
|
|
郭博 , 李守光
, 李守光
Guo Bo, Li Shouguang
中图分类号: TP181
通讯作者:
收稿日期: 2017-06-29
修回日期: 2017-09-26
网络出版日期: 2017-12-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
展开
摘要
【目的】通过对电商网站产生的海量用户评论数据进行综合分析, 及时获取与产品口碑相关的用户反馈信息, 以便快速有效地反馈企业的市场营销活动效果。【方法】运用词袋模型、依存句法分析和机器学习等新兴技术, 对来自京东和天猫两个主要电商网站的真实数据集进行分析, 实现了电商用户评论的自动情感分析和观点标签提取。【结果】评论情感分析获得约90%的准确率, 利用改进双向传播算法成功实现了一个自动化的词库构建系统, 摆脱对词典的依赖, 该系统的F值达到约71%。【局限】观点标签提取的召回率需要进一步提高。【结论】通过实时获取海量电商评论数据并进行有效分析, 成功实现对用户口碑的快速分析与准确把控, 具有较高的商业化推广前景。
关键词:
Abstract
[Objective] This study conducts a comprehensive analysis of huge amount of reviews generated by E-commerce website users, aiming to assess the marketing strategies. [Methods] We used syntactic parsing, bag of words model and machine learning techniques to examine real-world datasets from JD and TMall. The proposed method could analyze sentiment and extract opinion from the reviews automatically. [Results] The accuracy of the sentiment analysis was 90%. We constructed an automatic vocabulary building mechanism without dictionary dependency. The F-measure of the new system was 71%. [Limitations] The recall of the opinion extraction needs to be improved. [Conclusions] The proposed system could effectively monitor the word-of-mouth issues facing products sold online. It could be transferred to many online business.
Keywords:
近年来, 我国的电子商务行业取得了突飞猛进的发展。中国互联网络信息中心(CNNIC)发布《2015年中国网络购物市场研究报告》[1]显示, 截至2015年12月, 我国网络购物用户规模达4.13亿, 2015年全国网络零售交易额达3.88万亿元, 同比增长33.3%。面对电商平台上的海量商品, 消费者往往眼花缭乱, 难以做出有效选择。电商网站中积累的大量用户评论恰好可以发挥重大作用。
评论主要作用有: 评论功能缓解了真实交易过程中的信息不对称问题, 线上购物的过程中接触的所有信息都来自于卖家填写在页面上的描述信息, 而用户的评论在一定程度上可以客观反映商品的真实信息; 评论系统也可以帮助广大消费者降低决策成本, 通过分析用户评论的分布, 可以有效辨别商品的真实品质; 通过语义分析与数据挖掘等技术进行综合的用户评论分析, 为商家提供有效的商品口碑信息。基于上述分析, 如何利用电商评论信息为用户提供信息决策依据并为商家提供有效及时的商品口碑分析成为一个重要的研究方向。
(1) 情感分析相关研究
随着电子商务的兴起, 人们迫切需要通过自然语言处理技术对电商评论文本进行情感倾向判断。情感分析(Sentiment Analysis)是目前文本挖掘和自然语言处理的研究热点[2], 情感分析的概念最早由Nasukawa提出, 通过自动分析大量用户评论的文本内容, 输出每条评论对应的用户情感类型[3]。已有情感分析研究大部分是基于已经编辑好的情感词典或词表判断情感倾向, 比较典型的是使用种子词、领域词和WordNet扩展词表进行匹配计算[4]。
