{kind=link}
利用粒子群和模糊综合评判的模糊分类方法
[殷希红 , 乔晓东, 张运良, 李国双]
, 乔晓东, 张运良, 李国双]
, 乔晓东, 张运良, 李国双]
|
|


作者贡献声明:殷希红, 乔晓东, 张运良: 提出研究思路, 设计研究方案; 李国双: 方案实现及测试; 殷希红: 进行实验, 起草论文; 张运良, 殷希红: 论文最终版本修订。
目的 解决传统分类存在硬性划分和部分分类方法只能处理离散型数据的问题。方法 利用模糊综合评价方法实现对具有连续属性样本的模糊分类, 得到样本对于类别的软化分。划分过程中使用连续属性离散化方法对属性区间进行划分, 使用粒子群算法获取各属性的最优权重分配, 最终结果为样本对各个类别的隶属度。结果 可以有效地实现对样本类别的软化分, 并且达到较高的准确率。【局限】对于属性值过于集中的属性不易进行区间划分。结论 基于粒子群和模糊综合评判的模糊分类方法是有效可行的。
[Objective] Solve the problem of rigid division of the traditional classification and some classification methods only dealing with discrete data.[Methods] The fuzzy comprehensive evaluation method is put forward to realize the fuzzy classification for continuous attributes samples, obtaining the soft classification of samples to categories. In the process, the method of continuous attributes discretization is used to divide attribute interval, and the particle swarm optimization algorithm is used to obtain the optimal weight distribution. The final results are the membership degrees of samples to each category.[Results] This method can effectively achieve the soft division of samples. [Limitations] This method is difficult to divide the attribute whose values is too concentrated.[Conclusions] This fuzzy classification method based on particle swarm optimization and fuzzy comprehensive evaluation is effective and feasible.
