



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于知网的甲骨卜辞释义问题的可拓性研究*
[高峰 , 熊晶, 刘永革]
, 熊晶, 刘永革]
, 熊晶, 刘永革]
|
|


构建可拓的甲骨文语言模型并结合甲骨文知网知识库解决甲骨卜辞释义问题。
方法借鉴知网的构建体系, 建立一个融合甲骨文、现代汉语的语义知识库, 对甲骨卜辞进行可拓语言建模, 结合知网的知识表示, 进行语义相似度计算和对应的可拓策略应用。
结果实验结果表明, 该方法在甲骨卜辞的词义识别准确率可达到90%以上, 在甲骨卜辞的残辞语义推导上准确率可达75%以上, 能够有效解决甲骨卜辞释义问题。【局限】甲骨文知网的构建规模较小及可拓策略的成熟度不高制约着甲骨卜辞语义信息的自动理解。
结论结合甲骨文可拓语言模型和甲骨文知网进行甲骨文信息处理研究, 为甲骨字的语义推导和残缺甲骨拓片的文本内容整合提供新的解决方案。
[Objective] To solve the Oracle Bone Inscriptions (OBI) interpretation of ambiguity and semantic problems by constructing extenics OBI language model and OBI HowNet knowledge base. [Methods] Based on HowNet framework, a semantic knowledge base combined with OBI and modern Chinese is proposed. The OBI extenics language model is introduced and fusing the HowNet knowledge representation method, and it can implement semantic similarity computation and related extension strategy application. [Results] Small-scale experiments show that the method can reach more than 90% on OBI of the correctness of the definition of ambiguity recognition, and more than 75% on OBI for the residual alteration of the righteous. It can