在特征选取方面, 词袋模型 (Bag of Words Model)[5]已经成为经典的文本分类研究的标准模式。在处理评论情感分析的过程中, 不能将词语视为孤立的个体存在, 很多词语共同出现的时候才能表达某种特定的情感倾向。经典的文本分类研究主要使用向量空间模型作为机器学习算法的基础, 词袋模型则是最为常用的一种向量空间模型。后续诸多研究对词袋模型进行了优化, 主要体现在以下几个方面:
①权重计算: 传统向量模型中词语权重的计算主要依靠词频, 而Pang等[6]的研究发现对于评论情感分类问题, 以词语是否出现作为特征在分类效果上优于词频特征。
②词性: 词性是能够标识语义信息的重要语法特征。Hatzivassiloglou等[7]指出一些形容词的出现可以有效地识别主观性语言。在许多情感识别和抽取工作中, 特别是无监督方法, 往往抽取文本中的形容词、名词、动词或副词作为潜在的情感表达单元。
③句法结构特征: 句法分析常常被应用于句子水平的情感分析, 以识别句子主题、意见描述项和意见持有者等成分。Ku等[8]认为加入句法特征后可以提高分类器算法的准确性。
④否定结构: 否定的识别和表示对于情感分析问题非常重要。对于显式的否定结构, 相关研究主要采取两种处理方式: 一是忽略否定词语表示文本, 如果否定词语存在, 则取相反的情感计算结果[9]; 另一种方法是将否定结构编码到文本特征中[10]。
(2) 观点挖掘相关研究
观点挖掘是当前自然语言处理研究领域的一个热点问题, 也在工业界得到了十分广泛的应用。现有大量观点挖掘技术均依赖情感词典, 然而词语的情感倾向和语料的具体领域有密切的关系, 情感词存在多义、歧义的现象, 一个相同的情感词语在不同的语料环境中可能呈现完全不同的意思。在3C类消费电子产品领域, “发热”、“红屏”这样的词语带有强烈的负面情感倾向。现有情感词典往往只覆盖少数领域, 难以同时应对多个不同领域的情感分析研究。因而需要研究一种普遍适用于多个不同领域的用户评论的观点挖掘方法。
现有研究成果着重于建立一种对多个不同领域都适用的构建特征词和评价词词库的方法。两个形容词之间通常由and、or等词语连接起来, 表示一种同向或反向的关系。Hatzivassiloglou等[11]最早研究这一问题, 他们基于大量语料构建了一个推断形容词情感倾向的模型, 但该模型不能分析孤立出现的形容词。Wiebe[12]通过词语聚类的方法建立了一个寻找主观性形容词的模型, 其认为主观词语通常具有相似的使用场景, 因而在词语分布上呈现较为一致的特征。Kaji等[13]在分析日文HTML页面数据的时候引入网页的布局信息, 从页面中抽取形容词或形容词短语, 但其方法依赖HTML数据中的结构化信息, 难以应用于非结构化的文本数据。Kanayama等[14]最早利用从句级的语法依存特性从文本中抽取关键词语, 并利用统计学方法检验所得特征词语的准确性。Hu等[15]通过WordNet语义数据库建立词语之间的同义关系网络, 给定“好”和“坏”两个核心种子词, 通过计算每个词到两个核心种子词的距离确定各个词语的情感倾向。Qiu等[16]在Kaji等[13]的基础上进一步引入情感词和特征词两个维度的双向传播算法, 在语料中, 产品特征词和用户情感词往往是相互关联的, 通过基于语法依存关系进行特征和情感词的提取, 进一步利用得到的特征词和情感词进行多次迭代, 这一算法成功实现了对于任意类别的商品都能识别情感词和特征词。本文在Qiu等[16]研究的基础上进一步修改, 引入Word2Vec和聚类分析等方法对双向传播算法所得结果进行优化, 并结合依存句法分析的技术, 成功实现了用户评论的观点挖掘。
针对以上问题, 本文利用电商网站积累的大量、实时的用户评论数据, 实现了电商用户评论的自动情感分析和观点标签提取, 并从中提取归纳相关产品的用户口碑。
(1) 基于对电商行业的理解和技术上的持续探索创新, 笔者设计开发了一套分析电商评论信息的综合系统——PRAS (Product Review Analysis System)。
(2) 改进双向传播算法, 提出基于该算法的评论标签提取方法, 建立了准确的自动化电商用户评论情感分析机制, 可以精确判断每条用户评论的情感倾向, 继而可进行统计汇总, 得到用户好评率的整体趋势。