分类问题是通过对已知类别样本的学习来推断未知样本的归属[1], 是数据挖掘和机器学习领域热点关注的问题。传统的分类方法基本上都是对事务的硬性划分, 首先确定要分类的类别, 然后通过对一组已知类别样本训练, 利用有监督的学习方式, 为未知样本贴上相应的标签。分类的结果非常明确, 即一个样本只能完全属于或者完全不属于某一类别。但是在实际中, 许多事务并没有明确的分类, 可能在不同属性的判定方式下属于不同的类别。因此需要对事务进行软划分, 即模糊分类。在模糊分类中, 每一个样本都以一定的概率(隶属度)从属于所有的类。本文利用模糊综合评价方法实现对事务的模糊分类, 由于事务具有多个属性, 并且每个属性对于分类的贡献情况不同, 因此在模糊综合评价的过程中引入粒子群优化算法[2]确定各个属性值在类别划分中的重要程度。但是大部分事务的属性取值是连续的, 不能从单方面确定属性对类别的隶属度, 因此引入连续属性离散化方法[3, 4], 将每一属性划分成不同的区间, 确定属性取值在不同区间时对应各个类别的一个隶属度。最后利用模糊综合评价方法确定该事务隶属于不同类别的情况。
分类技术是数据挖掘中最有应用价值的技术之一, 经典分类方法包括: 决策树分类算法、K近邻分类算法、基于关联规则的分类算法、贝叶斯分类算法、人工神经网络方法和SVM分类方法, 但是这些方法均是对事务类别的硬性划分, 不能很好地处理客观事务类别的不明确性。因此需要模糊分类方法来对事务进行软化分, 主要包括: 传递闭包法、最大树法、编网法、基于摄动的模糊方法等; 但人们更多地将模糊方法和其他分类算法结合起来, 既有与传统分类算法, 如模糊决策树、模糊关联规则挖掘等的结合, 也有与软计算在内其他方法, 如模糊神经网络等的结合[5]。王熙照等[6]针对现实世界中存在的不确定性, 提出模糊决策树算法, 采用ID3算法, 通过模糊信息熵和模糊信息增益计算来诱导出一棵模糊决策树, 并将模糊决策树和清晰决策树进行对比分析, 发现模糊决策树更适用于属性和类模糊性强、有噪音的数据。之后, 为了改善模糊决策树仅凭经验设定参数值带来的不确定性, 孙娟等[7]提出了利用粒子群算法智能设定参数值的自适应模糊决策树算法, 减少了凭经验设定参数的低性能, 采用的适应度函数综合考虑了分类准确率、扩展能力和树的规模, 增强了模糊决策算法的适用性。邹晓峰等[8]应用模糊集软化数量型属性的划分边界, 提出了模糊分类关联规则的挖掘算法, 使挖掘到的模糊分类关联规则更易于理解。崔建等[9]利用模糊C-均值聚类算法首先对数据库中的连续属性进行离散化, 在此基础上提出一种改进的模糊关联算法挖掘分类关联规则, 通过计算规则和模式之间的兼容性产生一个特征向量集合, 来构建支持向量机的分类器模型。实验结果表明, 该方法具有较好的分类效果, 但是会受到置信度阈值设置和支持度大小的影响。1990年, Takagi[10]首次综述性地讨论了神经网络与模糊逻辑的结合, 认为模糊神经网络是将模糊化概念和模糊推理引入神经元的模糊神经网络, 它结合了神经网络系统和模糊系统的长处, 在处理非线性、模糊性等问题上有很大的优越性, 在智能信息处理方面存在巨大的潜力。目前国内外对模糊神经网络的研究较多, 大部分集中于BP神经网络与模糊逻辑融合的模糊神经网络, 但是由于BP网络本身存在的一些固有缺陷, 造成融合后的网络也存在学习收敛速度慢, 容易陷入局部极小, 实时学习能力差和泛化能力有待增强等缺陷[11]。
