
|
|
武慧娟 , JiaTinaDu
, JiaTinaDu
Wu Huijuan, Jia Tina Du
中图分类号: G250
通讯作者:
收稿日期: 2016-04-15
修回日期: 2016-05-9
网络出版日期: 2016-09-25
版权声明: 2016 《现代图书情报技术》编辑部 《现代图书情报技术》编辑部
基金资助:
展开
摘要
【目的】通过对社交网站平台用户行为的分析, 发现社会化小众群体中的核心用户, 为社会化资源推荐服务提供参考。【方法】收集豆瓣读书用户的1 208个标签, 对排名前100位的标签建立标签共现矩阵, 分析用户的K-核网络结构, 研究用户的K-核塌缩序列的波动情况。【结果】与度数中心度、最小K-核深度值等方法相比, 基于K-核塌缩序列方法发现了新的社会化小众群体中的核心用户。【局限】样本数据规模较小且局限于某领域, 排序问题不能得到很好的解决, 需要进一步改进K-核分析方法。【结论】本研究有利于社交网站平台的管理者制定或改进新的资源推荐策略, 从而促进社交网站平台更好地发展。
关键词:
Abstract
[Objective] This study aims to identify the core users in social minority groups with the help of social network behavior analysis technique, and then improve the service of social resources recommendation. [Methods] First, we collected 1,208 user tags from the website of Douban Reading, and built co-occurrence matrix for the top 100 tags. Second, we analyzed these users’ K-shell network structure and then investigated its collapse sequences volatility. [Results] We found new core users from the social minority group using the proposed method. [Limitations] The sample data size was relatively small and from only one specific field. The K-shell analysis method needed to be modified to improve the result ranking. [Conclusions] The proposed method could help the social media administrators develop new resources recommendation strategy, and promote the development of social networking systems.
Keywords:
目前, 互联网大数据问题日益严重, 互联网每天产生的数据可以刻满约1.68亿张DVD光盘, 这些数据蕴含着用户的信息行为, 即“标签”, 它与另外两个要素: 用户和资源, 已经成为社会化推荐研究的主要对象[1-2], 如何深度挖掘通过标签建立的用户关系网络, 为用户提供精准的符合其兴趣偏好的资源是信息学界和管理学界等关注的研究热点之一[3], 也是未来10年中非常重要的信息服务方向及研究课题[4]。
在社会化网络服务中, 与大众化的信息需求相比, 用户对资源的需求偏好分布呈长尾特征, 趋向于小众化[5], 用户更需要个性化的信息。而传统的过滤式的社会化资源推荐主要集中于大众的流行的信息, 很难发现小众社区中用户的需求。因此, 一方面, 用户需要获取深层次的个性化信息[6]; 另一方面, 用户作为偏好社区的一员, 与社区中其他用户具有相同或相似的需求, 因此用户与资源之间由于关联关系结构而形成和表现出小众化的结构特征, 即小众社区[5]。在多维语义关系(如浏览、评论、转发等)的虚拟社交社区, 社区内每个用户都有可能成为领域内的小众核心用户[7], 如何利用社交平台资源, 通过社会网络及复杂网络等分析方法分层识别出小众核心用户, 是目前该领域内需要解决的重要问题。
