{kind=link}
{kind=link}
利用LeaderRank识别有影响力的作者
[邓启平1, 2 , 王小梅1  ]
]
]
|
|


作者贡献声明:邓启平: 采集、清洗数据, 算法实现和论文起草; 王小梅: 提出研究思路, 设计研究方案, 论文最终版本修订。
目的 识别研究领域内有影响力的作者。方法 将LeaderRank用于合作网络测度作者影响力, 通过不同的加权算法探讨合作次数和被引频次对重要作者排序的影响, 在此基础上整合两个指标提出CW_LR算法, 从合作和引用两个维度识别有影响力的作者。结果 CW_LR算法与被引频次有相关性, 但与被引频次或其他几种加权方法相比, 识别出有影响力的作者与业界公认的更为一致。【局限】只在“信息计量学”领域进行实证, 后续将该方法扩展到其他领域进一步验证其有效性。结论 同时考虑合作关系强度和引用影响力, 从合作和引用两个维度能更准确地识别出有影响力的作者。
[Objective] Provide an alternative perspective for identifying influential authors.[Methods] This paper uses the weighted LeaderRank algorithm to measure author’s impacts in coauthorship network. Respectively validates the effects of citations and the number of cooperation on sorting influential authors through different weighted algorithms. And base on the validation a new weighted algorithm named CW_LR is proposed by integrating these two factors.[Results] CW_LR algorithm is interrelated with citations, but compared with citations or other weighted algorithms, the result of CW_LR algorithm is more consistent with expert knowledge. [Limitations] This algorithm is tested in the informetrics research community, while further effectiveness validation in other research community is required.[Conclusions] The strength of cooperation and citation impact are considered at the same time in CW_LR algorithm, and this algorithm identifies the influential author more accurately from two dimensions.
识别领域内有影响力的作者有助于评估研究人员的学术影响力和发展潜力, 为科研人员追踪业界先进技术, 科研决策者实施人才评估、了解本国科研实力提供信息支持。根据学术交流的形式, 作者影响力可分为引用影响力和合作影响力, 从“ 引用” 和“ 合作” 两个角度反映作者学术影响力的不同方面。已有的研究多是基于一个维度测度作者的影响力, 缺乏完整性, 因此笔者尝试从“ 引用” 和“ 合作” 两个角度综合测度作者的影响力。
基于引用测度作者影响力的研究和应用都很广泛, 主要包括两类:
(1) 基于被引频次。被引频次能反映作者的引用影响力, 一位作者的论文被引频次越高, 其在自己的领域内有更高的影响力, 这是测度作者影响力最基本的方法。后来出现的篇均被引频次、h指数及其衍生指数等都是对被引频次的改进, 这类基于被引频次的指标是评价作者影响力最常用的指标。
(2) 基于引用网络分析。引用网络是根据主体之间的某种共现关系构建的网络, 利用网络分析方法可以识别网络中的重要节点, 这种方法也是基于文献之间的引用关系, 但更多是运用在期刊层面, 很少有学者利用该方法研究个人影响力, Ding等[1]构建了作者之间的共被引网络, 利用PageRank算法对网络中的节点按照重要程度进行排序, 进而识别出有影响力的作者, 并探讨了不同阻尼系数对排序结果的影响; Fiala等[2]从引用关系中剔除合作关系, 定义了一个作者引用网络并提出算法识别有影响力的作者。虽然基于引用关系测度作者影响力的研究历史较长且使用最为广泛, 但其准确性存在一定的争议, 一方面因为学者的引用动机存在多样性, 比如自引现象可以增加文献的被引频次, 而被引频次又是评价影响力的重要指标, 但其本身存在着所引文献并非均是必要的、适当的等问题, 此外, 并不是所有的他引文献都对学术交流产生积极的影响; 另一方面, 基于引用的测度并不能全面评价一个学者的影响力, 通过引用这种交流方式产生的学术影响力只是影响力的一部分, 随着科学合作的增加和社会网络分析法的引入, 学者开始关注科研人员在科学合作中产生的影响力, 作为学术交流过程中产生的另一种影响力, 在测度作者影响力时不能忽视。