effectively solve the problem of OBI interpretation. [Limitations] The limit of OBI HowNet knowledge base scale and extension strategy maturity restricts the semantic information of automatic understanding on OBI. [Conclusions] The OBI information processing research is based on extenics OBI language model and OBI HowNet knowledge base. It provides a new solution for OBI characters semantic deduction and incomplete OBI rubbing text integration.
甲骨学的研究随着殷墟甲骨文的发现而备受关注, 现已成为一门国际性学科。但是, 甲骨文是距今久远的一种停止使用的古代文字, 只有掌握了它本身固有的一些规律方能懂通[1]。目前, 在甲骨文数字化、拓片缀合、辅助考释等方面的研究不少, 但利用计算机进行甲骨文理解的相关研究则较少[2]。而甲骨文的理解首先要解决甲骨卜辞的释义问题, 即甲骨卜辞的机器翻译问题。在甲骨文中, 如同现代汉语一样, 依然存在字或词的语义多样化问题, 这为甲骨卜辞的释义带来困难。本文的研究目标是为甲骨卜辞中甲骨文字或词的歧义问题提供解决方案。从自然语言的角度考虑, 在实际应用中, 为把语义进行一个定量化的区分, 常采用的策略是进行词汇语义相似度的计算[3]。
自然语言实际上也是一种知识表示方法, 如果将自然语言形式化为可拓模型, 就可利用可拓方法来理解自然语言。文献[4]和文献[5]分别从自然语言建模和古文翻译角度给出了可拓方法的应用尝试; 文献[6]和文献[7]提出利用知网的语言信息处理能力增强计算机系统的自然语言理解能力, 通过学习知网的知识组织改进可拓策略生成系统的基础知识库结构, 提高其策略生成能力。这些都给甲骨文信息处理研究带来一些启示。
本文从自然语言的可拓学表示方法出发, 研究了甲骨文可拓模型的建模方法, 借鉴知网的构建体系, 将甲骨文语言形式化为可拓模型, 建立了可拓甲骨文语言模型库, 将甲骨卜辞分词并进行基于知网知识库的语义相似度计算, 结合发散树、相关网和蕴含系等可拓策略来解决甲骨卜辞释义所出现的语义歧义问题, 从而更好地解决甲骨卜辞释义问题, 为甲骨学研究提供一种新的计算机辅助方法。
