{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种引入间接信任关系的改进协同过滤推荐算法
[吴应良, 姚怀栋 , 李成安]
, 李成安]
, 李成安]
|
|


作者贡献声明:吴应良: 提出研究思路, 设计研究方案, 论文最终版本修订; 姚怀栋, 李成安: 进行实验; 姚怀栋: 采集、清洗和分析数据; 吴应良, 姚怀栋, 李成安: 论文起草。
目的 解决传统协同过滤推荐算法中由于数据稀疏性等原因而导致的推荐质量恶化问题, 需要对协同过滤推荐算法的推荐机制进行改进优化。方法 利用社会网络分析中的凝聚子群分析技术挖掘隐含在信任网络中的间接信任关系, 与直接信任加权融合成综合信任度, 并将其融入用户相似度计算中。结果 实验结果显示, 信任关系中间接信任不容忽视, 当间接信任以35%的比例与直接信任融合时, 推荐效果比仅引入直接信任关系有进一步提升。【局限】在考虑信任网络中的间接信任时, 忽略了用户之间多中介节点的间接信任情况对推荐精度的影响。结论 引入间接信任关系的软集成可以提高协同过滤算法的推荐准确性。
[Objective] In traditional collaborative filtering algorithms, the issues such as data sparsity may make the quality of recommendation worse. This paper attempts to solve it by optimizing the recommendation mechanisms.[Methods] This paper uses cohesive subgroup analysis techniques to identify indirect trust relationship in trust networks, and combines with direct trust relationship to generate an integrated trust, which is used to calculate the user similarity in the new collaborative filtering recommendation algorithm.[Results] Experimental results show that the ultimate trust combining 35% direct and 65% indirect relationship can improve the accuracy of CF algorithms, and compared with only using direct trust relationship, the indirect trust relationship could not be ignored. [Limitations] When considering the indirect trust in the trust network, this paper ignores the impact of more intermediate nodes between two users.