综上所述, 模糊分类方法可以有效地实现事务的模糊划分, 使分类的结果更易于理解。并且国内外的大部分研究是将模糊方法与分类算法结合使用, 通过模糊分类解决传统分类方法在分类过程中的硬性划分问题。而本文不同于以往研究, 仅利用改进的模糊综合评价方法实现对事务的模糊分类。
模糊综合评判法[12, 13]是一种基于模糊数学的综合评判方法。该综合评判方法根据模糊数学的隶属度理论将定性评价转化为定量评价, 即利用模糊数学对受到多种因素制约的事物或对象做出一个总体的评价。首先确定由多种因素组成的模糊集合(因素集U), 再设定这些因素所能选取的评审等级, 组成评语的评判集合(评判集V), 分别求出各单一因素对各个评审等级的归属程度(模糊矩阵), 然后根据各个因素在评价目标中的权重分配, 通过计算(模糊矩阵合成), 求出评价的定量解值, 上述过程即为模糊综合评判。
模糊分类方法是利用模糊综合评价方法实现对样本类别的软划分, 首先需要对连续属性进行离散化, 实际上就是在特定的连续属性的值域范围内设定若干个离散化划分点, 将属性的值域范围划分为一些离散化区间, 最后利用不同的符号或整数值代表落在每个子区间中的属性值[14]。这个过程需要确定两个问题: 第一, 确定区间的个数, 一般是根据经验或实际问题需要确定区间个数; 第二, 确定每个区间的边界, 目前应用较多的是等间距法[15]、极大熵法[15]和等信息量区间法[16], 但这些方法均未考虑事先指定的样本所在的类别与某个属性的取值区间边界的关系, 并且也不能确定最佳的区间划分个数。为解决以上问题, 陈秉正等[3]利用极大熵法进行初始区间划分, 然后用多因素优选法对区间边界进行调整, 最后根据二阶概率统计检验和属性值的实际意义对区间进行合并。
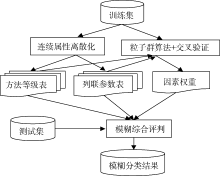
本文借鉴陈秉正等[3]提出的连续属性离散化方法, 对训练集的属性值进行离散化处理, 得到属性的区间划分, 以及“ 类-属性” 二维列联表; 评判因素的权重设置通常采用德尔菲法、层次分析法等, 但是这些方法存在一定的主观性, 不同的权重设置会影响到模糊综合评判的最终结果, 为增加权重设置的客观性及自动化程度, 利用经典的粒子群算法[2], 将属性权重作为粒子进行初始化, 将判定类别的准确率作为目标函数, 并在其中引入交叉验证的方法, 通过粒子寻优的方式, 求出达到最高平均准确率时所对应的一组属性权重; 然后输入测试集, 根据测试集中每个样本的属性值查找其所对应的属性区间, 再根据属性值所属区间查找对应的“ 类-属性” 二维列联表, 得到该属性值对应各个类别的隶属度; 最后利用各个属性的权重以及各个属性对各个类别的一组隶属度, 通过模糊综合评判的方法, 得到该样本对各个类别的隶属度, 实现对类别的模糊分类。具体的实施流程如图1所示:
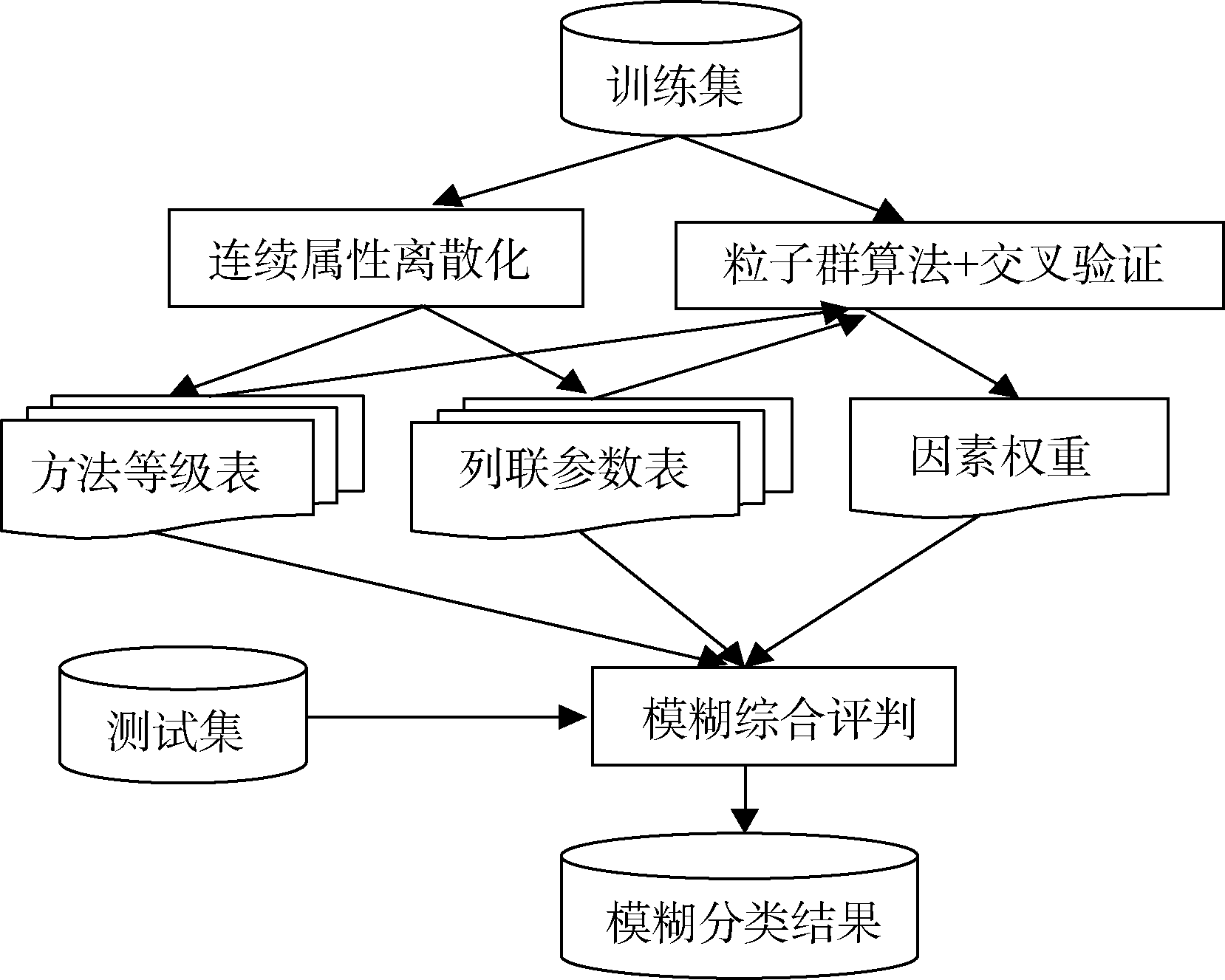 | 图1 模糊分类流程图 |
模糊分类方法的具体实施步骤如下:
(1) 确定因素集U={u1, u2, · · · , um}, 将样本的属性作为评价因素, 其中:ui(i=1, 2, · · · , m), 表示样本的第i个属性。
(2) 确定评判集V={v1, v2, · · · , vn}, 将要分类的类别作为评判集, 每个评判集对应一种类别, 其中:vj(j=1, 2, · · · , n), 表示第j种类别。
(3) 建立模糊关系矩阵
