
|
|
李湘东 , 阮涛
, 阮涛
Li Xiangdong, Ruan Tao
中图分类号: TP393 G35
通讯作者:
收稿日期: 2017-07-17
修回日期: 2017-08-17
网络出版日期: 2017-10-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】通过基于维基百科的特征扩展解决由于不同类型文献而产生的特征不匹配等问题, 以提高文本分类效果。【方法】在特征扩展之前, 对TF-IDF加以改进, 提出并使用一种新的特征选择方法CDFmax-IDF获得候选词集; 在使用维基百科进行特征扩展时, 通过分别计算直接链接关系、类别关系、间接链接关系三类词语间关系并进行融合得到词语间的语义相关度实现特征扩展; 针对扩展得到的特征, 提出一种改进的LDA概率主题模型wLDA模型进行文本建模。【结果】本文提出的方法分别在朴素贝叶斯、KNN和SVM三种分类器上实现分类, 其marco-F1和micro-F1分别提升1.6%-2.8%和1.4%-2.7%。【局限】尚未考虑特征词本身及特征词间的相互联系, 比如特征词本身的词性、出现在单篇文档中的位置、特征词间的共现关系等因素对特征词权重的影响。【结论】通过多种对比研究证明了使用基于维基百科的特征扩展方法对特征词扩展的有效性, 提高了多种类型文献的自动分类效果。
关键词:
Abstract
[Objective] This paper aims to improve the performance of text classification systems with the help of Wikipedia’s feature expansion function. [Methods] First, we established the CDFmax-IDF method based on the modified TF-IDF, which helped retrieve the candidate word list. Then, we used the Wikipedia to extend the document features and calculated the relationship among direct links, categories and indirect links, which decided the semantic relevance of the words. Finally, we proposed an improved LDA model, the wLDA, for the extended feature and text modeling. [Results] The proposed method improved the value of marco-F1 and micro-F1 on Naive Bayes, KNN and SVM classifiers by 1.6%-2.8% and 1.4%-2.7%. [Limitations] We did not include the properties of the words and relationship among them. [Conclusions] The feature expansion method based on the Wikipedia improves the effectiveness of automatic document classification methods.
Keywords:
多种类型文献是指包含了图书、期刊、网页、博客等各种传统和当前流行的社交媒体等形式的文献。从信息管理领域来看, 数字图书馆是一种新型图书馆, 它既具有传统图书馆在信息整合、组织管理上的优势, 又同时可以对来自网络的新兴文本资源(如新闻网页、博客微博等)进行整理收集与分类管理[1]; 从大数据领域看, 其最大特点之一就是数据类型的多样化; 除了数值型数据之外, 还包含图书、期刊、网页、博客等形式的文本数据。因此, 不管是传统意义上的信息资源管理研究, 还是当下最前沿的大数据分析, 其对象都包括了多种类型文献。
以多种类型文献为研究对象时, 一个突出的问题是不同类型文献之间对同一事物或主题使用不同的词汇或特征进行描述、产生语义上的差异, 由此导致研究结果的不正确。例如, 网页中通常使用的“电脑”可能被大数据分析为是与学术论文中的“计算机”不同的事物或主题。本文以自动分类为手段, 通过分类效果的客观比较, 找出解决多种类型文献之间语义差异的有效途径。并提出一种基于特征扩展的多种类型文献自动分类方法, 通过解决不同类型文献间自动分类时出现的特征不匹配问题, 从而消除上述的语义差异, 提升多种类型文献自动分类的效果。
面对高速增长的海量网络信息资源, 传统的手工分类和基于专家系统或知识库的半自动分类方法不能有效地对其进行分类与组织, 尤其是面对互联网中多种类型的文本信息, 如何有效地对多种类型的信息资源进行有效组织和管理, 这对当前的自动文本分类技术提出更高的要求[2]。在自动文本分类的研究领域中, 已有相关研究分别以图书书目信息作为训练集、网页新闻文本作为测试集[3], 以期刊论文作为训练集, 以期刊论文、网页和图书等三种类型文献作为测试集[4], 以CiteSeer中的英文研究论文、学术报告等多种类型文本资源分别作为训练集和测试集[5], 开展多种文献类型的自动分类研究。但是, 这些研究对不同类型文献之间可能存在的语义差异未加考虑。
维基百科是目前全球最大的在线协作式百科全书, 常常作为第三方知识库引入到研究之中, 作为词汇或特征的语义扩展研究中的桥梁被使用。文献[6]以维基百科作为第三方知识库进行特征扩展, 使原本只包含较少数量的特征的短文本得以使用语义相近的更多数量的特征加以表达, 从而解决短文本分类中存在的特征稀疏等问题, 其实验结果证明了维基百科在中文文本语义扩展上的有效性。文献[7]首先使用LDA (Latent Dirichlet Allocation)模型[8]对英文文本建模并获得特征词, 再使用维基百科对所抽象出来的特征词进行语义扩展。文献[9]使用维基百科在来自新闻组和讨论组等两种不同的英文语料之间建立语义关系开展分类, 两项研究均通过实验在一定程度上提高了分类效果。因此, 维基百科可以有效地用于解决文本中语义扩展或语义差异等问题。
文献[10]将维基百科作为第三方知识库, 将其应用到不同类型的中文文献的自动分类之中, 通过将来自不同类型文献、语义相近但所使用的词汇不同的特征之间进行扩展和匹配, 在一定程度上提高了分类效果。但是, 该文献的研究内容有三个方面值得探讨。
(1) 采用传统的TF-IDF方法选择特征词; 传统的TF-IDF是一种基本的特征选择方法、得到广泛的使用; 然而, 对该方法本身有许多研究并在不断改进[11-13], 值得借鉴。