可拓学是用形式化的模型去研究事物拓展的可能性和开拓创新的规律与方法, 并用于处理矛盾问题[8]。可拓学研究的主要方法包括物元可拓方法、物元变换方法、可拓分析方法以及在各领域进行应用的可拓工程方法[9]。
目前, 可拓创新方法的应用范围很广, 如研究设计领域、信息领域、控制领域、网络领域、管理领域等[10]。
可拓策略生成系统(ESGS)主要功能模块包括基础数据库、问题库、可拓规则库、可拓策略库和可拓变换库[9]。其中基础数据库中存储着比较详细的与要解决的问题相关的信息, 而它的实现是基于关系型数据库的技术。用可拓学中的基元信息与知识表示体系规范已有的数据资料, 即用基元表示概念类与实体, 同时利用调查手段获得缺少的数据资料。
知网(HowNet)是一个以汉语和英语的词语所代表的概念为描述对象, 以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库[11]。计算机化是知网的特色, 而且知网是一个网状的知识系统, 为自然语言处理提供了丰富的研究资源[12]。“ 概念” 和“ 义原” 是知网的两个重要概念。概念是对词语词义的一种描述, 而每个词语可能有不同的语义, 即可表达几个概念。义原是用于描述概念的最小意义单位, 每个概念都用一系列义原表示。同时, 知网的知识数据描述语言(KDML)具有很强的描述能力, 方便语义计算, 并有较好的可读性, 因此, 利用知网的相关知识进行语义相似度计算被更多研究者采用。
在基于知网的语义相似度计算方法上, 以基于义原的相似度计算为主。比较重要的是刘群等[13]提出的义原相似度计算, 后来李峰等[14]将其进行了改进, 结果也更为合理。其中, 刘群等[13]的计算公式为:
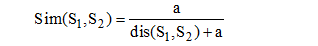 |
其中, S1和S2分别表示两个义原, dis(S1, S2)则表示义原和在同一棵义原层次树中的路径长度, 若在不同的两棵义原层次树时, 则路径长度取较大参数值; a是一个可调的参数。
李峰等[14]的改进计算公式为:
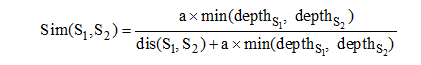 |
不难看出, 在公式(1)的基础上, 公式(2)增加了一个层次树的深度 
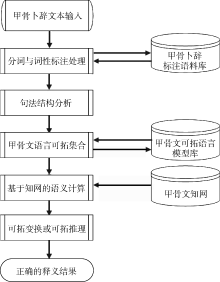
甲骨文卜辞释义问题的可拓处理流程如图1所示。首先将甲骨文语言进行可拓模型转换, 用基元信息构建ESGS中的问题库、可拓策略库和可拓变换库。然后构建基于知网体系的甲骨文知网基础数据库, 最后考虑具体释义过程中语义歧义矛盾问题ESGS的成功率和效率问题。