评论是用户对商品或品牌主观态度的直接反映, 大量用户评论汇集在一起的整体情感倾向反映了用户整体的口碑趋势, 因此分析某一商品或品牌在市场上的用户好感分布情况具有重要意义。现有主流电商网站中, 部分网站会明确要求用户在好评、中评或差评之间做出选择, 也有一些网站让用户给商品打分 (1-5分), 普通用户在访问商品评论页面时即可获知每条评论对应的评论等级。但也有一些网站只提供用户发表评论的功能, 并不要求用户做出明确的打分等级, 例如天猫。对于这样的网站, 通过简单的统计和分类汇总并不能获得好评率的具体情况, 因而需要对评论文本进行深入分析。
本文系统建立了一种基于评论文本内容自动对每条评论进行好差评分类的机制。输入为评论文本, 输出则是该评论对应的好评/差评分类结果。这一功能不仅显著降低了评论情感倾向分析的人力成本, 而且基于程序输出结果, 自动实现对差评的监控。
文本自动情感倾向分析主要有4个关键步骤, 如图1所示。
(1) 文本预处理: 直接从电商网站采集得到的评论通常含有一些无意义信息, 需要进行清洗过滤。此外, 由于目前各种自然语言处理算法都是基于词的, 中文的书写方式词和词之间没有空格, 因而需要先对每条评论进行分词处理。
(2) 文本向量表示: 基于词袋模型等方法将每条评论文本表示为可以被机器学习算法处理的向量化形式。
(3) 模型训练: 将所得模型向量输入到现有成熟机器学习算法中, 构建机器学习模型。
(4) 效果评估: 利用多种效果评估指标综合评价模型分类准确性。
评论情感分析提供了评论总体好评率趋势的结果, 但将每条评论只分类为“好评”、“差评”这两类标签过于笼统。实际生活中, 用户往往从多个维度对某一产品进行评价, 还可能包括对电商平台和物流服务的很多意见。从用户评论中获取这些信息对于改进产品设计、提升客户服务质量和加强客户关系管理等问题具有重要意义。从用户评论中提取产品特征不同纬度的评价是评论情感分析的进一步深化, 不再将每条评论视为一个整体, 而从多方面、多角度综合看待一条用户评论, 最终获得大量有价值信息。
评论标签提取中有两个基本概念:
(1) 特征词: 用户对于某一产品做出评价的主要维度和方面, 例如对于手机产品, 用户一般会就通话质量、屏幕尺寸、续航能力、客服态度、物流速度等多方面做出评价, 这些都称为产品的特征词。
(2) 评价词: 用户就某一方面特征具体给出的评价, 如物流很快、客服态度差等。
评论标签提取工作输入用户评论, 针对每条评论输出一组或多组(特征词, 评价词)的二元关系组合, 这种分析方法通常被称为观点挖掘。
为了解决上述问题, 本文对评论文本建立了基于依存句法补充的词袋模型, 在此基础上提出基于改进双向传播算法的评论标签挖掘方法, 完成细粒度的情感分析。
(1) 基于依存句法补充的词袋模型
词袋模型是自然语言处理领域较早出现的一种将文本表示为向量的方法, 该方法将文档看作若干个词汇的集合, 文档中出现的每个单词之间都是相互独立的, 词袋模型使用一组无序的单词构建表示文本的向量。
由于词袋模型只考虑文本中出现过的词汇, 不考虑词语之间的相互关系, 因此丢失了一定含量的信息, 为进一步改进词袋模型, 可以考虑新的词表构建方式, 引入更多信息含量。笔者进一步考虑了否定词的影响。加入否定词的词袋模型的构建过程与基本词袋模型的构建过程类似, 不同的是对否定词的处理。如果文本中出现了否定词, 则将否定词后的词加上“_INV”后缀形成新的词, 直到遇到标点。
在本研究中进一步引入句法分析的技术改进词袋模型的信息含量, 依存句法分析通过分析语言单位内成分之间的依存关系揭示其句法结构, 主张句子中核心动词是支配其他成分的中心成分, 而它本身却不受其他任何成分的支配, 所有受支配成分都以某种依存关系从属于支配者。依存句法分析的目标是将输入的自然语言文本从序列形式转化为树状结构, 进而应用于其他自然语言处理任务中。
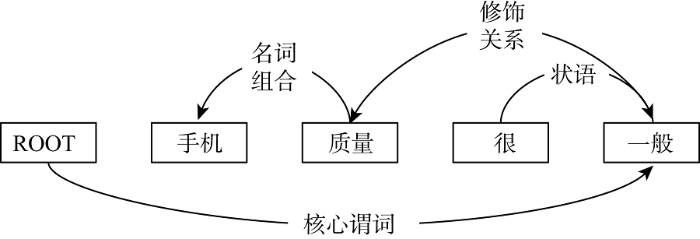
对于“手机质量很一般”这句话, 依存句法分析程序返回结果如图 2所示。
句子的核心谓词是“一般”, 其主语是“质量”, “很”是“一般”的状语, “手机”和“质量”构成一个名词组合。含有句法信息的词袋模型在构建过程中同样引入新的词语, 对于句法分析程序返回的结果中每一对有依存句法关系的词语都要在词表中组成一个新的词。如图2结果所示, “手机质量很一般”在句法分析过程中一共引入了“质量_手机”, “一般_质量”, “一般_很”三个新词。基于新的词表构建方式, 可以得到句法词袋模型下的文本向量表示。
