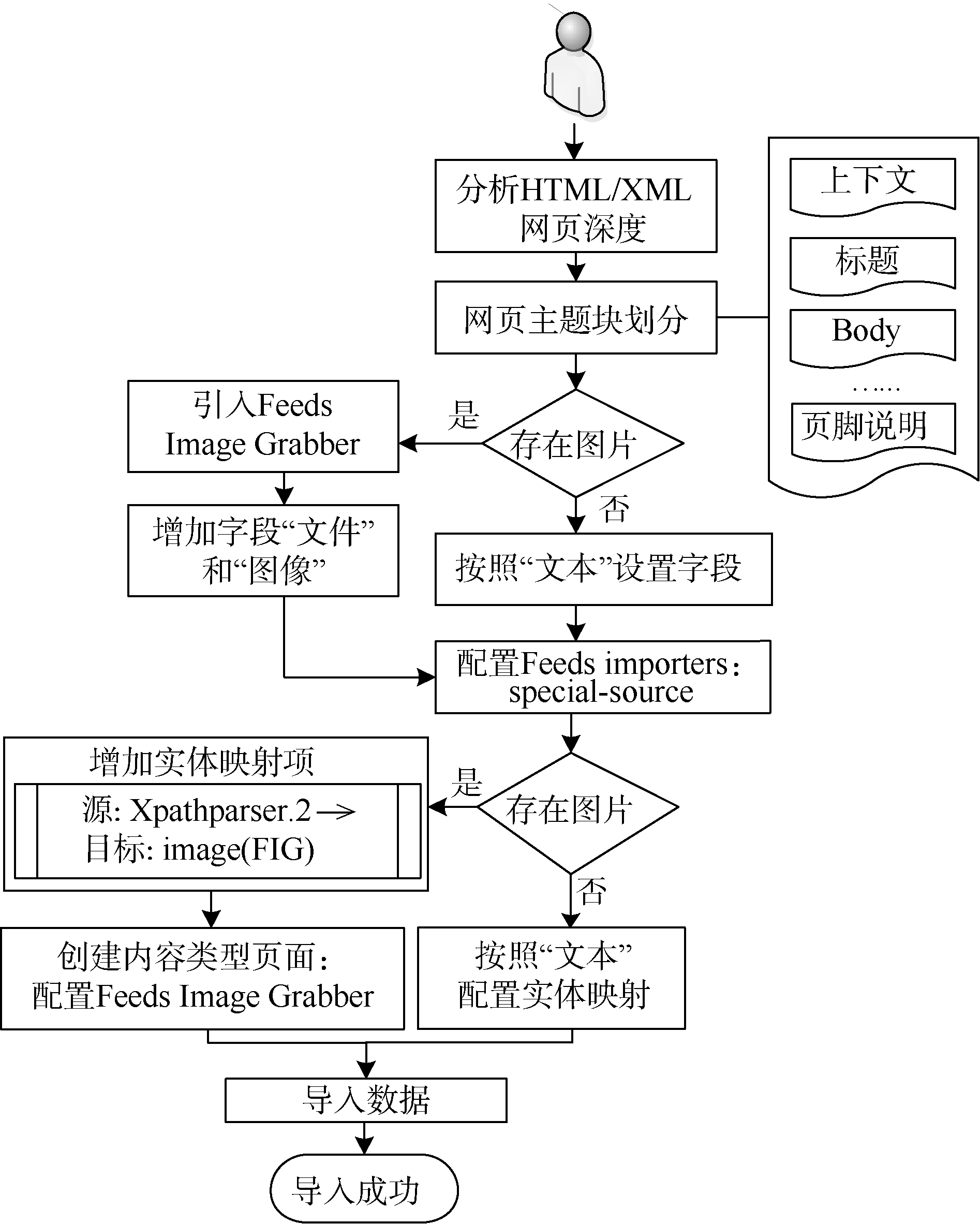 | 图3 图文采集流程 |
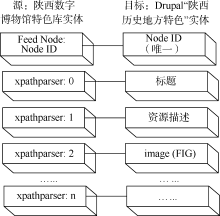
网页深度为2且存在图片, 引入File (Field) Paths和FIG; 增加内容类型“ 资源” 和字段“ 文件” 、“ 图像” ; 配置Feeds importers: special-source, 增加实体源图片字段到Drupal Image (FIG)的映射项(两实体字段映射如图4所示), 按照XPath语法在XPath HTML Parser中分别对各个字段编写XPath路径表达式(部分路径表达式如表2所示); 确定图片标签类型为“ class” ; 通过找到标题的父亲或者父亲的父亲标签, 选择离标题最近的标签为图片搜索范围。如图5所示, 该图片范围在class 值为page_left main的div标签内, 选择搜索时遇到的第一张图片为Feeling Lucky值; 设置图片采集时间为整个采集代码运行时间10%。设定好采集策略参数后, 即可根据URL收割图像, 将从陕西省数字博物馆特色资源库里抓取的图片存储到Drupal“ 资源” 类型节点中。
| 表2 网页XPath路径表达式 |
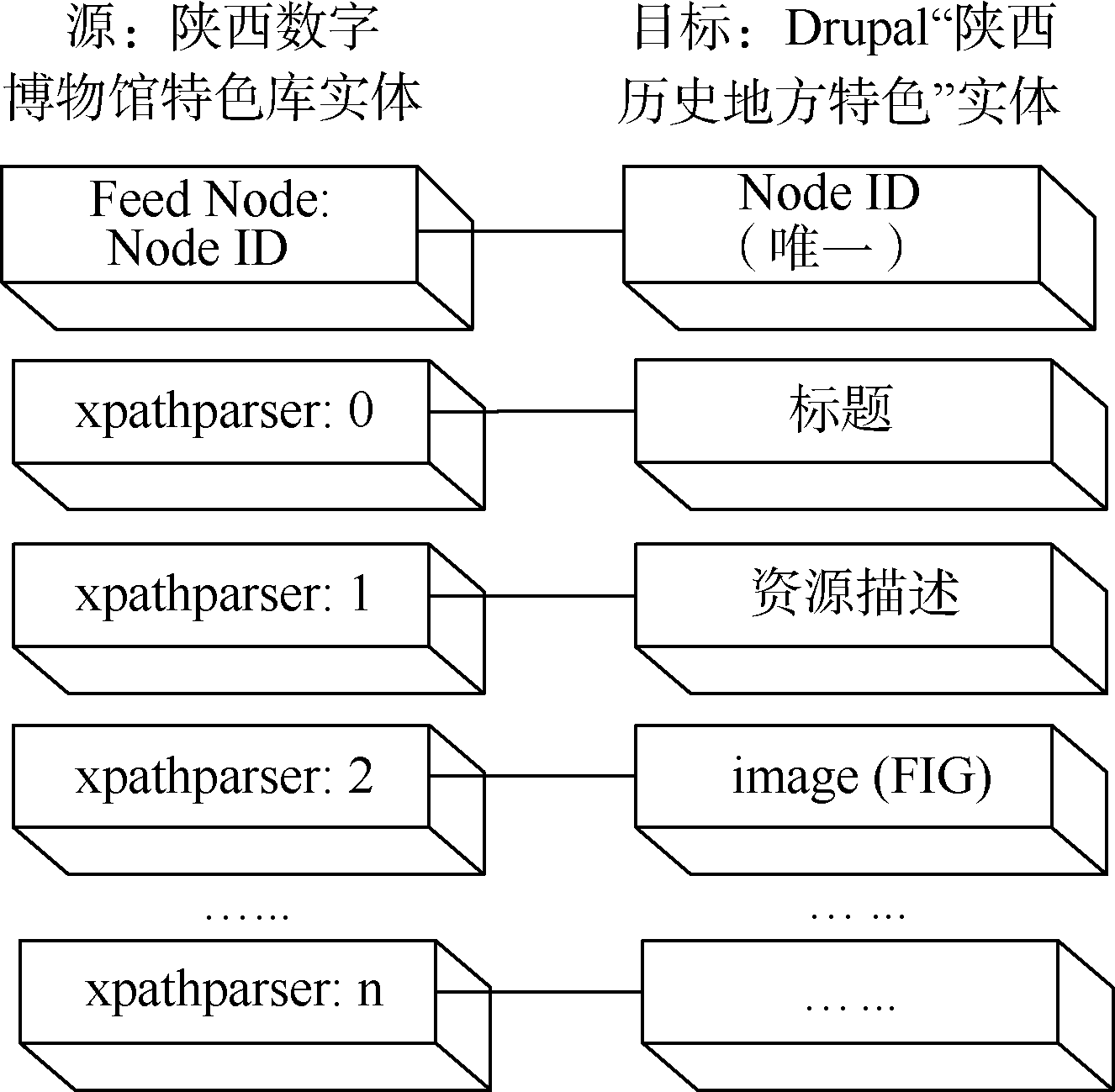 | 图4 实体映射对 |
 | 图5 陕西省数字博物馆特色资源HTML源码 |
(3) 批量数据导入
针对CNKI、西安交通大学及西安美术学院图书馆等特色馆藏图片、MARC, 采用Drupal Bibliography、Feeds整合, 将元数据进行人工处理、映射后导入到特色资源数据库中, 如图6所示:
基于Feeds批量导入之前需要对比源和目标实体中字段类型、数目的差别, 根据制定的数据标准, 修改和扩展源数据文件字段, 使得源字段和目标字段可以一一映射, 以Use Standalone Form格式导入, 关闭周期性导入, 选择File Upload为提取器, CSV Parser为解析器, 一一映射实体字段, 将元数据通过Feeds Tamper预处理后执行导入。