(2) 使用向量空间模型(Vector Space Model, VSM)进行文本建模; VSM是一种基本的文本表示模型、得到广泛的应用; 然而, VSM将所有的特征词看作是相互独立的, 无法解决同义词、近义词等语义问题; 而LDA模型可以对文本建模并有效挖掘文本中的语义信息, 已经广泛用于包括文本分类在内的各个领域, 并取得较好的分类效果[14-17], 可以考虑将其替代VSM用于不同类型文献自动分类时的文本表示模型。
(3) 在使用维基百科计算词语相似度时, 主要使用了直接链接关系、类别关系、间接链接关系等三类词语间关系, 其中, 类别关系和间接链接关系分别借鉴了其他论文中的计算方法, 相对比较复杂, 有进一步简化的可能。
为适应不同领域或学科的多种类型文献之间可能存在的语义差异, 本文在三个方面开展了与文献[10]不同的研究, 希望提供与文献[10]不尽相同的解决途径。在特征选择方面, 对传统TF-IDF公式进行改进, 引入类间聚集度和类内分散度两个概念, 得到改进的CDFmax-IDF公式进行特征选择; 在基于维基百科的相关度计算方法方面, 对类别关系和间接链接关系使用简洁的Jaccard相似系数公式计算, 并对融合公式进一步优化; 使用LDA模型代替VSM进行文本建模, 将LDA的权重更新公式改进为可以对非整数进行训练, 从而得到wLDA模型, 进行文本表示。
随着网络数字资源的急剧增加, 以数字资源为对象的各种研究和应用, 例如, 大数据分析、数字资源分类等向各个领域快速普及。以数字资源为研究对象时, 主要问题在于不同类型间的文献存在一定的语义差异, 比如在描述同一事物时, 图书期刊等类型的文献偏向于使用事物的学名或规范名称, 而新闻网页等类型的文献偏向于使用事物的俗称或常用名, 这就导致了在进行文本建模时会出现特征不匹配的问题, 而文本建模是大数据分析、数字资源分类的前提和基础, 不解决语义差异的问题, 意味着文本建模不能反映大数据分析的对象和数字资源分类的对象的实际, 必然会影响大数据分析和数字资源分类的结果。本研究通过借助第三方知识库来消除不同文献类型文本间的语义差异, 从而提升多种类型文献的自动分类效果, 有助于在大数据环境下对多种类型文献进行良好的建模, 以实现各种新兴类型和传统类型文献资源的分析、组织与整理工作。本文在这样的背景下进行选题并开展研究, 因此具有较高的理论及实用价值。
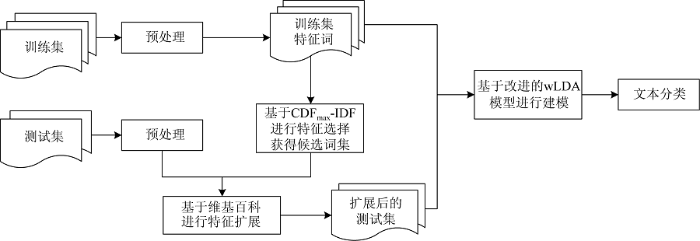
本文大致分为以下步骤进行: 对TF-IDF加以改进, 提出并使用一种新的特征选择方法CDFmax-IDF获得特征扩展候选词集; 基于特征扩展候选词集, 对测试集文本使用维基百科中的语义相似度计算进行特征扩展; 针对扩展得到的带权特征, 提出一种改进的LDA概率主题模型wLDA模型进行文本建模。其框架如图1所示。
TF-IDF特征选择方法综合考虑词频和逆文档频率两个因素, 认为某特征词在文档中出现的次数越多, 且只在很少的文档中出现, 说明该特征就越重要[18]。但是传统的TF-IDF由于未考虑特征的分布情况而未能选择出更具代表性特征。文献[11]针对传统TF-IDF的不足, 提出类间分散度和类内分散度两个概念并将其与传统TF-IDF相结合, 对基于TF-IDF的特征加权算法进行改进; 文献[12]引入类间集中度和类内分散度两个重要概念, 并对文献[11]中的公式进行重新定义, 主要区别在于计算时仅使用特征项的文档频率作为唯一参数, 减少了计算的复杂程度, 且通过实验验证其与文献[11]方法同样可以选择出更具类别区分能力的特征。最后, 再结合频度因素提出一种改进的基于TF-IDF的特征加权算法。该算法认为如果某一个特征项的频度越高、在类别间分布越聚集且在类别内分布越分散, 那么该特征对文本类别的区分作用就越大, 即分辨度越强。文献[13]将文献[12]的方法应用到LDA主题模型中, 进一步验证了文献[12]提出的改进的TF-IDF特征加权算法的有效性。但是, 文献[12-13]在计算类间聚集度时, 由于使用的是文档频率而未能反映出特征频度。因此, 本文在保留文献[12-13]的类间聚集度和类内分散度两个概念的基础上, 使用基于特征词频的类间聚集度代替文献[12-13]中基于文档频率的类间聚集度。
类间聚集度和类内分散度主要从特征词在类别间以及类别内分布情况的角度进行特征权重的考量, 克服了传统TF-IDF在计算特征权重时没有综合考虑类间、类内特征分布所存在的不足。而基于特征词频的类间聚集度不仅可以反映类别间的分布情况, 还可以反映出频度信息。所以本文在最终改进的TF-IDF中去掉了特征词频tfi(t), 这样有助于降低算法的计算复杂度。通过引入基于特征词频的类间聚集度和类内分散度两个参数, 本文提出一种改进的CDFmax-IDF特征选择算法, 其计算公式如下:
$CD{{F}_{\max }}\text{-}IDF(t)=\underset{i=1}{\overset{k}{\mathop{\max }}}\,(I{{C}_{i}}(t)\cdot I{{D}_{i}}(t))\cdot \log (\frac{\left| D \right|}{\sum\limits_{i=1}^{k}{d{{f}_{i}}(t)}+\varepsilon })$ (1)
其中, k表示总类别数, |D|表示文本集中文档总数, dfi(t)表示在第i个类别中特征词t的文档频数, ε为平滑因子, ICi(t)表示类别Ci下特征词t的基于特征词频的类间聚集度, IDi(t)表示类别Ci下特征词t的类内分散度, 对其乘积结果按类别取最大值。
(1) 基于维基百科的语义相关度计算
①直接链接关系
维基百科中的任意一个概念的解释页面中存在大量其他概念的引用, 引用概念和被引用概念之间往往存在极强的相关性, 因此概念间是否存在链接关系通常被作为衡量概念间相关度的一项重要指标[19]。如果概念t1的解释页面中含有概念t2的链接, 则称概念t1是概念t2的链入链接或概念t2是概念t1的链出链接。此时, 若概念t2也是t1的链入链接, 则称概念t1与概念t2之间存在双链接关系, 反之则称为单链接关系。
②链接相关度
链接相关度是通过衡量维基百科中任意两项概念拥有共同链入、链出概念的数量及其相互间的覆盖程度来确定的概念间的相关度。维基百科中的每一项概念都拥有两个相关的链接集合——链出概念集和链入概念集, 分别是由该概念的链出概念和链入概念构成。利用Jaccard相似系数可以很容易地衡量两个集合之间的相似性[20], 其计算公式如下:
$JS(A,B)=\frac{\left| A\bigcap B \right|}{\left| A\bigcup B \right|}$ (2)
其中, A、B分别代表两个集合。$A\bigcap B$表示A、B两集合的交集; $A\bigcup B$表示A、B两集合的并集。