(2) 基于改进双向传播算法的评论标签挖掘方法
在Qiu等[16]的基础上, 笔者提出改进的双向传播算法, 该算法的主要流程如图3所示。通过手工整理的方式收集一部分种子评价词, 利用依存句法分析的技术从评论中寻找相关词语。
种子评价词作为后续迭代传播流程的基础, 先会基于这些种子评价词发现相关的产品特征词, 再基于种子评价词发现新的评价词。将第一步所得特征词作为算法新的输入, 在所有评论文本中继续发现新的特征词, 这里新发现的特征词也会继续加入已有的特征词库中以再进一步发现新的评价词。至此, 4个关键步骤形成一个闭环, 循环迭代多轮后即可得到最终词库输出。笔者预先定义了一些依存句法规则用于上文4个关键步骤中, 如表1所示。
表1 依存句法规则
| 步骤 | 依存句法关系 | 含义 | 示例 |
|---|---|---|---|
| 种子评价词 → 新特征词 | nsubj(VA, NN) | 句子主语 | 手机(外形)很(漂亮) |
| amod(NN, VA) | 修饰关系 | 很(差)的(手机) | |
| amod(NN, JJ) | 修饰关系 | 这个手机有很(漂亮)的(外形) | |
| 种子评价词 → 新评价词 | dep(VA, VA) | 依赖关系 | |
| 新特征词 → 新特征词 | conj(NN, NN) | 并列关系 | 手机的(拍照)和(摄像)不错 |
| compound:nn(NN, NN) | 名词组合 | (手机外形)不错 | |
| nmod:assmod(NN, NN) | 名词短语 | (手机)的(外形)很漂亮 | |
| 新特征词 → 新评价词 | nsubj(VA, NN) | 句子主语 | 手机(外形)很(漂亮) |
| amod(NN, VA) | 修饰关系 | 很(差)的(手机) | |
| amod(NN, JJ) | 修饰关系 | 这个手机有很(漂亮)的(外形) |
(1) 特征词库的提取逻辑
从电商网站采集评论文本数据, 经过清洗、分词、词性标注和依存句法分析处理, 所得结果会和笔者手工搜集的少量种子评价词一起作为双向传播算法的输入, 用于发现其他特征词和评价词。基于如下规则对所得特征词进行初步剪枝清洗:
①提取出的特征词, 必须同时满足以下两个条件: 一个句子只提取一个特征词; 确保是有意义的词(不是无意义的词且不是特殊词, 即为有意义词)。无意义词表在通用的停用词表基础上由手工整理得到, 例如: 的、了、我等。特殊词列表主要包括品牌、型号、人名、颜色、地名、日期等。
②提取出的特征词和情感词, 出现的频率需要大于阈值0.00001(表示10万条评论中至少出现一次)。
③特征短语词序修正, 例如[外形_手机]修正为[手机_外形], 修正依据是特征短语出现的次数, [手机_外形]出现的次数大于[外形_手机]出现的次数。
在剪枝所得结果的基础上, 进一步使用Affinity Propagation[17]算法对所得特征词进行聚类处理。算法输入特征为每个词语通过Word2Vec[18]算法所得向量表示。Word2Vec是Google在2013年开源的一款将词表征为实数值向量的高效工具, 其利用深度学习的思想, 通过训练, 将对文本内容的处理简化为K维向量空间中的向量运算, 而向量空间上的相似度可以用来表示文本语义上的相似度。如果两个词语在聚类算法中被聚到一类, 有很大可能这两个词语指代同一产品特征。对聚类所得结果进行人工过滤, 得到最终的特征词库。
(2) 评价词情感倾向判定方法
基于信息论中点互信息[19]这一概念实现自动判定每个评价词的情感倾向, 其定义如下:
$PMI(x:y)\equiv \log \frac{p(x,y)}{p(x)p(y)}=\log \frac{p(x|y)}{p(x)}=\log \frac{p(y|x)}{p(y)}$
如果x和y两个随机变量是独立的, 那么$p(x,y)=p(x)p(y)$。如果x和y的相关性越强, 那么$p(x,y)$相比于$p(x)p(y)$就越大。这里设x为某个词语出现, y为该评论为好评/差评。利用S=PMI(词语:好评)-PMI(词语:差评)度量一个词语的情感倾向, 如果S>0, 则说明该词语与好评的相关性相比于和差评的相关性更强, 判定该词语为正面情感倾向, 否则判定该词语为负面情感倾向。
(3) 标签提取规则说明
