{kind=link}
{kind=link}
{kind=link}
面向单篇文献引文网络的主题来源与走向追踪
[秦晓慧1, 2  , 乐小虬
, 乐小虬1 ]
, 乐小虬|
|


作者贡献声明:秦晓慧: 文献调研, 细化研究方向及技术方法路线, 设计实验方案, 数据采集、清洗与结构化, 编程及实验结果分析, 论文撰写与最终版本修订; 乐小虬: 提出研究方向和思路, 提出研究方案及技术路线, 修改论文部分章节, 论文审阅及定稿。
目的 从单篇文献入手, 在其引文网络中追踪研究主题的来源与走向。方法 首先, 利用领域本体识别单篇文献中的主题; 其次, 筛选与主题相关的二级参考文献、参考文献、引证文献、二级引证文献, 构建面向单篇文献的引文网络; 然后, 对引文网络进行增量聚类处理, 形成主题的来源与走向演化图。结果 充分揭示文献主题来源或走向中继承、分化、合并的结构变化及各阶段的内容变化。【局限】引文网络构建时文献的筛选条件有待深入研究; 主题识别未考虑领域本体中词汇收录不完备问题。结论 本研究对单篇文献主题的来源与走向进行有效的追踪, 能够较好地揭示文献主题的来龙去脉。
[Objective] To track topic sources and trends for a high-impact paper from its citation network.[Methods] Firstly, topics are detected for each paper by domain Ontology. Secondly, a citation network towards a single paper’s topic is constructed. The nodes of the network are selected from second level cited papers, cited papers, citing papers and second level citing papers according to their contents. Thirdly, incremental cluster is applied for mining topic sources and trends from the network constructed before, the noisy sources or trends are filtered, and evolution paths of topics are formed.[Results] The structure changes and content changes of topic sources and trends are fully revealed. [Limitations] The screening conditions for the construction of citation network need to be further studied. Besides, completeness of the domain Ontology is not considered.[Conclusions] This study tracks topic sources and trends for single paper effectively, and helps reveal origin and development of the topics.