[Conclusions] Soft integration of indirect trust relationship can improve the recommendation accuracy of collaborative filtering algorithms.
随着社会信息化进程的快速发展, 信息量呈现“ 爆炸式增长” , 信息管理与服务正面临“ 信息日益丰富, 有用信息的采集也日益困难” 、“ 信息过载而知识贫乏(Information-Overload but Knowledge-Poor)” [1]等困境, 即人们对信息的处理和接受能力有限, 获取自己想要的信息或知识的难度与成本在日益增加, 信息和知识的合理利用严重受阻。推荐作为一种信息推送(Push)模式的重要方法在一定程度上弥补了这一缺口, 其以用户为中心, 通过分析用户数据, 挖掘网络行为特征、兴趣爱好及环境影响, 进而预测用户潜在信息需求, 主动为用户推送可能需要但又无法清楚表达的信息, 从而为用户推送更有针对性的信息, 实现按需定制的社会化网络信息服务[2]。
在各种推荐算法中, 协同过滤算法是一种基于内容的推荐算法, 对难以处理(如图片、音频、视频等)或难以分析(如服务质量、个人品味)的内容推荐效果比较突出, 既摆脱了对用户或商品本身信息的依赖性, 又提高了推荐的准确性[3]。然而, 当该算法面临用户对物品评价数据比较稀疏的情况时, 所得用户相似度的真实可靠性并不高, 进而在一定程度上影响最终推荐质量。所以, 如何有效地解决这一数据稀疏性[4]问题, 改进推荐系统的服务质量显得尤为重要。
社交网络服务的发展势态下, 社交信息日益丰富, 当以用户为顶点建立起社交网络时, 存在一些社交属性对改善传统协同过滤算法中的相似度计算质量提供了信息基础[5]。通过分析其网络结构及网络顶点(成员)的行为过程, 有助于发现用户间信任关系, 这为基于用户的协同过滤算法中相似邻居的形成机制的刻画与有机结合提供一种新的可能性[6], 从而为研究电子商务中用户社会化关联关系与行为特征提供一种重要的方法。本文尝试采用社会网络分析中的凝聚子群分析技术挖掘信任数据中隐含的用户间接信任关系, 与直接信任关系融合并将其引入到传统的用户相似度计算中, 解决由于数据稀疏性等原因而导致的推荐质量恶化问题, 进而实现一个实时、准确、高扩展性的推荐系统。
协同过滤推荐(Collaborative Filtering, CF)在推荐领域有着重要的作用, 目前基于社会网络的协同过滤算法已有部分研究成果:
张莉等[7]提出使用社会网络关键用户对CF进行性能的提升, 其中的关键用户是指通过网络节点的度识别信息传播过程中起重大作用的用户。该算法改变了推荐过程中的目标用户最近邻集合的选取方法, 依据关键用户的高推荐价值, 找出其邻居集, 提高了推荐的效果; 缺陷在于其考虑到关键用户对整个推荐系统的被接受程度, 而并未考虑其他用户对关键用户的接受程度和信任程度, 而且对于不存在关键用户最近邻的目标用户并不提供推荐。俞琰等[8]也提出结合社会网络, 找到用户之间的信任关系和兴趣改进传统的推荐算法, 利用用户兴趣和信任关系为目标用户更好地匹配邻居, 从而在一定程度上缓解传统CF存在的稀疏性问题和冷启动问题; 然而其不足之处在于信任关系中并没有提及间接关系和兴趣, 也没有给出具体的信任度传递规则。金亚亚等[9]阐述了对信任度的改进, 计算用户信任度时重点考虑用户的直接信任关系以及该用户在整个系统中被接受或是被信任程度, 对这两者进行线性加权求和得到新的信任度, 另外也重新定义了新的相似度计算公式, 在一定程度提高了推荐效果; 但仍存在缺点, 由于信任度必须包含直接和间接两种形式的信任度, 间接信任度指跨用户可达的最佳路径[10], 而在计算信任度时使用的却是用户在系统中的被信任程度, 而不是寻找对目标用户跨用户可达的间接信任度, 因此信任度计算方法并不准确。此外, 改进相似度计算公式也存在不合理之处, 当处理较稀疏的用户信任关系和用户项目评分矩阵数据时, 其信任度值和相似度值都会很小, 其结果不理想, 甚至远不如传统CF算法, 并没有在数据稀疏性问题上得到很好的改善。Zhou等[11]考虑在社会网络结构上进行资源分配的推荐算法; Pham等[12]通过限定在某社区内寻找目标用户的最近邻, 并在计算相似度时加入社区中的关系属性; Mao等[13]验证了社会网络用户的判断能力对CF推荐效果的影响。然而, 上述研究没有考虑到在社会网络节点之间存在的重要属性— — 信任关系, 特别是没有将社区的结构中既清晰反映又容易提取得到的信任关系融入相似度计算中。
通过深入研究发现, 一个好的协同过滤推荐系统从本质上, 既要关注项目间的相似性又不能忽略用户之间行为的相似性, 而传统的推荐过程中没有明确区分最近邻用户的推荐能力, 从而存在一定的恶意推荐行为[14]。研究显示, 用户趋向于接受来自信任用户的推荐[15, 16, 17], 而信任关系的发现通常离不开社会网络分析的应用, 该方法中的子群分析在寻找用户的直接和间接关系时, 能够提供便利的获取途径。因此本文提出基于社会网络分析的协同过滤推荐算法, 利用网络中存在的信任关系健壮原先的推荐技术, 新算法的核心是利用用户间邻接矩阵得到直接信任关系, 进一步应用凝聚子群分析方法, 根据成员间的可达性和捷径距离, 找出子群成员得到间接信任关系, 摆脱单纯依赖直接信任关系, 形成用户综合信任网络, 并融入到协同过滤算法中, 研究直接和间接信任关系对算法推荐准确性的影响。
在实际生活中, 用户接受推荐的前提通常建立在信任关系的基础上, 信任因素是推荐成功与否的重要参考因素。将该实际生活现象映射到推荐应用中, 考虑用户信任关系, 结合社会网络分析的“ 子群分析” 得到用户的信任关系图; 将用户间的直接和间接信任关系线性融入用户相似度计算, 得到新的综合信任度; 将综合信任度按照一定的权重融入相似度计算得到最终用户相似性, 使最近邻的构建更为准确; 由最近邻对项目的评分推导出目标项目的预测评分, 由此对协同过滤算法进行合理的改进。考虑到用户关系有效获取途径, 经改进后的算法可适用于具备评分系统的社会化电子商务网站。