在所得情感词库的基础上, 设计如下逻辑从评论文本中提取标签。对所有待处理的评论进行句法分析, 提取标签主干。当有评价对象时, 如果两个词语满足nsubj(VA, NN)、amod(NN, VA)或amod(NN, JJ)这三类关系之一, 则找到对应的特征词和评价词; 如果没有评价对象, 当关系是root(ROOT, VA)的时候, 令VA作为评价词, 此时没有特征词。然后提取特征词修饰符, 如果句法关系满足compound:nn(NN, NN)、nmod:assmod(NN, NN)或amod(NN, JJ)三类之一, 则提取对应的特征词修饰符。继续利用advmod(VA, AD)和neg(VA, AD)两条规则抽取评价词修饰符的规则。最后对所得标签进行归一化处理, 得到最终结果。
对语料中的全部词语聚类后, 人工整理、构建归一词表。归一词表反映了多个特征词对应到同一特征词的映射关系, 例如跑分、速度、反应、反应速度等多个词语都对应到性能这一个特征词。归一化处理的目的主要是为了将语义相近的标签进行合并, 凸显标签之间的重要性差异, 避免杂乱无章的标签对用户的理解和使用造成干扰。
本文的数据源基于笔者已经获取到的京东评论, 首先进行去重、去除特殊符号、去除HTML转义字符、过滤少于2个字的句子等若干清洗和预处理步骤, 然后从中选取1、2、4、5星的评论, 经过清洗后, 1、2星评论作为好评, 4、5星评论作为差评。由于好评总量远远多于差评, 出于构建各类样本比例均衡的训练数据集考虑, 对全部好评数据进行抽样, 最终差评总量76万条, 好评总量80万条。
本文使用多项指标评估情感分析的效果。
(1) 准确率(Precison): 程序分类为差评的评论中真实类别也为差评的评论占比。
(2) 召回率(Recall): 真实类别为差评的全部评论中被程序分类为差评的比例。
(3) F1值: 准确率和召回率之间存在权衡关系, 准确率提高往往会导致召回率的下降, F1是准确率和召回率的调和平均数, 用于获得对分类效果的整体评价。
(4) AUC: ROC曲线下的面积, 用来反映分类器综合性能的指标。
分类器的选择: 在数据集为150万条、特征维度300万条件下, 首先进行算法选取实验, 使用Naïve Bayes(NB)、Stochastic Gradient Descent(SGD)、Support Vector Machine(SVM)和Random Forest(RF)这4种分类器算法, 综合对比基础词袋模型、带有否定关系的词袋模型和句法词袋模型三种向量表示方式的效果, 所有评估结果都基于在全量数据集的10折交叉检验计算, 分类器效果如表2所示。算法执行时间对比如表3所示。
表2 评论分类结果
| 模型 | 算法 | 准确率 | 召回率 | F1值 | AUC |
|---|---|---|---|---|---|
| 基础模型 | NB | 0.889 | 0.892 | 0.890 | 0.950 |
| 否定词模型 | NB | 0.892 | 0.899 | 0.895 | 0.953 |
| 句法模型 | NB | 0.914 | 0.908 | 0.911 | 0.961 |
| 基础模型 | SGD | 0.908 | 0.894 | 0.901 | 0.958 |
| 否定词模型 | SGD | 0.911 | 0.904 | 0.907 | 0.961 |
| 句法模型 | SGD | 0.917 | 0.919 | 0.918 | 0.967 |
| 基础模型 | SVM | 0.902 | 0.902 | 0.902 | 0.959 |
| 否定词模型 | SVM | 0.912 | 0.900 | 0.906 | 0.960 |
| 句法模型 | SVM | 0.916 | 0.920 | 0.918 | 0.966 |
| 基础模型 | RF | 0.871 | 0.870 | 0.871 | 0.942 |
| 否定词模型 | RF | 0.875 | 0.874 | 0.874 | 0.945 |
| 句法模型 | RF | 0.880 | 0.880 | 0.880 | 0.948 |
根据表2-表3, 基于句法的词袋模型在所有模型中表现最好, 与基础词袋模型相比, 全部指标约有2%的提升。4种算法在精确度上表现一致, 但是与NB、SVM、RF算法相比, SGD算法的训练速度更快。因此选择SGD算法和句法词袋模型作为最终的模型。
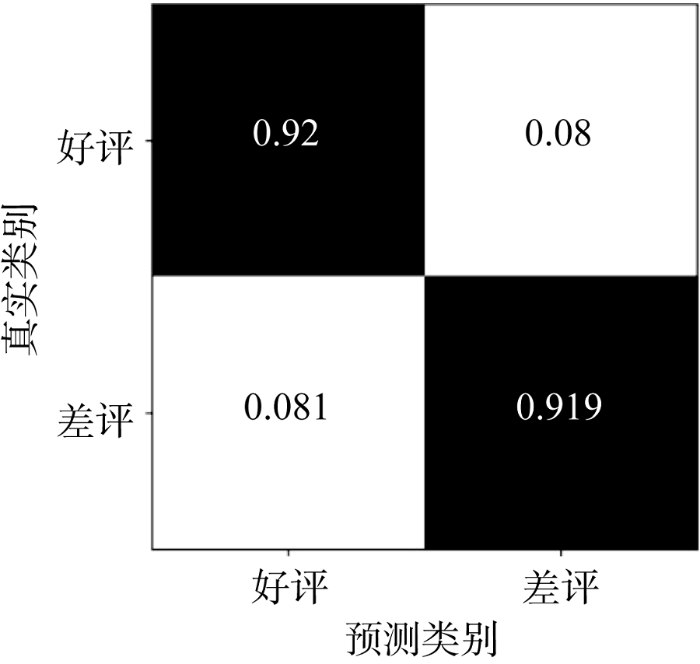