从一篇关键性文献入手开展文献调研分析是研究者常用的做法。这种关键性文献通常是研究领域中的高影响力文献(如重要期刊中高被引文献、核心专家的文献等), 其中蕴涵许多有价值的研究线索, 如新观点、新概念、新方法等。以这种文献作为“ 种子” , 沿着文中的多级参考文献、引证文献进行深入研读, 能够筛选出许多与研究问题相关的信息, 如主题的继承、分化、合并等发展路径。目前, 一些常用的文献数据库如SCI[1]、CNKI[2]和Google学术[3]等均提供了引文追踪功能, 但大都只是罗列出相关的引文, 缺乏对引文主题的梳理及主题研究侧重点变化的分析。
为解决这一问题, 本文利用领域本体(词表为主), 从单篇文献出发, 通过分析其二级参考文献、参考文献、引证文献、二级引证文献构成的引文网络中关于主题研究方向变化, 绘制文献中核心主题的来源与走向演化图。
主题追踪(Topic Tracking)在主题检测与跟踪(Topic Detection and Tracking, TDT)中是指对新闻数据流中的已知主题进行持续跟踪, 通常需要事先给定几个关于该主题的新闻报道, 然后判断后来信息流中的文档是否属于该主题[4]。在文献分析领域, 主题追踪并未直接用于后续文献的持续跟踪, 而是从主题演化的角度跟踪文献中研究主题的发展变化, 即从数据流中找出主题的发展历程, 描述主题的发展轨迹。目前尚未发现以单篇文献引文网络为基础的主题追踪研究, 但在针对领域或学科的主题演化方面已有大量的成果, 概括起来主要有三种基本方法:
(1) 基于共词分析的主题演化以主题词频次[5]或共现频次[6]为基础, 根据主题词间的相关程度进行聚类分析, 并绘制不同时期的主题网络图, 以观察主题的演化轨迹。该方法以词或词组为单位, 可直接揭示文献主题间的相关性, 但它简单地以主题词频次或共现频次作为主题演化分析的量化标准, 高频词阈值设定、词对的相关程度评定等都存在较大争议。
(2) 基于主题模型[7]的主题演化方法借助于主题模型能够揭示语料语义信息的优势, 在近几年得到广泛发展[8, 9]。常见的处理方式是先根据文献的出版时间离散到相应的时间窗口, 利用主题模型获取不同窗口中出现的主题, 然后将相邻窗口间的主题关联, 进而获得主题的演化过程, 然而不同时间窗口间主题关联的方式有待统一。
(3) 基于引文分析的主题演化分析是以文献共被引、耦合或直接引用的关系来分析学科或领域主题演化的方法。其主要研究思路可分为两类: 一类采用聚类的方式, 将引用关系密切的文献聚成类, 用类中的关键词、主题词或核心文献的主题反映该类的主题, 通过对比不同时间段的聚类图分析主题的演化过程。如Morris等[10]对炭疽病领域的相关文献在文献耦合分析基础上进行聚类分析, 揭示了炭疽病领域中主题发展、消亡的趋势; Takeda等[11]将拓扑聚类方法应用于光学领域文献的引文网络, 发现了该领域中主要存在的5个核心主题, 并分别从中探索新兴子主题。