早期对科学合作的研究主要集中在网络结构属性、演化特征等宏观层面上, 对节点重要性和合作影响力的评测研究相对滞后, 且多是以网络中心性指标作为影响力的表征。Burt[3]通过研究网络结构和社会资本的联系, 发现介数中心性高的节点拥有更多的社会资本, 能获取和传递更多的信息流, 作者合作网络能够反映作者在领域内的科学合作地位, 网络中中心性越高的作者也就拥有更高的合作影响力; Mutschke[4]将中心性指标应用到数字图书馆领域的作者合作网络中, 评估节点的地位, 发现领域专家; Yin等[5]分析了COLLNET会议成员的合作网络, 分别用度中心性、接近中心性、介数中心性和K-core识别网络中更具影响力的作者; 徐玲等[6]研究了《科学通报》20年间出版论文的作者合作网络, 通过文献数量、合作者数目以及中介中心性三个指标评测了网络中的作者影响力。事实上, 应用中心性指标测量作者的影响力并不十分科学, 在科学合作过程中, 一些研究者为了提高研究能力可能与多个学者有合作关系, 由此使得作者的中心性指标可能会比较高, 但其在科学合作网络中的重要性和影响力可能并不高。为了克服中心性指标的这一缺陷, 学者们提出了一些新的重要性识别方法, 其中PageRank算法的引入掀起了一个研究热点, 它不仅简单地考虑节点的度, 更重要的是考虑邻居节点的声望。Yan等[7]对度中心性、接近中心性、介数中心性以及PageRank算法的排序结果进行比较分析, 发现4个指标和被引频次有一定的相关性, 证明在影响力分析中这些指标是有效的。大部分指标将作者合作网络视为无权网络, 不能反映作者之间的合作关系强度, Liu等[8]提出了AuthorRank算法, 该算法考虑了作者合作关系的强度, 认为一篇文章的作者数越少, 其合作关系的权重越大, 作者数越多, 其合作关系的权重越小。与中心性指标不同, 类似于PageRank的重要节点识别算法能将节点特有属性和网络拓扑结构相结合, 同时反映邻居节点的声望, 使排序结果更加准确。
作者影响力的测度不应该仅依据引用关系或合作关系, 而应将二者结合互为补充, 使得科研人员影响力测度更加完善。整合学者的引用影响力和合作影响力主要有两种方法:
(1) 建立二维测度体系, 从两个维度遴选有影响力的作者, 丁洁兰[9]、杜建等[10]在各自的研究中选取并改进了不同的指标来表征两个维度的影响力, 根据两个维度的值将作者影响力划分为4种类型;
(2) 将两个维度的影响力整合为一个指标综合评价学者的学术影响力, Bö rner等[11]在合作网络的基础上通过重新定义边的权重将合作论文数和被引频次相结合, 并用中心性等指标衡量作者的影响力; Yan等[12]结合作者被引频次提出加权PageRank算法识别合作网络中有影响力的作者。这两种方法都尝试将引用分析和合作网络分析相结合, 前者用二维测度体系能清晰反映学者在不同维度的影响力, 但指标的合理性有待进一步验证; 后者在测度合作影响力的指标中融入被引频次, 直观体现学者的综合影响力, 但Bö rner等以中心性等指标表征影响力, 没有考虑合作者的权威, 不能反映影响力的变化情况, Yan等的加权PageRank算法只是将被引频次简单地结合到算法中, 并没有考虑合作论文的作者数, 也没有考虑合作网中的关系强度, 而PageRank算法中参数c的选取需要实验获得, 并且在不同的应用背景下最优参数不具代表性。
上述研究表明基于合作网络分析的合作影响力是对引用影响力的重要补充, 借助网络重要节点识别算法能将合作影响力与引用影响力整合起来共同测度作者的学术影响力。已有的研究主要是在合作网络中结合作者被引频次, 重新定义边的权重, 再利用中心性指标测度作者影响力, 不能反映合作者声望对作者影响力的影响; Yan等提出的加权PageRank算法能反映邻居节点的声望, 但没有考虑作者之间的合作关系强度。因此, 本文在合作网络基础上利用重要节点识别算法判别有影响力的作者, 分别结合合作次数和被引频次, 探讨了合作关系强度和引用影响力对排序结果的影响, 最后提出一个整合引用影响力和合作影响力的算法以识别有影响力的作者。