模型最终的混淆矩阵结果如图4所示, 本文模型达到90%以上的分类正确率, 能够非常有效地对好评和差评进行自动化识别区分。
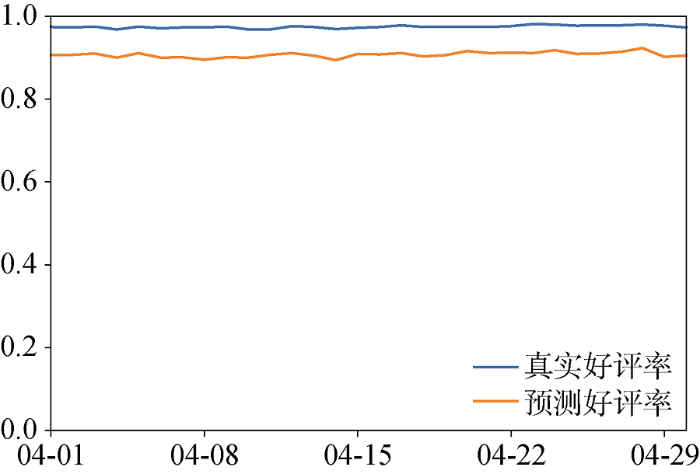
以小米手机为例, 利用所得分类器模型对小米手机在2017年4月的好评率变化情况进行预测分析。在预测过程中没有使用4月份评论中的具体评分信息, 只将评论文本输入本文的分类器模型, 得到预测好评率和真实好评率的对比如图5所示。
基于小米手机2017年4月的评论文本, 最终绘制出全部手机评论数据的标签云, 结果如图6所示。红色系文本表示正面情感倾向标签, 蓝绿色系文本表示负面情感倾向标签。
使用如下流程评估标签提取效果:
(1) 随机抽取N{Invalid MML}条评论文本作为测试数据集T{Invalid MML};
(2) 对T{Invalid MML}执行标签提取程序, 形成标签集L1{Invalid MML};
(3) 对T{Invalid MML}中所有评论进行人工标注, 人工标注结合Delphi[20]法与专家小组打分法确定标签集合, 可以消除专家主观影响, 得到更加全面、准确的标签集L2{Invalid MML}。统计人工结果和程序结合的重合度, 计算下列指标: 实际标签数、提取出的标签数和提取正确的标签数据;
(4) 计算三项评估指标: 准确率, 程序提取的标签中正确标签的占比; 召回率, 人工标注出的所有标签中有多少被程序正确提取出来; F值, 综合考虑准确率和召回率的指标, 定义为准确率和召回率的调和平均数。
随机抽取10 000条评论作为测试数据集, 人工标注共得到19 821个标签, 通过程序共提取出11 714个标签, 其中10 542个是人工和程序均认可的正确标签, 标签提取的准确率为88.9%, 召回率为57.1%, F值为70.9%。
通过以上分析可知, 结合依存句法分析技术与传统的词袋模型, 在规模庞大的电商用户真实评论数据集上, 利用成熟机器学习算法训练构建了较为准确的分类器模型, 不仅可以自动分析用户评论中的情感倾向, 在用户没有给出每条评论具体分数的情况下对用户总体好评率进行深入分析, 同时能够较为准确地自动提取评论标签, 能真实反映用户对某一产品某个方面的整体评价。但召回率不足, 存在遗漏特色观点的可能。
基于对电商行业的理解和技术上的持续探索创新, 笔者设计开发了一套分析电商评论信息的完整系统PRAS, 在该系统基础上对用户评论数据进行详细的文本语义特征分析, 并将结论以可视化的方式呈现给用户。同时, 还在改进双向传播算法基础上对评论文本数据进行深入挖掘分析, 实现了自动分析评论情感倾向和用户观点标签提取两项关键功能。本文提出的方案以及搭建的系统为准确把握用户口碑变化趋势提供了帮助, 展现了巨大的商业价值。不足之处是情感分析阶段进行了颗粒度较粗的划分, 将用户的情感倾向简单分成好与坏两类, 后续应该考虑引入中性情感判定; 在情感分析的过程中并没有针对大量的水军用户进行判定[21-22], 因此得到的用户情感倾向会产生一定的偏差; 在商品特征提取的归一化方面, 并没有进行深入的研究, 这也是未来的一个重点研究方向。
郭博: 提出研究思路, 设计研究方案;
李守光: 完成情感分析和标签提取功能的开发工作;
王昊: 起草论文, 完善分析思路;
张晓军: 完善论文中所需数据集合;
龚伟: 完成词云数据可视化工作;
于昭君: 论文最终版本修订;
孙宇: 全文统稿审定。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: gb@meizu.com。
[1] 郭博, 李守光, 王昊. product review.csv. 本文训练模型所用用户评论数据集.
[2] 郭博, 李守光, 王昊. experrimental_data.csv. 原始实验数据.
[3] 郭博, 李守光, 王昊. data_bz.csv. 专家标注数据.
[4] 郭博, 李守光, 王昊. word cloud.csv. 词云归一化数据.
| [1] |
2015年中国网络购物市场研究报告 [R].2015 China Online Shopping Market Research Report [R]. |
| [2] |
Machine Learning Approaches for Sentiment Analysis [A]// |
| [3] |