本文基于Jaccard相似系数计算两个维基概念的链接相关度。首先分别从维基百科中查找出概念t的链入概念集和链出概念集:
$\begin{align} & inlinks(t)=\{inlin{{k}_{t1}},inlin{{k}_{t2}},inlin{{k}_{t3}},\cdots \} \\ & outlinks(t)=\{outlin{{k}_{t1}},outlin{{k}_{t2}},outlin{{k}_{t3}},\cdots \} \\ \end{align}$ (3)
通常认为一个概念的链入概念和链出概念都是该概念的相关概念, 即链入概念集和链出概念集都具有概念表征能力, 因此基于Jaccard相似系数得到的概念链接相关度计算公式如下:
$\begin{align} & si{{m}_{link}}({{t}_{i}},{{t}_{j}})=\alpha \cdot \frac{\left| inlinks({{t}_{i}})\bigcap inlinks({{t}_{j}}) \right|}{\left| inlinks({{t}_{i}})\bigcup inlinks({{t}_{j}}) \right|}+ \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \beta \cdot \frac{\left| outlinks({{t}_{i}})\bigcap outlinks({{t}_{j}}) \right|}{\left| outlinks({{t}_{i}})\bigcup outlinks({{t}_{j}}) \right|} \\ \end{align}$ (4)
其中, α和β是权重参数, 满足α+β=1, 本文利用其计算概念间相关度时, 认为链入概念集和链出概念集拥有同样的表征, 故选取α=β=0.5。
③类目相关度计算
由于维基百科中的任意一项概念都至少属于一个类目下, 换句话说, 每一个维基概念都会拥有一个属于它的所属类目集:
$categories(t)=\{categor{{y}_{t1}},categor{{y}_{t2}},categor{{y}_{t3}},\cdots \}$ (5)
因此, 同样可以利用Jaccard相似系数计算方法实现两个概念间类目相关度的计算, 但值得注意的是, 在维基百科中的类目存在包含与被包含的关系, 且层级越高的类目往往拥有更多的从属概念, 所以不能直接使用Jaccard相似系数表征两个概念间的类目相关度。本文在计算类目相关度时, 对Jaccard相似系数进行加权改进, 以此平衡不同层级类目在计算相关度时的权重问题, 其具体计算公式如下:
$\left\{ \begin{align} & si{{m}_{cate}}({{t}_{i}},{{t}_{j}})=\frac{\sum\limits_{c}^{categories({{t}_{i}})\ \bigcap categories({{t}_{j}})}{weight(c)}}{\sum\limits_{c}^{categories({{t}_{i}})\bigcup categories({{t}_{j}})}{weight(c)}} \\ & weight(c)=\frac{1}{{{n}_{c}}} \\ \end{align} \right.$ (6)
其中, nc代表类目c的从属概念数量, 即用类目的从属概念数量的倒数替代原始公式中的类目本身, 从而对Jaccard相似度计算公式进行加权, 这么做可以让共同从属于较低层级类目的两概念之间获得更高的相关度计算结果。
④概念相关度计算
概念相关度计算是指对任意两个存在于维基百科中的概念, 通过定义一个合理的计算公式以准确度量两个概念间的语义相关度, 并且要求该相关度计算结果高的概念间需要能够从很大程度上说明这两个概念具有非常紧密的语义联系或通常在描述同一特定领域时共现[21]。综合考虑上述概念之间的三种关系的相关度计算公式, 本文提出一种新的概念相关度方法:

其中, α、β为可调参数, 且α+β=1, 用来调节链接相关度与类目相关度的参考权重。δ(x)是关于概念t1、t2直接链接关系的示性函数, 系数η1、η2取值大于1, 代表对拥有直接链接关系的两项维基概念的相关度计算结果进行不同程度的加权, 这样能尽可能保证拥有直接链接关系的概念能够被准确赋予更高的相关度。
(2) 基于语义相关度的特征扩展方法
基于语义相关度的特征扩展方法主要步骤如下:
①对整个文本集中的文本进行分词、词性过滤、停用词过滤等操作;
②对训练集文本进行特征选择, 得到特征扩展候选词集;
③对测试集中的每一篇文档, 利用提出的基于维基百科的相关度计算方法, 依次计算其与特征扩展候选词集中各特征词的相关度, 完成特征扩展。
(1) 标准 LDA模型
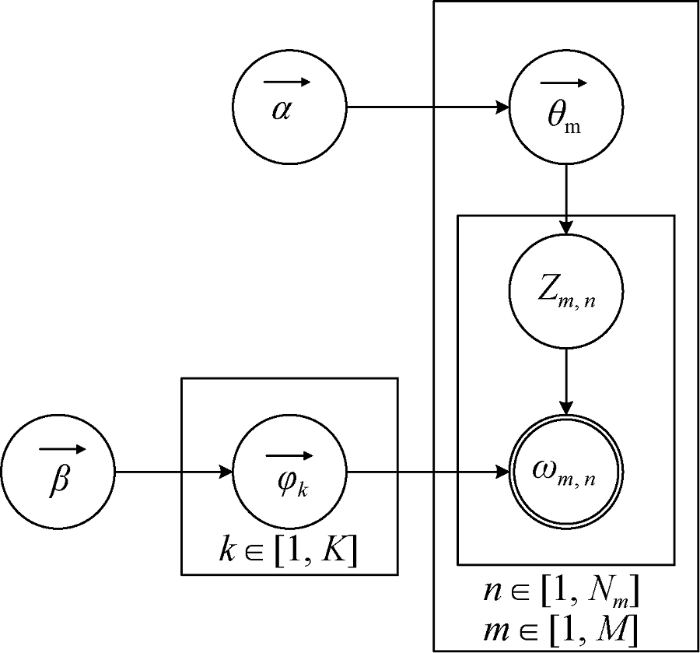
LDA模型是Blei在PLSI模型的基础上, 引入贝叶斯思想后提出的一种全新的概率生成模型。LDA模型在文本生成模型中引入了多项分布的共轭先验分布——狄里克雷(Dirichlet)分布, 从而构建了一个从词到主题, 再从主题到文档的三层结构概率文本表示模型。LDA主题模型的概率模型图[22]如图2所示。
其中, M表示文档总数, Nm表示第m篇文档中存在Nm个特征词, $\overrightarrow{{{\theta }_{m}}}$代表文档-主题的概率分布, $\overrightarrow{{{\varphi }_{\text{k}}}}$代表了主题-词的概率分布, K表示主题总个数, $\overrightarrow{\alpha }$和$\overrightarrow{\beta }$分别是两个分布的超参数, ${{Z}_{m,n}}$是由分布$\overrightarrow{{{\theta }_{m}}}$生成的第m篇文档中第n个词即${{\omega }_{m,n}}$的所属主题。
(2) LDA主题模型的求解及评价
①模型求解
LDA模型通常采用吉布斯采样方式估计特征词$\omega $和主题z的后验分布。吉布斯采样的计算公式[8]为:
$p({{z}_{i}}=k|{{\vec{z}}_{\neg i}},\vec{w})\propto \frac{n_{m,\neg i}^{(k)}+{{\alpha }^{(k)}}}{\sum\limits_{j=1}^{K}{(n_{m,\neg i}^{(j)}+{{\alpha }^{(j)}})}}\cdot \frac{n_{k,\neg i}^{(t)}+{{\beta }^{(t)}}}{\sum\limits_{j=1}^{V}{(n_{k,\neg i}^{(j)}+{{\beta }^{(j)}})}}$ (8)