由于PageRank算法中参数c的选取需要实验获得, 并且在不同的应用背景下最优参数不具代表性, Lü 等[13]提出LeaderRank算法, 其比PageRank算法收敛更快, 能更快地识别网络中有影响力的节点, 具有实际应用价值, 且有更强的鲁棒性。因此本研究以LeaderRank算法为基础, 首先从合作网络的拓扑结构出发识别合作影响力高的作者, 为了更准确地反映作者在合作中的地位, 考虑作者合作关系强度, 将合作次数引入LeaderRank算法中; 然后在网络拓扑结构基础上, 考虑作者的引用影响力, 将被引频次引入LeaderRank算法中, 从合作影响力和引用影响力两个维度识别重要作者; 同时考虑合作关系强度和引用影响力, 本文提出了一个综合加权算法以识别有影响力的作者。
(1) LeaderRank算法
LeaderRank算法的思想是在包含N个节点的网络中添加一个背景节点以及该节点与网络中所有节点的双向边, 代替PageRank算法中的跳转概率, 具体计算如公式(1)所示[14]:
初始时刻给定每个节点(除背景节点外)一个单位资源, 即LRii(0)=1, 蜄 i≠ g; LRg(0)=0。通过有向连接将资源分配给邻居节点, 经过公式(1)迭代直到稳态, 最后将背景节点的分数值LRg(tc)平分给其他n个节点。整个过程等同于在有向网络中随机游走, 可以用一个随机矩阵P表示, 其元素 
标准LeaderRank算法中背景节点和所有节点的连接都一样, Li等[14]对此提出改进, 认为背景节点出发访问其他节点时, 入度大的节点应该有更高的概率被访问到, 如果一个节点vi的入度为
值得注意的是改进后的LeaderRank算法同样适用于含权网络。本研究基于LeaderRank算法, 分别从合作影响力(合作次数)、引用影响力(被引频次)两个维度进行加权实验, 最后提出一个综合加权方法。
(2) 考虑合作强度的加权LeaderRank算法
原始的合作网络是一个二元网络, 两个作者之间有合作关系其边权为1, 否则为0。显然, 作者的合作关系有强弱之分, 为了更加准确地从合作影响力维度识别有影响力的作者, 通过对作者的合作关系进行加权将作者的合作次数引入到LeaderRank算法中。两个作者的合作次数越多, 其边权越大, 因此设定公式(1)中
(3) 考虑引用影响力的加权LeaderRank算法
合作网络反映的是作者的合作地位, 原始LeaderRank算法和W_LR算法并不能准确评估一个作者的影响力, 因此考虑将引用影响力结合到算法中。借鉴改进的LeaderRank算法[14], 通过对背景节点指向其他节点的边进行加权, 将作者的被引频次引入算法中, 从合作影响力和引用影响力两个维度测量作者的影响力。作者的被引频次越高其影响力越大, 在LeaderRank算法下, 如果节点的被引频次越高, 背景节点g指向该节点的边权越大, 因此设定公式(2)中背景节点指向节点vi的边权
(4) 结合引用影响力和合作强度的加权LeaderRank算法
分别探讨了合作关系强度和引用影响力对重要作者排序的影响后, 发现二者各有优劣, 均不能全面地识别出有影响力的作者。为了更准确地识别出有影响力的作者, 本文提出CW_LR算法, 该算法同时考虑被引频次和合作次数。由于合作论文的影响力与作者数量相关, 直接使用被引频次会夸大多作者合作论文中作者的影响力, 而合作论文中作者之间的合作关系强度与作者数量成反比, 因此为了使权重分配更加合理, CW_LR算法进一步考虑了合作论文的作者数量, 对两类边权进行调整。将作者的被引频次分为独立被引频次和合作被引频次两部分, 其中合作被引频次的计算方法借鉴了Bö rner 等[11]提出的CS指标, 将一篇合作论文的人均被引频次视为作者的合作被引频次。重新设计后, 公式(2)中背景节点与节点vi间的边权用公式(3)表示:
其中, p1表示作者cp1独立发表的论文, cp1表示论文p1的被引频次; p2表示作者合作发表的论文, cp2是论文p2的被引频次, n为p2的合作者数。作者之间的合作关系强度不仅考虑了合作次数, 还进一步考虑了作者每次合作的关系强度。将一篇合作论文的合作关系强度视为1, 文章的作者数越少, 作者之间的合作关系越强; 作者数越多, 合作关系越弱。假设某篇论文有三个作者, 在有向网络中共有3× 2对合作关系, 每对合作关系的强度为1/6。按照上述方法, 公式(2)中其他节点之间的边权如公式(4)所示:
其中, p是作者i和作者j的合作论文,
以“ 信息计量学” 研究领域为研究对象, 使用数据库为Web of Science, 检索时间为2014年8月31日, 包含默认的所有年份, 检索式为:
(TS=(Informetric* OR Bibliometric* OR Webometric* OR Scientometric* ) OR SO =(Scientometrics OR Journal of Informetrics) OR CF= (Informetric* OR Bibliometric* OR Webometric* OR Scientometric* )) AND DT=(ARTICLE OR PROCEEDINGS PAPER OR REVIEW ) OR (TS=(Zipf OR Bradford OR Lotka OR “ citation analy* ” OR “ cocitation analy* ” OR “ co-citation analy* ” OR “ link analy* ” OR “ hyperlink analy* ” OR “ self citation* ” OR “ self-citation* ” OR “ impact factor* ” OR “ S& T indicator* ” OR “ citation map* ” OR “ citation visuali* ” OR “ h-index” OR “ hindex” OR “ Hirsch index” OR “ HIRSCH-INDEX” OR “ citation network* ” OR “ collaboration network* ” OR “ coauthorship network* ” OR “ co-authorship network* ” OR “ collaboration analy* ” OR “ co-authorship analy* ” OR “ coauthorship analy* ” OR “ map* science” OR “ science map* ” OR “ map* of science” OR “ co-word analy* ” OR “ coword analy* ” OR “ network analy* ” OR “ performance rank* ” OR “ patent analy* ” OR “ patent citation* ” OR “ patent citing* ” OR “ patent cited* ” OR “ patent map* ” OR “ patent draw* ” OR “ patent landscap* ” OR “ Research productivity” OR “ Scien* collaboration” OR “ research collaboration” OR “ Research evalu* ” OR “ scien* productivity” OR “ International collaboration” OR “ Bibliographic coupling” OR “ interdisciplinarity” ) AND (SU=( “ INFORMATION SCIENCE & LIBRARY SCIENCE” OR “ COMPUTER SCIENCE INTERDISCIPLINARY APPLICATIONS” OR “ COMPUTER SCIENCE INFORMATION SYSTEMS” OR “ MULTIDISCIPLINARY SCIENCES” ) AND DT= (ARTICLE OR PROCEEDINGS PAPER OR REVIEW ))
共检索出文献10 202篇, 其中合作论文6 590篇, 包含11 605位作者, 23 373对合作关系。
实验时设定C_LR和CW_LR算法中
| 表1 不同算法Top-20 |
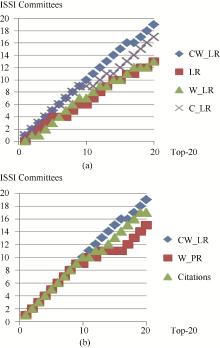
LeaderRank算法基于原始的合作网络识别出Leydesdorff, L、Rousseau, R、Thelwall, M等合作影响力高的作者, 由于没有考虑合作关系强度, 该算法也识别出一些实际合作影响力并不高的作者。W_LR算法在LeaderRank算法中引入了作者合作次数, 能更好地反映作者在合作网络中的地位, 进一步识别出Glanzel, W、Schubert, A P、van Raan, A F J等合作影响力高的作者, 同时降低了LeaderRank算法中一些合作影响力并不高的作者排名。LeaderRank算法和W_LR算法中网络拓扑结构起着主要作用, 仅从合作的维度识别有影响力的作者, 对于很少参与科学合作而引用影响力高的作者没有优势。为了更全面地测度作者的影响力, C_LR算法整合了引用和合作两个维度, 简单地将被引频次结合到LeaderRank算法中, 识别出Glanzel, W、Leydesdorff, L、Moed, H F等综合影响力高的作者, 但该算法没有考虑合作关系强度, 不能反映作者的实际合作影响力。CW_LR算法同时结合了引用频次和合作次数, 并进一步考虑了合作论文的作者数量, 能更真实地反映作者合作影响力和引用影响力, 识别出Glanzel, W、Rousseau, R、Schubert, A P、Leydesdorff, L、Thelwall, M等极具影响力的作者。