①从要处理的数据中随机抽取部分数据作为训练集, 人工确定训练集中各样本所属的类别。
②对样本的属性值进行归一化处理, 使属性的值域为[0, 1], 所以e0=0, 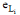
| 表1 “ 类-属性” 列联表 |
表1第i个属性的值域被分为Li个区间, 其中 qnr为当训练集中样本属性的取值属于区间[er-1, er)时, 类别为Vn的所有样本点个数。
③根据训练集样本在列联表中的分布情况, 以在某一阈值区间内样本在不同类别中的分布概率作为该阈值区间对应不同类别的隶属度, 其计算方法如下所示:

公式(1)表示当属性的取值在第r个阈值区间, 即[er-1, er)时, 对于不同类别的隶属度。
(4) 利用粒子群算法确定评价因素权重
①利用交叉验证的方法将训练集等分为10份, 每次取其中1份作为验证集, 其他9份作为训练集。
②训练集通过查找“ 类-属性” 列联表得到每个样本对应的模糊关系矩阵。利用因素权重和模糊关系矩阵进行模糊综合评价, 可得到每个样本的分类, 将交叉验证条件下10次分类的平均准确率作为粒子的适应度值。
③采用粒子群算法, 将因素权重作为“ 粒子” 进行位置和速度的初始化, 粒子们通过追随当前的最优粒子在解空间中搜索, 并通过公式(2)和公式(3)更新位置和速度。粒子通过不断更新迭代找到最优解, 即各个评价因素的最优权重。在每一次迭代中, 粒子通过跟踪两个极值来更新自己: 第一个是粒子本身所找到的最优解, 这个解称为个体极值; 另一个极值是整个种群目前找到的最优解, 这个极值是全局极值。
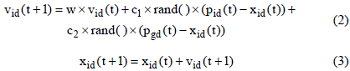
其中, w为惯性权重, 是粒子保持原来速度的系数; Vid、Xid分别为粒子当前的速度和位置; c1、c2 为加速常数, 一般情况下取2; rand( )是0-1之间的一个随机数; pid为第i个粒子个体极值第d 维的值; pgd为整个种群中全局极值第d 维的值; t 为当前迭代次数。
(5) 综合评判
根据各个属性值分别查找所对应的阈值区间, 根据阈值区间查找该属性值对应不同类别的隶属度, 由此获得该属性值对应的评判矩阵R, 通过以上建立的单因素评判矩阵R, 再根据确定的评价因素的权重因子W, 建立综合评判模型B=W B=W˙ R。
①假定样本的各个属性组成的因素集合为u=(u1, u2, · · · , um), 查找各个属性值所对应的阈值区间分别为r1, r2, …, rm。
②查找各个阈值区间对应不同类别的隶属度, 构成模糊关系矩阵如下。
R= 
③以权重分配W与模糊关系矩阵构成模糊评判模型, 得到样本对各个类别的隶属度, 实现对样本类别的软划分:
B=W˙ R=(w1, w2, · · · , wm)˙
实验采用来自权威的UCI机器学习数据库的Wine数据集, Wine数据集由3类共178个样本组成, 每个样本有13个属性, 并且属性值已经过归一化处理, 3个类不存在重叠部分, 其中第一类样本数为59, 第二类样本数为71, 第三类样本数为48。由于样本有13个属性, 3个类别, 因此确定因素集为U= {u1, u2, · · · , u13 }, 评价集为V={v1, v2, v3}。选取其中的89条作为训练集, 其中第一类中记录条数为30, 第二类中记录条数为36, 第三类中记录条数为23, 剩余部分为测试集。由于属性值已经过归一化处理, 因此将训练集利用连续属性离散化方法得到属性的区间划分及“ 类-属性” 二维列联表。表 2 为第一个属性的列联表, 其他属性的列联表与其形式一致。