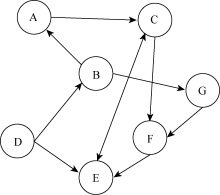
数据预处理的目的是为了确定用户信任度, 因此需要对用户信任度矩阵进行处理。信任度是指一个用户对另一个用户的信任程度, 同时又可分为直接和间接两种[5]。用户间的信任关系如图1所示, 其中节点A-G表示用户, 节点间存在的有向边表示用户间存在信任关系。
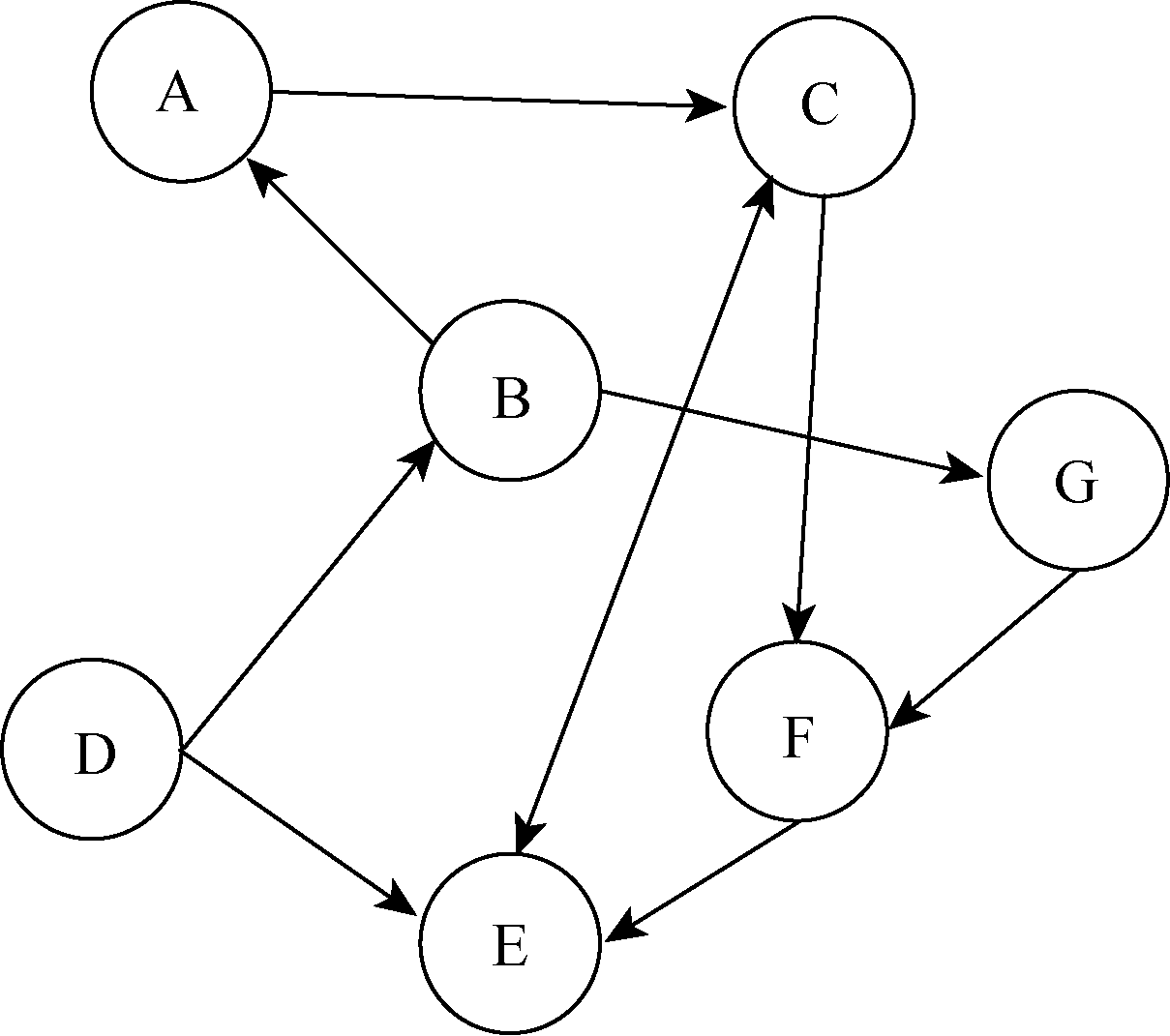 | 图1 用户之间的信任关系图 |
(1) 直接信任度
直接信任度DT(u, v)表示存在直接联系的用户u和v的信任度。如图1所示, B与A, A与C之间的信任度即为直接信任度。本文的直接信任度由用户信任数据(Trust)转换得到, 构成单模网络用户与用户间的有向信任邻接矩阵[10], 如表1所示。其中, u={u1, u2, u3, u4, u5}表示用户节点集合, 数值0或1反映了用户间是否存在直接信任关系, 如u1对u2存在直接信任关系, 即为DT (u1, u2)=1, 而u2对u1并不存在信任关系, DT(u2, u1)=0。
| 表1 有向网络的邻接矩阵 |
(2) 间接信任度
间接信任度IDT(u, v)表示不存在直接关系的用户u和用户v之间的信任度。根据表1的直接信任矩阵, 建立在可达性基础上的凝聚子群, 考虑到点与点之间的距离。根据人与人之间的信任度传递的社会特征, 即太长的传递路径并没有实际意义, 因此本文仅考虑目标节点与源节点之间只存在一个中介节点的情况, 也就是用户的2步可达子群网络中的间接信任度。由此, 在UCINET中采用凝聚子群分析操作(Subgroups), 设定临界值为2作为凝聚子群成员之间距离的最大值, 引出间接信任网络的2-派系(2-Cliques), 构成不同的子群。各子群反映的是2步可达的小团体, 进一步在矩阵中将具有2步可达的各团体中成员间的数据IDT(u, v)标为1, 独立成员或是不同派系成员的数据则标为0, 从而构成间接信任度矩阵[10], 如公式(1)所示:

(3) 综合信任度
根据用户之间的直接信任度DT(u, v), 形成直接信任度矩阵, 根据矩阵绘制出用户间的信任关系图, 利用社会网络分析中的凝聚子群分析方法, 在基于信任度传播的网络中, 找出各个小团体中目标用户的捷径距离和2步可达网络, 计算得出用户间的间接信任度IDT(u, v)。利用线性函数[9]将直接和间接信任度矩阵加权融合, 如公式(2)所示, 计算出用户u对用户v的综合信任度TotalT(u, v)。
TotalT(u, v)=mDT(u, v)+(1-m)IDT(u, v)m∈ [0, 1] (2)
对最终信任度TotalT(u, v)进行标准化, 使其服从均值为0, 方差为1的分布。此时矩阵中的数据取值范围为[-1, 1], 为了更好地理解用户间的信任关系, 需要将取值范围从[-1, 1]变化到[0, 1], 这时采用极差变换公式进行变换[17], 得到最终信任度UT(u, v), 如公式(3)所示, 其中m表示用户数量。