另一类将文献引用关系转化成网络的形式, 其中文献看作网络的节点, 文献的引用关系看作节点间的连线, 结合社会网络分析技术中的中心性、周期性等指标分析节点的地位、对其他节点的影响变化等。刘倩楠[12]在以太网领域的相关文献中建立引文网络, 利用中心性、中介性指标筛选网络中的关键节点, 并识别这些关键节点形成的主要路径, 即技术关键路径, 最后绘制技术演化可视图谱。与引文聚类的方式相比, 社会网络技术的应用更侧重于关键节点的研究, 较多应用于知识扩散、知识流动等方面[13, 14]。
目前基于引文分析的主题演化方法大多针对于领域中大量文献的引用关系或所形成的复杂网络, 能够揭示领域内主题的分布、演化趋势等。然而少有研究针对于单篇文献做更深入的分析, 事实上高被引文献、核心专家的文献等正是调研分析的重点, 揭示这些文献主题的来源与走向, 可以帮助调研者快速了解所关注的方向。因此本文探索从单篇文献入手, 通过分析该文献为中心的引文网络追踪该文献主题的来龙去脉。
本文的主题(Topic)与文献[15]中主题定义相似, 是指文献中用于反映相关研究内容的词汇或短语。追踪主题来源与走向的基本思路是: 利用领域本体从文献标题、摘要、关键词中抽取候选主题词并计算权重, 根据权重大小筛选出能够表征文献内容的主题词, 即主题; 构建面向单篇文献主题的引文网络, 该网络由该主题相关的二级参考文献、参考文献、引证文献、二级引证文献组成; 对引文网络进行增量聚类处理, 形成文献主题的来源与走向演化图。
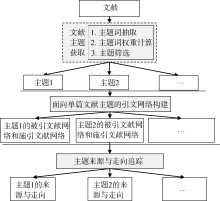
根据上述思路, 基本处理流程分为三个阶段: 文献主题获取; 面向单篇文献主题的引文网络构建; 主题来源与走向追踪。整体分析框架如图1所示:
 | 图1 主题来源与走向追踪整体分析框架 |
从文献中准确识别主题是主题追踪的基础。领域本体针对特定的领域具有较高的概念完备性[16], 利用本体中概念的同义词抽取主题词条并映射到概念的标准形式, 可以有效地降低文本特征向量的维数, 提高主题识别的质量。文献主题识别主要包括主题词抽取、主题权重计算和主题筛选三个方面。
(1) 主题词抽取
在领域本体中每个概念有一个标准形式, 但在文献中作者并非以概念的标准形式表达, 而是以其他形式的同义词进行描述。如概念“ 乳腺癌” 的标准形式为“ Breast Carcinoma” , 其同义词有Breast Cancer、Cancer of Breast等, 文献作者可能采用不同形式的词汇表达乳腺癌。为统一对领域中的多篇文献进行主题分析, 本文构建“ 同义词-标准形式” 词典, 利用该词典的同义词部分从文献的标题、关键词、摘要中抽取词条, 然后映射到概念的标准形式(本文称为主题词), 并记录各主题词在每个位置上出现的频次。主题词用
(2) 主题词权重计算