以采集西安交通大学图书馆特色馆藏中有关“ 陕西特色” 的书目信息为例, 导入时经常遇到数据不准确、显示乱码和数据冗余等问题。数据不准确是由元数据项作者字段为多值以及特色资源“ 分类” 和“ 资源类型” 中存在多值分类等现象造成, 可通过Feeds Tamper Explode预处理解决。中文字段导出数据出现乱码是由特色库页面编码格式引起的, 可通过转换文件格式为CSV格式、采用UTF-8编码, 在Feeds Tamper添加“ Find Replace” 替换乱码字符来解决, 也可引入模块Feeds Excel, 修改插件中设置编码的函数。数据冗余出现在一次导入大量数据时, 通过在实体映射中正确设置唯一的映射字段解决。
(4) 批量更新采集数据
利用上述三种策略采集的资源中存在中文部分有乱码显示、部分图片显示不完整现象, 笔者以解决图片显示为例, 通过VBO或Drupal API批量深度更新采集数据的算法如下:
输入: 采集到的“ 资源” 类型节点集
输出: 准确展示的“ 资源” 类型节点集
①分析内容类型为“ 资源” 的所有实体的“ 资源描述” 、“ image” 等字段值;
②建立VBO批量处理view: update-image;
③利用VBO模块的Bulk Operations中Execute Arbitrary PHP Script操作批量更新图片URL, 将“ 资源描述” 图片URL字段值更新后写入“ image” 字段。核心代码如下:
//$home表示源特色库网站地址
$field_url = $entity-> field_body ['und'][0]['value'];
$field_url = substr_replace ($field_url, $home, 0);
$entity-> field_sourceimage ['und'][0]['value'] = $field_url;
④保存, 批量更新节点。
中文乱码显示处理方法与以上算法类似, 通过字符串迭代转换, 实现采集中文数据的准确显示。