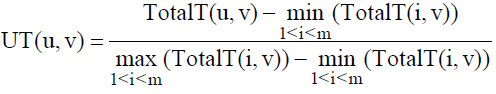
本文将综合信任度融入用户相似度计算中, 在传统CF算法的用户相似度计算基础上进行改进, 将公式(3)得到的最终信任度UT(u, v)与余弦相似度sim(u, v)加权融合, 得到最终用户相似度sim’ (u, v), 如公式(4)所示。由于本算法的最终用户相似度是在传统基础上融入信任度计算的, 所以p取值通常不超过0.5。
sim𠈙 (u, v)=p× UT(u, v)+(1-p)× sim(u, v) (4)
对用户相似性进行计算后, 按照大小进行升序排序, 选择排在前面的K个用户作为目标用户的最近邻, 再根据最近邻的相关评分信息预测指定用户对指定项目的评分, 这里采用中心加权计算[9], 如公式(5)所示。其中, Rv, c表示用户u的最近邻用户v对目标项目c的评分, 和分别表示用户v和u对所有项目平均评分。
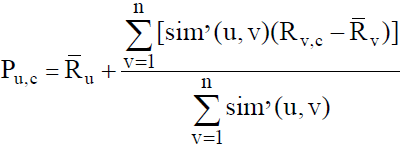
根据目标用户对目标项目集的预测评分结果, 对所有的预测评分进行降序排序, 选择最靠前的K(K由用户或系统指定)个项目推荐给目标用户。而对推荐系统效果的衡量与评价, 则借助精度评价。对于建立在用户项目评分的协同过滤推荐算法, 一种对精度评价指标直观的理解就是计算预测评分与用户实际评分的差距, 这种精度指标有很多, 最经典也最常用的是平均绝对误差(Mean Absolute Error, MAE)[9], 其计算方法如公式(6)所示。其中, {p1, p2, p3, • • • pi}表示用户的预测评分集, {q1, q2, • • • , qi}表示用户的实际评分集, N表示测试集的大小, MAE越小说明推荐精度越高。
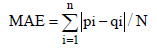
实验数据采用Epinions真实数据集(http: //www.epinions.com.)对本文提出的改进算法进行验证。Epinions是一个在线服务网站, 用户可在网站上进行一些信息共享操作, 如分享商品评分及购物心情评论等。此外, 还可将其他用户加入到个人的信任列表中, 建立自己的朋友圈。该数据集包含用户对项目的评分信息和用户之间的直接信任关系信息, 考虑到此数据集中信任关系的稀疏性, 选取该数据集中的一个相对稠密的子集进行实验。经整理后数据子集包含560个用户对340个项目的3 000个评分, 此外, 该数据集还包含用户间信任关系信息, 列出了存在直接信任关系的用户ID。实验过程采用Matlab编程, 实现上述算法并运行测试, 最后统计出相应的MAE。
(1) 实验一
①根据上文可知, 协同过滤算法最关键的步骤在于K最近邻的发现, 而K最近邻数的形成主要依据相似度值的排序。本文在传统基于用户的协同过滤推荐算法(UCF)基础上, 将信任关系融合入UCF的相似度计算过程。采用对信任度与相似度之间进行加权的方式(权值为p), 计算改进后的相似度sim’ (u, v)。因此, 需要设计实验观察权值p是否影响K最近邻数的形成。