文献的标题、摘要、关键词中可抽出大量与领域相关的主题词, 但并非所有的主题词都能表征该文献的研究内容[15], 需给主题词赋予权重。设标题、关键词、摘要中出现的主题词权重分别为Wt、Wk、Wa, 一般认为文献标题、关键词、摘要中的词汇反映文献内容的能力依次降低[17], 因此Wt> Wk> Wa。笔者定义主题词的权重计算公式为:
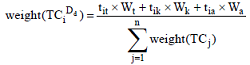
其中, weight()表示主题词在该文献中的权重, tit、tik、tia分别是在标题、关键词、摘要中出现的次数, n为文献中主题词总数。
(3) 主题筛选
经以上两个步骤的处理, 每篇文献都可抽取出一系列的主题词及其对应的权重, 权重大的主题词出现在文献重要的位置或出现次数较多, 能够更好地表征文献内容。设置阈值ξ , 若weight()> ξ , 则认为是该文献的主题。
设是文献Dd的第m个主题, 其来源与走向来自于Dd的引文集合。考虑到中间层次较多的引文与主题文献之间的内容相关度较低, 且数据较不容易获取, 本文的引文集合仅选自主题文献的二级参考文献、参考文献、引证文献和二级引证文献。在分析的来源与走向之前, 需构建面向主题的引文网络。
Dd的引文集合中并非所有文献都与主题密切相关, 若分析过程中引入大量的无关文献, 会对主题来源与走向的追踪造成干扰。从引文集合中筛选含有主题或 下位词(下位词从领域本体中获取)的文献作为网络节点, 以此方式可缩小文献集合, 排除无关文献的干扰。
在文献主题及其引文网络的数据基础上, 采用聚类的方式从中获取主题的来源与走向。
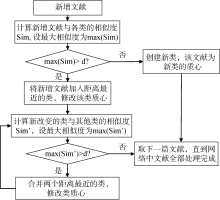
在诸多的聚类方法中, 增量聚类算法可以只处理增量部分的数据, 并对已有的聚类结果进行增量式的修改和完善[18], 满足动态追踪主题来源与走向变化的需求。因此, 本文采用增量聚类方法, 按照文献引用顺序, 逐篇处理网络中的文献, 处理步骤如图2所示, 其中d(0< d< 1)是相似度阈值。文献Dd之前的文献网络称为前向网络, 所生成的类反映主题的来源; 文献Dd之后的文献网络称为后向网络, 所生成的类反映主题的走向; 类的质心表示主题来源或走向的内容。
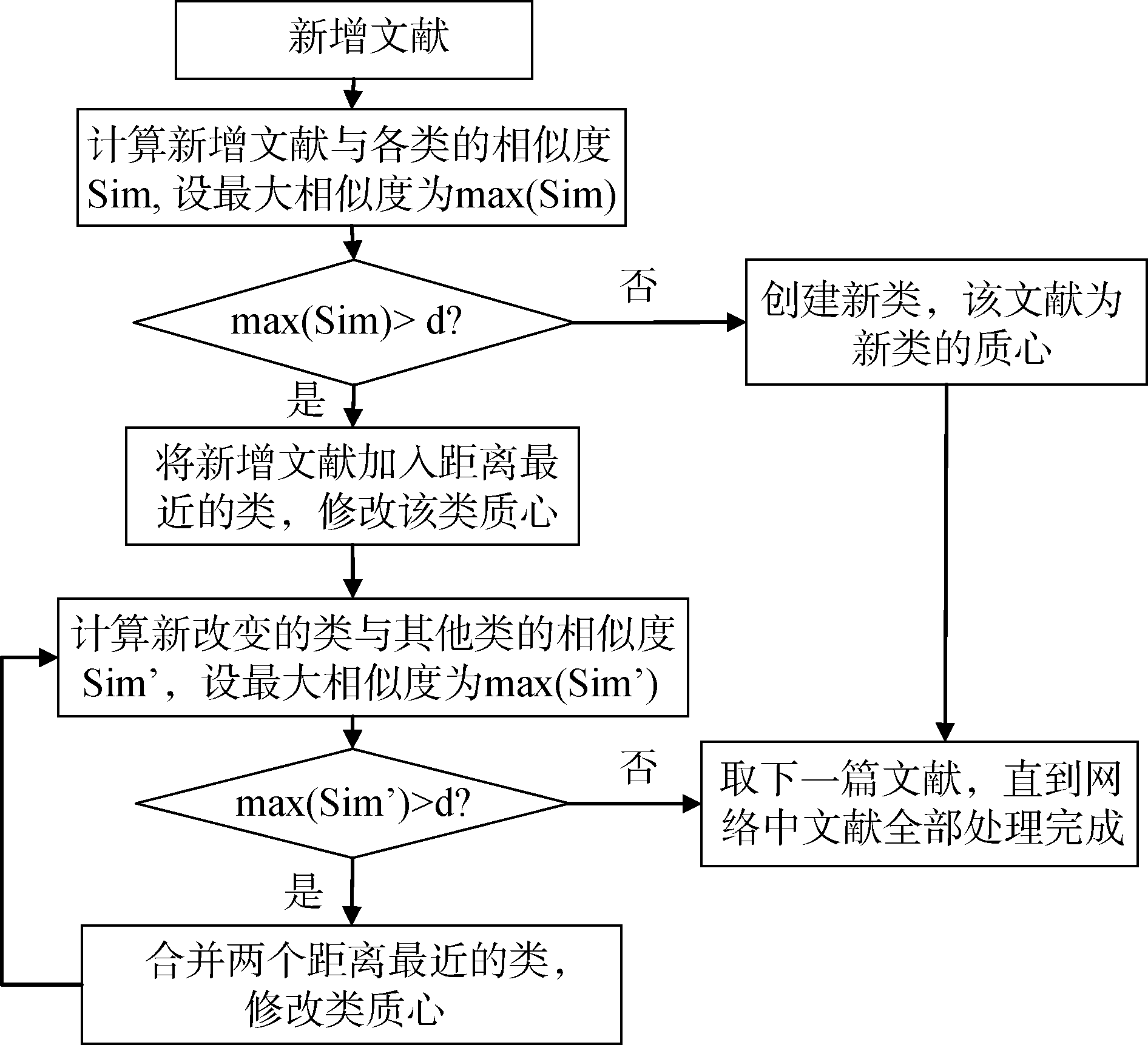 | 图2 引文网络的增量聚类步骤 |
利用该方法, 逐步将文献融入到原有聚类结果中, 会改变原有类的质心, 即改变原有主题来源或走向的内容, 根据增加数据后的类质心与原有各类质心距离的比较, 对原有聚类结果可能产生以下三种影响(为便于描述, 此处来源或走向统称为方向):
(1) 创建新类, 即形成新的方向: 如果一篇新增文献的内容与已有方向的内容相似度普遍较小, 则将该文献看作一个新的方向。
(2) 归入某一类, 改变该类的质心, 即改动原有方向的内容: 如果一篇新增文献的内容与已有的某个方向的相似度较高, 则将该文献归入对应的方向, 并重新计算该方向的内容。
(3) 合并相邻的类, 即合并内容相似的方向: 步骤(2)之后需重新计算新方向与其他方向的相似度。若最大相似度大于d, 则将相应的两个方向合并, 并再次计算方向间的相似度。如此循环, 直至方向之间的相似度皆小于d。