其中, ${{z}_{i}}$表示第i个特征词对应的主题变量, ${{\vec{z}}_{\neg i}}$表示k≠i时特征词编号的主题分布, $n_{m,\neg i}^{(k)},n_{k,\neg i}^{(t)}$分别代表第m篇文档中主题k的频数以及主题k中特征词t的频数。
根据狄里克雷分布的参数估计公式可得:
$\begin{align} & {{{\hat{\theta }}}_{mk}}=\frac{n_{m,\neg i}^{(k)}+{{\alpha }^{(k)}}}{\sum\limits_{j=1}^{K}{(n_{m,\neg i}^{(j)}+{{\alpha }^{(j)}})}} \\ & {{{\hat{\varphi }}}_{kt}}=\frac{n_{k,\neg i}^{(t)}+{{\beta }^{(t)}}}{\sum\limits_{j=1}^{V}{(n_{k,\neg i}^{(j)}+{{\beta }^{(j)}})}} \\ \end{align}$ (9)
${{\hat{\theta }}_{mk}},{{\hat{\varphi }}_{kt}}$分别代表第m篇文档中选取主题k的概率估计以及主题k中选取特征词t的概率估计。
②模型评价
LDA主题模型本质上是一种文本聚类算法, 所以在利用LDA进行文本建模的时候, 需要事先指定主题数, 常用的指标有主题相似度[23]、困惑度[24]等, 本研究将选择困惑度作为确定最优主题数的方法。随着主题数的逐渐增大, 困惑度会一直减小, 但最终其值会趋于平稳。因此通过综合考虑困惑度和主题数的比率, 可以在合理范围内选取最合适的主题数, 得到最优的文本概率模型。
(3) 改进的LDA模型
标准LDA主题模型在通过吉布斯采样训练模型参数的时候, 是利用特征词的频数对参数进行迭代更新, 这样会使文档的主题明显倾向于高频词的主题分布, 从而影响分类效果。另一方面, 根据上文所述的特征扩展方法得到的扩展词以[0,1]的相关度被扩展到文本集中、形成带有权值的扩展特征, 这样的参数更新方式并不能对这些带有权值的扩展特征进行吉布斯采样, 因此有必要对标准LDA模型的求解方式进行改进, 改进后的吉布斯采样公式为:
$\begin{align} & p({{z}_{i}}=k|{{{\vec{z}}}_{\neg i}},\vec{w})\propto \frac{weight(n_{m,\neg i}^{(k)})+{{\alpha }^{(k)}}}{\sum\limits_{j=1}^{K}{(weight(n_{m,\neg i}^{(j)})+{{\alpha }^{(j)}})}}\cdot \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \frac{weight(n_{k,\neg i}^{(t)})+{{\beta }^{(t)}}}{\sum\limits_{j=1}^{V}{(weight(n_{k,\neg i}^{(j)})+{{\beta }^{(j)}})}} \\ \end{align}$ (10)
利用改进的weight-LDA(简称wLDA)模型, 可以对特征扩展后的文本进行主题建模, 从而使用分类算法进行文本分类。
(4) 基于wLDA模型的分类流程
结合前文的特征扩展方法, 本文提出结合特征扩展和改进的wLDA主题模型的文本分类算法, 其具体流程如下:
①对训练集和测试集的文本进行分词、词性过滤、停用词过滤等操作;
②对训练集文本进行初步统计, 通过本文提出的CDFmax-IDF特征选择算法筛选出特征扩展候选词集, 并通过维基词典进行过滤, 即选取在维基百科中能找到对应概念的特征词;
③针对测试集中的每一篇文档, 利用基于维基百科的相关度计算方法依次计算文档中的每一项特征词和特征扩展候选词集中每一项特征词的相关度, 将相关度大于某一阈值的特征词扩展到测试集文本中, 形成包含带有权值的扩展特征的新测试集文本;
④使用常见的几种分类算法对训练集建模, 对测试集进行分类并评价分类效果。
本实验利用期刊论文为主的文献信息构成训练语料, 对以新闻网页为主要类型的文献信息进行分类实验, 实现多种文献类型的文本自动分类。为使实验过程与结果满足公开原则与可复现性, 本文实验所用语料全部取自复旦大学中文语料库[25]和搜狗互联网语料库[26], 其中复旦语料库以期刊文本和学术论文为主, 搜狗语料库主要由新闻网页文本组成。本实验选取复旦语料库与搜狗语料库中共有的经济、体育、环境三个类别语料各800篇, 其中复旦语料库中各抽取500篇组成训练语料(共1 500篇), 搜狗语料库中各抽取300篇组成测试语料(共900篇), 为避免随机干扰项对实验结果造成影响, 在公开语料集上利用多次随机抽取的文本集进行实验, 对实验数据取平均值作为最终的实验结果。
(1) LDA主题模型中最优主题数的确定:其基本过程为对训练集在不同主题数下进行多次LDA主题建模, 并分别计算其困惑度, 再根据困惑度的变化趋势确定最合理的主题个数。
(2) 扩展特征语义相关度计算结果的考量。本文解决多种文献类型文本分类的主要思路是通过特征扩展来消除训练集与测试集间的语义差异, 而特征扩展的核心则是计算特征间的语义相关度, 但对语义相关度计算结果的考量并没有一种权威的测度方式, 因此将随机抽取几组特征的语义相关度计算结果, 通过人工审查的方式对计算结果是否合理做出合理的定性判断。
(3) 本文分类方法分类结果的对比验证。为了验证本文提出的基于特征选择的多种文献类型文本自动分类方法的有效性, 通过在多种经典的自动分类算法上进行分类实验, 分别对是否使用本文提出的分类方法的分类效果进行比较分析, 从而论证本文提出的改进方法的可行性和有效性。
(1) 最优主题数的确定
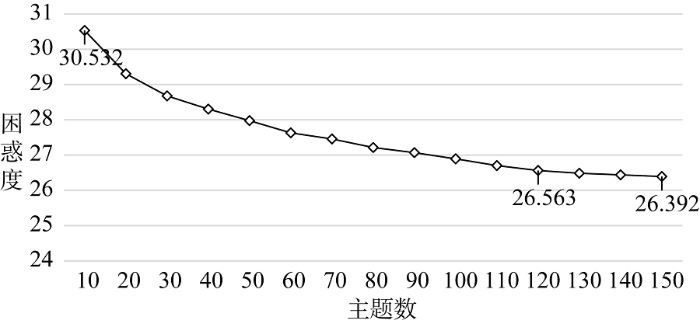
本文使用困惑度来确定LDA模型的最优主题数, 使用吉布斯采样法求解LDA模型的参数, 其中超参数α、β根据经验分别设置为50/t(t为主题数)和0.01, 对训练集迭代次数为1 000次。本实验中对主题数进行从10到150的预设(梯度为10)分别计算该主题数下的困惑度, 绘制成趋势图如图3所示。
由图3可知, 困惑度随着主题数逐渐增大而下降, 且下降趋势逐渐平稳, 本文选取困惑度下降趋势明显放缓的第一个拐点作为本实验中LDA模型的最优主题数, 因此选取120作为后续LDA建模的最优主题数。
(2) 扩展特征语义相关度计算结果
特征扩展是本文解决多种文献类型文本分类方法的核心环节, 而语义相关度计算结果的准确与否是决定特征扩展最终效果的直接影响因素。在进行特征扩展前, 先分别使用TF-IDF方法和本文提出的CDFmax-IDF特征选择方法从训练集中提取特征扩展候选词集。表1为一次实验中使用TF-IDF特征选择方法提取的候选词集(取前45个特征词)。