国内外与核心用户相关的研究主题主要有“意见领袖”与“小众专家”, 如Momtaz等[8]利用社会网络分析法综合考虑中心点、结构洞、点入度等辨别出意见领袖; Zhang等[9]设计基于时间序列的社群抽取及意见领袖挖掘的聚类算法, 并以天涯社区为例, 通过实证证明该算法的可行性; Gnambs等[10]对意见领袖的知识和特点建立了适度模型; 王国华等[11]和顾品浩等[12]从突发性事件中对意见领袖的识别和挖掘进行分析; 李纲等[13]以MetaFilter为样本数据来源, 从中介中心性和聚类系数的角度细化小众专家, 判别不同时期小众专家的用户特征及扮演的角色; 陈福集等[14]从意见领袖的引导作用研究其在舆情事件中的影响机制。
总体上, 利用社会网络分析方法进行社会化资源推荐时, 重点是如何识别关系网络中的核心用户, 许多学者主要从传统的度中心性、介数中心性、近邻中心性等角度分析, 部分学者从K-核值的角度分析, 如He等[15]利用K值越大, 其传播能力就越强的特点, 研究微博中个性化信息推荐; Kitsak等[16]认为社区中传播效率较高的用户一般存在于K-核分解中; 周漩等[17]提出重要度评价矩阵识别网络中的最重要用户, 分析了K-核值很小的用户的传播能力; 任卓明等[18]利用邻居用户的K-核信息分析K-核值较小用户的传播能力。而很少学者从K-核塌缩序列的角度分析核心用户。本文主要利用K-核塌缩序列识别用户关系网络的总体分裂性, 发现核心用户及其所在的小众社区, 将其所掌握的资源推荐给其他用户。
在社会化资源推荐过程中, 按照核心用户的发现过程构建如图1所示的社会化资源推荐模型。首先构建用户关系网络, 并对其进行K-核分解, 构建用户的K-核塌缩序列, 分析网络的总体分裂性, 如果存在分裂, 则能够发现其中的核心用户; 然后进行高密度子群筛选, 发现小众社区; 最后将核心用户所掌握的信息推荐给小众社区的其他用户, 完成社会化资源推荐。
K-核是研究复杂网络的层次结构非常有效的方法, 从中可以发现具有凝聚性的子群, 它是以度数为基础的一种测量标准, Seidman[19]认为对成分结构的研究可以运用最小度标准, 以便区分高、低凝聚力的领域。对一个图的“K-核”结构分析是对密度测度的一个重要补充, 一个K-核是一个最大子图, 其中的每个用户都至少与其他K个用户连接: 每个用户的度数都至少为K。一个简单的成分就是一个“1-核”, 其中所有用户都相连, 因而其度数至少为1; “2-核”就是去掉所有度数为1的用户, 考察剩余各个用户之间的关联结构, 它是由度数为2的剩余关联用户组成的, 其他的以此类推。
对于一个无向图G=(V, E), V为用户, E为用户之间的标签共现集, 在集合W 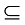
图2中, n位用户可以进行4种分区, 其度数分别为2、3、5、6, 其中6-核是最大的连通子图, 包括的用户也处于核心-边缘图的核心区, 其中的每个用户至少与图中的其他6个用户相连。从最大的6-核到5-核、3-核, 最后是最小的2-核, 大核都是小核的子图, 在小核中可以完全找到大核中包含的用户。从小核到大核聚类的过程中, 每级可能会产生剩余用户。
K-核是在整个图中的一个凝聚力相对较高的区域, 但它不一定是最大的凝聚子图, 因为有可能存在一些相互之间联系松散, 但却有很高凝聚力的区域, 即网络存在总体分裂性。Seidman[19]用核塌缩序列来估计一个网络的总体分裂性, 核塌缩序列主要针对的是网络中每次升级聚类产生的剩余用户, 一个K-核中的点可以分为两个集合: 在K+1中的点和不在该核中的点。Seidman[19]将后一群体称为K-剩余集合, 每当K增加一个单位, 从核中消失的点所占的比例可以排列为一个向量(即一行简单的数值), 可用该向量描述成分内部的局部密度结构, 如果向量中的值持续增加到比较高的K值, 说明网络的结构具有一致性, 如果向量中的K值在较低的值出现以后持续出现了0值, 说明网络中存在多个高密度区。
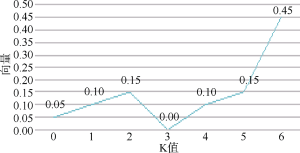
表1为K-核的塌缩示意图, 随着K-核的逐渐塌缩, K值在从0到6增加的过程中产生了许多剩余用户, 得到的核塌缩序列为: (0.05, 0.10, 0.15, 0.00, 0.10, 0.15, 0.45), 具体的序列变化如图3所示。
表1 K-核塌缩示意图
| K值 | 剩余用户 | 剩余点 所占比例 | 颜色 | |
|---|---|---|---|---|
| 0 | U5 | 0.05 | 粉色 | |
| 1 | U11、U3 | 0.10 | 黑色 | |
| 2 | U2、U14、Un-2、Un | 0.15 | 蓝色 | |
| 3 | 0 | 0.00 | ||
| 4 | U4、U15 | 0.10 | 灰色 | |
| 5 | U1、Un-1 | 0.15 | 红色 | |
| 6 | U12、U13、U9、U10、U6、U7、U8、U16、U17 | 0.45 | 浅绿色 | |