资源中心服务器采用VMware 虚拟服务中心提供的虚拟机搭建运行环境, 使用软件包括Windows Server 2003操作系统、MySQL数据库管理系统、Drupal 7.24、Feeds 7.x-2.0-alpha8、FIG 7.x-1.0-alpha2、Feeds XPath Parser 7.x-1.0-beta4、Feeds Crawler 7.x- 1.0-beta2等。
利用Drupal采集特定主题Web数据, 有效解决了数据获取问题, Drupal 采集的优势在于其Feeds+ XPath+Crawls+Image Grabber采集工具可将复杂信息量化成可配置的采集参数。采集发布效果如图7所示:
 | 图7 采集发布效果 |
(1) RSS采集实验
目前已经建立的“ 陕西文史资料” 、“ 陕西民间美术” 等大部分特色数据库几乎不提供RSS接口, 只有一些国家级图书馆和高校图书馆支持该功能, 虽然主题内容不是很契合, 但是方法相同, 故笔者选取国家图书馆在线展览和科学网以及西安交通大学图书馆社会科学/政治/文化类新书部分RSS数据(近30条)进行测试, 实验结果显示: 所有RSS数据都可以采集到, 但是存在数据内容采集不全的现象。经分析, 一方面多数特色资源网站只提供RSS摘要抓取, 需要人工补充全文信息, 如西安交通大学图书馆新书RSS页; 另一方面RSS发布时, 信息标题和详细内容不在同一个RSS中, RSS采集一次只能完全采集RSS列表的一级页面和RSS详细文本页面以及RSS中部分图片, 比如科学网RSS列表页和国家图书馆在线展览RSS页。另外, 分析所采集到的RSS数据, 发现数据过于杂乱, 并不仅仅囊括有关“ 陕西特色” 的内容, 还需要人工后期剔除。
(2) HTML/XML网页分析自动采集实验