表1 基于TF-IDF方法的特征扩展候选词集
| 关键词 |
|---|
| 经济、体育、企业、发展、市场、浓度、社会、政府、产业、改革、增长、投资、我国、土壤、国有、消费、制度、地区、吸附、技术、图、结构、政策、中国、工业、降解、专业、农村、资本、水、管理、菌、国家、农业、知识、污泥、生产、要、研究、产品、教育、环境、体制、氧、人、…… |
使用传统TF-IDF方法进行特征选择得到的候选词集中存在许多诸如“中国”、“要”、“人”这类相对高频但却不具有类别区分能力的特征词, 如果将这类特征词作为候选词会在特征扩展的同时引入大量的“噪声”而影响分类结果。表2是则使用本文提出的CDFmax-IDF特征选择方法提取的候选词集(每个类各取前15个特征词), 通过对比可以说明本文提出的特征选择方法的有效性。
表2 基于CDFmax-IDF的特征扩展候选词集
| 类别 | 关键词 |
|---|---|
| 经济 | 资本、经济增长、企业、经济发展、市场、政策、金融、价格、投资、增长、资金、国民经济、利益、劳动力、市场经济、…… |
| 体育 | 比赛、队、体育、运动员、冠军、选手、成绩、队员、女子、速率、决赛、训练、胜、力量、中国队、…… |
| 环境 | 环境科学、浓度、中国环境、scientiae、水、污染、污染物、化学、温度、试验、生物、离子、含量、pollution、监测、…… |
表2对筛选得到的类别关键词进行了类别区分, 便于观察特征词是CDFmax-IDF计算结果取最大值时的所属类别以及其类别归属本身的合理性。在实际实验过程中利用关键词集进行特征扩展时是不区分其所属类别的, 而是将所有关键词汇总在一起不作区分地计算语义相关度并与阈值进行比较确定是否被扩展。表3是一次实验中对待分类文本的几个特征词进行特征扩展时得到的语义相关度计算结果。
表3 语义相似度计算结果
| 特征词 | 扩展特征词及语义相关度 |
|---|---|
| 市场 | 交易:0.102 金融市场:0.211 劳动力市场:0.212 批发:0.224 |
| 股东 | 股票市场:0.146 |
| 净利润 | 资金:0.111 增长率:0.136 市场化:0.108 负债:0.172 |
| 女排 | 排球:1.000 |
| 王宝泉 | 袁伟民:0.115 |
| 亚军 | 冠军:0.709 金牌:0.106 银牌:0.274 |
| 环境监测 | 污染:0.346 污染物:0.100 富营养化:0.148 |
| 凝固 | 蒸发:0.288 |
| 污水处理 | 水质:0.173 水污染:0.357 生活污水:0.112 |
表3从三个类中各列举了三个特征词扩展结果作为代表, 不难看出扩展得到的特征词确实与原特征词具备很强的语义关联, 如“市场”与“交易”、“金融市场”、“劳动力市场”等。与此同时也可以充分反映出不同扩展特征词与原特征词间的关联强弱差异, 比如“亚军”与“冠军”、“金牌”、“银牌”间的语义相关度为“冠军”>“银牌”>“金牌”, 这基本符合一般认知。因此, 利用维基百科进行的语义相关度计算方法, 不仅能对互为同义词、近义词的特征词进行扩展, 还能利用维基百科中蕴含的领域知识, 将类似“王宝泉”与“袁伟民”这样只有具备相当领域背景知识才能正确识别和处理的相关特征词进行扩展。
通过以上分析可以证明本文提出的基于维基百科的特征扩展方法确实能够对待分类文本进行恰当的特征扩展处理, 接下来再通过分析对比最终的分类实验结果论述特征扩展后得到的新的待分类文本可以更容易地被正确自动分类。
(3) 本研究分类方法的对比验证
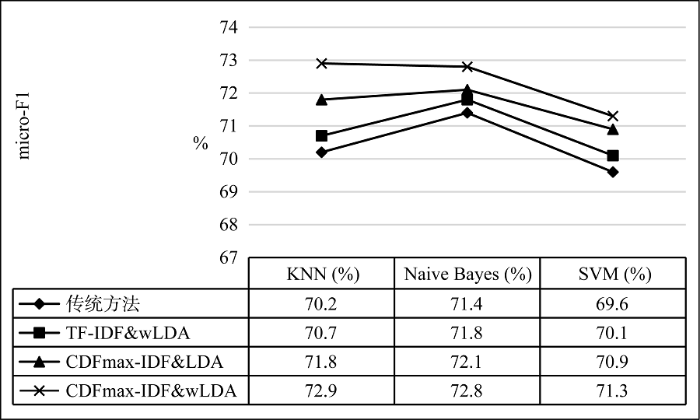
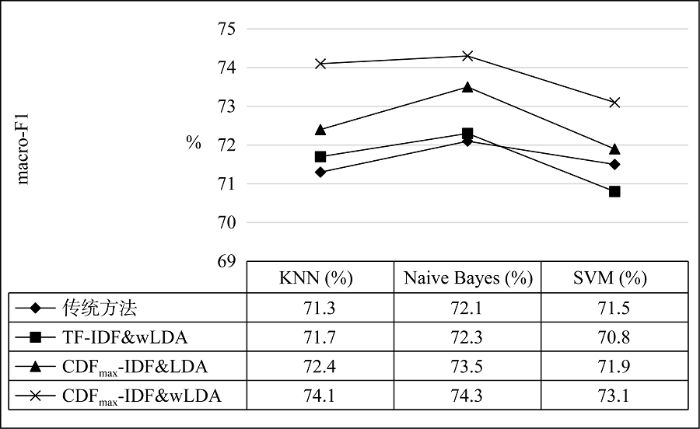
为了验证本文提出的基于特征选择的多种文献类型文本自动分类方法的有效性, 通过在三种经典的自动分类算法(K最近邻算法、朴素贝叶斯算法、支持向量机算法)上进行分类实验, 分别比较是否使用本文提出的分类方法的效果, 如图4和图5所示。
根据图4、图5展示的实验结果, 分别使用macro-F1和micro-F1两种评价指标对本研究中涉及的对比实验进行评价。在三种经典分类算法上分别比较特征扩展前后的分类结果, 其中朴素贝叶斯算法的平均表现最好, macro-F1和micro-F1在使用本文改进的特征扩展方法后准确率分别达到了74.3%和72.8%, 较未进行扩展的结果分别提升了2.2%和1.4%; 而在使用了本文提出的改进方法后使用KNN算法进行分类的marco-F1和micro-F1分别提升了2.8%和2.7%, 是三种分类算法中提升最为明显的; 在使用SVM算法的分类结果上, 本文提出的特征扩展方法marco-F1和micro-F1分别提升了1.6%和1.7%。同时为证明本文提出改进的特征选择方法和wLDA主题模型的有效性, 还分别设置了TF-IDF&wLDA方法及CDFmax- IDF&LDA方法的对照组进行实验, 结果表明本文提出的新的文本分类方法均优于另外两种只进行其中一种改进的分类方法。综上, 本文提出的基于特征扩展的多种类型文献自动分类方法是可行且有效的。
本文提出一种基于特征扩展的多种类型文献分类方法, 通过利用维基百科作为第三方知识库消除不同文献类型文本间的语义差异, 由此提高多种类型文献混合自动分类的分类效果。针对传统TF-IDF的不足, 对TF-IDF加以改进, 提出并使用一种新的特征选择方法CDFmax-IDF获得特征扩展候选词集; 在使用维基百科进行特征扩展时, 通过分别计算直接链接关系、类别关系、间接链接关系三类词语间关系并进行融合得到词语间的语义相关度进行特征扩展; 针对扩展得到的带有权值的特征, 提出一种改进的LDA概率主题模型wLDA模型进行文本建模, 使特征词被赋予了不同权重, 提高了LDA模型本身的精度和准确性。
本文通过实验论证了提出的基于维基百科的特征扩展方法能在一定程度上提高多种类型文献自动分类的分类效果, 但本方法实际上还存在诸多局限性, 比如改进后的CDFmax-IDF特征选择方法虽然在继承了TF-IDF优点的基础上又综合考虑了特征词在各个类别中出现的分布和在整个文档集中出现的文档频次, 但缺乏对特征词本身及特征词间的相互联系的充分考虑, 比如特征词本身的词性、出现在单篇文档中的位置、特征词间的共现关系等, 这些都能对特征词的权重起到一定的度量作用, 可予以适当考虑。此外, 将本方法应用于英文语料也是一个需要检验的课题。
李湘东: 提出研究思路, 设计研究方案, 论文最终版修订;
阮涛: 采集数据, 结果分析, 论文修订;
刘康: 论文起草, 进行实验。
所有作者声明不存在利益冲突关系。
支撑数据见期刊网络版http://www.infotech.ac.cn。
[1] 李湘东, 阮涛, 刘康. data.zip. 训练集和测试集文件.