该方法可以动态跟踪每篇文献对主题方向的影响, 但考虑到数据存储量, 本研究以年为单位, 仅记录每年的最后一篇文献融入聚类后的方向内容, 这种保存结果可用于分析主题来源或走向逐年的变化状态。
以“ 肿瘤(Cancer)” 研究领域为例, 对上述单篇文献主题来源与走向追踪方法的可行性与有效性进行验证。由领域专家确定领域核心期刊列表, 从Web of Knowledge[1]数据库中下载对应的期刊文献, 期刊列表如表1所示。下载时间为2013年7月3日, 文献类型限定为Article、Proceedings Paper、Editorial Material、Review和Letter, 文献量为176 286篇。下载的数据中含有文献的参考信息, 通过编写Java程序, 在数据集中建立文献之间的引用关系, 并存储到数据库中, 便于构建引文网络时应用。
| 表1 肿瘤领域核心期刊 |
下载肿瘤领域本体NCIt[19] (National Cancer Institute thesaurus, NCIt), 将其作为领域词典应用到本文的主题抽取过程中。NCIt中概念的同义词属性标签为FULL_SYN, 每个概念有一个或多个FULL_SYN标签; 另外每个概念用一个Label标签表示其标准形式。如“ 糖原合酶激酶-3” 的Label为“ Glycogen Synthase Kinase 3” , 有4个FULL_SYN标签, 值分别为“ GSK-3” 、“ GSK3” 、“ Glycogen Synthase Kinase 3” 和“ Glycogen Synthase Kinase- 3” 。因此可为“ 糖原合酶激酶-3” 建立“ 同义词-标准形式” 词典:
GSK-3 — Glycogen Synthase Kinase 3
GSK3 — Glycogen Synthase Kinase 3
Glycogen Synthase Kinase 3 — Glycogen Synthase Kinase 3
Glycogen Synthase Kinase- 3 — Glycogen Synthase Kinase 3
利用3.2节的方法从文献的标题、关键词、摘要中抽取主题词, 可获得文献的系列主题词及其权重。实验发现, 权重大于0.1的主题词能够很好地表征文献的研究内容, 因此本文设置权重阈值为0.1。
肿瘤领域数据中随机选择出一部分文献做主题识别结果的分析并与标准的TF-IDF计算结果作对比, 以验证文献主题识别的有效性。表2展示的是随机选取的5篇文献的主题识别结果。为在同一数量级下对比, 将TF-IDF值进行归一化处理。其中TF-IDF结果中阈值难以确定, 因此仅展示与本文方法所获得主题相同数目的前几位词汇。
从形式上, 根据位置、频次获取的主题权重普遍高于TF-IDF权重, 容易区分于权重低的词汇, 具有较好的主题代表性。而TF-IDF所得的权重值相对比较均匀, 主要原因是其未考虑词汇出现的位置。从内容上, 两种方法获得的主题基本相同, 都可以展示出与文献相关的内容。但两者又存在差异, 筛选后的主题词不尽相同且权重的排序区别较大, 这是由于本文方法中主题词权重的评估依赖于主题词在文献本身中的位置、频次, 未分析主题词在文献集中出现的特点; 而TF-IDF还考虑到词汇在文献集中出现的文档频次, 侧重于与其他文献作区分。