在图3中, 当K处于[0, 2]时, 向量值由0.05到0.15; 然后, 当K为3时, 向量值为0, 塌缩序列有小幅变动, 向量值整体上逐渐增大, 所以K分别为4和5时会产生高密子群, 即分别以用户(U4、U15、U1、Un-1)为中心, 即子群(U4、U15、U6、U13)、(U1、U10、U12、U13、U17、Un-1), 它们是除了常见的6-核子群(U12、U13、U9、U10、U6、U7、U8、U16、U17)之外发现的小众社区。
对于第1个子群, 可以将U4、U15的资源偏好推荐给小众社区中其他用户; 同理, 对于第2个子群, 可以将U1、Un-1的资源偏好进行推荐。
通过豆瓣的“读书”页面对用户数据进行随机抓取, 从每个用户关注的其他用户中随机选取样本, 同时采用滚雪球的方式展开, 共取得35位用户的资料, 为方便统计, 每个用户均赋予编号, 同时每个用户的标签是去掉重复标注次数后得到的数量, 35位用户的最终标签数是1 208。
对35位用户的所有标签进行频次降序排序, 截取其中排名前100位的标签, 数据如表2所示, 其中“文学”的频次最高, 说明35位用户中喜好文学的较多。
表2 豆瓣数据标签频次排序(部分)
| 序号 | 标签 | 频次 | 序号 | 标签 | 频次 | 序号 | 标签 | 频次 |
|---|---|---|---|---|---|---|---|---|
| 1 | 文学 | 21 | 14 | 女性 | 6 | 27 | 香港 | 4 |
| 2 | 散文 | 12 | 15 | 社会 | 6 | 28 | 文化 | 4 |
| 3 | 历史 | 11 | 16 | 生活 | 5 | 29 | 张爱玲 | 3 |
| 4 | 日本 | 10 | 17 | 随笔 | 5 | 30 | 爱情 | 3 |
| 5 | 传记 | 8 | 18 | 设计 | 5 | 31 | 科普 | 3 |
| 6 | 短篇集 | 8 | 19 | 美国 | 5 | 32 | 故事 | 3 |
| 7 | 漫画 | 8 | 20 | 管理 | 5 | 33 | 音乐 | 3 |
| 8 | 外国 | 8 | 21 | 英国 | 5 | 34 | 梦想 | 2 |
| 9 | 小说 | 6 | 22 | 摄影 | 5 | 35 | 安妮宝贝 | 2 |
| 10 | 绘本 | 6 | 23 | 旅行 | 5 | 36 | 张大春 | 2 |
| 11 | 台湾 | 6 | 24 | 童话 | 4 | 37 | 思想史 | 2 |
| 12 | 电影 | 6 | 25 | 上海 | 4 | 38 | 动物 | 2 |
| 13 | 艺术 | 6 | 26 | 经济 | 4 | 39 | 时尚 | 2 |
将35位用户按相应的编号形成标签共现矩阵, 首先按使用频次对标签集合排序, 将排名前37位的标签截取成为样本数据; 然后分析35位用户使用这37个标签的具体情况, 按两位用户同时使用过的标签次数计算, 如果有3次, 则两位用户的标签共现值就为3, 矩阵中对角线均设为某一值, 如0, 表示用户与自身之间的关系; 最后形成标签共现矩阵。
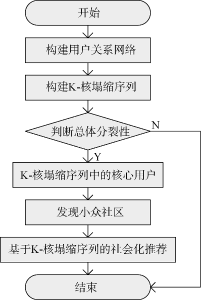
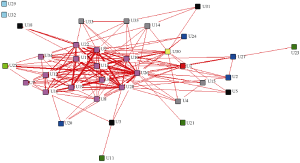
在Ucinet中对豆瓣数据进行K-核分析的结果如图4所示:
图4中, 35位用户可以进行7种分区, 其度数分别为3、4、5、7、8、9、10。10-核是最大的连通子图, 包括的用户也处于核心-边缘图的核心区, 其中的每个用户至少与图中的其他10个用户相连。从最大的10-核到9-核、8-核、7-核、5-核、4-核, 最后是最小的3-核, 大核都是小核的子图, 在小核中可以完全找到大核中包含的用户。
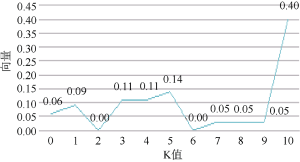
从小核到大核聚类的过程中, 每级可能会产生剩余用户, 表3为豆瓣数据中K-核的塌缩。从0到10增加的过程中产生了许多剩余用户, 得到的核塌缩序列为: (0.06, 0.09, 0.00, 0.11, 0.11, 0.14, 0.00, 0.03, 0.03, 0.03, 0.40), 序列的变化如图5所示。
表3 豆瓣数据中K-核的塌缩
| K值 | 剩余用户 | 所占比例 |
|---|---|---|
| 0 | U29、U32 | 0.06 |
| 1 | U11、U21、U23 | 0.09 |
| 2 | 0 | 0.00 |
| 3 | U3、U5、U18、U31 | 0.11 |
| 4 | U2、U20、U24、U27 | 0.11 |
| 5 | U4、U14、U15、U33、U35 | 0.14 |
| 6 | 0 | 0.00 |