CW_LR算法整合了引用和合作两个维度, 由于CW_LR算法基于合作网络, 其与合作影响力自然相关, 这里主要分析CW_LR与被引频次(Citations)之间的相关性。为了简单清晰地展示二者之间的关系, 计算具有相同Citations的作者对应的平均CW_LR值代替每个作者的独立CW_LR值。图1是Citations和平均CW_LR值的双对数图, 可以看出更多点分布在趋势线附近, 表明CW_LR值与Citations整体上相关, 然而Citations较大时相关性较小, Citations较小时相关性较大。CW_LR算法中作者合作影响力的变化依赖邻居节点的个数和声望, 当度中心性较小时作者影响力的大小主要决定于背景节点分配的引用影响力(Citations)。事实上, 研究数据中大部分作者的Citations很小且相应的度中心性也很低, 这些作者的合作影响力对CW_LR值的贡献很小, 得分主要来自引用影响力, 因此Citations和CW_LR值都很低, 二者之间的相关性较大; Citations较大时, 作者的度中心性变化范围大, 合作影响力对CW_LR值的贡献不稳定, 使得 Citations与CW_LR之间的相关性较小, 分析认为二者的相关性变化是合理的。
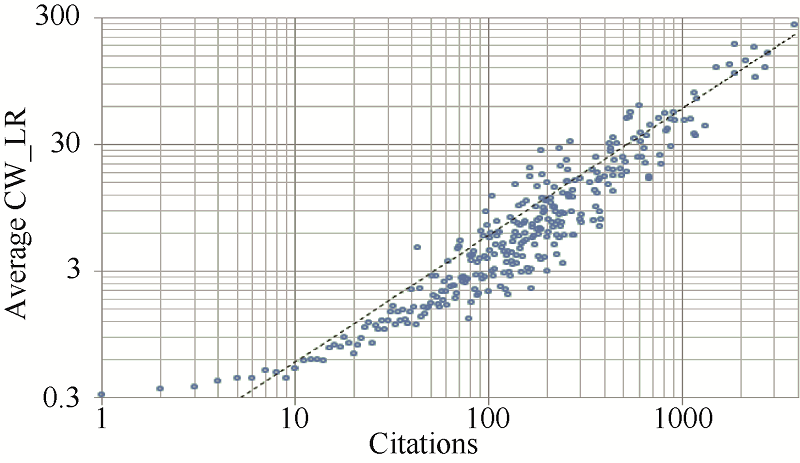 | 图1 Citations与平均CW_LR的散点图 |
为了验证CW_LR算法的有效性, 将排名结果与收集到的14届国际科学计量与信息计量学会(ISSI)委员会名单和获奖者名单进行对比分析, 委员会成员和获奖者的排名应该高于其他作者。表2列出了不同的加权LeaderRank算法、Yan等提出的Weighted PageRank算法排序结果, ISSI Committees表示作者在14届ISSI委员会名单中出现的次数, 值为null表示作者不在委员会名单中。
各个算法前20名作者中累计的委员会人数如图2所示, CW_LR排名前20的作者有19名是ISSI委员会成员, W_LR和C_LR分别为13和17, Weighted PageRank算法和Citations分别为15和17。将不同算法前20名作者中包含的Derek de Solla Price Award获奖者人数进行比较, 其中CW_LR排名前20的作者中有9名是获奖者, W_LR、C_LR以及Weighted PageRank算法都包含7名获奖者, 而Citations包含11名获奖者, 这个情况是合理的, 因为奖项的评选主要是依据作者的被引频次。
为了进一步验证算法的有效性, 将所有获奖者在不同算法中的具体排名情况进行了比较分析, 如表3所示。其中Citations和加权PageRank算法是本研究用于对比分析的重要算法。11 605位合作者中包含23位Derek de Solla Price Award获奖者, 理论上获奖者在一个算法中的排名越靠前说明这个算法越有效。分析可以看出, 23位获奖者在CW_LR算法中排名比较靠前, 前864名作者列表中就包含了所有的获奖者; W_PR算法中, 获奖者的排名相差较大, BROOKES, B C等早期在领域内影响力较大的作者排名很靠后, 在前 4 905名作者列表中才能包含所有23位获奖者; Citations中获奖者的排名也比较靠前, 但前1 392名作者列表中才能包含所有的获奖者。可以看出, CW_LR算法的有效性较其他算法有所提升, 排序结果更加有效稳定, 识别出的重要作者与业界公认的更为一致。
| 表2 不同算法的比较 |
 | 图2 累计委员会人数 |
| 表3 获奖者排名比较 |
本研究将LeaderRank算法应用到“ 信息计量学” 研究领域的作者合作网中识别有影响力的作者。首先在原始网络基础上分别考虑合作关系强度和引用影响力, 通过不同的加权方法探讨了其对重要作者排序的影响, 发现二者均存在不足, 进而提出CW_LR算法, 不仅同时考虑了作者合作次数和被引频次两个指标, 还进一步考虑了合作论文的作者数量, 使权重分配更加合理。将不同的算法与14届国际科学计量与信息计量学会委员会名单和获奖者名单进行对比分析, 结果表明本文提出的CW_LR算法得到的排序结果更加可靠, 能有效地识别出领域内有影响力的作者, 是对基于作者被引频次评价作者影响力的有效补充。由于LeaderRank算法收敛速度更快, 当网络中包含较多节点时CW_LR算法的优势更为明显。
本文只探讨了CW_LR算法中
(致谢: 感谢Ronald Rousseau 教授提供的国际科学计量与信息计量学会(ISSI)委员会名单, 及对本论文有影响力作者排序结果的基本认可。)
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|