[2] 李湘东, 阮涛, 刘康. collection.zip. 实验中间文件.
[3] 李湘东, 阮涛, 刘康. result.zip. 实验结果文件.
| [1] |
浅谈网络图书馆、数字图书馆、虚拟图书馆的概念 [J].https://doi.org/10.3969/j.issn.1002-1248.2006.09.039 URL [本文引用: 1] 摘要
结合多位专家学者对网络图书馆、数字图书馆、虚拟图书馆概念的认识,利用哲学中的认识论浅谈三者的慨念。三概念间有着千丝万缕的联系,但是由于认识角度不同三者有细微差异。网络图书馆、数字图书馆、虚拟图书馆分别强调现代图书馆信息资源共享的网络化传播方式、数字化加工过程、虚拟化组织形式。三者是对同一事物从不同侧面进行的描述。
Discussion on Concepts of Network Library, Digital Library and Virtual Library [J].https://doi.org/10.3969/j.issn.1002-1248.2006.09.039 URL [本文引用: 1] 摘要
结合多位专家学者对网络图书馆、数字图书馆、虚拟图书馆概念的认识,利用哲学中的认识论浅谈三者的慨念。三概念间有着千丝万缕的联系,但是由于认识角度不同三者有细微差异。网络图书馆、数字图书馆、虚拟图书馆分别强调现代图书馆信息资源共享的网络化传播方式、数字化加工过程、虚拟化组织形式。三者是对同一事物从不同侧面进行的描述。
|
| [2] |
数字图书馆多种类型文献混合自动分类研究 [J].The Study of Mixed Automatic Categorization on Digital Library Collections [J]. |
| [3] |
A Comparative Study of Two Automatic Document Classification Methods in a Library Setting [J].https://doi.org/10.1177/0165551507082592 URL [本文引用: 1] 摘要
In current library practice, trained human experts usually carry out document cataloguing and indexing based on a manual approach. With the explosive growth in the number of electronic documents available on the Internet and digital libraries, it is increasingly difficult for library practitioners to categorize both electronic documents and traditional library materials using just a manual approach. To improve the effectiveness and efficiency of document categorization at the library setting, more in-depth studies of using automatic document classification methods to categorize library items are required. Machine learning research has advanced rapidly in recent years. However, applying machine learning techniques to improve library practice is still a relatively unexplored area. This paper illustrates the design and development of a machine learning based automatic document classification system to alleviate the manual categorization problem encountered within the library setting. Two supervised machine learning algorithms have been tested. Our empirical tests show that supervised machine learning algorithms in general, and the k-nearest neighbours (KNN) algorithm in particular, can be used to develop an effective document classification system to enhance current library practice. Moreover, some concrete recommendations regarding how to practically apply the KNN algorithm to develop automatic document classification in a library setting are made. To our best knowledge, this is the first in-depth study of applying the KNN algorithm to automatic document classification based on the widely used LCC classification scheme adopted by many large libraries. CILIP.
|
| [4] |
基于语料和基于标引经验的自动分类模式比较 [J].https://doi.org/10.3969/j.issn.1671-7465.2005.04.016 URL [本文引用: 1] 摘要
以传统文献分类体系为框架,构建知识库或分类器来实现信息的自动分类是信息加工自动化的一个发展方向。这种自动分类系统一般有两种模式:基于训练语料和基于人工标引经验。我实验室分别在这两种模式的基础上设计开发了两个不同的自动分类系统。本文将详细介绍这两个自动分类系统的结构、设计及其构建,然后分别从原理、知识库构建、分类算法等方面对这两者进行比较分析。
A Comparison of Automatic Classification Between Corpus-based Model and Experiences-based Model [J].https://doi.org/10.3969/j.issn.1671-7465.2005.04.016 URL [本文引用: 1] 摘要
以传统文献分类体系为框架,构建知识库或分类器来实现信息的自动分类是信息加工自动化的一个发展方向。这种自动分类系统一般有两种模式:基于训练语料和基于人工标引经验。我实验室分别在这两种模式的基础上设计开发了两个不同的自动分类系统。本文将详细介绍这两个自动分类系统的结构、设计及其构建,然后分别从原理、知识库构建、分类算法等方面对这两者进行比较分析。
|
| [5] |
An Unsupervised Approach to Automatic Classification of Scientific Literature Utilizing Bibliographic Metadata [J].https://doi.org/10.1177/0165551511417785 URL [本文引用: 1] 摘要
This article describes an unsupervised approach for automatic classification of scientific literature archived in digital libraries and repositories according to a standard library classification scheme. The method is based on identifying all the references cited in the document to be classified and, using the subject classification metadata of extracted references as catalogued in existing conventional libraries, inferring the most probable class for the document itself with the help of a weighting mechanism. We have demonstrated the application of the proposed method and assessed its performance by developing a prototype software system for automatic classification of scientific documents according to the Dewey Decimal Classification scheme. A dataset of 1000 research articles, papers, and reports from a well-known scientific digital library, CiteSeer, were used to evaluate the classification performance of the system. Detailed results of this experiment are presented and discussed.
|
| [6] |
基于维基百科的中文短文本分类研究 [J].