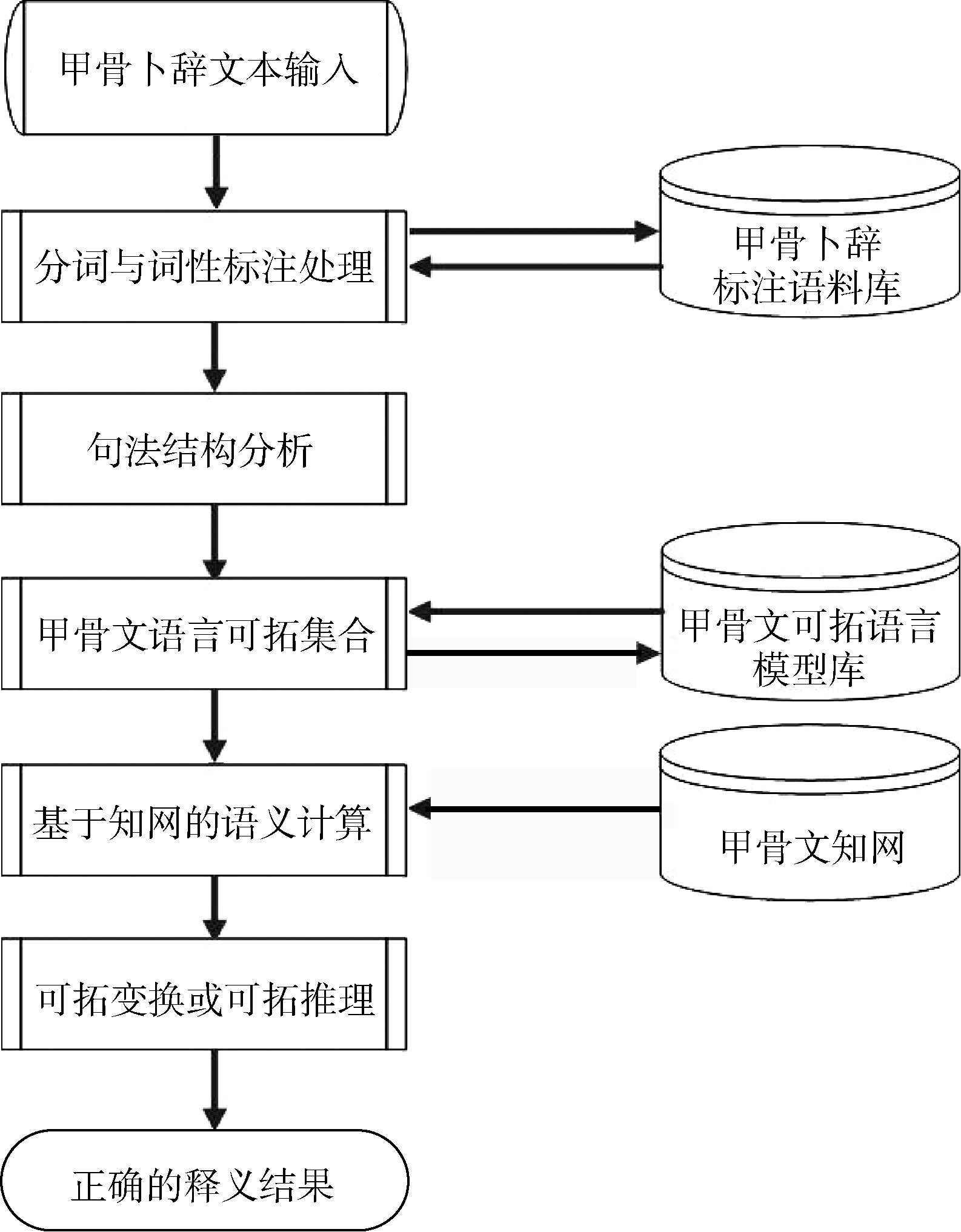 | 图1 基于知网的甲骨卜辞释义问题可拓处理流程 |
(1) 提取物元模型的甲骨文语言句式一般形式
句子具有主谓宾标准结构, 例如: “ 王入于商” , 主语: 王(商王); 谓语: 入(进入); 宾语: 商(商地)。宾语中包含“ 进入” 特征项c及其量值v商。表示为物元:
M=(王, 入, 商)
(2) 提取事元模型的甲骨文语言句式一般形式
句子具有主谓宾标准结构且谓语中心词为动词, 同时可包含时间、地点等信息。例如, “ 在正月王来征人方” (《甲骨文合集》 36484), 谓语中心词: 征(事I, 释义为征伐); 施动对象: 王(商王); 支配对象: 人方(名为“ 人方” 的方国); 时间: 正月。表示为事元:

(3) 提取关系元模型的甲骨文语言句式一般形式
句子描述两个或两个以上物主且包含关系词(基于知网)或近义词, 则可以用关系元表示。例如, “ 妇好入五十” , 可得关系元:

(4) 复合句
甲骨卜辞中复合句的比重较大。笔者将复合句先分解出简单句, 然后按简单句提取相应基元, 组合成某一形式的复合元。例如, “ 庚午卜, 内, 贞: 王作邑, 帝若” 。先分解其句法得: “ 庚午卜内贞” 和“ 王作邑” 和“ 帝若” , 然后分别建立其基元模型。具体如:



(5) 卜辞问句式处理
以上考虑的都是命题句或有谓语中心词的句子, 而甲骨卜辞中占卜类的卜辞占绝大多数, 而且以问句形式出现, 建立基元之后需要一种标志表明这个句子获得的知识有待求证(即甲骨卜辞中的命辞)。在此引进提问式可拓逻辑, 它由标志符“ ?-” , 不完全信息的物元、事元、关系元或者复合元和提问项组成, 其中提问项用符号“ -” 表示, 例如“ 今日雨?” 基元表示为:

而从甲骨卜辞语料的模型库中搜索到的匹配模型, 如:

地点还有如西边、北边、南边等。从甲骨卜辞的形式上来讲, 完整的卜辞具有前辞(也叫叙辞, 指占卜日期和贞人)、贞辞(或问辞, 指贞问的内容)、占辞(指商王看了卜兆作出的判断)和验辞(事后验证的结果)。完整形式的卜辞只是少数, 绝大多数是不完整的, 这也是甲骨文的重要特征, 在处理起来需要更多的灵活机制。
建立可拓模型后, 可对甲骨卜辞句子进行分词、词性标注、句法分析等处理, 判断该句子适合建立何种可拓模型, 再结合其可拓性到甲骨文对应的知网知识库去拓展建立可拓模型。
对实验室已经整理的甲骨文资料信息进行合理选材, 即构建课题研究的甲骨文语料库语料; 基于知网体系的甲骨文基本语义词典进行甲骨文知网的构建, 同时也是对甲骨文资料进行一定规模的语料标注; 进行基于可拓模型的建模并展开相关研究。