| 7 | U25 | 0.03 |
| 8 | U30 | 0.03 |
| 9 | U1 | 0.03 |
| 10 | U6、U7、U8、U9、U10、U12、U13、 U16、U17、U19、U22、U26、U28、U34 | 0.40 |
图5中, 当K处于[0, 5]区间时, 向量值先从0.06下降到0, 然后又上升到0.14, 虽然塌缩序列有小幅变动, 但向量值整体上是逐渐增大的, 且增加的幅度比较小, 所以此区间的塌缩序列变动可以不予考虑; 但是当在K处于[5, 10]区间时, 向量值首先从0.14降到0, 然后又增加到0.03, 塌缩序列发生了一些变动, 最后当K为10时, 向量值突然增加到0.40, 塌缩序列发生了非常大的变动。所以当K分别为7, 8, 9的时候, 网络会产生三个高密子群, 前两个高密子群均是小众社区, 第一个小众社区(U30、U1、U26、U27、U2、U10)以U30和U1为核心, 第二个小众社区(U25、U26、U34、U12、U16)以U25为核心, 第三个高密子群(U6、U7、U8、U9、U10、U12、U13、U16、U17、U19、U22、U26、U28)以U26和U28为核心, 核心用户可以将其所掌握的资源向其所在的小众社区用户推荐。
(1) 与度数中心度比较
在社会网络分析中, 如果一个用户的中心度越高, 就说明该用户处于网络的核心区, 部分拥有较高度数中心度的用户, 如表4所示:
表4 豆瓣数据的度数中心度
| 用户 | 度数中心度 | 用户 | 度数中心度 |
|---|---|---|---|
| U26 | 82.353 | U6 | 47.059 |
| U28 | 58.824 | U16 | 41.176 |
| U10 | 58.824 | U12 | 41.176 |
| U13 | 58.824 | U1 | 35.294 |
| U9 | 55.882 | U19 | 35.294 |
| U22 | 52.941 | U8 | 32.353 |
| U17 | 50.000 | U30 | 31.238 |
表4中, U26的度数中心度最高, 说明该用户是网络中的核心用户, 依次是U28、U10、U13等, 此表中并没有发现U1、U30的核心地位; 但是从K-核塌缩序列的角度, 却发现U1、U25及U30均为小众社区的核心用户。
(2) 与最小K-核值深度比较
在社会网络分析中, 存在大量的K-核值很小的用户, 一般为边缘用户, 从该类节点的邻居集中的最大K-核值即深度, 可以发现核心用户, 表5是豆瓣数据的最小K-核值(一般为0或1)的深度。
表5中, 由于U21的深度为28, 即该节点的邻居集中的最大K-核值为28, 结合图4, 可以发现邻居U26为核心用户, 但没有发现U1、U25、U28、U30的核心地位。
因此, 利用社会网络分析方法在发现核心用户方面, 与基于度数和最小K-核值深度方法相比, 基于K-核塌缩序列的方法具有一定的优势。
本文在K-核的基础上提出利用K-核塌缩序列发现社会网络群体中的核心用户, 对其所在的小众社区进行小众推荐, 并利用豆瓣网中的读书社交平台提取样本数据, 进行实证分析, 结果证明基于K-核塌缩序列方法发现核心用户与度数、介数、最小K-核深度值等方法相比较具有可行性及优越性。但是, 本文也存在一定的局限性, 一方面仅考察了豆瓣读书用户, 样本数据相对较小; 另一方面由于在K-核值相同的情况下, 无法对核心用户所在小众社区中其他用户进行排序。因此后期工作将不断扩大样本研究数据, 进一步完善和改进K-核塌缩序列排序算法, 为用户提供更好的社会化小众信息资源。
武慧娟: 提出研究思路, 方法设计与实现, 撰写论文;
Jia Tina Du: 提出论文的修改建议;
孙鸿飞: 数据分析;
Jannatul Fardous: 数据收集。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: 413170720@qq.com。
[1] 武慧娟, Jia Tina Du, 孙鸿飞, Jannatul Fardous. usercollection. xls. 用户数据集合.
[2] 武慧娟, Jia Tina Du, 孙鸿飞, Jannatul Fardous. tagmatrix.xls. 标签共现矩阵.
[3] 武慧娟, Jia Tina Du, 孙鸿飞, Jannatul Fardous. networkdensiny. doc. 网络密度图.
[4] 武慧娟, Jia Tina Du, 孙鸿飞, Jannatul Fardous. structure.doc. 核心边缘结构图.

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}