Sentiment Analyzer: Extracting Sentiments about a Given Topic Using Natural Language Processing Techniques [C]// |
| [4] |
Alignment of Standards Using WordNet for Assessing K-12 Engineering Practices in a Participatory Learning Environment [C] // |
| [5] |
Bag-of-Words Method Applied to Accelerometer Measurements for the Purpose of Classification and Energy Estimation [OL].
Accelerometer measurements are the prime type of sensor information most think of when seeking to measure physical activity. On the market, there are many fitness measuring devices which aim to track calories burned and steps counted through the use of accelerometers. These measurements, though good enough for the average consumer, are noisy and unreliable in terms of the precision of measurement needed in a scientific setting. The contribution of this paper is an innovative and highly accurate regression method which uses an intermediary two-stage classification step to better direct the regression of energy expenditure values from accelerometer counts. We show that through an additional unsupervised layer of intermediate feature construction, we can leverage latent patterns within accelerometer counts to provide better grounds for activity classification than expert-constructed timeseries features. For this, our approach utilizes a mathematical model originating in natural language processing, the bag-of-words model, that has in the past years been appearing in diverse disciplines outside of the natural language processing field such as image processing. Further emphasizing the natural language connection to stochastics, we use a gaussian mixture model to learn the dictionary upon which the bag-of-words model is built. Moreover, we show that with the addition of these features, we're able to improve regression root mean-squared error of energy expenditure by approximately 1.4 units over existing state-of-the-art methods.