| 表2 “ 类-属性” 列联表(属性1) |
表2中的数据为当属性值属于某一区间时, 对应各个类别的隶属度。第一个属性被划分为3个区间。其他属性也会根据样本的属性值及类别划分成不同的区间。
将训练集分成10份, 采用交叉验证的方法, 每次取1份作为验证集, 其余9份作为训练集, 然后利用粒子群算法, 将迭代次数设置为100次, 群体规模设置为20, 惯性权重w设为0.9, 学习因子c1和c2均设为1, 每个参数的取值范围均为[0, 5], 经过100次迭代, 粒子群算法计算出各个属性的最优权重, 如表3所示:
| 表3 属性权重表 |
输入测试集, 例如测试集中的第一个样本的第一条属性值为0.71, 从表2中查找其所属区间为[0.46, 0.75), 然后得到该属性值对应各个类别的一组隶属度值为(0.39, 0.2, 0.41)。其他属性值同样采用该方法查找对应的隶属度值, 从而生成模糊关系矩阵, 再利用表3中的各个属性的权重, 计算出样本对于各个类别的隶属度, 实现对样本类别的模糊分类和软划分, 结果如表4所示:
| 表4 样本对各个类别的隶属度 |
表4中数据为样本分别属于不同类别的隶属度, 如果取样本属于不同类别隶属度中的最大值作为该样本类别, 则该方法准确率可以达到98.88%。而在同样的数据集下, 采用SVM分类方法, 选用RBF核函数, 同样使用粒子群算法对SVM模型中的参数c和g进行寻优, 粒子群算法中c1设为1.5, c2设为1.7, 迭代次数为200, 群体规模为20, 参数c的取值范围为[0.1, 100], 参数g的取值范围为[0.01, 1000], 惯性权重设为1, 并且也使用交叉验证方法, 交叉验证次数为10, 最终分类结果准确率达到97.75%, 因此表明基于粒子群和连续属性离散化的模糊分类方法可以有效地实现模糊分类。但是无论是本文的分类方法还是SVM分类方法均会受到实验中参数设置的影响, 虽然参数经过了不断的试验筛选, 但参数设置仍存在一定的主观性。然而采用粒子群这种启发式的参数寻优算法, 尤其当在大范围内寻找最优参数时, 可以有效地节约时间, 提高方法运行效率, 并且同样可以得到全局最优解, 不会对实验结果造成较大的影响。
本文利用模糊综合评价的方法实现对样本的模糊分类, 解决传统分类方法对样本的硬性划分问题, 并且引入连续属性离散化方法, 解决部分分类方法只能处理离散型数据的问题。在实验中利用粒子群算法和交叉验证方法获取因素的最优权重分配, 并且利用连续属性离散化方法根据样本的分布情况获取各个属性对各个类别的隶属度, 使模糊综合评判的过程科学客观, 实验结果证明该方法可行有效, 可以实现对样本的模糊分类, 并且通过与SVM分类方法对比, 表明该方法达到较高的准确率。但是该方法需要对属性值进行离散化处理以确定不同属性区间对类别的隶属度, 如果属性值过于集中, 区间不易划分, 则会影响最后结果, 因此后续将针对样本属性值过于集中的模糊分类问题做进一步研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|