甲骨文知网的构建具体工作如下:
(1) 选取科学发掘的各种甲骨文原始资料作为语料库内容, 主要整理甲骨文的已释字和未释字信息, 并进行统一的编码, 给出每个甲骨字的唯一ID。目前已完成6 199个甲骨字信息的编码。
(2) 建立甲骨文的基本语义知识词典。词典样式参考知网的描述体系, 完成语料中涉及的甲骨字所对应的DEF和RMK记录。其中已整理甲骨字300多个, 具体对应记录1 400多条。
(3) 建立隶定字与知网的映射表。把每个隶定字与知网中意思相同的记录建立一个映射关系, 并且把这个隶定字的ID记录到知网记录的“ RMK” 项中。针对甲骨文已释字、隶定字和未释字三种情况的操作界面分别如图2-图4所示。
 | 图2 已释甲骨字“  ” (日)的4个义项操作 ” (日)的4个义项操作 |
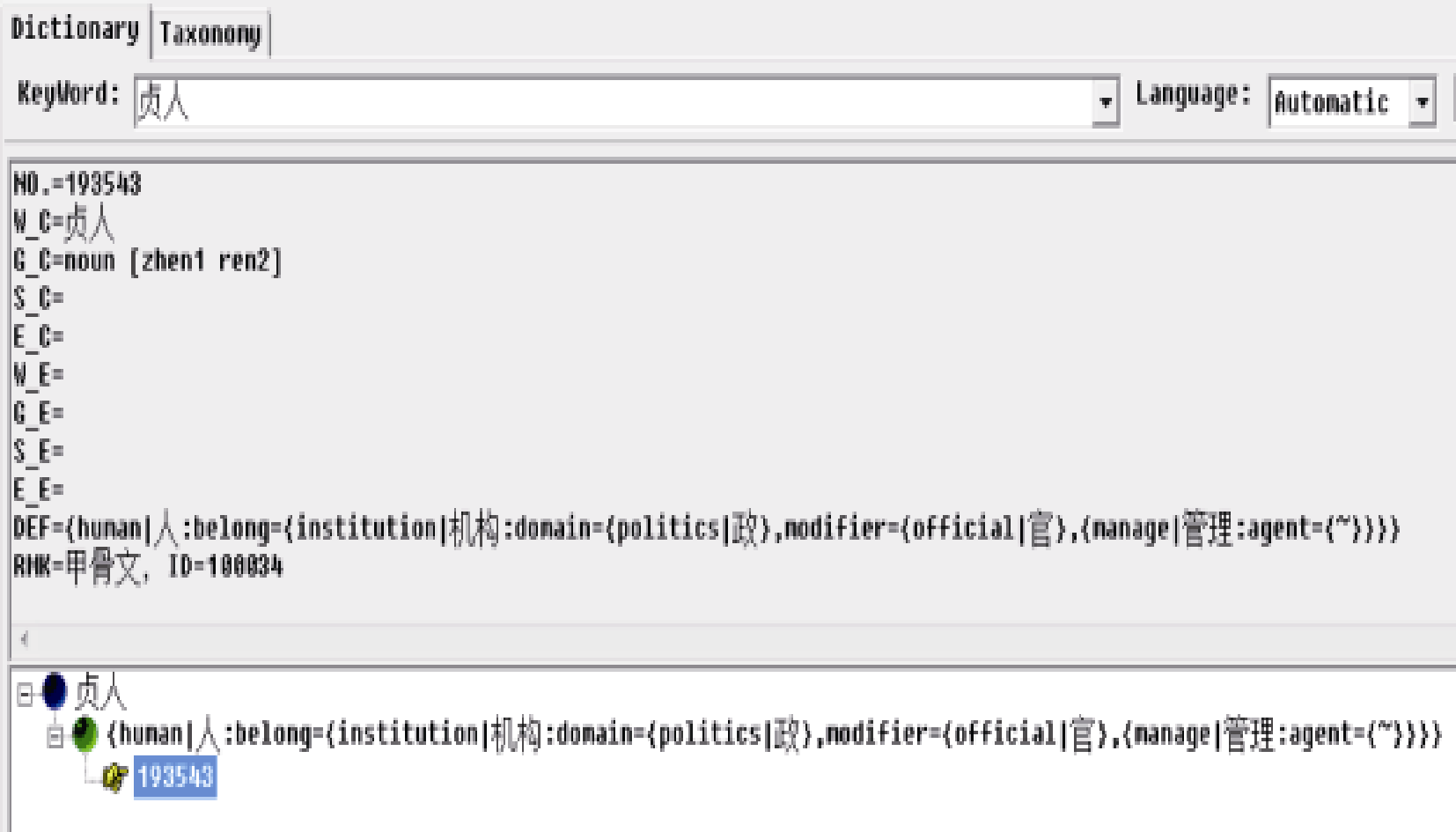 | 图3 隶定甲骨字“  ” (隶定为: “ ” (隶定为: “  ” )的操作 ” )的操作 |
 | 图4 未释甲骨字“  ” 的操作 ” 的操作 |
甲骨卜辞的分词采用基于词典句法规则和句法分析相结合的方法[15]。在分词和词性标注处理的结果上, 进行句法结构分析, 针对可拓模型的特点, 主要做了以下工作: 句子主谓宾定状补成分确定, 物主中心词、谓语中心词和关系词的确定与扩展等。
甲骨文属早期汉字, 而早期汉字特点之一是“ 异字同形” , 当然甲骨文中最为常见的也包括“ 同字异形” , 即常说的异体字或异形体, 这些情况都会使甲骨文释义遇到障碍, 也为甲骨卜辞释读带来困难。虽然上述情况在甲骨文中普遍存在, 但随着甲骨学研究的不断深入, 甲骨卜辞的原文转换成对应的释文工作已经有了一定成效, 给甲骨文信息处理工作提供了方便。虽然如此, 但人为操作难免会有疏漏, 在收集整理甲骨卜辞数据库时就会面临诸多问题。如《甲骨文合集》5445正(H5445正)与《甲骨文合集》14226(H14226)中原文释文对比, 如表1所示:
| 表1 甲骨卜辞的原文释文 |
从表1不难看出 
另一种矛盾问题如同古汉语一样, 甲骨卜辞中的甲骨字可识别出对应的现代汉字, 但对应的白话文解释, 即甲骨卜辞的翻译会因多义而产生矛盾, 如图2中的“ 日” 字, 这种情况更是考察可拓策略生成系统的准确性。
基于此, 笔者所采取的解决方案是建立甲骨文知网和可拓方法相结合, 利用知网的词汇语义相似度计算和知识库应用来解决甲骨卜辞释义的矛盾问题。
以甲骨字“ 
以图2的知网记录形式将甲骨字信息进行整合, 即将不同义原的义项存储在一个关系表中, 如表2所示:
| 表2 义原存储表结构 |
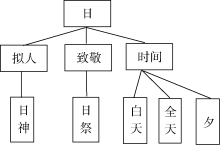