Research on Chinese Short Text Classification Based on Wikipedia [J].
|
| [7] |
Multi-level Topical Text Categorization with Wikipedia [C]//
|
| [8] |
Latent Dirichlet Allocation [J]. |
| [9] |
Co-Clustering Based Classification Algorithm with Latent Semantic Relationship for Cross- Domain Text Classification Through Wikipedia [J].https://doi.org/10.9756/BIJDM.8330 URL |
| [10] |
维基百科在多种类型数字文本资源自动分类中的应用 [J].URL 摘要
【目的/意义】书目信息和网页等不同类型文献之间存在特征词不匹配等语义差异问题,使得将书目信息作为训练集来对网络信息资源进行自动分类时,现有分类方法的分类性能不佳。【方法/过程】文章提出使用维基百科开展语义特征扩展,解决语义差异问题的自动文本分类方法。使用数字图书馆中容易获取类别标识及等文本内容的书目信息作为训练集,引入第三方资源的维基百科对其进行语义特征扩展,缩小作为训练集的书目信息与作为待分类文本的网页之间的语义差异,对属于不同文献类型的网页进行分类。【结果/结论】实验表明与未经过扩展的分类方法相比,分类准确率分别提高5.5%至8.4%,证明该方法能够有效提高文本自动分类的分类效果。
Application of Wikipedia to Automatic Categorization with Multiple Types of Digital Text Resources [J].URL 摘要
【目的/意义】书目信息和网页等不同类型文献之间存在特征词不匹配等语义差异问题,使得将书目信息作为训练集来对网络信息资源进行自动分类时,现有分类方法的分类性能不佳。【方法/过程】文章提出使用维基百科开展语义特征扩展,解决语义差异问题的自动文本分类方法。使用数字图书馆中容易获取类别标识及等文本内容的书目信息作为训练集,引入第三方资源的维基百科对其进行语义特征扩展,缩小作为训练集的书目信息与作为待分类文本的网页之间的语义差异,对属于不同文献类型的网页进行分类。【结果/结论】实验表明与未经过扩展的分类方法相比,分类准确率分别提高5.5%至8.4%,证明该方法能够有效提高文本自动分类的分类效果。
|
| [11] |
文本自动分类中特征权重算法的改进研究 [J].An Improved Approach to Term Weighting in Automated Text Classification [J]. |
| [12] |
文本分类中特征提取和特征加权方法研究 [D].
Research on Feature Extraction and Feature Weighting in Text Categorization [D].
|
| [13] |
基于复合加权LDA模型的书目信息分类方法研究 [J].
以书目信息为分类对象的自动分类研究对信息资源组织具有重要意义.本文以概率主题模型LDA作为书目信息的文本表示模型,以克服因文本短小而产生的特征稀疏问题;以书目信息的体例结构和所在类目的类别区分能力分别实现两种不同的特征加权策略,在此基础上构建复合加权策略,使获取的特征词集既不向高频词倾斜,也更能代表书目信息的所属类别.将复合加权策略融合于LDA、提出一种基于复合加权LDA的书目信息分类方法.使用公开和自建的书目信息语料进行对比实验,验证和分析复合加权策略的有效性,实验显示本文提出的复合加权LDA分类方法的分类性能优于仅考虑其中一种特征加权策略的LDA分类方法.
The Research of Bibliographic Information Classification Method Based on the Composite Weighted LDA Model [J].
以书目信息为分类对象的自动分类研究对信息资源组织具有重要意义.本文以概率主题模型LDA作为书目信息的文本表示模型,以克服因文本短小而产生的特征稀疏问题;以书目信息的体例结构和所在类目的类别区分能力分别实现两种不同的特征加权策略,在此基础上构建复合加权策略,使获取的特征词集既不向高频词倾斜,也更能代表书目信息的所属类别.将复合加权策略融合于LDA、提出一种基于复合加权LDA的书目信息分类方法.使用公开和自建的书目信息语料进行对比实验,验证和分析复合加权策略的有效性,实验显示本文提出的复合加权LDA分类方法的分类性能优于仅考虑其中一种特征加权策略的LDA分类方法.
|
| [14] |
基于LDA-wSVM模型的文本分类研究 [J].https://doi.org/10.3969/j.issn.1001-3695.2015.01.005 URL [本文引用: 1] 摘要
SVM分类算法处理高维数据具有较大优势,但其未考虑语义的相似性度量问题,而LDA主题模型可以解决传统的文本分类中相似性度量和主题单一性问题。为了充分结合SVM和LDA算法的优势并提高分类精确度,提出了一种新的LDA—wSVM高效分类算法模型。利用LDA主题模型进行建模和特征选择,确定主题数和隐主题一文本矩阵;在经典权重计算方法上作改进,考虑各特征项与类别的关联度,设计了一种新的权重计算方法;在特征词空间上使用这种基于权重计算的wSVM分类器进行分类。实验基于R软件平台对搜狗实验室的新闻文本集进行分类,得到了宏平均值为0.943的高精确度分类结果。实验结果表明,提出的LDA—wSVM模型在文本自动分类中具有很好的优越性能。
Research on Text Categorization Based on LDA-wSVM Model [J].https://doi.org/10.3969/j.issn.1001-3695.2015.01.005 URL [本文引用: 1] 摘要
SVM分类算法处理高维数据具有较大优势,但其未考虑语义的相似性度量问题,而LDA主题模型可以解决传统的文本分类中相似性度量和主题单一性问题。为了充分结合SVM和LDA算法的优势并提高分类精确度,提出了一种新的LDA—wSVM高效分类算法模型。利用LDA主题模型进行建模和特征选择,确定主题数和隐主题一文本矩阵;在经典权重计算方法上作改进,考虑各特征项与类别的关联度,设计了一种新的权重计算方法;在特征词空间上使用这种基于权重计算的wSVM分类器进行分类。实验基于R软件平台对搜狗实验室的新闻文本集进行分类,得到了宏平均值为0.943的高精确度分类结果。实验结果表明,提出的LDA—wSVM模型在文本自动分类中具有很好的优越性能。
|
| [15] |
Supervised Labeled Latent Dirichlet Allocation for Document Categorization [J].https://doi.org/10.1007/s10489-014-0595-0 URL 摘要
Recently, supervised topic modeling approaches have received considerable attention. However, the representative labeled latent Dirichlet allocation (L-LDA) method has a tendency to over-focus on the pre-assigned labels, and does not give potentially lost labels and common semantics sufficient consideration. To overcome these problems, we propose an extension of L-LDA, namely supervised labeled latent Dirichlet allocation (SL-LDA), for document categorization. Our model makes two fundamental assumptions, i.e., Prior 1 and Prior 2, that relax the restriction of label sampling and extend the concept of topics. In this paper, we develop a Gibbs expectation-maximization algorithm to learn the SL-LDA model. Quantitative experimental results demonstrate that SL-LDA is competitive with state-of-the-art approaches on both single-label and multi-label corpora.