②在相似度计算中融入信任度, 而信任度中引入常被忽视的间接信任关系, 对于信任度的计算过程则采用直接信任度与间接信任度加权的方式(权值为m)计算最终信任度UT(u, v)。所以, 还需要观察权值m变化对MAE的影响, 并选择使MAE最小的m值作为后续实验的最佳m值。
(2) 实验二
在选定最佳m值情况下, 寻找使MAE值最小的最佳p值。由于p值一般不能超过0.5, 但为更好地比较说明和最终确定p值, 将p值取值延长至1, 进一步观察MAE的变化情况。
(3) 实验三
选定实验一和实验二确定的最佳权值p和m, 计算不同最近邻数K下的MAE, 并分为以下三种情况与UCF进行对比:
①只引入直接信任度时, 即当m=1时, 与UCF进行比较。
②只引入间接信任度时, 即当m=0时, 与UCF进行比较。
③同时引入直接和间接信任度时, 即当取最佳m值时, 与UCF进行比较。
根据实验一的描述, 将计算的相似度结果整理如表2所示:
| 表2 不同的权值p与权值m对MAE的影响 |
| 表2(续表) 不同的权值p与权值m对MAE的影响 |
(1) 在权值m一定的情况下, 横向观察表2中的数据。用户最近邻居数K以步伐为4进行增长, 当 K< 20时, 随着m值的增加, MAE值逐步降低, 而当K=20开始时, MAE值不再变化, 即K=24的曲线与K=20的曲线重合, 此时说明无论p取何值, MAE都趋于平稳, 因此p值并不影响K最近邻居数的形成。更进一步, 当K=20时, MAE达到最低值并趋于稳定, 取得较好的推荐效果。
(2) 表2的数据中, 随着m值的增长, MAE大致呈现先降低后逐步上升的态势, 这说明单一信任度(直接或间接)占比过高时, 皆不能使MAE最优; 而当权值m=0.65时, MAE达到最低, 此时达到最好的预测效果, 因此本实验的最佳m值取0.65。
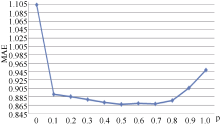
根据实验二的描述, 选定实验一得出的最佳m值和K值, 即m=0.65, K=20, 观察p值变化对MAE的影响, 如图2所示:
 | 图2 p值对MAE的影响效果(m=0.65, K=20) |
随着p从0至1增长, MAE呈现先下降后上升的变化, 当p=0.5时达到最小值。对于p值的极端情况, 当p=0时, 意味着最终相似度与传统的UCF相同, 没有考虑综合信任度; 当p=1时, 表示完全使用综合信任度作为用户间的相似度, 平均误差与UCF相比, 提高了14.08%; 当p=0.5时, 平均误差与UCF相比, 提高了21.44%。然而, 在现实推荐情况中, p=1的极端情况并不常出现, 因为一般的推荐需在用户对项目的相似度高的情况下进行, 而并非完全依赖用户的信任关系。UCF算法(即p=0时)计算出的MAE较高的原因可能是由于用户项目评分数据稀疏, 造成在计算与目标用户相似度时可供利用的用户不多, 没有足够的最近邻预测评分。因此, 融合信任度后的相似度计算, 相对较好地缓解了稀疏性问题造成的影响, 也能表现出更好的推荐效果。