对于义项“ 日” 的描述可以看出, 在知网的知识体系中, 每个义项都是由义原进行描述, 而义项的相似性又可以根据义原的相似性判定。在知网的知识体系中, 根据上下位关系可以构建出义原层次关系树状图。“ 日” 字的义原层次图如图5所示。
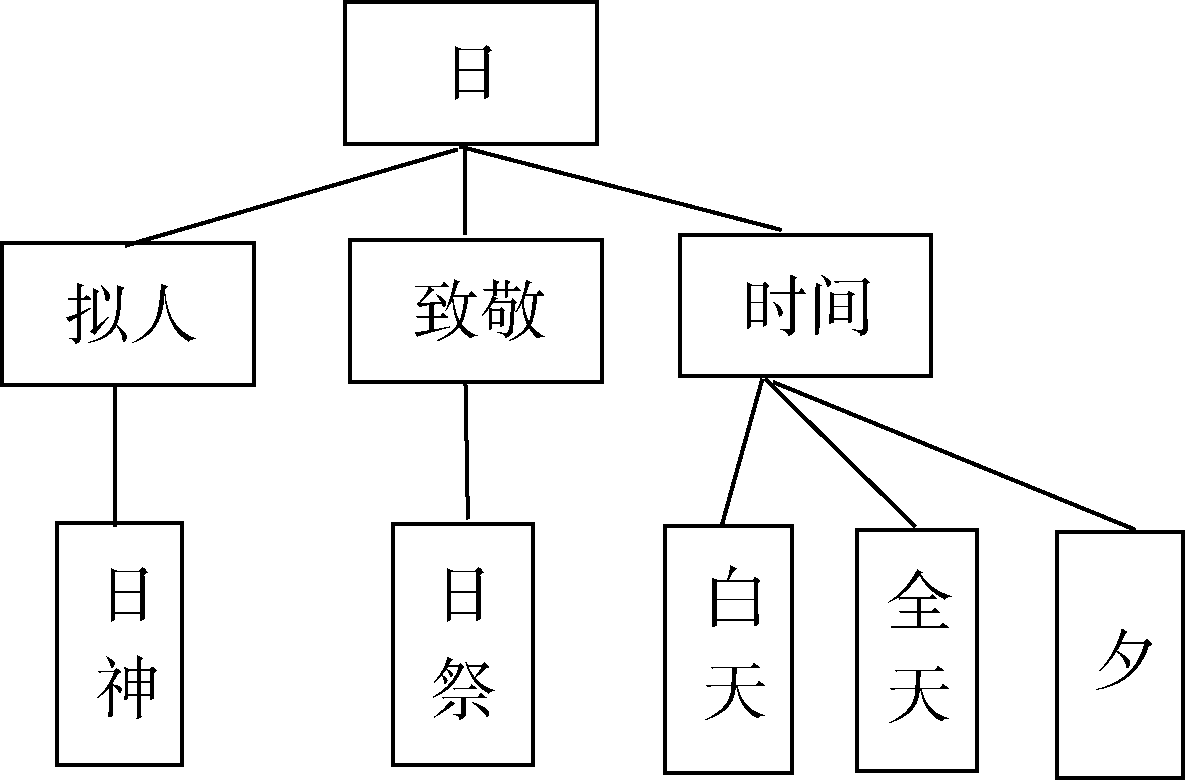 | 图5 “ 日” 字的义原层次树 |
义原之间的距离与其在层次树对应节点之间的最短路径边数有关, 据此, 由公式(1)可计算出义原间的相似度。通过语义相似度计算比较后, 将会提升系统对甲骨卜辞语义理解的能力。
查询含有“ 日” 字的甲骨片, 得到甲骨卜辞释文如下:
(1) 丁卯卜, 今日雨, 夕雨?(《甲骨文合集》33 871)
(2) 贞今日夕侑于祖乙。(《甲骨文合集》1 653)
针对句(1)和句(2)进行分词, 对有歧义的词汇“ 日” 进行义原相似度计算。
通过义原“ 今” 和“ 日神” 等的语义距离的计算以及与“ 夕” 等语义距离的计算比较, 结果如表3所示。很容易得到句(1)和句(2)的“ 日” 都应解释为时间概念, 而进一步拓展分析后不难发现, 句(1)中的“ 日” 解释为“ 白天” 合理些, 因为和后面的“ 夕” 对应; 而句(2)中的“ 日” 字解释为“ 全天” 更合适, 即包含“ 夕” 的含义, 之间属于蕴含关系(蕴含系策略)。
| 表3 义原相似度结果 |
为更好地验证本文方法的效果, 笔者进行了量化的对比实验。从已有的186片甲骨拓片中提取了500条表达清楚的完整卜辞作为实验样本。经过预处理后, 每条卜辞都有正确的释文和释义。分别采用基于知网策略的处理方法和本文方法(基于甲骨文知网的可拓方法), 从50个(涉及136条甲骨文知网记录)和100个(涉及278条知网记录)不同的带有多义特征的词条组成两组数据进行测试, 其实验结果如表4所示。
| 表4 甲骨卜辞释义的正确性对比实验结果 |
结果显示, 基于知网的策略和本文方法在甲骨卜辞的歧义处理方面的准确率均达到90%左右, 且本文方法较之基于知网的策略有更高的准确率, 但是随着测试数据量的增大, 两者都要受到甲骨文知网规模和测试数据的影响, 且F值随着测试数据量增加而降低。主要原因是甲骨文知网信息集、可拓信息集和可拓变换策略等内容的不完善, 今后要进一步完善和提高甲骨文基础信息。
以甲骨卜辞的一残辞拟补为例分析如下:
查询甲骨片号H14898的甲骨片信息。根据可拓变换的“ 一征多物” 和“ 一物多征” 思想, 综合处理, 可得到图6中“ 示” 所对应的相关基元信息集。
 | 图6 《甲骨文合集》H14898的原文与释文 |