|
| [16] |
基于mRMR和LDA主题模型的文本分类研究 [J].https://doi.org/10.3778/j.issn.1002-8331.1506-0266 URL Magsci 摘要
LDA没有考虑到输入,在原始的输入空间上对每一个词进行主题标签,因保留非作用词,而影响了主题概率分布。针对这种情况提出了一种mRMR_LDA算法,预先使用mRMR特征选择算法将输入空间映射到低维空间,过滤掉非作用词,使得LDA能在更简洁和更清晰的空间上进行主题标签,得到更精确的主题分布。对20 Newsgroups语料库和复旦大学语料库进行分类,分类精度分别提高了1.53%和1.18%,实验结果表明提出的mRMR_LDA模型在文本分类中有较好的分类性能。
Research on Text Categorization Based on mRMR and LDA [J].https://doi.org/10.3778/j.issn.1002-8331.1506-0266 URL Magsci 摘要
LDA没有考虑到输入,在原始的输入空间上对每一个词进行主题标签,因保留非作用词,而影响了主题概率分布。针对这种情况提出了一种mRMR_LDA算法,预先使用mRMR特征选择算法将输入空间映射到低维空间,过滤掉非作用词,使得LDA能在更简洁和更清晰的空间上进行主题标签,得到更精确的主题分布。对20 Newsgroups语料库和复旦大学语料库进行分类,分类精度分别提高了1.53%和1.18%,实验结果表明提出的mRMR_LDA模型在文本分类中有较好的分类性能。
|
| [17] |
MR-LDA: An Efficient Topic Model for Classification of Short Text in Big Social Data [J].https://doi.org/10.4018/IJGHPC.2016100106 URL [本文引用: 1] 摘要
react-text: 434 Network Hotpoint discovery is to discover the topic from the mass of network data. Micro-blog data have distinct characteristics from other network data, while the traditional topic detection method performs poorly. This paper presents an improved method for short text theme found, First, based on HMM model discovered new words to the text, new words are added to the user dictionary, and then... /react-text react-text: 435 /react-text [Show full abstract]
|
| [18] |
|
| [19] |
维基百科知网的构建研究与应用进展 [J].https://doi.org/10.3969/j.issn.1002-0314.2012.05.010 URL [本文引用: 1] 摘要
文章分析维基百科中的文档、目录、超链接、重定向以及消歧义等基本元素与结构关系特点,围绕维基百科在信息检索、文本分类、文本聚类、歧义消解、查询扩展与信息抽取以及本体构建等信息处理任务中的典型解决方法与相关项目,综述和评析基于维基百科的语义知识挖掘的研究与应用方法,从整体上把握基于维基百科的知识挖掘研究现状与进展,为当前知识服务系统建设提供借鉴。
Construction Research and Application Progress of Wikipedia Knowledge Network [J].https://doi.org/10.3969/j.issn.1002-0314.2012.05.010 URL [本文引用: 1] 摘要
文章分析维基百科中的文档、目录、超链接、重定向以及消歧义等基本元素与结构关系特点,围绕维基百科在信息检索、文本分类、文本聚类、歧义消解、查询扩展与信息抽取以及本体构建等信息处理任务中的典型解决方法与相关项目,综述和评析基于维基百科的语义知识挖掘的研究与应用方法,从整体上把握基于维基百科的知识挖掘研究现状与进展,为当前知识服务系统建设提供借鉴。
|
| [20] |
LDA模型在网络视频推荐中的应用 [J].https://doi.org/10.19358/j.issn.1674-7720.2016.11.023 URL [本文引用: 1] 摘要
视频推荐系统最主要的功能就是从用户的历史行为中发现用户兴趣偏好,然后找出其可能感兴趣的视频并展示给用户。该文针对用户的视频选择过多、视频转化率较低等问题,提出了一种基于LDA模型的电影推荐方法。首先将视频的评论文本集转化为评论-主题-词语的三层贝叶斯模型,提取每个视频的评论关键词,再基于目标用户的历史行为发现其偏好的视频关键词集合,最后利用杰卡德相似系数,预测用户可能感兴趣的视频,以实现基于内容的个性化视频推荐服务。实验表明,该方法可以提高视频推荐的精度,使得视频转化率得到较好的提升。
The Application of LDA in Online Video Recommendation [J].https://doi.org/10.19358/j.issn.1674-7720.2016.11.023 URL [本文引用: 1] 摘要
视频推荐系统最主要的功能就是从用户的历史行为中发现用户兴趣偏好,然后找出其可能感兴趣的视频并展示给用户。该文针对用户的视频选择过多、视频转化率较低等问题,提出了一种基于LDA模型的电影推荐方法。首先将视频的评论文本集转化为评论-主题-词语的三层贝叶斯模型,提取每个视频的评论关键词,再基于目标用户的历史行为发现其偏好的视频关键词集合,最后利用杰卡德相似系数,预测用户可能感兴趣的视频,以实现基于内容的个性化视频推荐服务。实验表明,该方法可以提高视频推荐的精度,使得视频转化率得到较好的提升。
|
| [21] |
基于中文维基百科的概念相关词群研究 [D].Research on the Concept-related Phrases Based on Chinese Wikipedia [D]. |
| [22] |
LDA-based Document Models for Ad-Hoc Retrieval [C]// |
| [23] |
基于LDA主题模型的文本相似度计算 [J].https://doi.org/10.3969/j.issn.1002-137X.2013.12.049 URL [本文引用: 1] 摘要
LDA(Latent Dirichlet Allocation)模型是近年来提出的一种具有文本表示能力的非监督学习模型。提出了一种基于LDA主题模型的文本相似度计算方法,该方法利用LDA为语料库建模,利用MCMC中的Gibbs抽样进行推理,间接计算模型参数,挖掘隐藏在文本内的不同主题与词之间的关系,得到文本的主题分布,并以此分布来计算文本之间的相似度,最后对文本相似度矩阵进行聚类实验来评估聚类效果。实验结果表明,该方法能够明显提高文本相似度计算的准确率和文本聚类效果。
Text Similarity Computing Based on Topic Model LDA [J].https://doi.org/10.3969/j.issn.1002-137X.2013.12.049 URL [本文引用: 1] 摘要
LDA(Latent Dirichlet Allocation)模型是近年来提出的一种具有文本表示能力的非监督学习模型。提出了一种基于LDA主题模型的文本相似度计算方法,该方法利用LDA为语料库建模,利用MCMC中的Gibbs抽样进行推理,间接计算模型参数,挖掘隐藏在文本内的不同主题与词之间的关系,得到文本的主题分布,并以此分布来计算文本之间的相似度,最后对文本相似度矩阵进行聚类实验来评估聚类效果。实验结果表明,该方法能够明显提高文本相似度计算的准确率和文本聚类效果。
|
| [24] |
A Density-based Method for Adaptive LDA Model Selection [J].https://doi.org/10.1016/j.neucom.2008.06.011 URL [本文引用: 1] 摘要
Topic models have been successfully used in information classification and retrieval. These models can capture word correlations in a collection of textual documents with a low-dimensional set of multinomial distribution, called “topics”. However, it is important but difficult to select the appropriate number of topics for a specific dataset. In this paper, we study the inherent connection between the best topic structure and the distances among topics in Latent Dirichlet allocation (LDA), and propose a method of adaptively selecting the best LDA model based on density. Experiments show that the proposed method can achieve performance matching the best of LDA without manually tuning the number of topics.
|
| [25] |
复旦大学中文语料库 [DB/OL]. [udan-Classification-Corpus [DB/ OL]. [ |
| [26] |
搜狗互联网语料库 [DB/OL]. [SogouT [DB/OL]. [ |

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}