| 表2 主题识别结果对比(部分) |
为了进一步验证结果的准确性, 通过人工判读的方法对抽取的文献进行分析, 结果发现所识别的主题能较好地揭示文献的研究内容。例如, 文章WOS: 000234334700007主要是研究药物SU11248在转移性肾细胞癌患者体内的活性, 这种药物既是血管内皮生长因子受体, 又是血小板源性生长因子受体的多靶点抑制剂。经过本文主题获取方法, 可识别SU11248、转移性肾细胞癌(Metastatic Renal Cell Cancer)、血管内皮生长因子受体(Platelet-derived Growth Factor Receptor)、抑制剂(Inhibitor)等核心主题, 与文献研究内容一致, 为主题来源与走向分析奠定了基础。
在以上数据处理的基础上, 按照3.3节依次为每篇文献的每个主题构建引文网络并根据3.4节中的方法追踪主题的来龙去脉。
本方法需从文献的前后向引文网络中获取主题来源与走向, 但在数据集中并非所有文献都能构建出来双向网络。通过对整体数据集分析发现文献主题追踪的结果可分为4类:
(1) 文献的双向网络都可构建出来, 可完整地获取其主题来源与走向;
(2) 文献出版年份较早, 其参考文献难以获取, 但其引证文献、二级引证文献数量充足, 只可追踪其主题走向;
(3) 文献出版时间晚或影响力低, 但可获取其参考文献、二级参考文献, 可追踪其主题来源;
(4) 文献出版时间早且影响力低, 其主题来源与走向都不可获取。
为了验证实验结果, 分别选择前三类文章各10篇, 通过对引文网络中文献标题、关键词、摘要的判读, 发现主题追踪的结果符合网络中文献的内容。
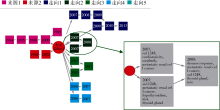
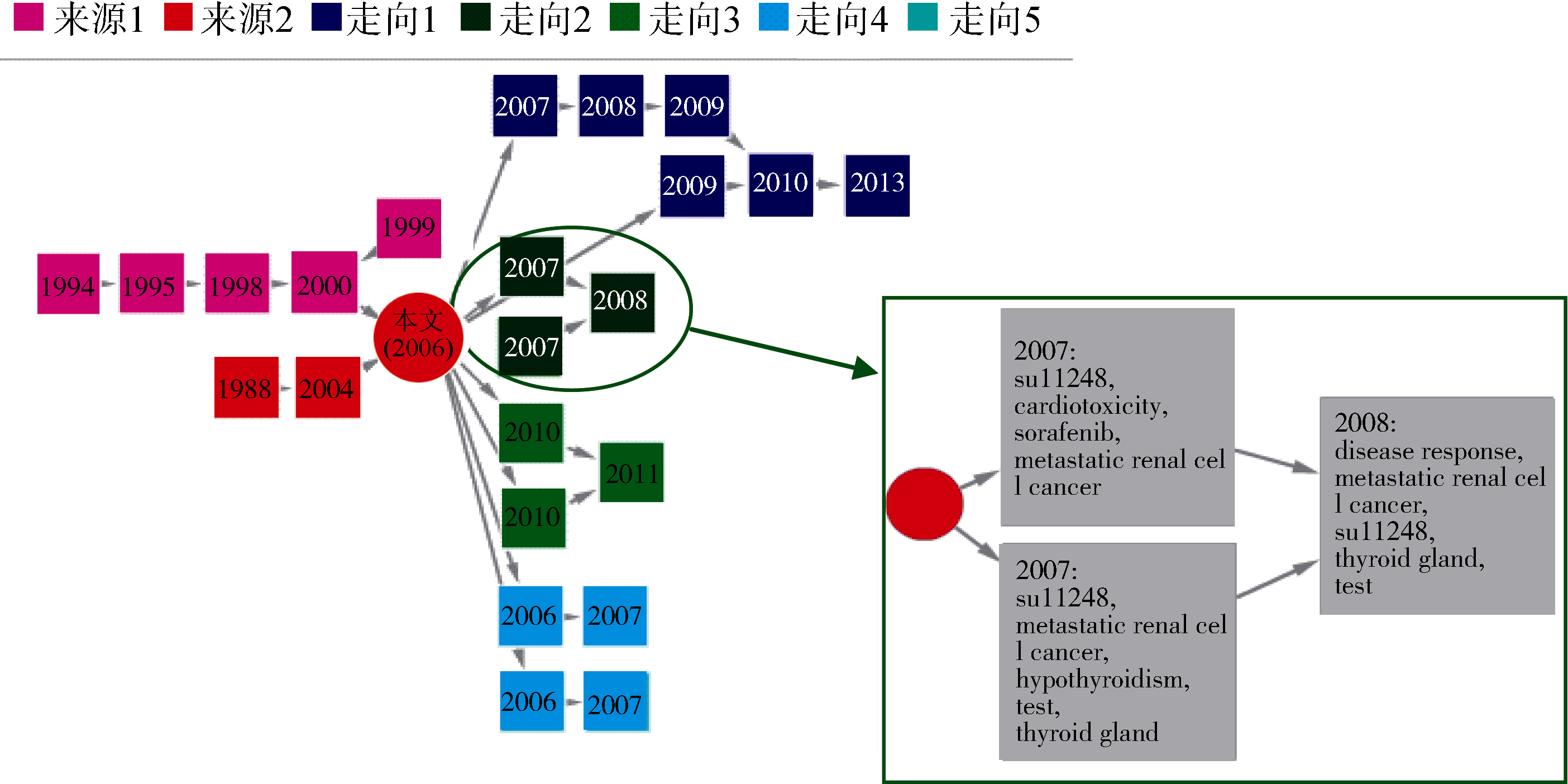
选择数据集中一篇高被引(本地被引数: 179, 本地二级被引数: 1 091)文献[20](ID: WOS: 00023433470 0007, 下文称Motzer RJ(2006)), 以下就其主题Metastatic Renal Cell Cancer的追踪结果展开讨论。利用3.4节中方法对文章中主题Metastatic Renal Cell Cancer的引文网络增量聚类, 形成其来源与走向的演化图, 如图3所示, 其中红色圆形表示文章Motzer RJ(2006), 颜色相同的方块构成主题的一个来源或走向, 数字表示该方向在该年份的状态, 箭头表示各状态间的变化。红色圆形左侧是该主题的来源, 最终的箭头流向该文献; 右侧是该主题的走向, 每个走向都始于该文献。最右侧是走向2内容详情, 走向2与走向4在各年份对应的文献如表3所示。