利用相关网策略, 可得基元“ 王” 的相关网基元可拓全集信息, 如表5所示:
| 表5 基元可拓全集信息 |
从每一条卜辞得出的关于物元“ 王” 的相关祭祀信息出发, 结合甲骨文知网对“ 示” 的概念描述和“ 王” 可拓基元信息库中特征“ 祭祀用牲” 量值对比, 可推出“ 大示” 与“ 小示” 之间的关系(蕴含系策略), 即可拓推出论域或结论: “ 大示” 或“ 上示” 的祭祀用牲方面规格要大于“ 小示” 或“ 下示” 。
再从甲骨卜辞的文字使用频率角度出发(在7万多片甲骨卜辞中“ 小示” 出现次数为23次, 而“ 下示” 为5次), 则该片甲骨的残缺字为“ 小” 的可能性更大些。
对于残辞拟补的实验, 以本文方法和基于统计的方法进行实验对比。具体测试的目标实验样本采用专家已经正确处理的残辞甲骨片123片, 实验总共用于统计的甲骨文拓片为72 151片, 可统计的甲骨拓片的文本字数共计约75万。其中基于统计的方法根据残辞中残字或缺失甲骨字的上下文进行统计, 以最大模式匹配方法为依据。具体实验对比结果如表6所示:
| 表6 甲骨卜辞残辞拟补的正确性对比实验结果 |
在现存的甲骨拓片中, 残辞所占比重很大, 如何更好地处理残辞甲骨片是甲骨文信息处理中一项非常重要的基础工作。表6结果表明, 目前常用的处理甲骨文残辞的方法是基于上下文统计, 但是该方法效果并不理想, 其准确率只有30.26%。其原因与所测试的样本有关, 但可以说明仅仅简单地依靠统计来进行残辞的语义推导是行不通的。而单纯人工处理的方法能保证准确率, 但是需要高度依赖甲骨文专家, 在应对大量的残辞处理时是不切实际的。本文方法利用计算机改善传统的残辞拟补方法, 能极大地提高准确率(75.65%), 便于辅助甲骨文专家做后期研究处理。这是因为将甲骨卜辞的语言模型进行了可拓处理, 同时建立了甲骨文知网, 并利用可拓变换策略。表6中的F值虽然有了不少改变, 但是如果测试样本发生变化或者测试数据增大, 那么本文方法的实验效果将会受到影响, 尤其是应对更多的未释甲骨字的时候。故后期研究考虑在可拓变换的策略上进行改善, 即将专家处理的经验转变为更合适的规则处理, 合理使用这些规则将会改善实验效果。
针对甲骨卜辞释义中的甲骨字歧义问题和甲骨文语义推导问题, 提出了基于知网和可拓策略生成系统相结合的研究方法。从理论和实际应用两方面例证分析了甲骨卜辞释义的可拓学应用。下一步将在系统建模的程序质量和材料数据的完善上做重点研究, 同时和相关的甲骨学专家积极沟通, 探讨在甲骨文考释或甲骨拓片缀合这些重要的基础应用领域的可拓方法的具体应用。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|