笔者选取陕西省图书馆 “ 秦腔秦韵” 、“ 陕西民间美术” 、“ 陕西非物质文化遗产” 等特色专题数据库和陕西省数字博物馆数据库特色资源进行实验测试, 采集数据300余条, 从结果可以看出大部分信息可以采集到但存在部分图片、视频、文本抓取不全的问题, 一方面由于网页格式非结构化, 编写通用的XPath提取规则比较困难; 另一方面, Drupal网页分析、提取采集数据测试局限于网页布局统一的一级页面, 多级深层次采集需要深度修改插件代码; 再次, 目前许多特色库都增加了流媒体数据支持以吸引访问者, 如采集陕西省图书馆“ 秦腔秦韵” 特色库时, 由于特色数字资源页面布局复杂, 各种剧目介绍页面多以视频格式呈现, 数据抓取时需要修改采集工具源码, 并且要借助其他数据处理工具对抓取到的数据进行清洗, 数据处理的工作量较大。
(3) CSV等文件批量数据导入实现
笔者选取通过NotePress基于关键词“ 陕西特色数字资源” 从CNKI检索到的相关数据, 西安交通大学图书馆有关“ 陕西特色” 书目信息(* .xml)以及西安美术学院图书馆有关“ 陕西特色” 的馆藏信息进行测试, 实验结果显示所有数据都可以完整批量导入, 但是存在数据内容采集不全的现象, 如表3所示:
| 表3 文件批量数据导入实验结果 |
相比前两种采集策略, 此方法适合数据量大的信息采集, 且导入后数据格式比较规整, 不包含冗余信息。如在整合西安交通大学图书馆馆藏资源时, 出现作者姓名导入不全、部分关键词丢失的问题, 主要原因是MARC格式与源文件不一致, 部分MARC字段信息不全。批量更新数据时, 部分字段在导入数据后消失, 解决方法是导入时采用更新实体节点方式。批量导入及数据更新时细节工作很关键, 一旦发生差错, 批量修改很困难。
有效采集和整合陕西省特色数字资源, 丰富了特色资源平台数据来源, 部分解决了数据采集困难、数据格式不规范、数据来源途径有限的问题。下一步, 将根据特色数字资源平台需要, 结合Drupal数据采集功能进行开发, 改进Feeds RSS 模块, 完整采集多级页面内容, 根据关键词检索结果智能采集RSS数据, 将数据采集重点放在动画、视频、图片等格式的特色资源上, 重点考虑如何对某一主题的流媒体实现快速批量下载。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|