|
| [6] |
Thumbs up?: Sentiment Classification Using Machine Learning Techniques [C]// |
| [7] |
Effects of Adjective Orientation and Gradability on Sentence Subjectivity [C] // |
| [8] |
Opinion Extraction, Summarization and Tracking in News and Blog Corpora [C]// |
| [9] |
Replication Issues in Syntax-based Aspect Extraction for Opinion Mining [OL].https://doi.org/10.18653/v1/E17-4003 URL [本文引用: 1] 摘要
Reproducing experiments is an important instrument to validate previous work and build upon existing approaches. It has been tackled numerous times in different areas of science. In this paper, we introduce an empirical replicability study of three well-known algorithms for syntactic centric aspect-based opinion mining. We show that reproducing results continues to be a difficult endeavor, mainly due to the lack of details regarding preprocessing and parameter setting, as well as due to the absence of available implementations that clarify these details. We consider these are important threats to validity of the research on the field, specifically when compared to other problems in NLP where public datasets and code availability are critical validity components. We conclude by encouraging code-based research, which we think has a key role in helping researchers to understand the meaning of the state-of-the-art better and to generate continuous advances.
|
| [10] |
SentiCompass: Interactive Visualization for Exploring and Comparing the Sentiments of Time-varying Twitter Data [C]// |
| [11] |
McKeown K R. Predicting the Semantic Orientation of Adjectives [ |
| [12] |
Learning Subjective Adjectives from Corpora [C]// |
| [13] |
Building Lexicon for Sentiment Analysis from Massive Collection of HTML Documents [ |
| [14] |
Fully Automatic Lexicon Expansion for Domain-oriented Sentiment Analysis [ |
| [15] |
Mining and Summarizing Customer Reviews [C]// |
| [16] |
Expanding Domain Sentiment Lexicon Through Double Propagation [ |
| [17] |
Clustering Large-scale Data Based on Modified Affinity Propagation Algorithm [J].https://doi.org/10.1515/jaiscr-2016-0003 URL [本文引用: 1] 摘要
Traditional clustering algorithms are no longer suitable for use in data mining applications that make use of large-scale data. There have been many large-scale data clustering algorithms proposed in recent years, but most of them do not achieve clustering with high quality. Despite that Affinity Propagation (AP) is effective and accurate in normal data clustering, but it is not effective for large-scale data. This paper proposes two methods for large-scale data clustering that depend on a modified version of AP algorithm. The proposed methods are set to ensure both low time complexity and good accuracy of the clustering method. Firstly, a data set is divided into several subsets using one of two methods random fragmentation or K-means. Secondly, subsets are clustered into K clusters using K-Affinity Propagation (KAP) algorithm to select local cluster exemplars in each subset. Thirdly, the inverse weighted clustering algorithm is performed on all local cluster exemplars to select well-suited global exemplars of the whole data set. Finally, all the data points are clustered by the similarity between all global exemplars and each data point. Results show that the proposed clustering method can significantly reduce the clustering time and produce better clustering result in a way that is more effective and accurate than AP, KAP, and HAP algorithms.
|
| [18] |
Combining Word2Vec with Revised Vector Space Model for Better Code Retrieval [C] // |
| [19] |
Using Pointwise Mutual Information to Identify Implicit Features in Customer Reviews [C]// |
| [20] |
Using the Delphi Method to Value Protection of the Amazon Rainforest [J].https://doi.org/10.1016/j.ecolecon.2016.09.028 URL [本文引用: 1] 摘要
Valuing global environmental public goods can serve to mobilize international resources for their protection. While stated-preference valuation methods have been applied extensively to public goods valuation in individual countries, applications to global public goods with surveys in multiple countries are scarce due to complex and costly implementation. Benefit transfer is effectively infeasible when there are few existing studies valuing similar goods. The Delphi method, which relies on expert opinion, offers a third alternative. We explore this method for estimating the value of protecting the Amazon rainforest, by asking more than 200 environmental valuation experts from 37 countries on four continents to predict the outcome of a contingent valuation survey to elicit willingness-to-pay (WTP) for Amazon forest protection by their own countries' populations. The average annual per-household values of avoiding a 30% forest loss in the Amazon by 2050, assessed by experts, vary from a few dollars in low-income Asian countries, to a high near $100 in Canada, Germany and Norway. The elasticity with respect to average (PPP-adjusted) per-household incomes is close to unity. Results from the Delphi study match remarkably well those from a recent population stated-preference survey in Canada and the United States, using a similar valuation scenario.
|
| [21] |
Detecting Spammers in E-Commerce Website via Spectrum Features of User Relation Graph [ |
| [22] |
Detecting the Internet Water Army via Comprehensive Behavioral Features Using Large-scale E-commerce Reviews [C]// |

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}