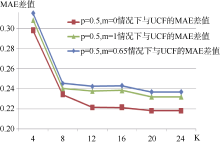
根据实验三的描述, 对三种情况计算得出的MAE值与UCF进行差值计算, 差值越大, 则表示精度提升程度越高, 如图3所示:
 | 图3 三种情况下与UCF的MAE差值 |
同时引入直接和间接两种信任度时(p=0.5, m=0.65), 差值最大, 位于最上方; 只引入直接信任度时(p=0.5, m=1), 仅次之; 而单纯依赖间接信任度的情况, 与前两者差距逐步拉开。由此揭示了在信任关系对推荐准确度的影响过程中, 直接信任的作用大于间接信任。此外, 融合两种信任的效果也明显比单纯依赖某一种信任的计算效果更佳, 这与现实生活中的情况也是相符合的。
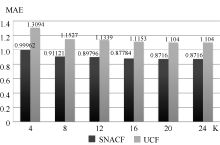
在实验的最后, 使用本文提出的融合直接和间接社会网络信任关系的协同过滤算法(SNACF)与传统基于用户的协同过滤算法(UCF)进行一次直观的对比, 如图4所示:
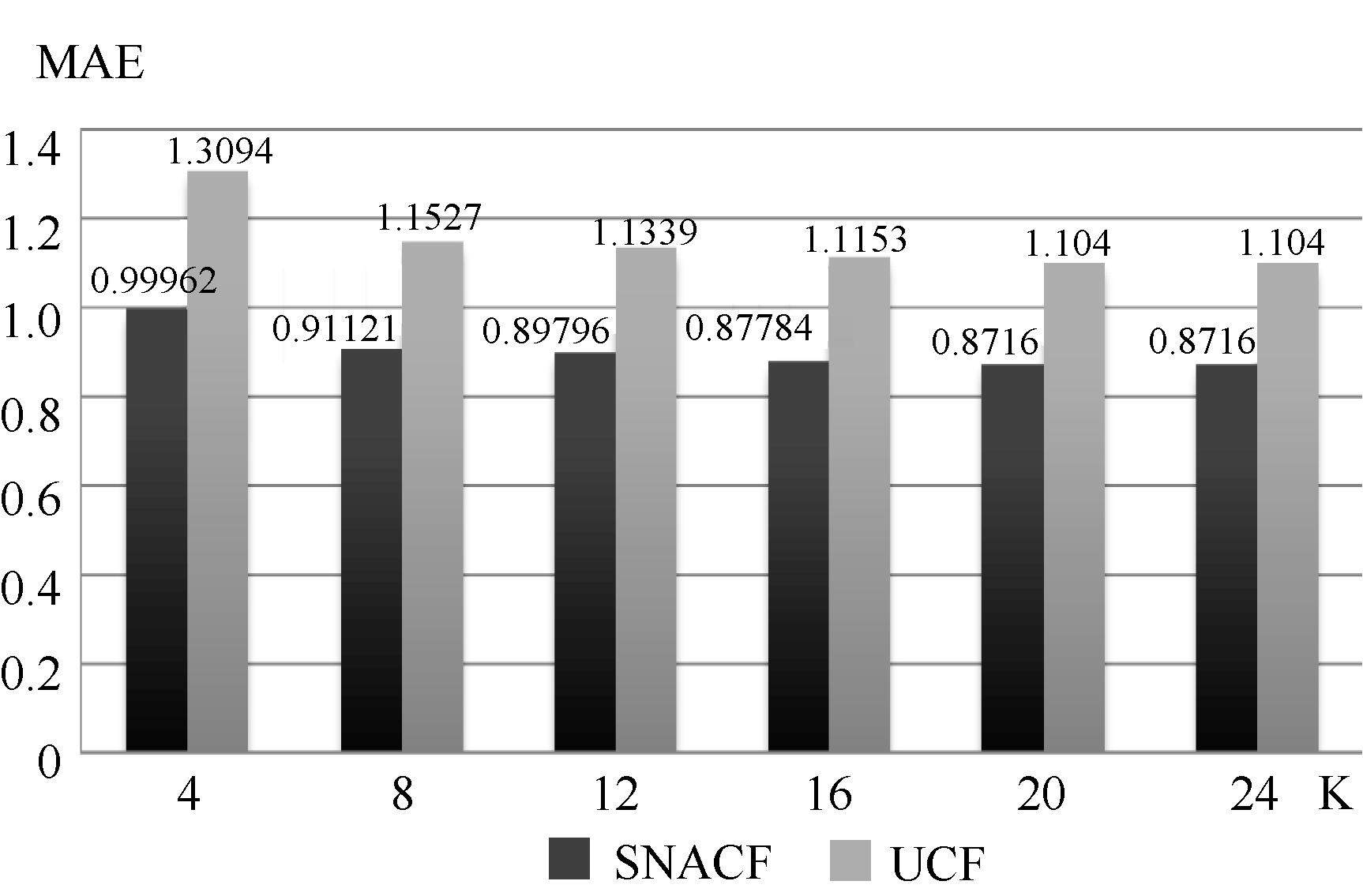 | 图4 两种算法在不同最近邻居数K下的MAE比较 |
改进后的算法在MAE值上有明显的下降, 表示在相似度计算中融入信任关系后推荐效果的准确度有明显的提高。映射到现实情况, 相对于根据用户的评分寻找相似邻居, 融入信任关系, 推荐过程更值得信任。在根据用户标识建立起的信任关系的数据中, 直接信任关系可从数据中直接判别并对推荐效果有一定的提升, 然而间接信任关系并不能轻易发现和获取, 在实验中也验证了引入间接信任关系后, 相对于单纯依靠直接信任关系带来的推荐效果有了进一步的提升, 间接信任关系对推荐精度影响效果不容忽视。
传统协同过滤推荐算法一直以来受到数据稀疏性和恶意推荐问题的困扰, 而引入信任关系是一种已被认可的行之有效的解决途径[18, 19, 20]。引入信任关系常建立在用户标识的信任数据基础上, 由此可轻易直观地获取用户直接信任关系。而信任关系的构成并不完全依赖直接信任, 还存在一种隐含于直接信任背后的关系, 即间接关系。与直接信任相比, 间接信任获取较困难, 其所具备的影响作用也常被忽视。鉴于此, 本文对传统基于用户的协同过滤算法的用户相似度计算步骤进行适当改进, 采用凝聚子群分析方法寻找用户2步可达网络, 从而引入一种包含间接信任的综合信任关系, 试图提高算法的推荐效果。利用公开数据集Epinions, 设计相关实验对算法的改进效果进行验证。结果显示, 信任关系中直接信任起到主导作用, 而间接信任的作用也不容忽视, 当间接信任以35%的比例与直接信任融合时, 推荐效果比仅引入直接信任关系有进一步的提升, 所以本文改进算法与传统协同过滤算法相比, 获得了更加优越的推荐效果, 是一种有效可行的推荐算法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|