(1) 该方法能够在主题的来源之间与走向之间做较好的区分。结合图3可以看出, 从文献Motzer RJ(2006)主题Metastatic Renal Cell Cancer的引文网络中, 可追溯到其2个来源和5个走向。其中走向2和走向4的主题词分别为“ SU11248, Metastatic Renal Cell Cancer, Hypothyroidism” 、“ Immunotherapy, Metastatic Renal Cell Cancer, Biological Therapy” 。从其相关文献来看, 走向2的文献多是讨论“ SU11248对转移性肾细胞癌病人的影响” , 走向4的文献则在探讨“ 是否选择免疫疗法(Immunotherapy)治疗转移性肾细胞癌” 。本文的主题来源与走向获取方法将这些文献鲜明地划分到两个不同走向中, 且提取其中的主题词作为走向的内容, 表明该方法能够较好地区分不同方向。
 | 图3 主题Metastatic Renal Cell Cancer的来源与走向演化 |
| 表3 图3中主题走向2与走向4对应的文献 |
图3中其他来源与走向的主要内容分别是: 来源1, α 干扰素对转移性肾细胞癌的治疗作用; 来源2, 转移性肾细胞癌的预后因子; 走向1, 转移性肾细胞癌的靶向治疗; 走向3, 转移性肾细胞癌与mTOR抑制剂的相互作用; 走向5, 用减瘤性肾切除方法治疗转移性肾细胞癌。此处限于篇幅, 不再一一展开讨论。
(2) 该方法同样可以动态揭示文献主题来源或走向的继承、分化、合并的结构变化及各阶段的内容变化。以Metastatic Renal Cell Cancer的走向2为例, 从结构上看在2007年从文献Motzer RJ(2006)中分化出两个走向, 在2008年这两个方向发生合并。从内容上看, 2007年的两个方向中一个侧重于“ SU11248在转移性肾细胞癌的治疗中可能导致甲状腺功能减退” , 另一个方向则在探讨“ SU11248在转移性肾细胞癌中的应用” , 但核心主题词都包含“ SU11248、Metastatic Renal Cell Cancer” , 都未脱离“ SU11248对转移性肾细胞癌病人的影响” 的讨论, 具有高度的相似性。2008年在这两个走向的基础上展开了进一步研究, 可看作主题走向发生合并。
本文从单篇文献出发, 以单篇文献的二级参考文献、参考文献、引证文献、二级引证文献形成的引文网络为基础, 利用领域本体, 采用增量式聚类方法对文献中核心主题的来源和走向进行追踪, 并绘制主题演化图。从肿瘤领域的实验结果来看, 该方法能够较好地呈现核心主题的起源、发展、合并、分化的不同变化阶段和路径。
为提高方法的准确性与应用性, 本文还需从以下两个方面加以改善: 首先, 引文网络构建基于如下假设: 若参考文献与施引文献存在相同的主题词, 则两篇文献在该主题上具有内容的相关性。而文献的引用原因或内容更多地由引证文献的引用句和上下文决定, 仅依靠出现的相同主题词可能将相关度较小的文献引入网络。因此在后续研究中需获取文献全文, 识别引文内容, 从而准确构建引文网络。其次, 主题识别仅依靠领域本体, 而文献中常有关键词未被登录, 可能造成主题识别不全面。下一步研究中考虑将关键词融入到主题识别过程中, 以关键词扩充词典, 提高主题识别的全面性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|